ERaftGroup
课程介绍与路线图
今天我们将深入探讨如何为 GPU 编写高性能代码。 因此,作业2的一部分内容将要求大家进行大量的性能分析(Profiling)。你们需要为 Flash Attention 2 编写自己的 Triton 内核(Kernel),并设法确保所有这些组件都能达到极高的性能。因此,在本节课中,我们将深入技术细节,尝试为语言模型中的标准组件编写高性能代码。
因此,作业2的一部分内容将要求大家进行大量的性能分析(Profiling)。你们需要为 Flash Attention 2 编写自己的 Triton 内核(Kernel),并设法确保所有这些组件都能达到极高的性能。因此,在本节课中,我们将深入技术细节,尝试为语言模型中的标准组件编写高性能代码。 本节课的安排是:首先简要复习 GPU 基础知识,帮助大家重温后续内容所必需的 GPU 核心组件。
本节课的安排是:首先简要复习 GPU 基础知识,帮助大家重温后续内容所必需的 GPU 核心组件。
深入探讨与作业更新
接着,我将介绍关于基准测试(Benchmarking)与性能分析(Profiling)的基础知识,这对完成作业以及日后编写高性能的 PyTorch 或深度学习代码都大有裨益。然后,我们将动手编写一些内核(Kernel)。我们会先以类 C++ 的方式编写 CUDA 内核(CUDA Kernel),随后在 Triton 中实现相同的功能。 最后,我们将采用一种简单但极为有效的方法:利用 PyTorch 现有的即时编译器(Just-In-Time Compiler)自动优化代码。之后,我们会对比上述所有方法,并执行性能分析与基准测试。在整个过程中,我们将深入底层,一直追踪至 PTX (Parallel Thread Execution) 层面。该层级非常接近机器码,能帮助我们清晰理解编写代码时 GPU 底层的实际运行机制。如果时间允许(我认为应该来得及),我们将在课程最后编写一个高效的 Triton 版 Softmax 实现作为收尾。
最后,我们将采用一种简单但极为有效的方法:利用 PyTorch 现有的即时编译器(Just-In-Time Compiler)自动优化代码。之后,我们会对比上述所有方法,并执行性能分析与基准测试。在整个过程中,我们将深入底层,一直追踪至 PTX (Parallel Thread Execution) 层面。该层级非常接近机器码,能帮助我们清晰理解编写代码时 GPU 底层的实际运行机制。如果时间允许(我认为应该来得及),我们将在课程最后编写一个高效的 Triton 版 Softmax 实现作为收尾。 作业一已接近尾声,排行榜依然开放,大家仍可提交和更新结果。部分同学可能正在使用迟交宽限期(Late Days),请尽快完成作业一。作业二现已发布。
作业一已接近尾声,排行榜依然开放,大家仍可提交和更新结果。部分同学可能正在使用迟交宽限期(Late Days),请尽快完成作业一。作业二现已发布。 正如我此前所述,作业中包含大量系统层面的内容需要完成。现在,大家可以着手处理涉及 GPU 内核的有趣部分了。下周我们将探讨并行计算,这将是作业的另一半内容,例如编写数据并行等高效并行代码。
正如我此前所述,作业中包含大量系统层面的内容需要完成。现在,大家可以着手处理涉及 GPU 内核的有趣部分了。下周我们将探讨并行计算,这将是作业的另一半内容,例如编写数据并行等高效并行代码。 我们下周将对此进行详细讲解。
我们下周将对此进行详细讲解。
GPU 架构与内存层级复习
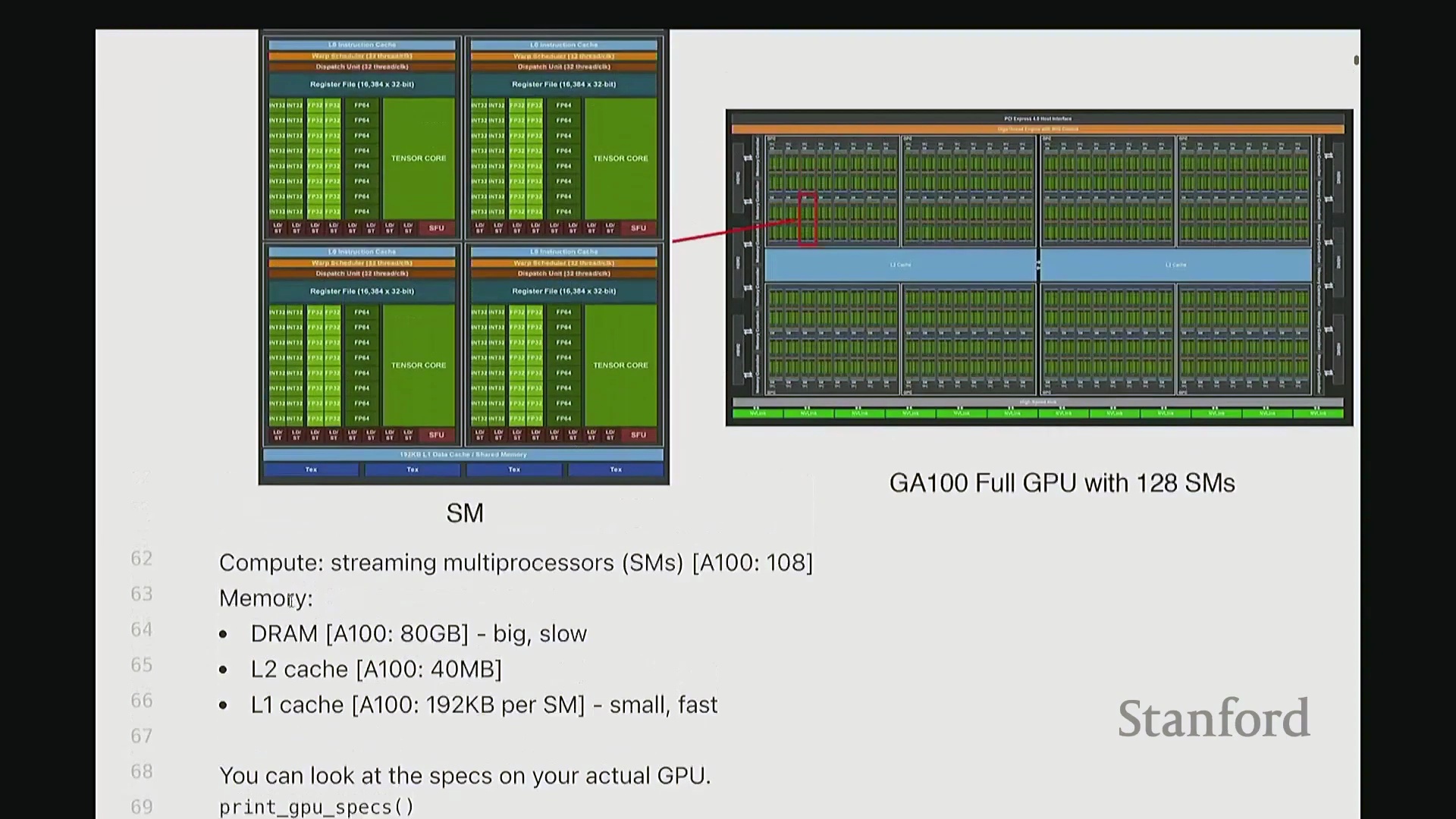
首先,让我们回顾一下 GPU 的工作原理。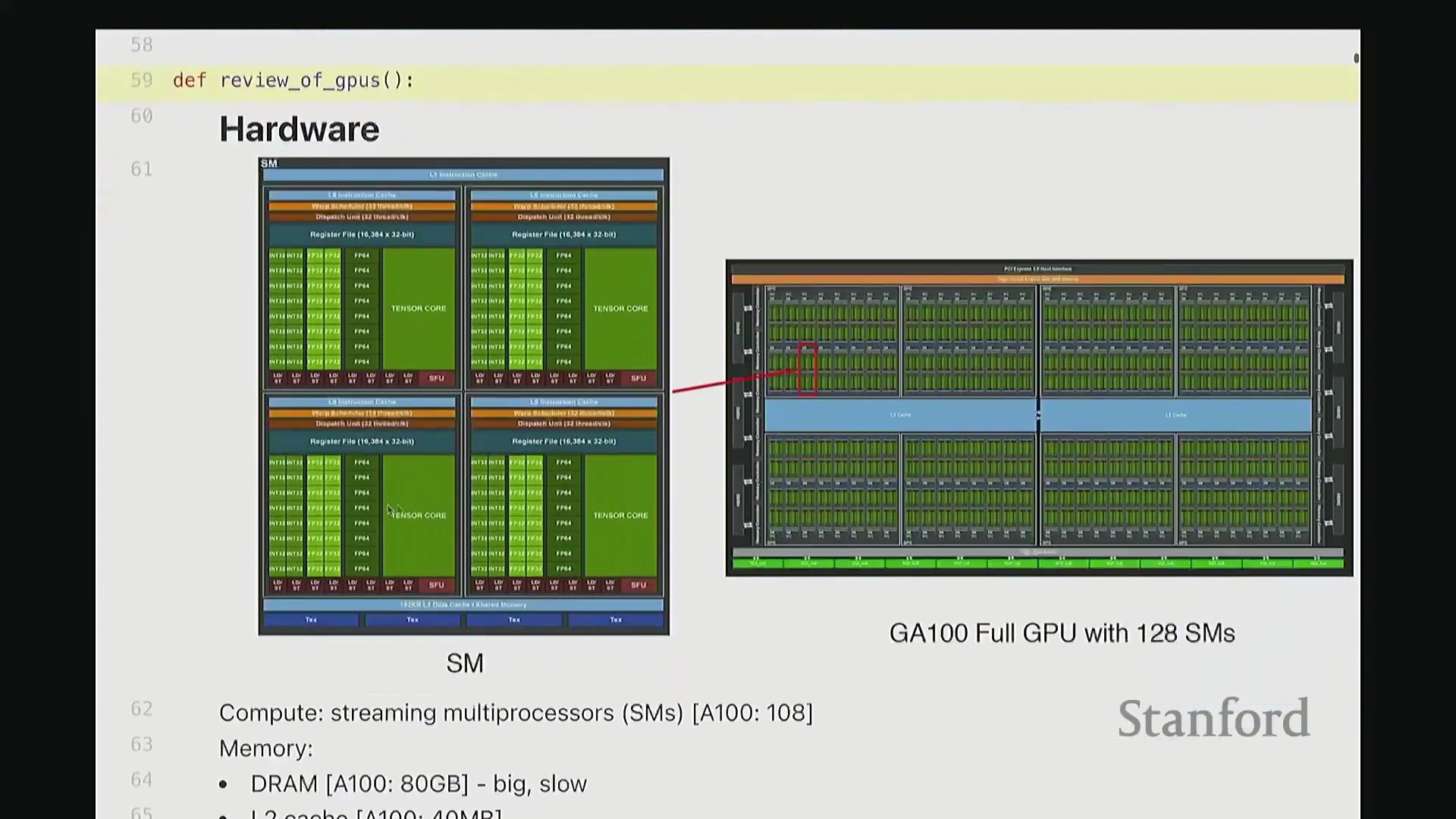 当我们使用 A100 或 H100 这类 GPU 时,硬件上会集成大量的流多处理器(Streaming Multiprocessor, SM)。每个 SM 内部都包含大量用于执行计算的算术逻辑单元,例如 INT32 或 FP32 计算核心。每个 SM 会同时调度并启动大量线程。此外,GPU 具备清晰的内存层级结构:包含容量大但速度较慢的 DRAM(即全局内存(Global Memory)),以及速度更快的各级缓存。事实上,大家在此处可以看到一个名为寄存器文件(Register File)的组件。
当我们使用 A100 或 H100 这类 GPU 时,硬件上会集成大量的流多处理器(Streaming Multiprocessor, SM)。每个 SM 内部都包含大量用于执行计算的算术逻辑单元,例如 INT32 或 FP32 计算核心。每个 SM 会同时调度并启动大量线程。此外,GPU 具备清晰的内存层级结构:包含容量大但速度较慢的 DRAM(即全局内存(Global Memory)),以及速度更快的各级缓存。事实上,大家在此处可以看到一个名为寄存器文件(Register File)的组件。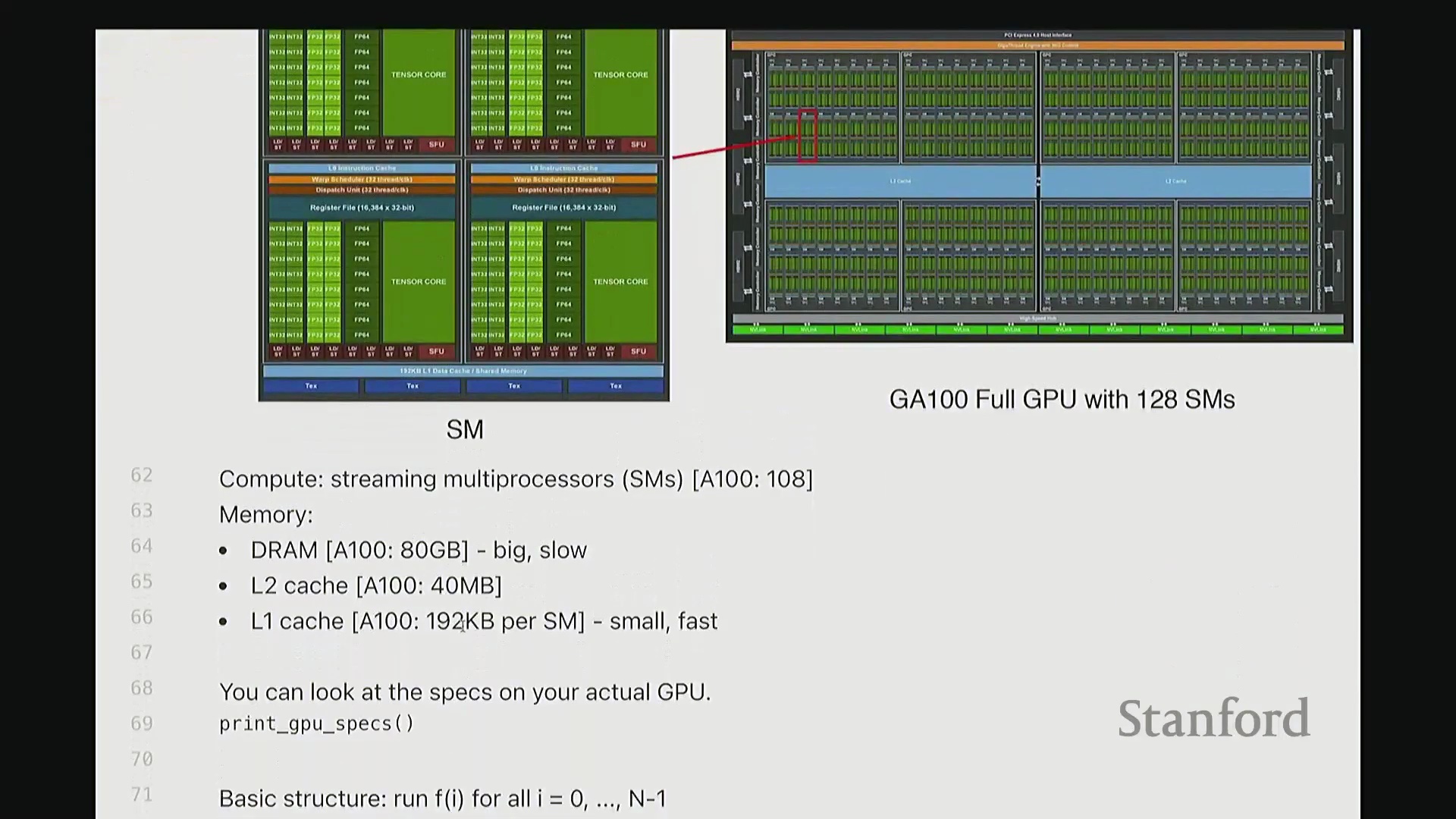
 这是每个线程均可访问的超高速存储单元,今天在为 GPU 编写高性能代码时,我们将大量依赖这些寄存器。
GPU 执行模型的基本结构如下:我们定义一组线程块(Thread Block),每个块会被调度至单个 SM 上执行。因此,线程块是我们进行代码设计与逻辑思考的基本原子单位,尤其是在使用 Triton 编程时。在每个线程块内部包含大量线程,实际计算正是由这些线程执行的。例如,若要对一个向量进行操作,你可以编写代码让每个线程处理该向量的若干元素。所有线程协同工作,即可完整处理整个向量。
这是每个线程均可访问的超高速存储单元,今天在为 GPU 编写高性能代码时,我们将大量依赖这些寄存器。
GPU 执行模型的基本结构如下:我们定义一组线程块(Thread Block),每个块会被调度至单个 SM 上执行。因此,线程块是我们进行代码设计与逻辑思考的基本原子单位,尤其是在使用 Triton 编程时。在每个线程块内部包含大量线程,实际计算正是由这些线程执行的。例如,若要对一个向量进行操作,你可以编写代码让每个线程处理该向量的若干元素。所有线程协同工作,即可完整处理整个向量。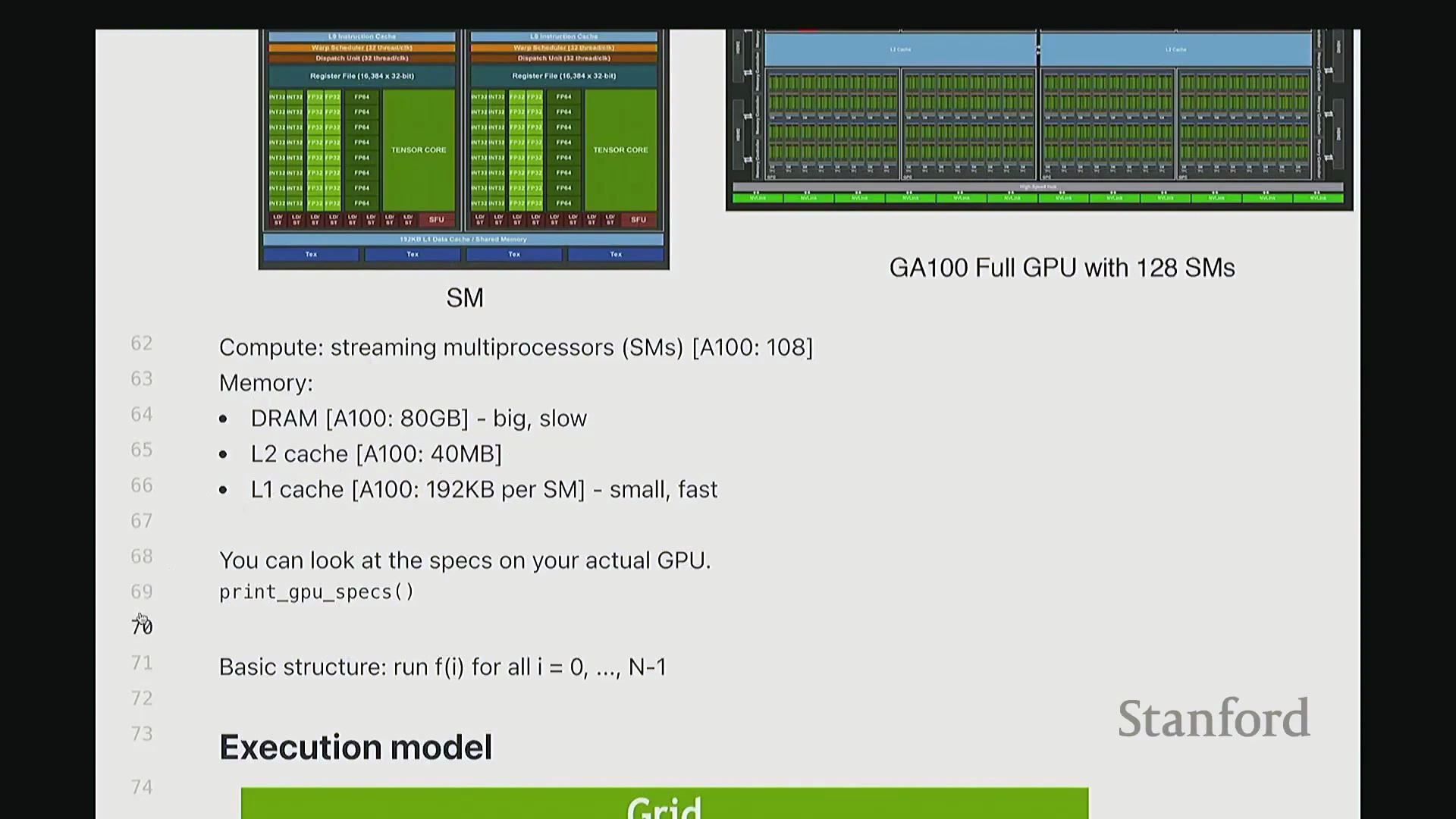
线程块、共享内存与线程束(Warps)
那么,为什么需要引入线程块(Thread Block)的概念?为什么不直接使用线程和庞大的全局上下文?因为同一线程块内的线程可以相互通信。它们位于同一个 SM 内,共享访问速度极快的共享内存。因此,在执行矩阵乘法等操作需要线程间传递数据时,块内通信速度极快;而若跨线程块或跨组通信,开销则会急剧增加。 因此,应尽可能将所需数据保留在同一线程块内,以维持极高的数据访问速度(其性能媲美 L1 缓存)。你可以利用该机制实现块内线程同步,但无法进行跨块同步。实际上,你也无法精确控制跨块执行的具体顺序。
还记得我上周提到的概念吗?虽然“波次(Wave)”并非大家通常熟知的固有术语,但在性能优化中却至关重要。实际上,当任务在 GPU 上运行时,线程会以每 32 个为一组进行划分,这一组线程被称为线程束(Warp)。
因此,应尽可能将所需数据保留在同一线程块内,以维持极高的数据访问速度(其性能媲美 L1 缓存)。你可以利用该机制实现块内线程同步,但无法进行跨块同步。实际上,你也无法精确控制跨块执行的具体顺序。
还记得我上周提到的概念吗?虽然“波次(Wave)”并非大家通常熟知的固有术语,但在性能优化中却至关重要。实际上,当任务在 GPU 上运行时,线程会以每 32 个为一组进行划分,这一组线程被称为线程束(Warp)。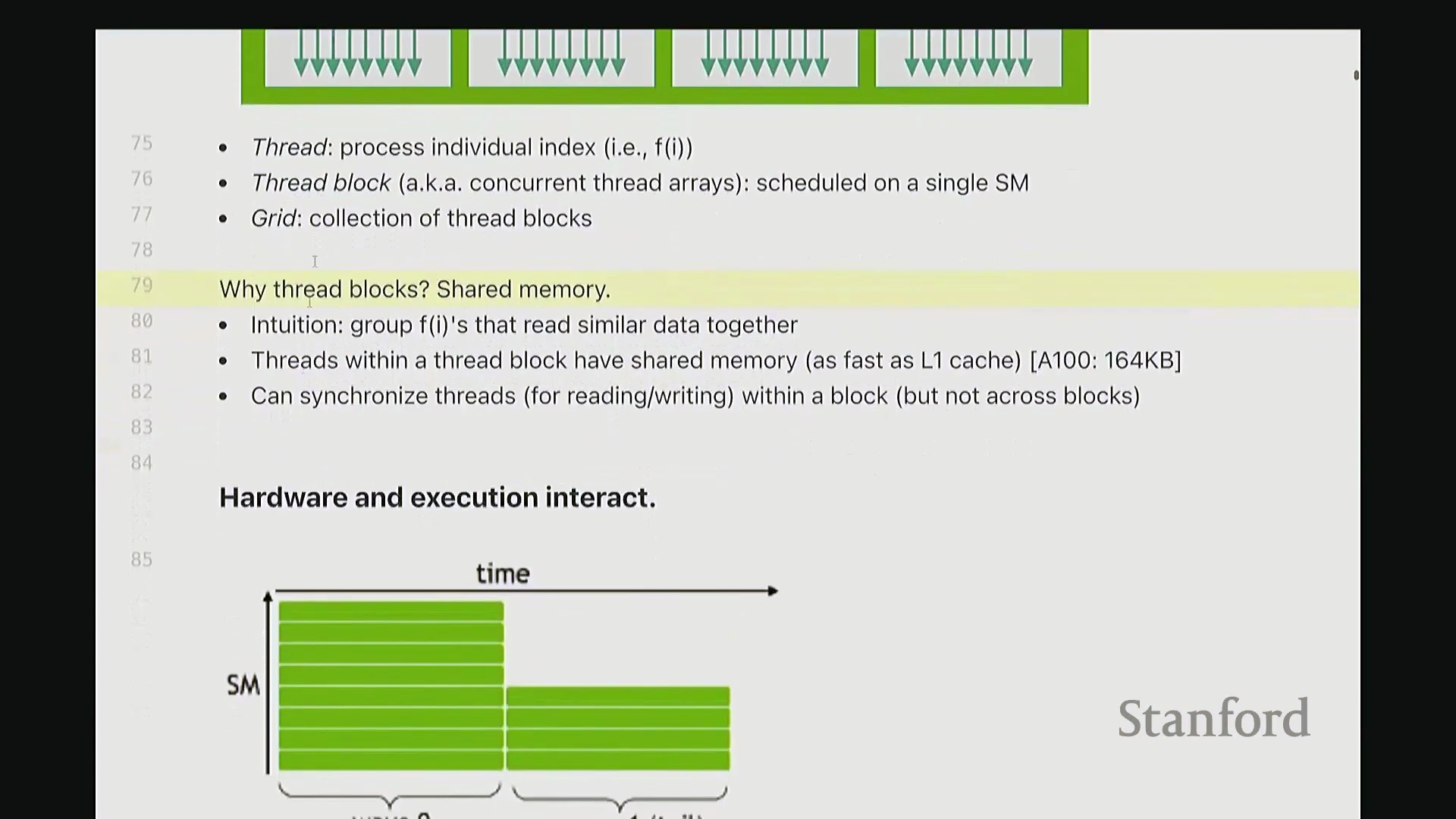 它们在 SM 中基本是同步执行的。因此,我们希望尽可能确保所有线程束(Warp)拥有均衡的计算负载。虽然在实际开发中并不总能完美实现,但若能达成,无疑是最理想的状态。因此,理想情况下,线程块的数量应远多于 SM 的数量,并合理分布以确保每个线程束的计算负载均衡。我们在编写高性能代码时,会努力朝这一目标优化。
它们在 SM 中基本是同步执行的。因此,我们希望尽可能确保所有线程束(Warp)拥有均衡的计算负载。虽然在实际开发中并不总能完美实现,但若能达成,无疑是最理想的状态。因此,理想情况下,线程块的数量应远多于 SM 的数量,并合理分布以确保每个线程束的计算负载均衡。我们在编写高性能代码时,会努力朝这一目标优化。
算术强度与硬件权衡
接下来是最后一个概念,也是本部分最重要的概念之一:算术强度(Arithmetic Intensity)。我们始终希望保持较高的算术强度。换言之,我们希望浮点运算次数(FLOPs)远高于内存传输的字节数。正如上节课所学的扩展规律,计算能力的提升速度远快于内存带宽的提升速度。因此,许多操作最终会受限于内存带宽,即变为内存受限(Memory Bound)状态,导致计算单元无法满负荷运行。 通常情况下,矩阵乘法属于计算受限(Compute Bound)操作。通过巧妙的优化,我们可以使其他操作也尽可能接近计算受限状态,或减轻其内存受限的程度。
以上就是对 GPU 架构的简要复习。希望大家牢记这些要点,并对执行模型保持清晰的认知。如果大家对上述机制仍有疑问,请随时打断我提问。
(提问)线程束(Warp)的具体作用是什么?抱歉,让我解释一下。线程束(Warp)本质上是一组被硬件同时调度和执行的线程。引入线程束的目的在于精简控制逻辑。由于这 32 个线程被同步执行,硬件无需为每个线程单独配置控制单元,只需每 32 个线程共享一个即可。因此,你会发现计算单元的数量远多于线程束调度器(Warp Scheduler)的数量。这种设计使我们能够以极低的控制开销实现大规模并行计算,这也是 GPU 与 CPU 在设计哲学上的重要权衡。
通常情况下,矩阵乘法属于计算受限(Compute Bound)操作。通过巧妙的优化,我们可以使其他操作也尽可能接近计算受限状态,或减轻其内存受限的程度。
以上就是对 GPU 架构的简要复习。希望大家牢记这些要点,并对执行模型保持清晰的认知。如果大家对上述机制仍有疑问,请随时打断我提问。
(提问)线程束(Warp)的具体作用是什么?抱歉,让我解释一下。线程束(Warp)本质上是一组被硬件同时调度和执行的线程。引入线程束的目的在于精简控制逻辑。由于这 32 个线程被同步执行,硬件无需为每个线程单独配置控制单元,只需每 32 个线程共享一个即可。因此,你会发现计算单元的数量远多于线程束调度器(Warp Scheduler)的数量。这种设计使我们能够以极低的控制开销实现大规模并行计算,这也是 GPU 与 CPU 在设计哲学上的重要权衡。 CPU 会将更多的芯片面积分配给复杂的控制逻辑和分支预测等功能,而 GPU 则将重心放在计算核心上,控制逻辑相对精简。
CPU 会将更多的芯片面积分配给复杂的控制逻辑和分支预测等功能,而 GPU 则将重心放在计算核心上,控制逻辑相对精简。
基准测试与性能分析的关键作用
接下来我们将探讨一些进阶内容。我认为大家只需牢记一条核心原则:若想编写高性能代码,就必须对代码进行基准测试(Benchmarking)与性能分析(Profiling)。 这听起来或许显而易见,但我见过太多反例:许多学生或开发者起初会认为“我觉得这里是瓶颈,我要花几个小时优化它”,结果却发现该处根本不是瓶颈。优化过程固然有趣,但这无疑是时间分配上的失误。因此,只有借助专业的性能分析工具,你才能精准定位瓶颈所在,并洞察硬件的实际运行状态。掌握这些信息后,你便能将精力集中投入到真正影响性能的关键路径上。
这正是我想传达的核心思想。GPU 的执行细节以及编写 Softmax 内核的具体方法可能会随时间演进,你未来甚至可能完全依赖 Torch Compile 的自动即时编译功能。但无论如何,工具形态如何变化,“必须进行性能分析”这一原则永远不会过时。
这听起来或许显而易见,但我见过太多反例:许多学生或开发者起初会认为“我觉得这里是瓶颈,我要花几个小时优化它”,结果却发现该处根本不是瓶颈。优化过程固然有趣,但这无疑是时间分配上的失误。因此,只有借助专业的性能分析工具,你才能精准定位瓶颈所在,并洞察硬件的实际运行状态。掌握这些信息后,你便能将精力集中投入到真正影响性能的关键路径上。
这正是我想传达的核心思想。GPU 的执行细节以及编写 Softmax 内核的具体方法可能会随时间演进,你未来甚至可能完全依赖 Torch Compile 的自动即时编译功能。但无论如何,工具形态如何变化,“必须进行性能分析”这一原则永远不会过时。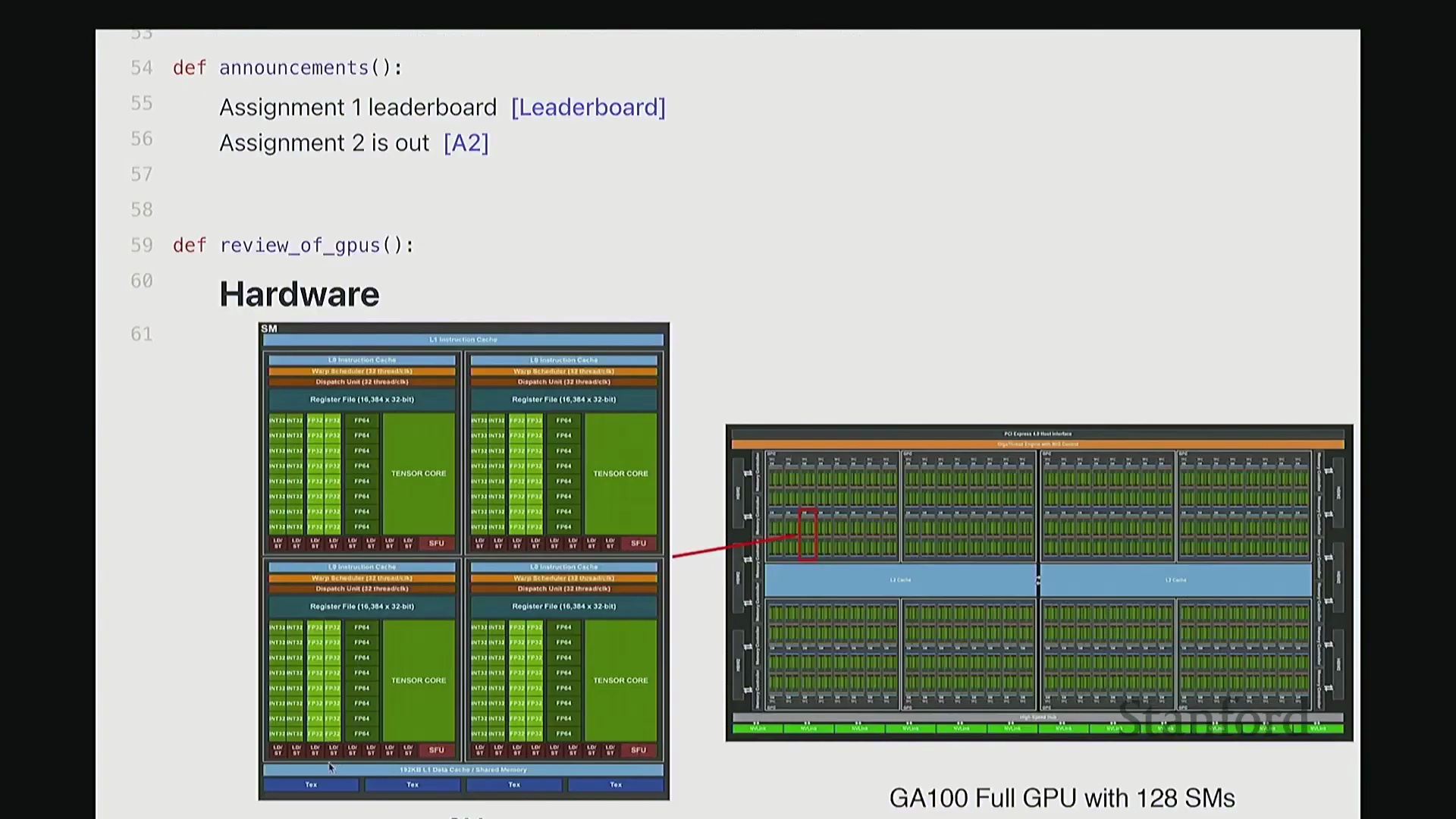 因此,希望大家将这一理念内化于心:追求高性能代码,就必须持续进行性能分析。实际上,纯理论分析存在局限性。本课程中“系统”层面的内容通常可以通过逻辑严密推导,但“架构”层面的特性往往难以仅凭理论预测,你可能需要借助屋顶线模型(Roofline Model)等工具进行辅助分析。
因此,希望大家将这一理念内化于心:追求高性能代码,就必须持续进行性能分析。实际上,纯理论分析存在局限性。本课程中“系统”层面的内容通常可以通过逻辑严密推导,但“架构”层面的特性往往难以仅凭理论预测,你可能需要借助屋顶线模型(Roofline Model)等工具进行辅助分析。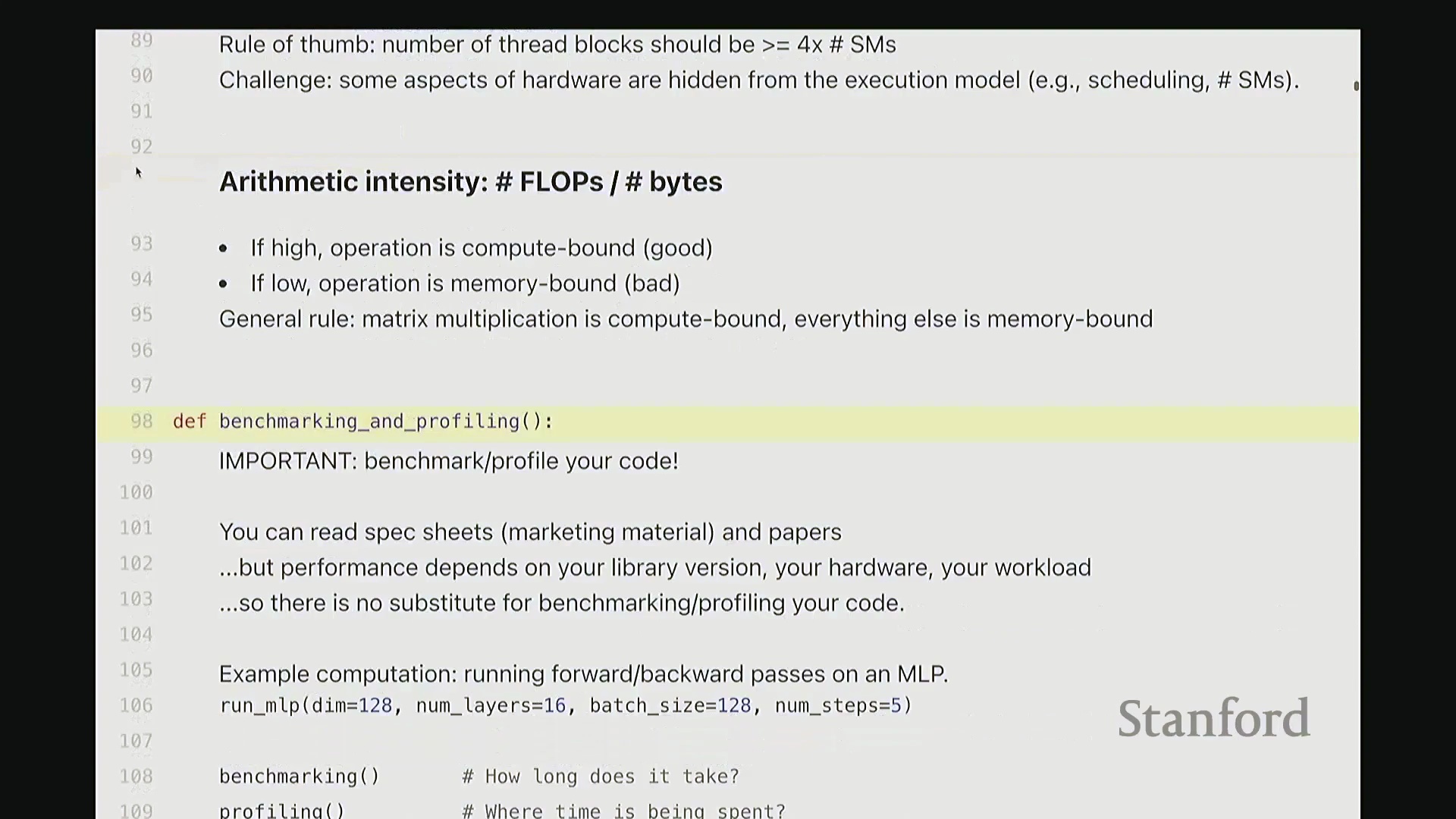 至于你的矩阵乘法究竟能跑多快?这往往取决于底层库的版本或具体的硬件型号。真正的瓶颈在哪里?成因是什么?这背后涉及大量开发者难以完全掌控的微代码(Microcode)细节。因此,在开发过程中,你最终必须进行端到端(End-to-End)的基准测试。
至于你的矩阵乘法究竟能跑多快?这往往取决于底层库的版本或具体的硬件型号。真正的瓶颈在哪里?成因是什么?这背后涉及大量开发者难以完全掌控的微代码(Microcode)细节。因此,在开发过程中,你最终必须进行端到端(End-to-End)的基准测试。
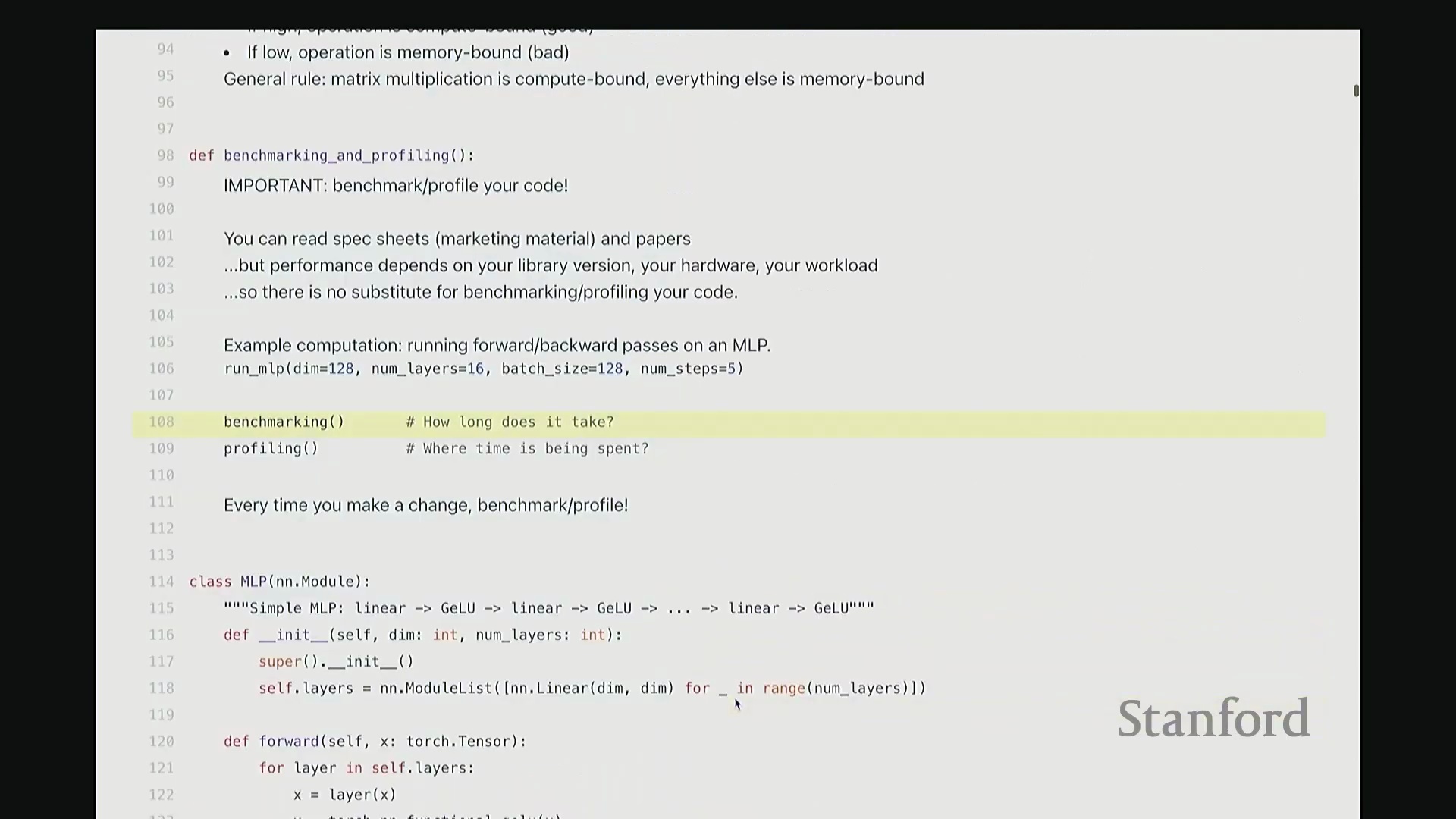
基线 MLP 示例设置
接下来我将展示一个计算示例。与大家在作业一中完成的任务相比,这是我们能运行的最简模型。我将运行一个非常基础的多层感知机(Multi-Layer Perceptron, MLP)。 该模型将包含 128 个隐藏维度、16 层网络、指定的批量大小(Batch Size),并循环运行 5 个迭代步骤。在此过程中,我将执行 5 步的前向传播(Forward Pass)与反向传播(Backward Pass)。为保持代码结构清晰,大致设置如下:
首先定义一个 MLP 模型(稍后展示代码),接着生成一个服从随机高斯分布的输入张量。随后循环运行 5 个迭代步骤,在最后一步中执行前向传播与反向传播,并返回 MLP 输出的均值。没错,这里甚至没有定义损失函数,逻辑非常简单。简而言之,我们仅执行 MLP 的前向传播,并在末尾计算输出均值。
该模型将包含 128 个隐藏维度、16 层网络、指定的批量大小(Batch Size),并循环运行 5 个迭代步骤。在此过程中,我将执行 5 步的前向传播(Forward Pass)与反向传播(Backward Pass)。为保持代码结构清晰,大致设置如下:
首先定义一个 MLP 模型(稍后展示代码),接着生成一个服从随机高斯分布的输入张量。随后循环运行 5 个迭代步骤,在最后一步中执行前向传播与反向传播,并返回 MLP 输出的均值。没错,这里甚至没有定义损失函数,逻辑非常简单。简而言之,我们仅执行 MLP 的前向传播,并在末尾计算输出均值。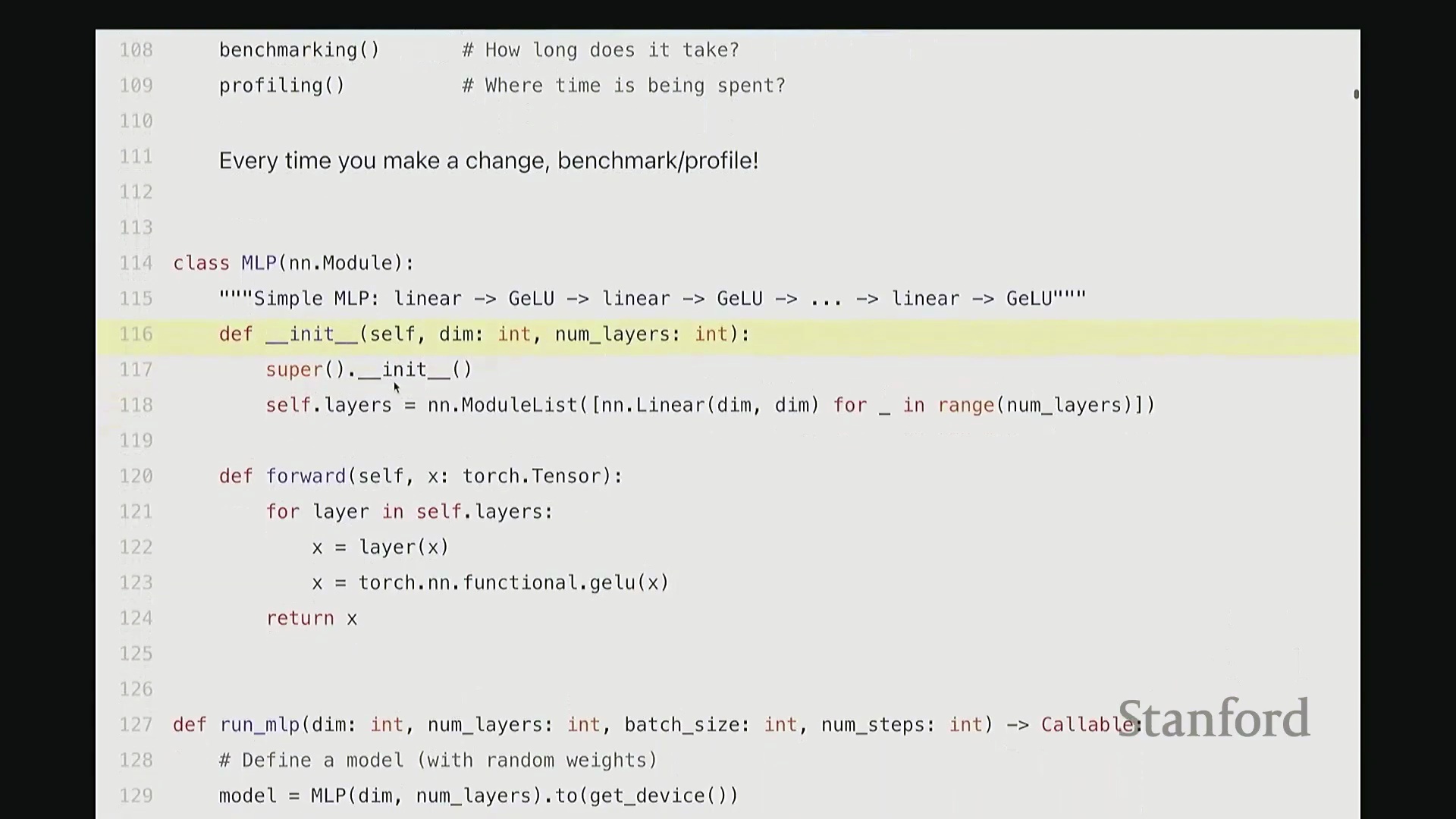 该 MLP 采用最基础的结构,你可以将其视为一系列线性层(Linear Layer)的简单堆叠。代码中,我们在层与层之间穿插了 GeLU 激活函数(Gaussian Error Linear Unit)。因此结构大致为:GeLU、线性层、线性层、GeLU……以此类推。所有张量的特征维度均保持一致(即维度对齐)。
该 MLP 采用最基础的结构,你可以将其视为一系列线性层(Linear Layer)的简单堆叠。代码中,我们在层与层之间穿插了 GeLU 激活函数(Gaussian Error Linear Unit)。因此结构大致为:GeLU、线性层、线性层、GeLU……以此类推。所有张量的特征维度均保持一致(即维度对齐)。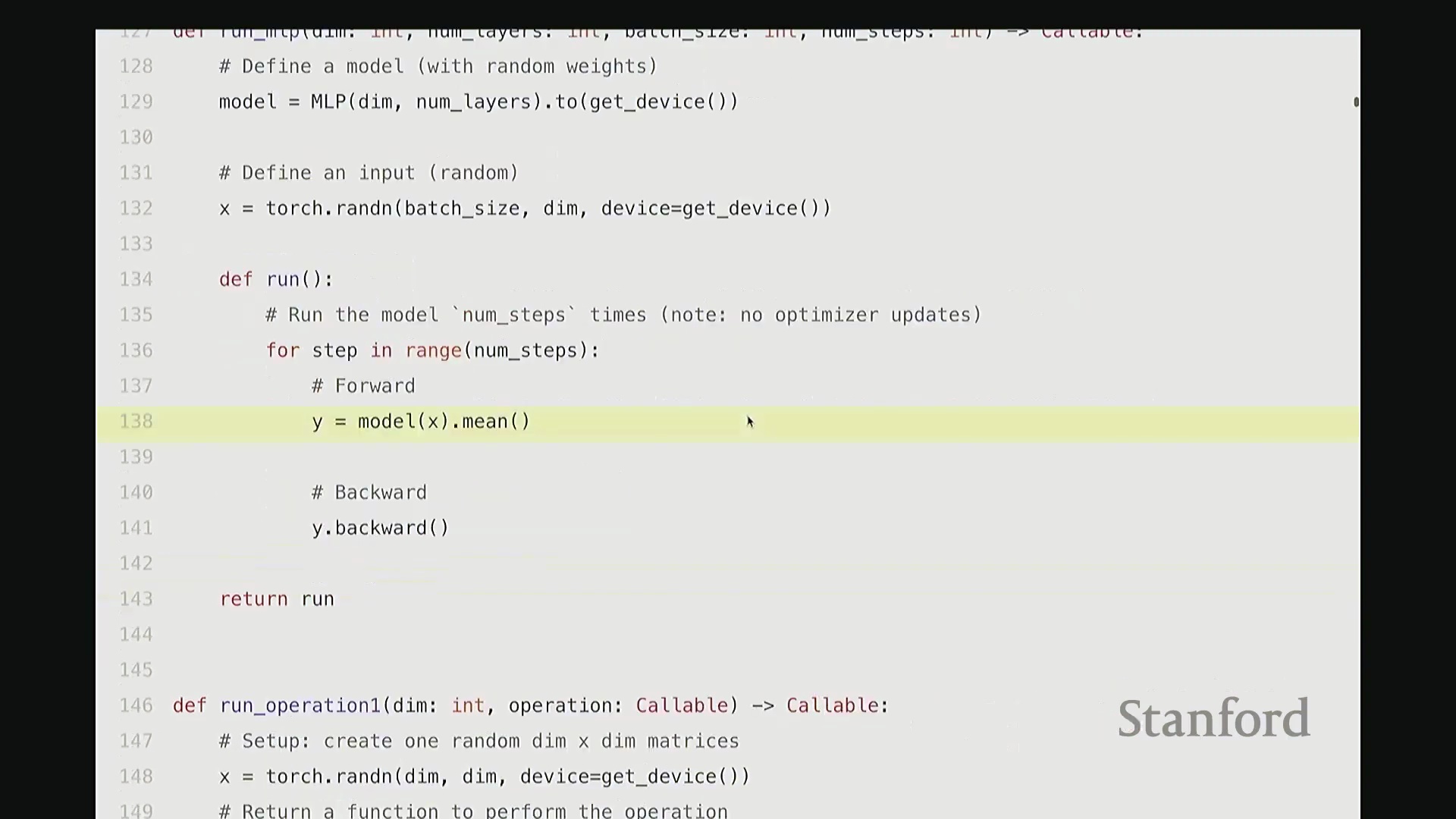 相信大家对这种基础的 MLP 结构已经非常熟悉。接下来我们返回上一页幻灯片。稍等,抱歉,我想切回上面的内容。
相信大家对这种基础的 MLP 结构已经非常熟悉。接下来我们返回上一页幻灯片。稍等,抱歉,我想切回上面的内容。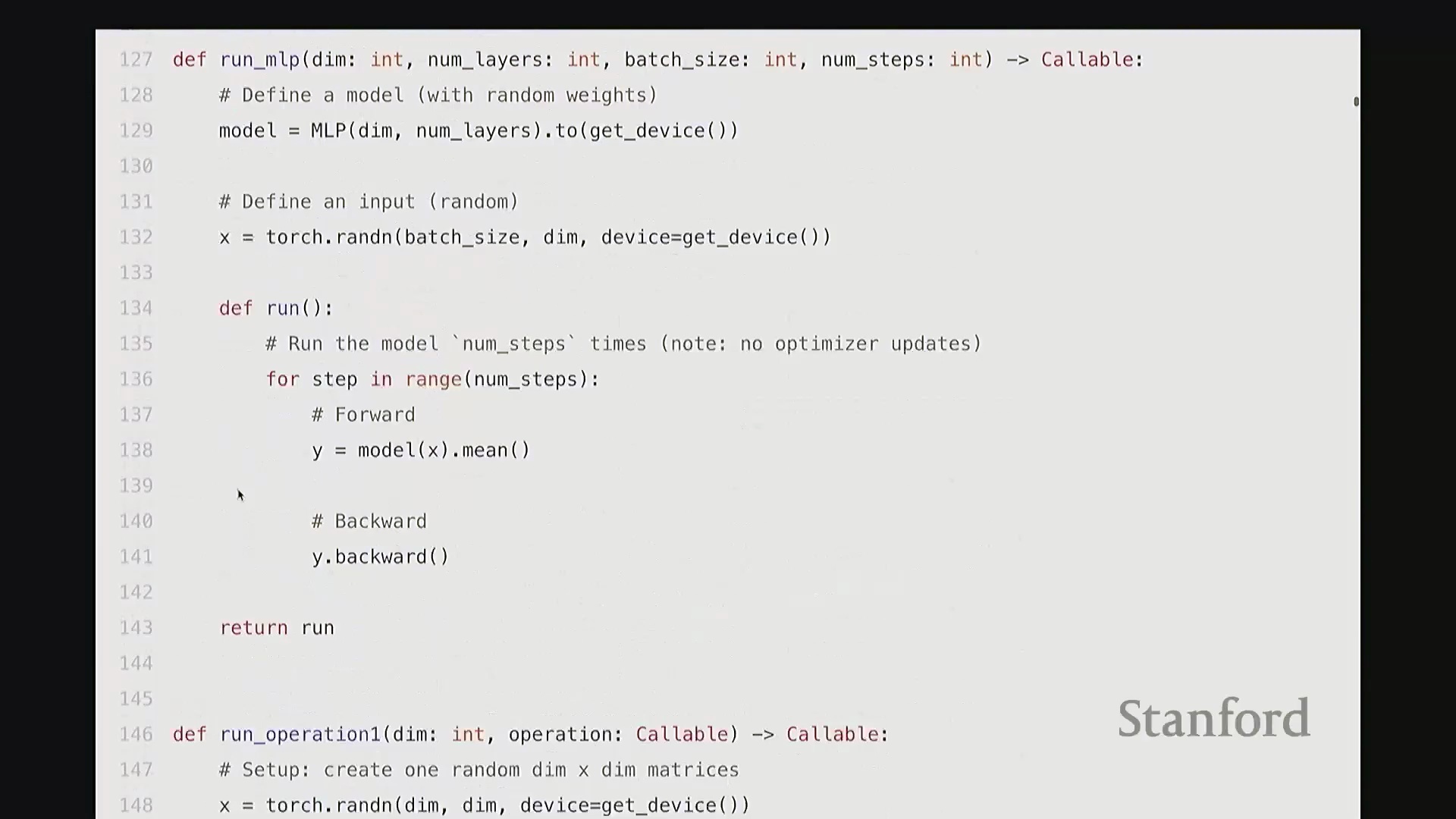
基准测试与性能分析简介
回到这里,确认无误。现在我们已经有了这段准备运行的多层感知机(Multi-Layer Perceptron, MLP)代码。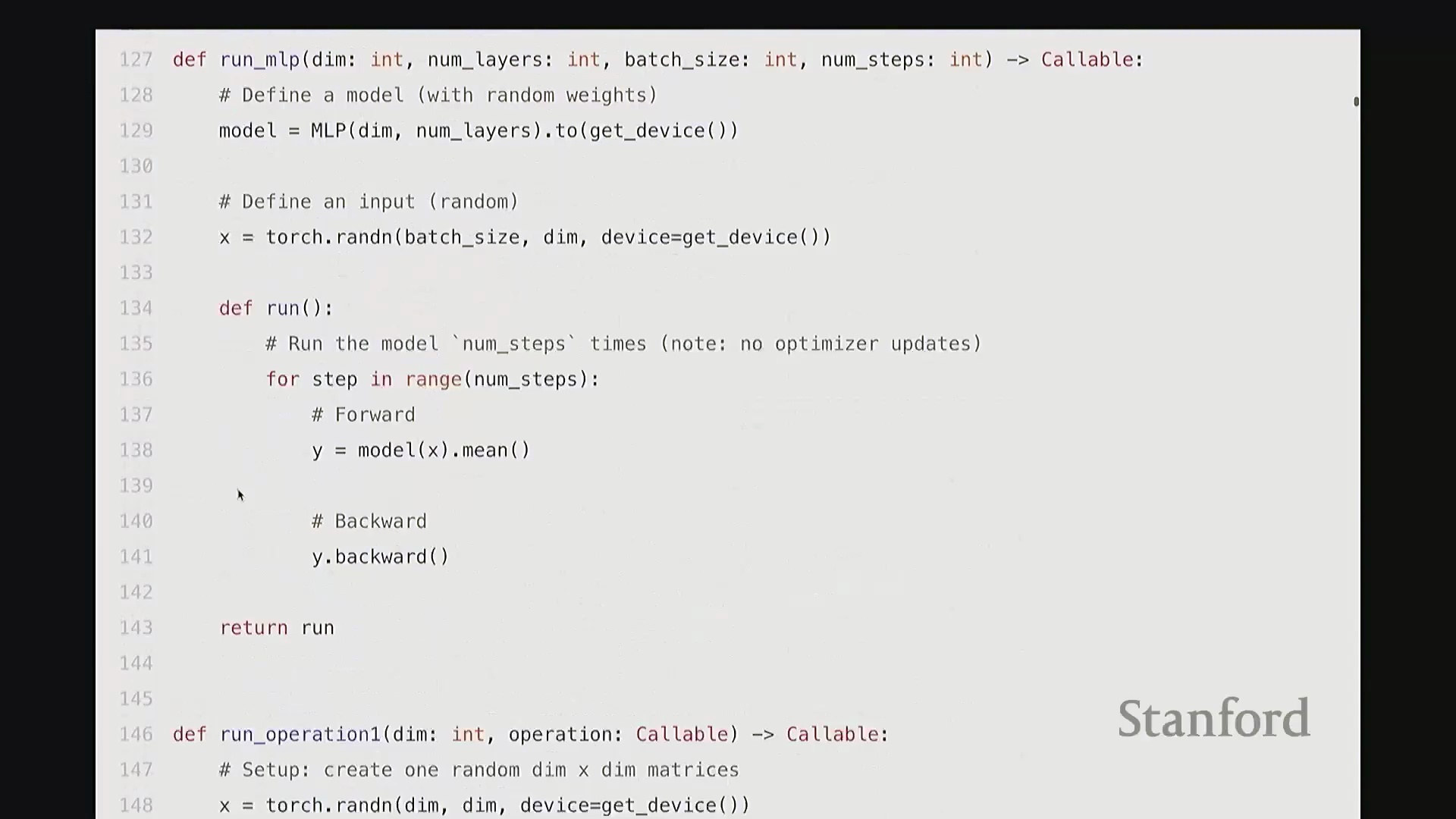 接下来我将执行两项任务。首先是基准测试(Benchmarking),即进行计时操作,以量化该函数的执行耗时。随后是性能分析(Profiling),旨在深入函数内部,精准定位时间具体消耗在哪些环节。
接下来我将执行两项任务。首先是基准测试(Benchmarking),即进行计时操作,以量化该函数的执行耗时。随后是性能分析(Profiling),旨在深入函数内部,精准定位时间具体消耗在哪些环节。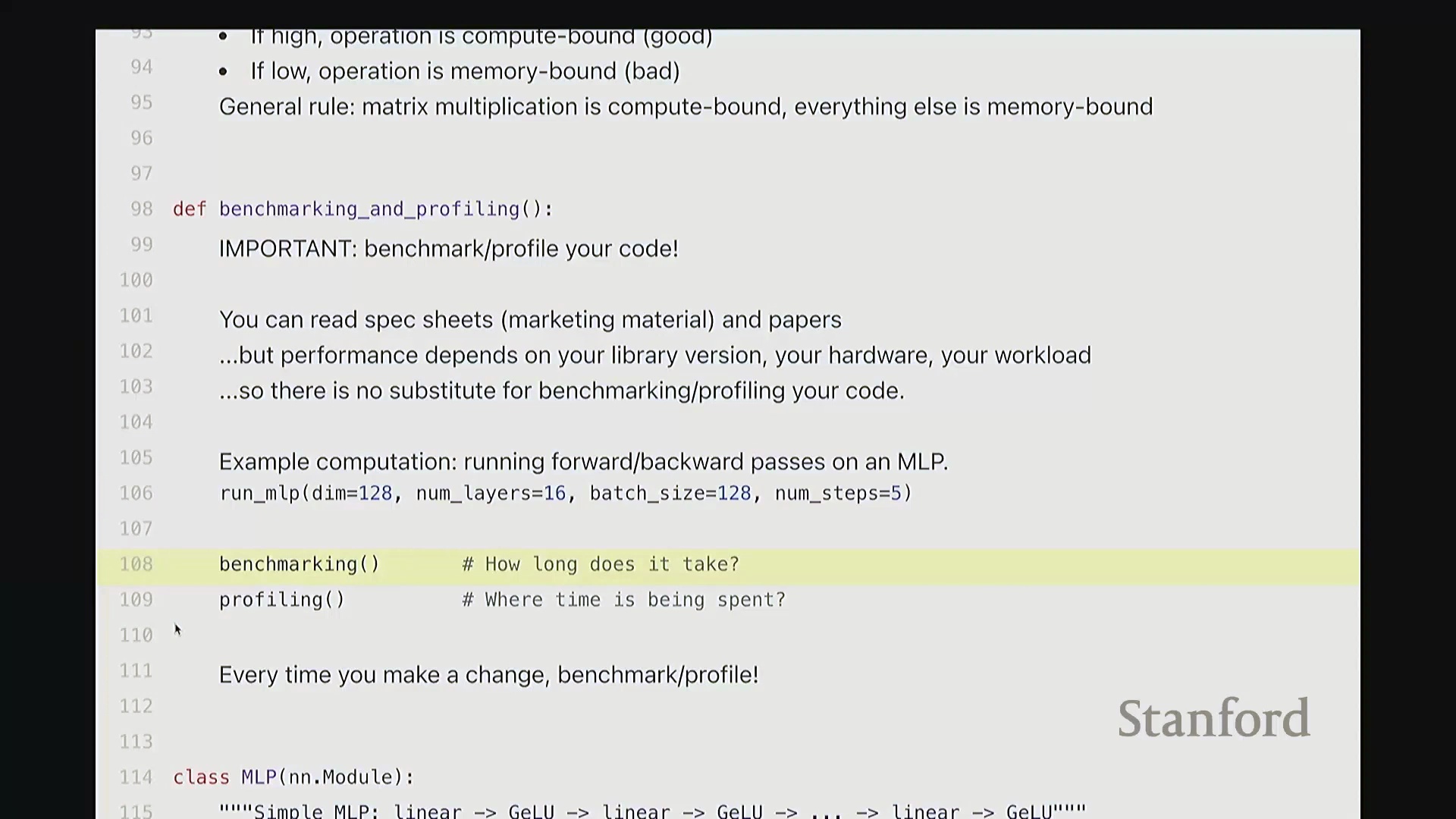 下面让我们从基准测试开始。
下面让我们从基准测试开始。
基准测试的基础与目的
基准测试的核心在于测量执行操作所消耗的实际时间,即墙上时钟时间(Wall-Clock Time)。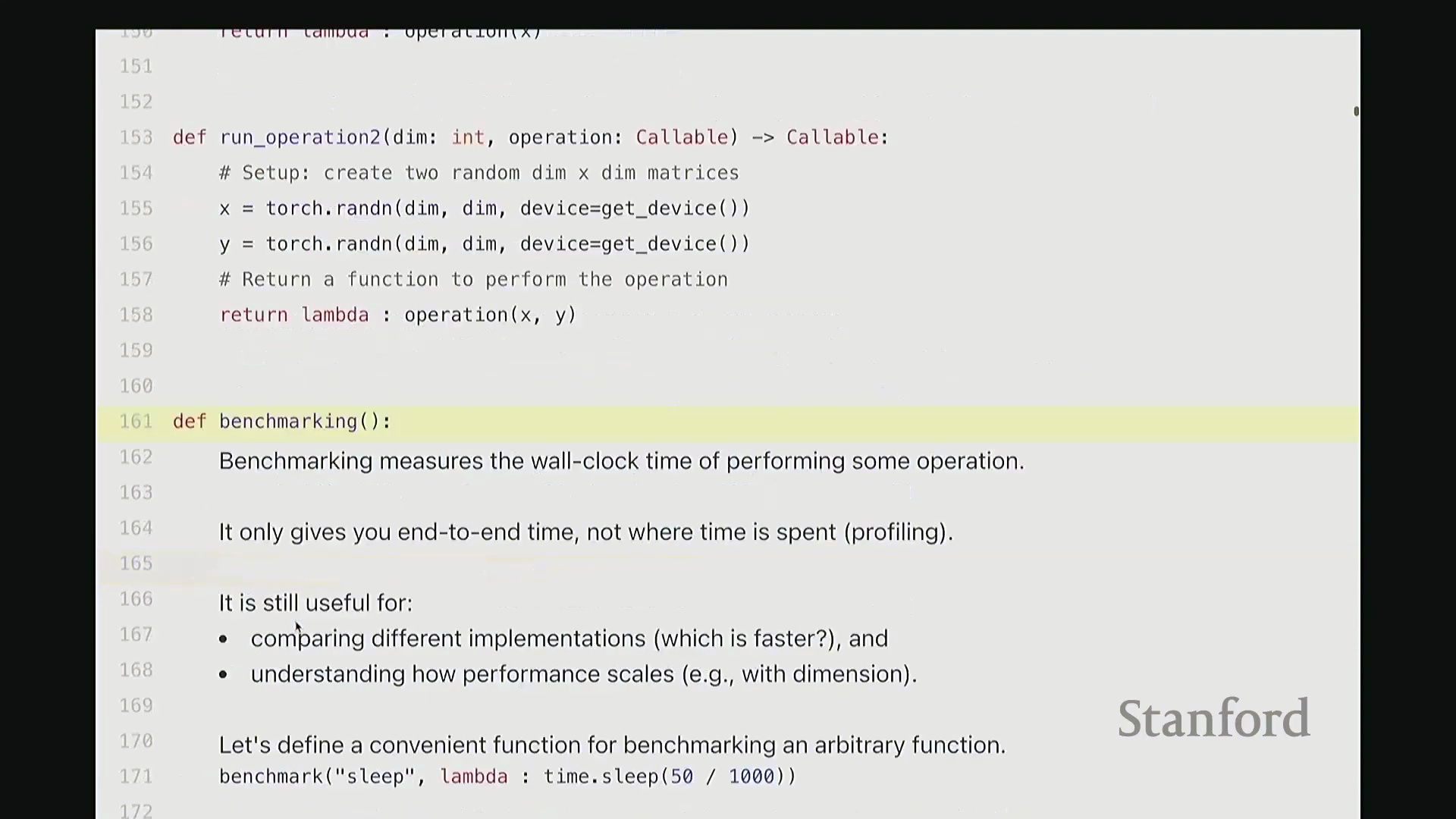 此处,我主要关注 MLP 函数的端到端(End-to-End)执行耗时。这其中有几个关键细节需要注意。你或许会想:“连如何调用计时函数都需要专门讲解吗?”但在实际测量时,确实需要格外谨慎。若不注意这些细节,在后续作业中极易踩坑。那么,我们为什么要进行基准测试呢?
此处,我主要关注 MLP 函数的端到端(End-to-End)执行耗时。这其中有几个关键细节需要注意。你或许会想:“连如何调用计时函数都需要专门讲解吗?”但在实际测量时,确实需要格外谨慎。若不注意这些细节,在后续作业中极易踩坑。那么,我们为什么要进行基准测试呢?
稍后我们将对比多种实现方案,包括 Triton 实现、手写 C++ 实现、PyTorch 原生实现以及 Torch Compile 编译后的版本。我们需要评估:手写 CUDA 内核(CUDA Kernel)是否真的能带来显著的性能收益?同时,我们也希望了解当矩阵乘法规模增大时,运行时间会如何变化。因此,我们需要通过经验性的基准测试来量化这些情况。
关键计时实践:预热与同步
因此,在整个课程中,我将使用这个 benchmark 函数。它本质上是一个计时包装器(Wrapper)。我会逐步拆解其逻辑。该函数接收一个待测试的目标函数(即 run 函数)。首先执行若干次预热(Warm-up)迭代,随后再进行多次正式的性能测试。你可能会问:“这里的‘预热’究竟有何作用?”关键在于,当你首次运行 PyTorch 代码并向 GPU 分发任务时,过程看似迅速且透明。但在首次执行期间,后台实际上正在进行底层机器码的编译工作。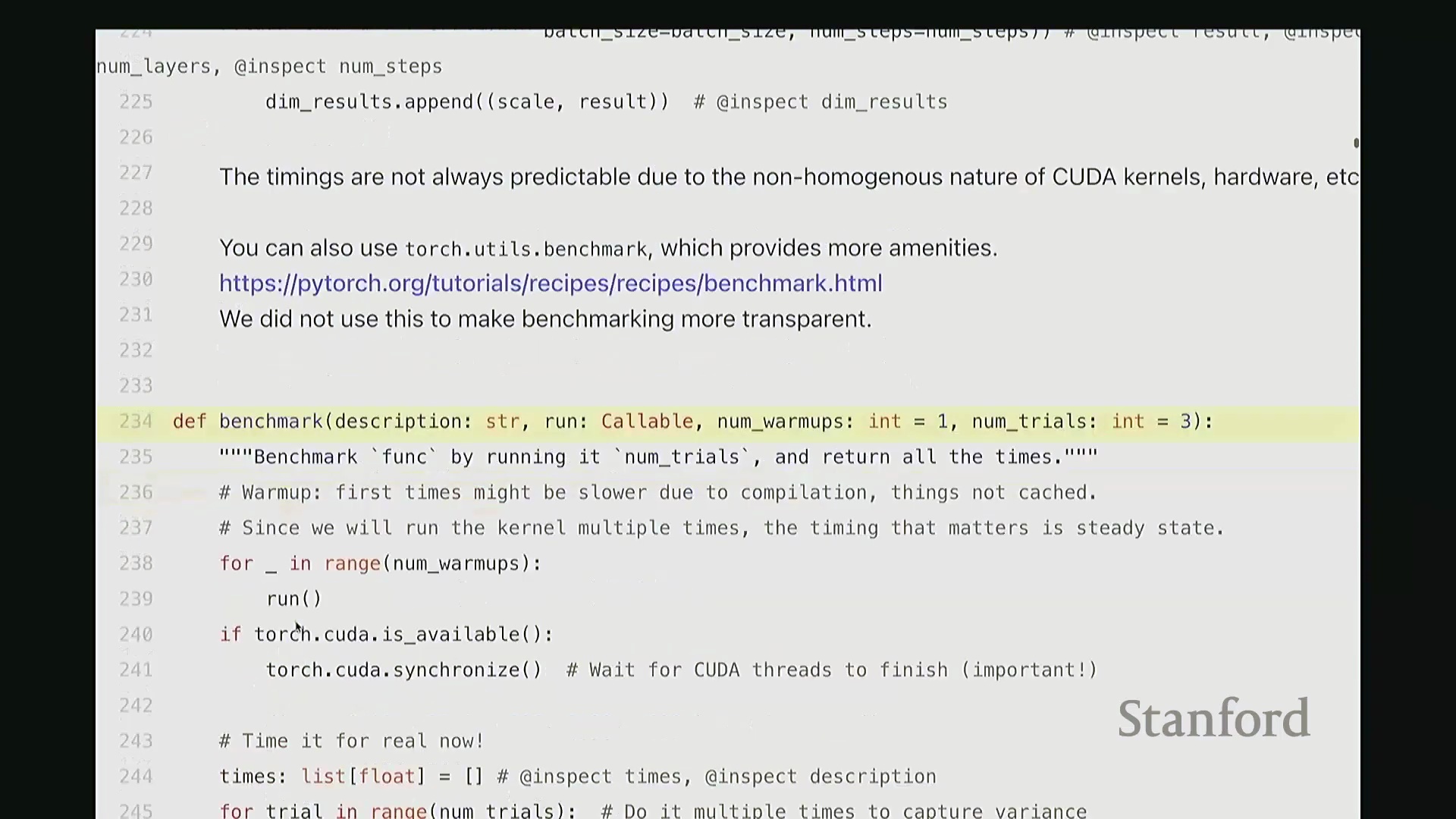 此时,代码指令正被传输至 GPU,同时伴随各种后台初始化操作。因此,必须执行预热迭代,以确保我们测量的并非冷启动耗时,而是系统进入稳定状态后的稳态(Steady-state)性能。在动辄运行成千上万次的实际场景中,我们关心的应是稳态表现,而非 CUDA 代码即时编译(Just-In-Time Compilation)的速度。这正是预热的必要性所在,务必在每次测试中保留预热步骤。
此时,代码指令正被传输至 GPU,同时伴随各种后台初始化操作。因此,必须执行预热迭代,以确保我们测量的并非冷启动耗时,而是系统进入稳定状态后的稳态(Steady-state)性能。在动辄运行成千上万次的实际场景中,我们关心的应是稳态表现,而非 CUDA 代码即时编译(Just-In-Time Compilation)的速度。这正是预热的必要性所在,务必在每次测试中保留预热步骤。
另一个至关重要的细节是(稍后讲解性能分析器(Profiler)时会进一步展开),即必须调用 torch.cuda.synchronize。它的作用是什么?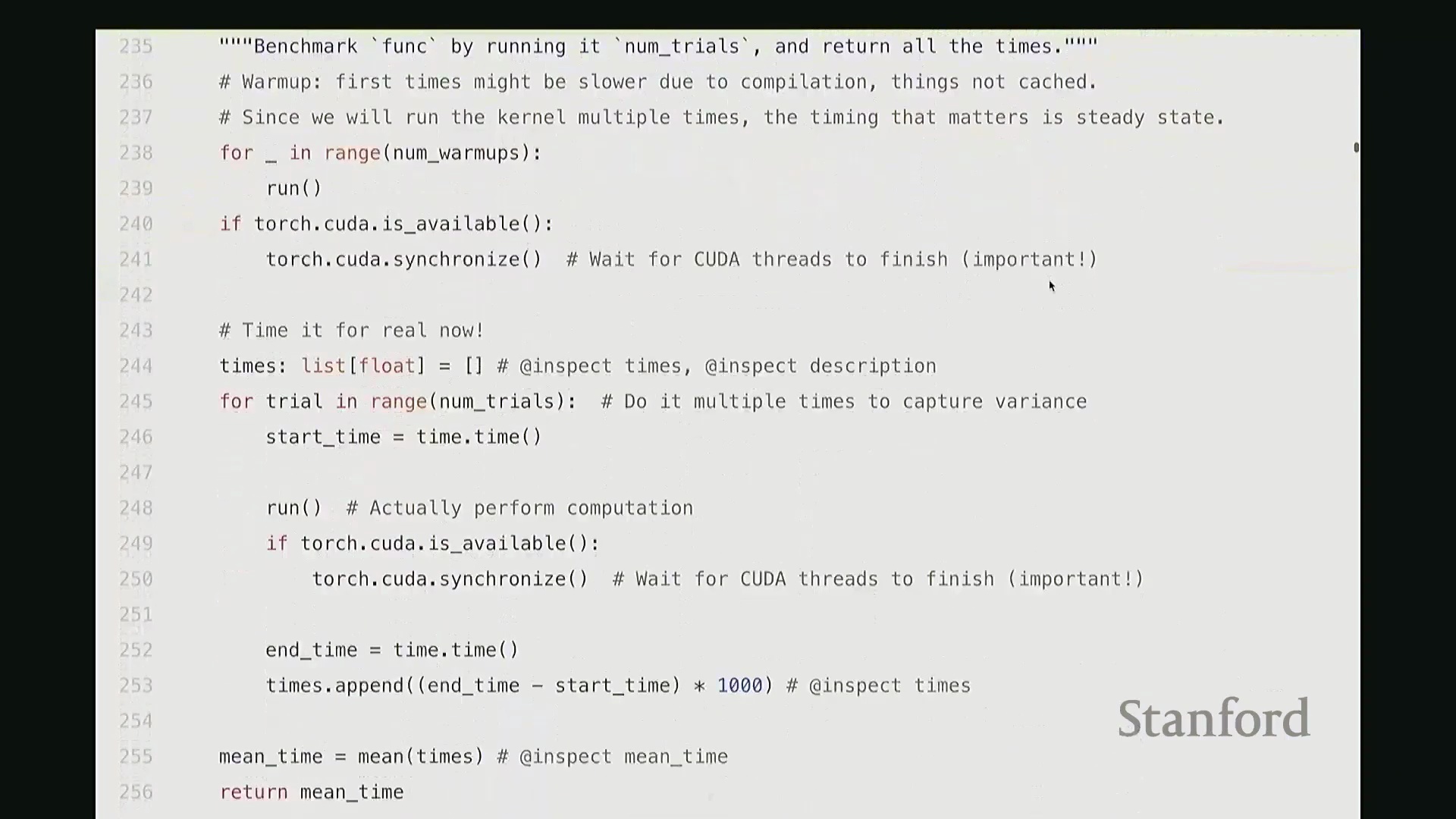 实际上,CPU 与 GPU 是计算机中两个独立的计算单元,具备异步执行(Asynchronous Execution)的能力。其执行模型如下:此处的 Python 代码运行在 CPU 上。当调用某个算子时,CPU 会向 GPU 提交一系列 CUDA 内核,相当于下达指令“请执行这些任务”。随后 GPU 开始处理,而 CPU 则继续执行后续代码,并不会阻塞等待 GPU 完成。这种异步机制虽有利于编写高性能代码,但在进行基准测试时则会引发问题。若计时期间 GPU 仍在后台运算,而 CPU 已执行完毕,那么测得的根本不是 GPU 的真实耗时。因此,
实际上,CPU 与 GPU 是计算机中两个独立的计算单元,具备异步执行(Asynchronous Execution)的能力。其执行模型如下:此处的 Python 代码运行在 CPU 上。当调用某个算子时,CPU 会向 GPU 提交一系列 CUDA 内核,相当于下达指令“请执行这些任务”。随后 GPU 开始处理,而 CPU 则继续执行后续代码,并不会阻塞等待 GPU 完成。这种异步机制虽有利于编写高性能代码,但在进行基准测试时则会引发问题。若计时期间 GPU 仍在后台运算,而 CPU 已执行完毕,那么测得的根本不是 GPU 的真实耗时。因此,torch.cuda.synchronize 的核心作用在于:强制 CPU 等待,确保 GPU 完成所有已排队的 CUDA 任务,使 CPU 与 GPU 的执行进度保持同步。
同步完成后,CPU 与 GPU 状态对齐,此时方可进行精确计时。我将对目标操作进行多次计时与重复计算(示例中使用了 sleep 命令)。假设每次休眠 50 毫秒,三次计时结果应与之吻合。当然,在 run 函数末尾,我也调用了 torch.cuda.synchronize,以确保所有 GPU 任务彻底完成后再结束计时。若 CPU 执行过快,该函数会在此阻塞等待;反之亦然。如此便完成了单次计时流程。随后,由于 GPU 的频率缩放、散热等动态特性,单次测量易产生波动,因此需多次重复运行并取平均值后返回。这就是完整的基准测试代码。逻辑虽简单,但请务必牢记两大关键点:始终执行预热,并确保调用 CUDA 同步。若遗漏这些步骤,极易得出荒谬的结果(例如,大规模矩阵乘法看似瞬间完成),这显然不符合物理事实。
经验结果:矩阵乘法与 MLP 的扩展
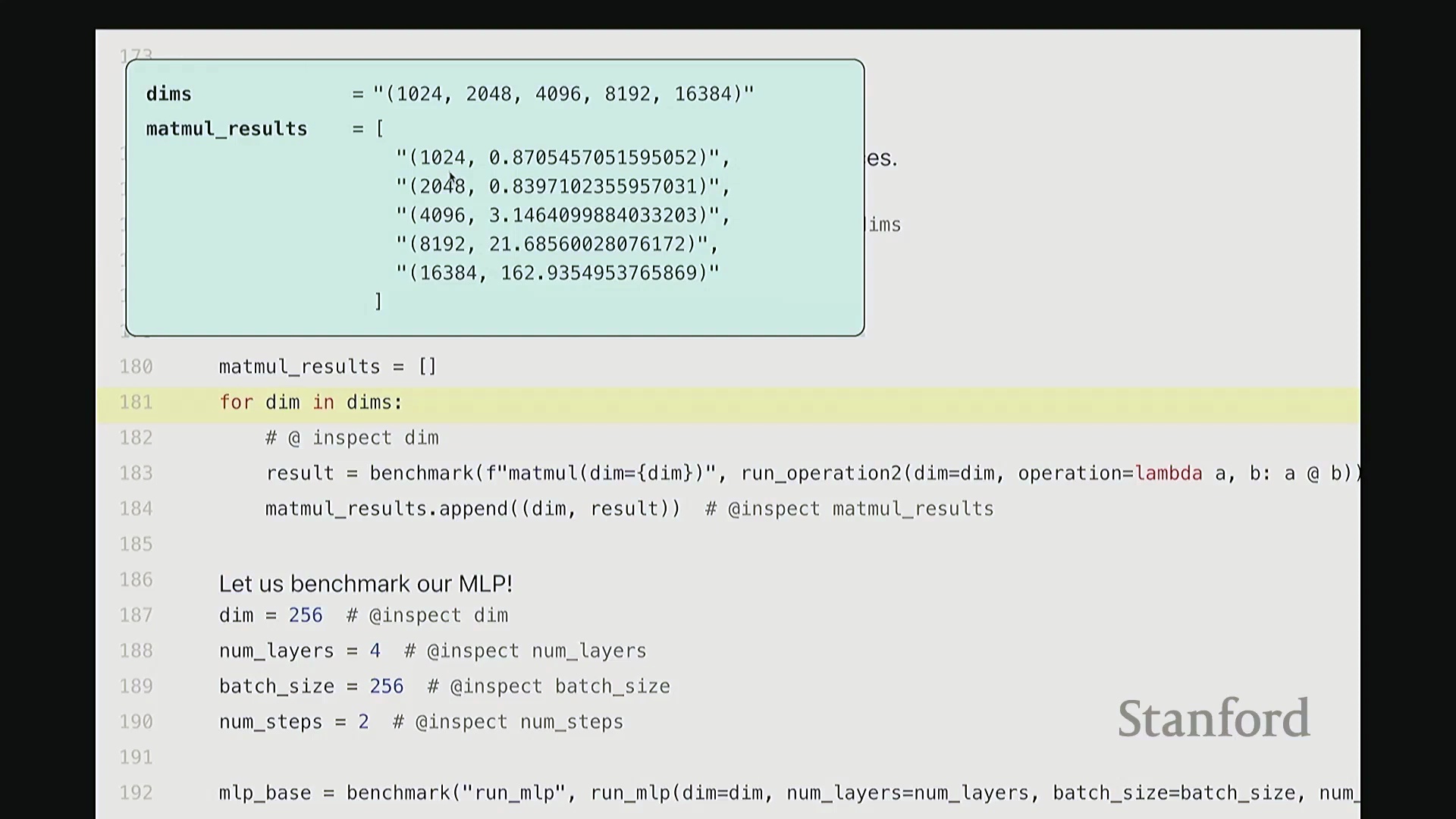
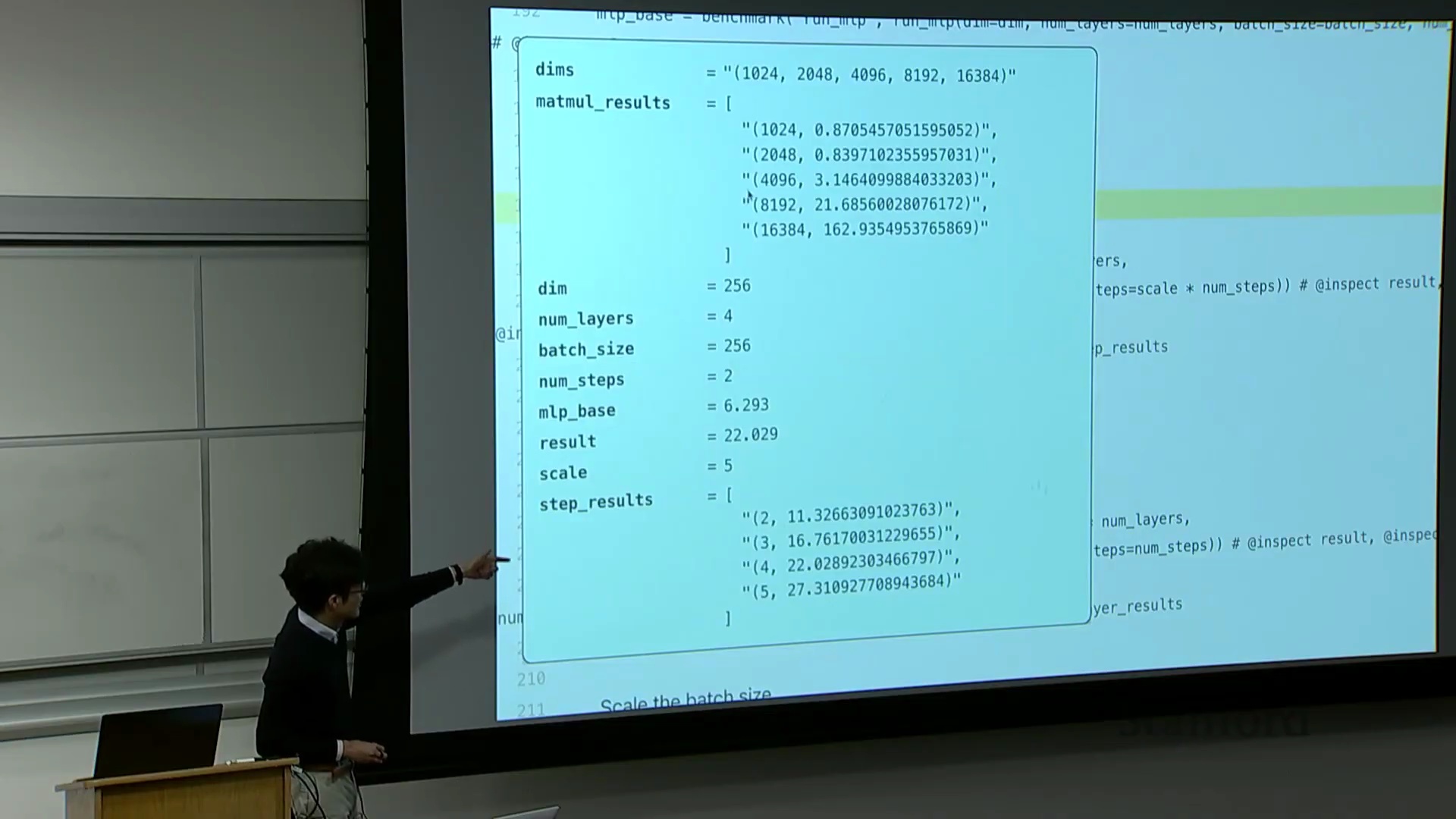
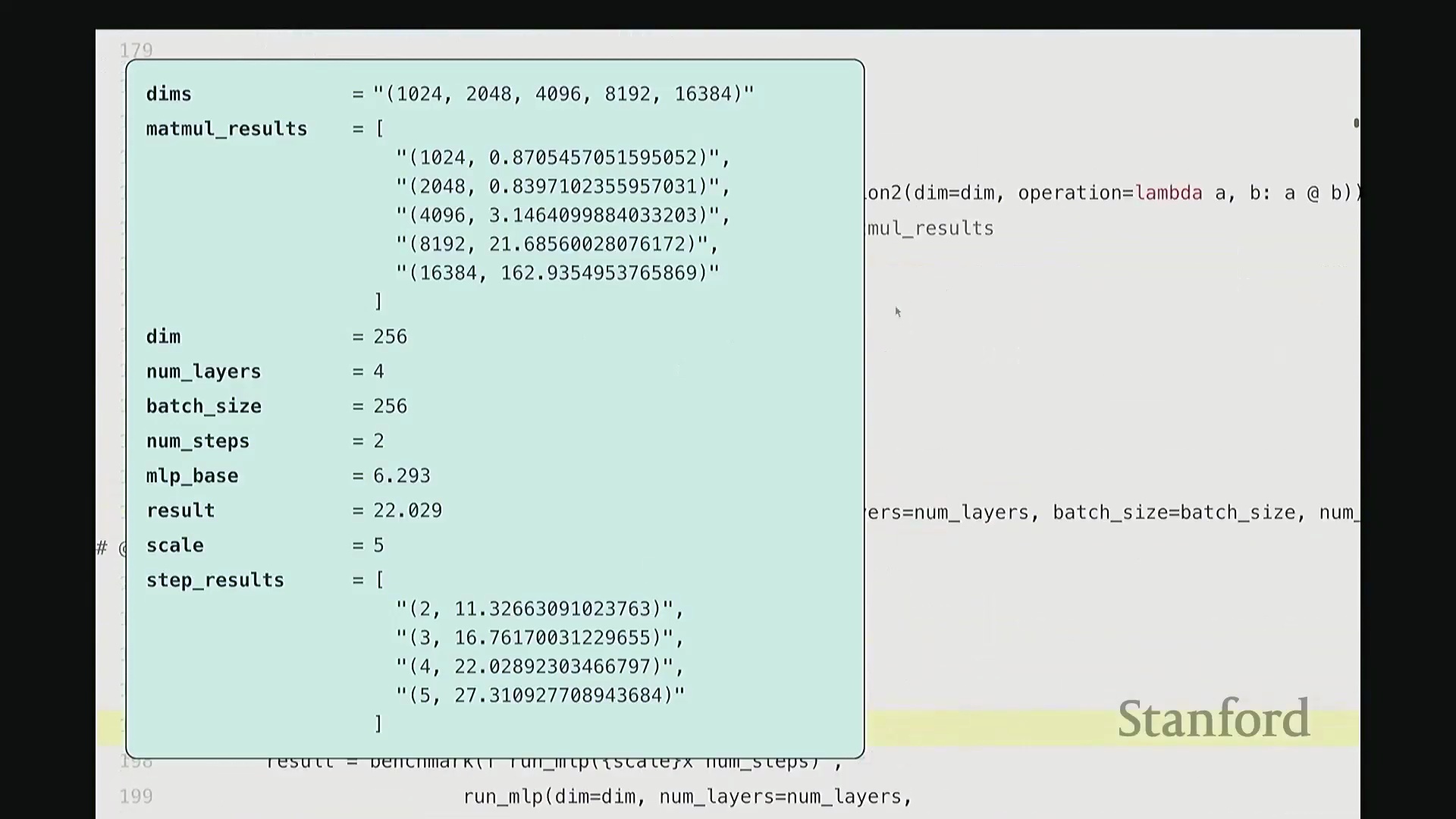
接下来,我们对矩阵乘法进行基准测试。我将通过几个实例演示,旨在为已知的理论规律补充具体数据。尽管结论可能众所周知,但仍值得逐一验证以达成共识。以下测试均在课程提供的 H100 GPU 上进行。我将对一系列不同维度的矩阵执行乘法运算,并遍历记录每个尺寸下的耗时数据。正如预期,随着矩阵尺寸增大,运行时间呈现超线性(Super-linear)增长。
当然,在极小尺寸(如 10x24 和 20x48)下,耗时几乎未明显增加。这是因为执行矩阵乘法本身存在固定的常数开销,包括数据从 CPU 传输至 GPU 以及内核启动(Kernel Launch)的耗时。因此,曲线并非从零开始就严格遵循超线性增长。但当矩阵规模足够大时,计算开销占据主导,我们便能清晰地观察到符合预期的矩阵乘法性能扩展规律。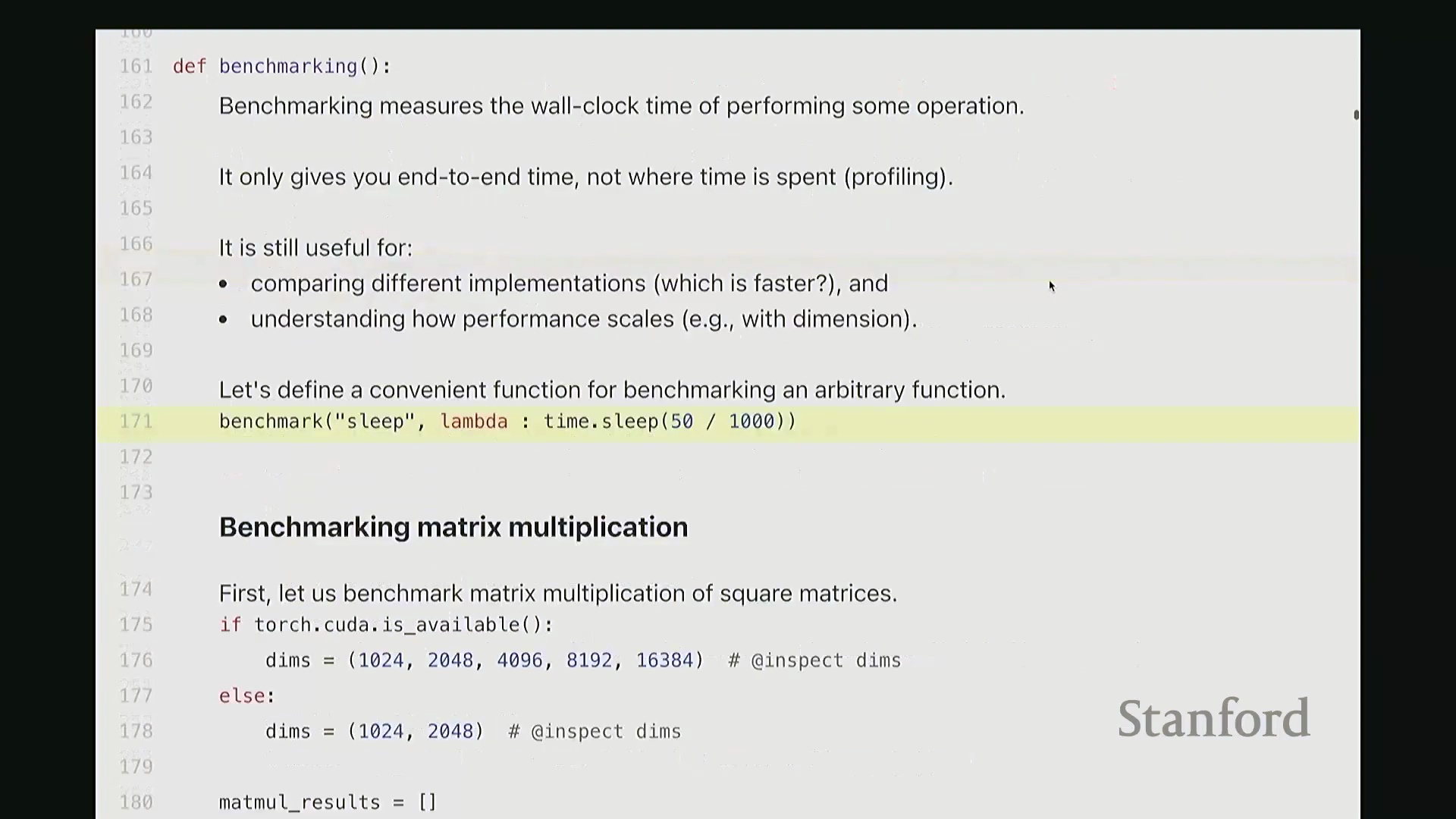
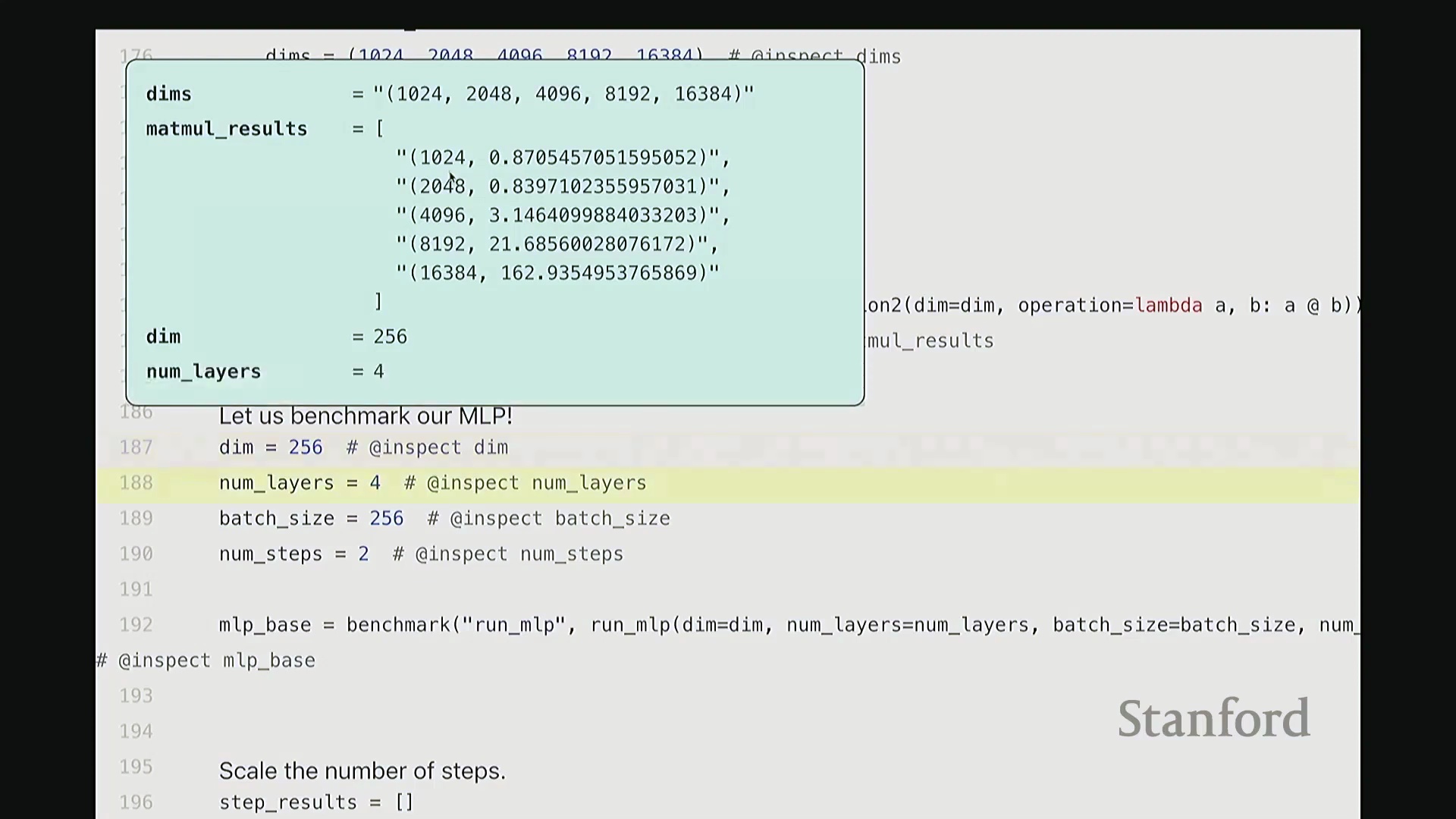
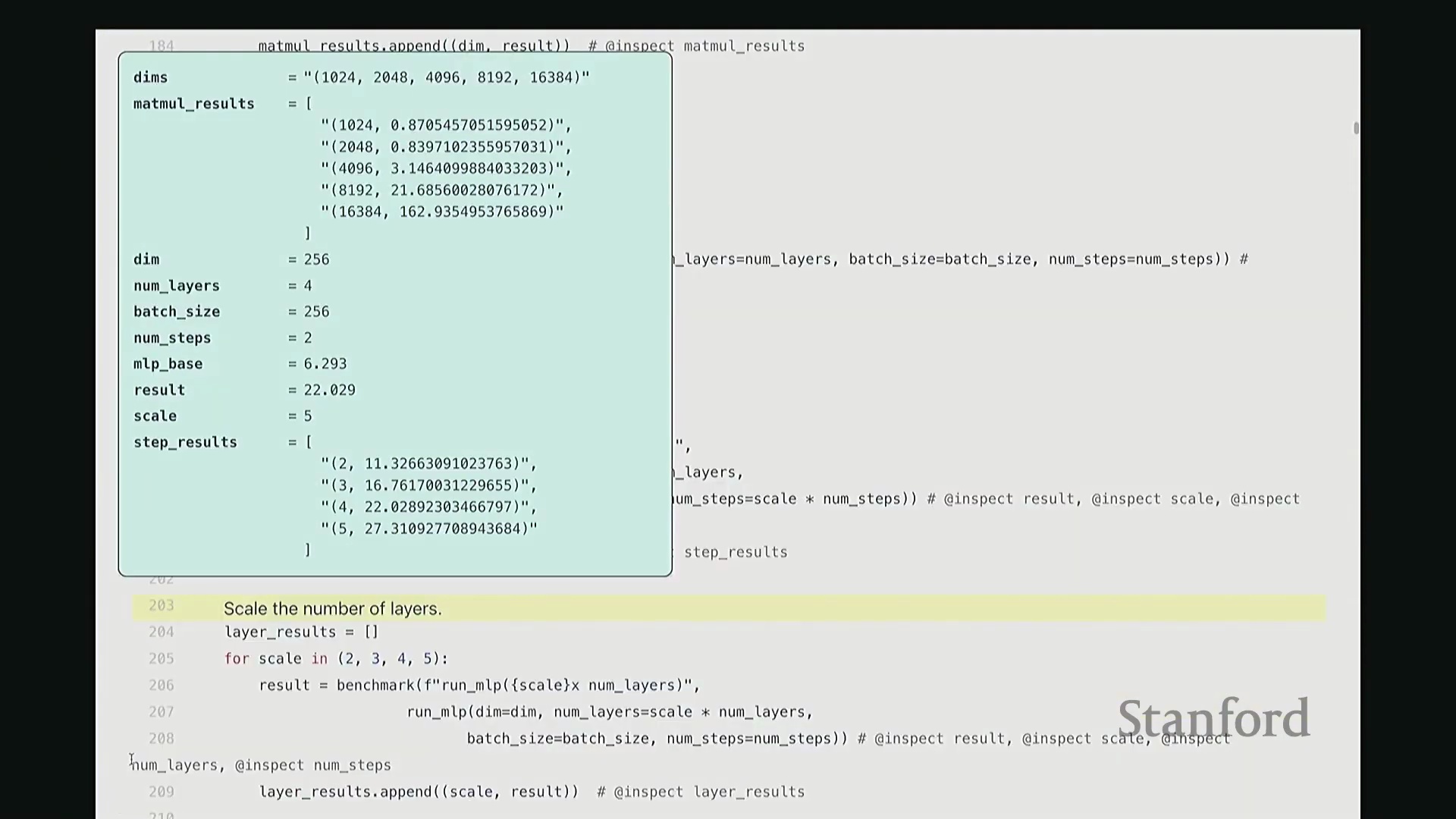
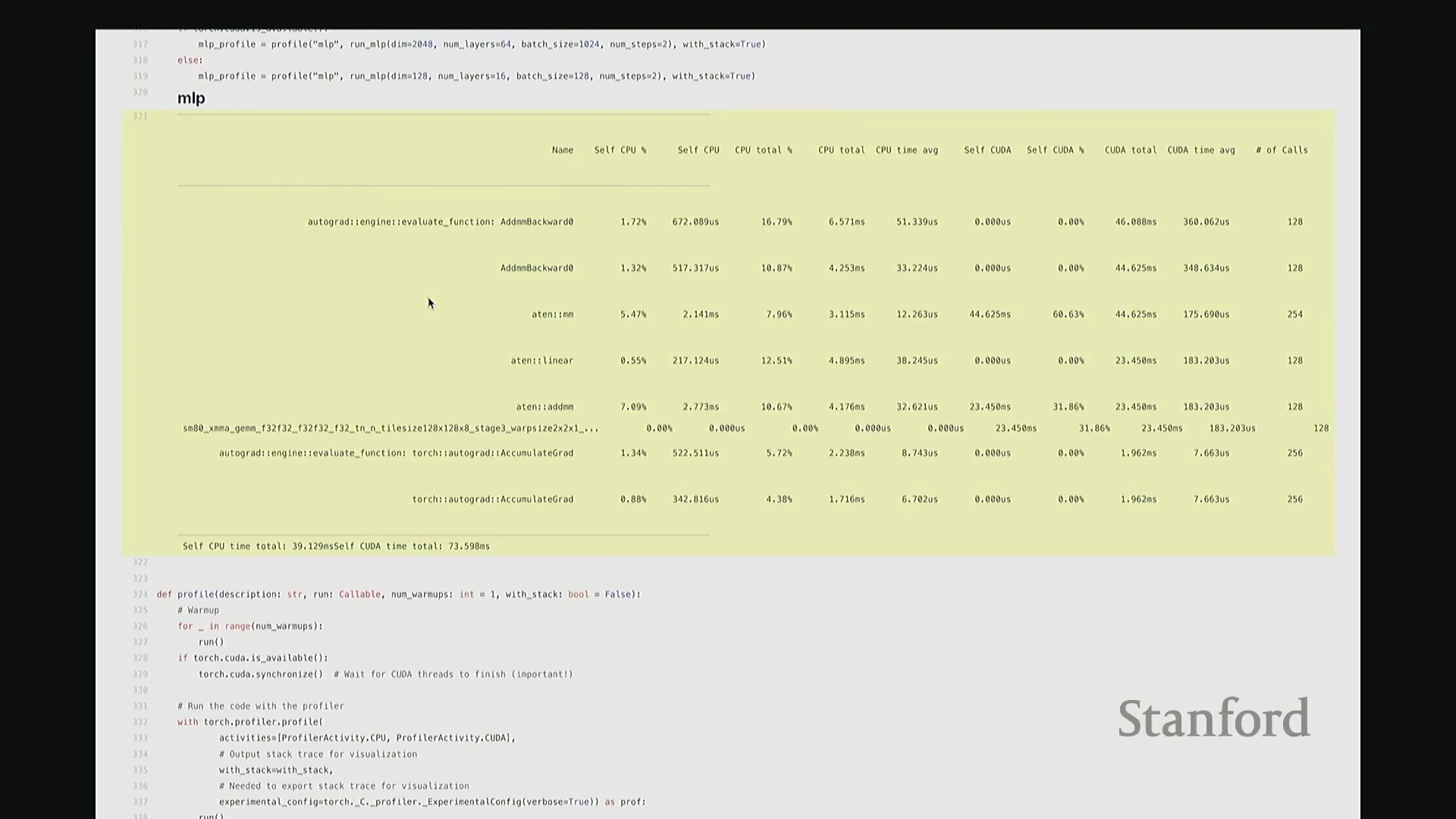
希望这部分足够直观。现在让我们对 MLP 进行基准测试。具体做法是逐步扩大模型规模:设置隐藏维度为 256、网络层数为 4、批量大小(Batch Size)为 256,并执行 2 个训练步骤(Steps)。此配置下的耗时约为 6.2 秒。接下来进行扩展测试。我将训练步骤数从 2 逐步增加至 5,并记录各情况下的耗时,得到 2、3、4、5 步的结果。与矩阵乘法的超线性增长不同,若增加 MLP 的迭代步骤数或前向传播(Forward Pass)/反向传播(Backward Pass)次数,运行时间将如何变化?预期应为线性扩展(Linear Scaling)。实测结果也确实如此:每增加一次完整的 MLP 迭代,耗时约增加 5 秒。可见,n 步运行的总耗时大致为 n × 5 秒。
让我尝试重置此处的监控面板显示……抱歉,似乎无法重置。我将视图稍微缩小一些,请见谅。
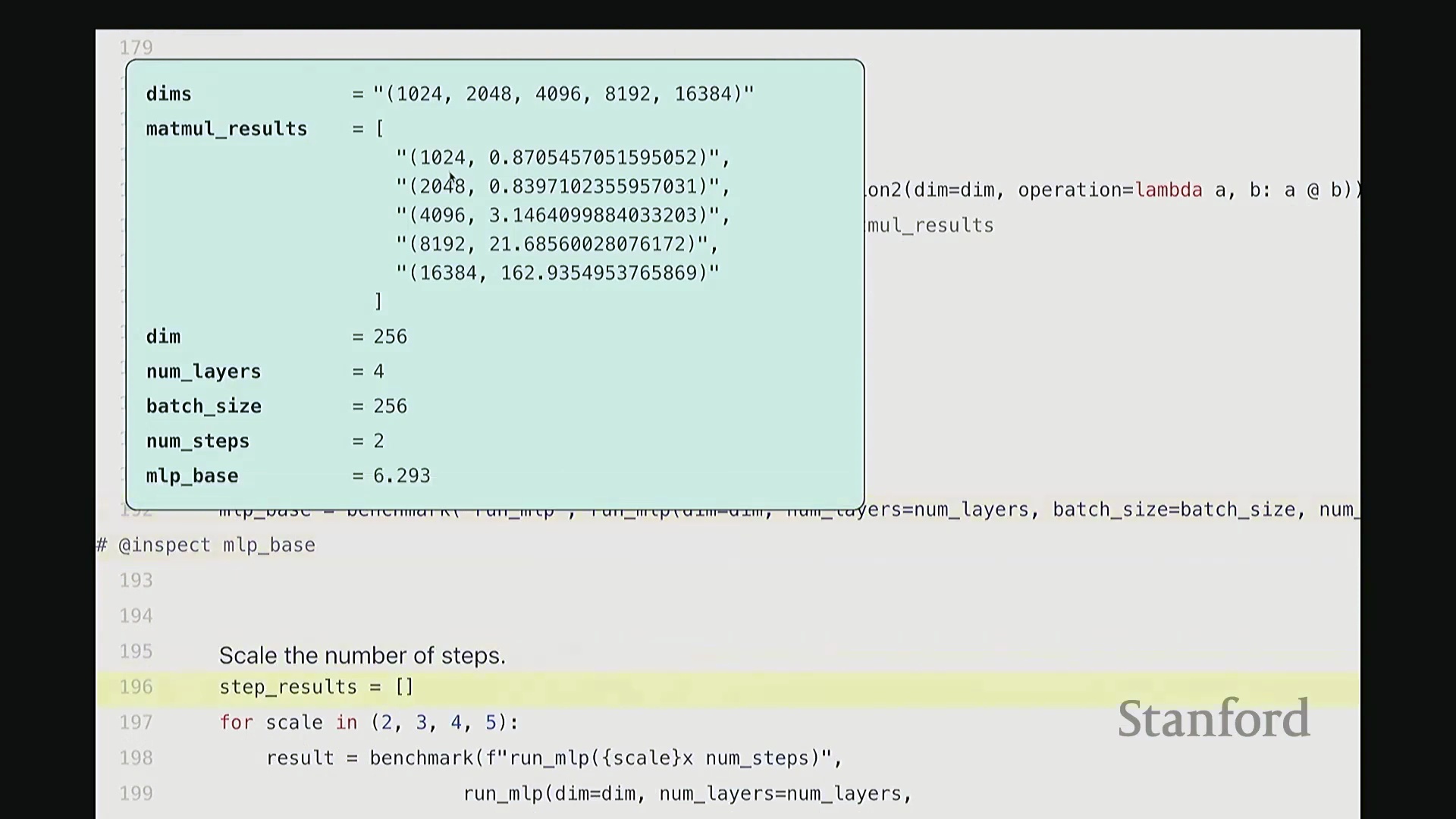
现在,我们进一步将网络层数从 2 层逐步扩展至 5 层。结果如何?运行时间随之增加,且与层数呈严格的线性关系。此时,每增加一层约耗时 5 秒(略低于 5 秒)。因此,当层数增至四倍时,线性扩展规律再次得到验证。这完全符合预期,对吧?由此可见,训练步骤数与网络层数均与运行时间呈线性正相关,这正是我们在此观察到的结论。
批量大小的扩展测试在此略过,因为当前跟踪的指标已较多,过多变量会干扰分析。至此,基准测试部分讲解完毕。通过编写这样一个包含预热与 CUDA 同步的实用函数,我们可以精准测量任意代码段的运行时间。这在开发中极为实用,建议大家在日常编码中频繁使用。例如,你可以借此评估一个新颖复杂架构的实际推理或训练耗时。
过渡到细粒度的性能分析
然而,若需定位具体性能瓶颈,基准测试显得过于粗粒度(Coarse-grained)。它仅能告知代码整体运行缓慢,却无法揭示耗时具体分布。因此,我们需要引入性能分析。
性能分析提供了更细粒度(Fine-grained)的洞察。它的优势在于,不仅能定位时间消耗的具体函数,还能透视调用栈(Call Stack)。通常情况下,我们仅与 PyTorch 高层 API 交互;但在 PyTorch 底层,实际调度了一整套 CUDA 生态组件。运行性能分析器(Profiler)后,你可以一路追踪至底层调用,清晰掌握究竟触发了哪些内核。这将极大加深你对程序在硬件上实际执行机制的理解。接下来,我们将逐步演示如何对几个基础函数进行分析,以建立对底层运行机制的直观认知。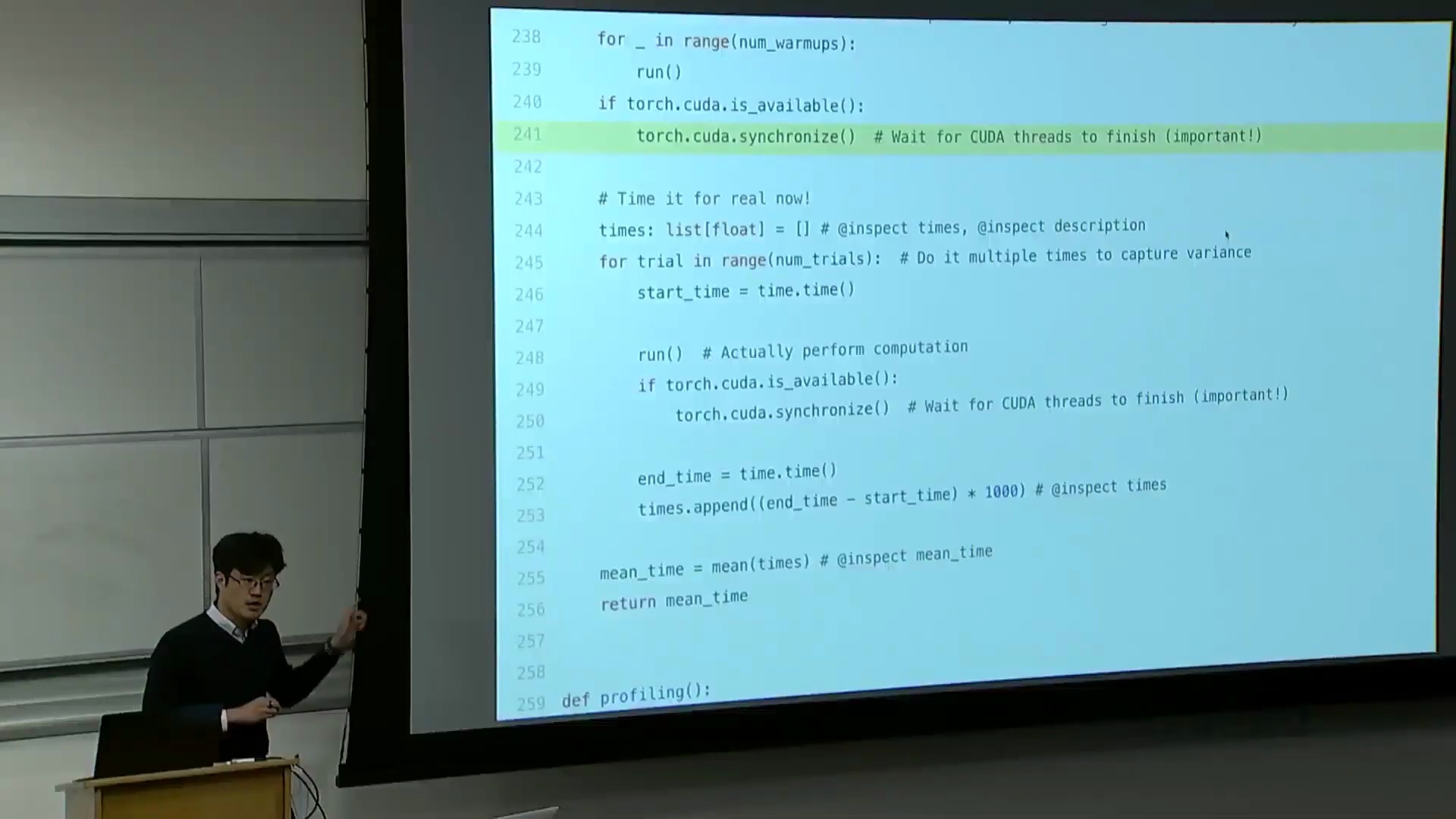
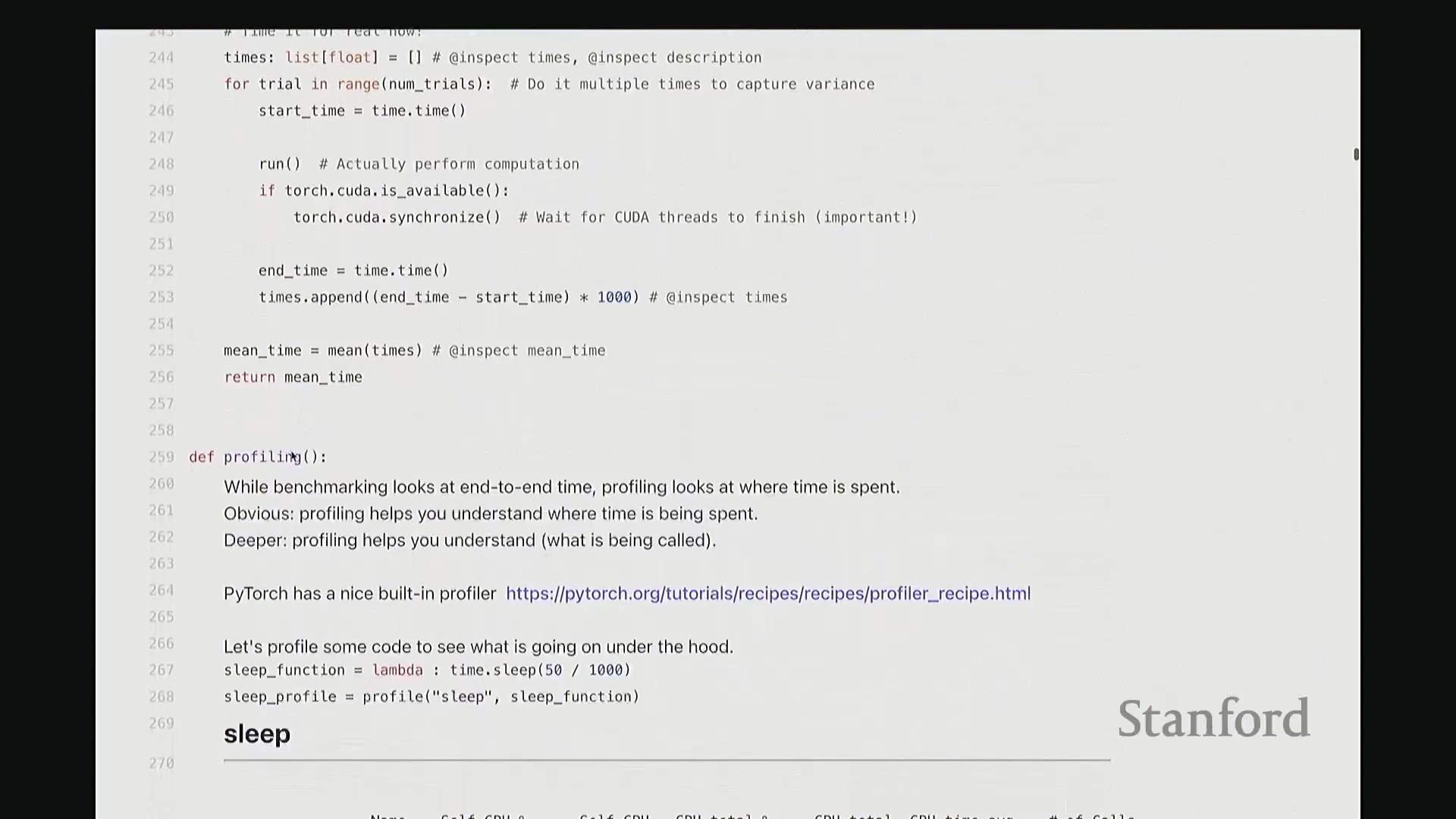
值得庆幸的是,对于基础性能分析需求,PyTorch 提供了极为易用的内置分析器(Built-in Profiler)。它允许我们无需脱离 Python/PyTorch 环境,即可获取清晰直观的分析报告。此处我对若干函数进行了分析,大家可参考对应输出。我沿用了之前的 sleep 示例。针对该函数的分析代码逻辑如下:首先执行预热,调用 torch.cuda.synchronize 确保同步;随后启动分析器,同时记录 CPU 与 GPU 的耗时;接着执行目标操作,再次同步;最后打印各操作耗时的平均统计表。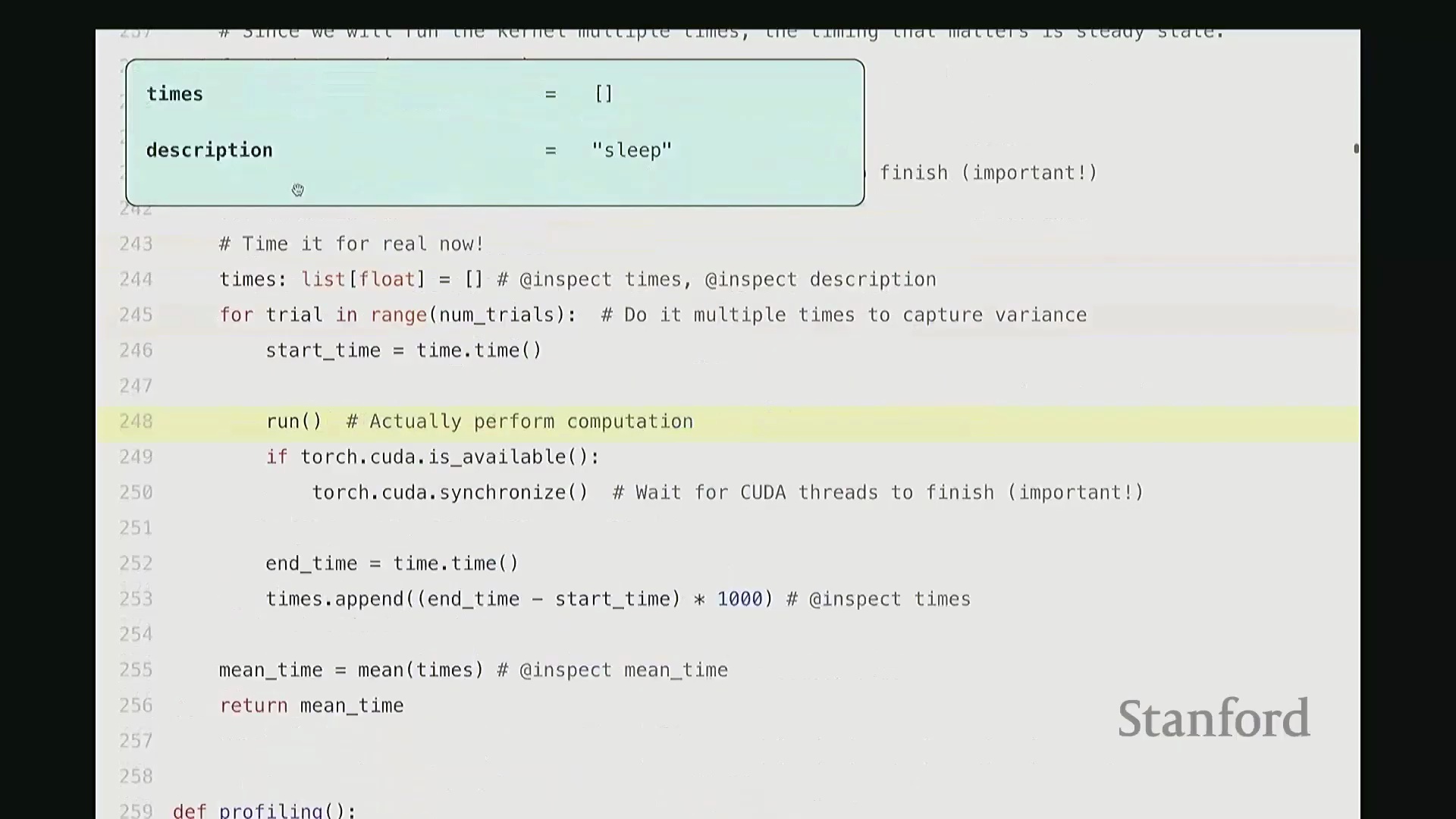
性能分析实战:分析函数执行
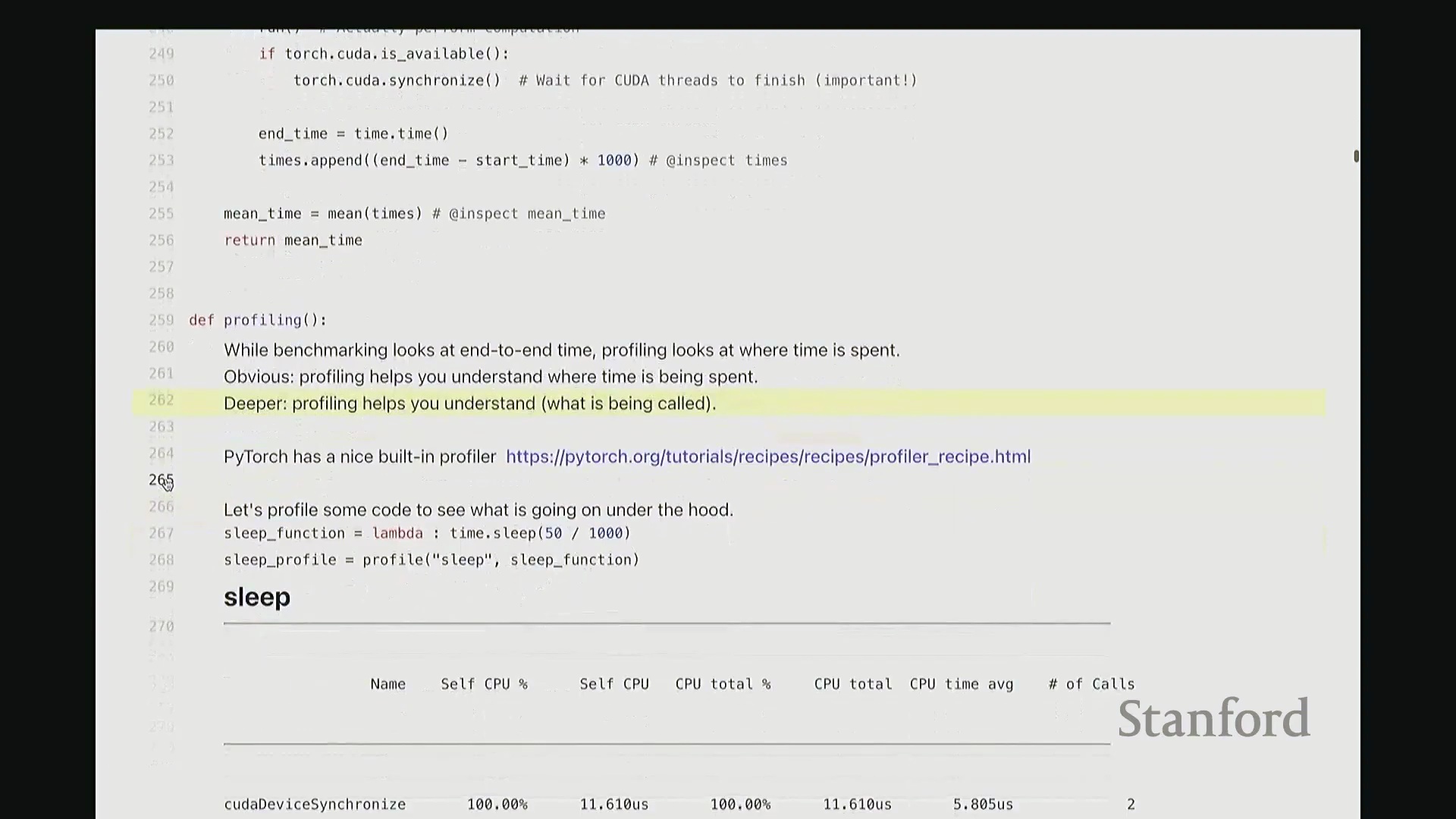
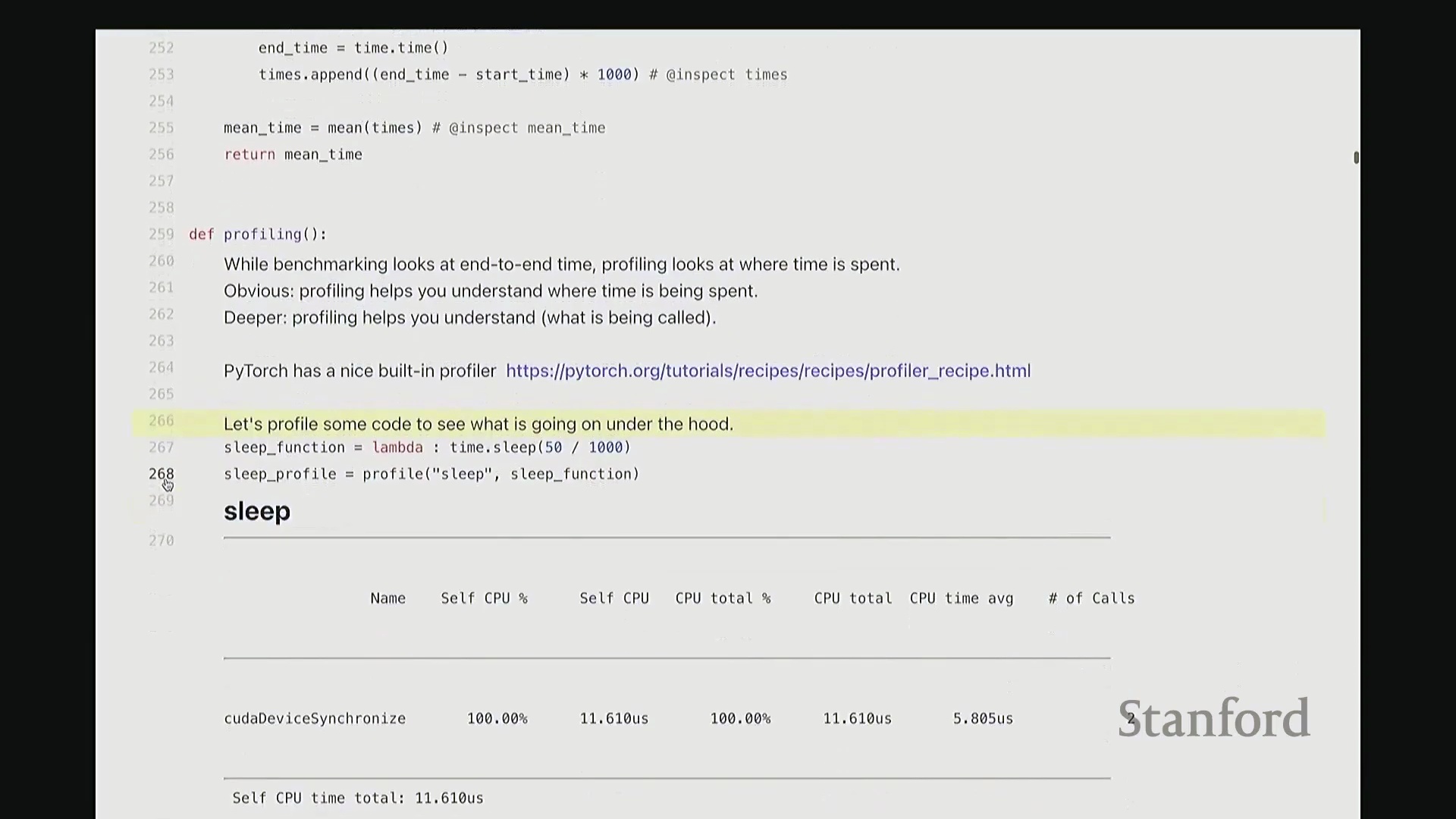
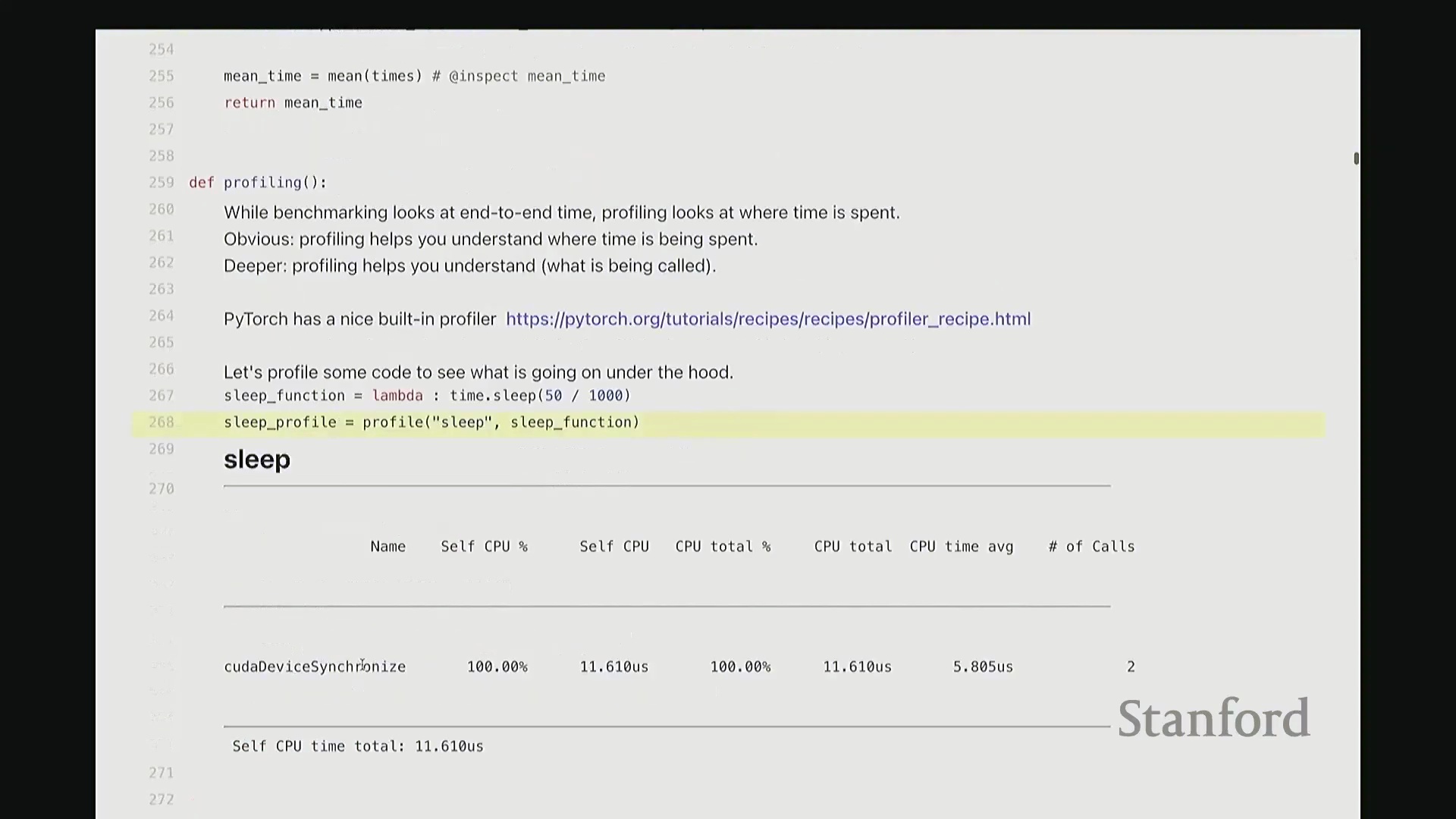
回到代码界面。现在对 sleep 函数执行性能分析。观察输出结果会发现什么?实际上,100% 的耗时均集中在 cudaDeviceSynchronize(CUDA 设备同步)操作上。因为该示例并未执行任何实际的 GPU 计算,同步操作成了唯一的主要开销。用这样一个“空操作”来分析确实略显滑稽。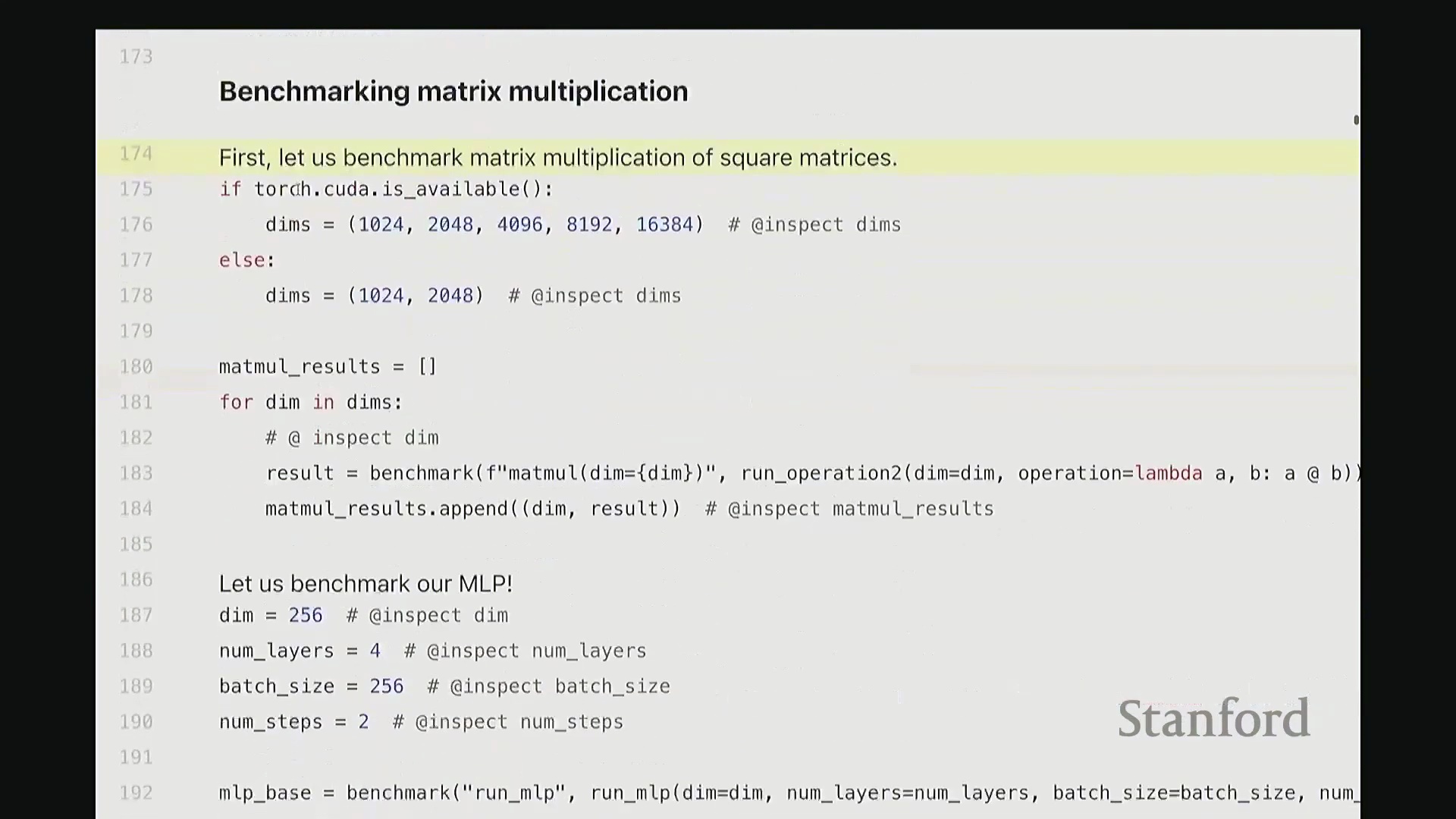
接下来,我们来看一些具有实际计算意义的非平凡(Non-trivial)示例。观察此处的基础算子操作: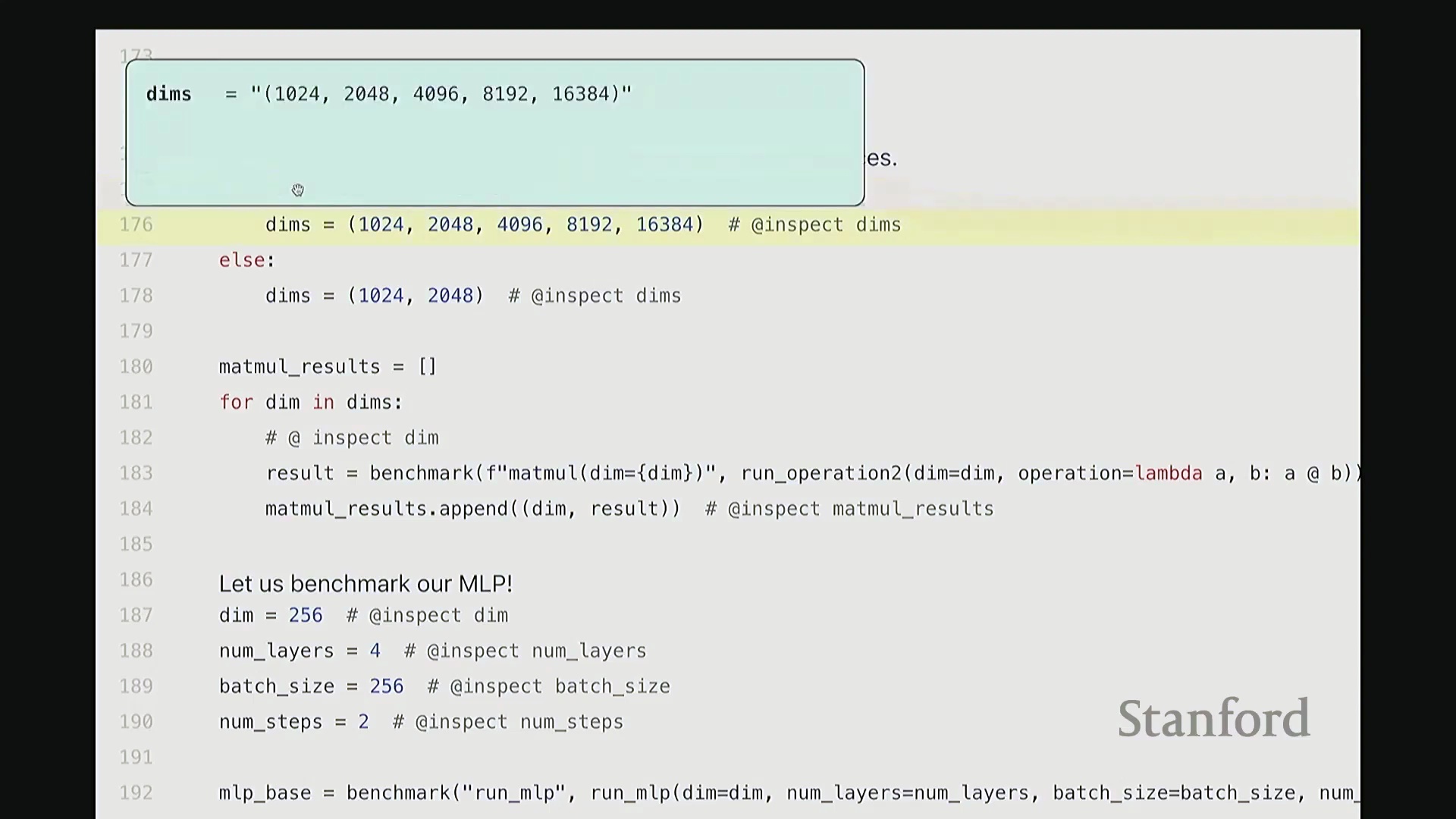

分析基础操作:矩阵加法
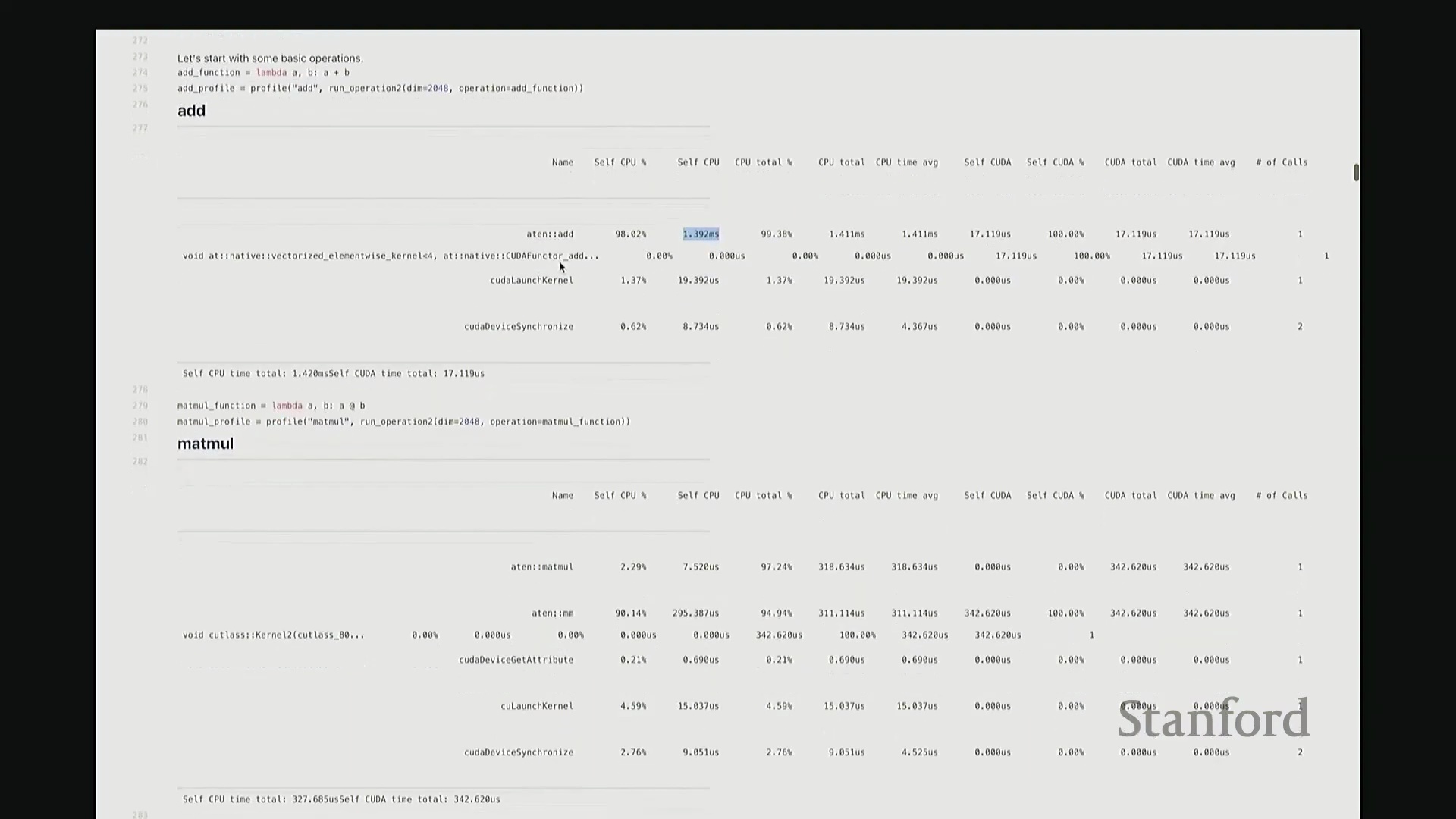
让我们来看一个基础操作:矩阵加法。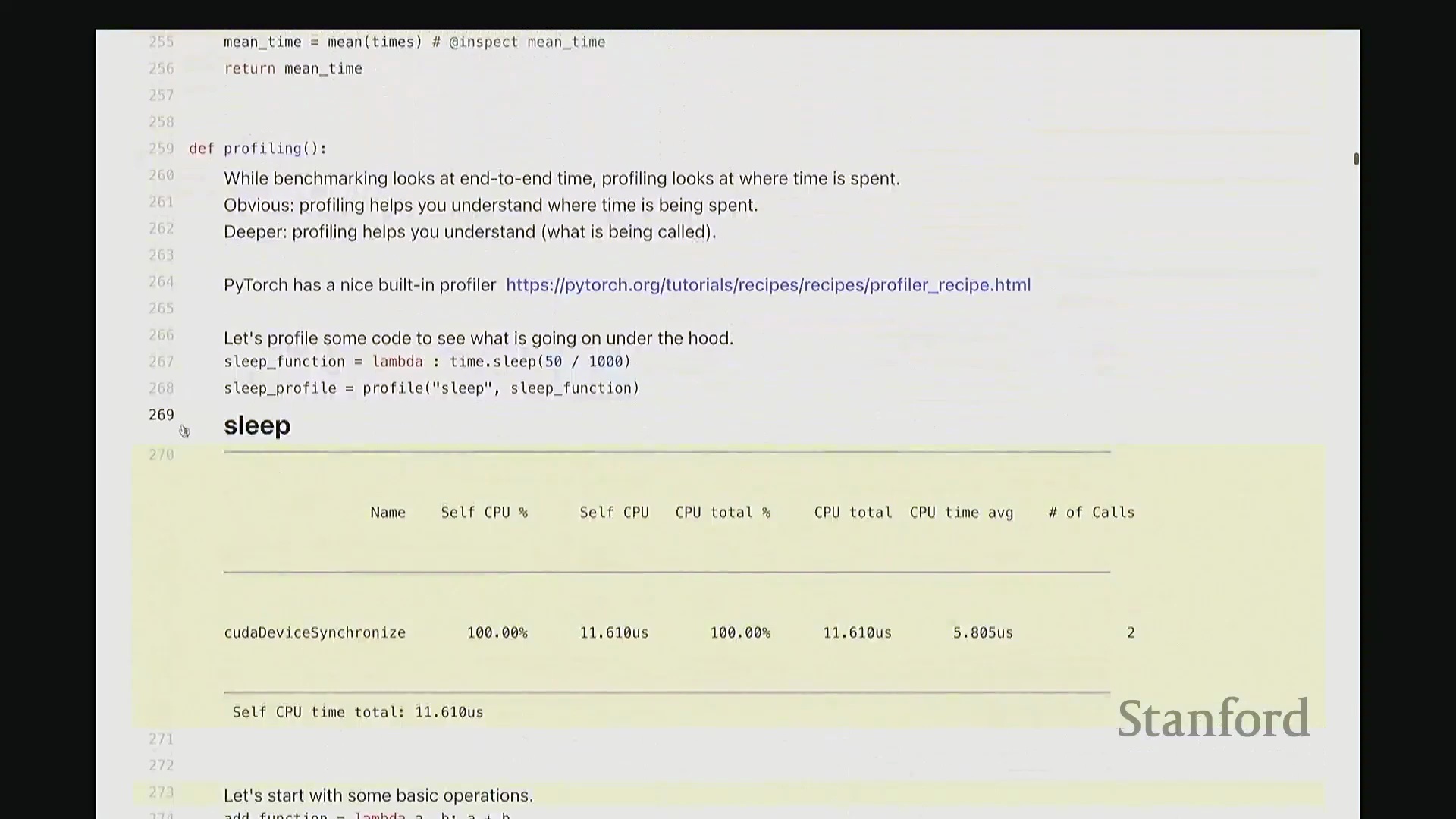 我定义了一个
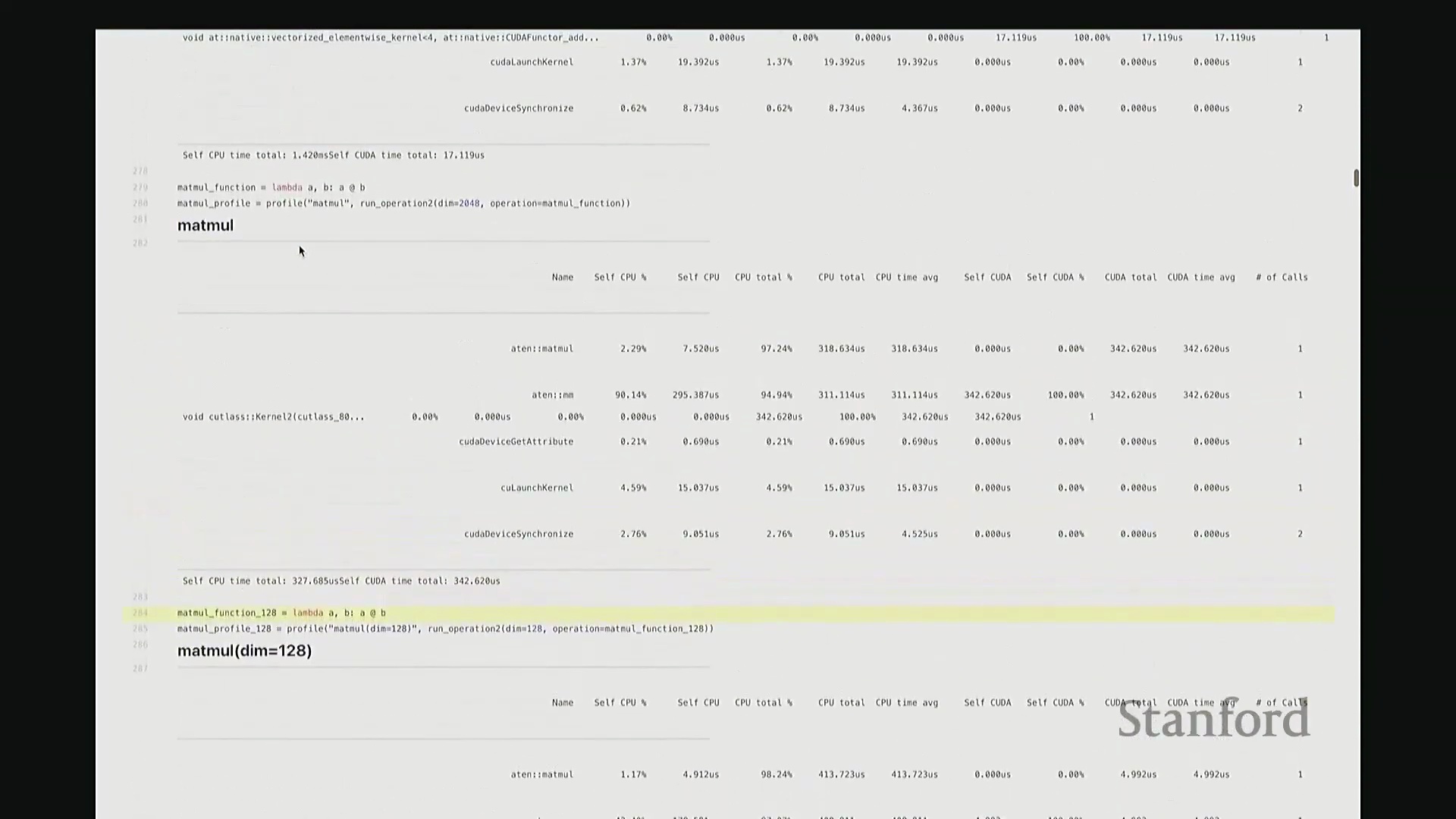
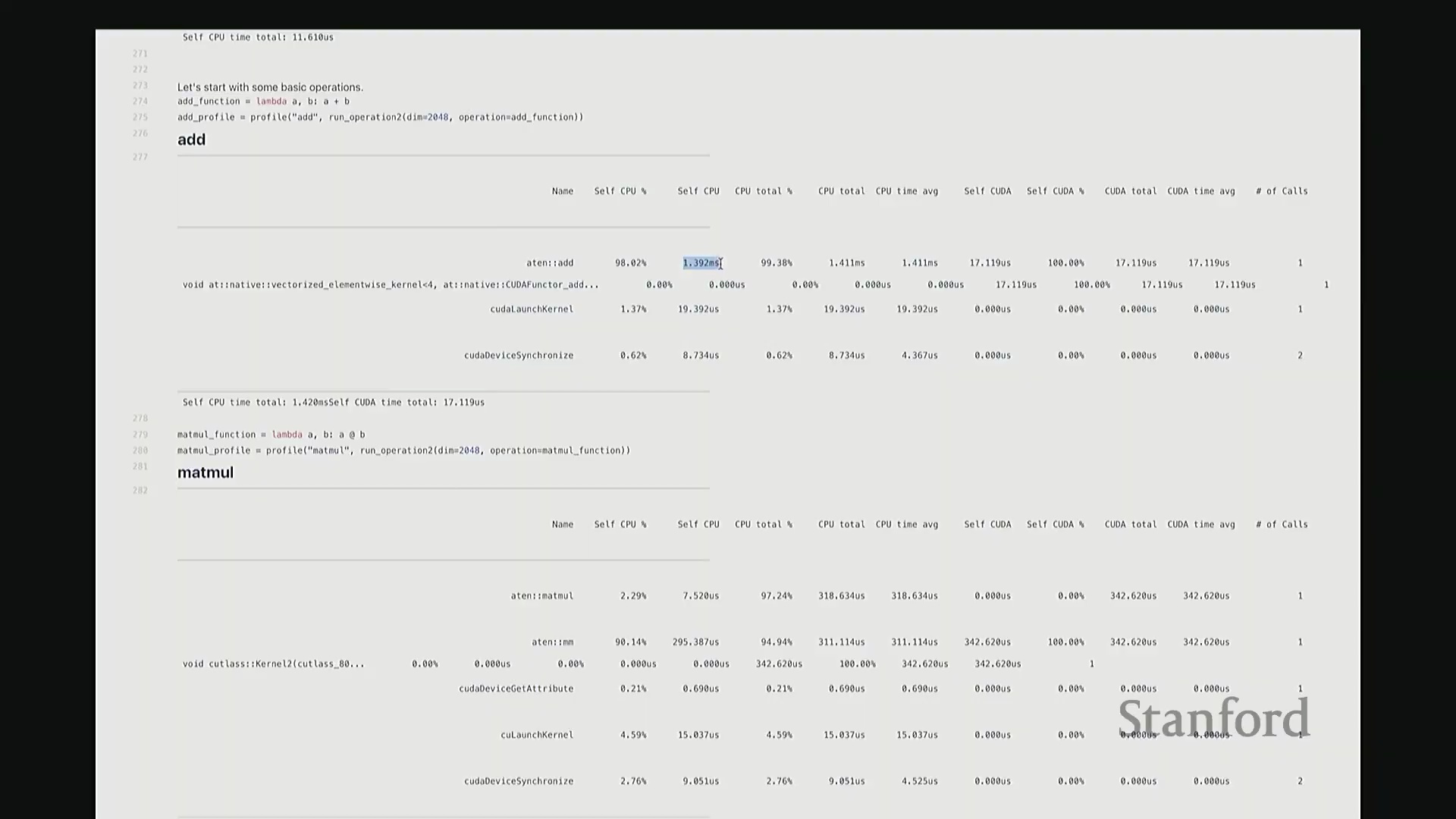
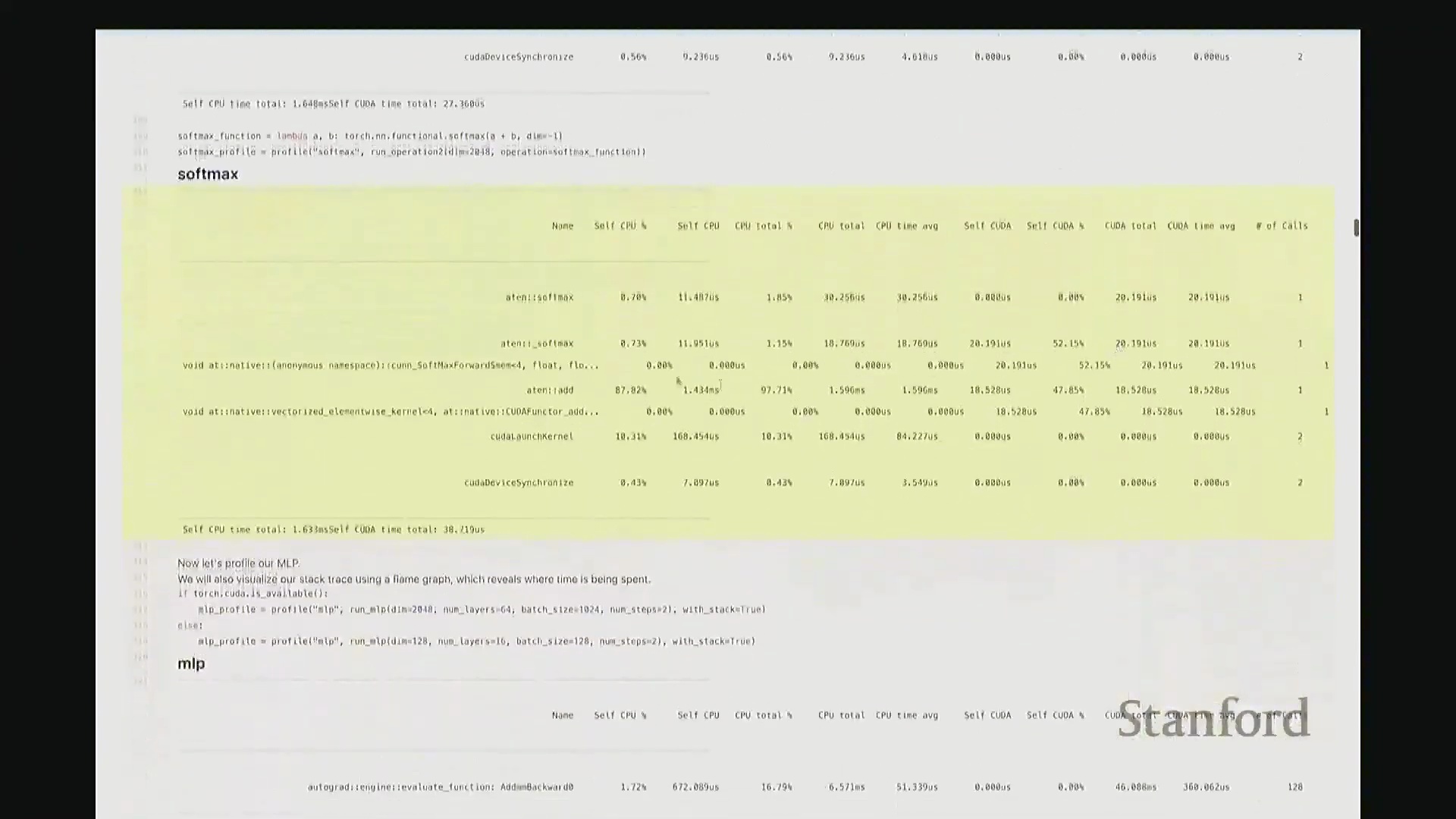
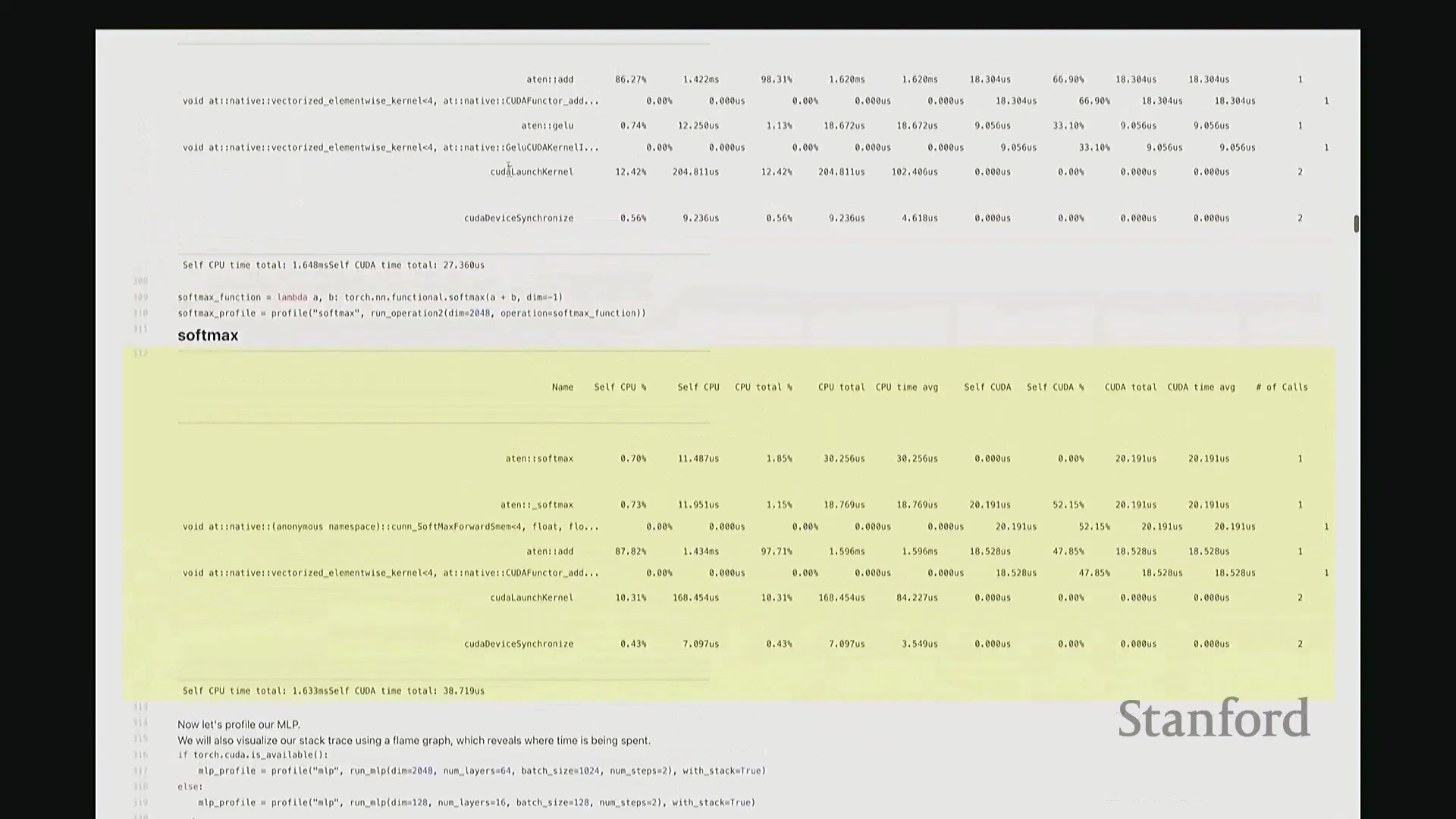
我定义了一个 add 函数,接收矩阵 A 和 B 并执行相加操作。这是一个辅助函数,它会实例化两个服从随机高斯分布(Gaussian Distribution)的矩阵,随后调用作为参数传入的目标操作函数。在此,我们对两个维度为 2048x2048 的矩阵执行加法。现在,我将启动性能分析器(Profiler)对该操作进行分析,并得到类似右侧代码块的输出结果。这就是分析器返回的性能报告。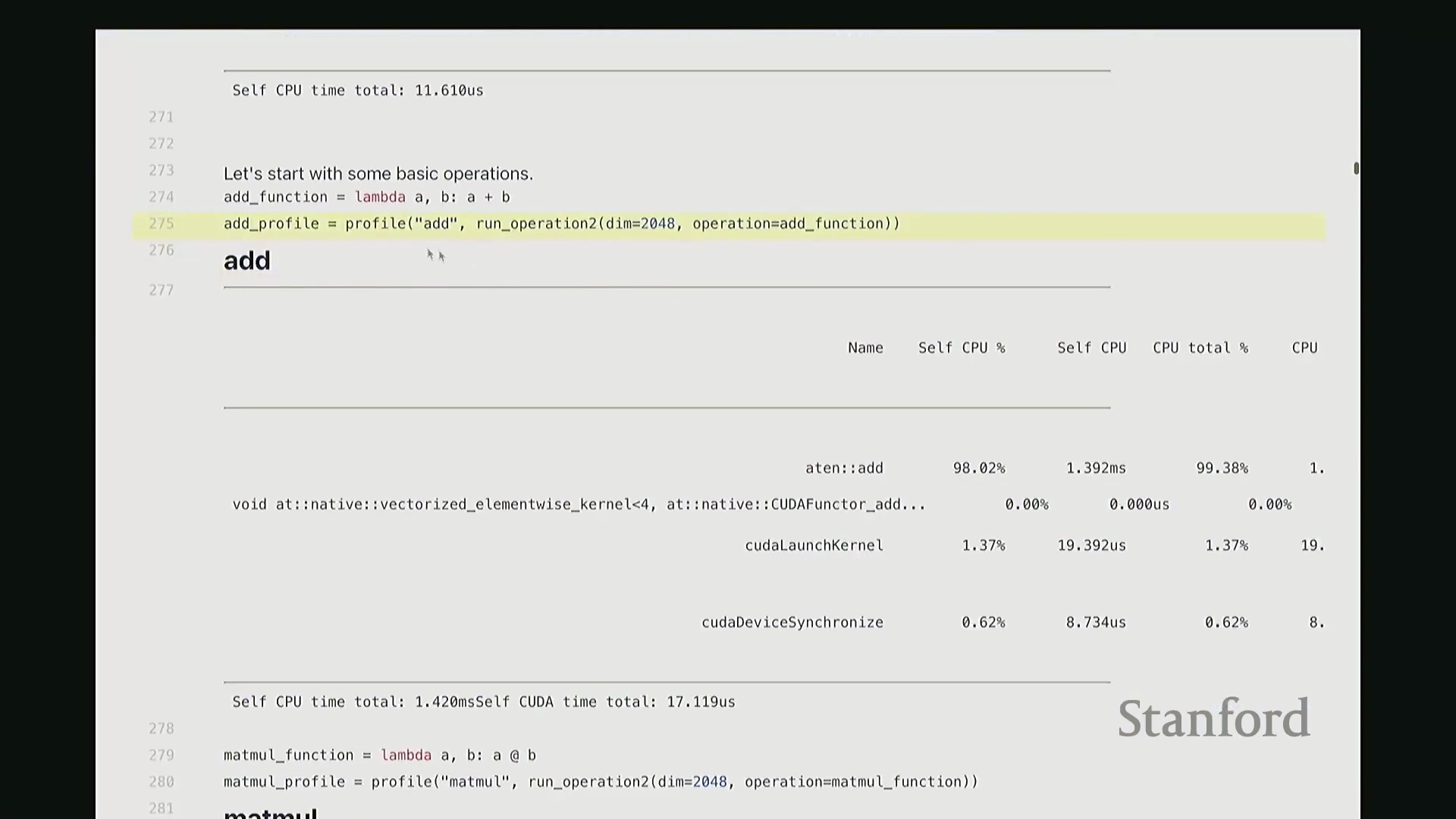 我需要将视图缩小一些,因为当前显示内容超出了屏幕范围。好的,后排的同学能看清吗?看清的请给我竖个大拇指?很好。如果看不清请竖小拇指示意。
我需要将视图缩小一些,因为当前显示内容超出了屏幕范围。好的,后排的同学能看清吗?看清的请给我竖个大拇指?很好。如果看不清请竖小拇指示意。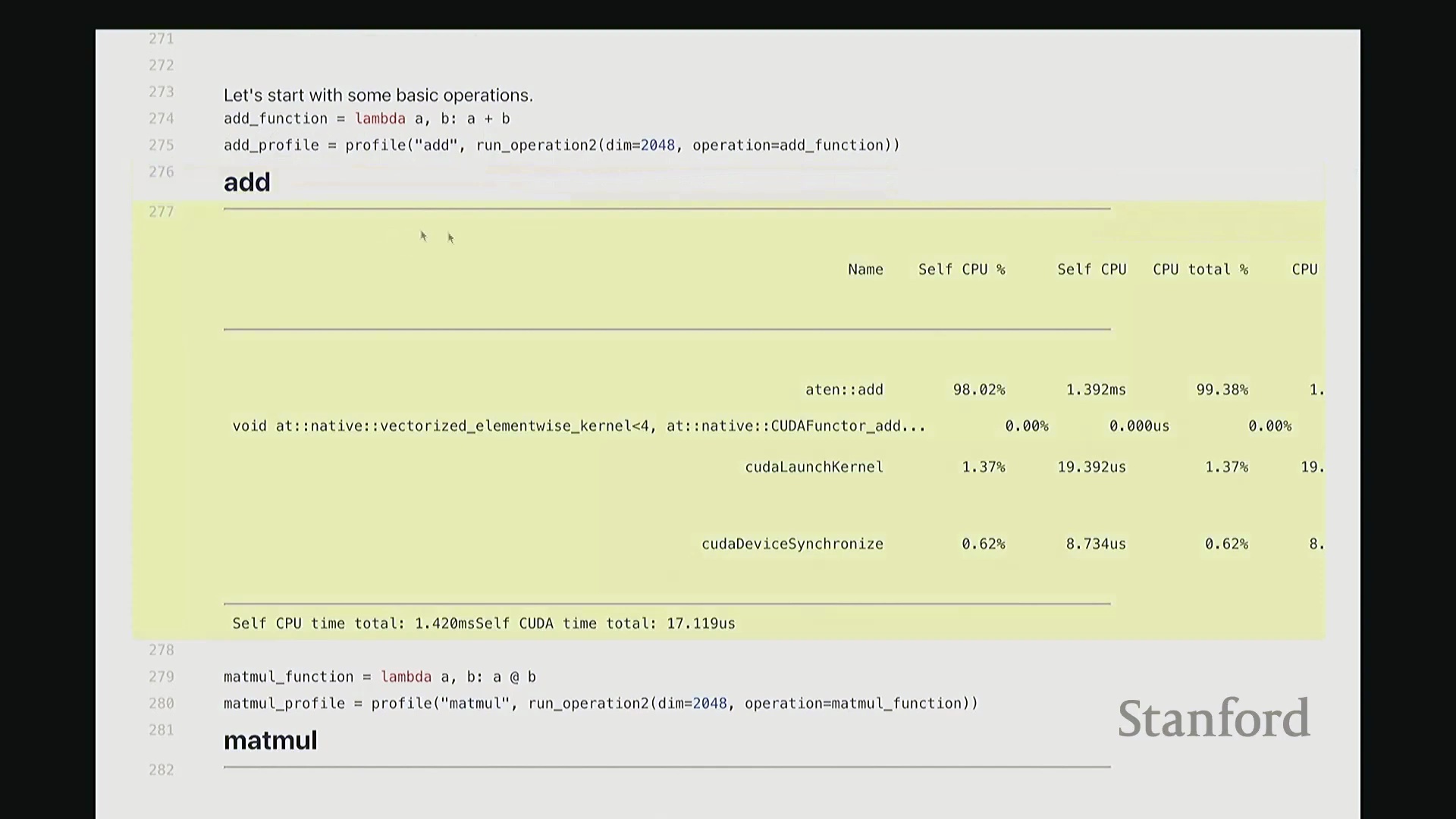
理解加法执行的“冰山”模型
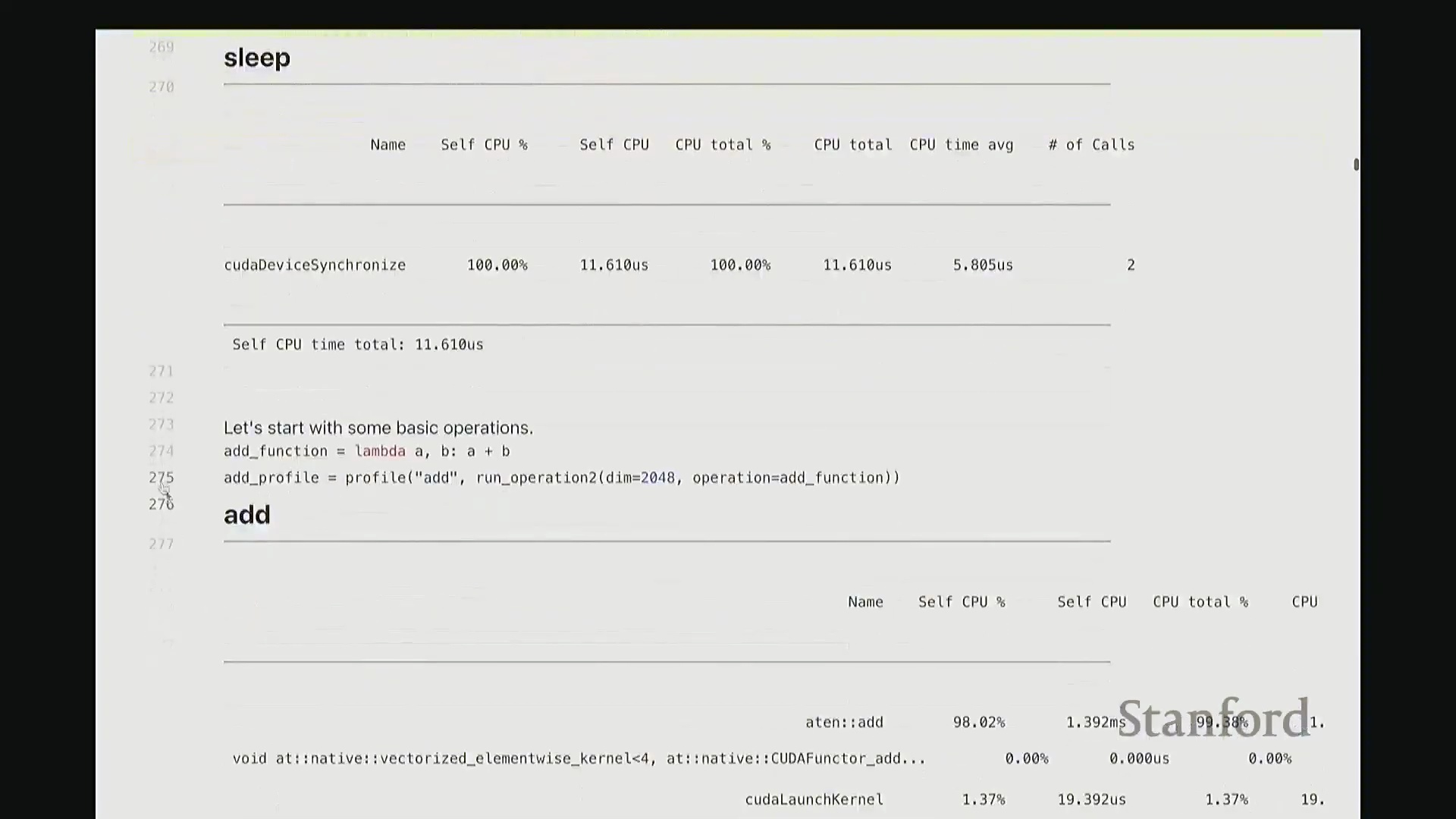
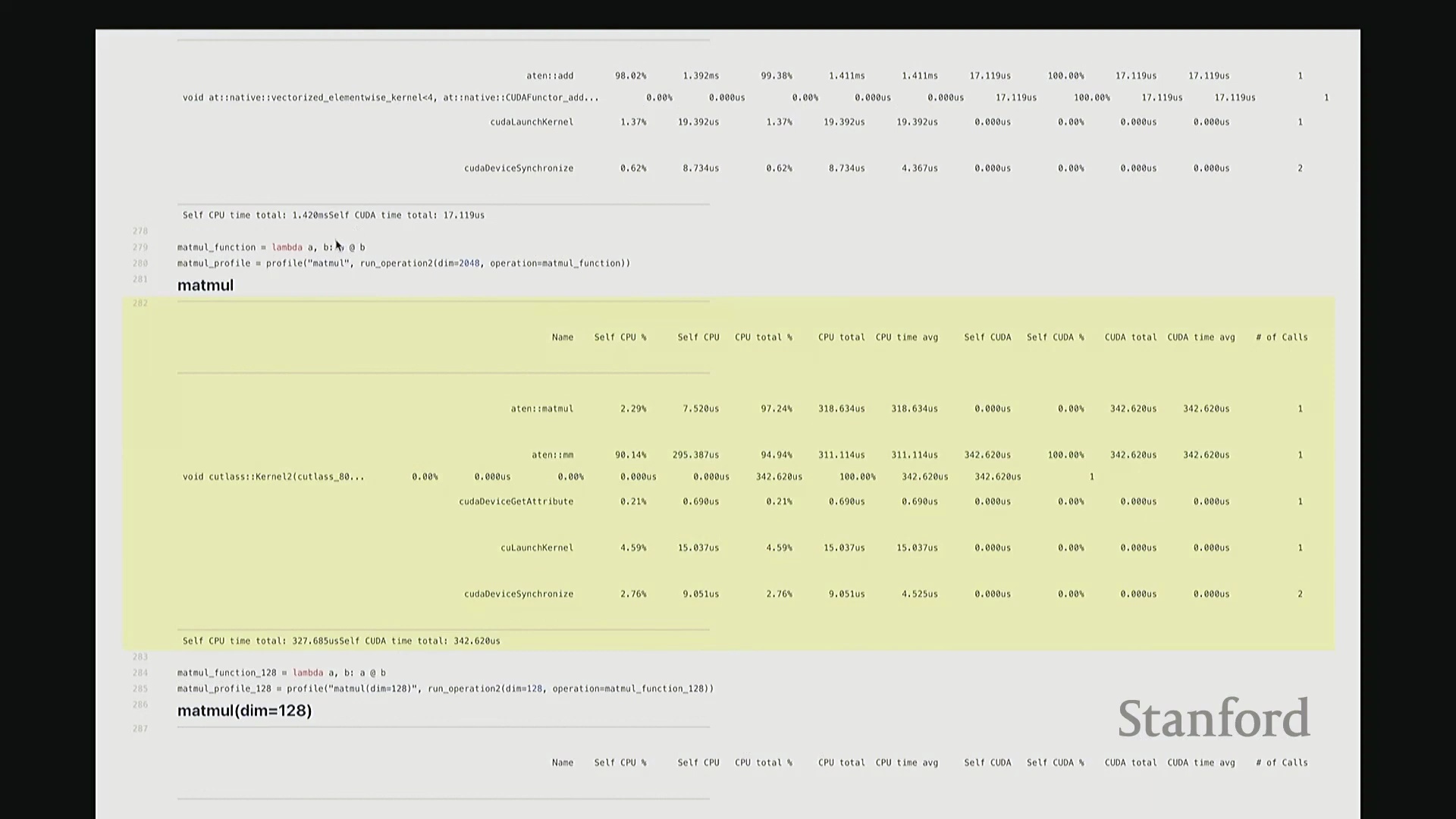
因此,当我们在 Python 中调用 add 函数时,表面可见的交互仅此而已——即 A + B 这个加法表达式。这通常是我们认知中的全部过程。但实际上,正如“冰山模型”所揭示的,其底层隐藏着大量幕后工作。该操作首先会被派发(Dispatch)至 GPU。首先,它会经过 ATen 层,这是 PyTorch 的核心 C++ 张量库(Tensor Library)。该包装层(Wrapper)被调用,意为“执行数值相加操作”,这就是实际触发的外部接口。随后,请求被进一步派发至一个特定的 CUDA 内核(CUDA Kernel),名为 vectorize_elementwise_kernel(向量化逐元素内核(Vectorized Element-wise Kernel)),这才是真正负责执行加法计算的核心组件。此外,名为 cudaLaunchKernel 的函数调用同样消耗了时间。这实际上是 CPU 接收指令并将其下发给 GPU 的过程,即内核启动(Kernel Launch),其本身也会产生一定的延迟。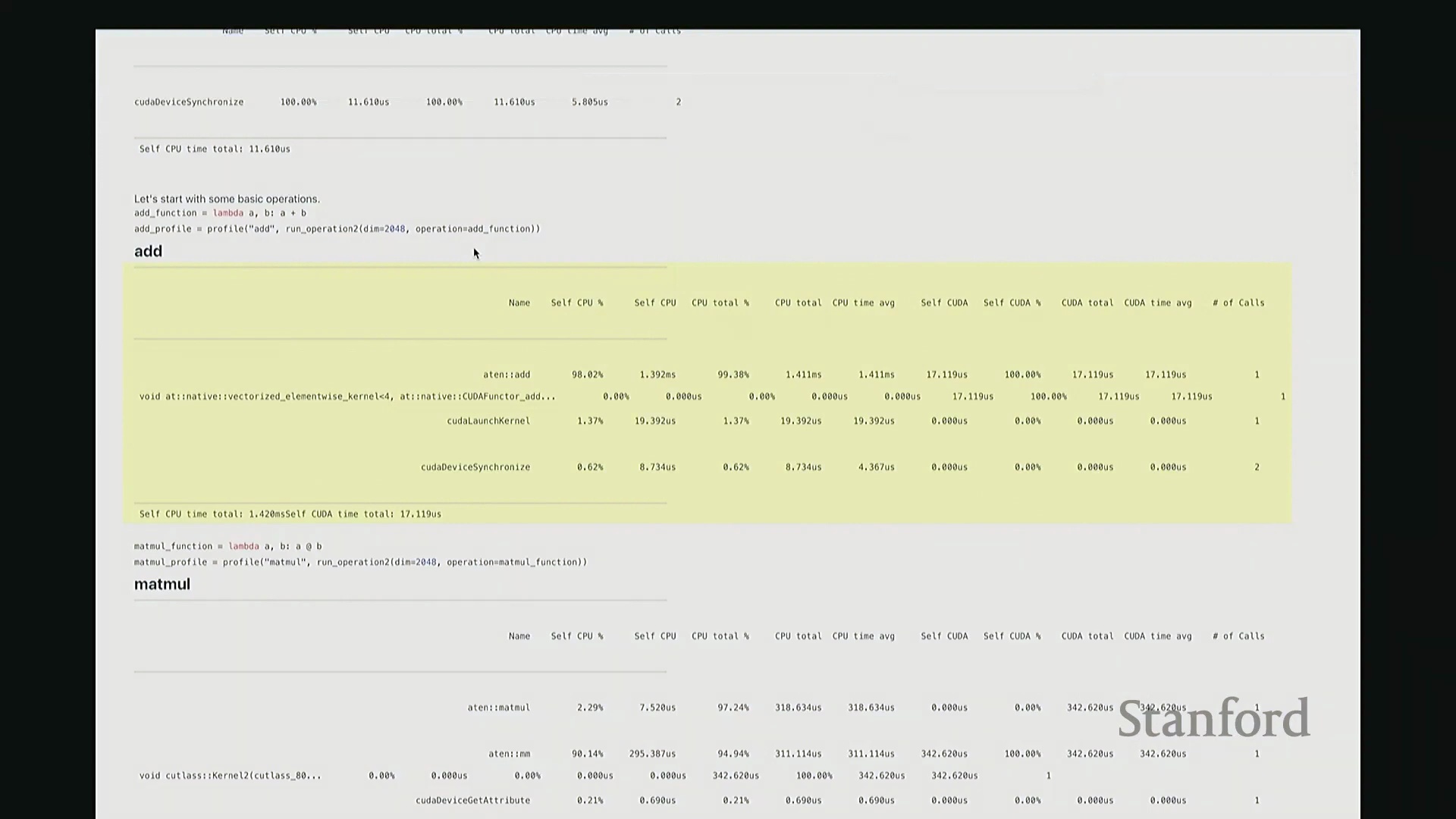 最后,执行
最后,执行 cudaDeviceSynchronize(CUDA 设备同步),强制 CPU 等待 GPU 完成计算并返回结果。这同样需要时间,仅设置同步屏障(Synchronization Barrier)就会引入固有开销。因此,最终观测到的总耗时为:CPU 端 1.4 毫秒,CUDA 端 17 微秒。可见 GPU 上的实际计算极快,主要开销集中在 CPU 端。若查看消耗的 CPU 时间(即自身 CPU 时间(Self-CPU Time)),会发现 C++/C 接口层占据了大量时间。这些本质上是将任务派发至 GPU 所带来的固有开销(Overhead)。以上就是 add 函数的完整执行链路,我们由此得以窥见底层实际发生的机制。
分析矩阵乘法与内核分发
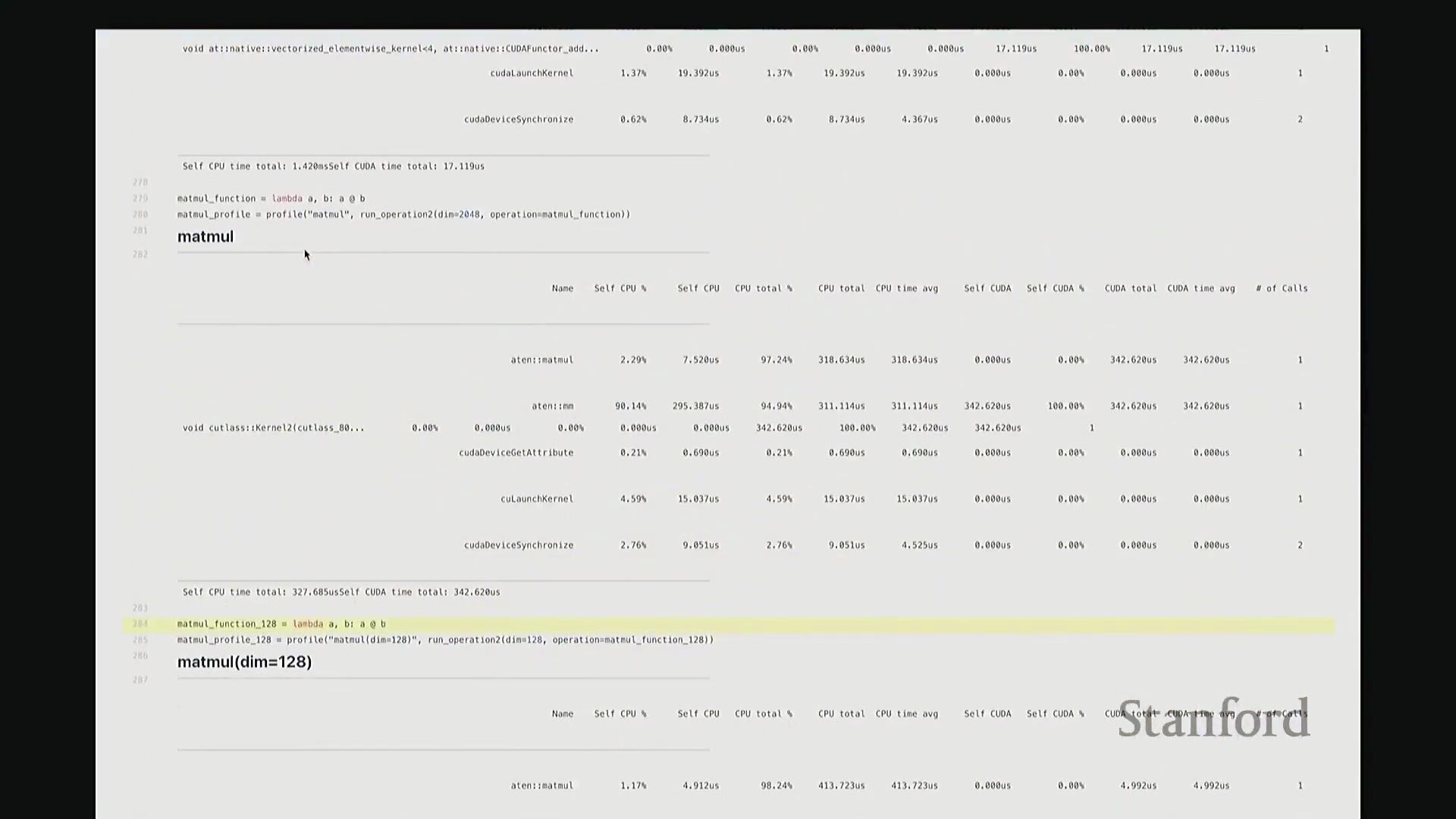
矩阵乘法(Matrix Multiplication)的执行逻辑与此类似。我执行 A 乘以 B 的操作,同样使用维度为 2048 的矩阵,并启动性能分析。此次输出中出现了 ATen::matmul,表明这是 PyTorch 底层处理矩阵乘法的 C++ 接口。随后,该请求被派发至 CUTLASS(CUDA 线性代数子程序模板库),这是 NVIDIA 专为高性能矩阵乘法设计的 CUDA 库。接着,它进一步调用了一个特定的 CUTLASS 内核,该内核配置了特定的瓦片大小(Tile Size)。由于显示限制,内核名称在此处被截断,我稍后会展示完整版本。该名称实际上对应了一组高度特定的编译参数,例如分块尺寸、线程块数量等。因此,该内核是高度参数化(Parameterized)的,也正是它在底层真正执行矩阵乘法计算。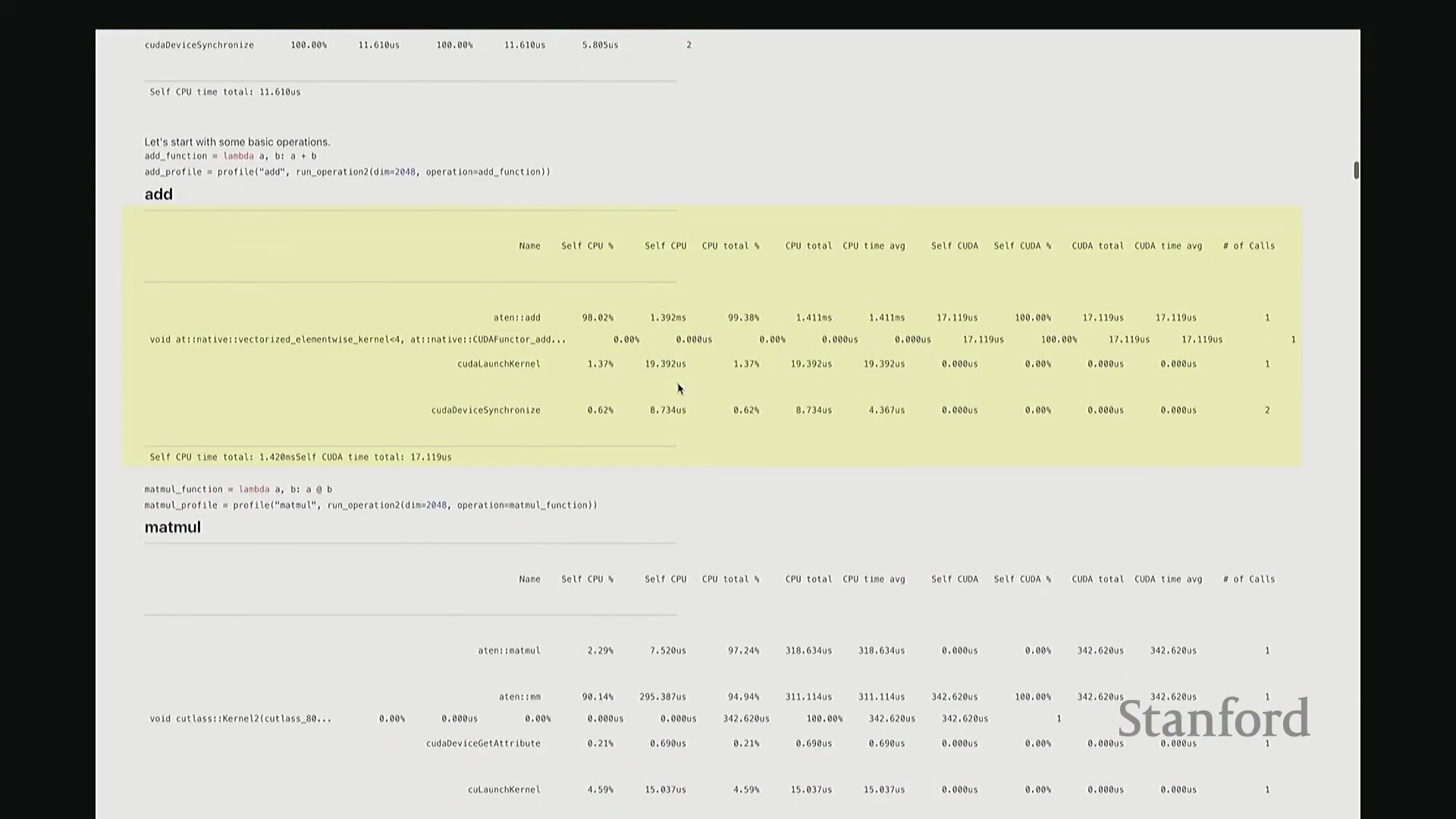
同样,在输出底部我们再次看到内核启动与 CUDA 设备同步的耗时占比。值得注意的是,此次 CUDA 端的耗时比例显著上升,因为矩阵乘法本身的计算量远大于简单的逐元素加法,GPU 计算时间相应增加。到目前为止大家有疑问吗?我可以稍作停顿。刚才讲解分析器时我语速偏快,且主要是单向输出。如果有任何问题,请随时提出。没有的话我将继续。好,请讲。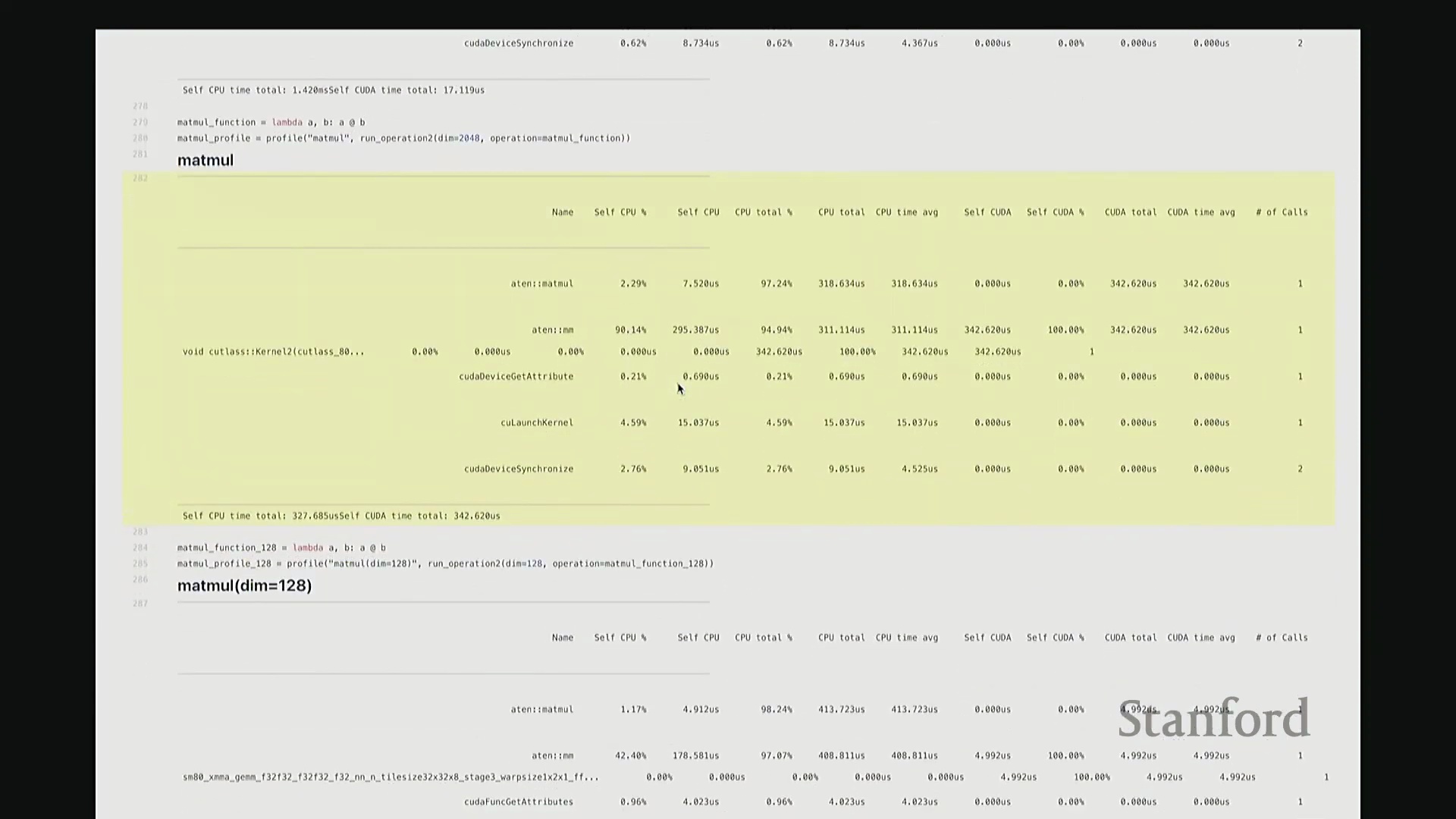
(问答环节)
问:在这种配置下,我的 CPU 时间占比似乎更高,但我们确实设置了同步屏障来对齐 CPU。那么,CPU 耗时难道不应该与之前保持一致吗?
答:不完全是这样。在计时中,这部分等待时间会被纳入计算。不过,严格来说,精确切割这部分时间的归属并非我们当前最关注的核心因素。
问:好的。抱歉,我还有另一个问题。有没有什么原因会导致从加法切换到矩阵乘法时,CPU 时间占比发生变化?为什么切换到矩阵乘法后,CPU 时间占比反而下降了?
答:老实说,我目前无法给出确切的定论。有同学研究过这个现象或与他人讨论过吗?
问:性能分析器(Profiler)本身是否存在测量开销(Measurement Overhead)?与实际运行相比,它是否会扭曲计时结果?
答:是的,性能分析器确实会引入一定的开销。同步屏障本身就会造成这种影响。稍后我将展示 NVIDIA 提供的高级分析工具。即使在代码中添加性能分析注解,也只会轻微影响计时结果,偏差很小。大家所看到的宏观性能指标(Macro-level Performance Metrics)不会被严重扭曲。因此,如果你关注的是微观级别(Micro-level)的极精细计时,确实可能存在些许偏差;但我们在本课程中关注的大多数宏观指标,基本不会受到分析器开销的显著影响。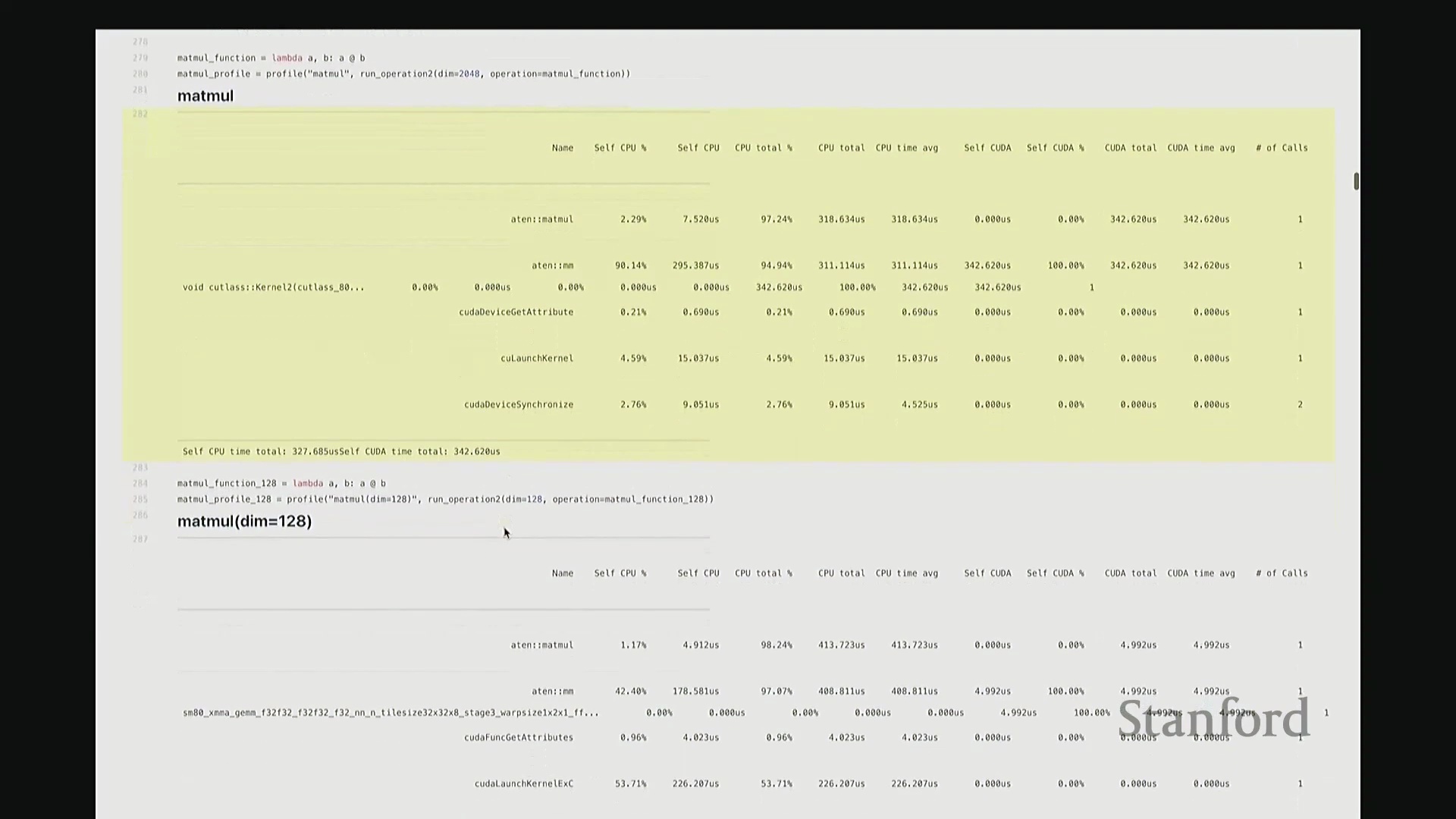
澄清分析器指标与内核选择
问:为了确认我准确理解了这个指标。准确地说,对于 add 操作,98% 的耗时都归因于 CPU。您是这个意思吗?在整个测量周期内。
答:没错。是的,这表示的是时间占比百分比(Percentage of Total Time)。你可以看到 ATen::add 在 CPU 端实际执行所占用的具体毫秒数。
问:我认为这并非指“CPU 使用率(CPU Utilization)”的概念。这 100% 是否仅代表 CPU 在处理此任务期间处于活跃状态?
答:是的。这是一个反映 CPU 活跃状态的高阶指标,而非硬件算力利用率的百分比。它不代表 CPU 的浮点运算能力(FLOPs)占用,仅表示 CPU 在执行该特定任务期间所消耗的时间占总运行时间的比例。
问:明白了。
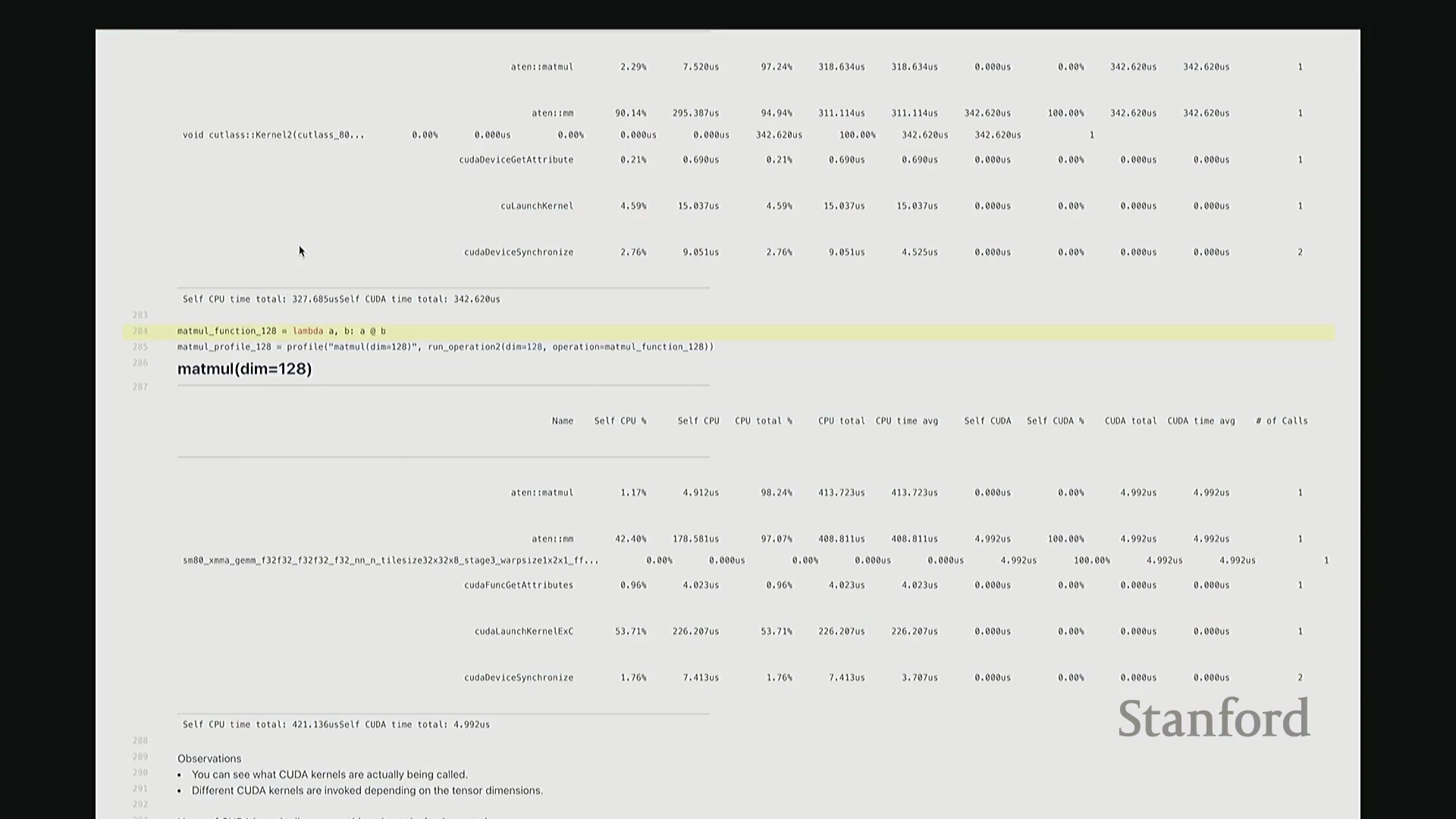
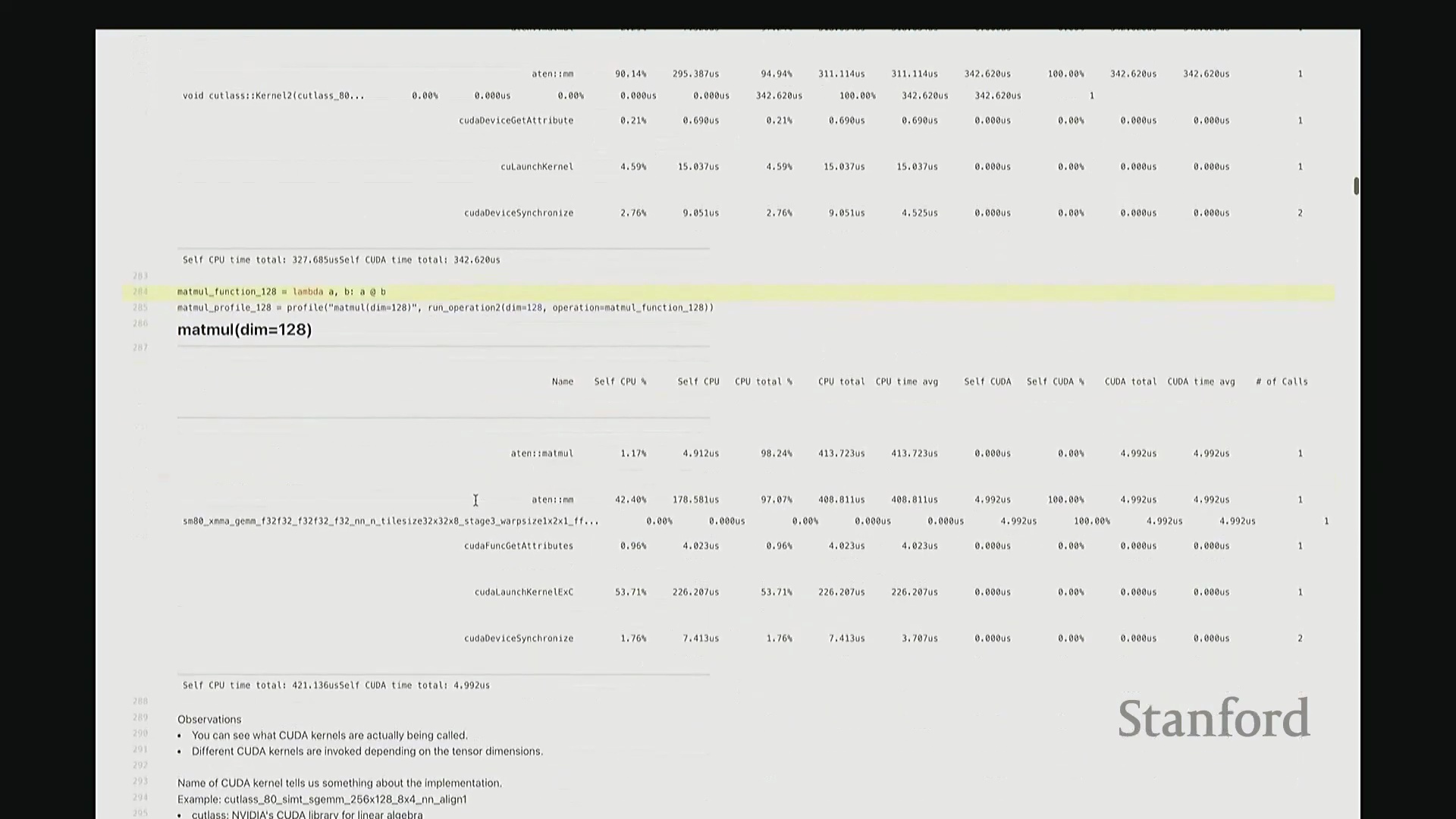
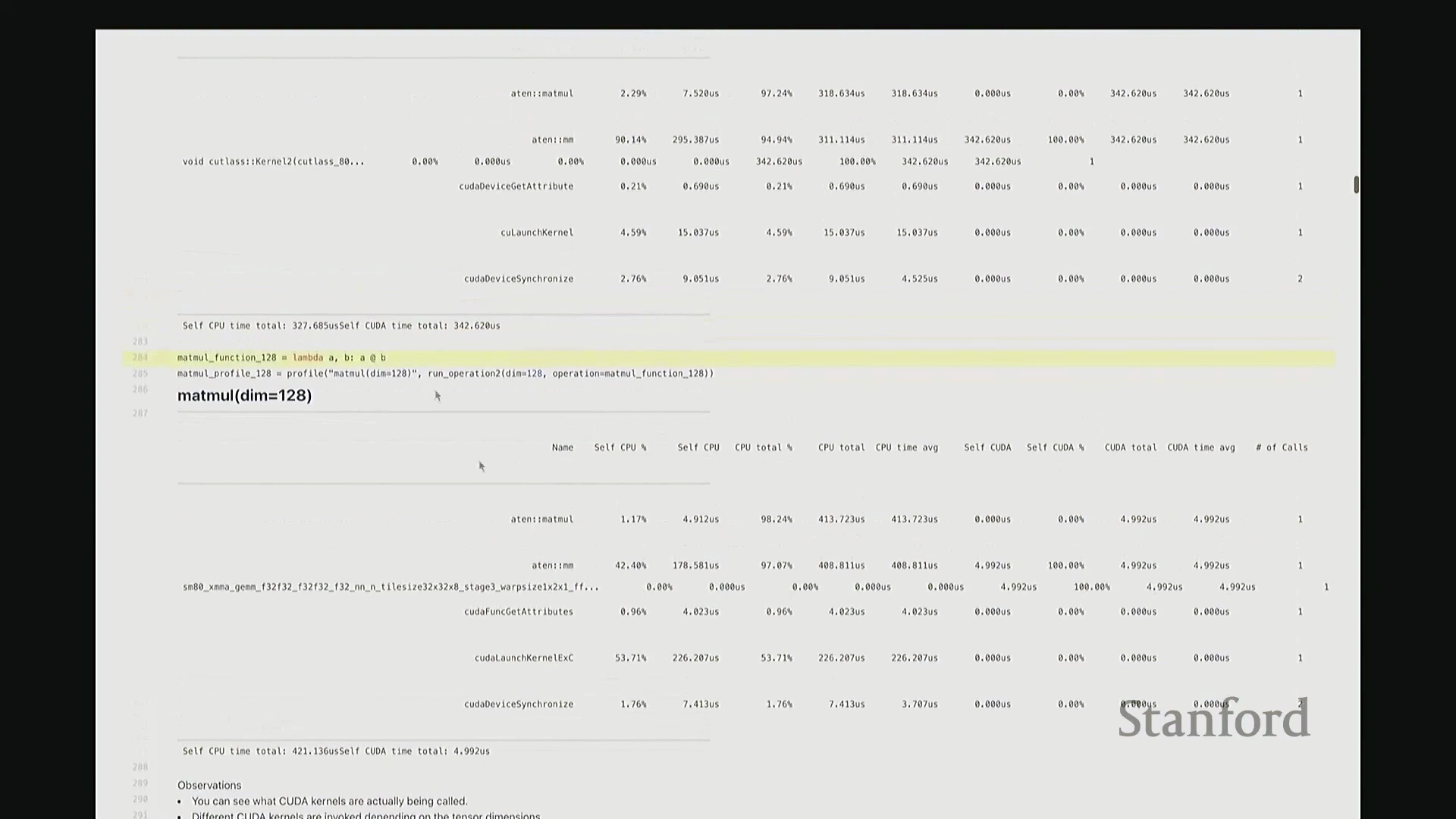
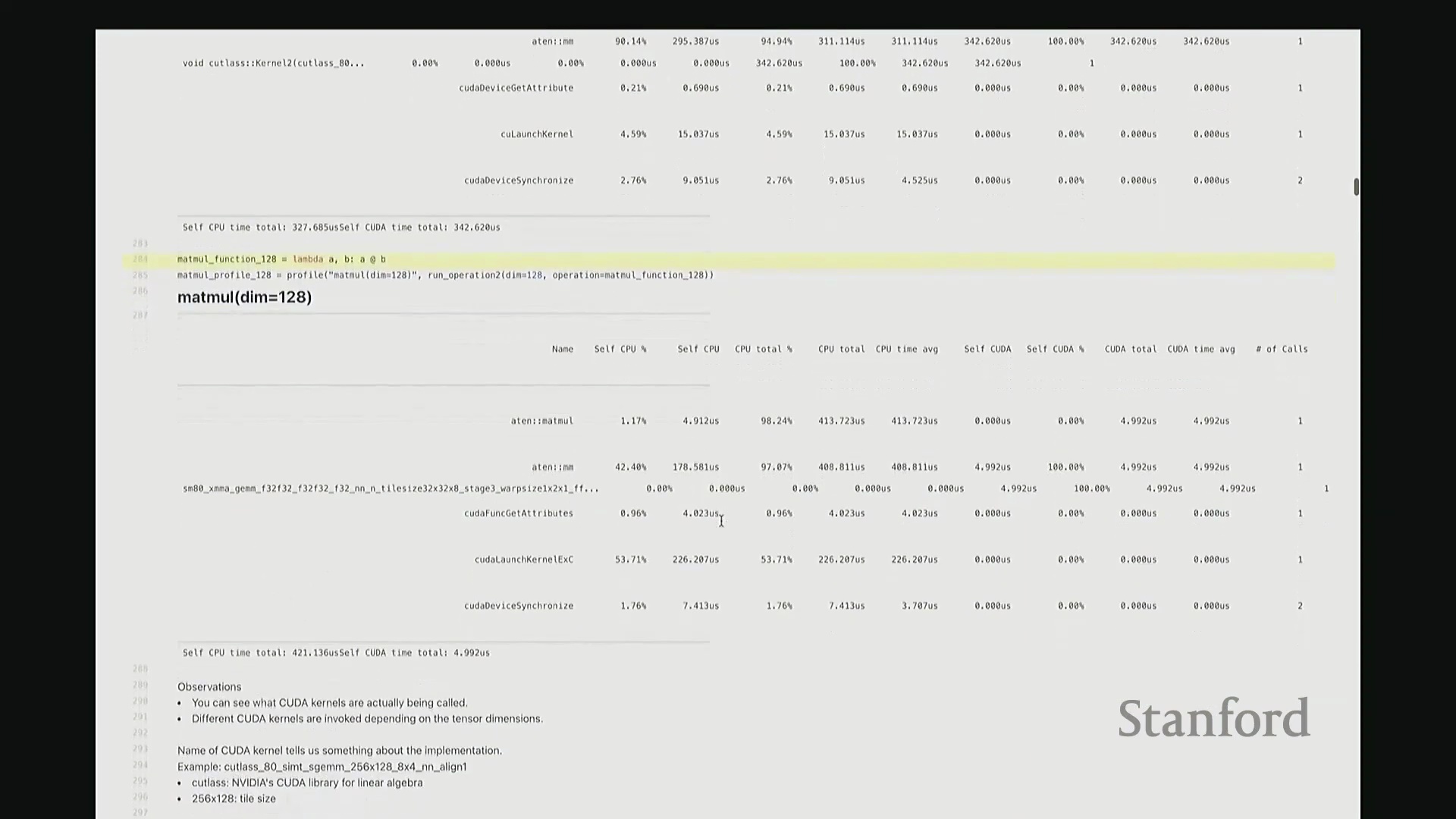
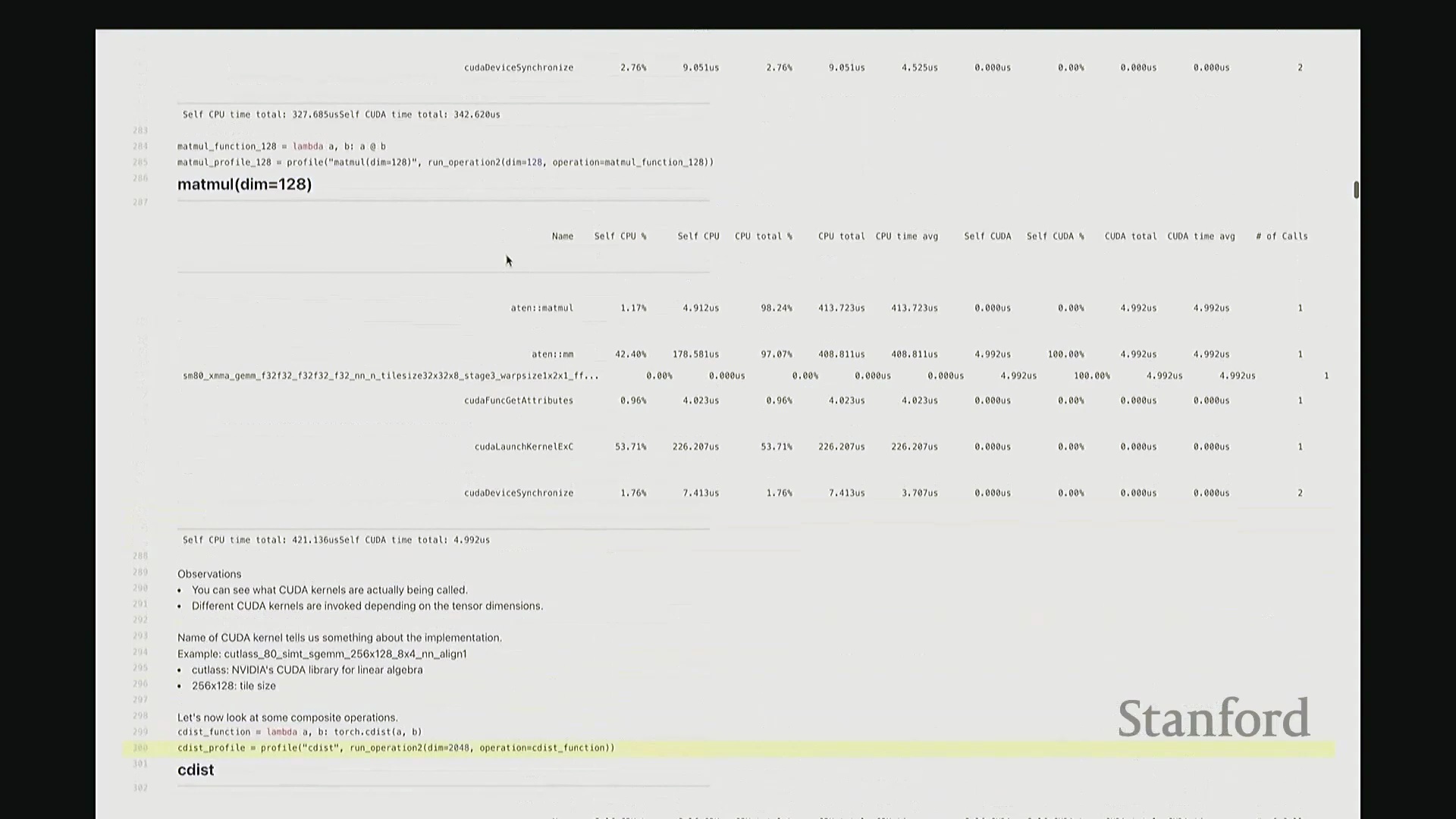
答:好的。接下来是另一个矩阵乘法的示例,但这次采用了不同的维度。我在此相乘的是 128x128 的矩阵,规模显著缩小。大家可以看到,系统此时直接调用了另一套指令集:sgemm(单精度通用矩阵乘法(Single-precision General Matrix Multiply, SGEMM)),用于处理 float32 数据类型。从该内核的命名即可推断其底层行为:这是一种针对特定分块策略优化的矩阵乘法内核。它并未经过 CUTLASS 库的常规派发流程,而是直接调用了这个特定的底层实现。因此,针对小规模矩阵乘法,调度器会自动将其路由至不同的内核。由此可见矩阵乘法实现的复杂性。在高级抽象层面,我们通常将矩阵乘法视为一个黑盒操作,只需调用 A @ B 即可。但在底层,根据输入数据的维度与当前硬件环境,该操作会被动态派发至截然不同的底层原语(Primitives),从而直接导致性能特征的显著差异。
这里有一个非常实用的技巧:我稍后将详细讲解 torch.compile。它提供了一个内置选项,可在你的特定硬件上自动执行矩阵乘法微基准测试(Micro-benchmark),并据此为你的模型自动择优匹配性能最高的矩阵乘法子程序。根据过往经验,这通常能“免费”带来约 10% 的性能加速。针对这些底层调度细节进行优化,确实能在实际应用中带来显著的零成本性能收益,非常实用。回到这个矩阵乘法示例。与单纯的原始基准测试相比,使用性能分析器的核心优势在于:我们现在能清晰透视底层究竟调用了哪些 CUDA 内核。我们可以直观看到,不同尺寸的矩阵会触发不同的内核调度策略。此外,还能获取诸如 CUTLASS 库中 sgemm 的具体实现版本及其分块大小等关键参数信息。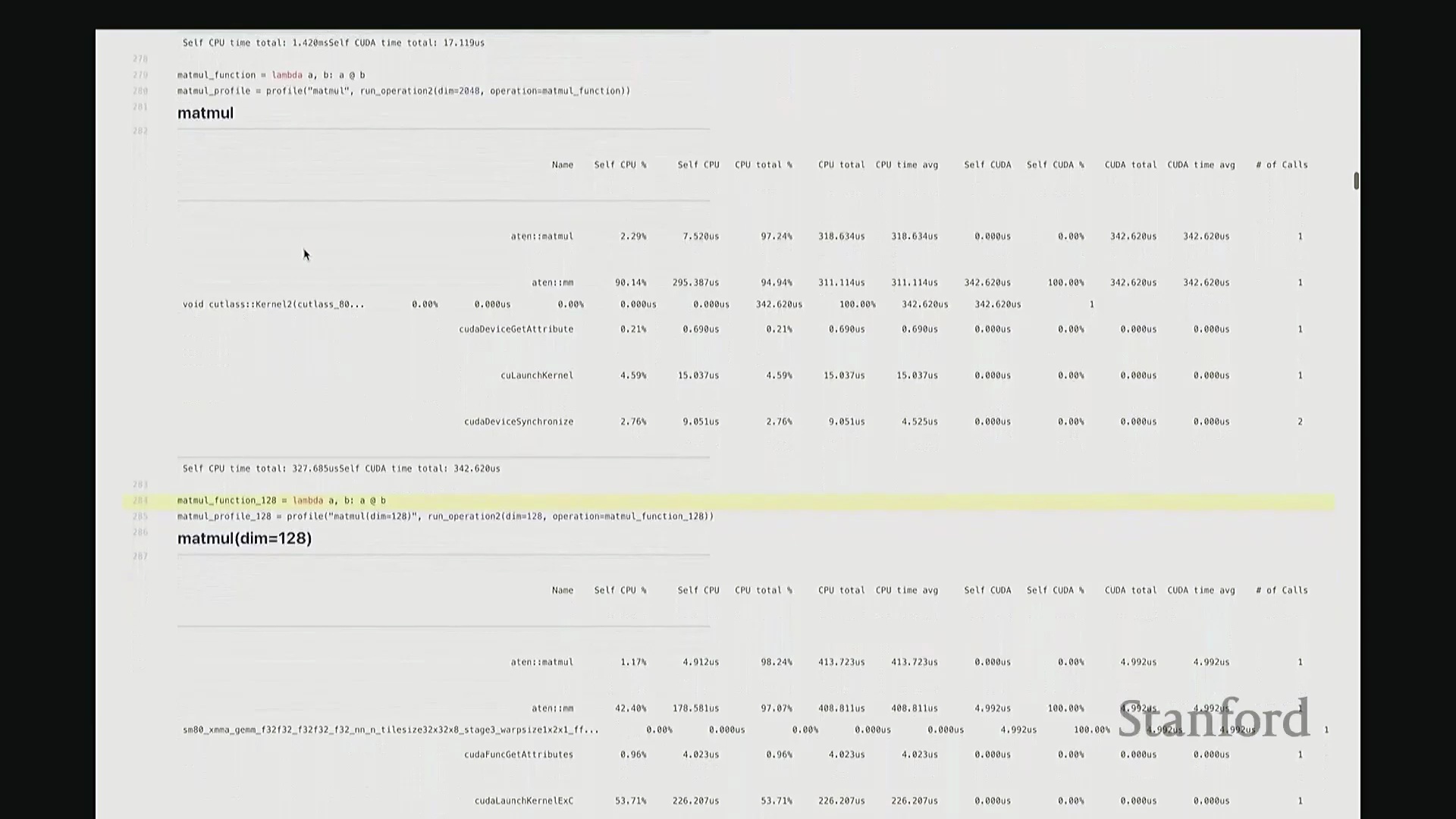

分析复合操作:torch.cdist
截至目前,我们分析的操作在某种程度上都相对“简单”。像矩阵乘法和加法,它们基本呈现一对一的映射关系:CPU 端的一个高级操作直接对应转换为一个 GPU 内核,随即下发执行。换言之,在这些示例中,GPU 上仅执行单一的有效计算内核。因此,接下来我想观察一些更复杂的操作,它们展现出更多复合(Compound)行为。
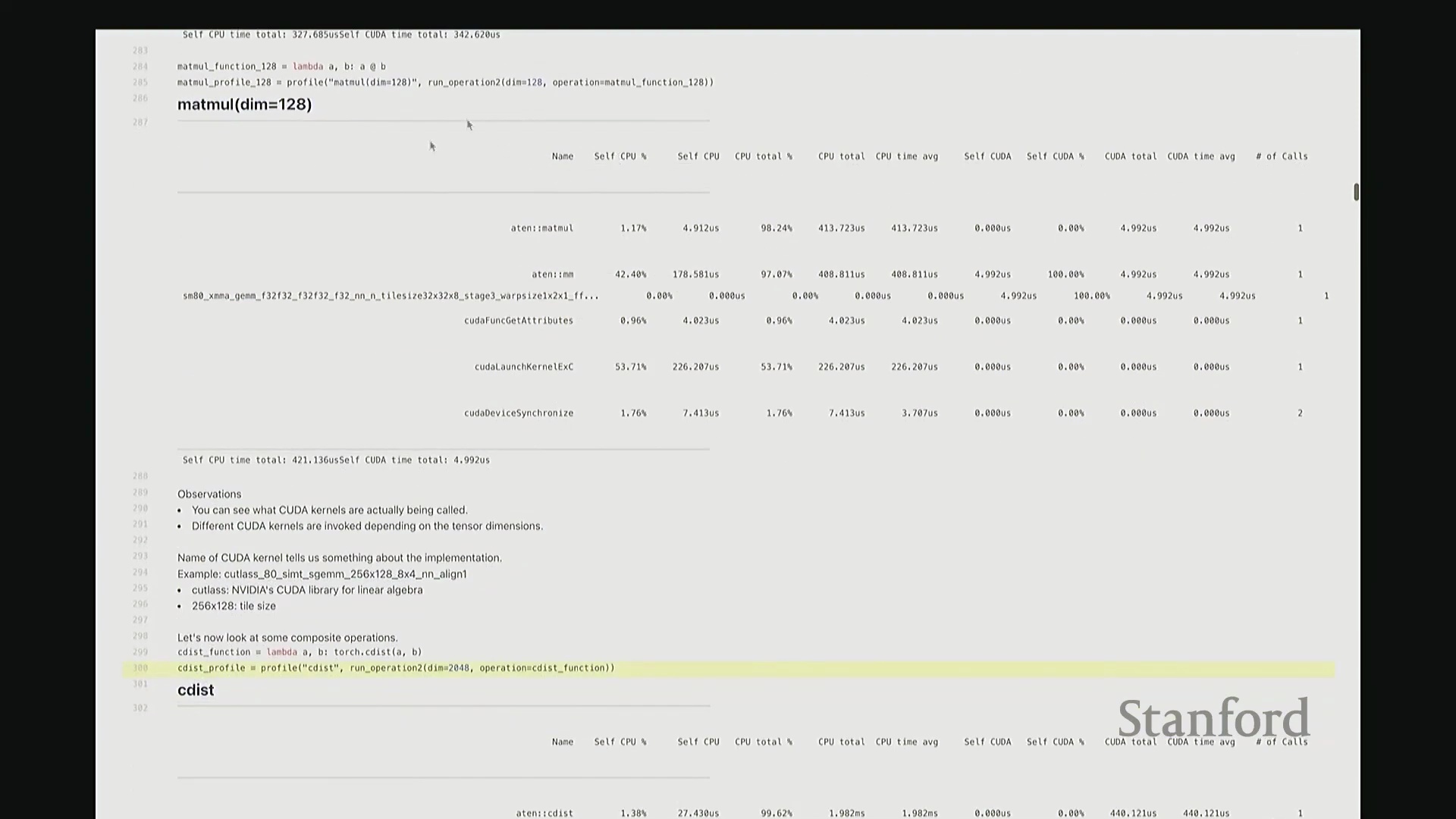
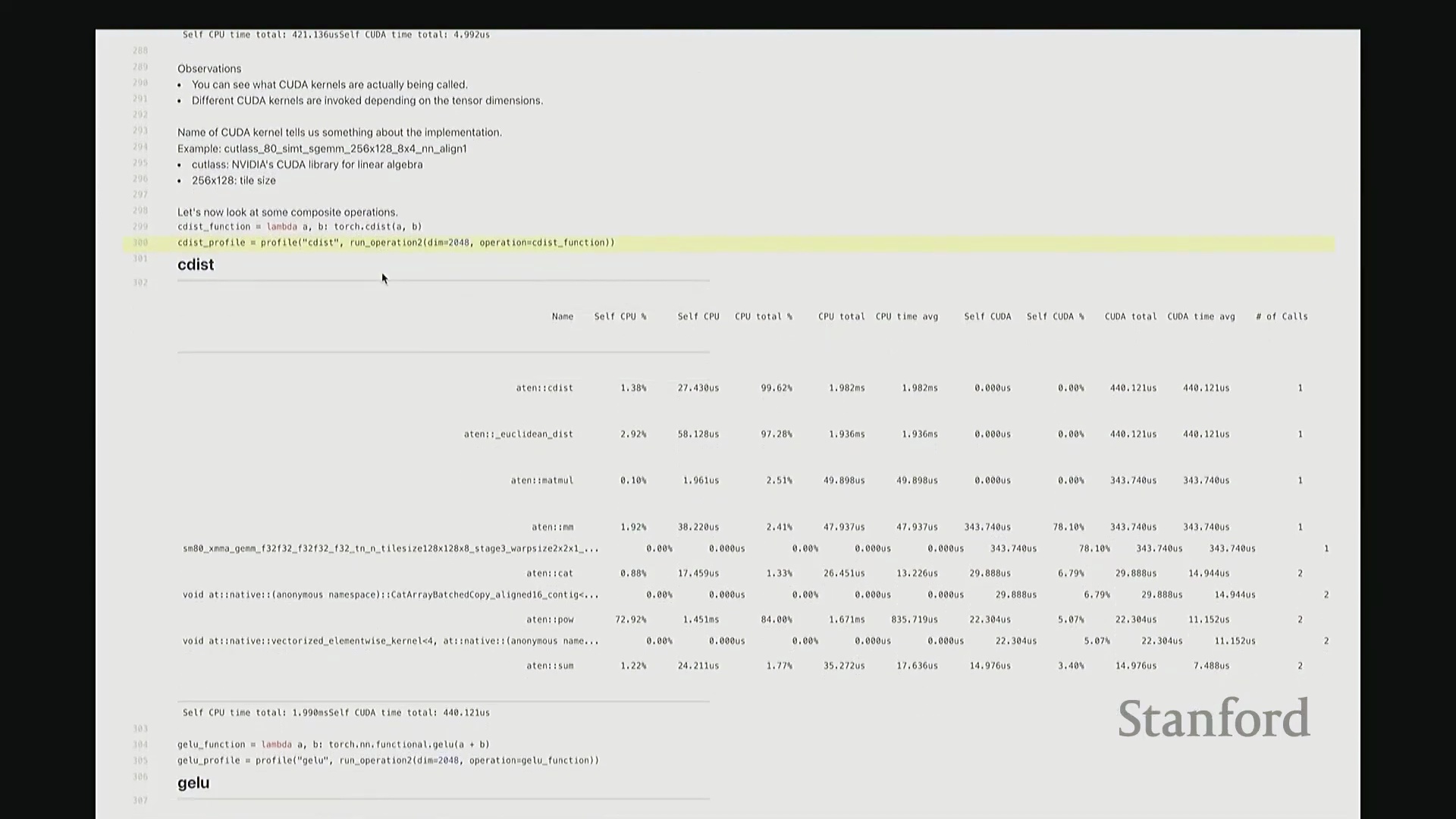
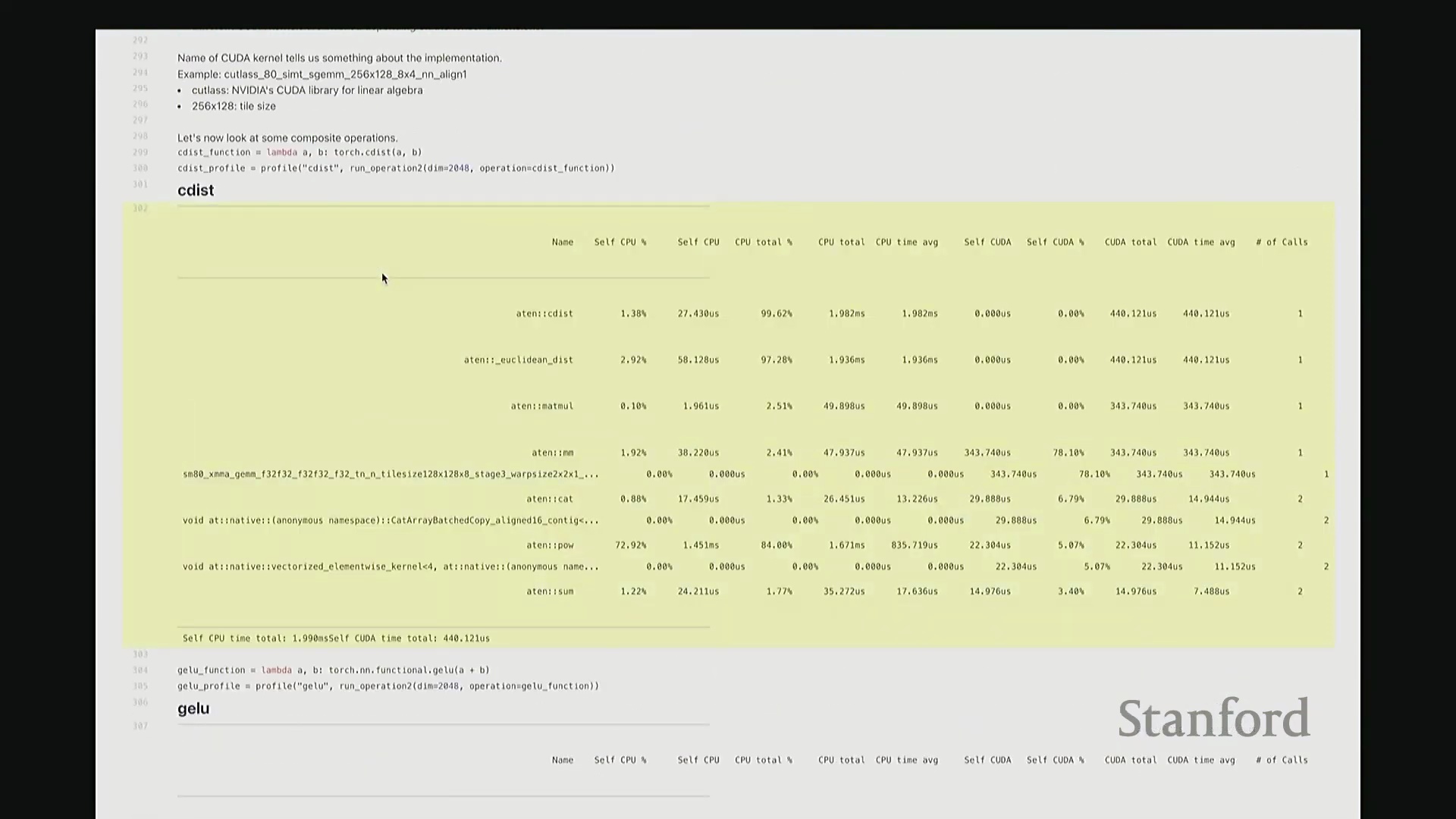
我现在要分析的是 torch.cdist 操作。该函数用于计算两组向量之间的成对欧氏距离(Pairwise Euclidean Distance),对吧?这将生成一个大规模的距离矩阵。显然,cdist 的内部逻辑要复杂得多。若要计算欧氏距离,底层需执行点积(Dot Product)、平方根(Square Root)等一系列数学运算。一旦我们对 cdist 进行性能分析,这些底层步骤将一览无余。
这是 cdist 的性能分析报告。我们可以看到,Python 层的 torch 命令首先映射至 C++ 底层接口 ATen::cdist,随后进一步调用 ATen::euclidean_distance。紧接着,该操作被拆解为大量子操作,例如 ATen::matmul(矩阵乘法)、ATen::pow(逐元素幂运算)等,因为这些正是计算欧氏距离所必需的底层数学原语(Primitives)。随后,系统依次计算所有向量对之间的欧氏距离。针对其中的每一个步骤(如矩阵乘法、张量拼接(Tensor Concatenation)、逐元素乘方等),均有对应的 CUDA 内核被调度执行。大家请看,我们再次遇到了熟悉的 gemm(通用矩阵乘法(General Matrix Multiply)),它占据了 GPU 计算总耗时的 78%。此外,数据复制与数组拼接操作约占 6% 的执行时间。其余时间则消耗在这类向量化逐元素(Vectorized Element-wise)内核上……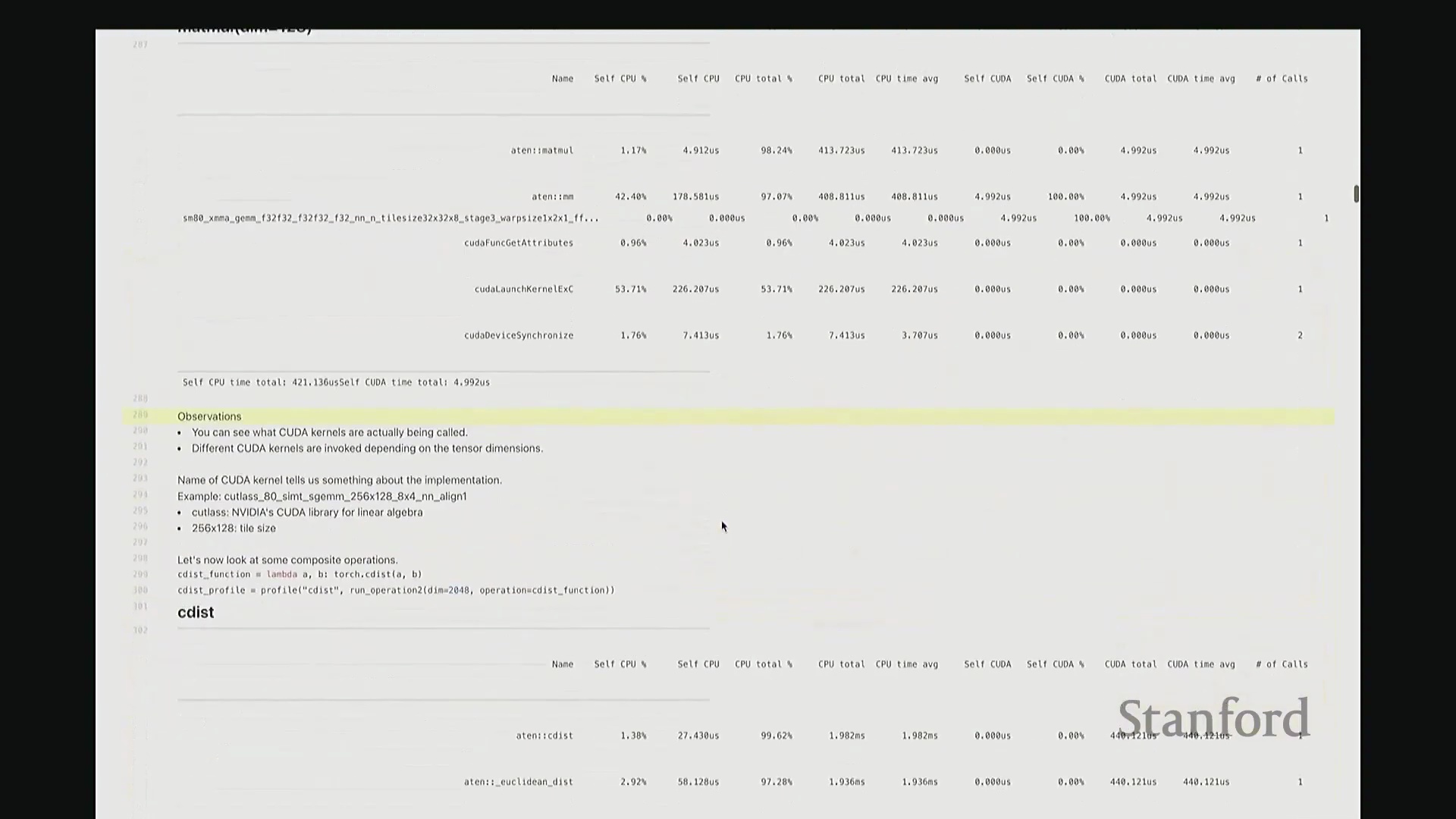
分析复合操作与定位瓶颈
……的执行时间。随后,负责幂运算的向量化逐元素内核(Vectorized Element-wise Kernel)消耗了 5% 的 GPU 计算时间,另有 3% 的时间用于求和(Reduction)操作。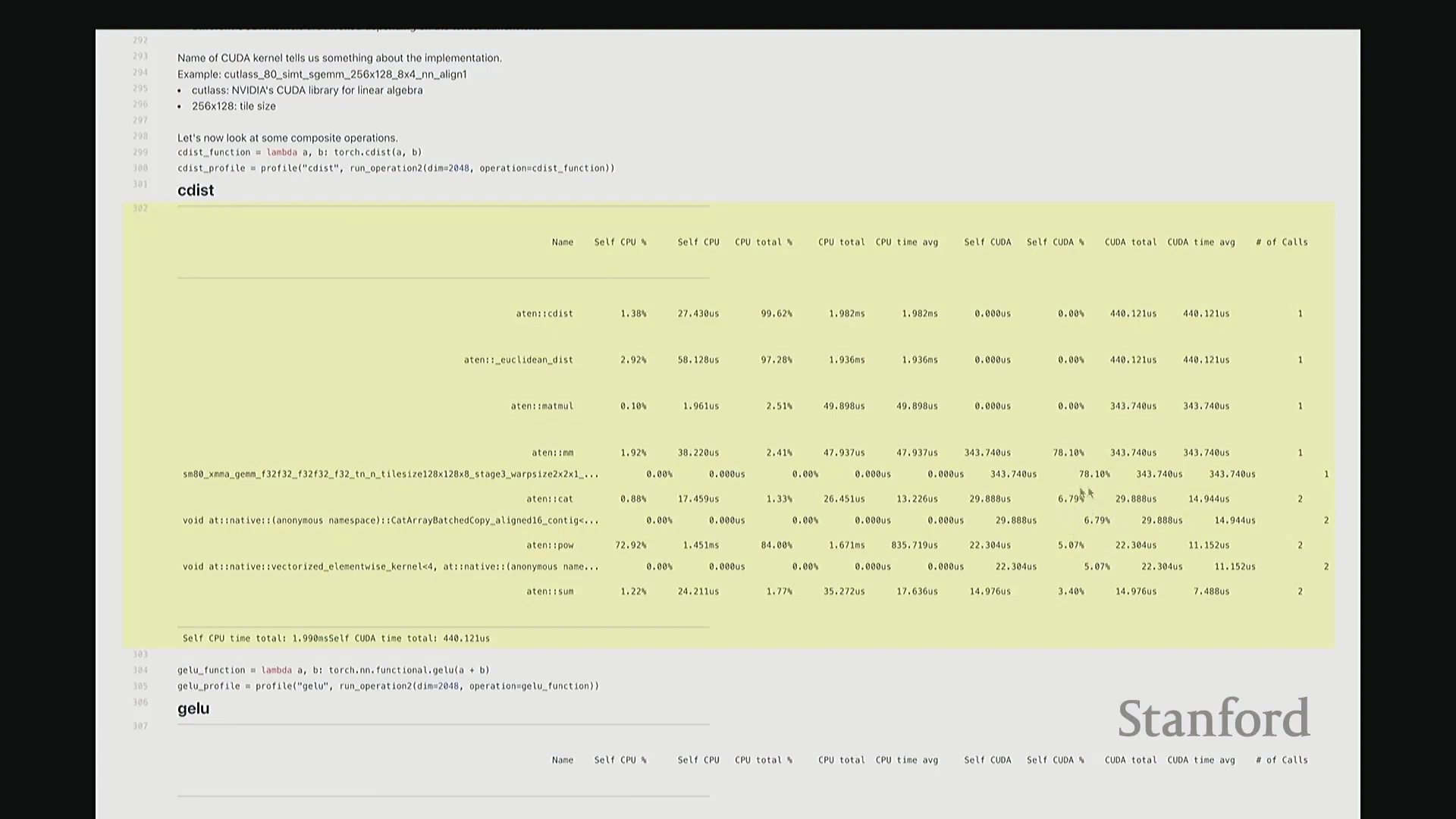 至此,我们获得了极为清晰的底层性能明细,精准定位了 GPU 的耗时分布。基于此,我们可以明确性能优化的核心方向。例如,我可能会优先优化矩阵乘法(Matrix Multiplication),这将是极具价值的投入,因为它占据了高达 70% 的 GPU 计算时间。
至此,我们获得了极为清晰的底层性能明细,精准定位了 GPU 的耗时分布。基于此,我们可以明确性能优化的核心方向。例如,我可能会优先优化矩阵乘法(Matrix Multiplication),这将是极具价值的投入,因为它占据了高达 70% 的 GPU 计算时间。
核心原语的融合内核:GeLU 与 Softmax
接下来要分析的最后两个示例是 GeLU 和 Softmax。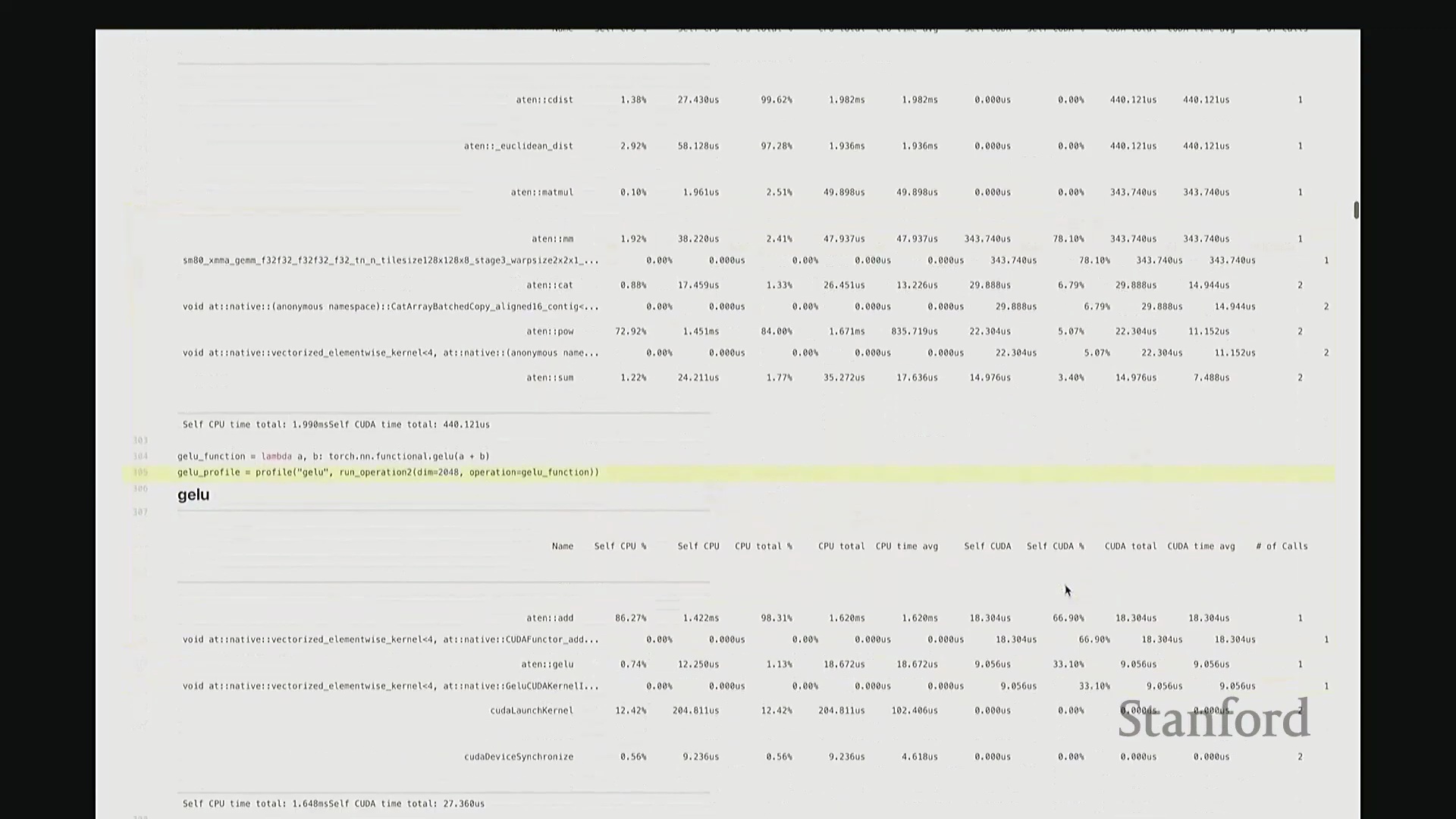 它们将作为贯穿本课程的核心案例。哦,抱歉,现场有个问题。那是什么?大概两英里外?(讲师笑)我在回想那个公式。稍后我会用几分钟解答,因为借助更强大的分析器,我们可以用更直观的图表来阐释。我先把链接放出来,但稍后用图示讲解效果更佳。
它们将作为贯穿本课程的核心案例。哦,抱歉,现场有个问题。那是什么?大概两英里外?(讲师笑)我在回想那个公式。稍后我会用几分钟解答,因为借助更强大的分析器,我们可以用更直观的图表来阐释。我先把链接放出来,但稍后用图示讲解效果更佳。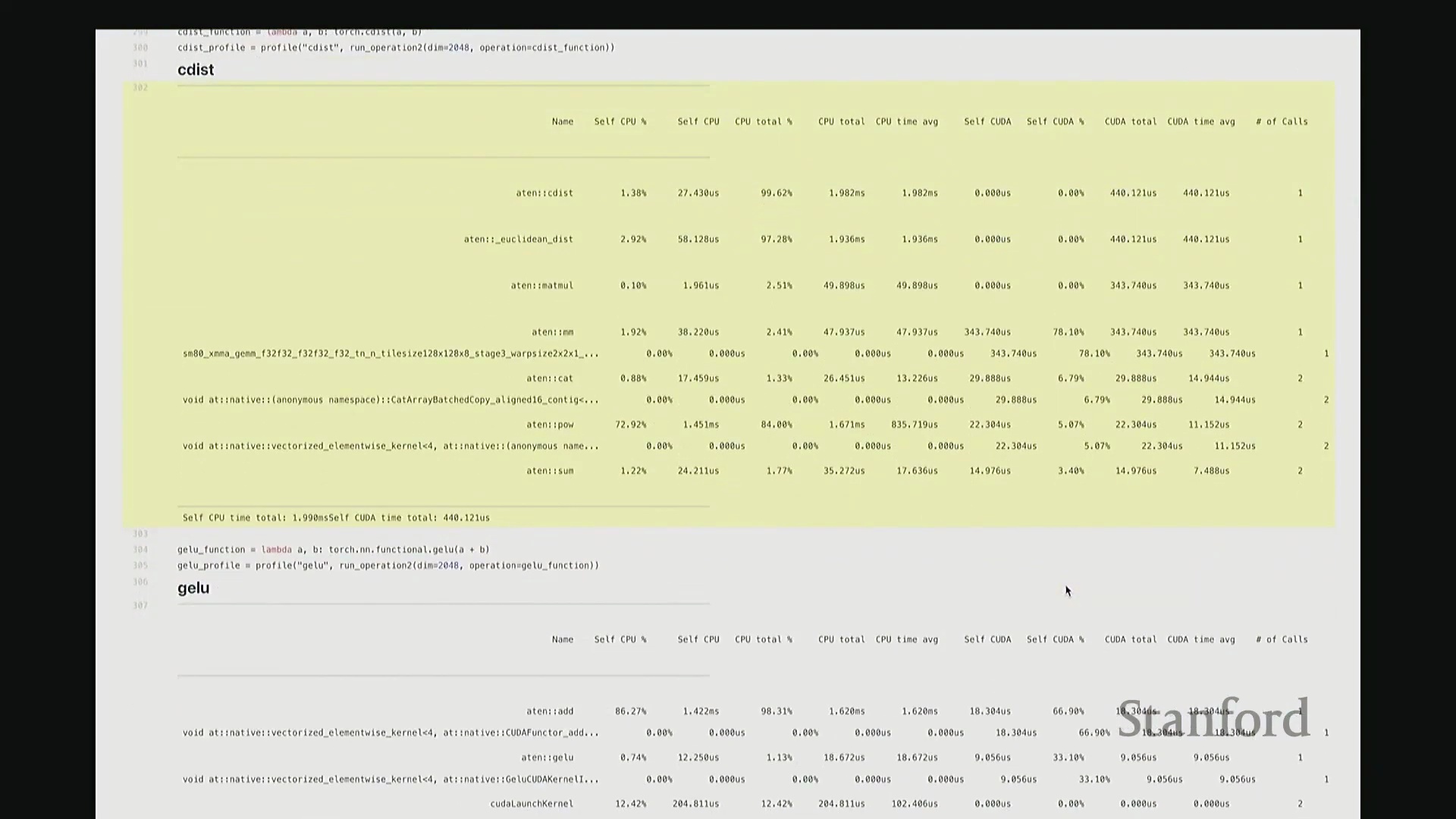 现在回到 GeLU 和 Softmax。GeLU 将作为本课程的主要分析对象。它是一种非线性激活函数(Non-linear Activation Function),全称为高斯误差线性单元(Gaussian Error Linear Unit, GeLU)。若我没记错,其数学表达式由
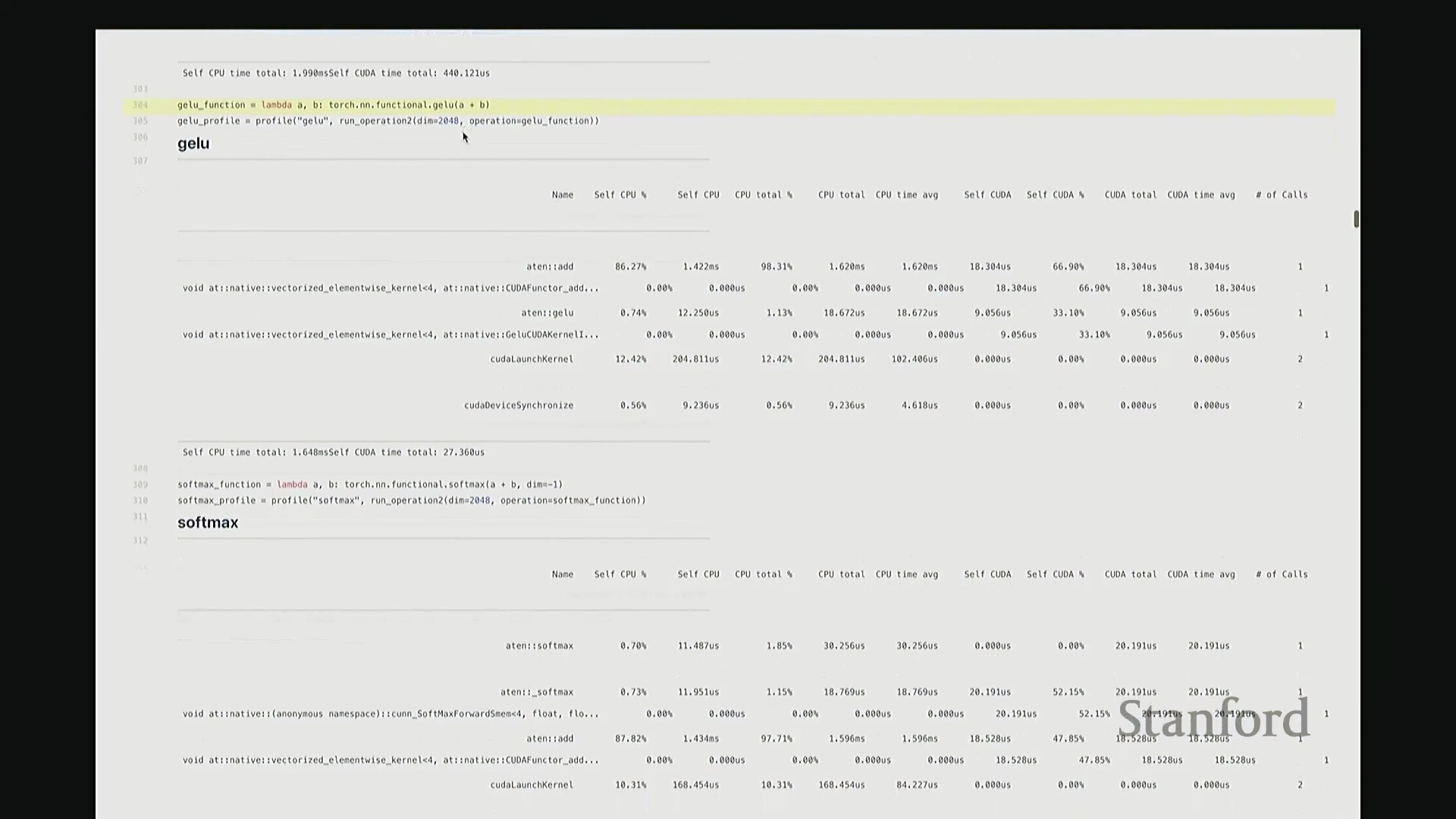
现在回到 GeLU 和 Softmax。GeLU 将作为本课程的主要分析对象。它是一种非线性激活函数(Non-linear Activation Function),全称为高斯误差线性单元(Gaussian Error Linear Unit, GeLU)。若我没记错,其数学表达式由 tanh 和指数函数(Exponential Function)组合而成,因此涉及多种底层运算。示例中,我们将 a 和 b 相加后进行线性变换,以此模拟多层感知机(MLP)中典型的“线性层(Linear Layer) + 非线性激活”结构。我们再次观察到相似的底层映射关系:ATen::add 对应 a + b 操作,并调用对应的 CUDA 实现。随后,我们看到一个完全由 CUDA 实现的 GeLU 函数位于调用栈底层,约消耗 33% 的计算时间,这一比例相当合理。接着是 Softmax 分析。稍后我们会极其详尽地剖析这些案例,虽然它们的分析视图看起来大同小异。但我想特别强调一个关键设计:对于 Softmax 和 GeLU 这类核心基础原语,底层已为其专门编写了高度优化的内核。因此,GPU 并非逐个调度执行这些零散的原语操作,而是通过一个融合算子(Fused Operator)一次性完成所有计算。这有效避免了操作间频繁的 CPU-GPU 通信与同步开销。
PyTorch 分析器的局限性与 Nsight Systems 简介
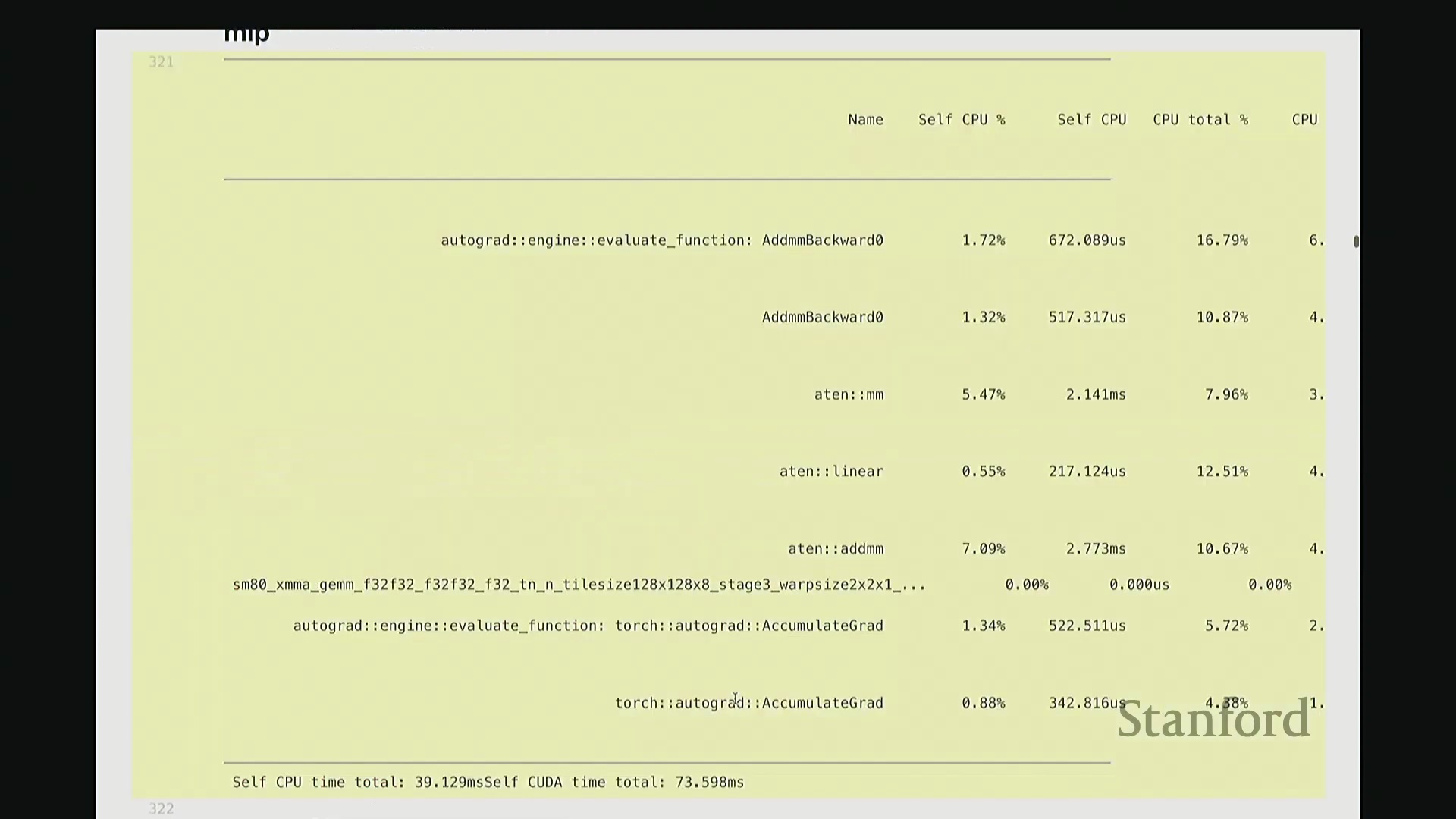
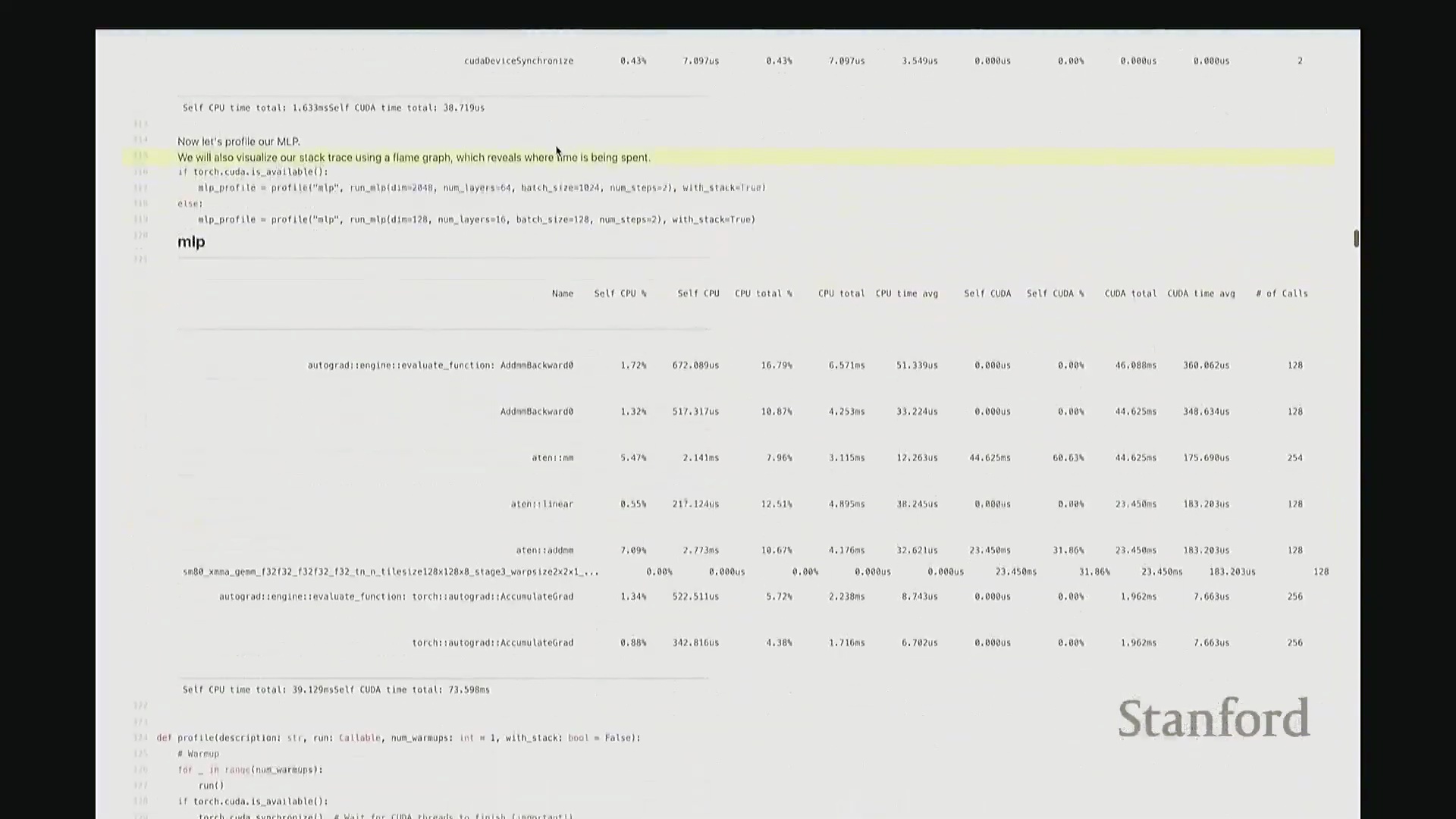
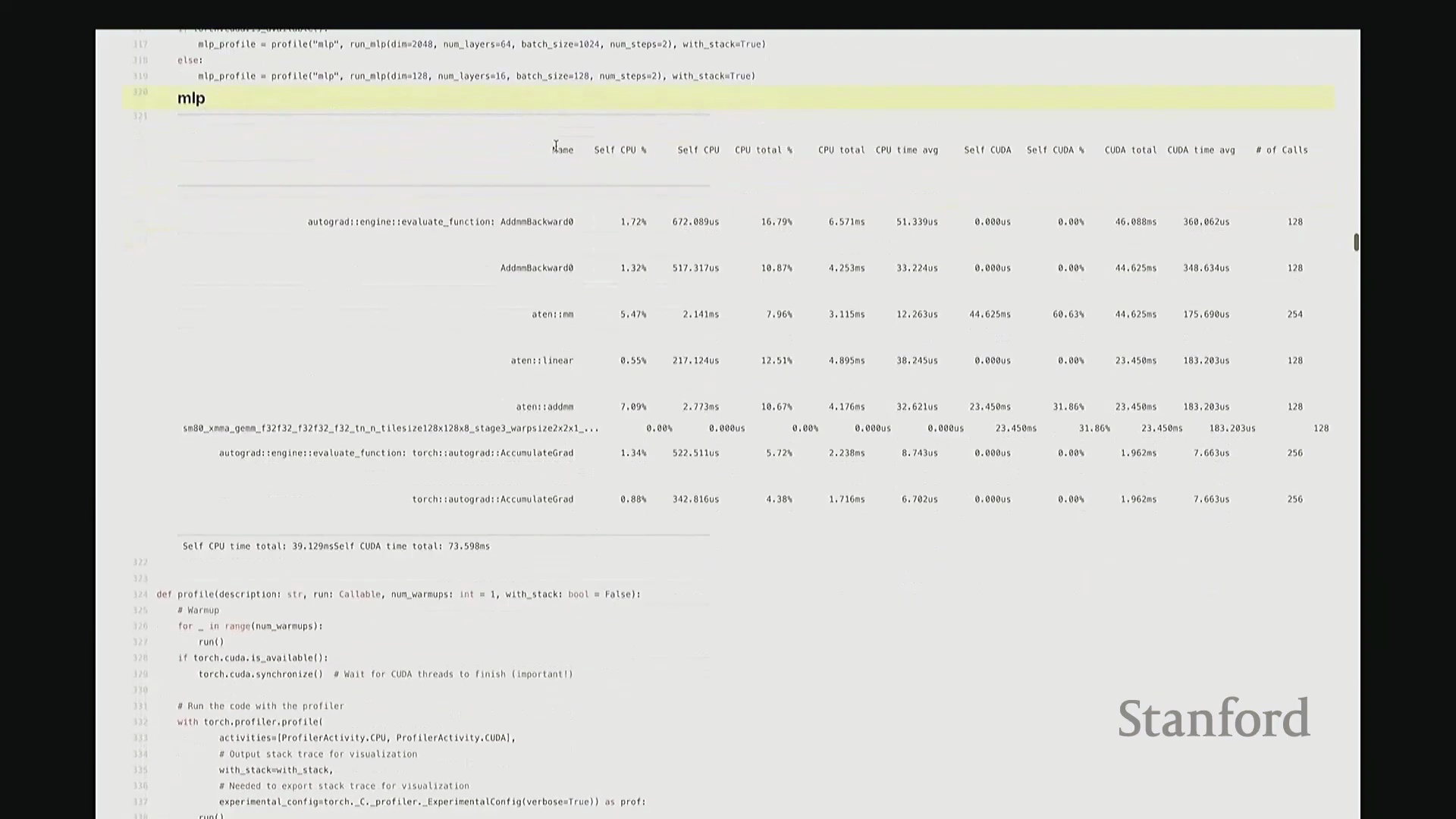
此前我承诺过会解答“CPU 在此期间究竟在做什么”的疑问。为此,我们需要分析更复杂的场景。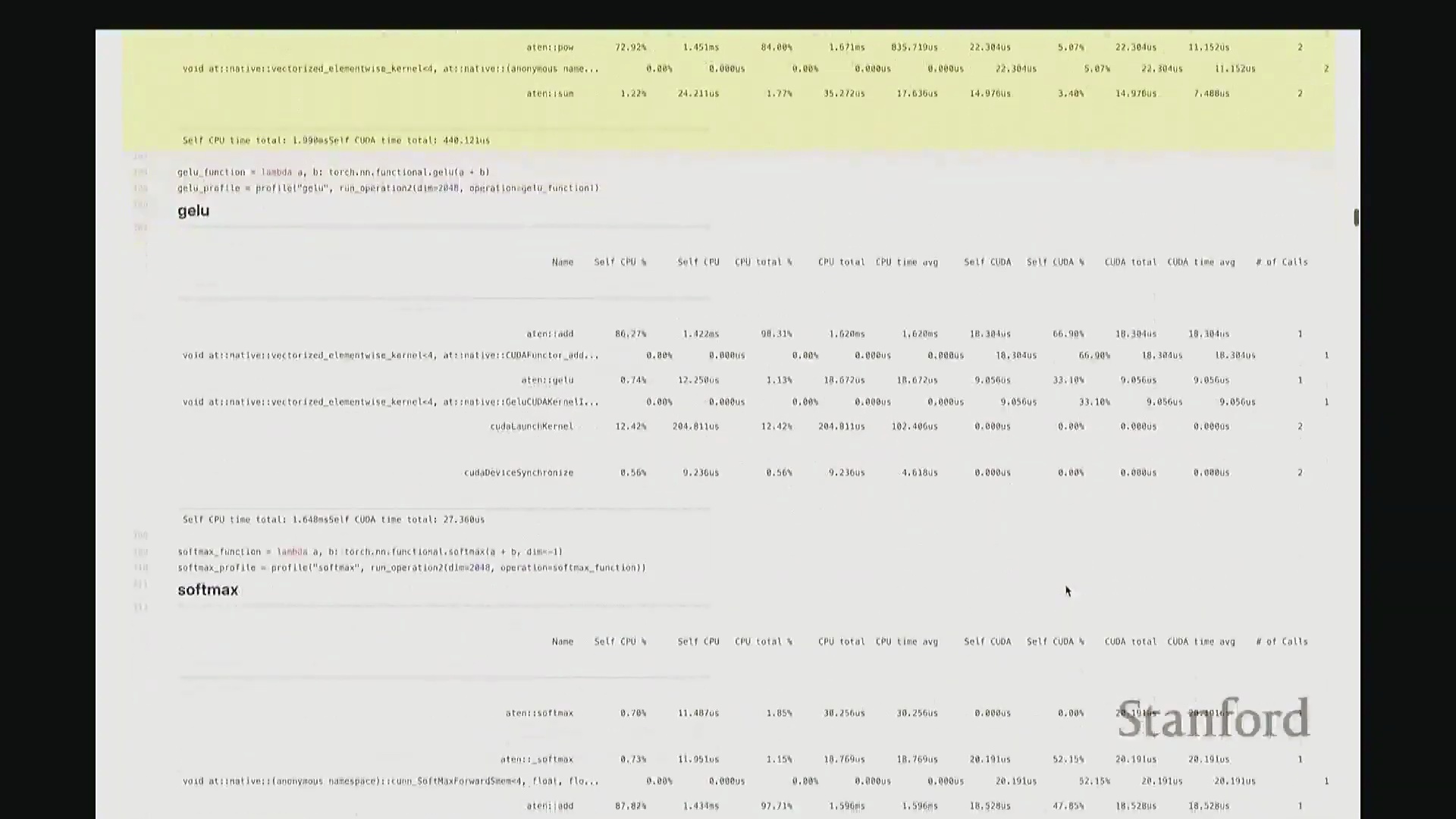 回顾课程开头用于基准测试的 MLP 示例。若我们旨在将该 MLP 优化至极致性能,该从何入手?理想情况下,我们需要以更高细粒度(Fine-grained)进行性能剖析。若仅使用 PyTorch 内置分析器(PyTorch Profiler),输出结果大致如下。大家应还记得该 MLP 的结构:由多层堆叠的线性层构成,包含完整的前向传播(Forward Pass)与反向传播(Backward Pass)。从输出中可粗略看到反向传播的痕迹,例如矩阵乘法和线性层操作。反向传播中还包含梯度累加(Gradient Accumulation /
回顾课程开头用于基准测试的 MLP 示例。若我们旨在将该 MLP 优化至极致性能,该从何入手?理想情况下,我们需要以更高细粒度(Fine-grained)进行性能剖析。若仅使用 PyTorch 内置分析器(PyTorch Profiler),输出结果大致如下。大家应还记得该 MLP 的结构:由多层堆叠的线性层构成,包含完整的前向传播(Forward Pass)与反向传播(Backward Pass)。从输出中可粗略看到反向传播的痕迹,例如矩阵乘法和线性层操作。反向传播中还包含梯度累加(Gradient Accumulation / accumulate_grad)步骤,以及对应的矩阵乘法内核。然而,该视图默认仅显示 10 个条目,后续内容疑似被截断。尽管如此,它确实明确指出大部分耗时集中于 matmul。但你会疑惑:剩余的耗时去哪了?为何仅有 31% 的时间被明确归类?那 60% 的耗时究竟消耗在何处?报告虽将其归于 matmul,却未展示对应的底层内核细节,这显得颇为晦涩。对于矩阵乘法此类复杂操作,该工具的可视化能力显然不足。因此,我们必须引入工业级专业分析工具。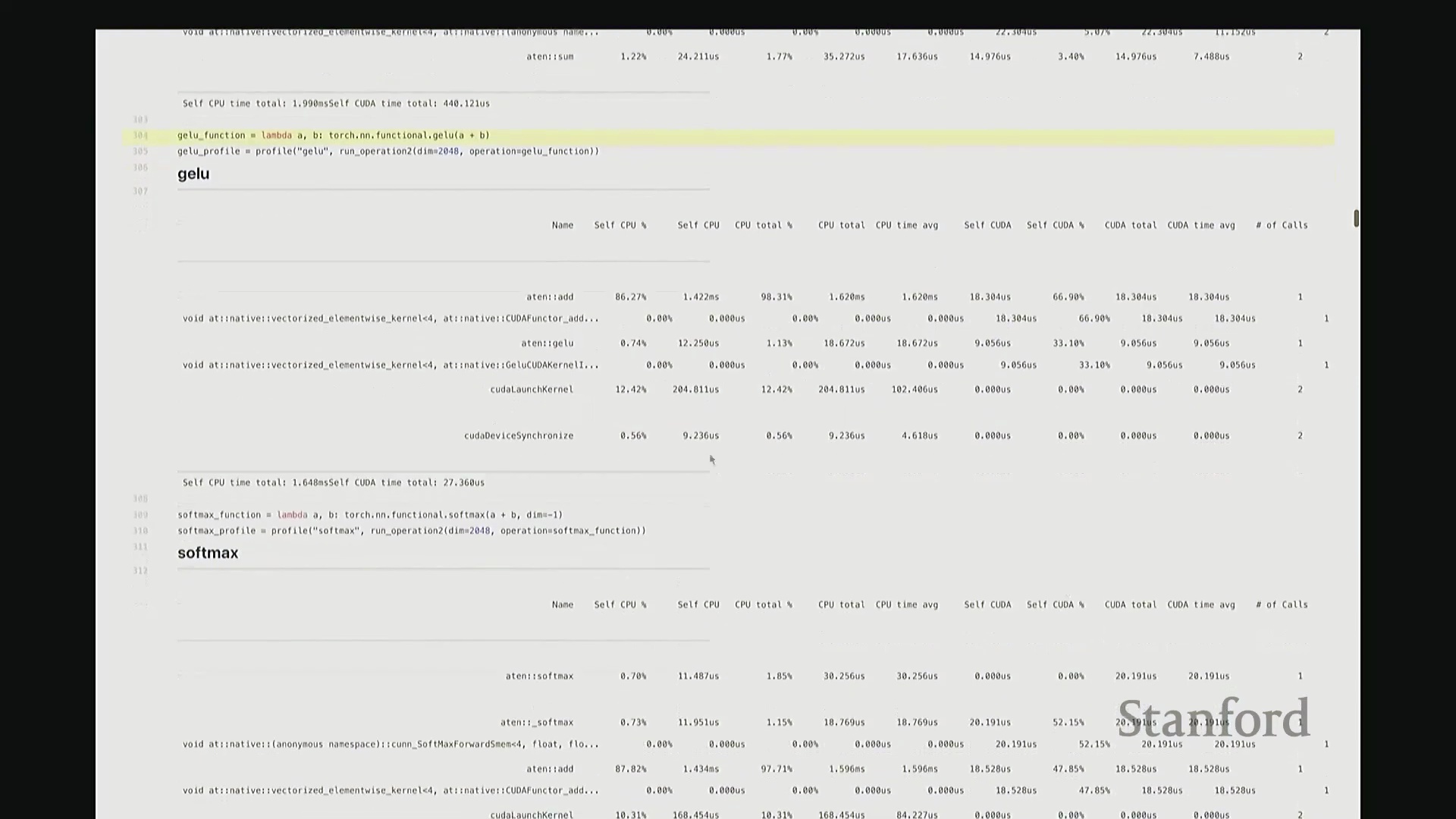
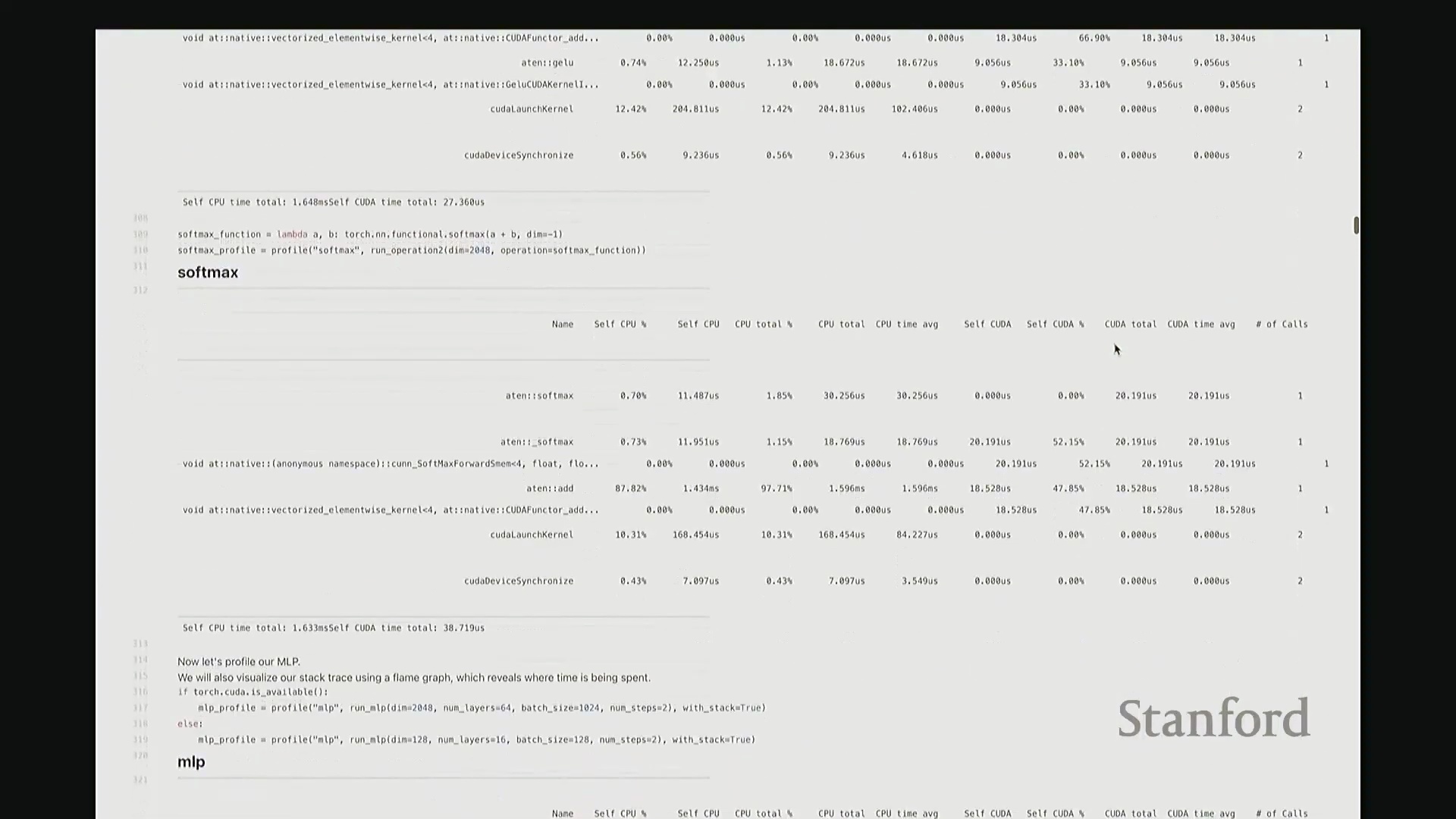
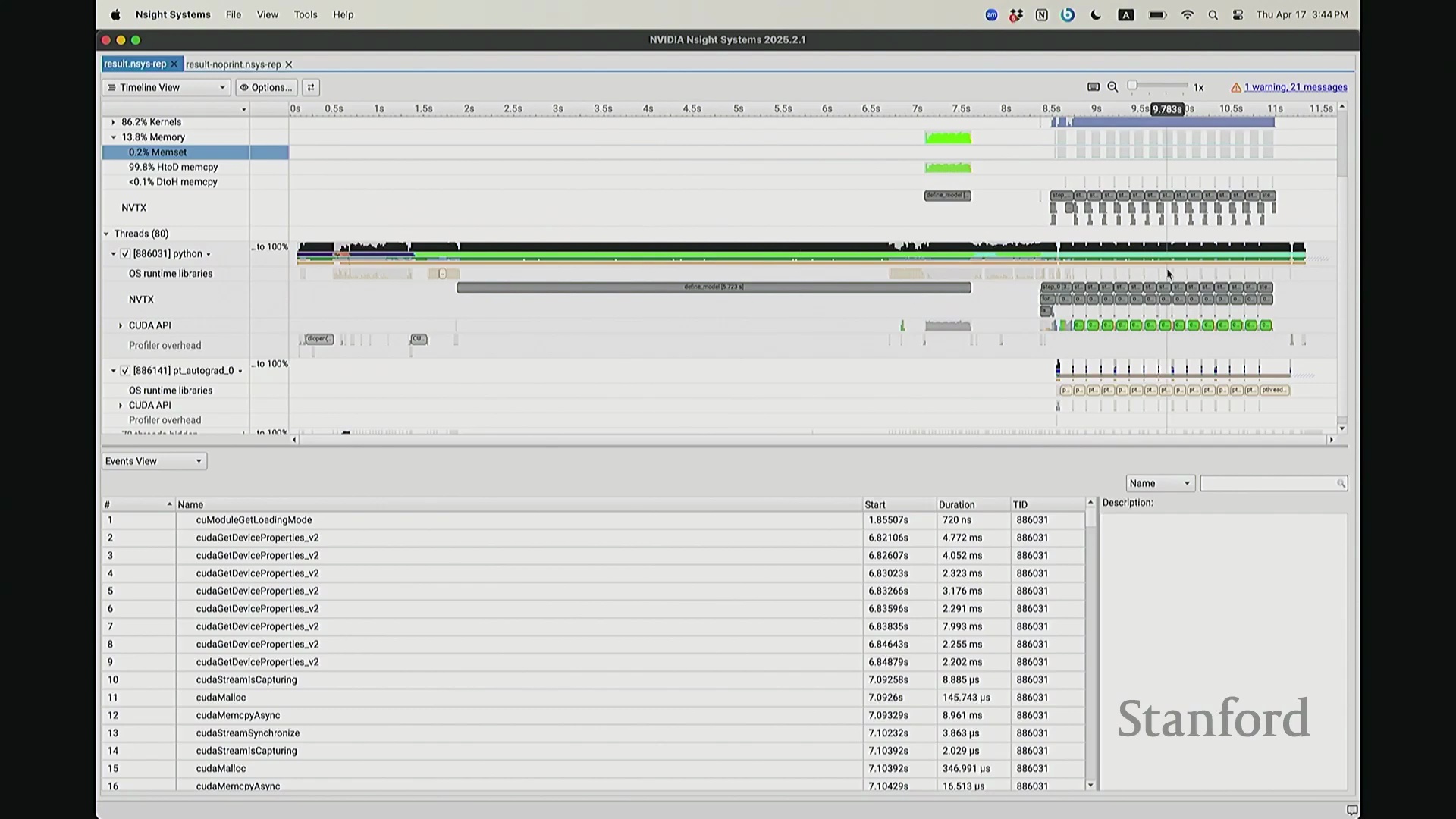
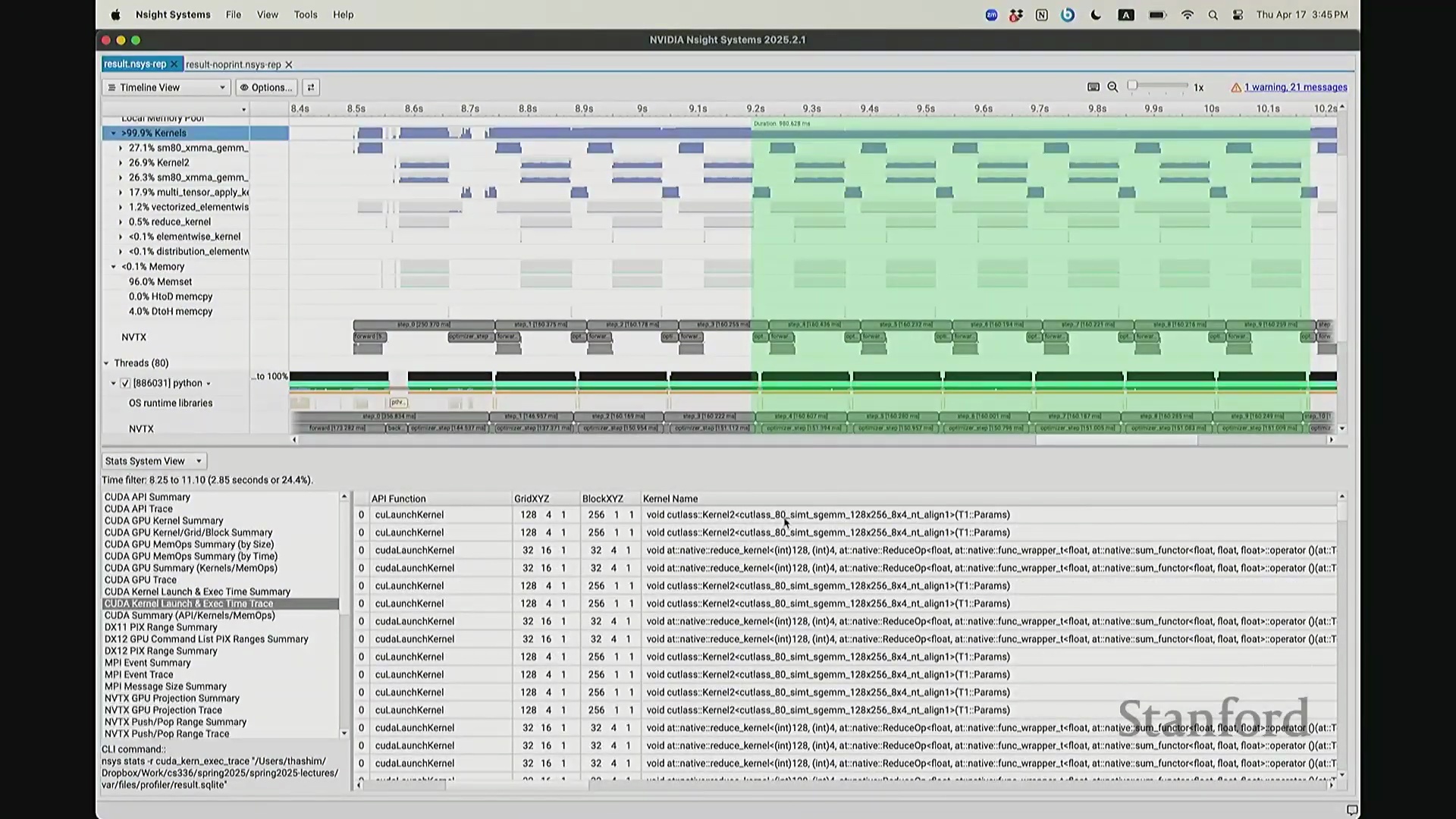
 你们在后续作业中将必须使用此工具——NVIDIA Nsight Systems。这是 NVIDIA 官方提供的深度剖析 GPU 行为与性能的旗舰级工具。借助它,我们将清晰透视运行该 MLP 时,系统底层究竟在发生什么。
你们在后续作业中将必须使用此工具——NVIDIA Nsight Systems。这是 NVIDIA 官方提供的深度剖析 GPU 行为与性能的旗舰级工具。借助它,我们将清晰透视运行该 MLP 时,系统底层究竟在发生什么。
结合 NVTX 标注深入分析与初始化开销
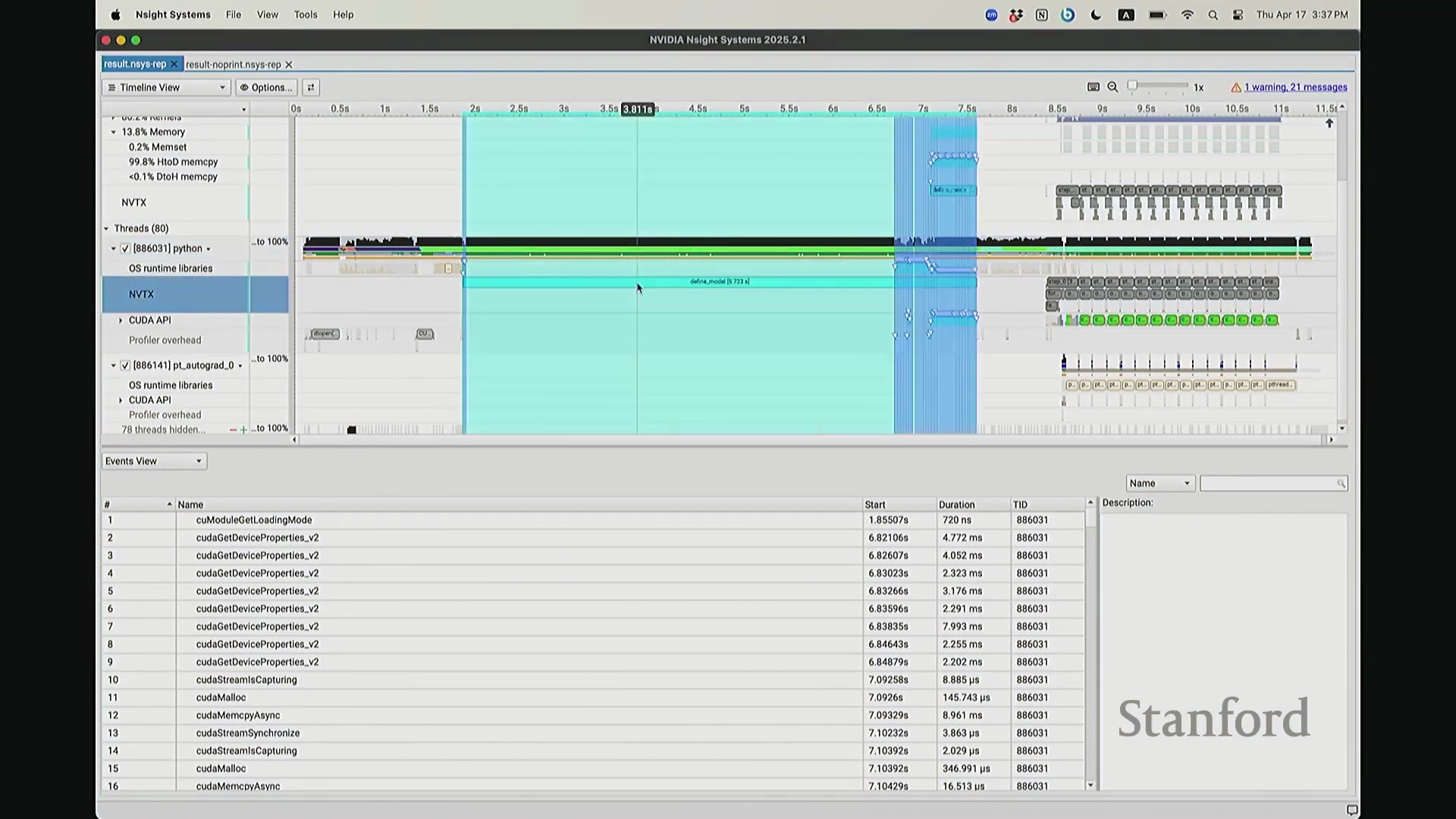
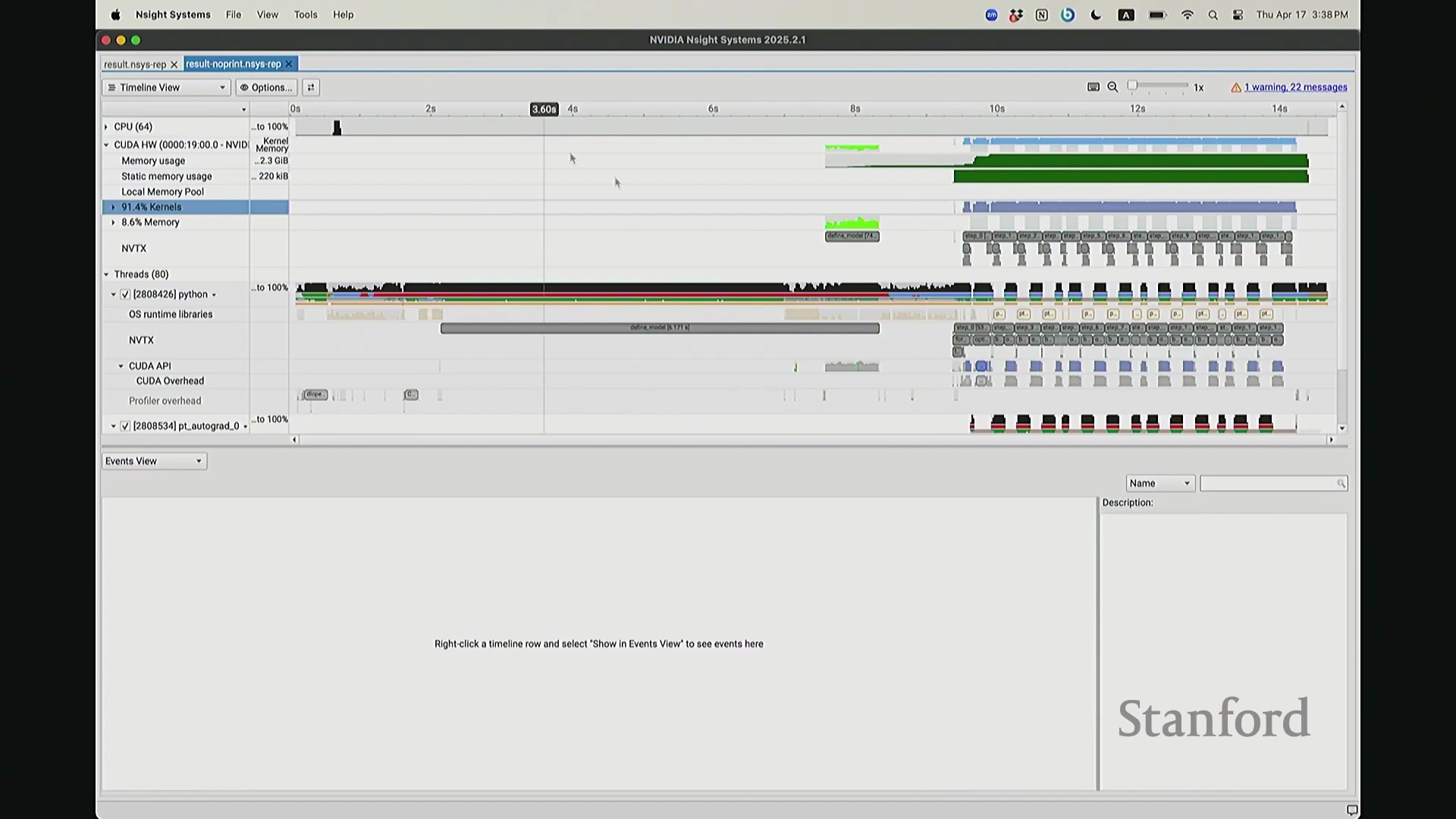
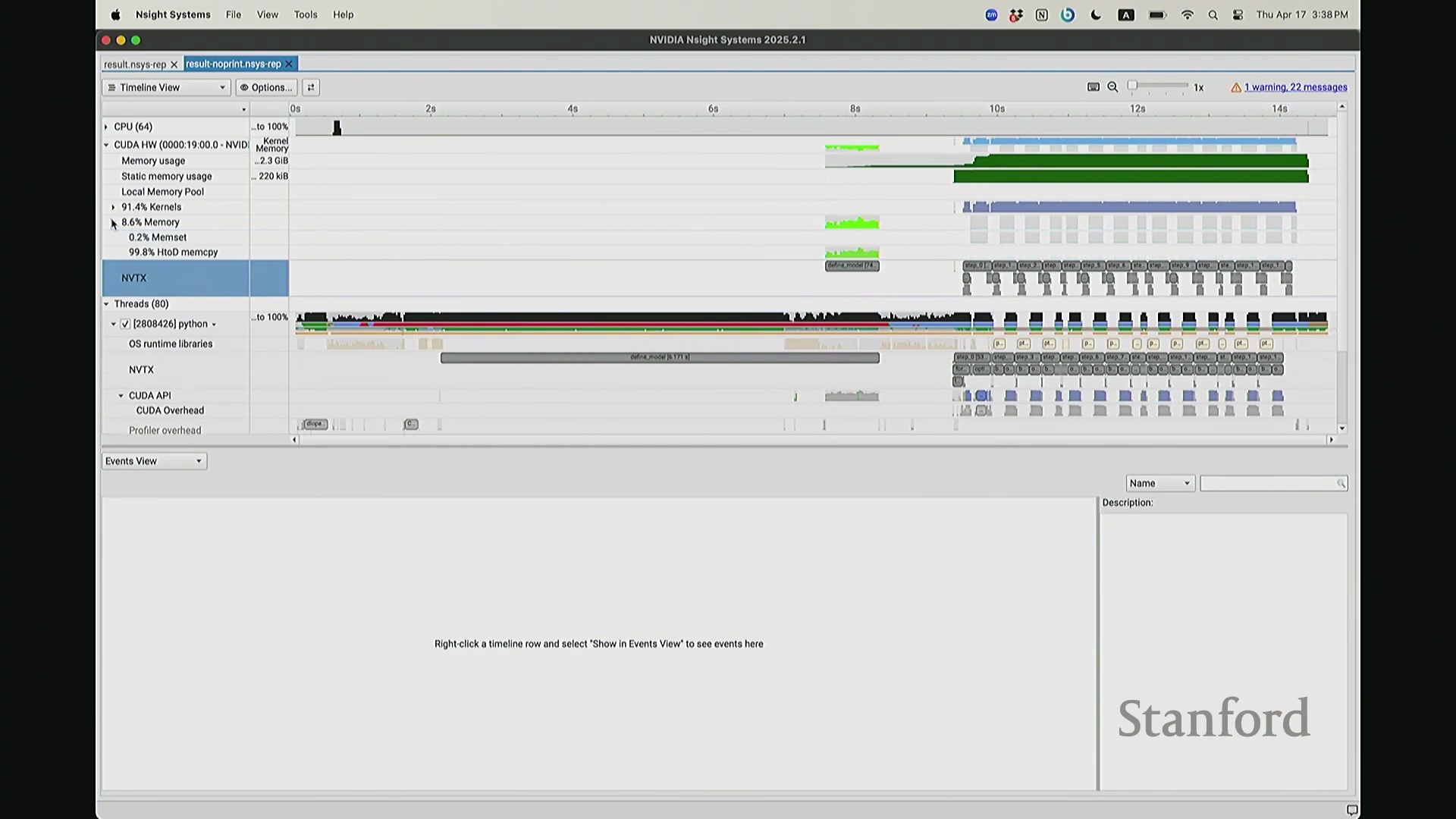
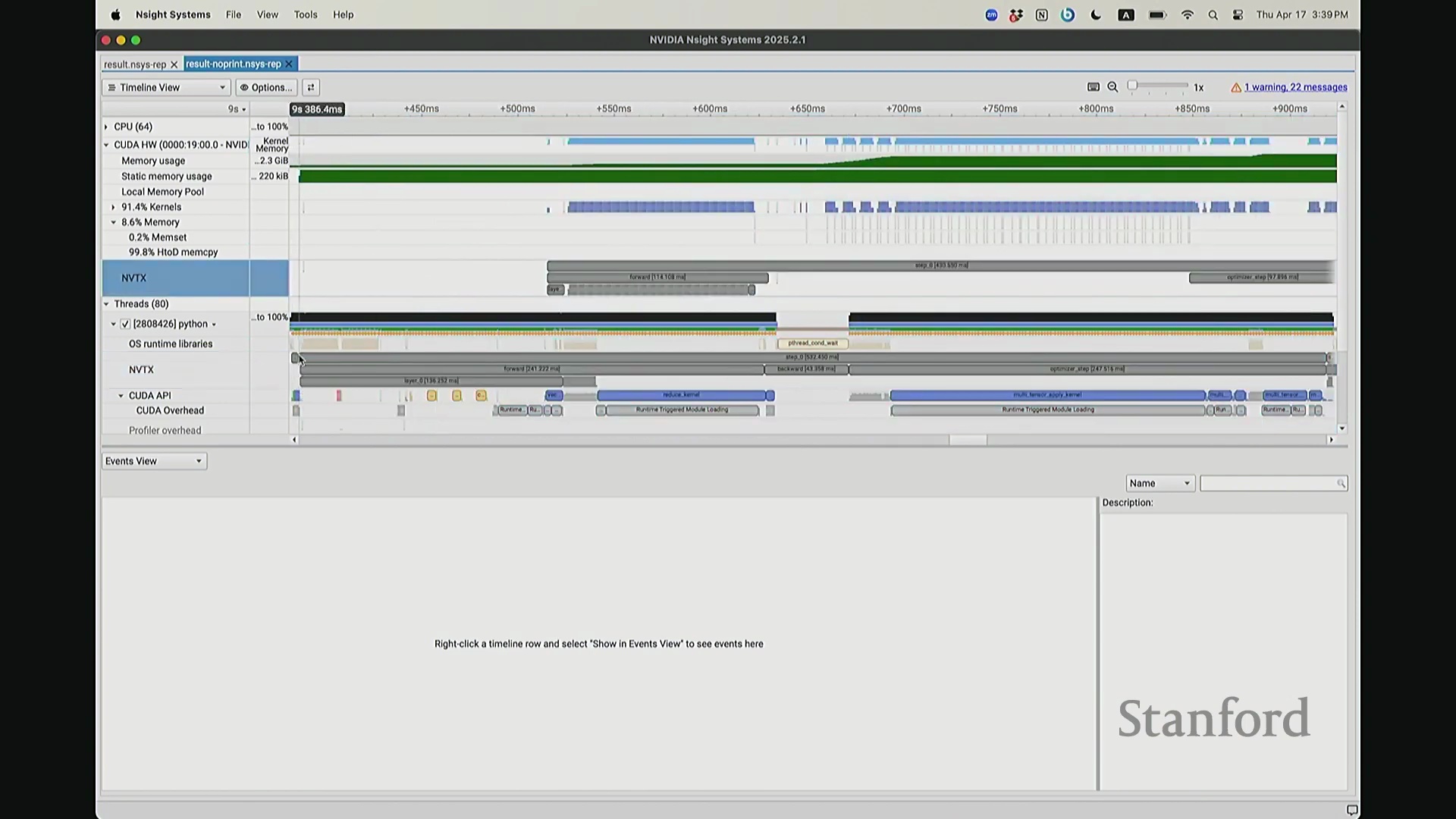
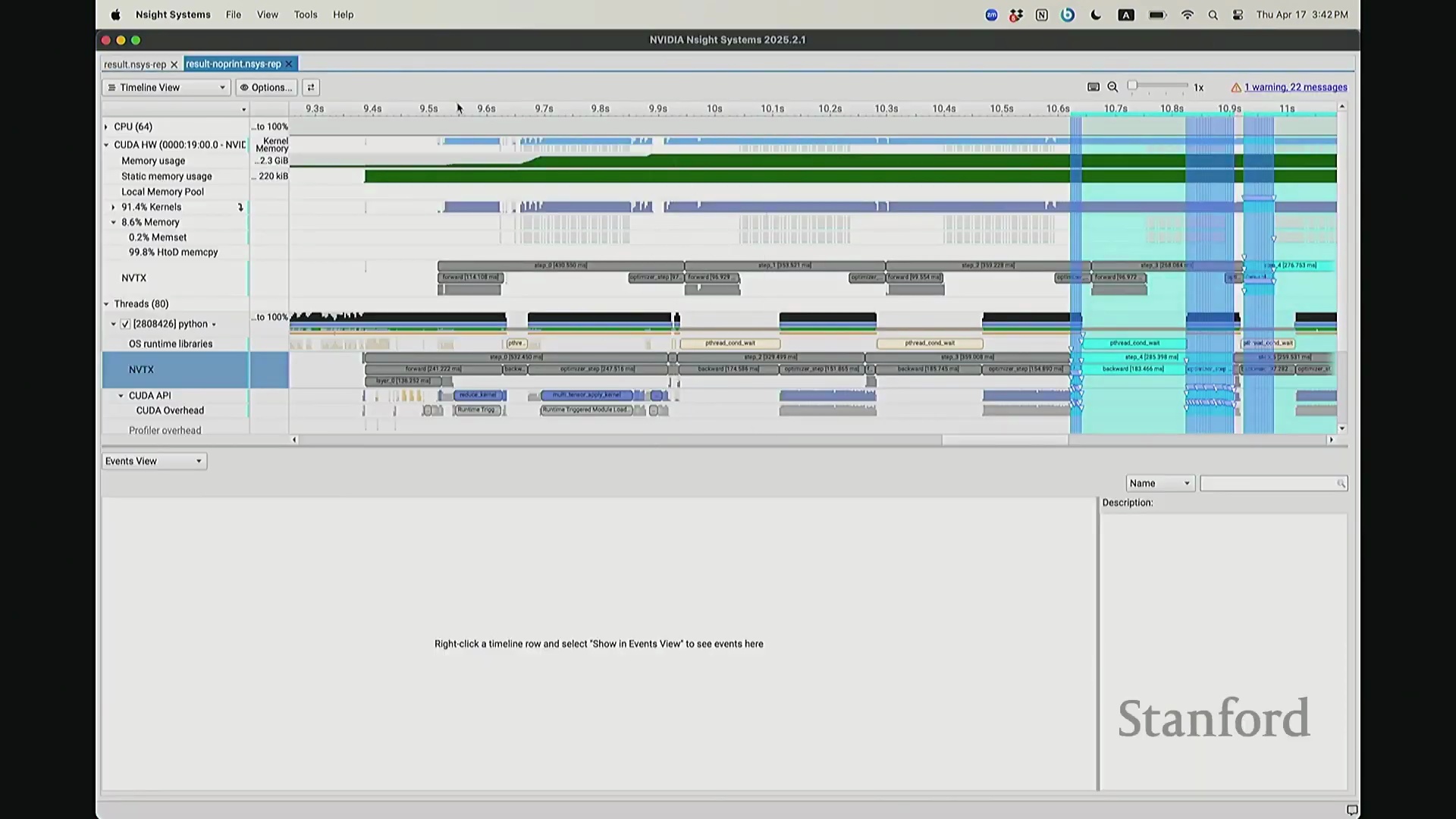
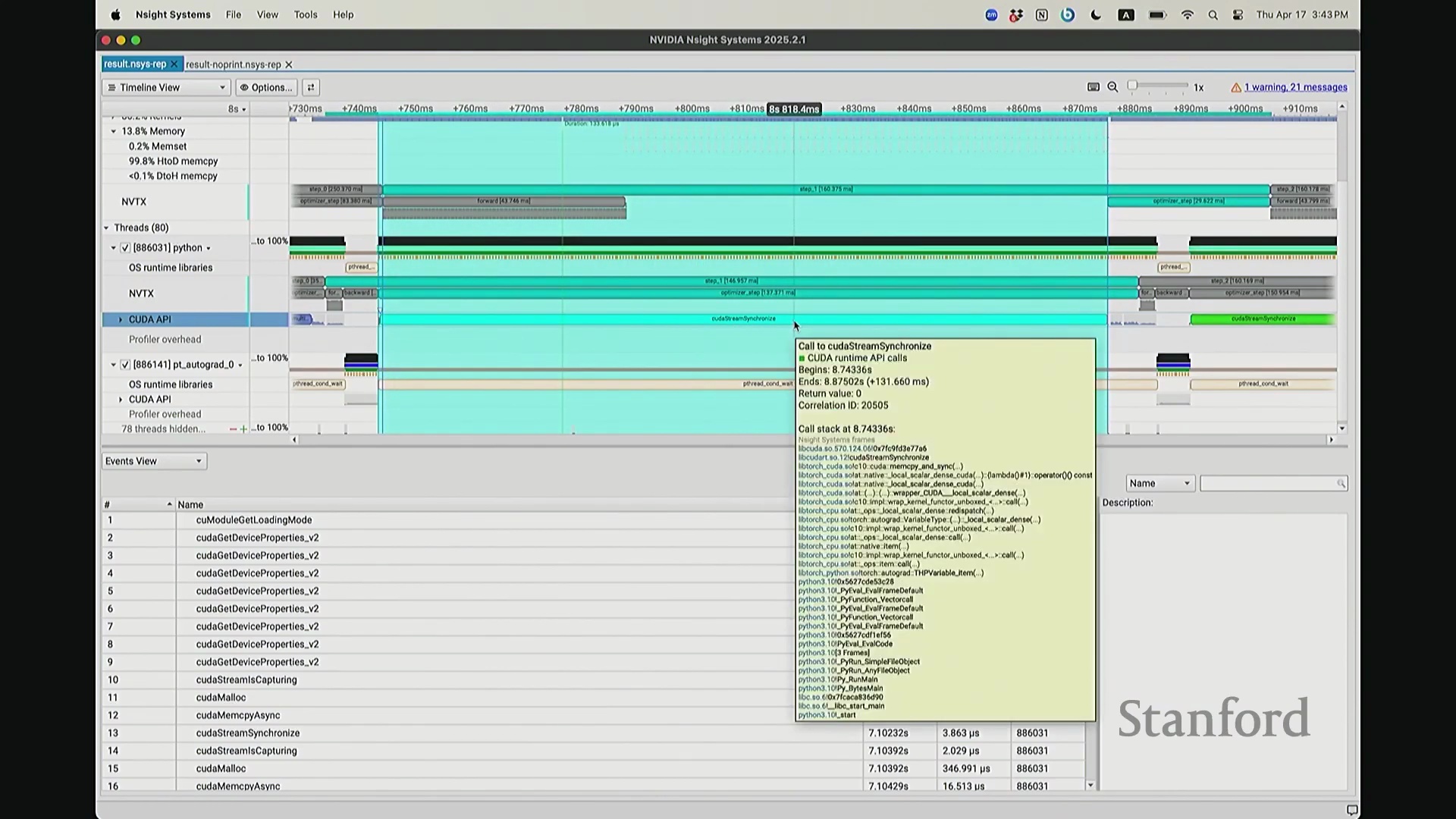
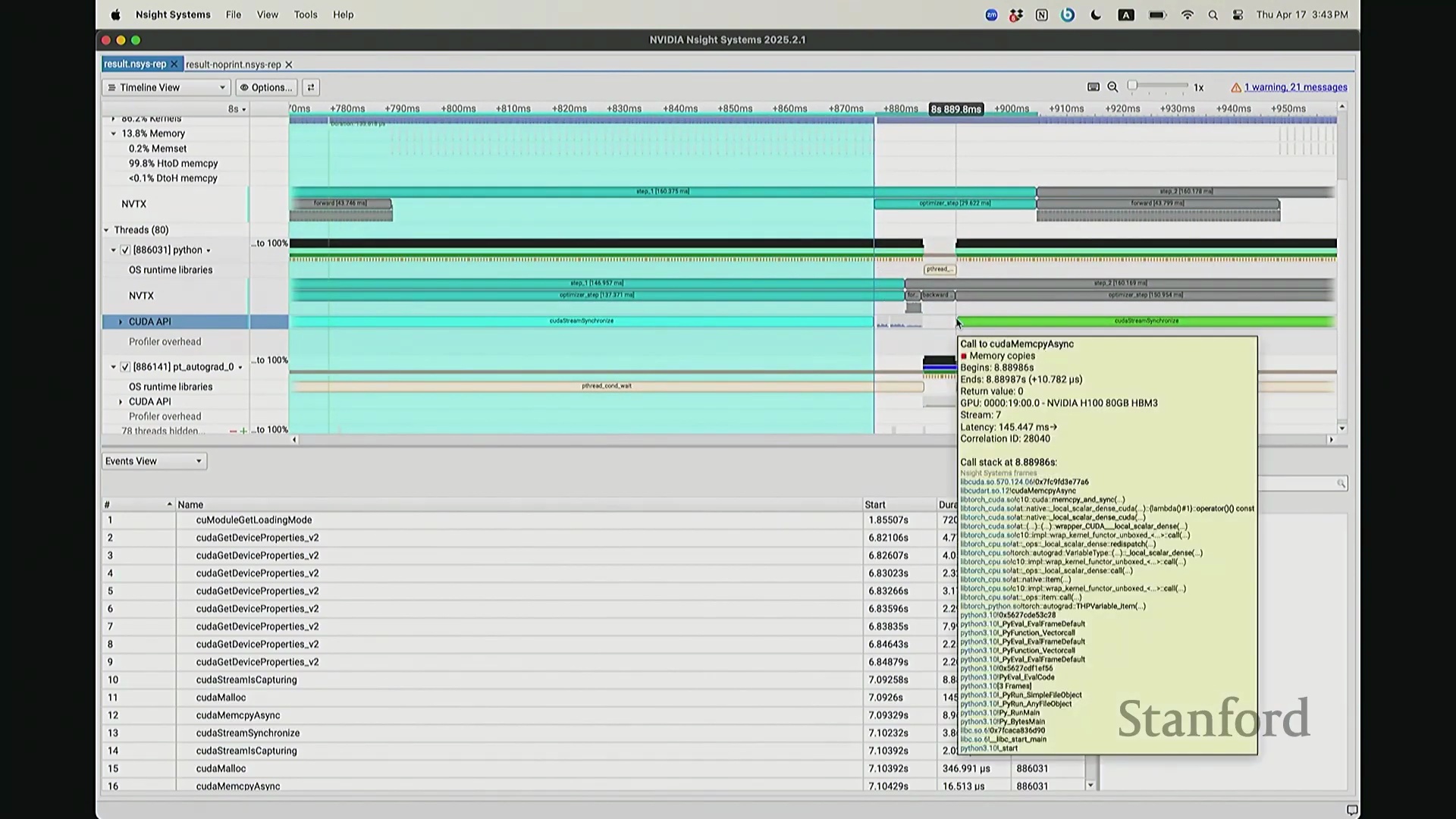
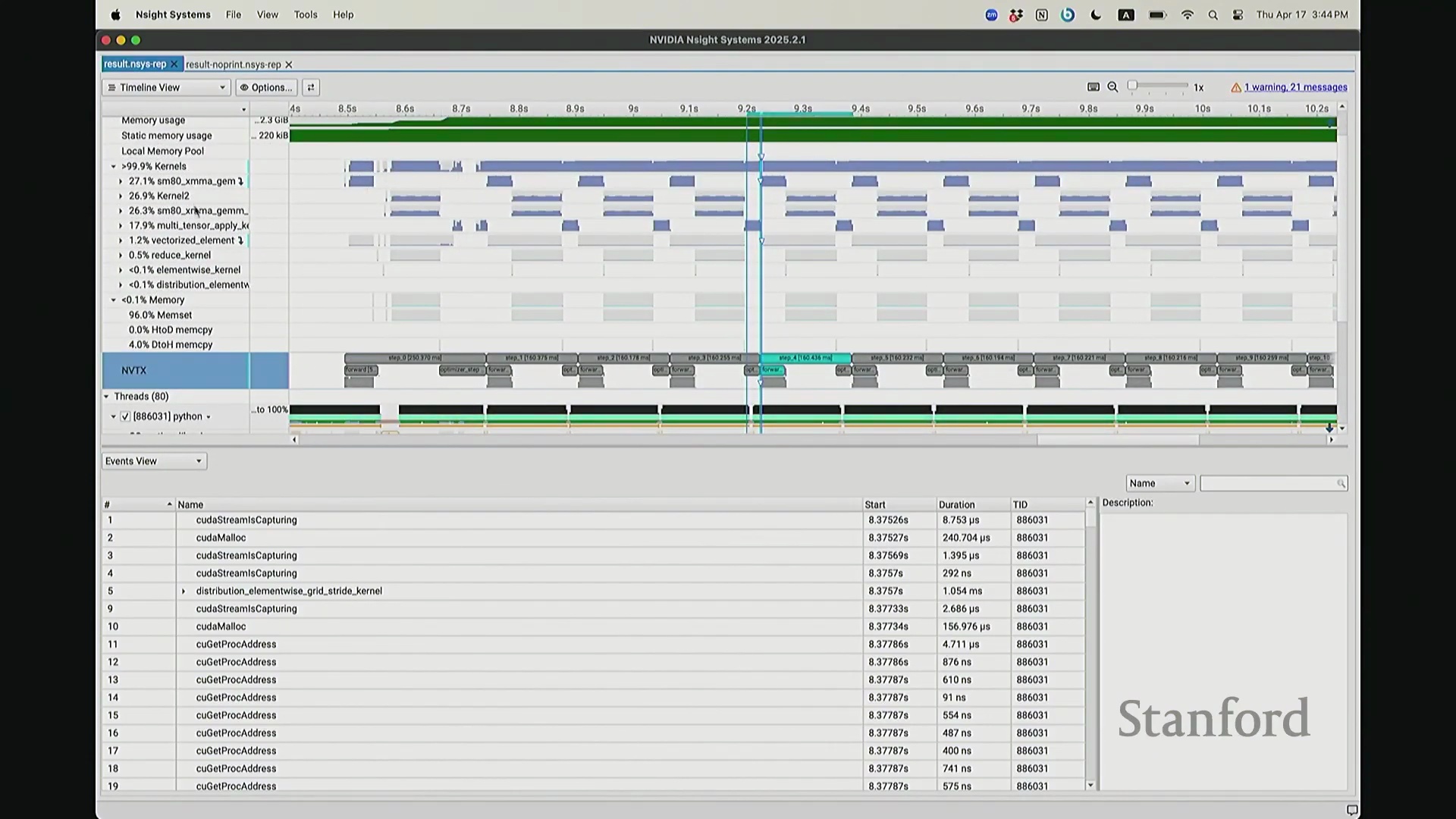
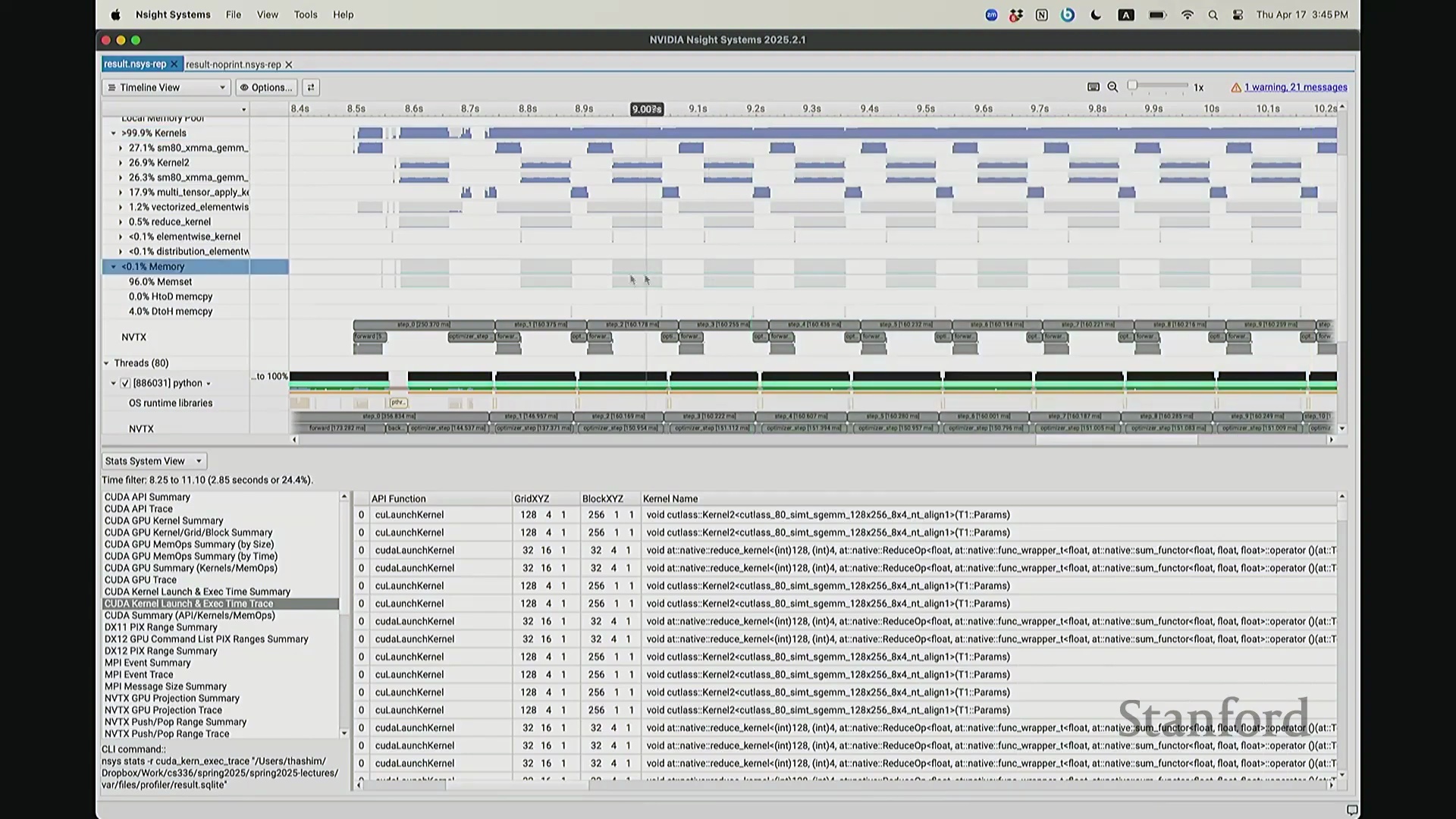
后排的同学能看清这些微小的文本吗?看清的请竖大拇指。好的。既然大家能看清,我就不放大了,尽管缩放后确实显得紧凑。聚焦时间轴,我们会观察到几个核心分区:左侧为 CUDA HW(CUDA 硬件状态),下方为 Threads(CPU 线程活动)。简言之,上半部分直观展示了 GPU 的硬件执行轨迹,而 Threads 区域则记录了 CPU 的线程调度情况。我顺便调出对应源码。是的,在进行性能分析前,我在代码中嵌入了性能标注。这部分必须放大查看。准备就绪,我们开始分析。我在代码中集成了 NVTX(NVIDIA Tools Extension)API 进行范围标记,用以精准划分代码逻辑块。当分析器捕获到这些标记时,便能明确识别该段代码所属的逻辑域。例如,标记 step 配合 range push 与 range pop,将第 55 行至 77 行的代码块标注为一次迭代步骤(step)。在启动分析器前,我已预先植入这些标记。返回分析视图,定位至 NVTX 标记行,可见 Define Model 标签,这对应我封装模型构建的代码段。随后依次排列着 step 0 至 step 5。每个训练步骤均在时间轴上获得清晰标识。随着模型迭代推进,我们可完整追踪其底层行为。从时间轴左侧起始观察,一个显著现象是:该阶段并未执行大量实质计算,仅耗时约 14 秒。实际上,分析器记录的绝大部分初期耗时均消耗于初始化开销(Initialization Overhead)。直至此处,系统主要在执行动态库加载等准备工作,耗时长达 7.5 秒。换言之,程序运行至 7.5 秒左右时,GPU 才真正开始构建模型。大家可在此处观察到显存占用(Memory Footprint)曲线开始攀升,表明 GPU 显存分配正式启动。模型构建完毕后,step 0 标志着实际数值计算的开始。
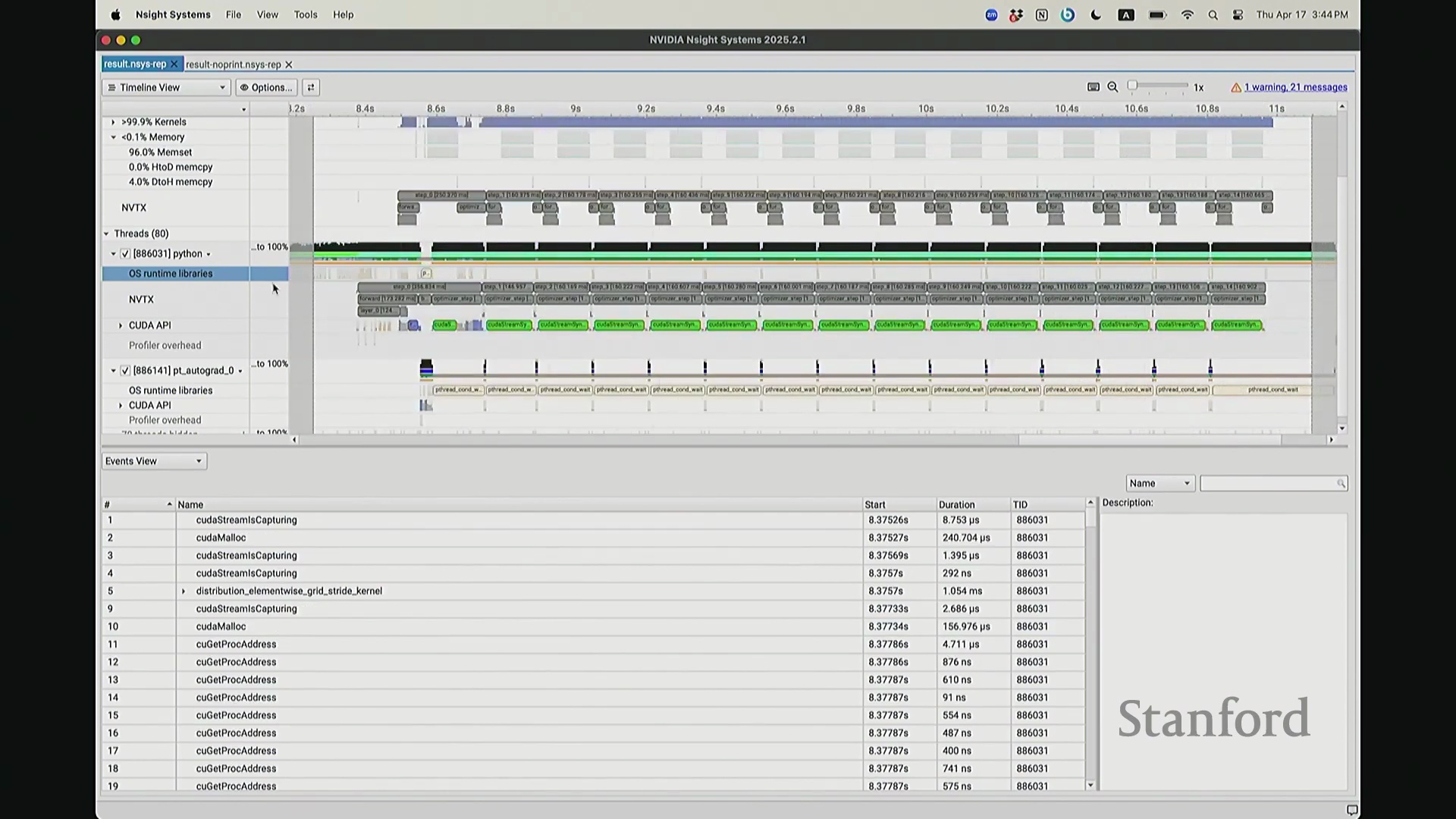
CPU 与 GPU 执行模型及异步命令排队
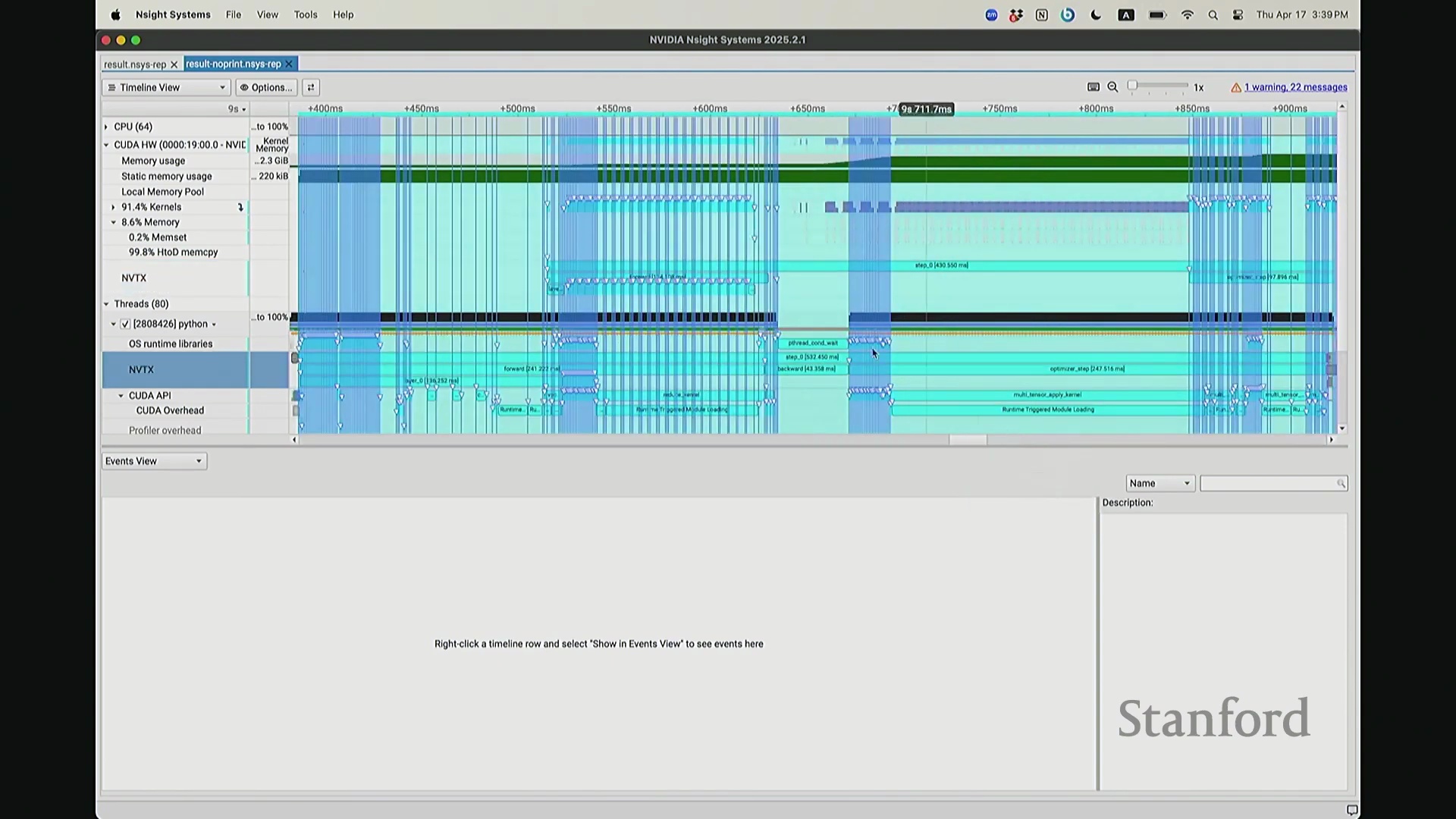
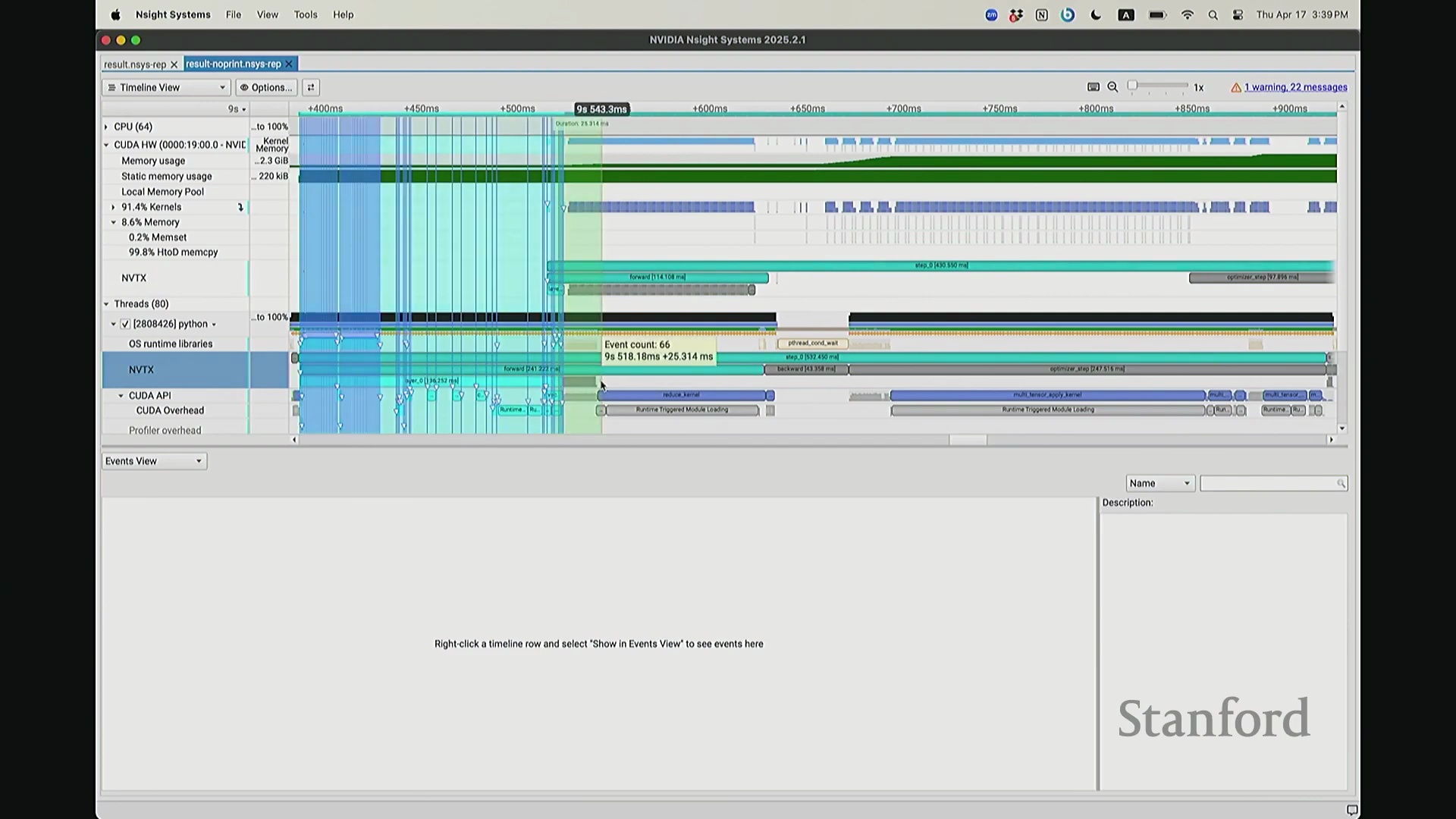
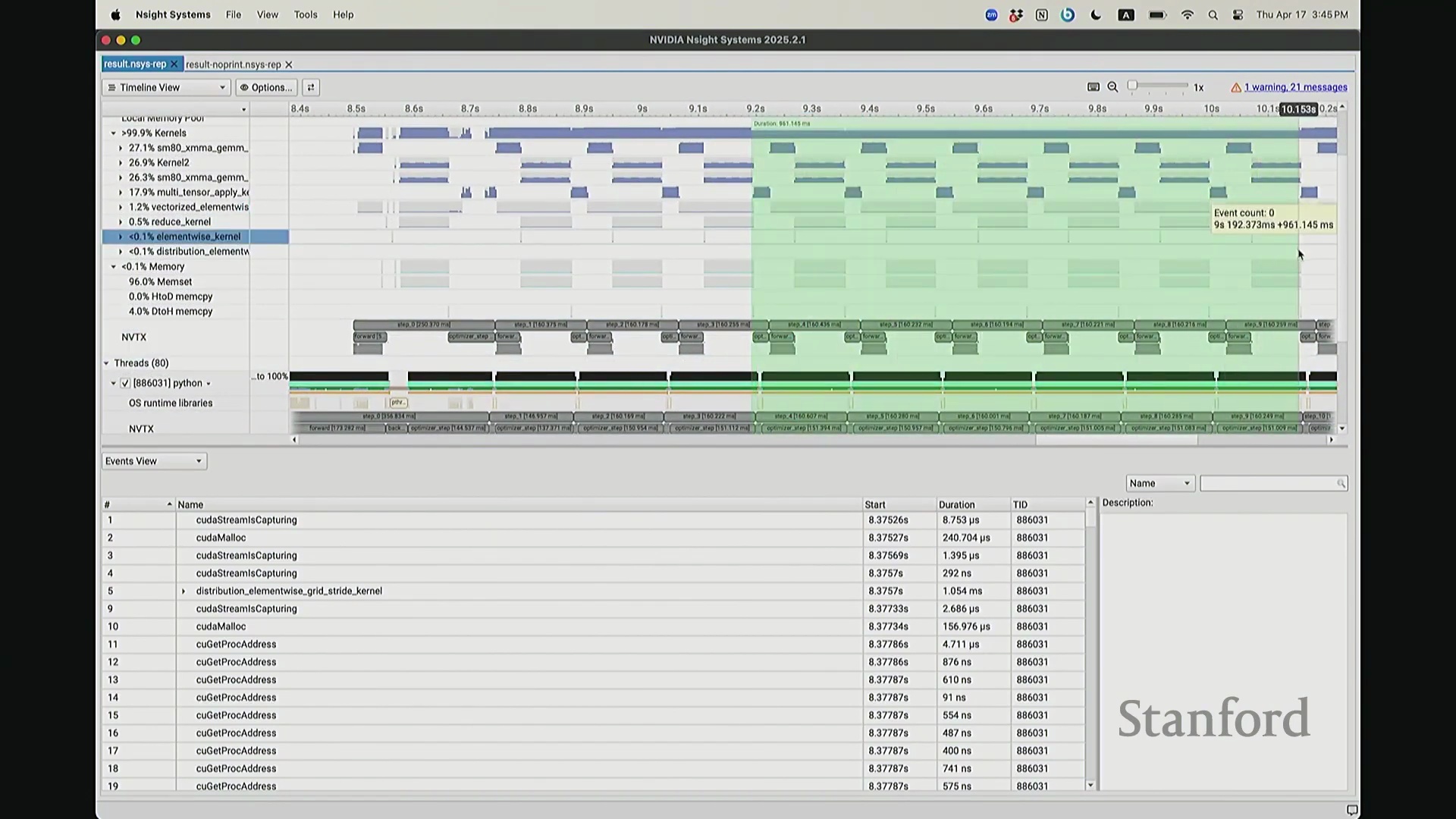
回到之前关于“CPU 与 GPU 交互机制”的提问。其执行模型(Execution Model)的工作原理如下:聚焦 CPU 端的 step 0 起始位置,此处为前向传播,对应网络第 0 层。让我们梳理执行流:如前所述,首次在 PyTorch 中调用算子时,代码并非立即执行,而是触发即时编译(Just-In-Time Compilation)等预处理。因此,runtime trigger(运行时触发)与 module loading(模块加载)等操作,均属于初始化层结构、编译计算图并将相关内核传输至 GPU 的固有开销,这解释了初期的漫长等待。待 layer 0 初始化完成后,我们选取任意时间切片并放大观察。可见每一层的实际计算耗时极短。此处的关键现象在于异步执行机制:当我高亮 CPU 线程的 layer 1 处理阶段时,请注意 GPU 硬件时间轴上,layer 1 的计算并未在同一时刻对齐。CPU 与 GPU 是独立的并行计算设备。CPU 完成 layer 0 的调度后进入 layer 1,此时它并非等待 GPU 计算完毕,而是在批量向 GPU 命令队列(Command Queue)中提交后续 CUDA 内核的启动(Kernel Launch)请求。换言之,当 CPU 显示正在处理 layer 1 时,它实质上在向 GPU 派发任务指令:“执行下一个内核,继续下一个”。因此,CPU 的调度进度大幅领先于 GPU 的实际计算进度。当 GPU 真正开始执行 layer 1 时,CPU 的调度指针可能已推进至 layer 9。CPU 通过维护命令队列持续超前下发任务,直至队列达到容量上限才会产生背压(Backpressure)暂停下发。在此示例中,这种超前调度表现得尤为显著(让我缩小视图……抱歉无法撤销放大)。拉远视角后可见,在多个训练步骤中,CPU 调度极度超前:step 0 的 CPU 调度在此,step 2 的调度已紧随其后。step 1 的 CPU 调度几乎瞬间完成。可见,CPU 的调度进度已整体超前 GPU 整整一个前向-反向传播周期。
CPU-GPU 同步带来的性能损耗
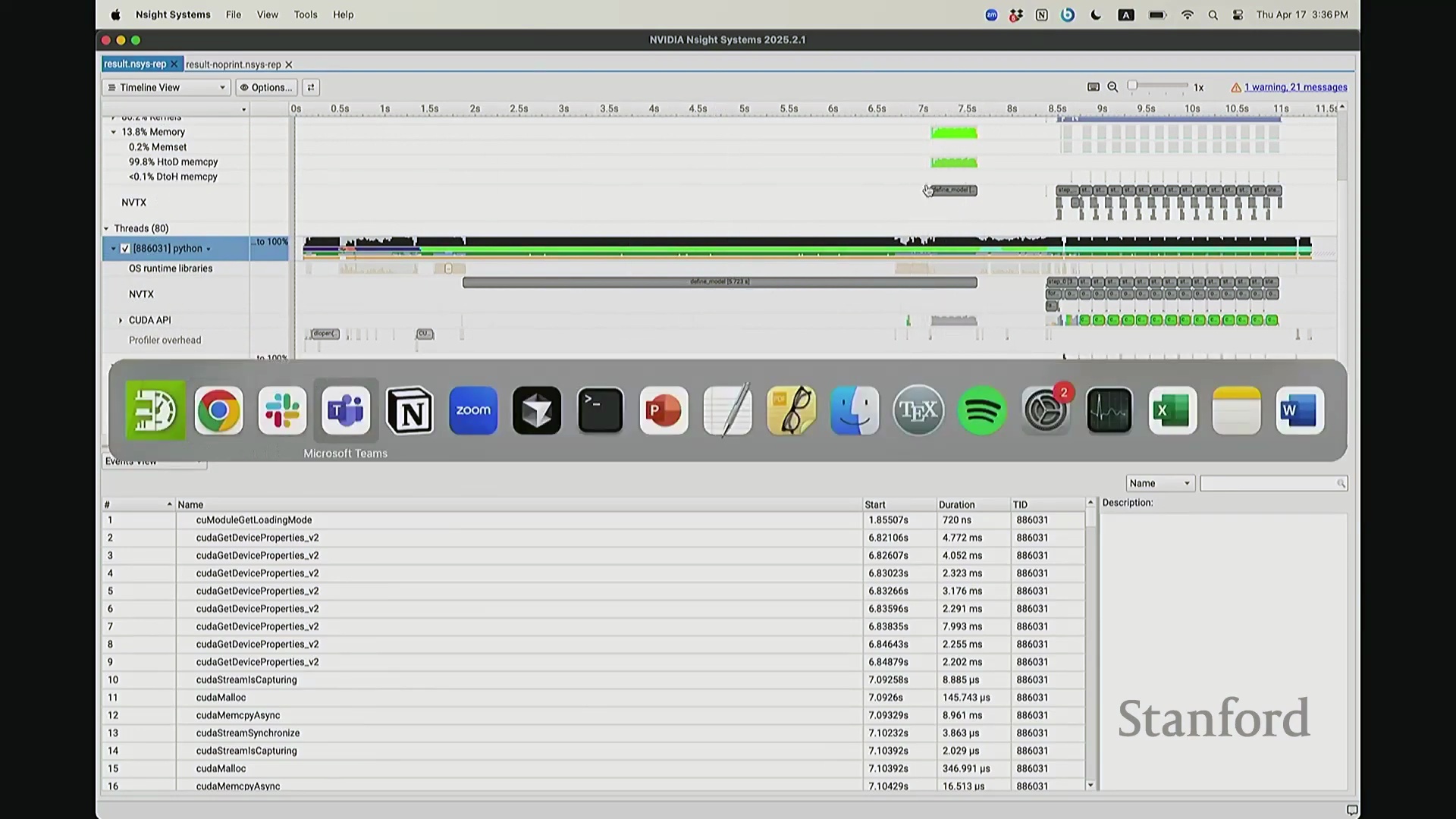
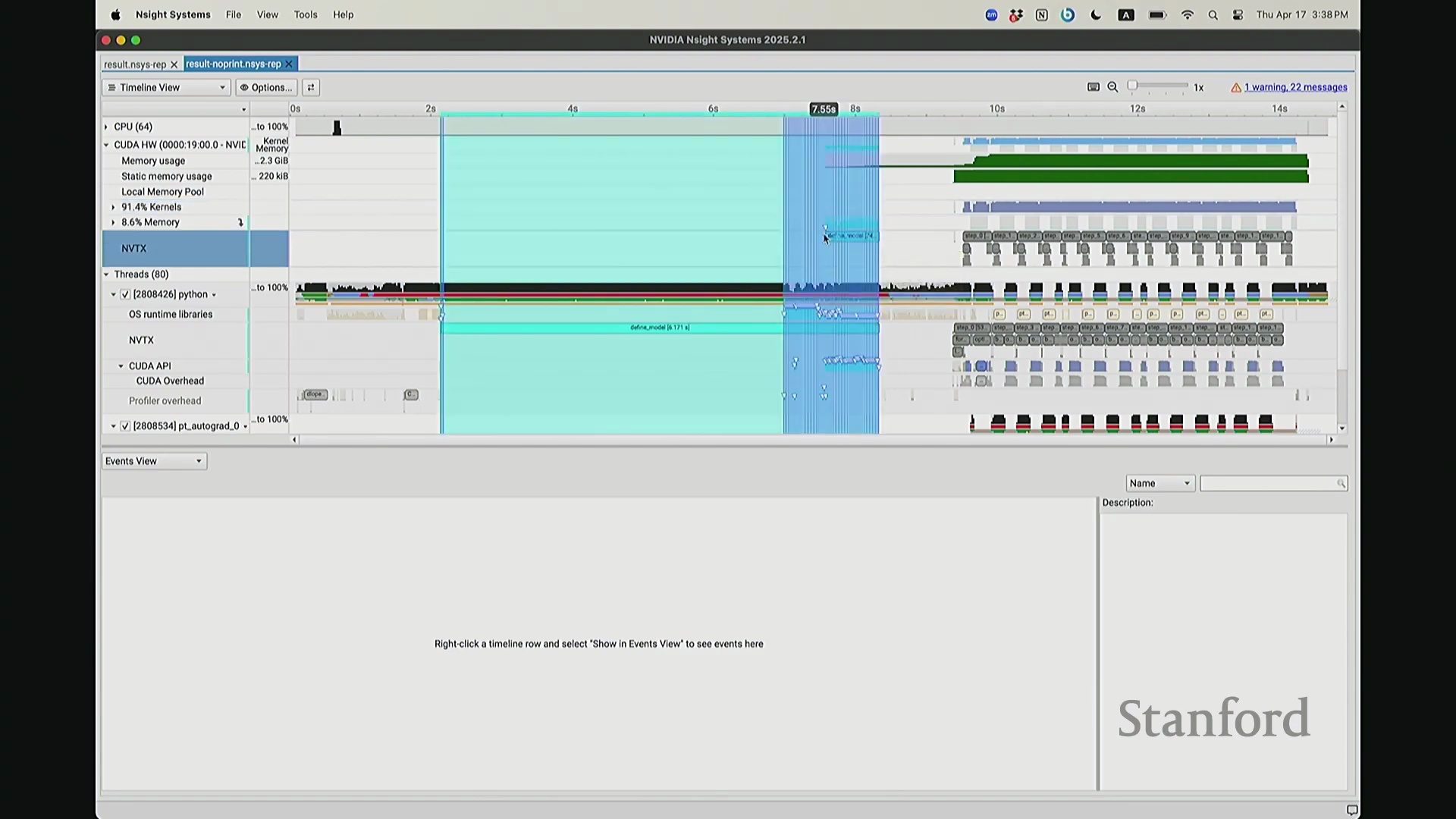
现在考虑一个常见但易被忽视的优化陷阱。在训练语言模型时,开发者常在迭代间隙插入打印损失值(Print Loss)的代码以监控训练状态。直观上,这似乎不会对 GPU 计算产生干扰。你可能会想:“不过是一句打印语句,能有多大影响?”但深入分析其执行机制便会发现,此举将对 GPU 的执行时间线(Timeline)造成显著影响。因为 print 语句运行于 CPU 端,而 CPU 必须先获取损失值才能执行打印。这意味着 CPU 必须强制等待 GPU 完成对应的前向计算并返回结果,从而触发隐式的 CPU-GPU 同步(CPU-GPU Synchronization)。让我们观察其实际影响:如前所述,在无 print 语句时,CPU 端的 step 4 调度远早于 GPU 端的实际执行。现在切换至添加了 print 语句的版本进行分析。放大该时间片段后可见……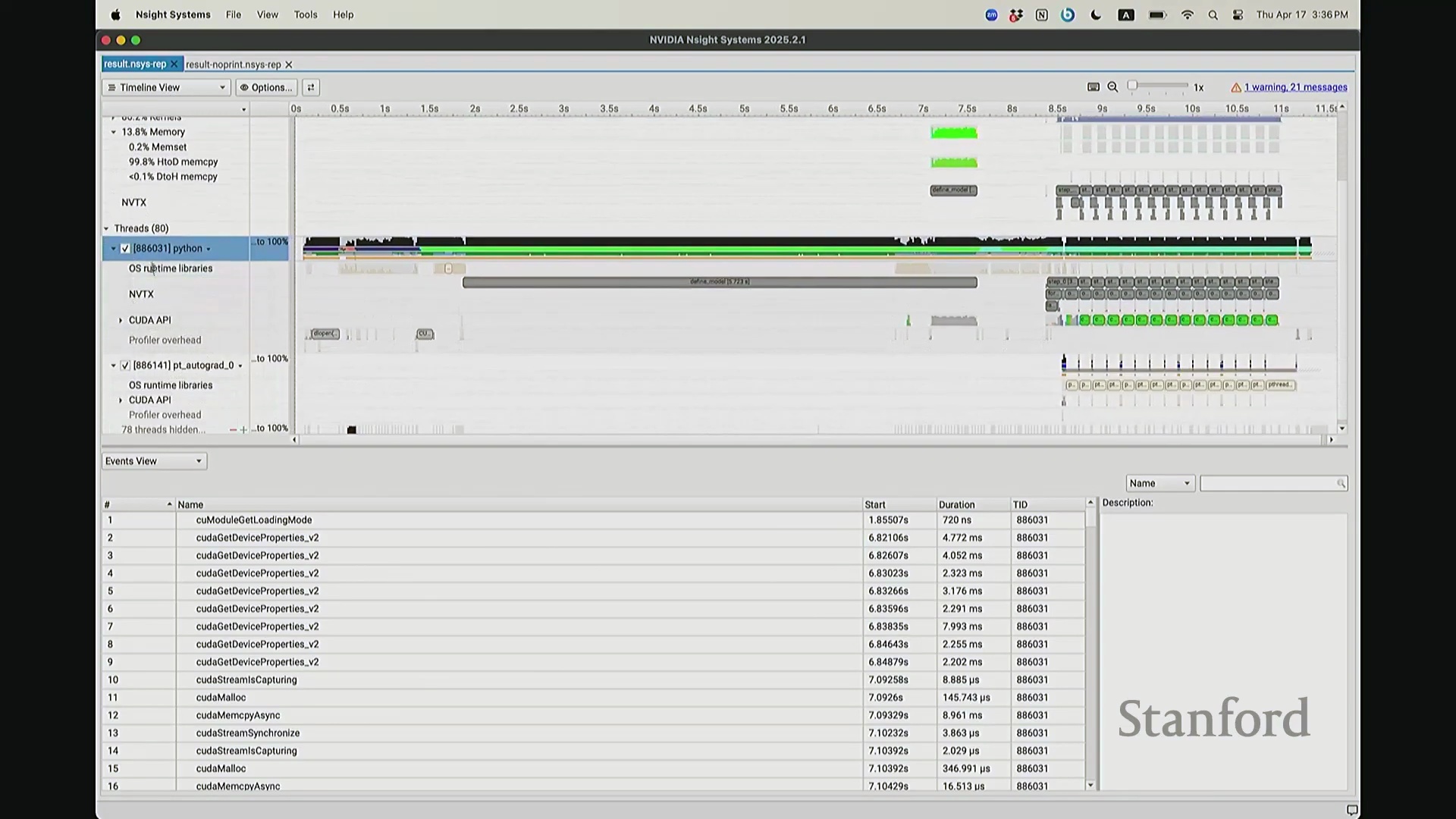
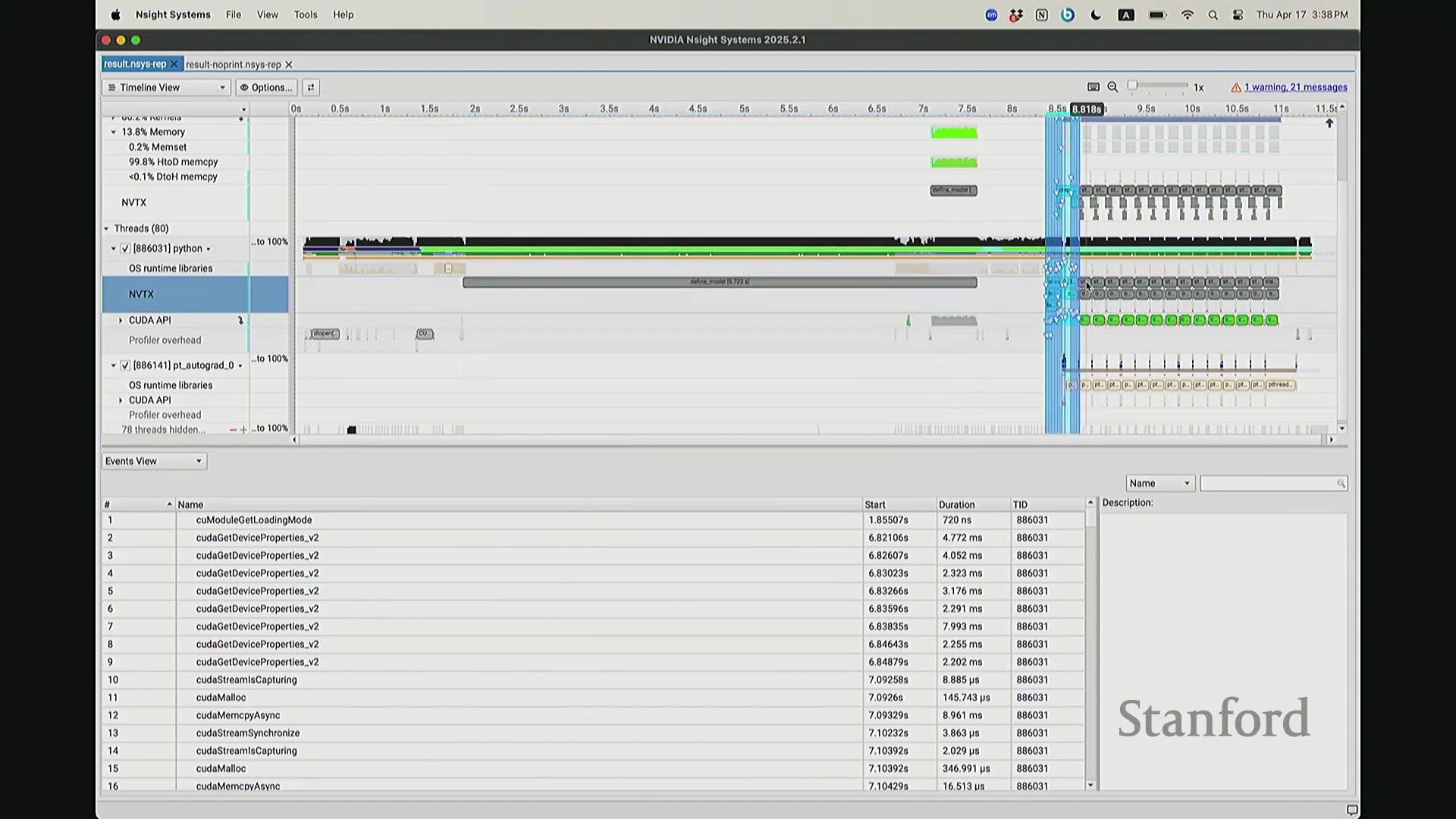
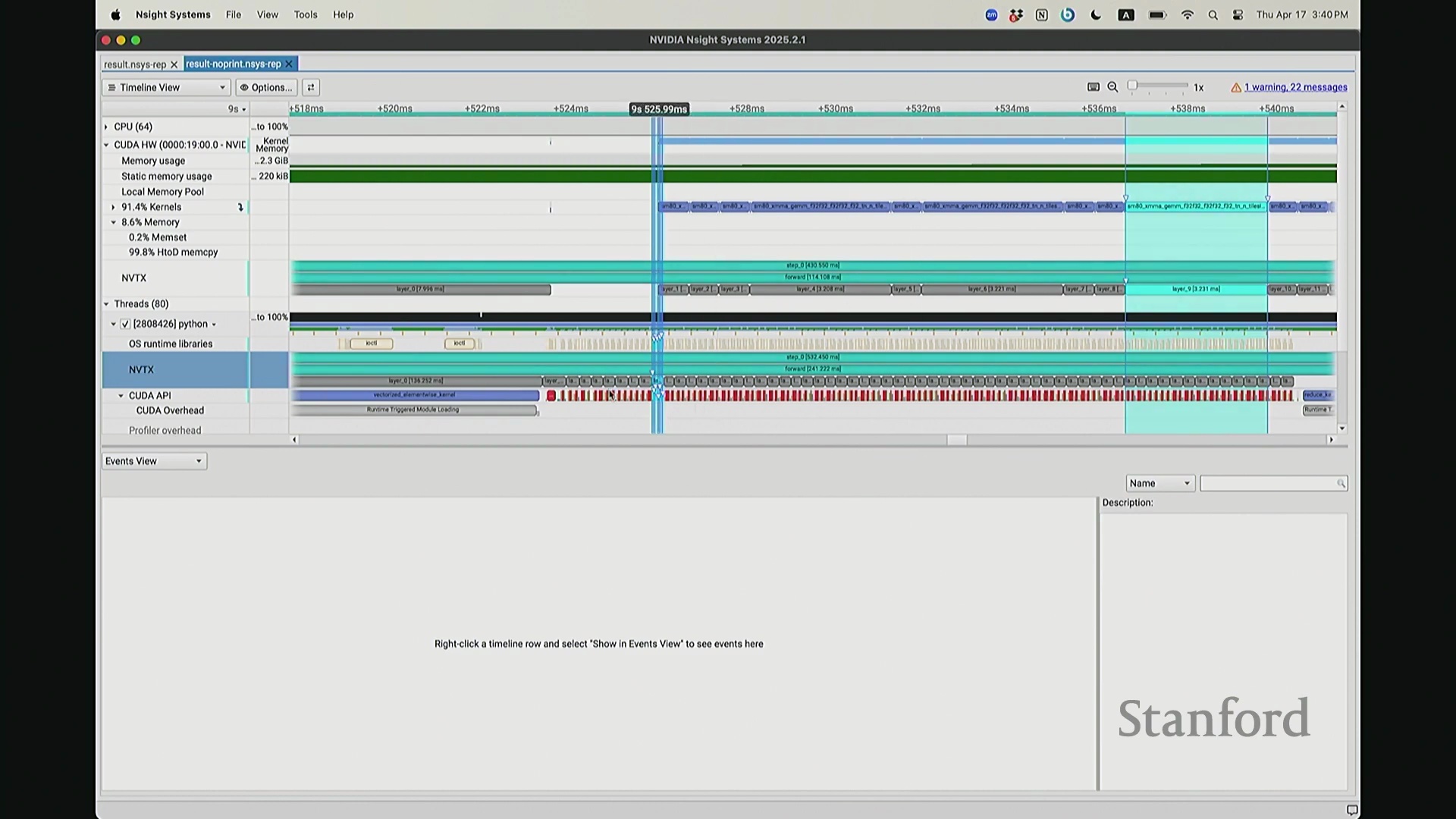
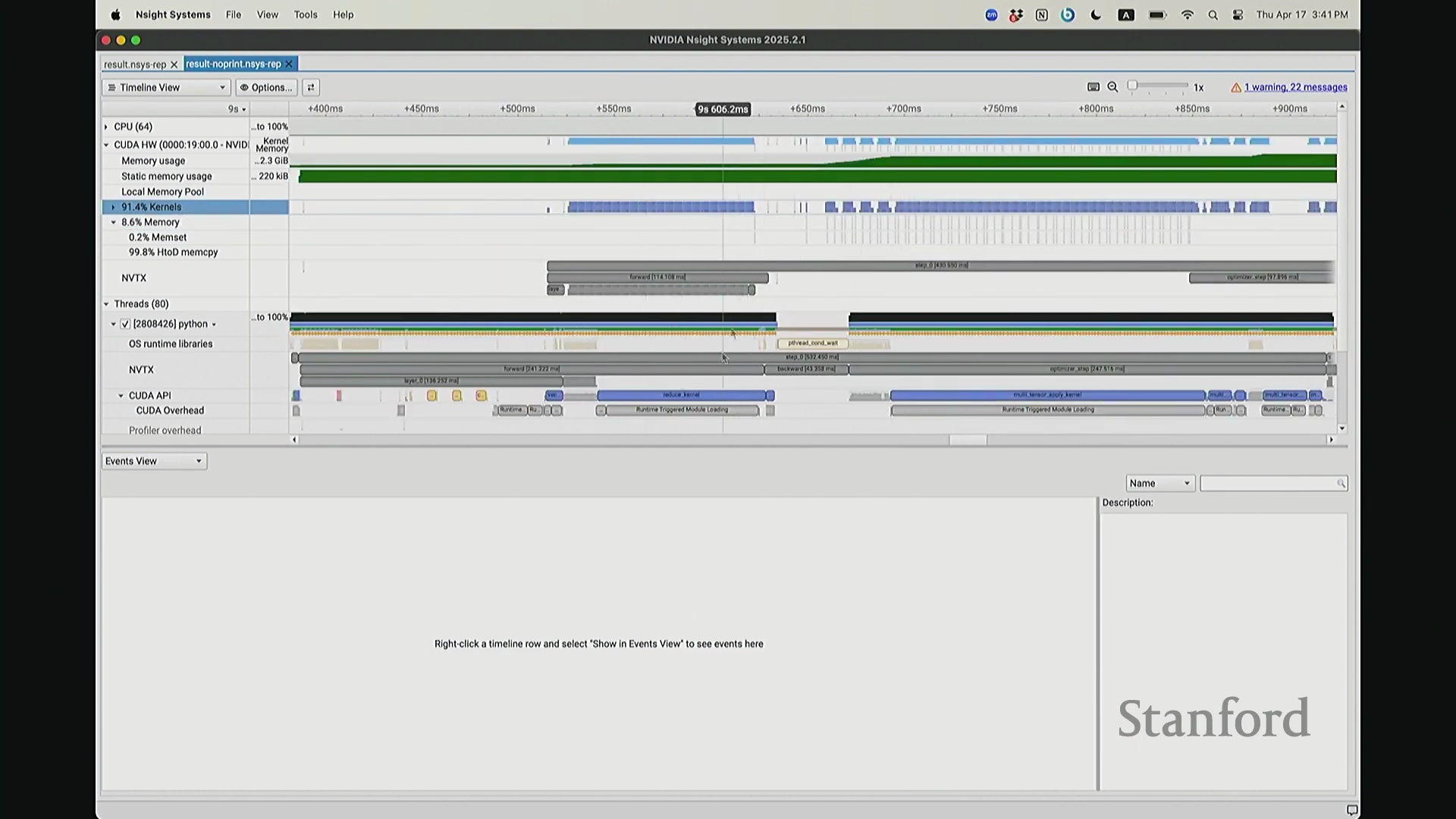
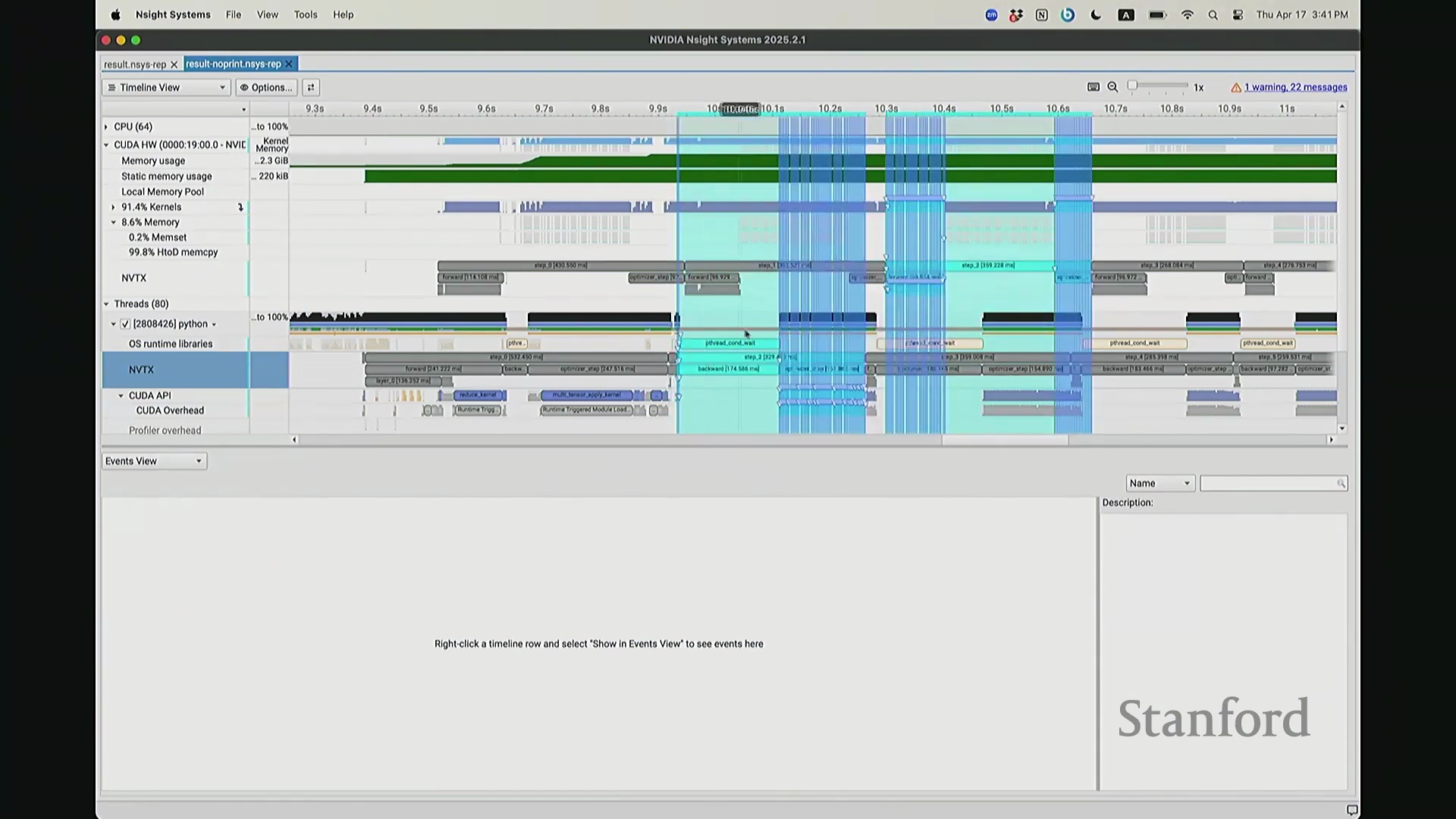
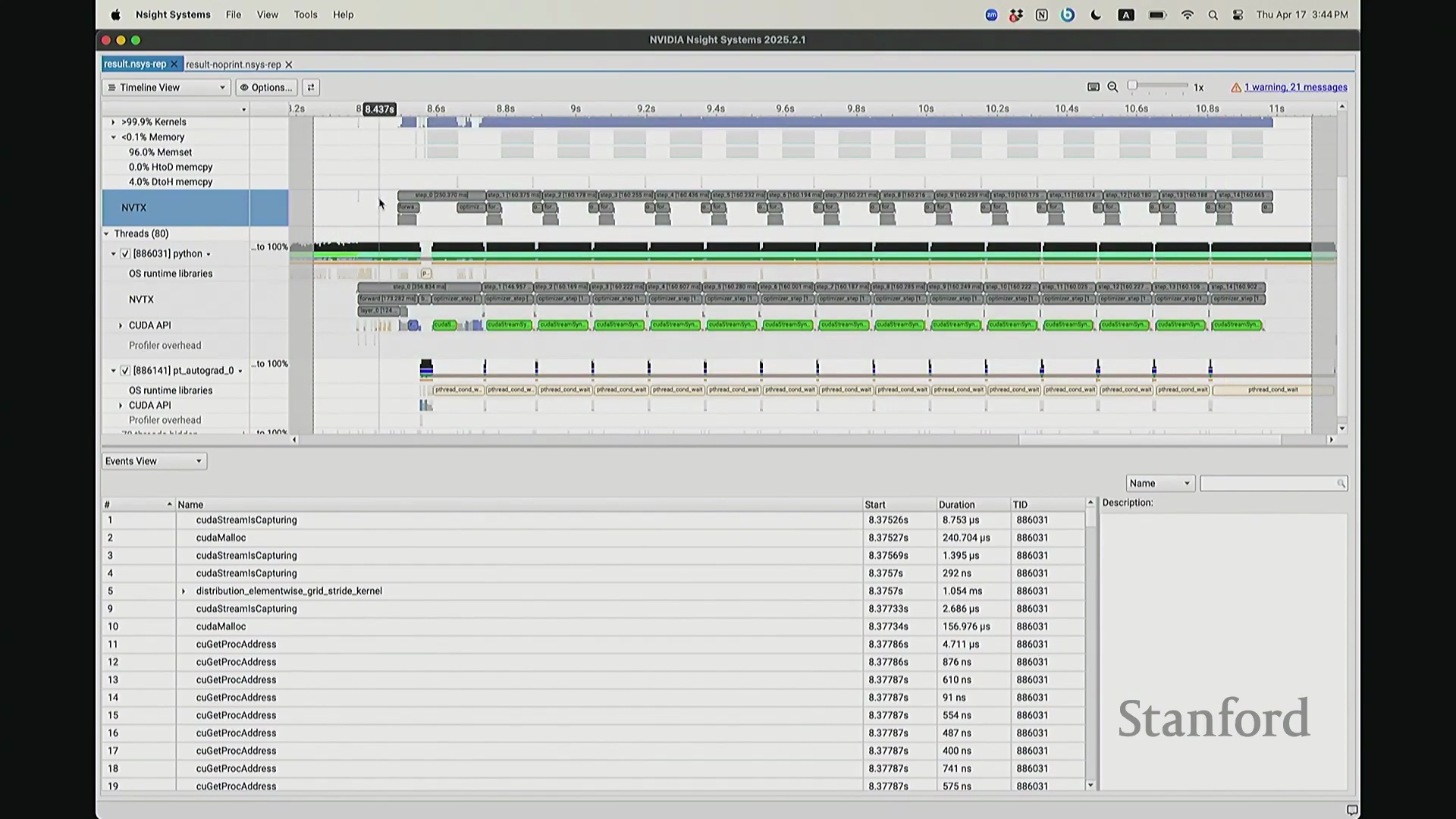
CPU-GPU 同步与执行开销
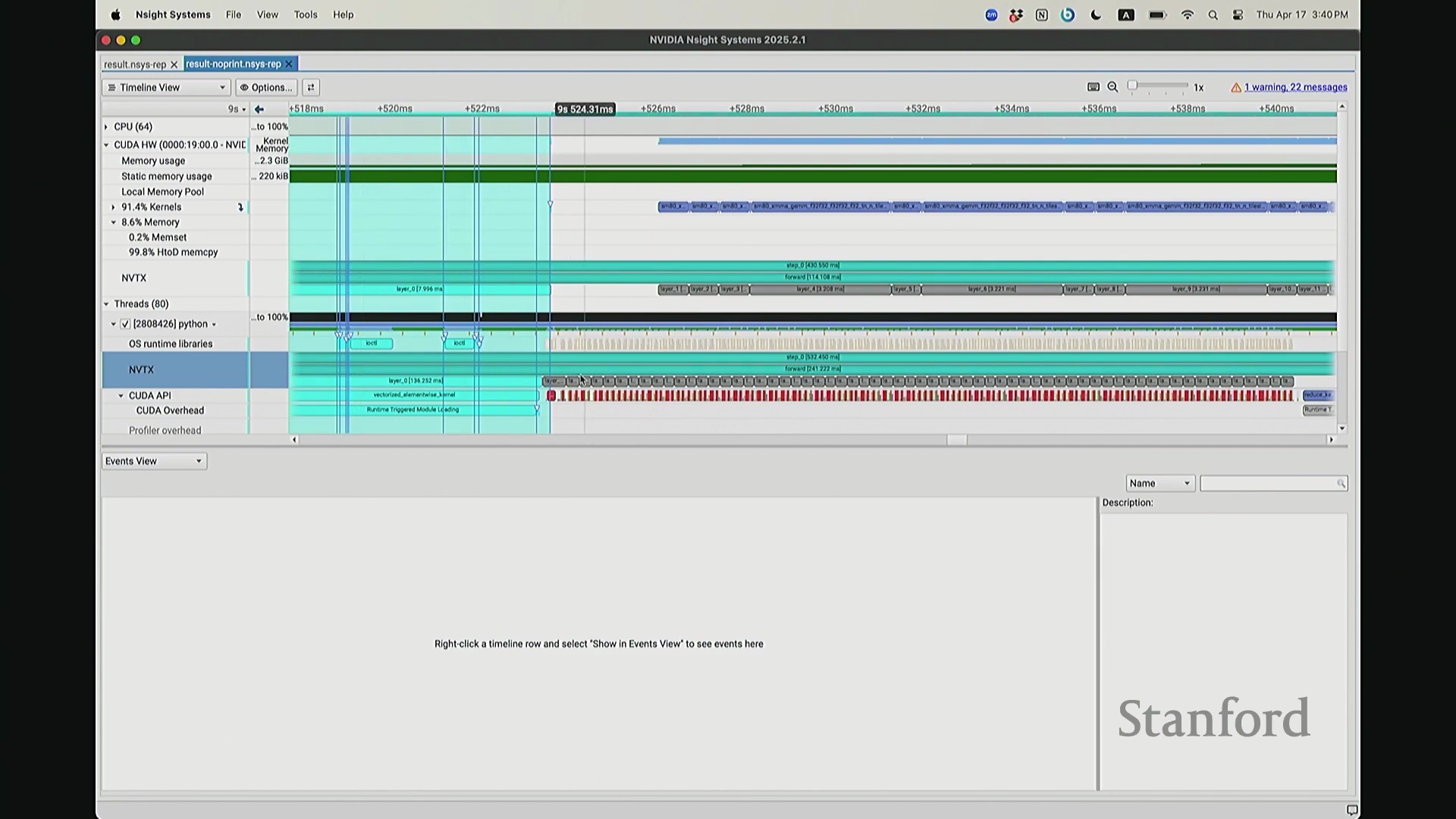
现在可以看到,step 1 和 step 2 的执行进度已经基本同步,对吧?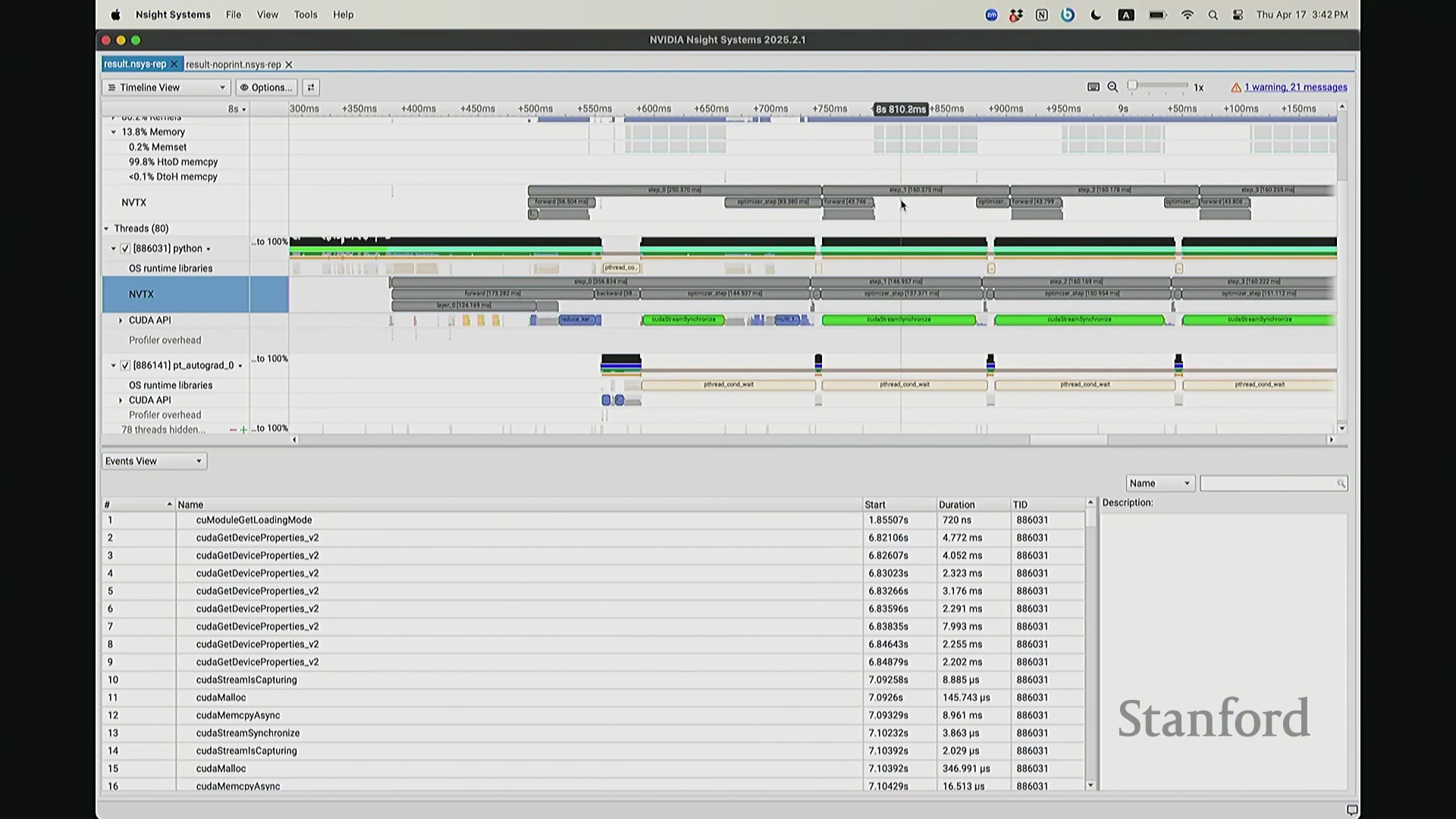 因为 CPU 必须等待损失值(Loss)计算完成。你可能会注意到时间轴上仍存在细微偏移,例如
因为 CPU 必须等待损失值(Loss)计算完成。你可能会注意到时间轴上仍存在细微偏移,例如 step 2 和 step 1 并未完全对齐。现在让我们放大视图,仔细观察 CPU 在 step 1 期间究竟发生了什么?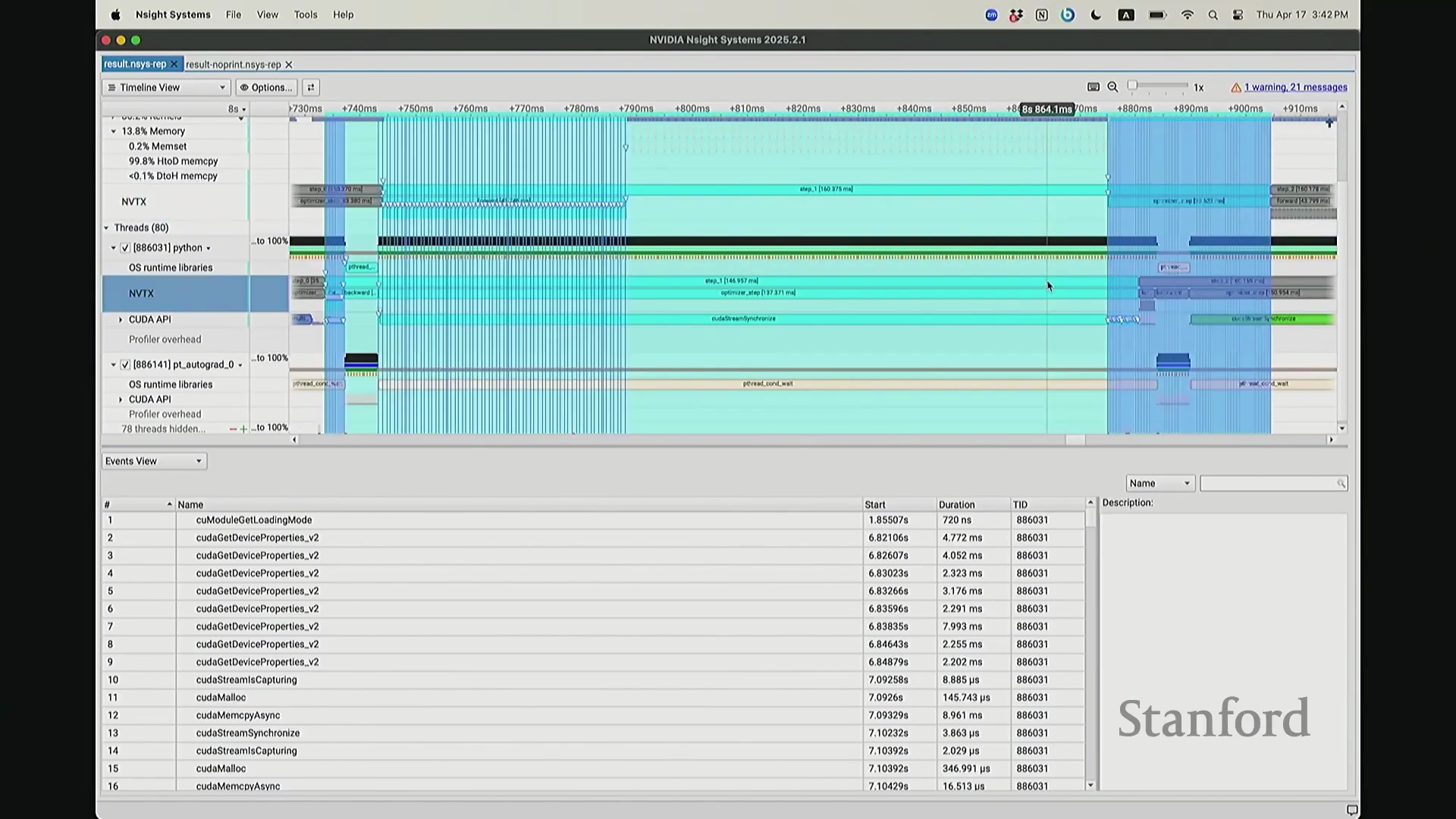 实际上,CPU 端
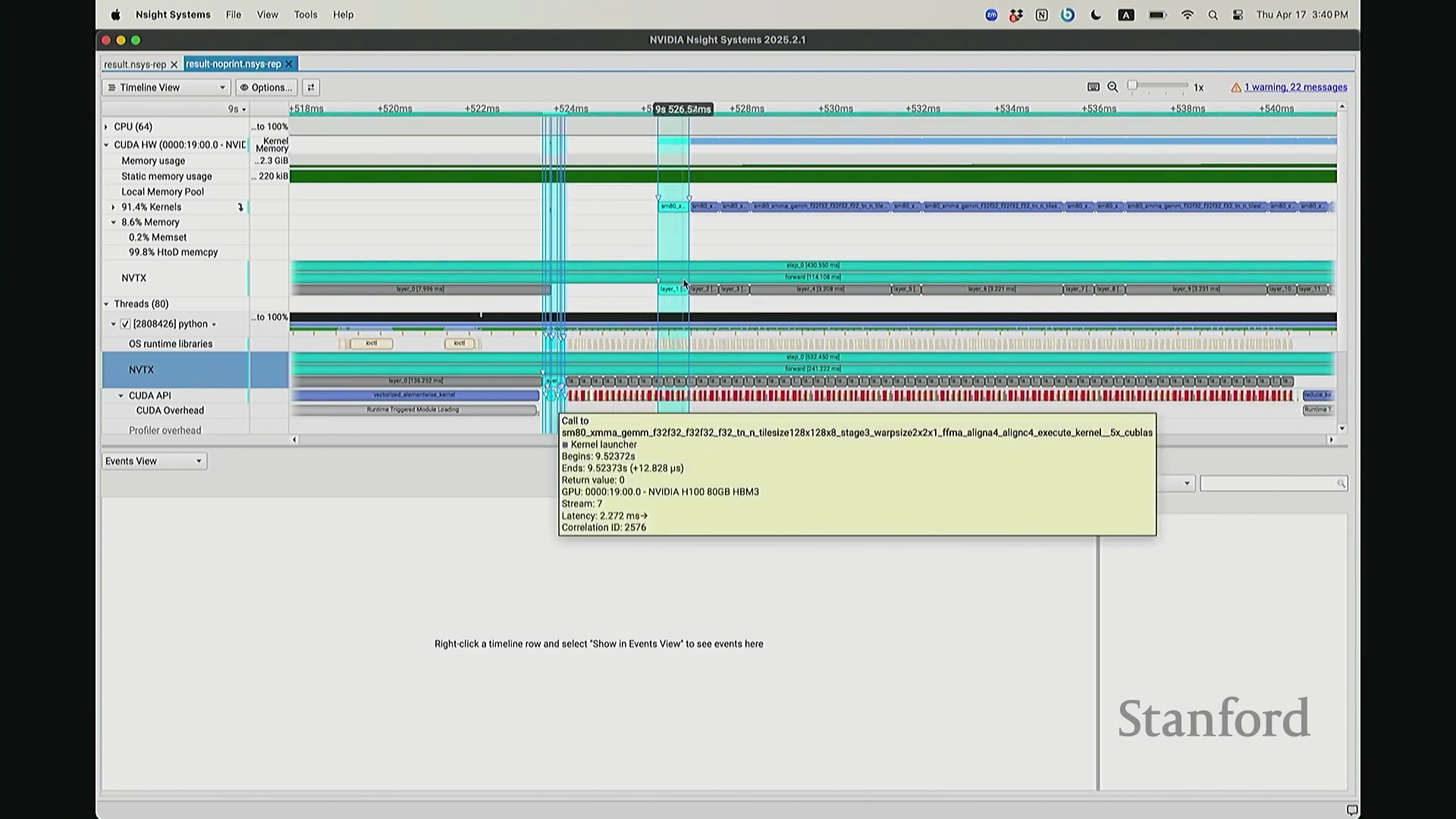
实际上,CPU 端 step 1 的结束点正是优化器步骤(Optimizer Step)的起始点。当前向传播(Forward Pass)完成后——抱歉,这里实际上触发了一个流同步操作(Stream Synchronization)。也就是说,CPU 执行了一条流同步命令。该命令的语义是:“暂停执行,等待 GPU”。因为 CPU 无法继续超前调度,它必须等待损失值计算完成并回传。这类似于一个空操作(Placeholder Operation),向 CPU 发出阻塞信号:等待……直至反向传播(Backward Pass)步骤完成。此时方可打印损失值。打印完成后,CPU 恢复异步调度,再次超前运行并开始派发 step 2 的相关指令。随后,当命令队列(Command Queue)耗尽时,CPU 再次陷入等待,执行同步操作,直至反向传播步骤完成、损失值打印完毕,才继续超前调度。在此场景下,GPU 在两种配置中均能保持较高的硬件利用率(Hardware Utilization)。但在极端情况下,例如频繁打印大量日志,实际上会引入 CPU 瓶颈(CPU Bottleneck)。因为 CPU 被迫反复同步等待,无法持续提前发射(Kernel Launch)内核。这正是高级性能分析器(Profiler)的强大之处:它清晰揭示了 CPU 与 GPU 的交互轨迹,证明它们是独立运行并通过通信协同的设备,而非单一的统一计算实体。若不借助此类工具,此类底层现象将无法被察觉。关于这部分有疑问吗?好的,我们继续。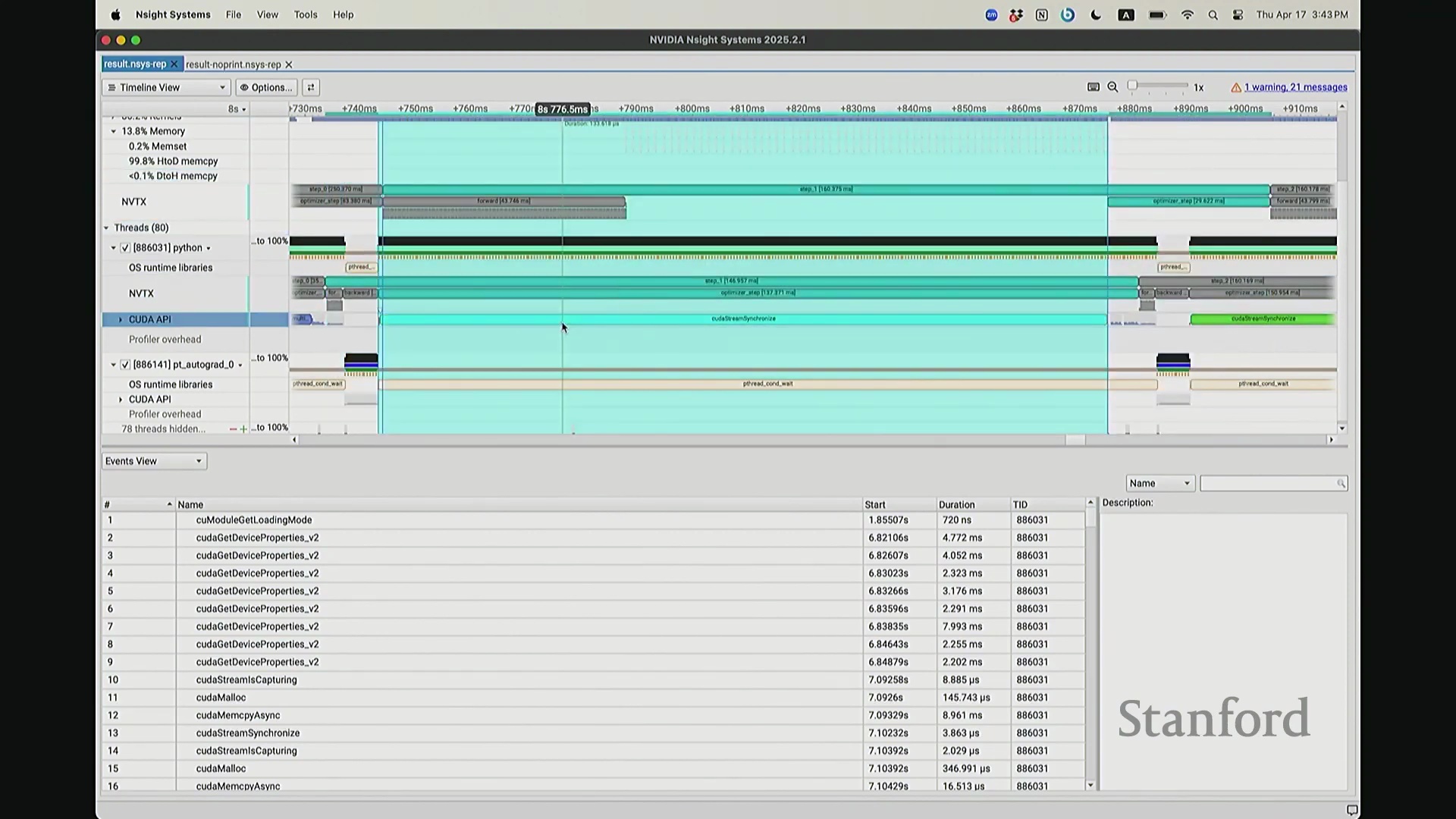
使用 Nsight Systems 进行高级性能分析
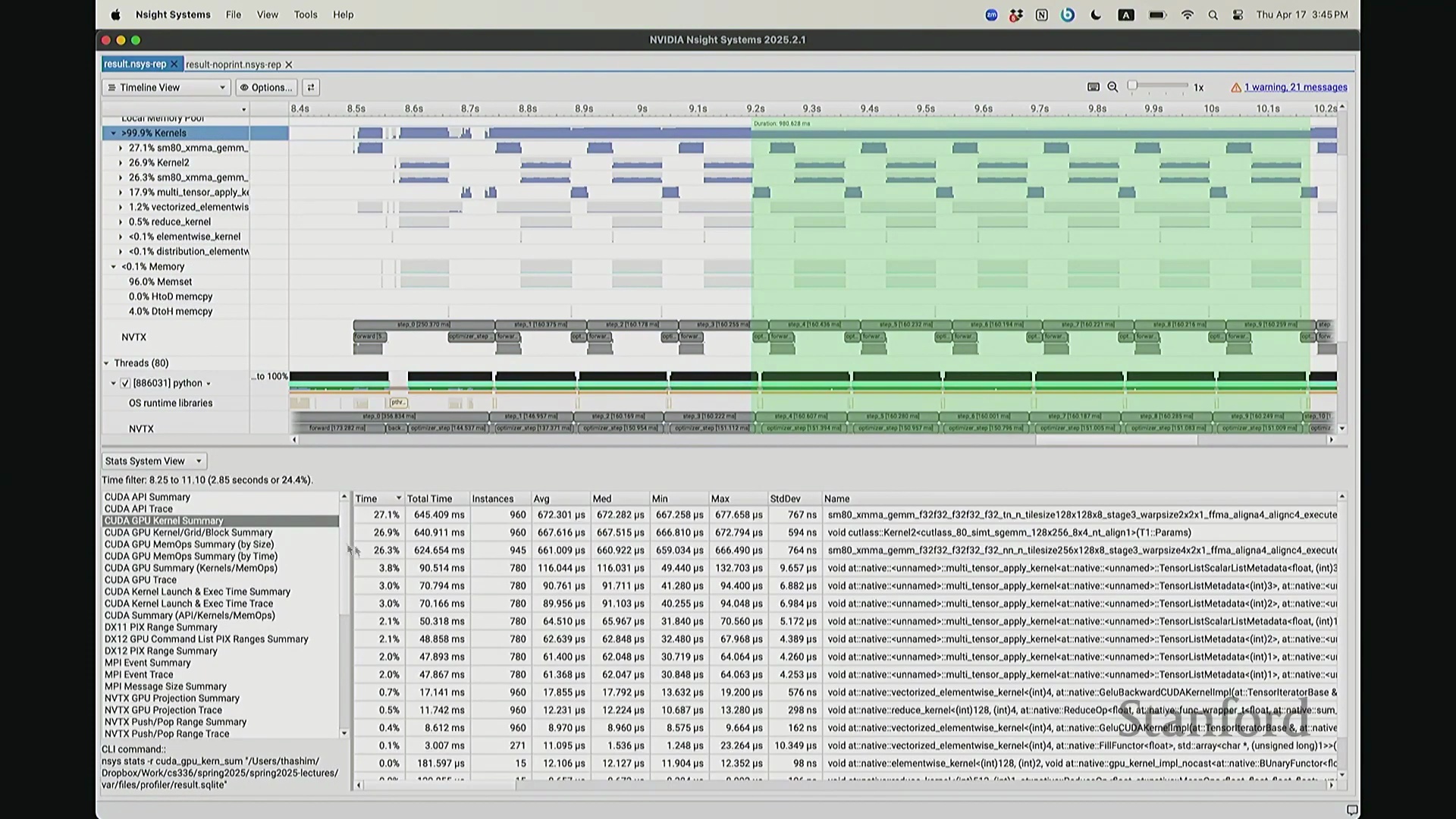
我想补充展示的另一点是,此前演示的分析器功能,在 NVIDIA Nsight Systems (Nsys) 中同样可以生成高度相似的视图。你可以自定义分析的时间范围。如前所述,需排除预热(Warm-up)阶段,因此我们应从 step 3 开始截取并测量后续步骤。在选定范围内,我们可以提取出实际执行计算的内核(Kernels)。大家可以看到,系统中实际上调度了多种不同类型的矩阵乘法(Matrix Multiplication)内核。此处是一个矩阵乘法内核,彼处是另一种实现的矩阵乘法内核,此外还有不同的向量化逐元素内核(Vectorized Element-wise Kernel)。它们各自消耗不同量级的计算资源。借助这些数据,我们可以在事件视图(Events View)中全局掌控任务执行状态,并可切换至统计视图(Stats View)查阅各项操作的精确耗时。稍等,让我确认一下……我们需要的是平均耗时吗?不,应该是 CUDA 内核执行摘要(CUDA Kernel Execution Summary)。对,我们需要统计内核的总持续时间(Total Duration)。借此可精准定位最耗时的内核,并在不同视图间交叉比对数据。这确实是一款极其强大的工具,既能提供宏观的性能瓶颈汇总视图,又能微观追踪单个被发射的内核详情、精确发射时间及其对应的 CPU 调用源。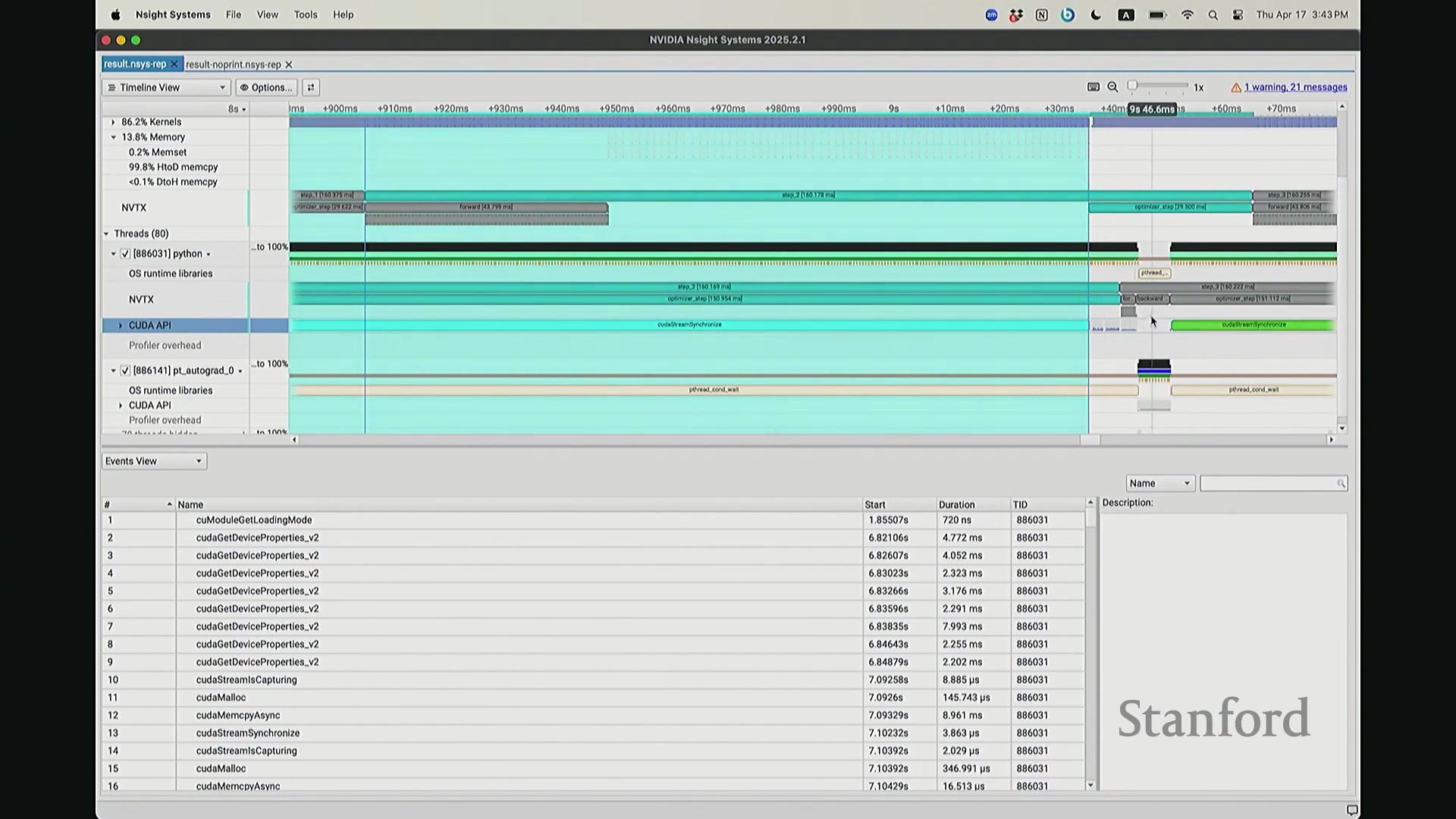
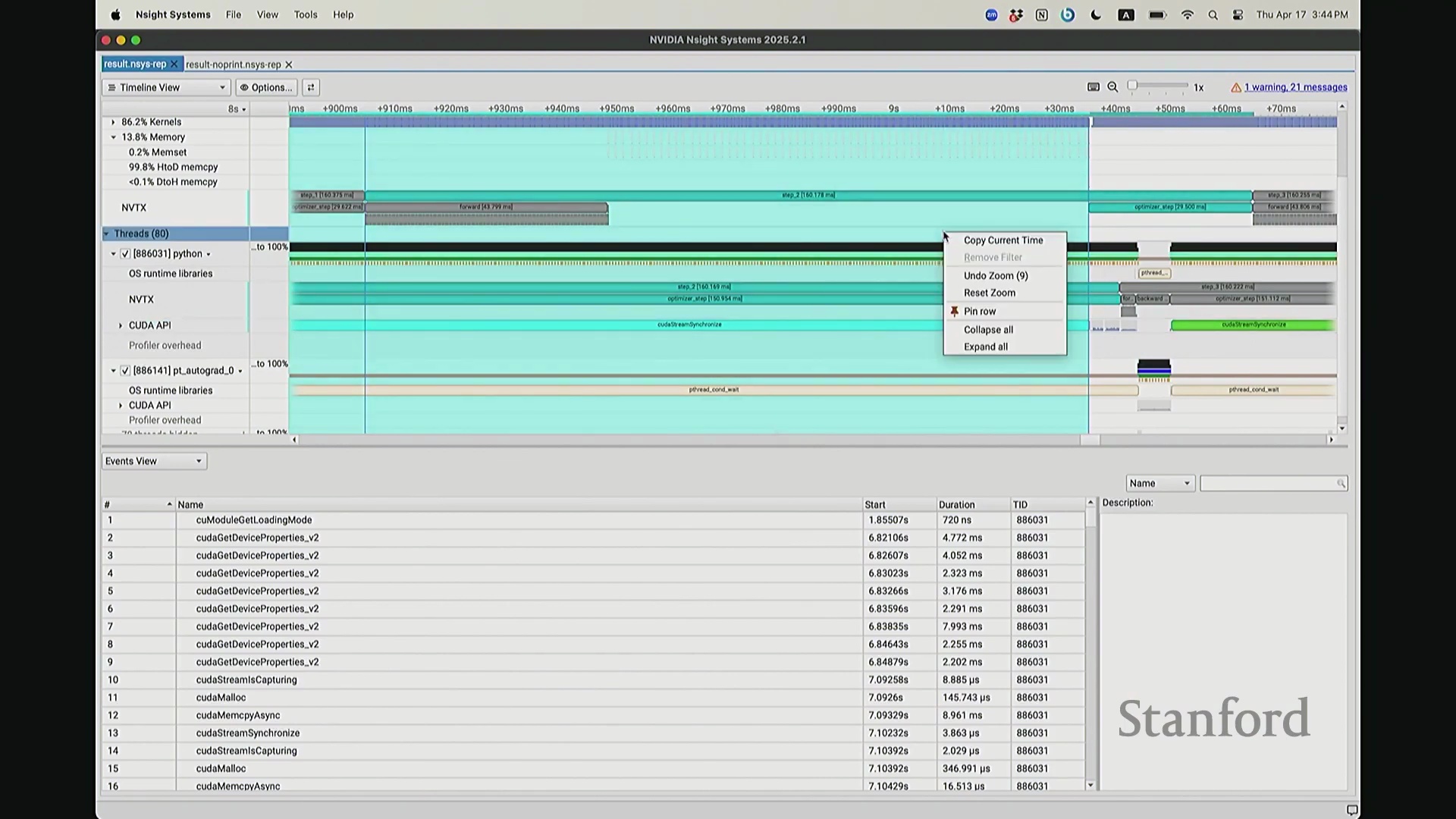
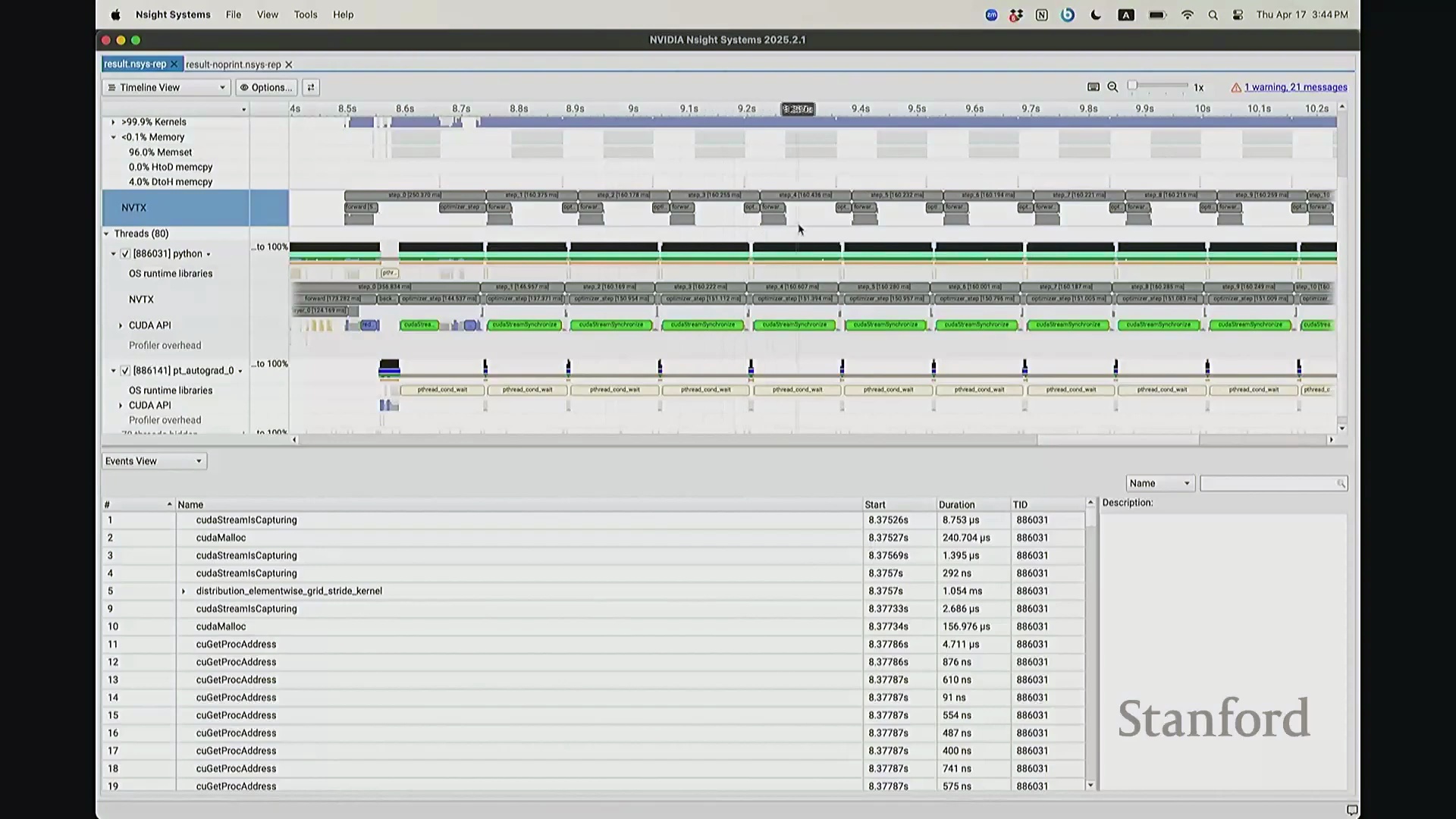
 最后补充一点,这也是使用 Python 编程通常不会成为性能瓶颈的核心原因之一。Python 本身并非高性能语言,但由于 CPU 具备异步超前调度与命令排队(Command Queuing)能力,计算负载始终能被高效填满。正是这种 GPU 与 CPU 解耦(Decoupling)的设计,使我们得以兼顾高级编程语言的易用性与 GPU 的满载利用率。关于此视图还有疑问吗?若无,本节关于性能分析器的讲解就到此为止。大家将在作业二中实际操作该工具,相信你们会深刻体会到其价值,因为它能直观揭示硬件底层驱动大语言模型(Large Language Model, LLM)训练的真实机制。
最后补充一点,这也是使用 Python 编程通常不会成为性能瓶颈的核心原因之一。Python 本身并非高性能语言,但由于 CPU 具备异步超前调度与命令排队(Command Queuing)能力,计算负载始终能被高效填满。正是这种 GPU 与 CPU 解耦(Decoupling)的设计,使我们得以兼顾高级编程语言的易用性与 GPU 的满载利用率。关于此视图还有疑问吗?若无,本节关于性能分析器的讲解就到此为止。大家将在作业二中实际操作该工具,相信你们会深刻体会到其价值,因为它能直观揭示硬件底层驱动大语言模型(Large Language Model, LLM)训练的真实机制。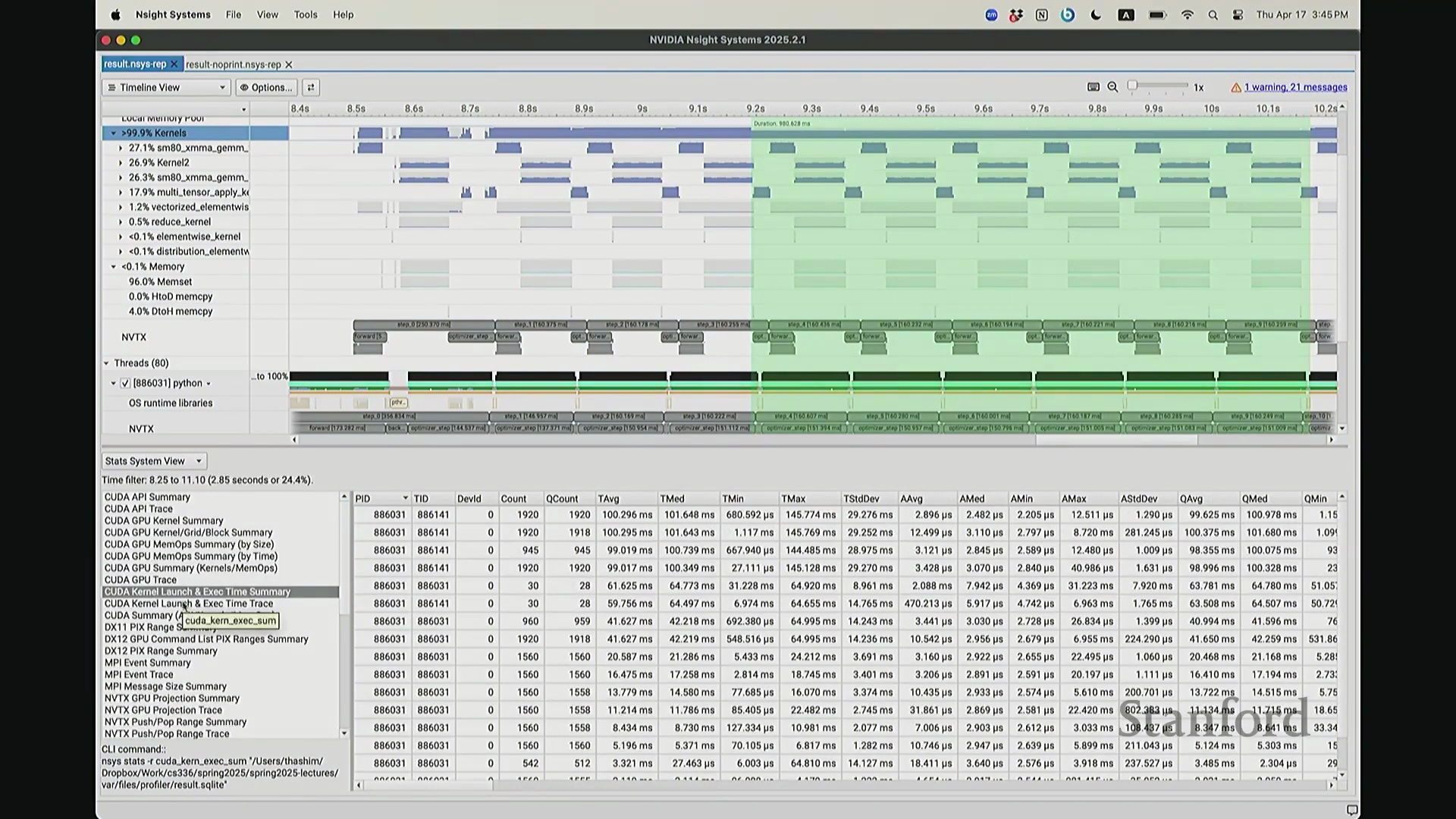

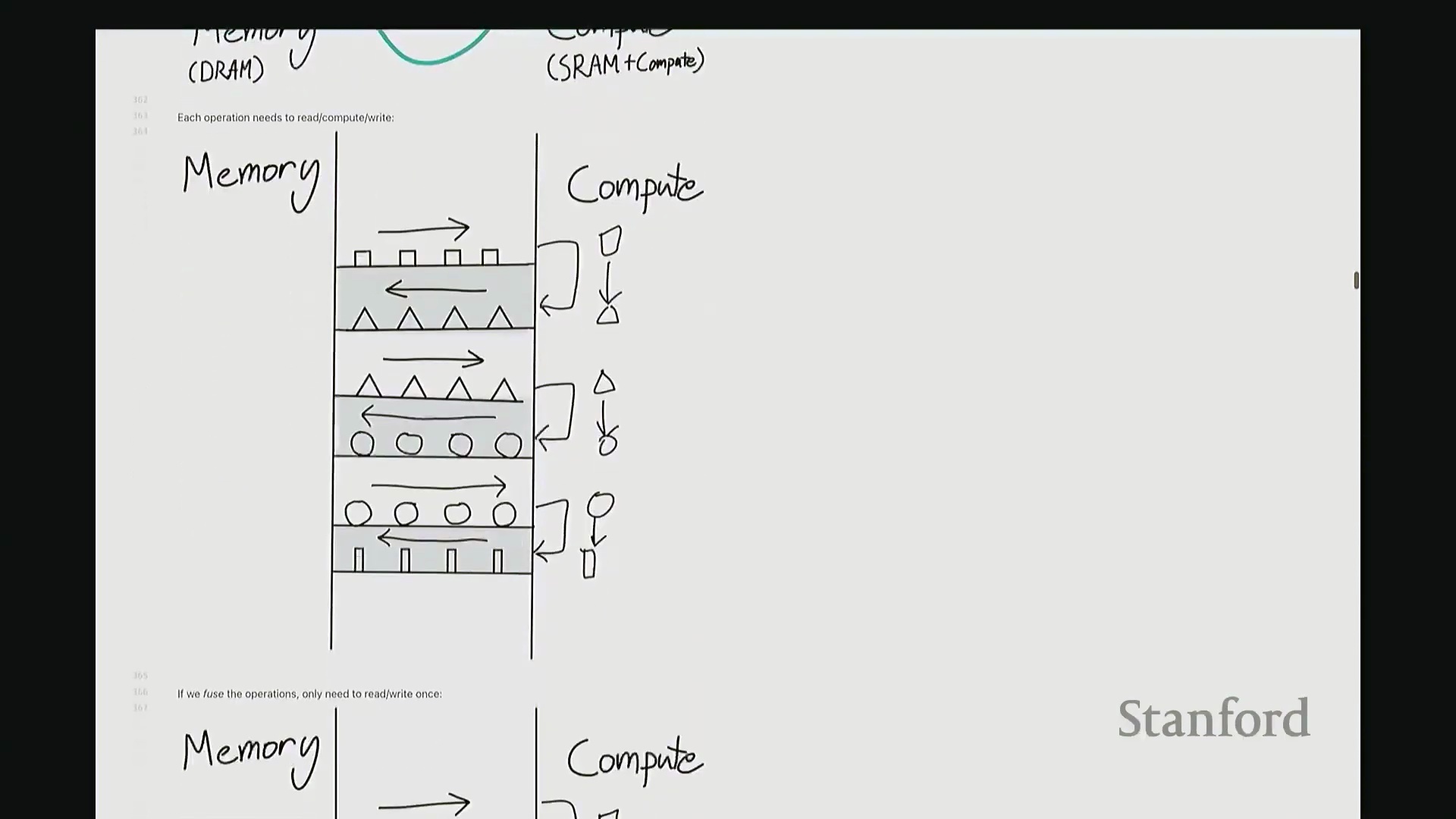
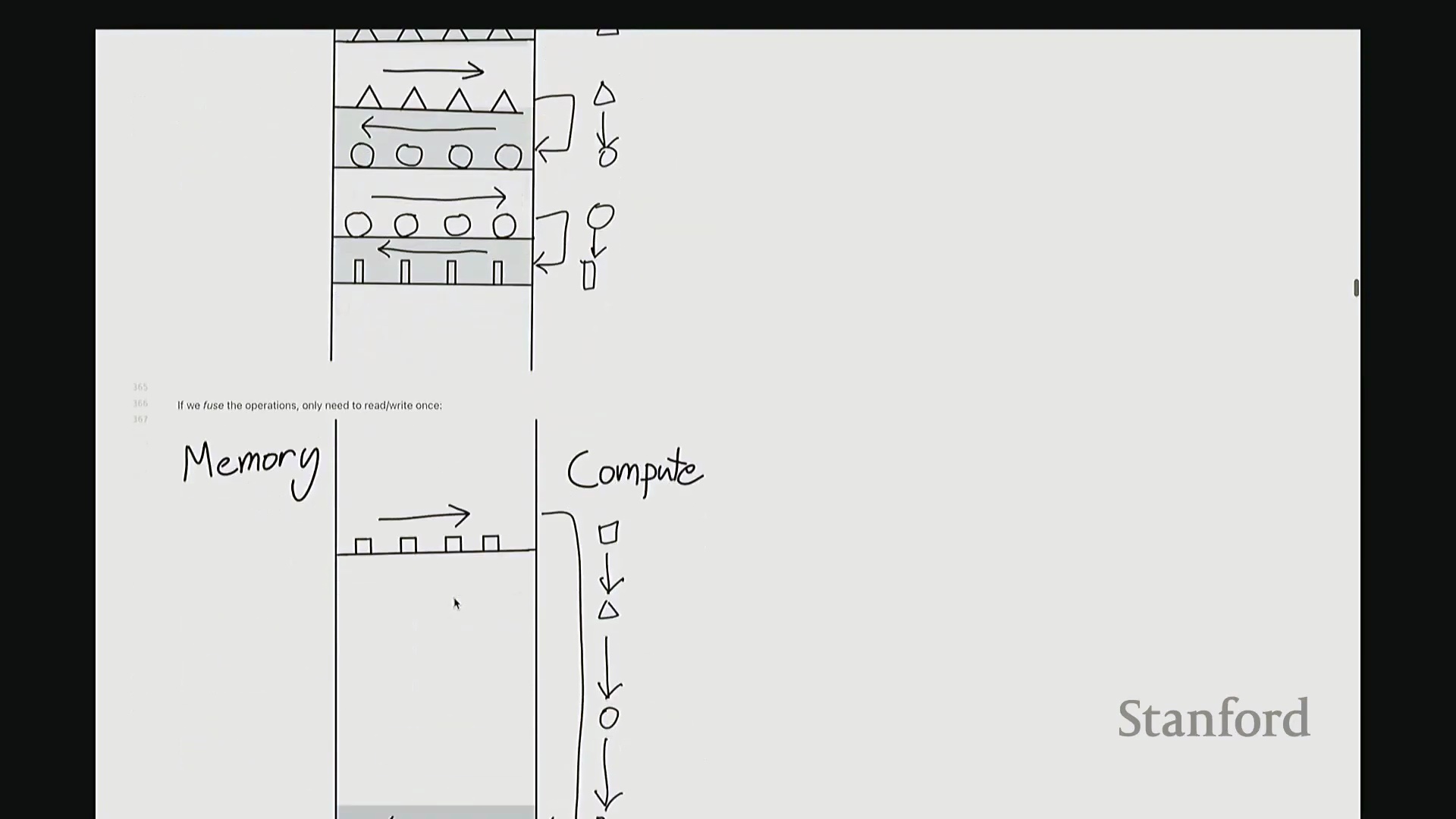
内核融合与 GeLU 的性能差距
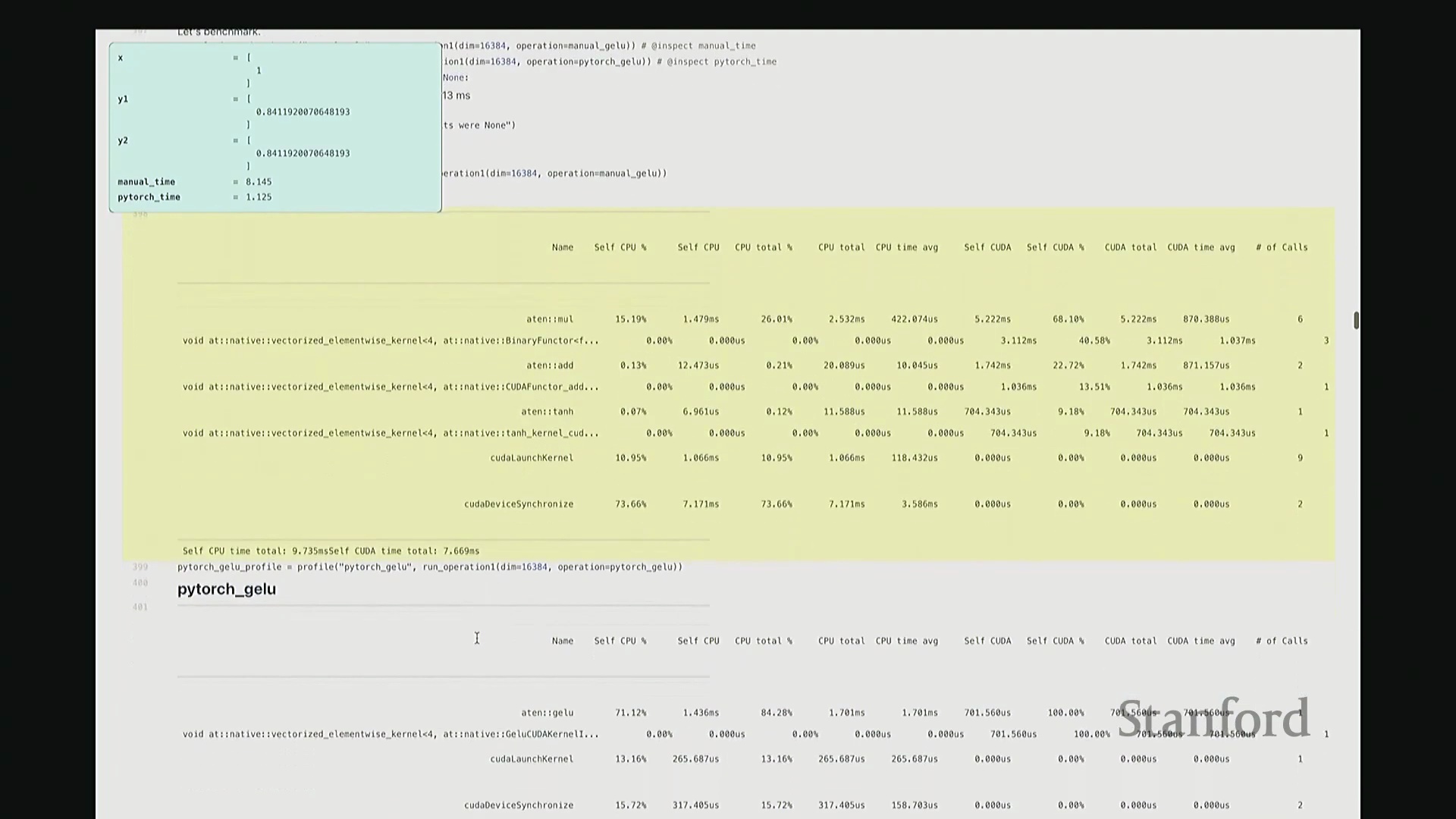
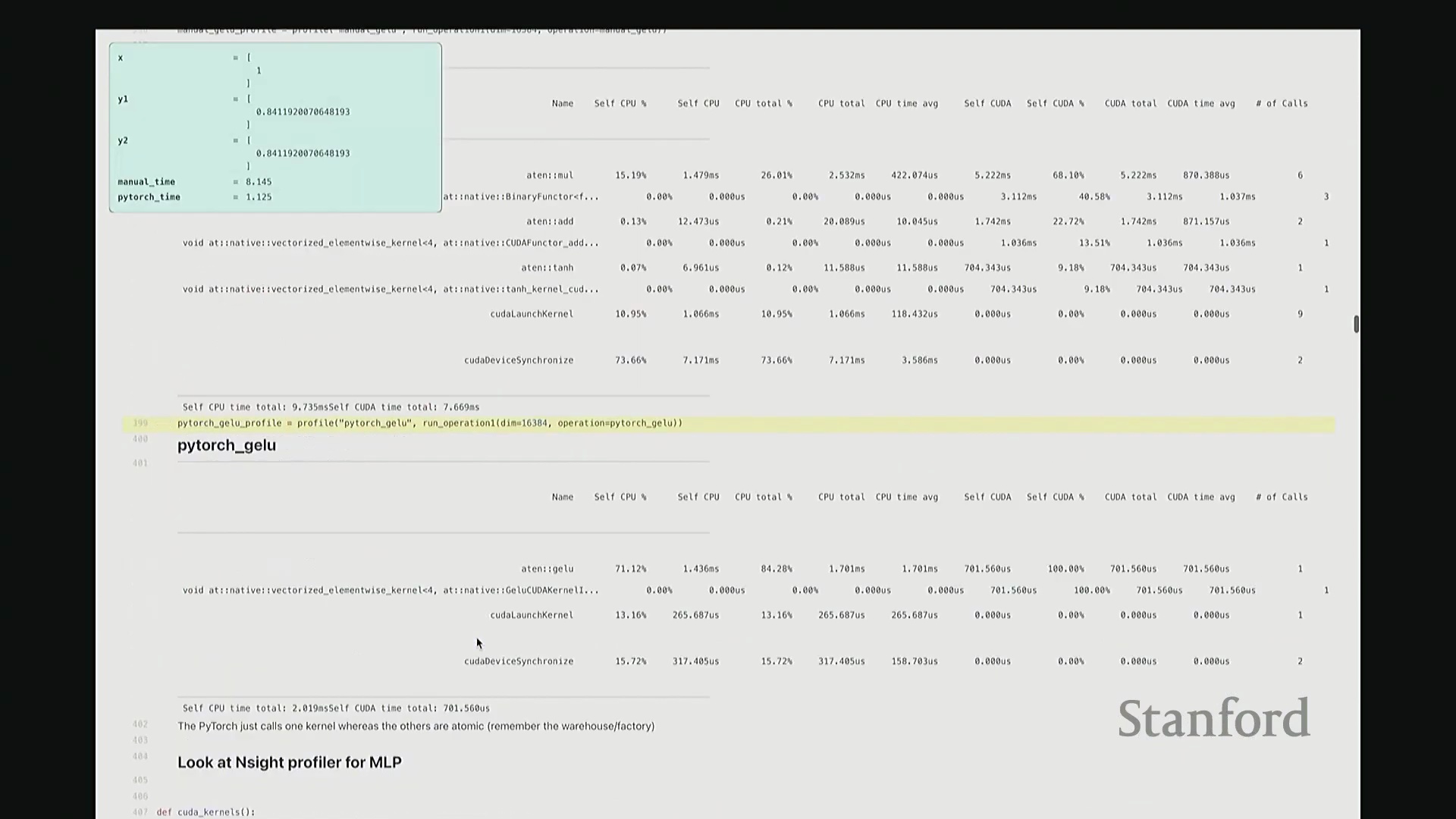
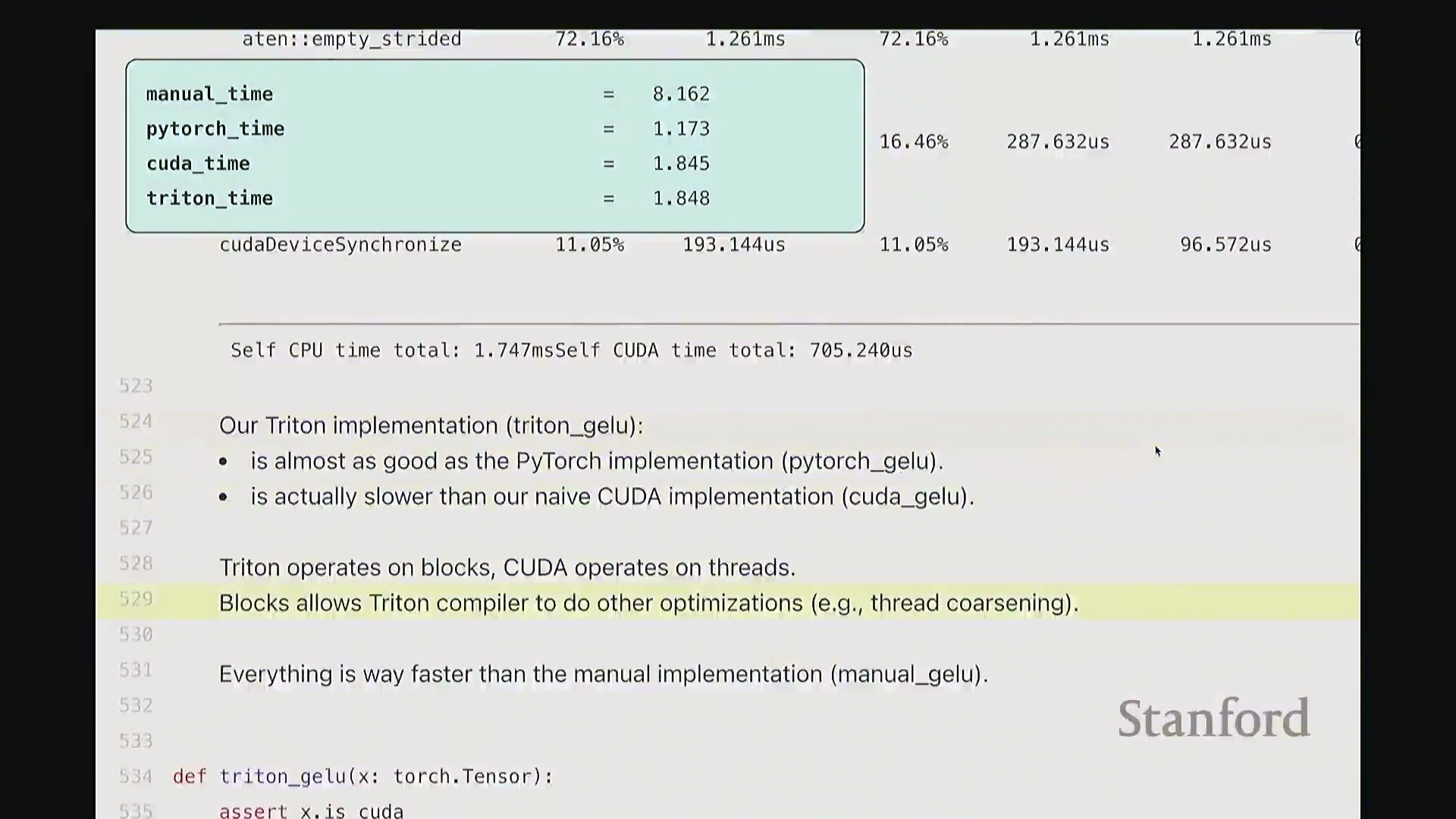
好的,基准测试(Benchmarking)与性能分析(Profiling)部分至此结束。大家现已掌握性能优化所需的核心工具,剩余时间我们将动手编写自定义内核。大家是否还记得内核融合(Kernel Fusion)的概念?正如课件所示,这好比一个加工厂:若每次执行单一操作都需将数据从内存仓库(Global Memory)运至计算工厂,处理后再运回,将产生高昂的搬运成本。若天真地按顺序串行执行一系列操作,数据在内存与计算单元间的频繁往返将支付巨额的数据传输开销(Memory Transfer Overhead)。正确的做法是让单个内核一次性完成所有关联运算,从而避免重复的数据搬运成本。这一原则至关重要。现在我们将以 GeLU 为例编写专属内核。我会采用多种实现方式,并对比其性能差异。这是 PyTorch 官方的 GeLU 实现:torch.nn.functional.gelu。我设置了 approximate='tanh' 参数,以便与稍后手写的朴素实现(Naive Implementation)精确对齐。该实现并非直接乘以高斯分布的累积分布函数(Cumulative Distribution Function, CDF),而是采用了一种计算效率更高的数学近似公式。这就是 PyTorch 的底层实现逻辑。接下来我要做一个“反模式”操作。大家看到这段代码可能会断定其性能极低:我将在 PyTorch 中手动展开 GeLU 公式:0.5 * x * (1 + torch.tanh(sqrt(2/pi) * (x + 0.044715 * x^3)))。这是一个经验公式(Magic Formula),但对 GeLU 的拟合度极佳,大家可以查阅文献验证。然而,如此实现会触发大量独立的张量操作,对吧?包括 tanh 激活、三次方运算、常数乘法、加法以及标量乘法等。若每个操作都独立调用不同的 CUDA 内核,性能必然低下,对吧?结合前文所述的内核融合理论,这符合我们的直觉。下面我们通过实验验证。两者在数学上是等价的。如左上角所示,它们输出完全一致的数值。我们也可在服从随机高斯分布(Random Gaussian Distribution)的测试集上进行系统性验证。现在进行基准测试。对于超大规模输入,手动展开实现耗时 8.1 毫秒,而 PyTorch 官方实现仅耗时 1.1 毫秒。融合版本的速度呈数量级提升,事实上快了约八倍。可见,编写一个融合内核带来的性能差异极为显著。尽管矩阵乘法可能仍是整体瓶颈,但若能将激活函数耗时从 8 毫秒压缩至 1 毫秒,无疑极具成就感。因此,在后续课程中,我们将逐步尝试逼近 1.1 毫秒的性能标杆。
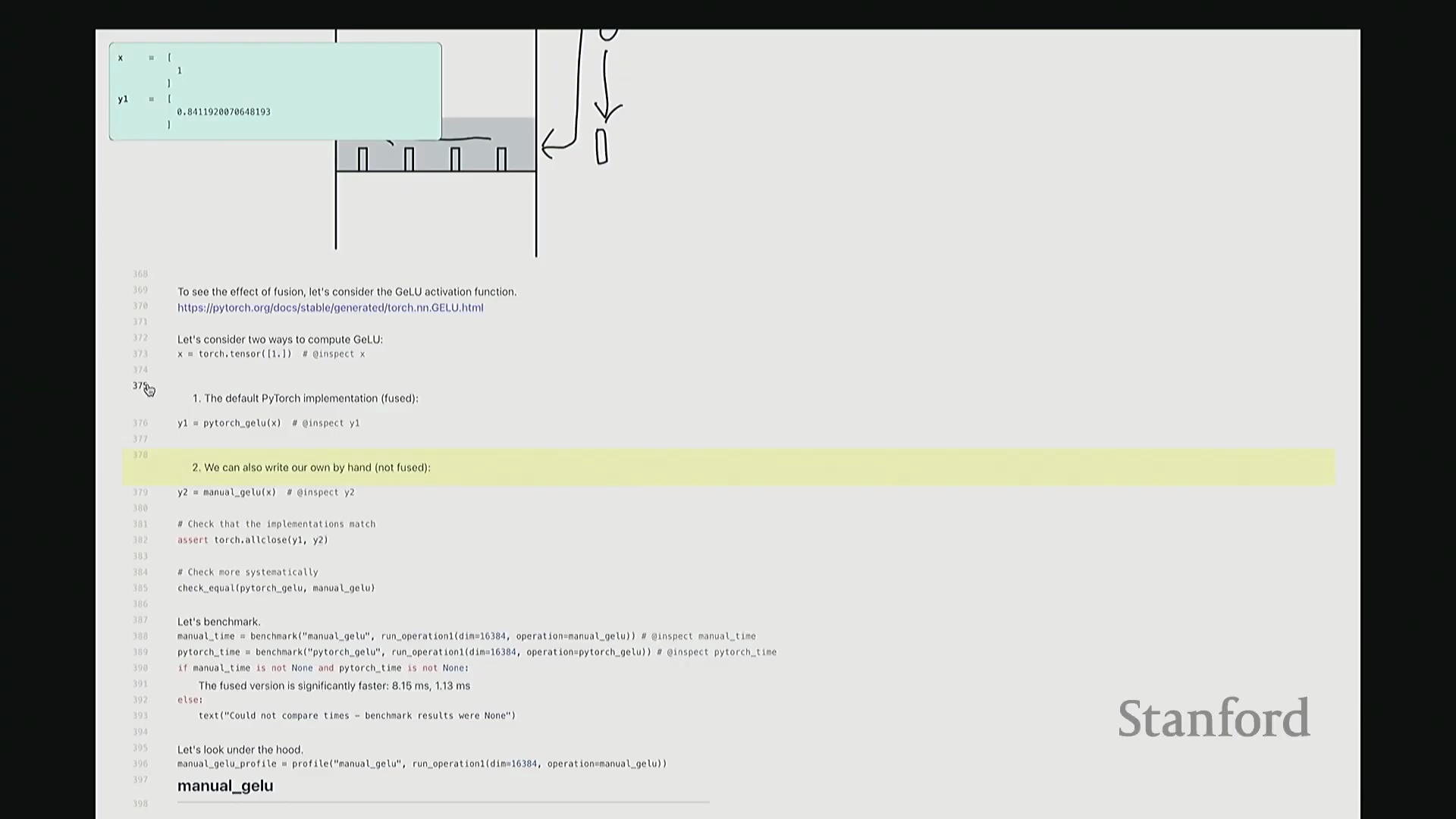
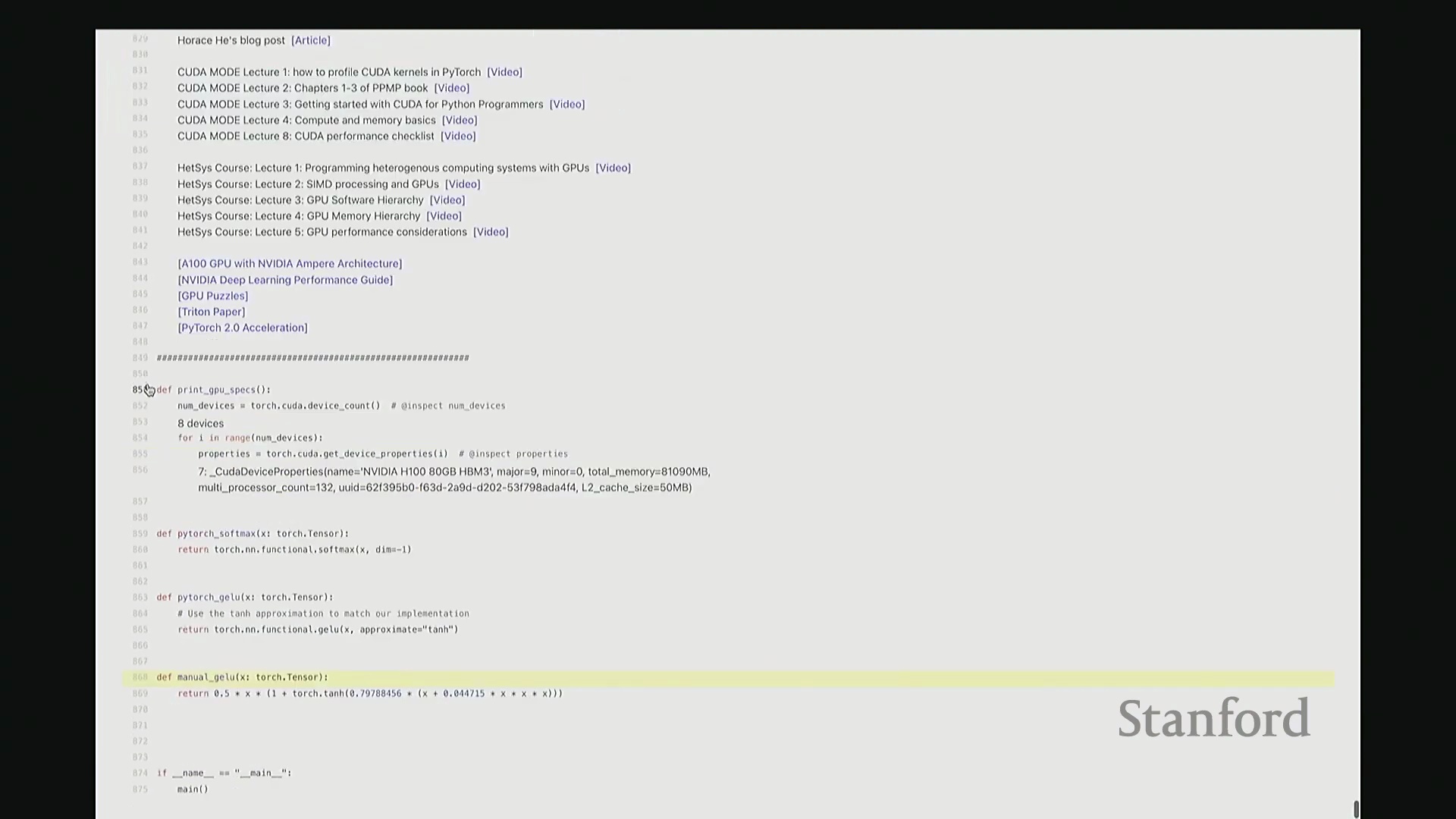
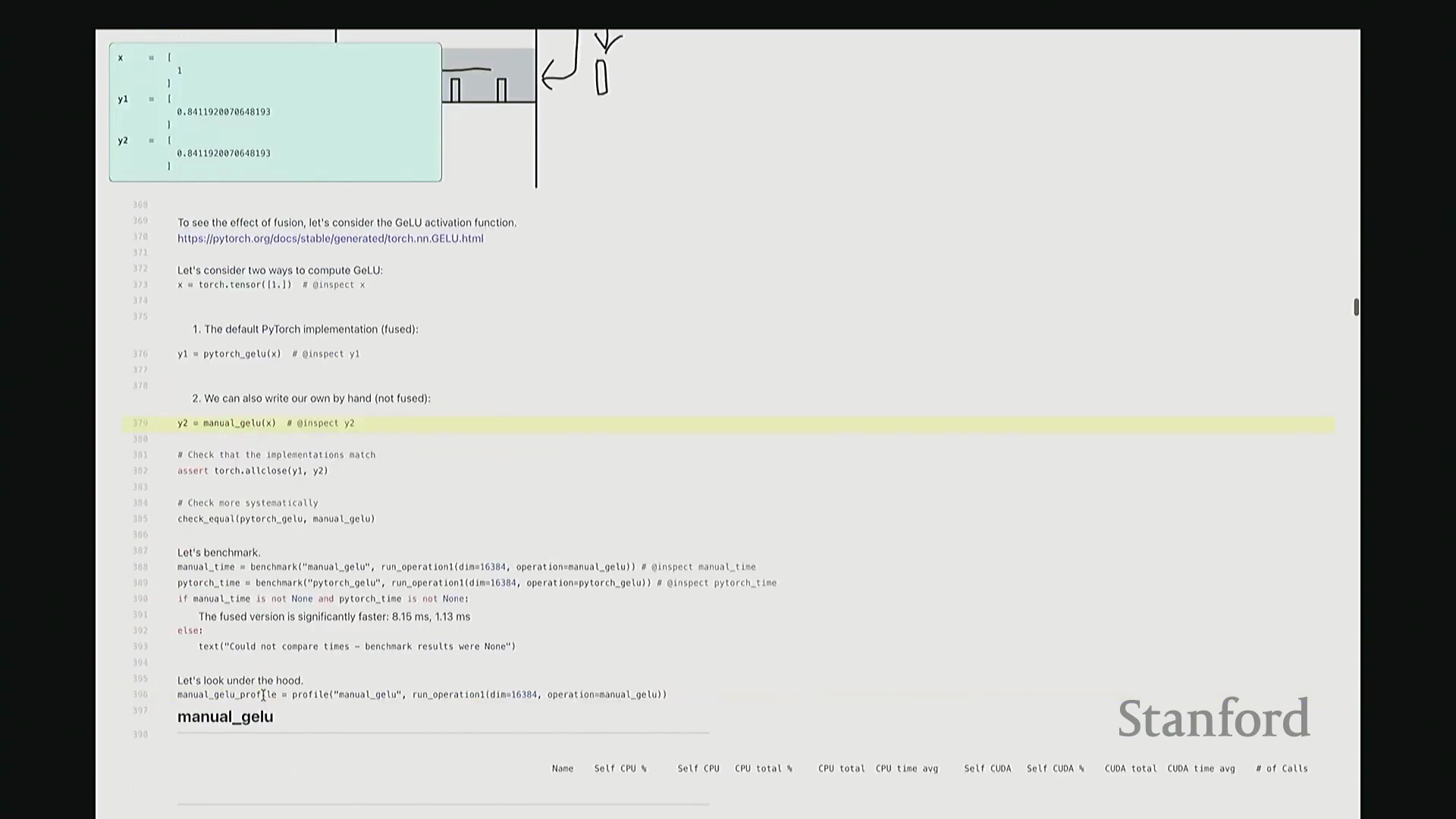
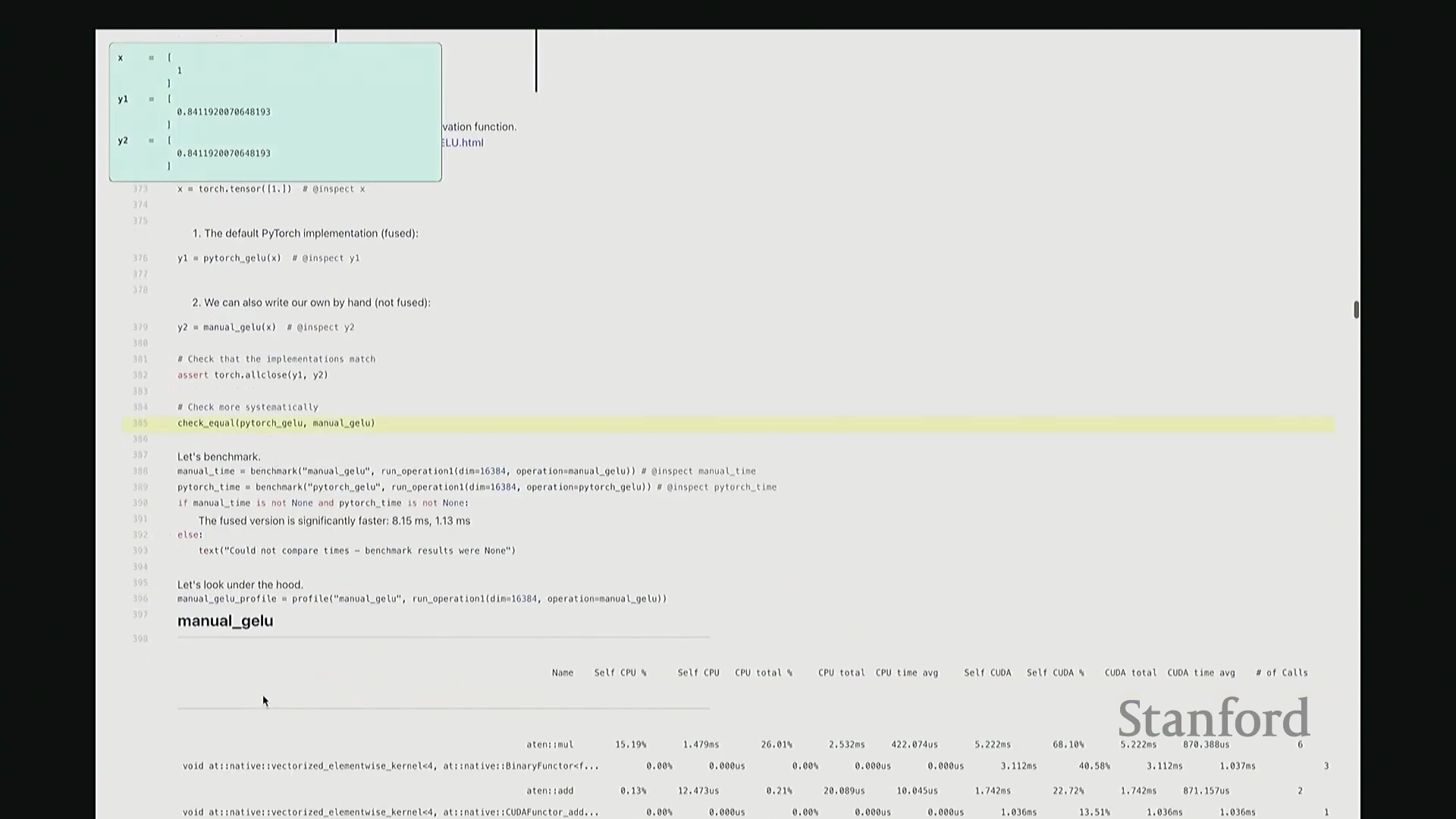
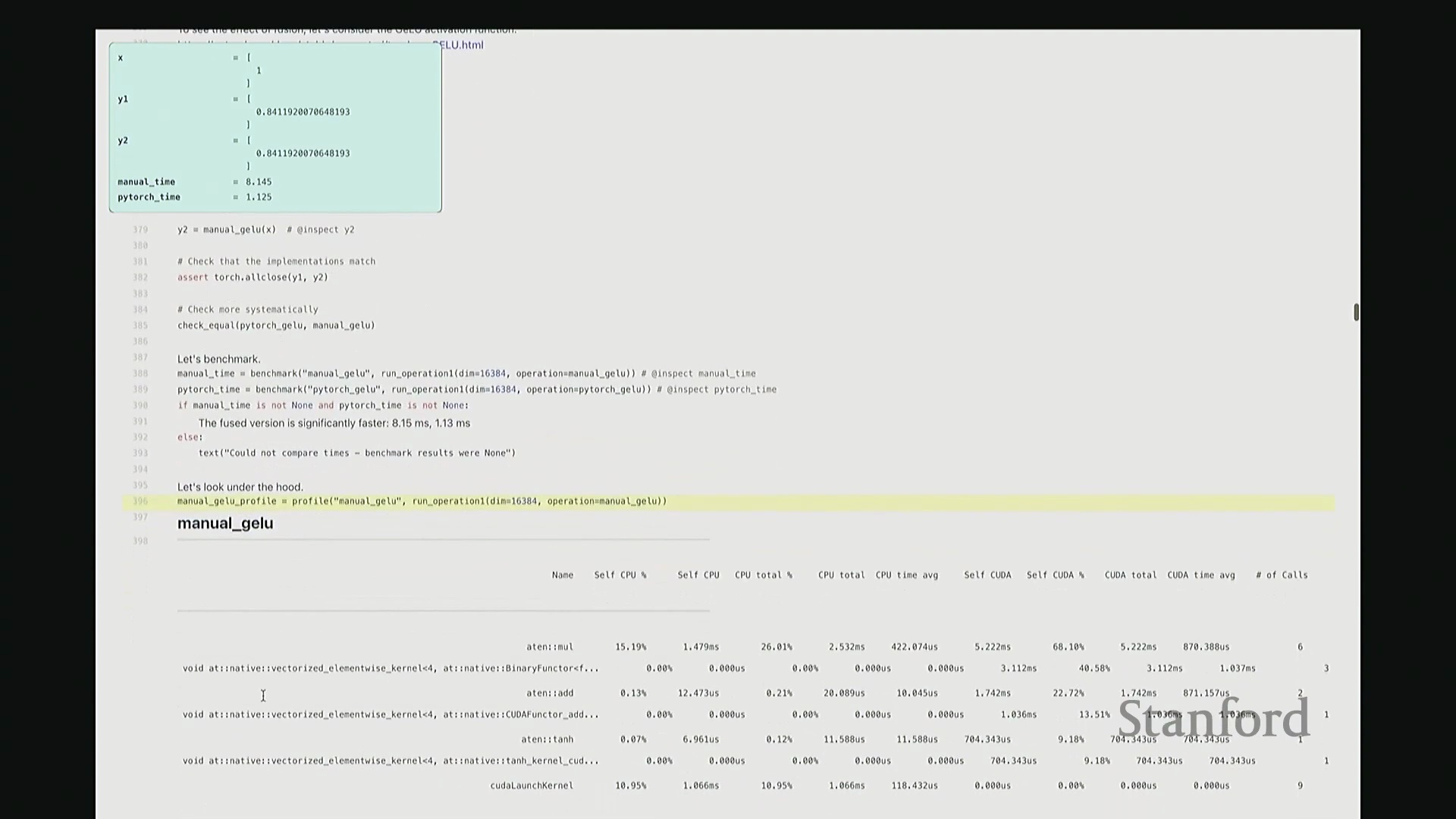
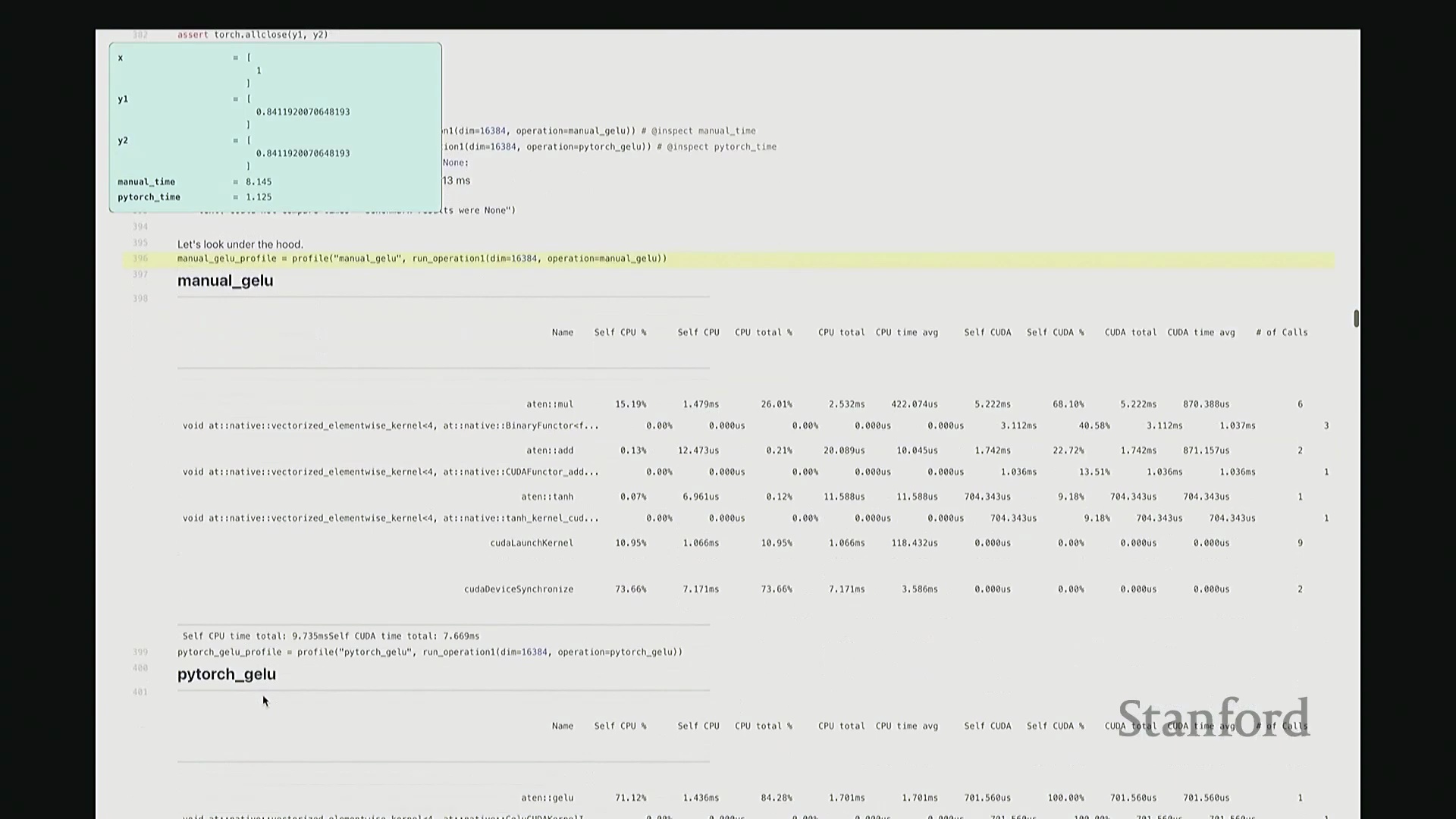
深入底层分析与单内核发射
接下来剖析底层执行细节。此处无需动用 Nsight Systems,仅凭 PyTorch 内置分析器即可洞察高层趋势。对于手动实现的 GeLU,如前所述,其底层会触发大量独立操作。尽管这些运算是向量化(Vectorized)的,但系统会依次发射多个 CUDA 内核。注意右侧调用栈:同一个浮点乘法内核被重复调用了三次。此外还有加法内核与 tanh 内核。每次内核启动均伴随固有开销,累积起来将造成显著的性能损耗。现在对 PyTorch 官方 GeLU 进行同等分析。结果令人欣喜:仅发射了一个 CUDA 内核。该内核单次运行即处理完全部数据,这正是我们追求的理想状态。极高的执行效率正源于此单一内核设计。我们的目标即是实现同等水准的 CUDA 内核。基于高效 GPU 编程的常识,你或许会推测:PyTorch 团队必定使用了极底层的语言进行开发。我们也应遵循此路径。虽无需触及最底层的 PTX,但我们将采用 C++ API。接下来,我们将使用 C++ 手写此 CUDA 内核。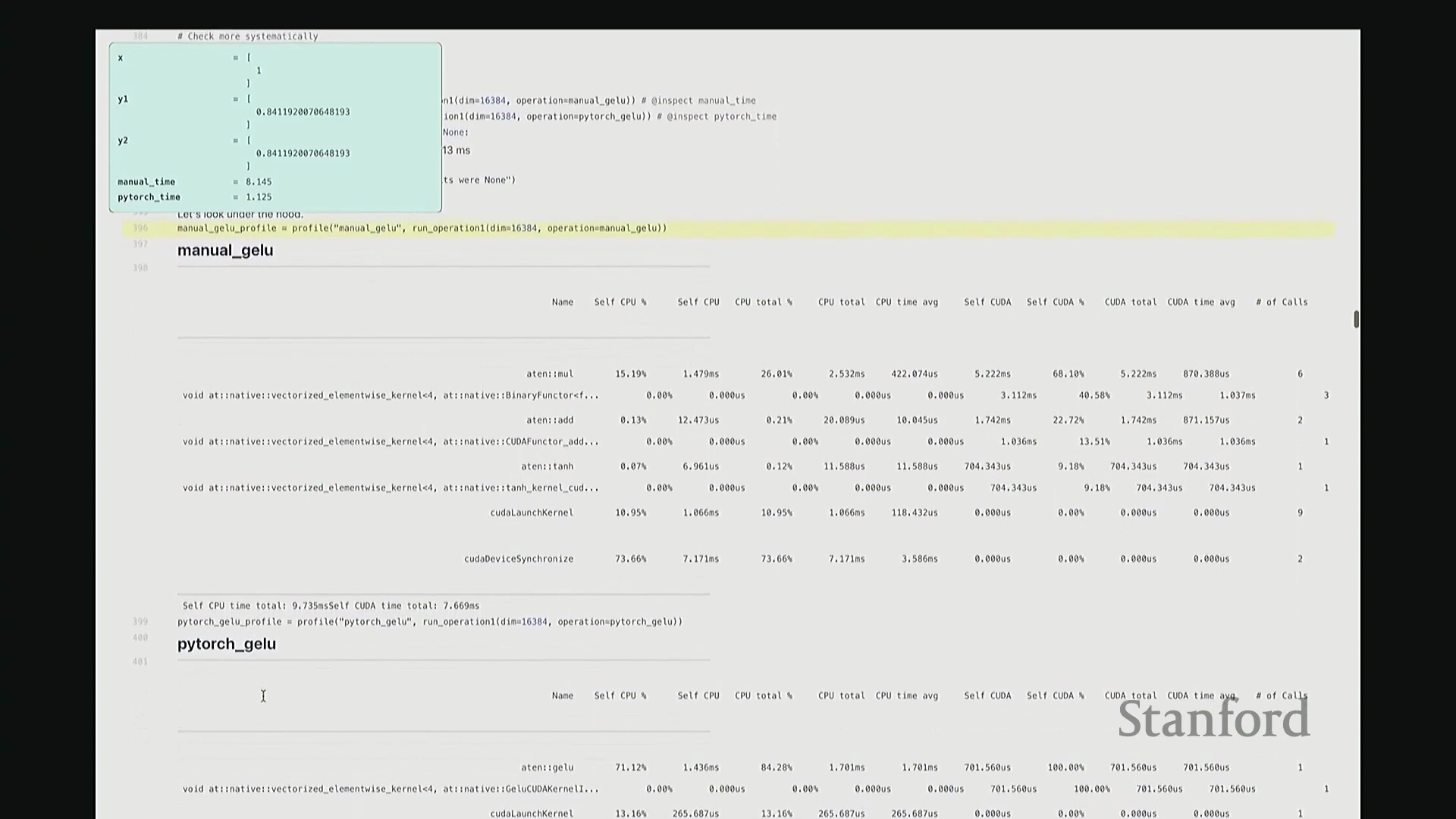
CUDA C++ 内核架构简介
现在让我们深入底层,编写自定义 CUDA 内核。具体该如何实现?好的,我们已搭建好完整的 C++ 开发环境。CUDA 本质上是用于 GPU 交互与并行编程的 C++ 扩展 API。沿用此前所述的 GPU 逻辑模型,我们将定义一个核心计算函数 f。调用该 CUDA 内核时,运行时(Runtime)将自动在向量或矩阵的每个元素上并行调度函数 f,从而实现大规模并行计算。在 CUDA 的宏观执行模型中,我们首先定义一个线程网格(Grid),它是由若干线程块(Thread Block)构成的集合。你可以将其理解为:将庞大任务切分为多个可并行处理的子任务块。网格中包含特定数量的块。以二维网格(2D Grid)为例,每个块可通过行坐标与列坐标唯一索引。这在处理矩阵运算时尤为便捷。每个块具备固定的尺寸(Block Size),即其包含的线程维度(Dimensions)。块内部进一步划分为一组线程(Thread)。图示即为特定线程块在网格中的坐标定位。而每个线程则隶属于其所在的线程块内部。由此形成清晰的三级层级结构:网格(Grid)包含线程块,线程块包含线程。在编程时,每个设备函数(Device Function)会自动接收内置变量以获取执行上下文。例如,通过块索引(Block Index)可确定当前所属的线程块,通过块维度(Block Dimensions)可获知块的大小。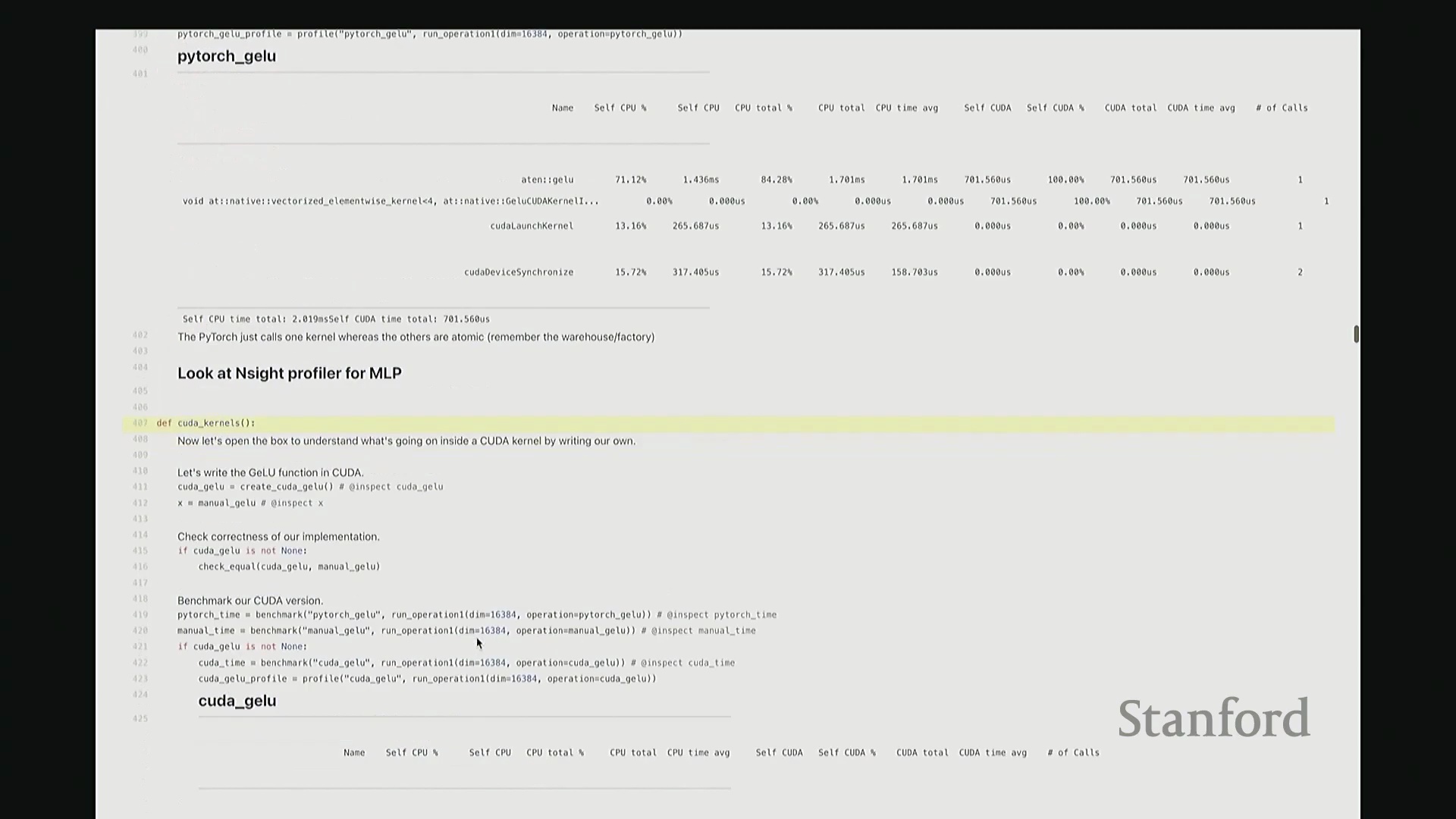
CUDA 内核参数与调试要点
块的维度(Block Dimensions)具体指什么?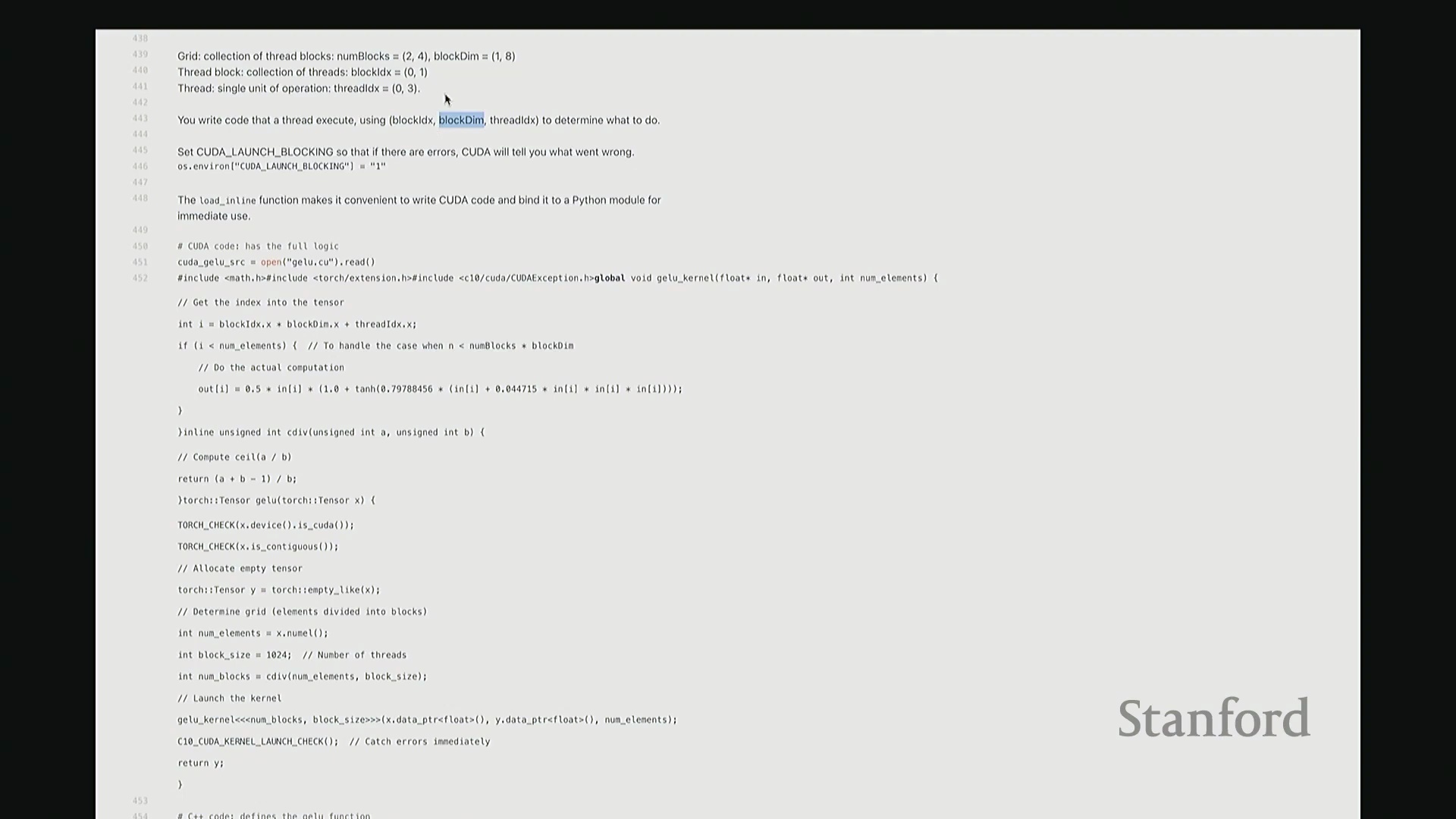 接着是当前线程在块内的索引(Thread Index)。借助这些内置参数,线程即可确定自身在矩阵或向量中的全局坐标(Global Coordinates),进而执行相应的计算逻辑。在深入实际的 C++ 代码之前,最后强调一个关键调试技巧:
接着是当前线程在块内的索引(Thread Index)。借助这些内置参数,线程即可确定自身在矩阵或向量中的全局坐标(Global Coordinates),进而执行相应的计算逻辑。在深入实际的 C++ 代码之前,最后强调一个关键调试技巧: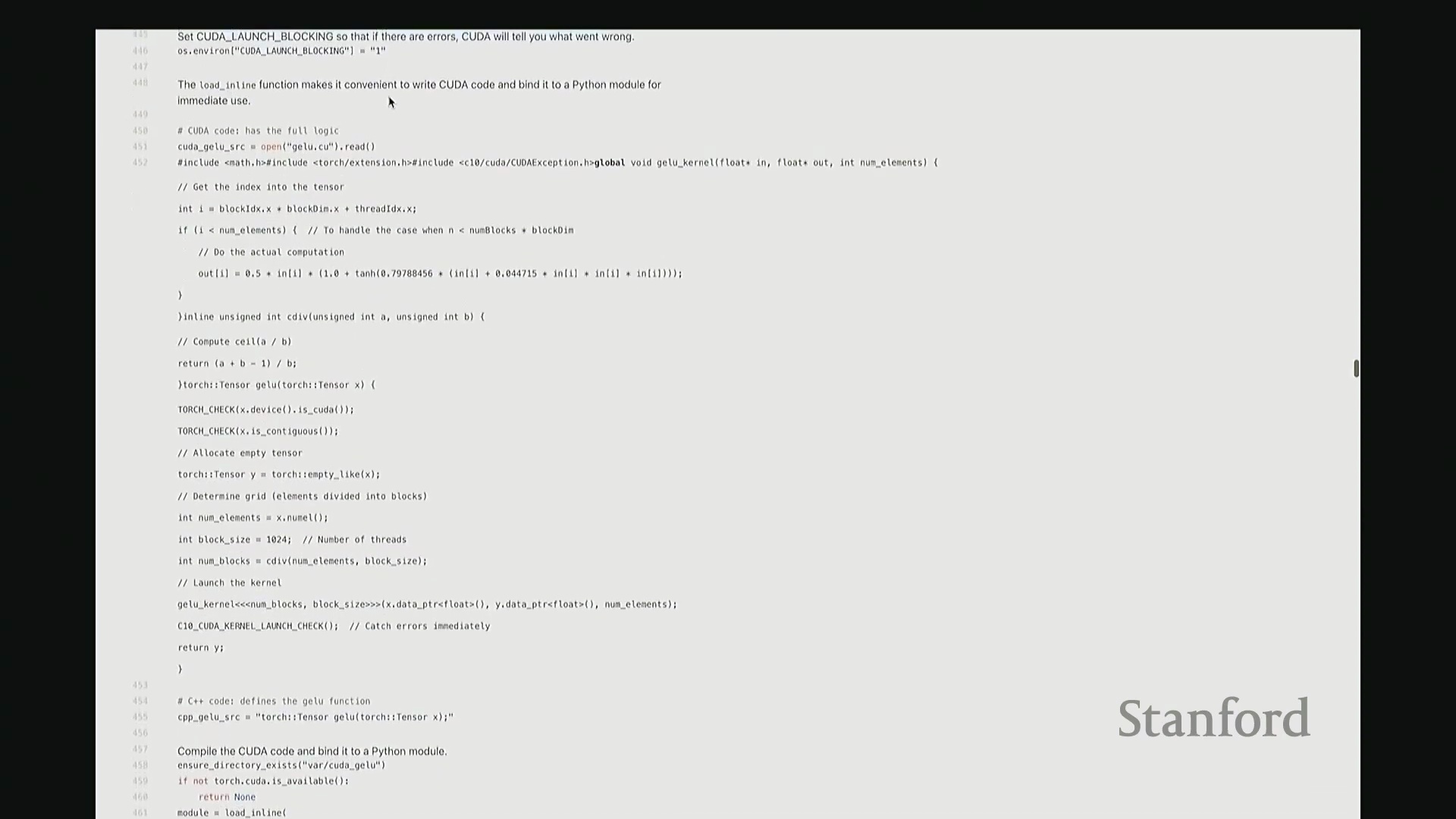 每次调试 CUDA 代码时,务必在启动脚本前设置环境变量
每次调试 CUDA 代码时,务必在启动脚本前设置环境变量 CUDA_LAUNCH_BLOCKING=1。该设置会强制 CUDA 内核同步执行(Synchronous Execution),虽然会牺牲部分运行性能,但能返回精确的错误堆栈信息。若不进行此设置,CUDA 的异步特性将导致报错滞后或定位困难,调试过程将极为痛苦。
主机包装函数:设置与启动
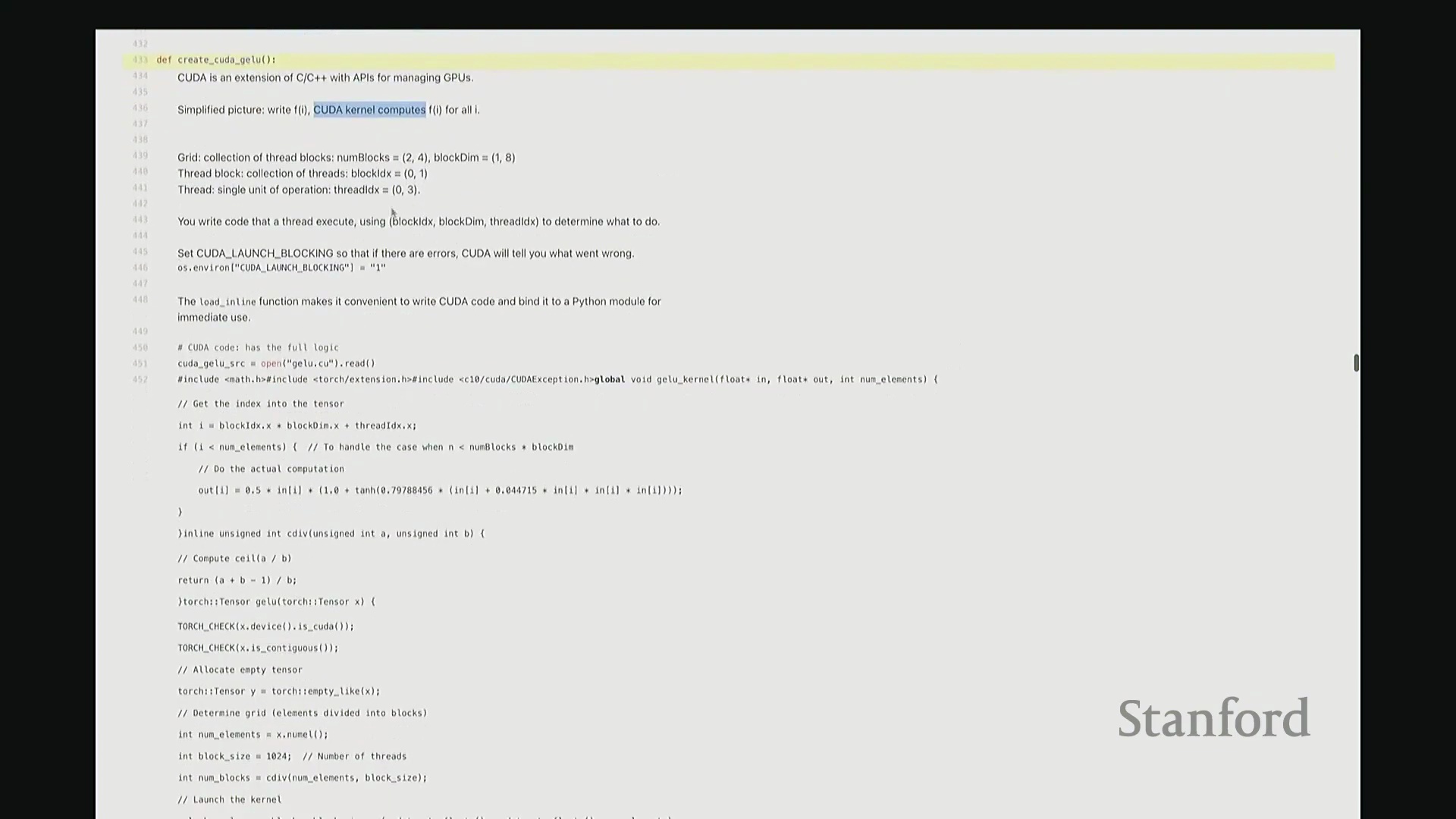
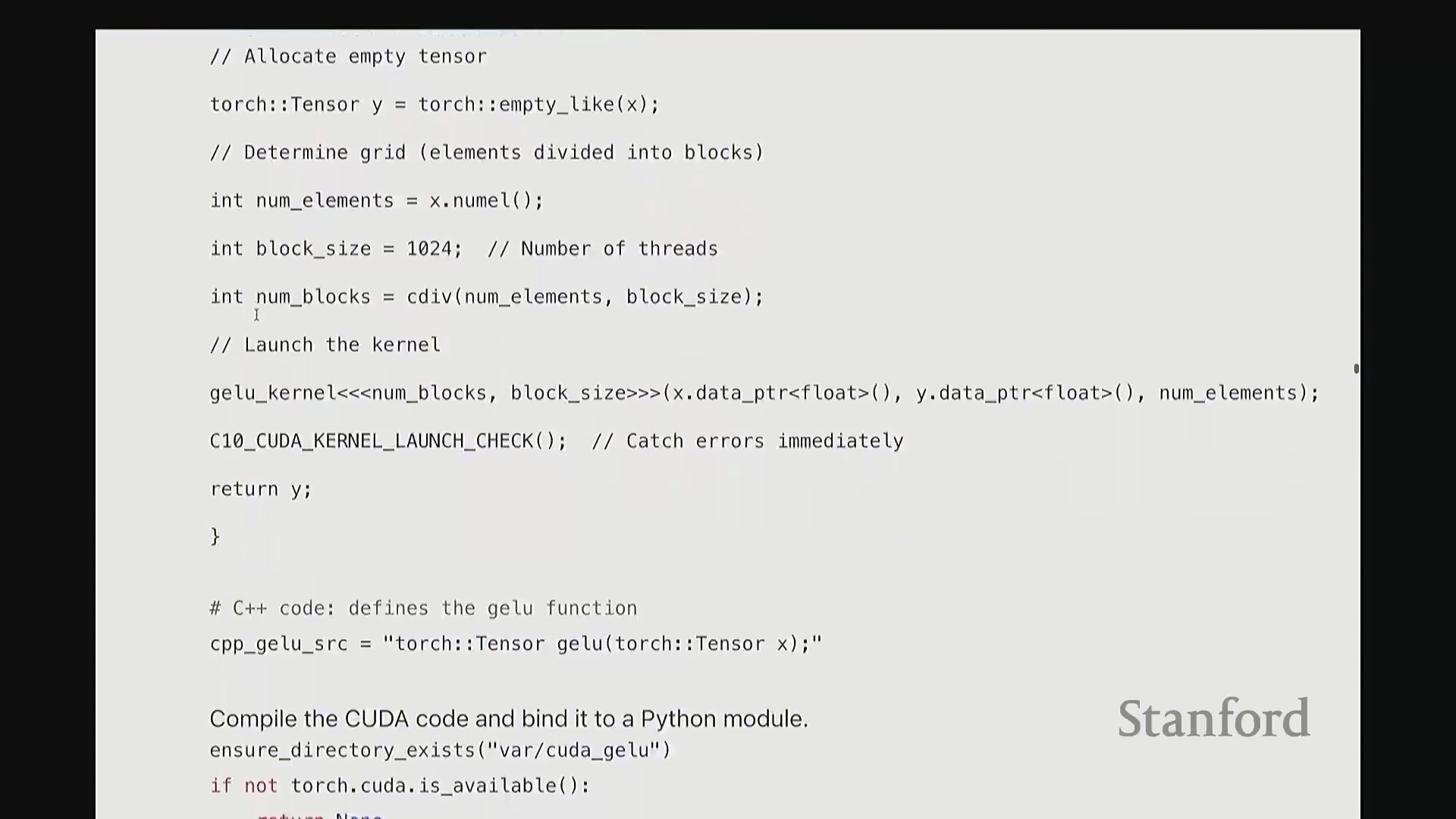
下面展示我的 GeLU 内核代码。我们将逐段拆解,并详细解释各部分的作用。除了底层机器码的生成,这可能是本教程中最耗时的解析环节。一旦掌握此部分的逻辑,你便能举一反三理解其他 CUDA 代码。因此,我们会放慢节奏详细讲解。该代码主要分为两部分:上半部分是 GELU_kernel,即实际执行计算的设备端内核(Device Kernel)。它将被加载至 GPU 执行并行计算并输出结果。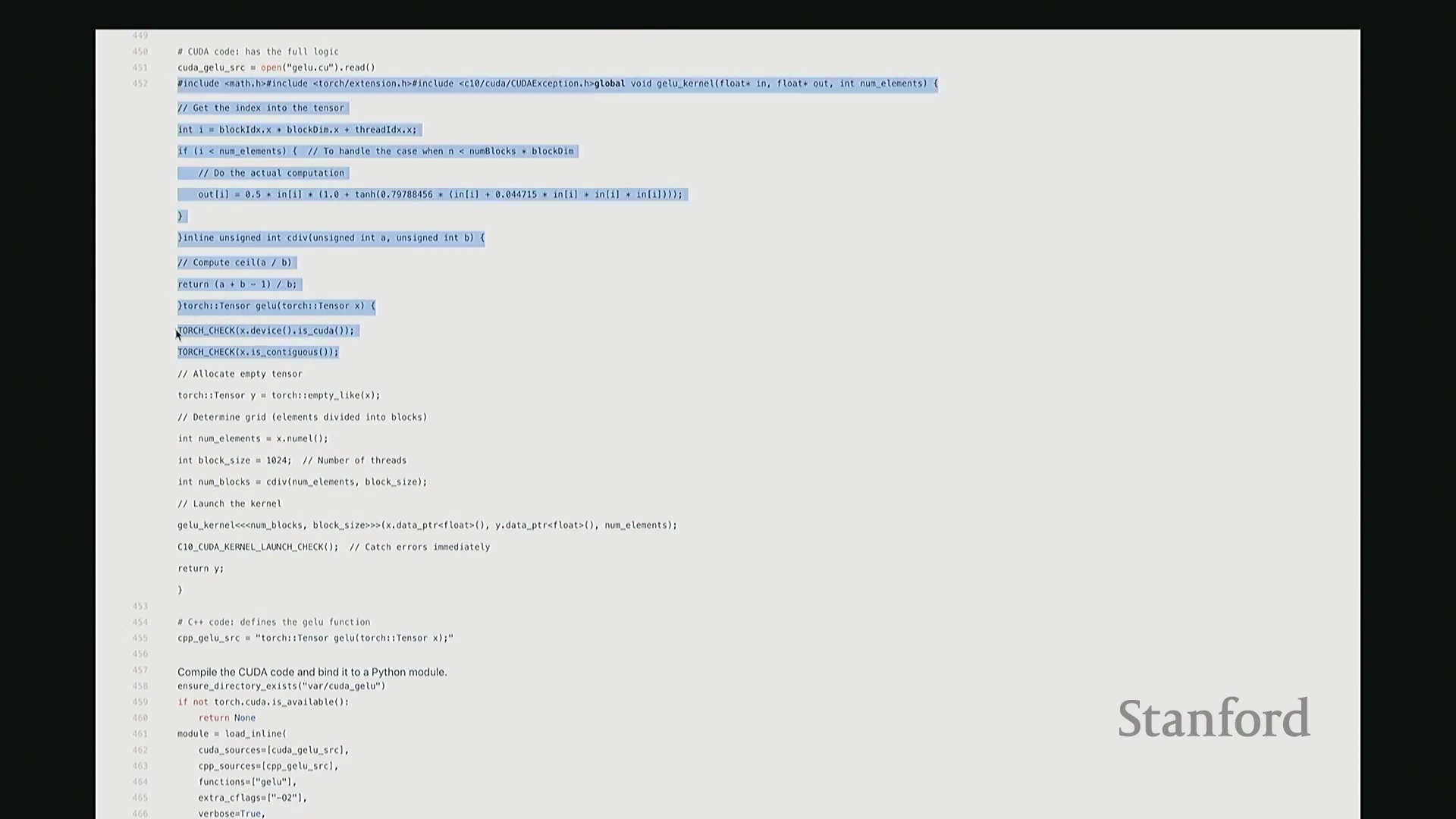 下半部分的
下半部分的 GELU 函数则是一个主机端包装函数(Host Wrapper Function)。它运行于 CPU,负责配置环境、分配内存并协调内核在 GPU 上的启动。我们首先从主机端包装函数开始。在编写 CUDA 或 Triton 代码时,通常需完成两项关键检查。哦,稍等,后面有同学提问……抱歉,我暂时没看到。好的,问题已解决,这很容易调整。确认大家都能看清屏幕,很好。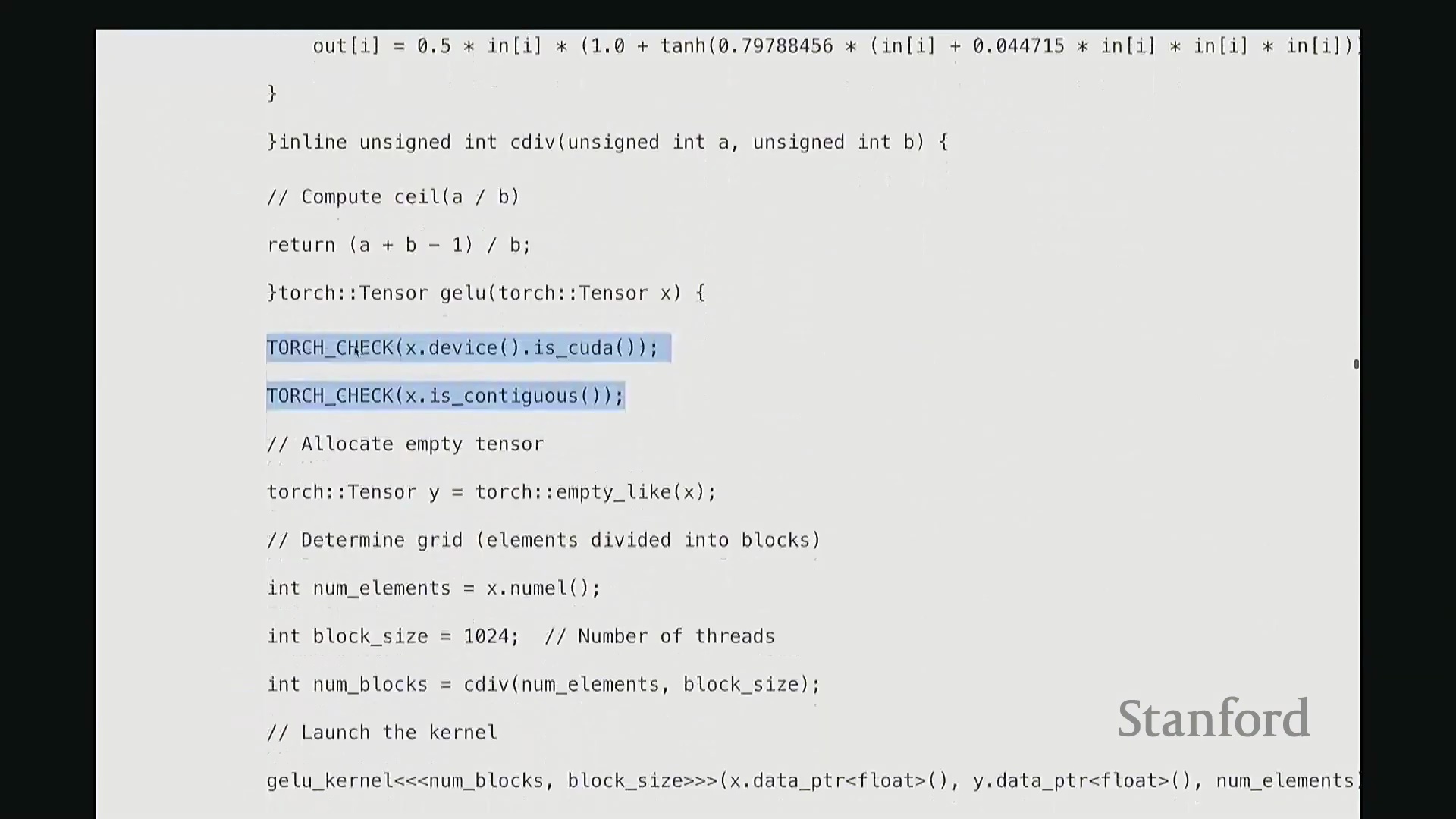 现在继续。
现在继续。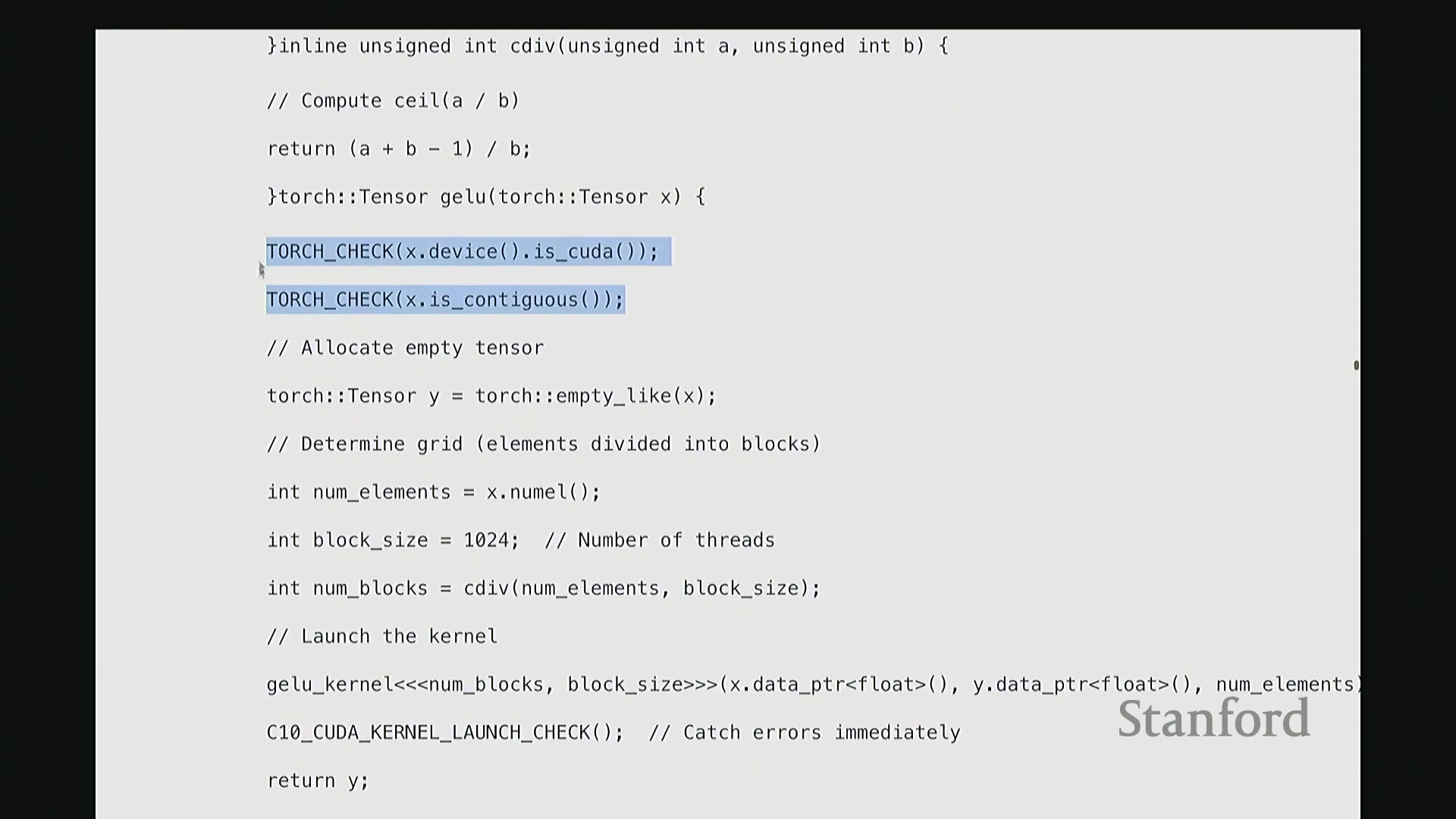
回到 GELU 函数,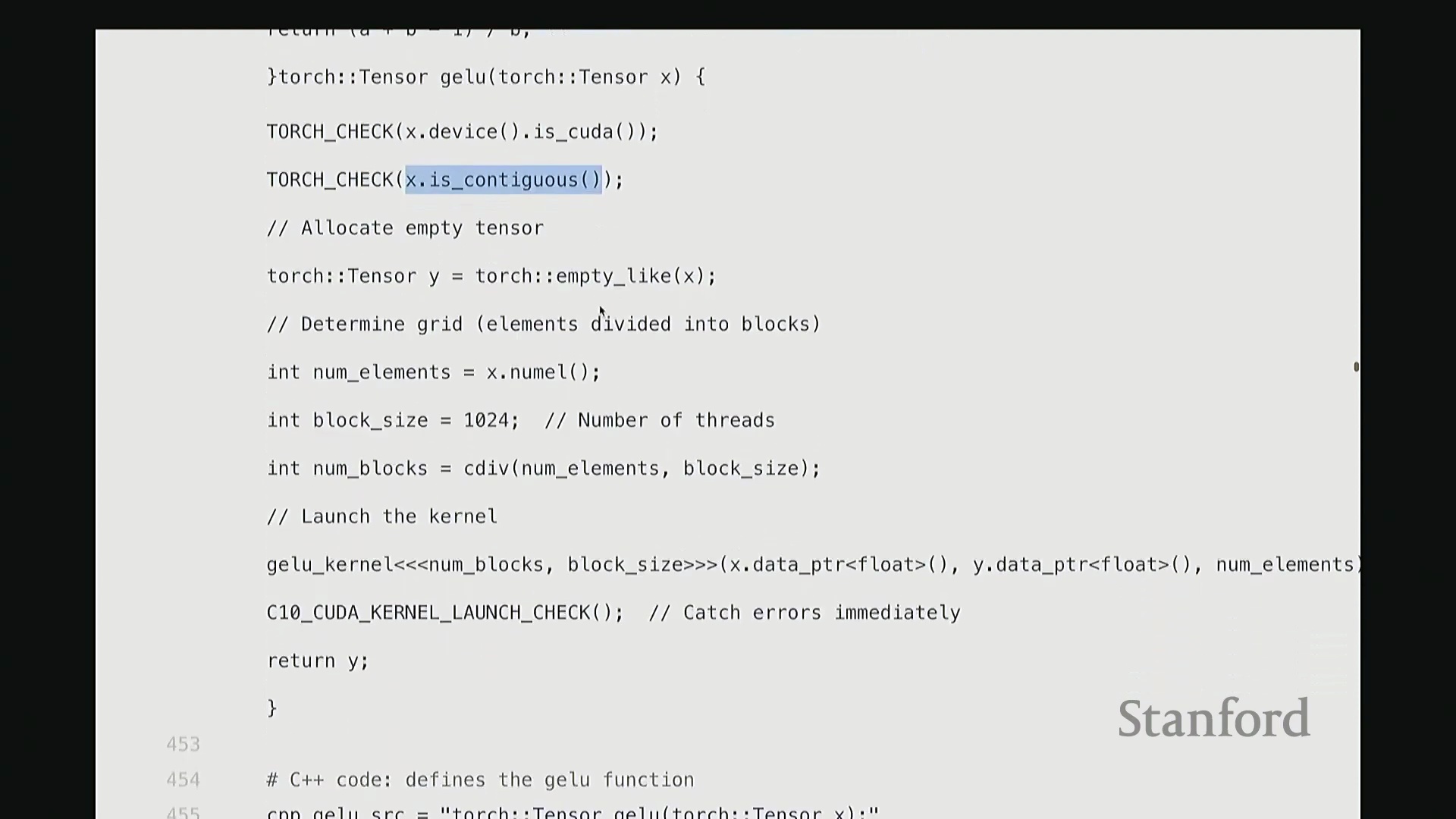 我们必须执行两项关键检查。首先,验证输入张量
我们必须执行两项关键检查。首先,验证输入张量 X 是否已分配至 GPU 设备(Device),即它必须是 CUDA 张量(CUDA Tensor)。若数据仍在 CPU 内存中,后续操作将无法执行。其次,确保 X 在内存中是连续的(Contiguous)。这意味着张量数据必须存储在物理地址连续的内存块中。由于内核在进行索引计算时,会依赖连续内存的线性偏移假设进行指针运算,若内存不连续,通用内核将无法正确寻址,几乎无法以通用方式处理。
因此,在计算 GeLU 时,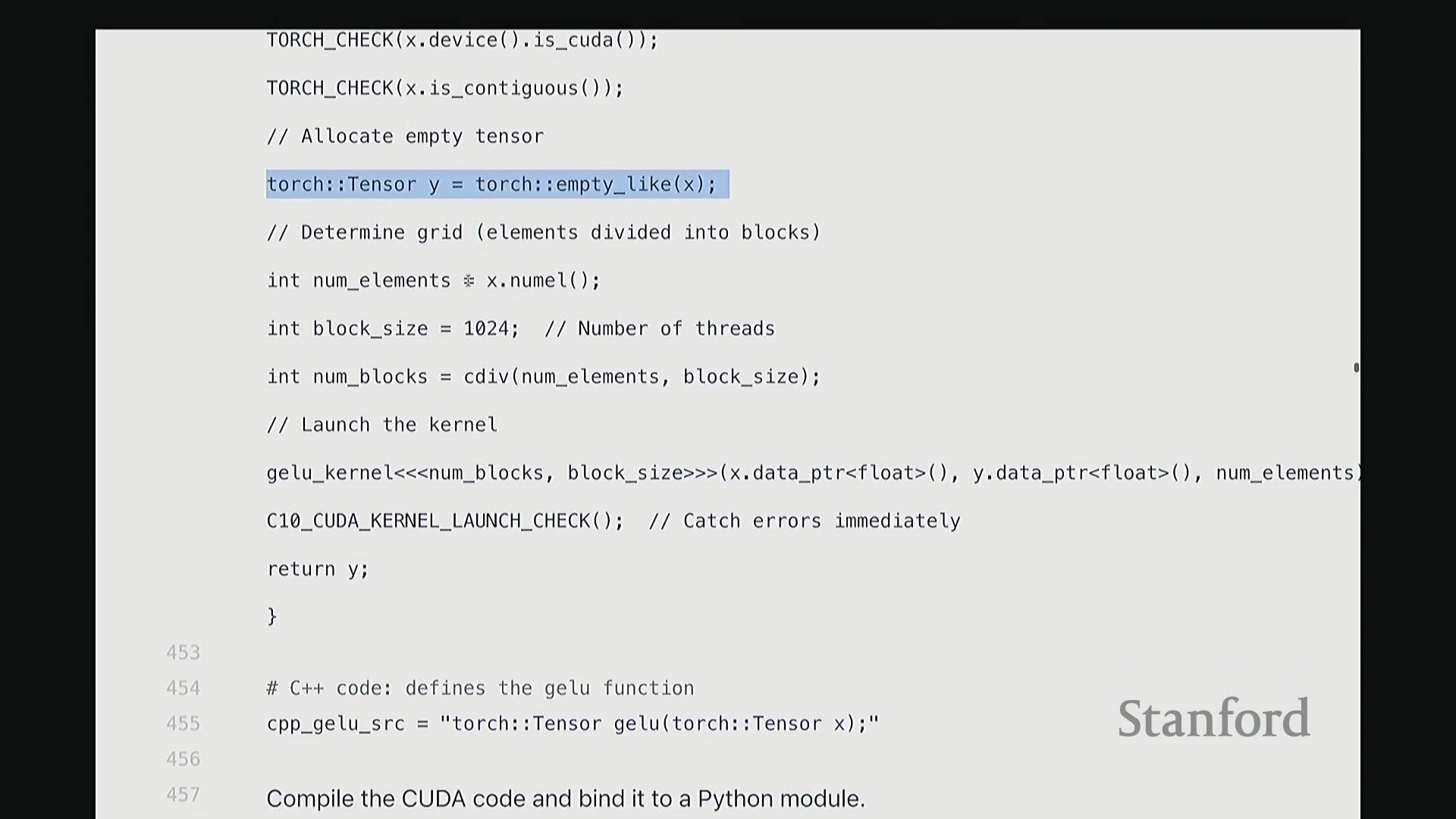 我们接收输入
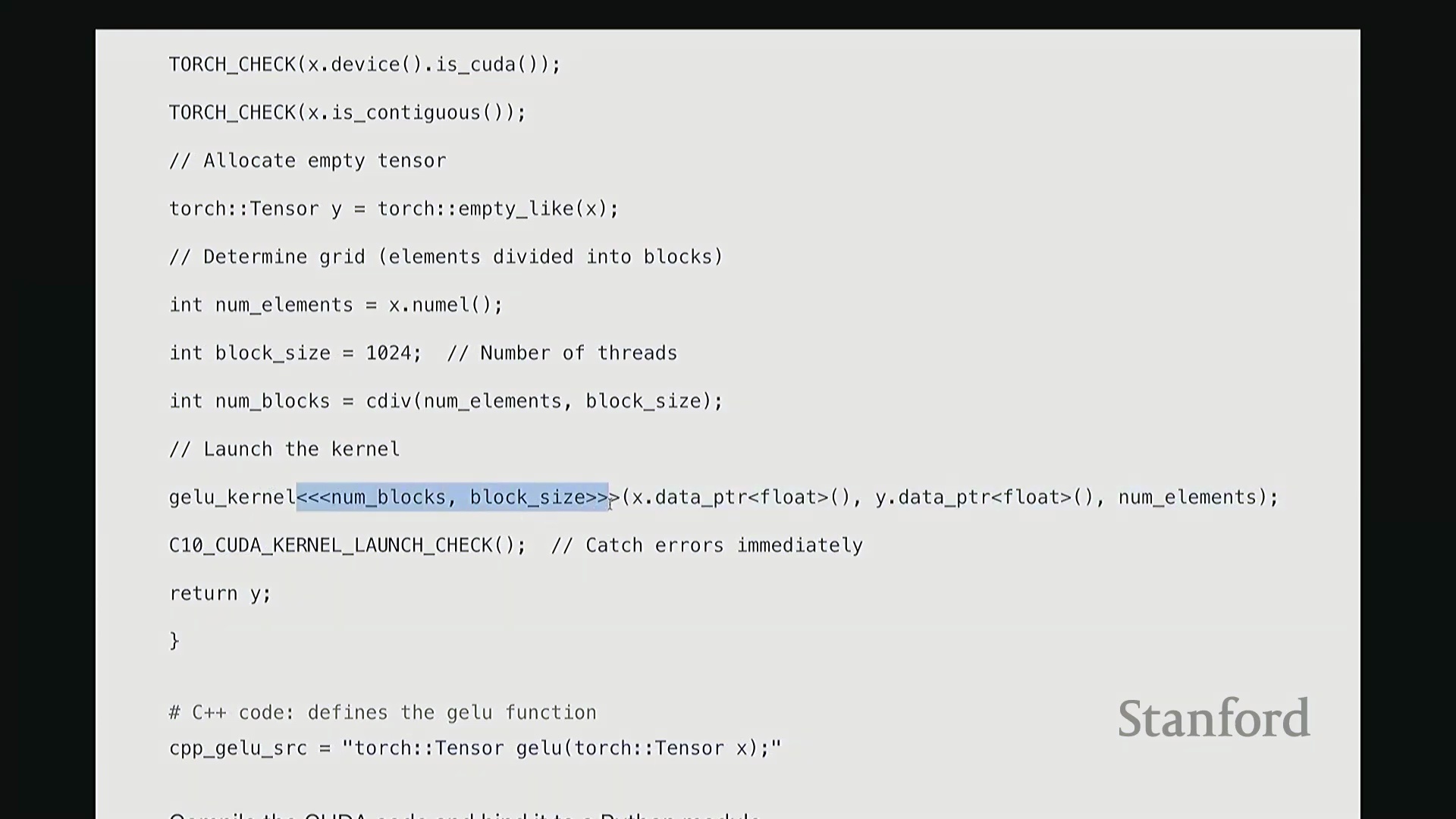
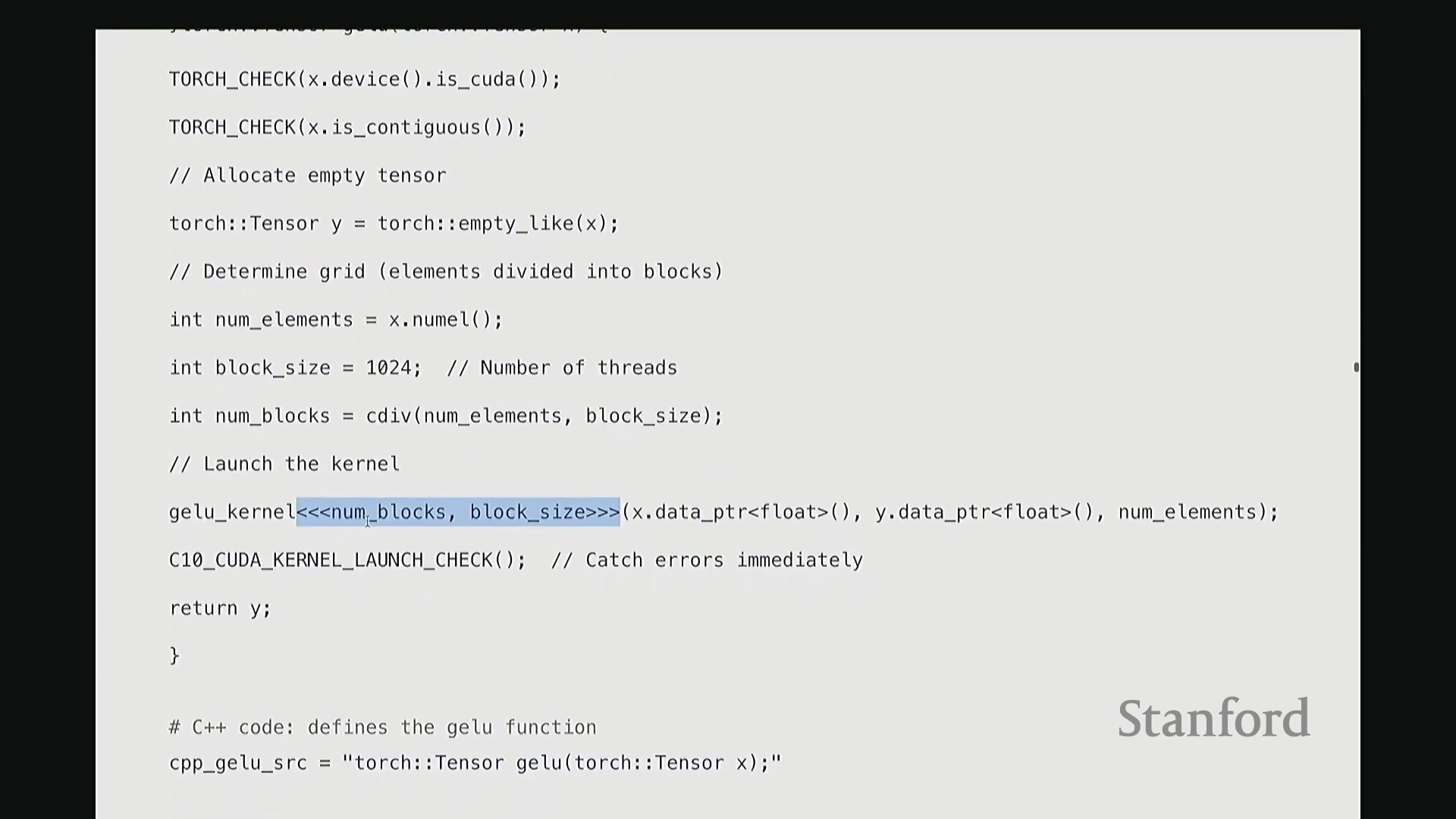
我们接收输入 X 并生成输出 Y,需预先分配输出内存。通过 Y = torch.empty_like(X) 即可创建与 X 形状相同的未初始化张量。该函数仅分配对应维度的内存空间并返回指针。此处特意使用 empty 而非 zeros,以跳过不必要的内存清零操作。由于内核随后会直接覆盖写入数据,无需预先初始化零值。这是一个微小的性能优化,但值得养成习惯。接下来,在所有 CUDA 编程中都必须配置的参数是线程网格(Grid)的维度。我们需要计算:输入数据的总元素数、每个线程块(Thread Block)的大小(即包含的线程数),以及所需的总线程块数量。计算线程块数量时,我使用 cdiv(向上取整除法(Ceiling Division))。其逻辑为总元素数除以块大小后向上取整。向上取整至关重要,它能确保当总元素数无法被块大小整除时,剩余元素仍能被分配到一个线程块中处理。我们需取上界(Ceil)而非下界(Floor)。完成这些基础配置与参数记录后,即可启动内核。调用 GELU_kernel<<<grid_size, block_size>>> 时,三重尖括号语法用于指定网格尺寸与块尺寸。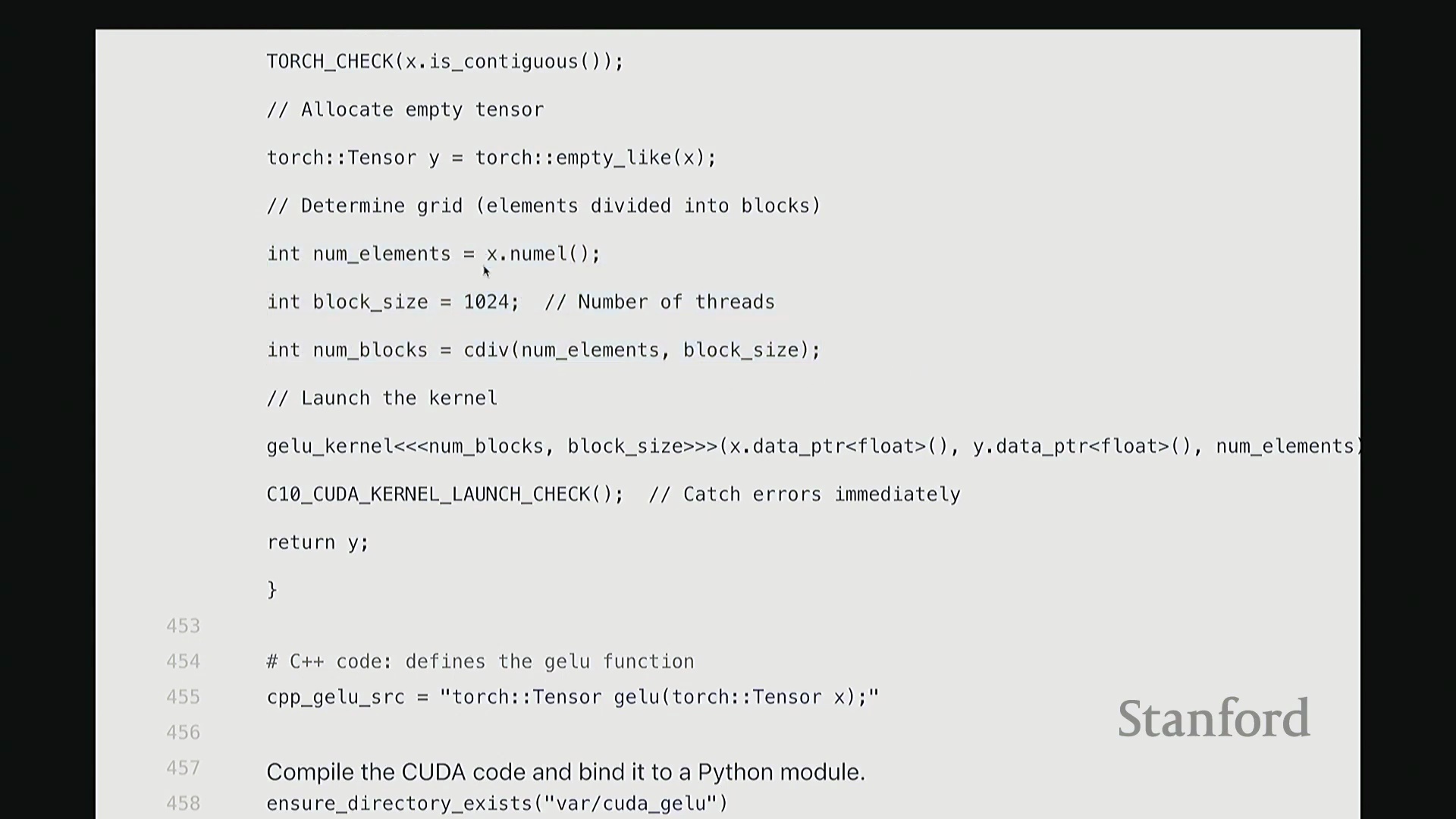 该配置将作为内核启动参数(Kernel Launch Configuration)传递。随后,函数传入指向输入
该配置将作为内核启动参数(Kernel Launch Configuration)传递。随后,函数传入指向输入 X 和输出 Y 的设备内存指针(Device Pointers)(而非数据本身),以及总元素数 n,用于在内核中计算边界条件。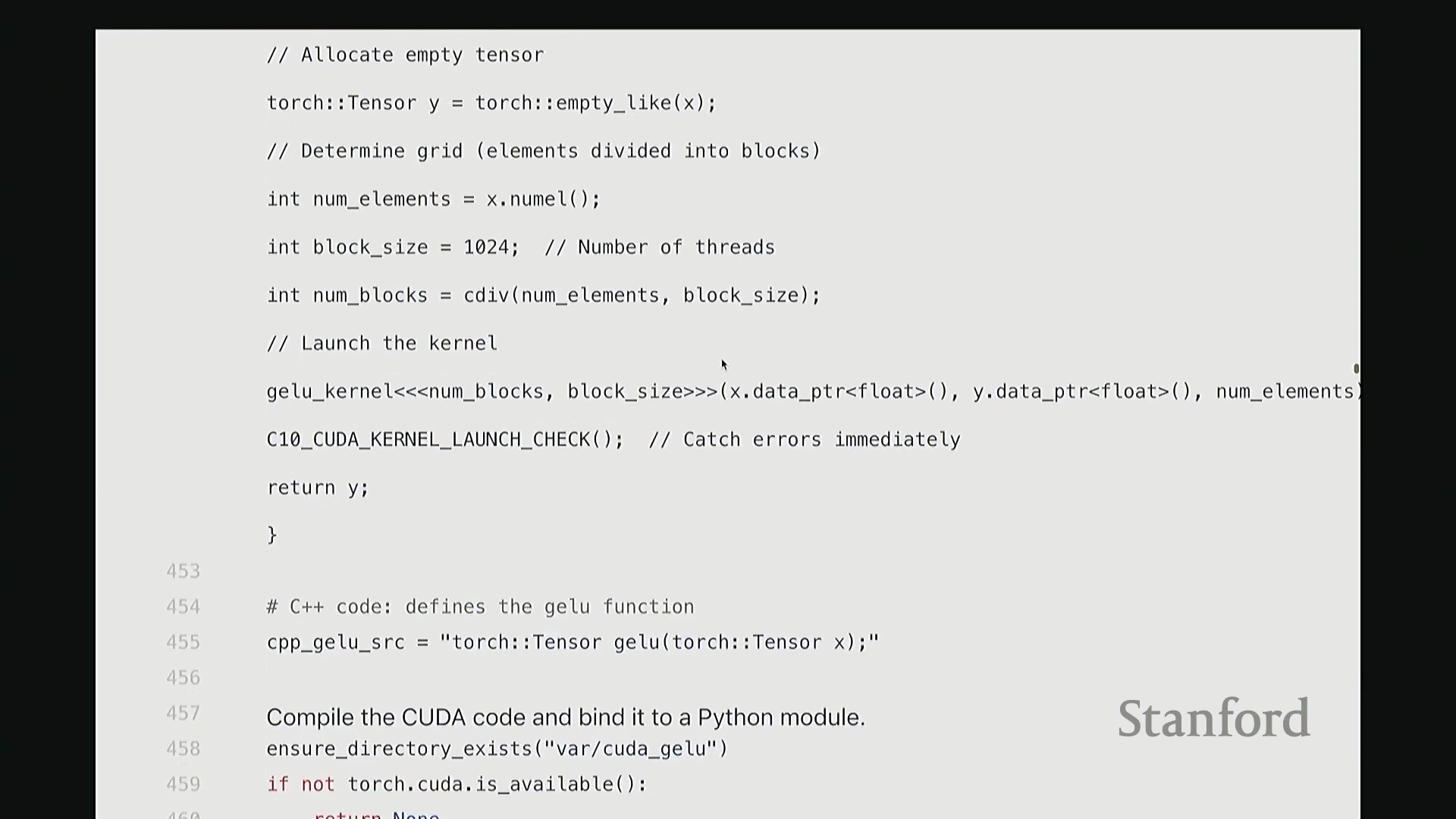
设备内核:索引计算与边界检查
现在深入设备端内核的实现。我们定义 __global__ void GELU_kernel,它接收输入/输出指针以及元素总数 n。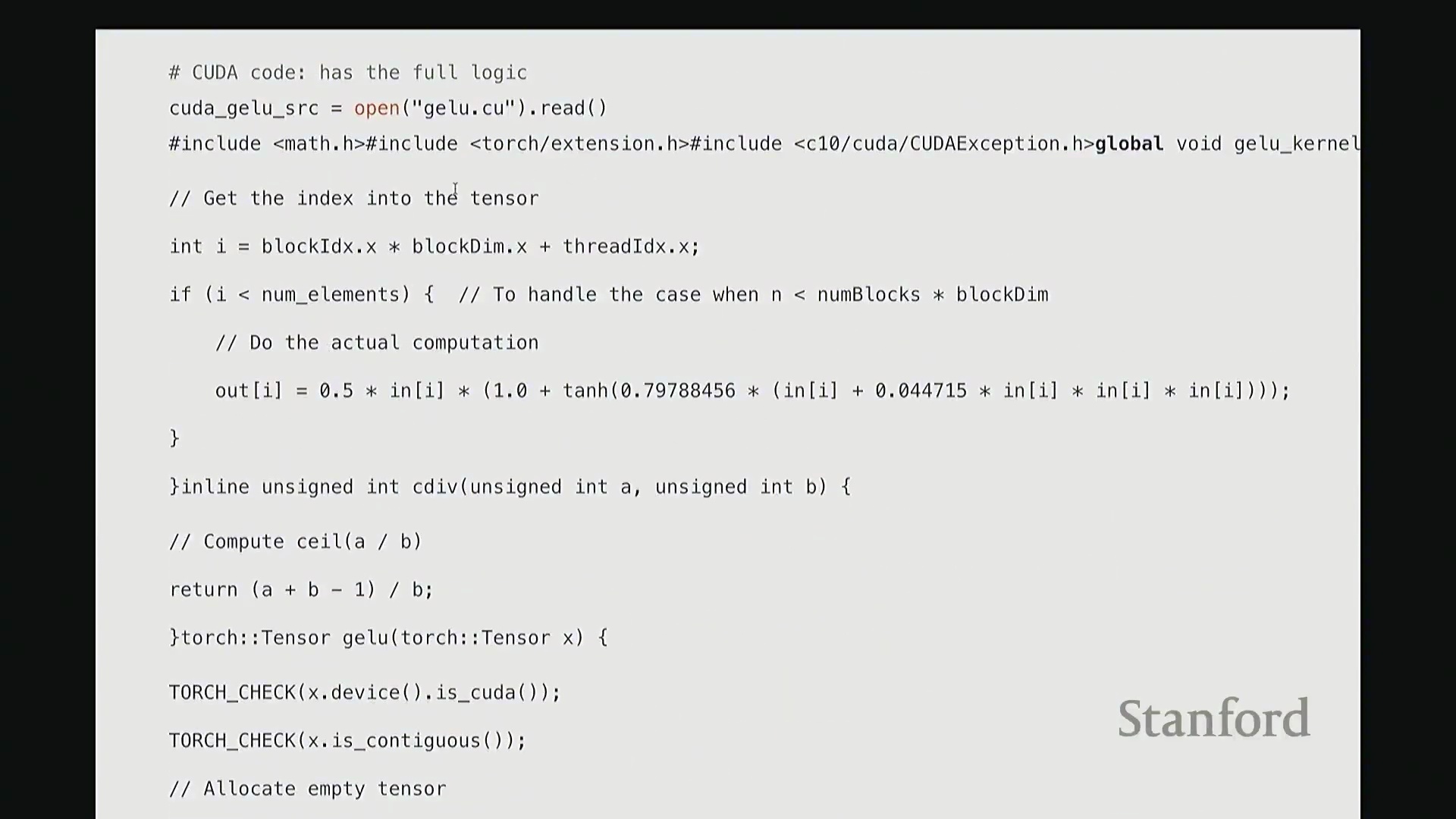
__global__ 是 CUDA 特有的关键字,用于声明该函数为可在主机端调用、在设备端执行的 GPU 内核函数。内核的核心逻辑是:让每个线程独立处理张量中的一个元素 i。但 i 并非直接作为参数传入。系统不会自动告知线程其处理的全局索引,因此需手动计算。计算方法如下:首先获取当前线程的块索引(Block Index),一维情况下为 blockIdx.x。将其乘以线程块尺寸 blockDim.x,即可得到当前线程块在网格中的全局起始偏移量。随后加上当前线程在块内的线程索引(Thread Index) threadIdx.x。块起始偏移量与块内偏移量相加,即得到该线程对应的全局线性索引 i。这是 CUDA 编程中计算全局索引的标准模式。接下来的边界检查(Boundary Check)同样至关重要,它广泛存在于所有健壮的 CUDA 代码中。CUDA 硬件不会自动拦截内存越界访问。因此,计算完索引 i 后,必须显式检查其是否小于总元素数 n。由于线程块大小通常大于剩余未处理元素数,处于块末尾的多余线程可能会访问非法内存地址。通过添加 if (i < n) 条件守卫(Guard),可确保越界线程直接返回,避免非法内存读写。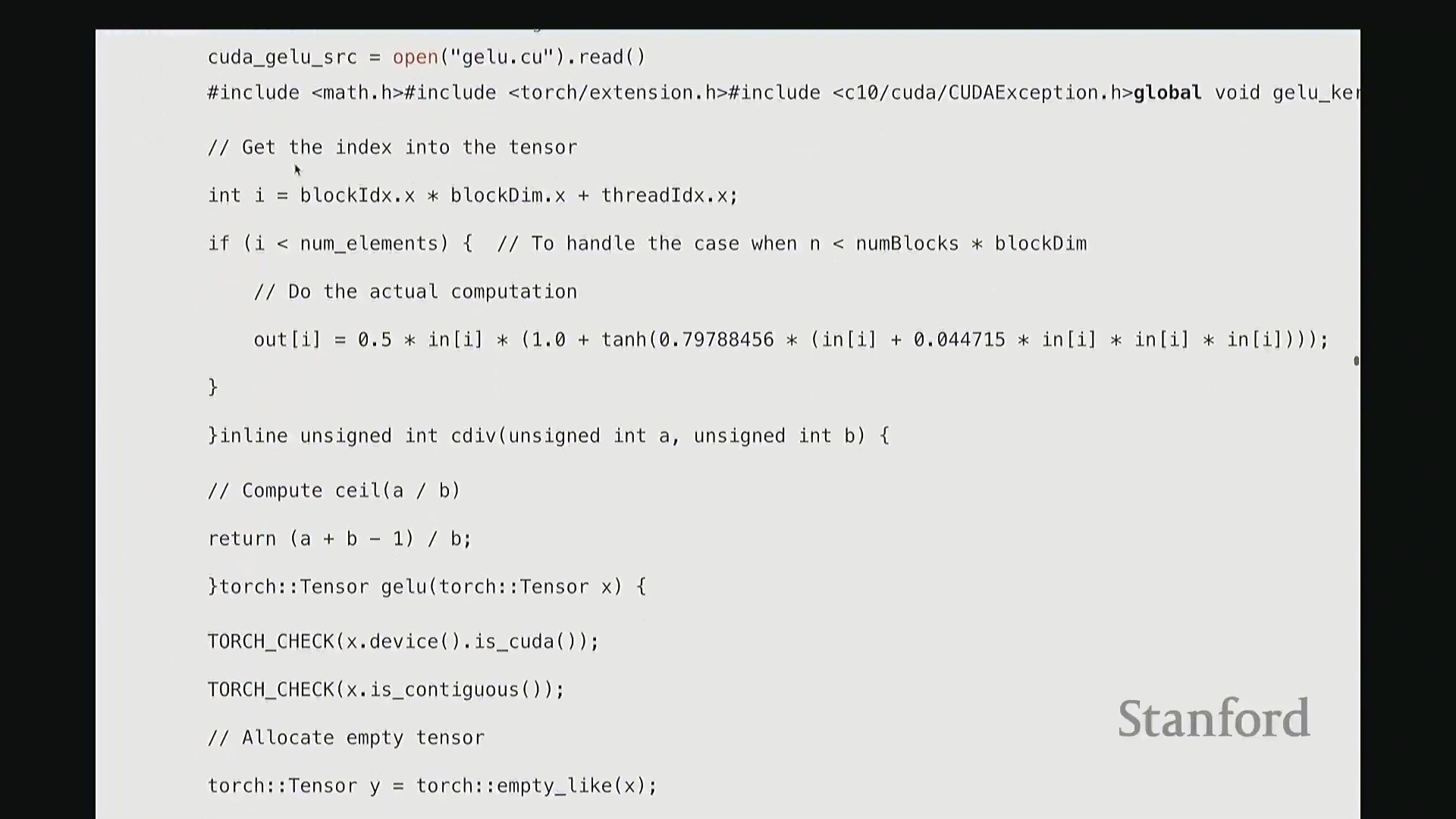
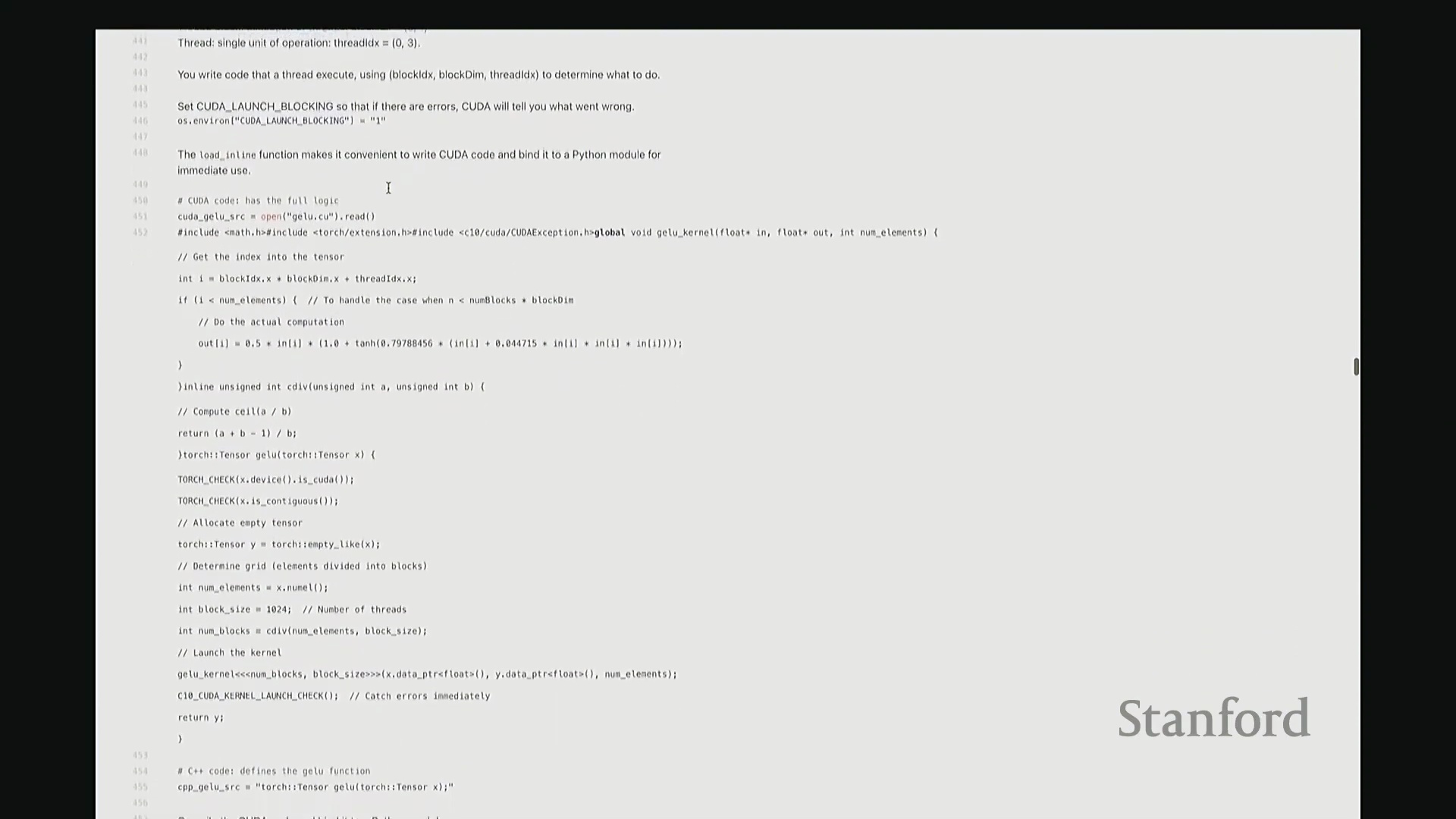
内联编译与性能基准测试
抱歉,刚才有同学问文件扩展名的问题。是的,CUDA 代码通常以 .cu 结尾,它在语法上兼容标准 C++,但包含 CUDA 特有的扩展关键字与运行时 API。这仅是文件约定的差异,并无特殊之处。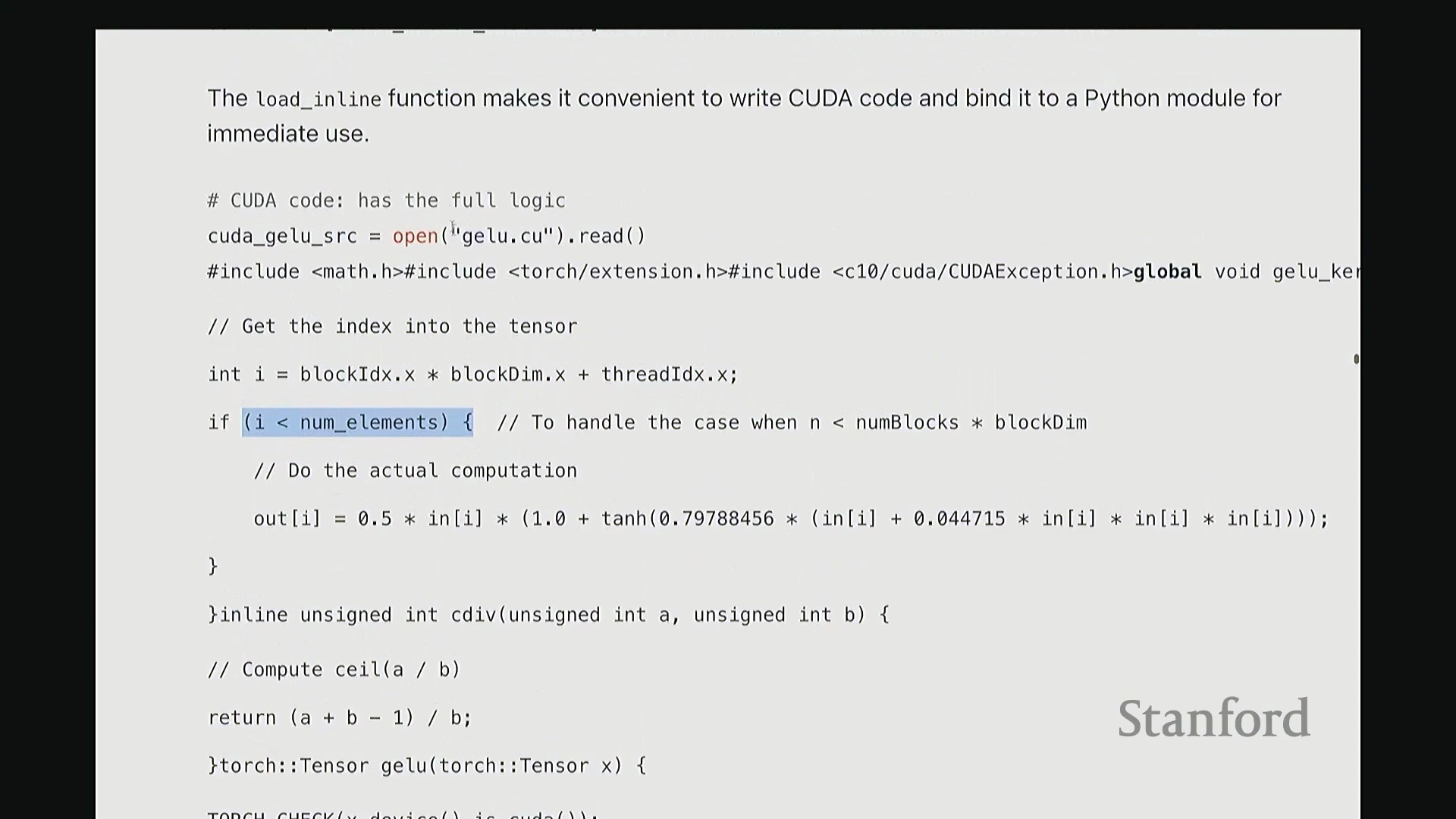 回到内核内部,实际计算逻辑非常直观:通过输入指针
回到内核内部,实际计算逻辑非常直观:通过输入指针 in 直接访问第 i 个元素 in[i],应用 GeLU 数学公式后,将结果写入输出指针 out[i]。借助指针算术运算,我们无需手动管理底层内存移动。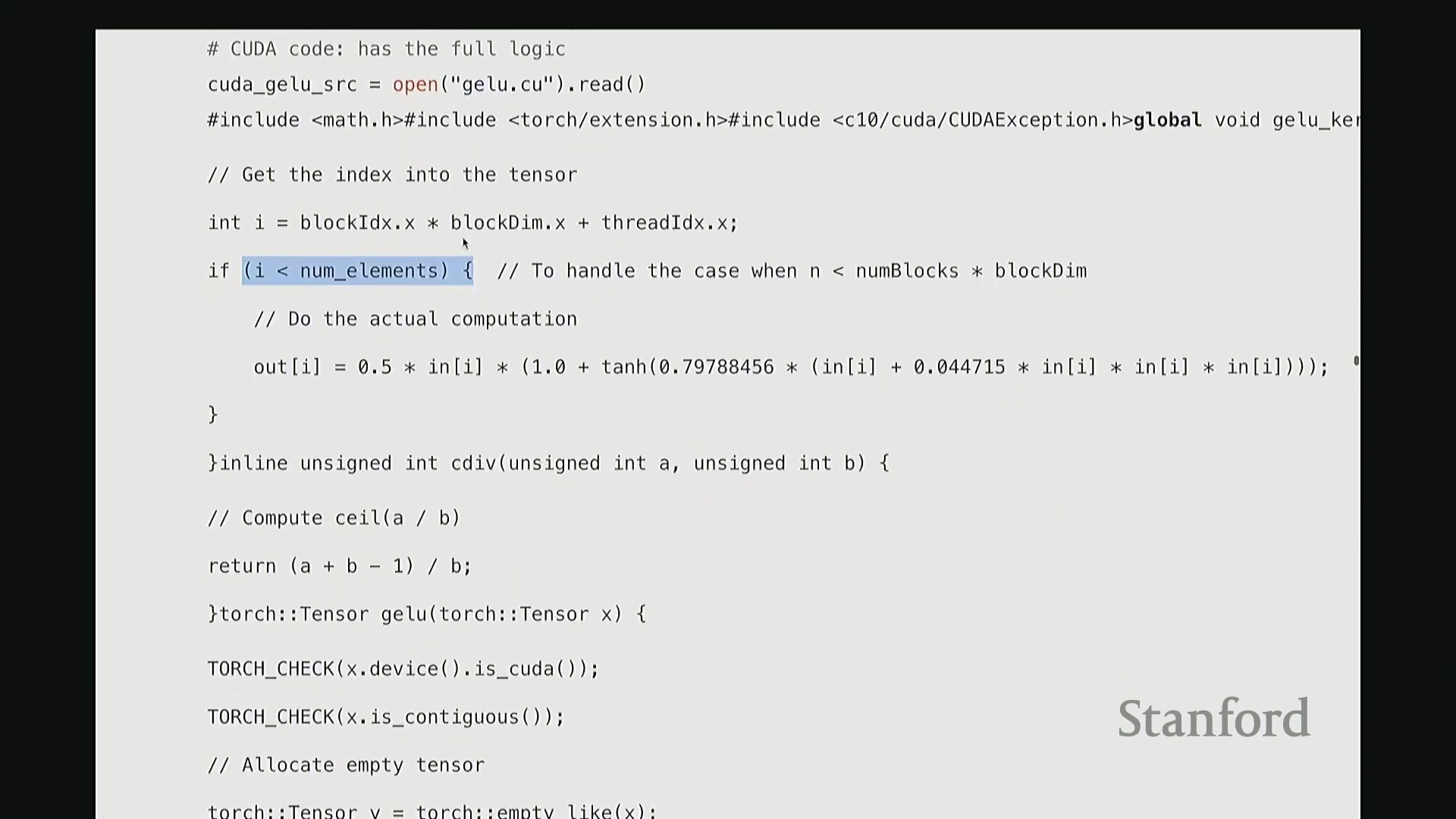
接下来是编译集成环节。利用 PyTorch 的扩展接口,我们可以将 C++/CUDA 源码以内联方式(Inline Compilation)直接嵌入 Python 脚本,并自动编译为可调用模块。这极大简化了开发流程,无需手动配置 Makefile 或运行命令行编译指令。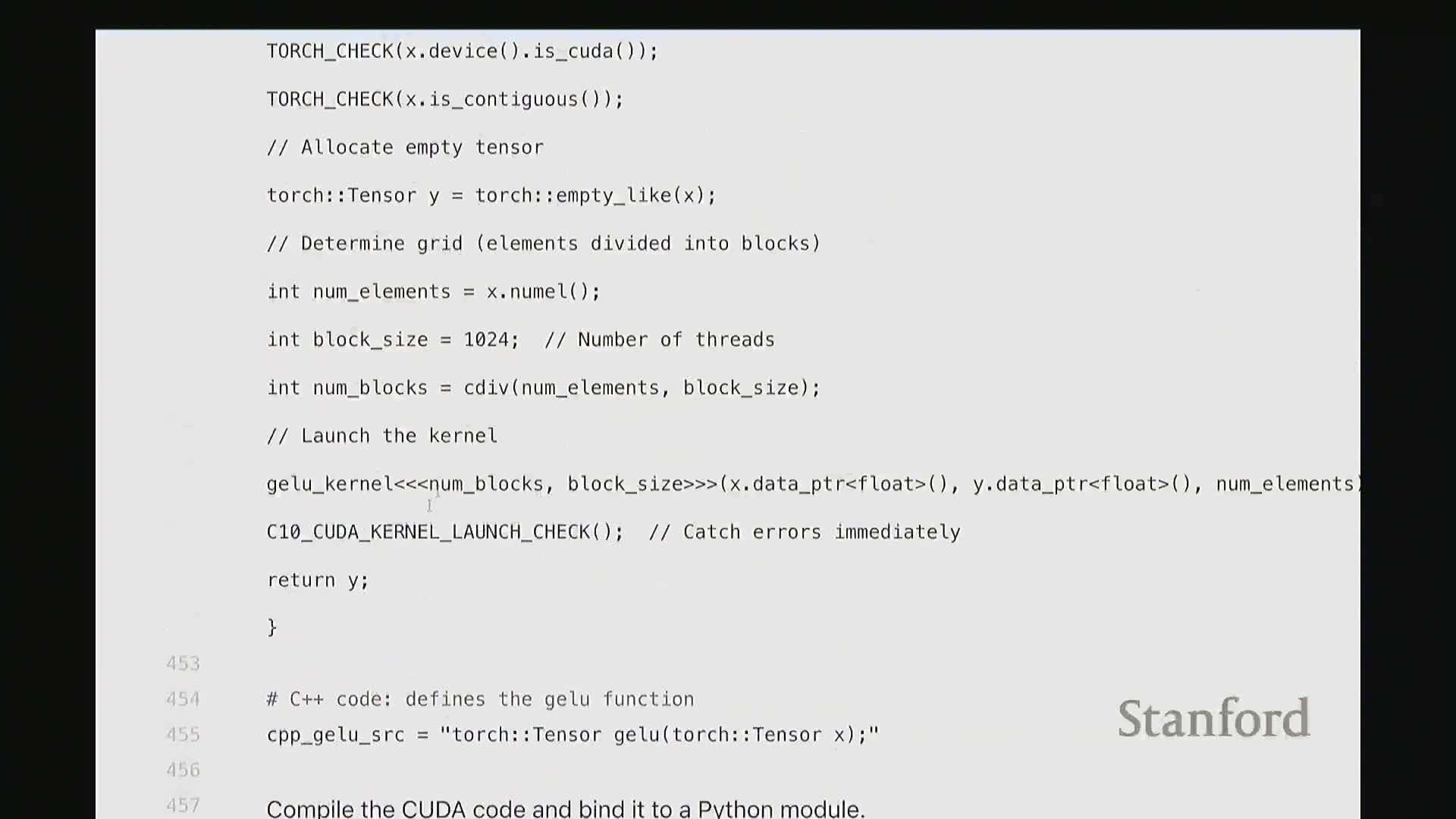 至此,
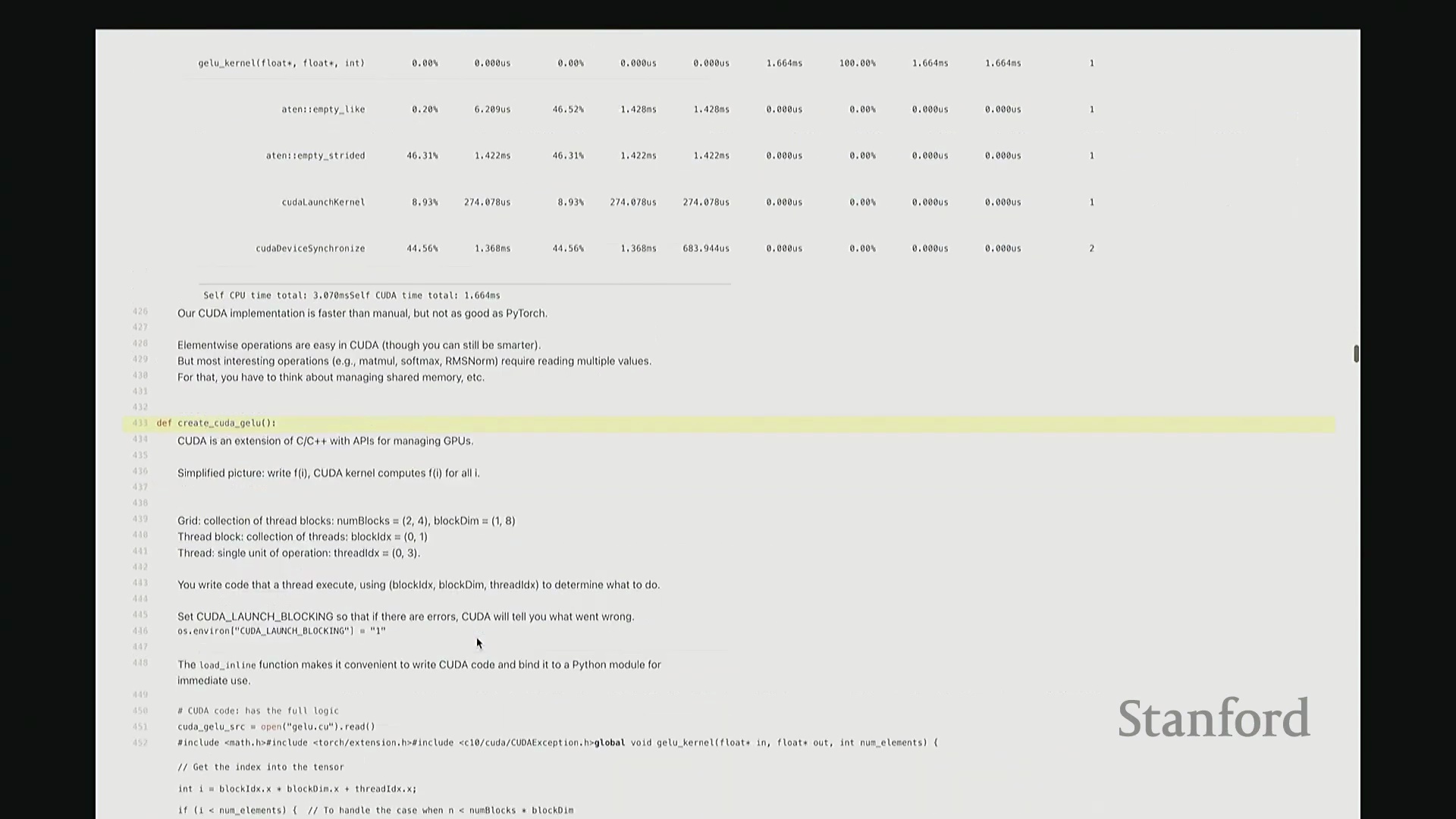
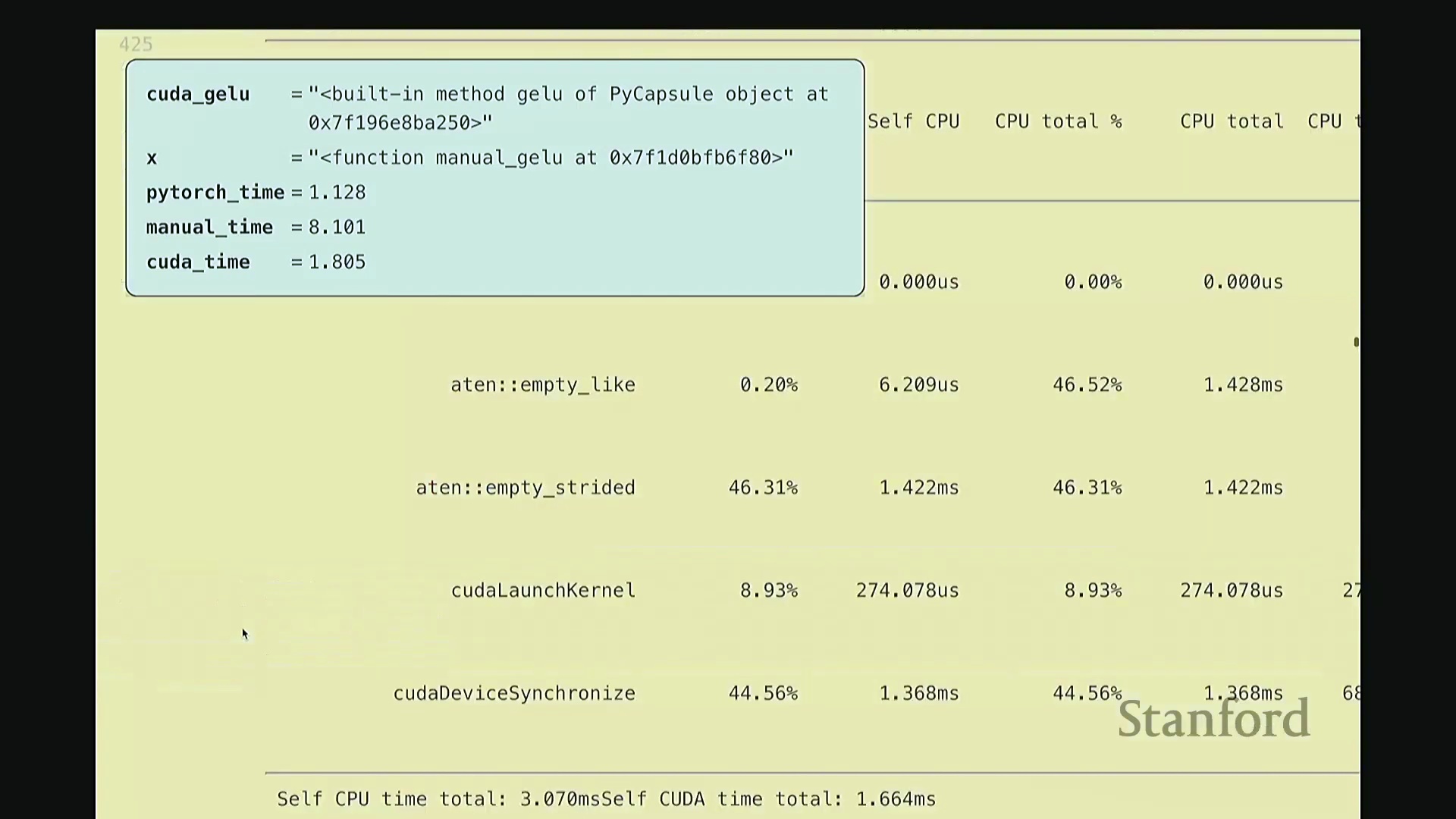
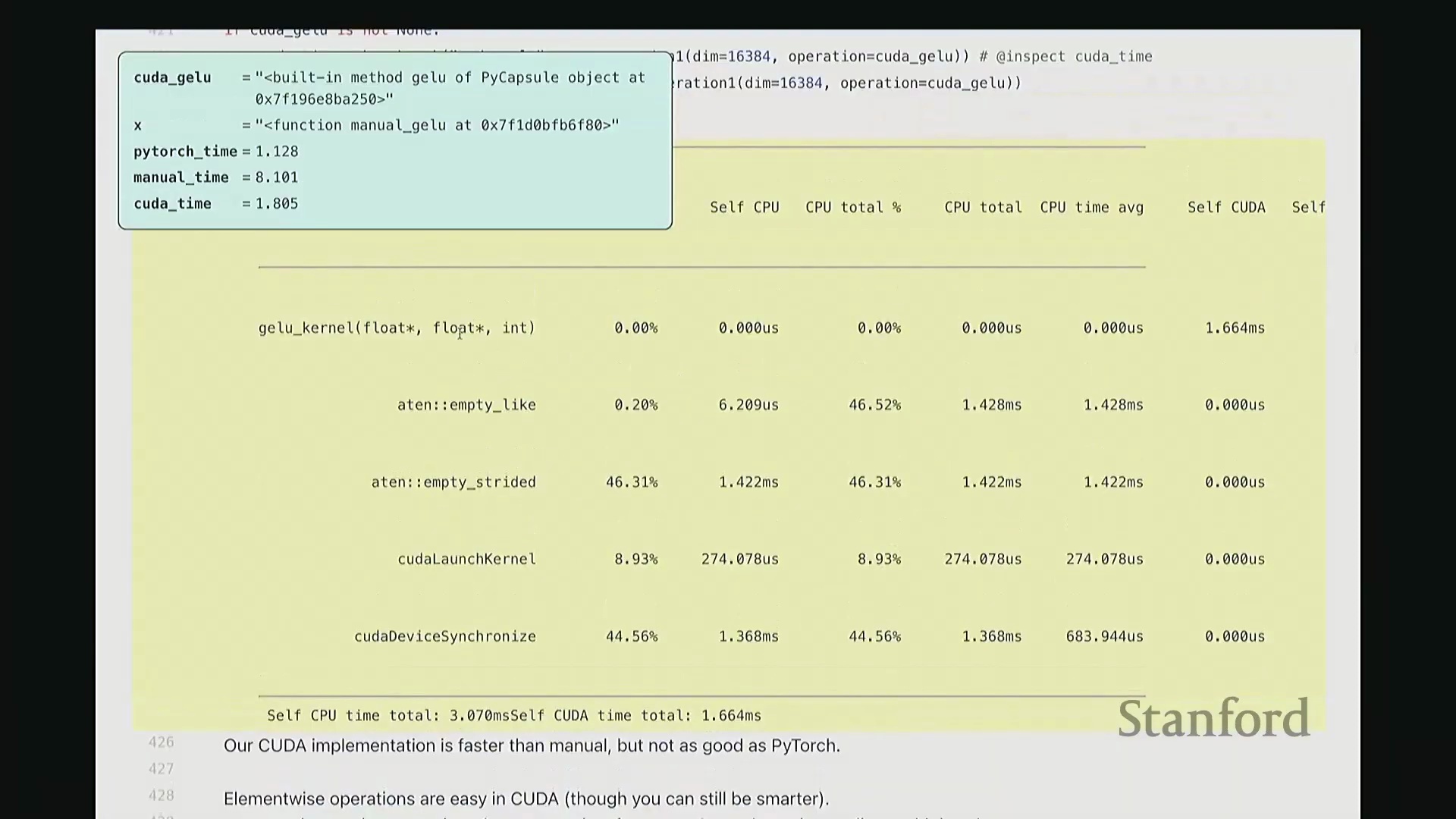
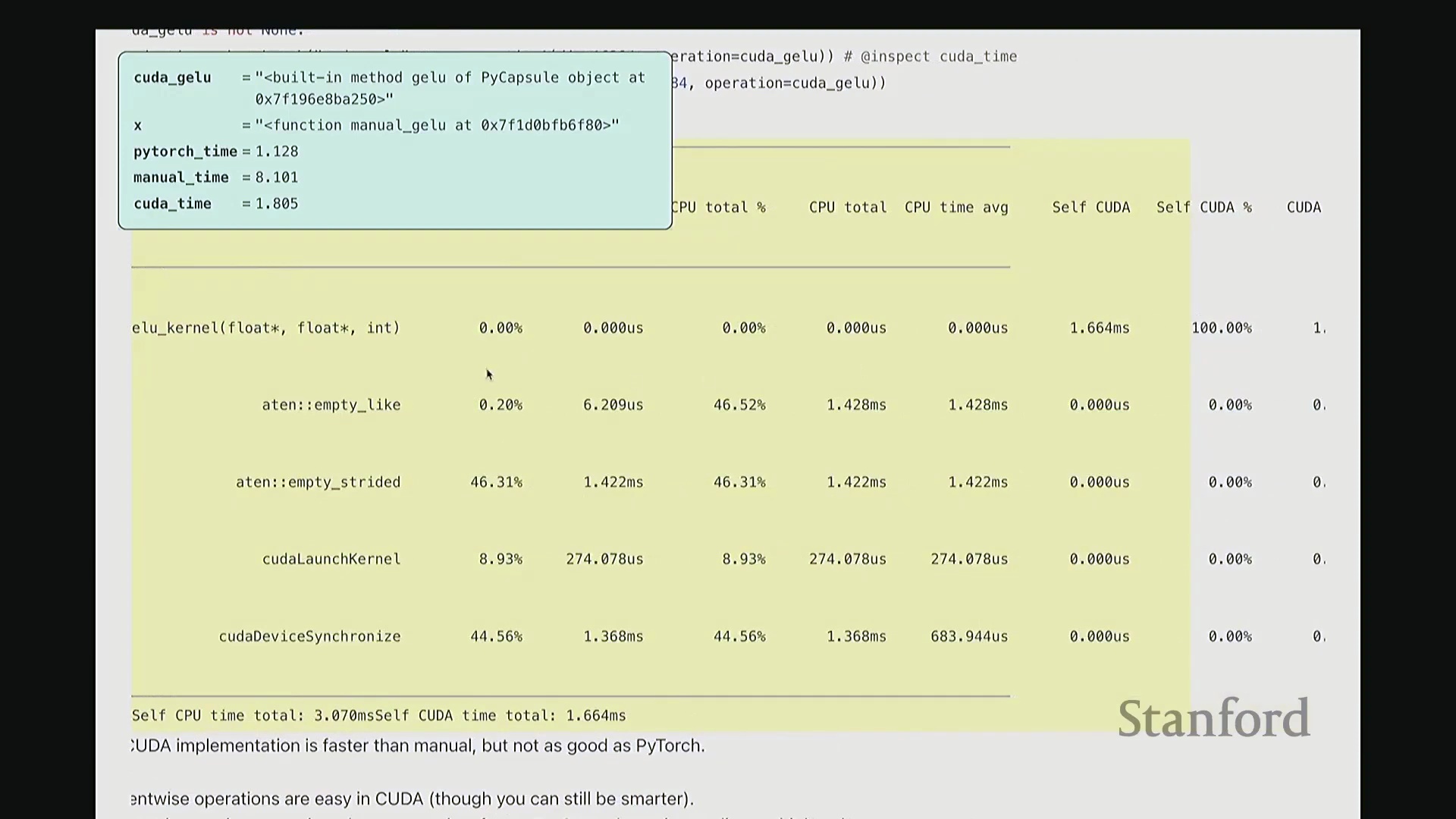
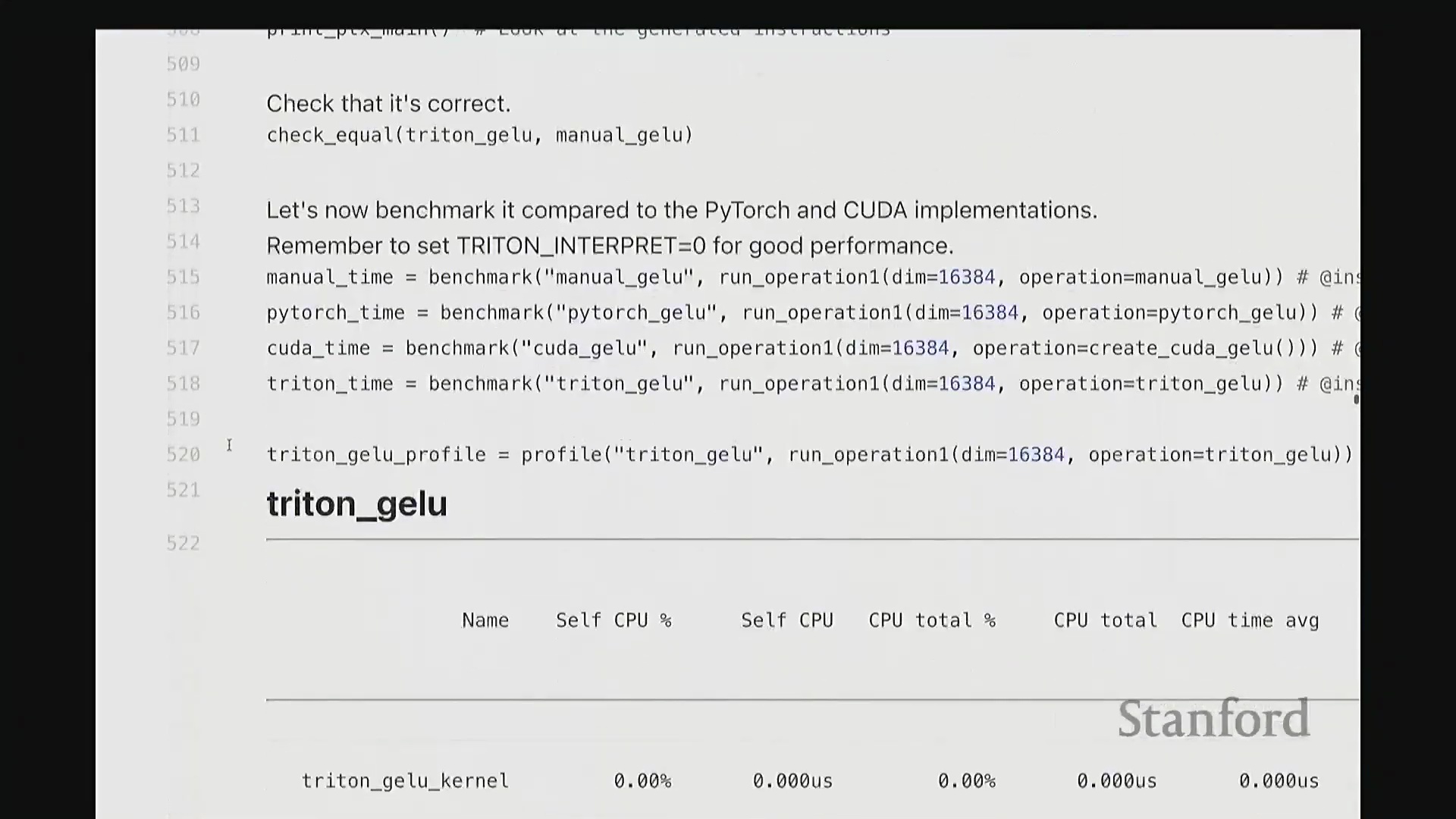
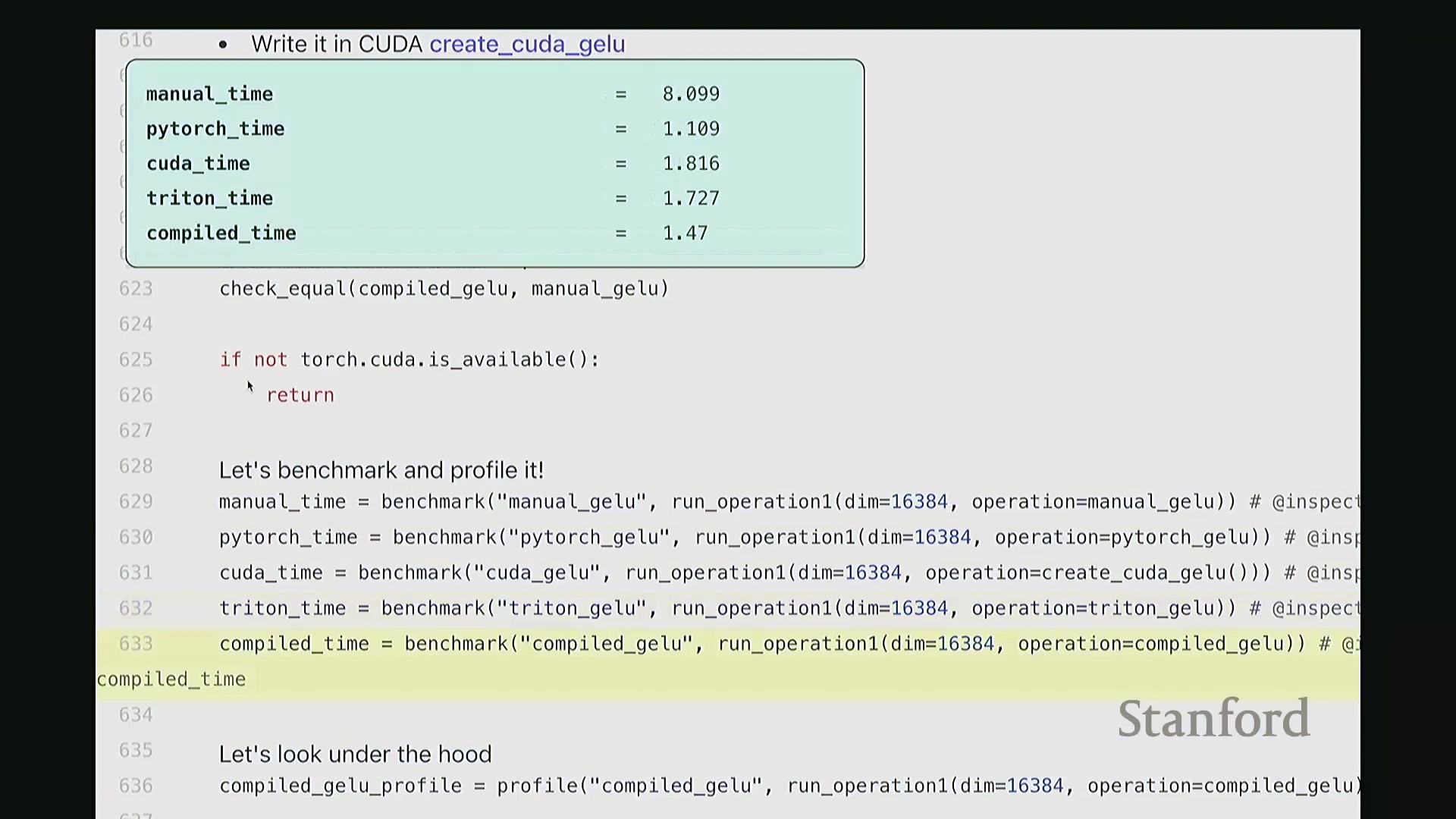
至此,cuda_gelu 函数定义完成。它底层通过 C 绑定(C Bindings)桥接 Python 与编译后的 CUDA 二进制代码,实现无缝调用。调用 cuda_gelu 后,我们首先验证其与手动实现 manual_gelu 的数值一致性。随后进行基准测试(Benchmarking)。已知 PyTorch 原生版本耗时约 1.1 毫秒,纯 Python 手动展开实现耗时 8.1 毫秒。现在揭晓我们手写 CUDA 版本的表现……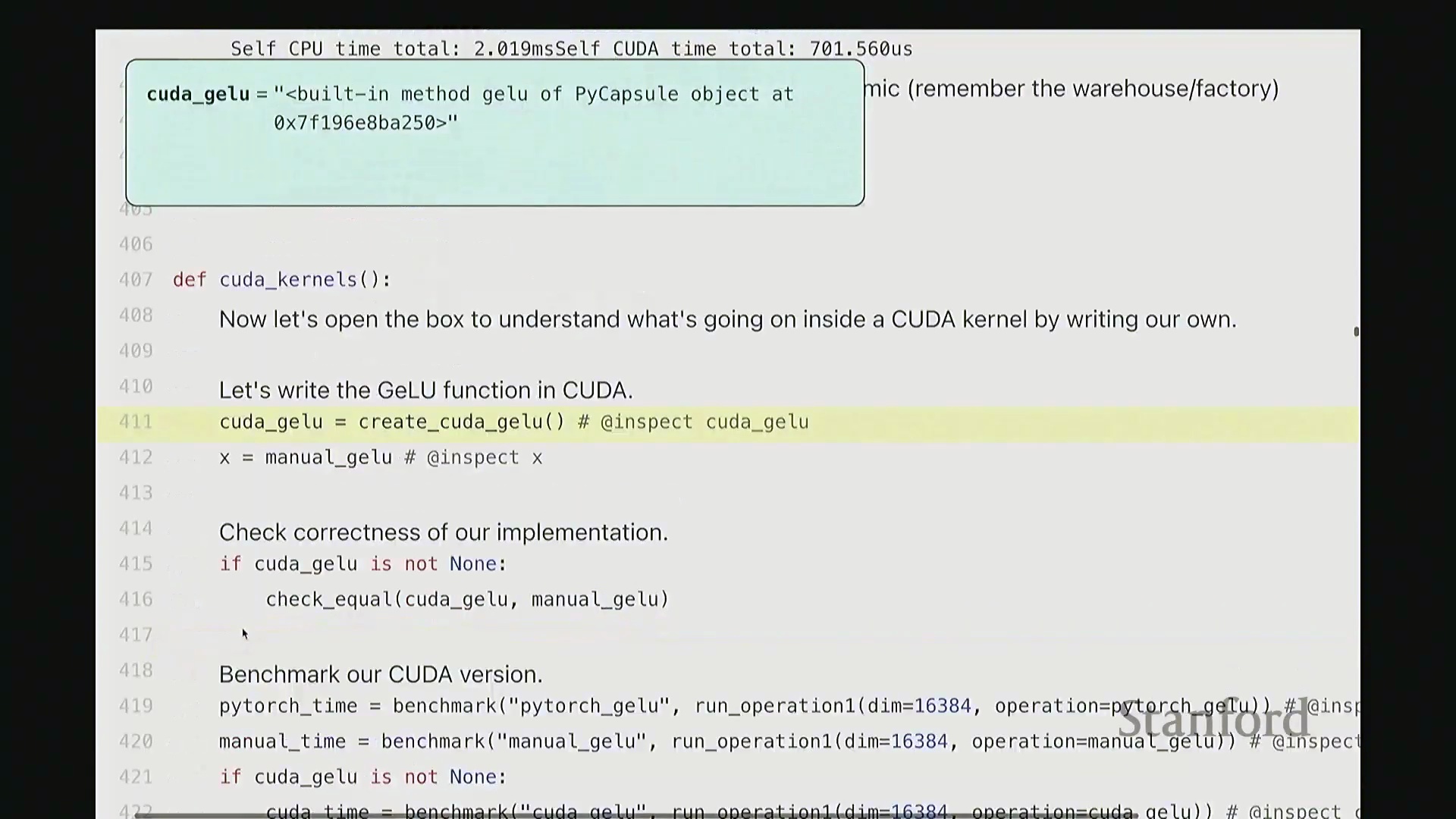 结果显示,CUDA 版本耗时降至 1.8 毫秒。尽管尚未超越 PyTorch 高度优化的原生实现,但已相当接近。从 8.1 毫秒优化至 1.8 毫秒(近 4.5 倍加速),考虑到代码实现相对基础,这一成果已十分出色。
结果显示,CUDA 版本耗时降至 1.8 毫秒。尽管尚未超越 PyTorch 高度优化的原生实现,但已相当接近。从 8.1 毫秒优化至 1.8 毫秒(近 4.5 倍加速),考虑到代码实现相对基础,这一成果已十分出色。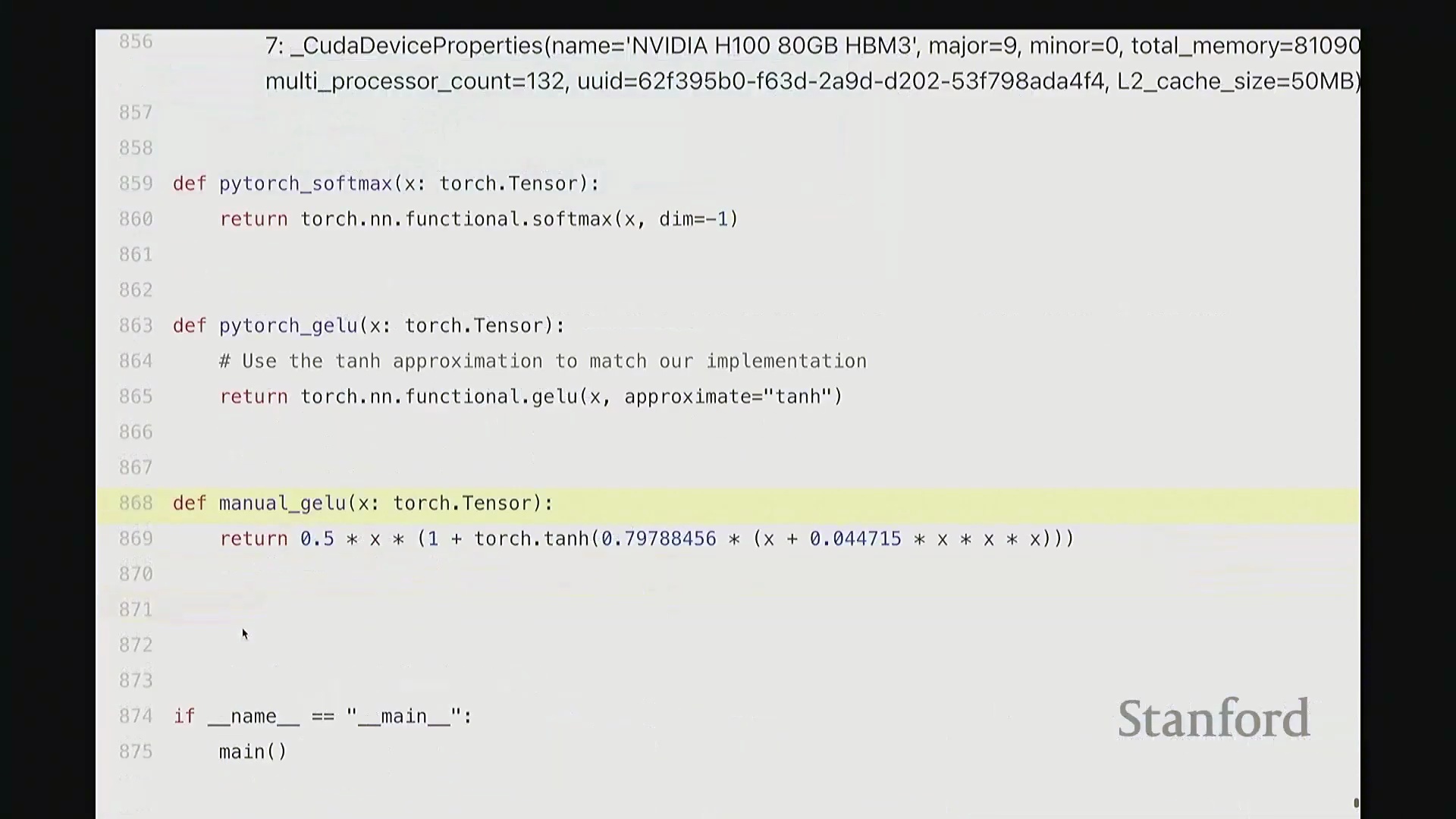
接着进行性能分析(Profiling)以观察底层调用栈。可见,核心计算确实调用了 GELU_kernel,即实际下发至 GPU 执行的内核。此外还包含少量的内存分配(Memory Allocation)、cudaLaunchKernel(内核启动)与 cudaDeviceSynchronize(设备同步)调用。关键在于,整个计算流程仅由单个 CUDA 内核主导,占据了 100% 的 GPU 计算时间,这正是内核融合(Kernel Fusion)所追求的理想状态。我们成功将多个逐元素操作融合为单一内核执行。总体而言表现优异。此类逐元素操作(Element-wise Operations)的 CUDA 实现相对直接。若你需实现自定义的新型非线性激活函数,可轻松照此模板编写。然而,涉及多值交互的操作(如归约计算(Reduction))则会复杂许多。后续作业中需实现的 Flash Attention 同样具备一定复杂度,但只要掌握基础范式,实现起来亦不会过于困难。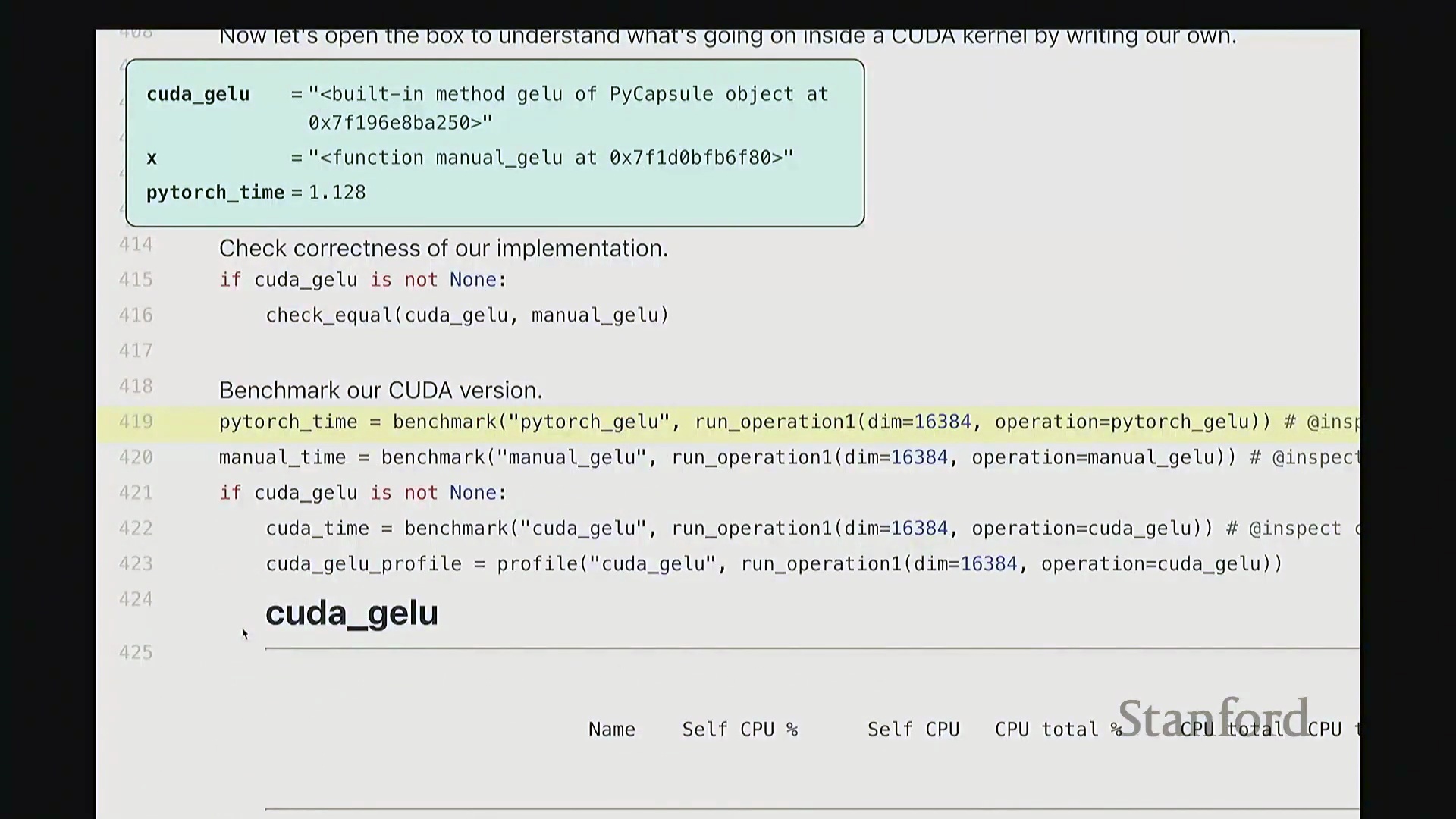
内存连续性与实现问答
关于此基础 CUDA 内核是否有疑问?请讲。好的,关于开头那段内存检查代码……问题核心是:若输入内存非连续(Non-contiguous)会怎样?在当前代码中,assert 会直接抛出断言错误(Assertion Error)。虽然理论上可编写支持非连续内存的复杂逻辑,但在实际深度学习框架中,张量分配默认即为连续内存。除非进行极底层的内存碎片化管理或高级定制优化,否则常规操作不会破坏内存连续性。因此,在绝大多数 CUDA 内核开发中,默认假设输入内存连续是安全且标准的做法。同学问:哪些操作会导致内存不连续?例如张量转置(Transpose)或切片操作会改变步长(Stride),生成非连续视图(Non-contiguous View)。此时必须显式调用 .contiguous() 方法,强制在内存中重新分配连续副本,方可安全传入内核。对。大致如此。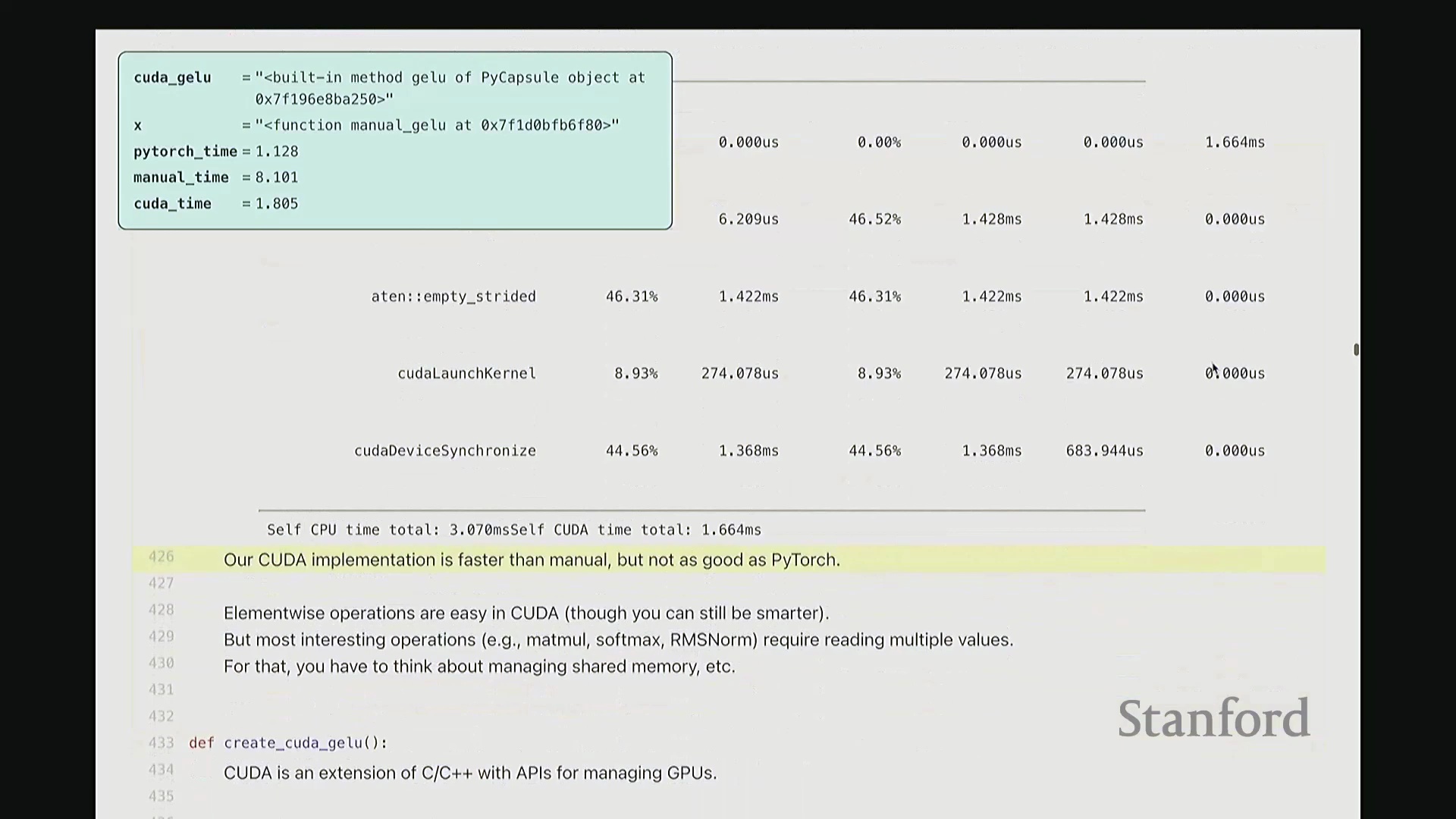


内存连续性与朴素内核性能
有同学提问。没错,问题在于:如果执行了转置(Transpose)操作,内存布局将不再连续(Contiguous)。当对数据进行反转或重排(例如列优先存储布局)时,逻辑索引与物理内存地址之间会出现跳跃。 实际上,除了转置(Transpose)、视图(View)或维度重排(Dimension Reshaping)等少数情况外,张量内存通常都是连续的。这些非连续情况完全可以在外层包装函数(Wrapper Function)中统一处理,只需在传入内核前确保张量连续即可。对于绝大多数矩阵运算,你无需过度担忧。因此,答案是否定的(通常不需要特别处理)。
实际上,除了转置(Transpose)、视图(View)或维度重排(Dimension Reshaping)等少数情况外,张量内存通常都是连续的。这些非连续情况完全可以在外层包装函数(Wrapper Function)中统一处理,只需在传入内核前确保张量连续即可。对于绝大多数矩阵运算,你无需过度担忧。因此,答案是否定的(通常不需要特别处理)。
如果调整线程块大小(Block Size)会怎样?选择不同的块大小确实会引入 GPU 架构层面的考量。例如,线程块数量是否足以填满(饱和(Saturate))流多处理器(Streaming Multiprocessor, SM)?每个线程块内的计算负载(Workload)是否充足?这两点都会影响性能。但我推测,当块大小达到一定阈值(如 1024)后,继续增大可能不再带来显著收益。因为当前实现未涉及高级优化,纯粹是逐元素操作(Element-wise Operations),对于这种极简场景,块大小的敏感度较低。是的。

核心问题在于:我们那个朴素实现(Naive Implementation)(手动展开的逐元素操作)为何如此缓慢?是因为缺乏内核融合(Kernel Fusion)吗?因为它本质上是在 GPU 上串行执行一系列细粒度操作。这符合常规算法逻辑吗?我不确定。但根本原因并非数据在 CPU 与 GPU 间频繁传输。实际上,张量 X 始终驻留在 GPU 设备上。我们也是在 GPU 上分配的内存。但问题在于,数据并不会始终缓存在流多处理器(SM)的高速缓存中。一旦执行 X ** 2 这类操作,PyTorch 就会启动独立的 CUDA 内核。该乘法操作会将向量从全局内存(Global Memory)读取至 SM,计算完成后再次写回全局内存。因此,性能瓶颈主要源于全局内存(DRAM)与 SM 之间频繁的数据搬运开销,而非主机到设备(CPU-to-GPU)的传输延迟。当然,若错误地将张量置于 CPU 内存,则会叠加额外的跨设备传输开销。好的。
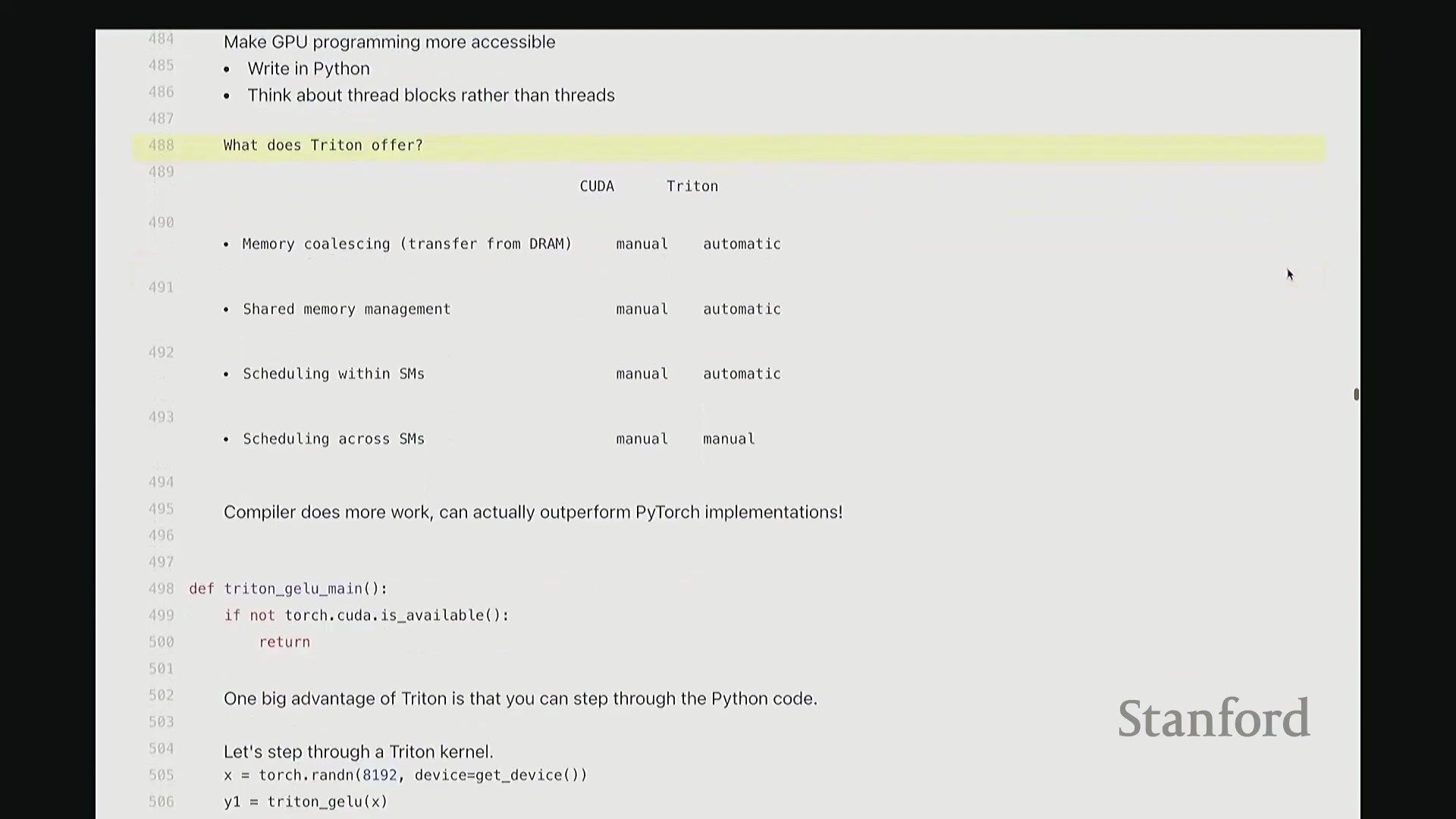
Triton 简介:基于 Python 的 GPU 领域特定语言
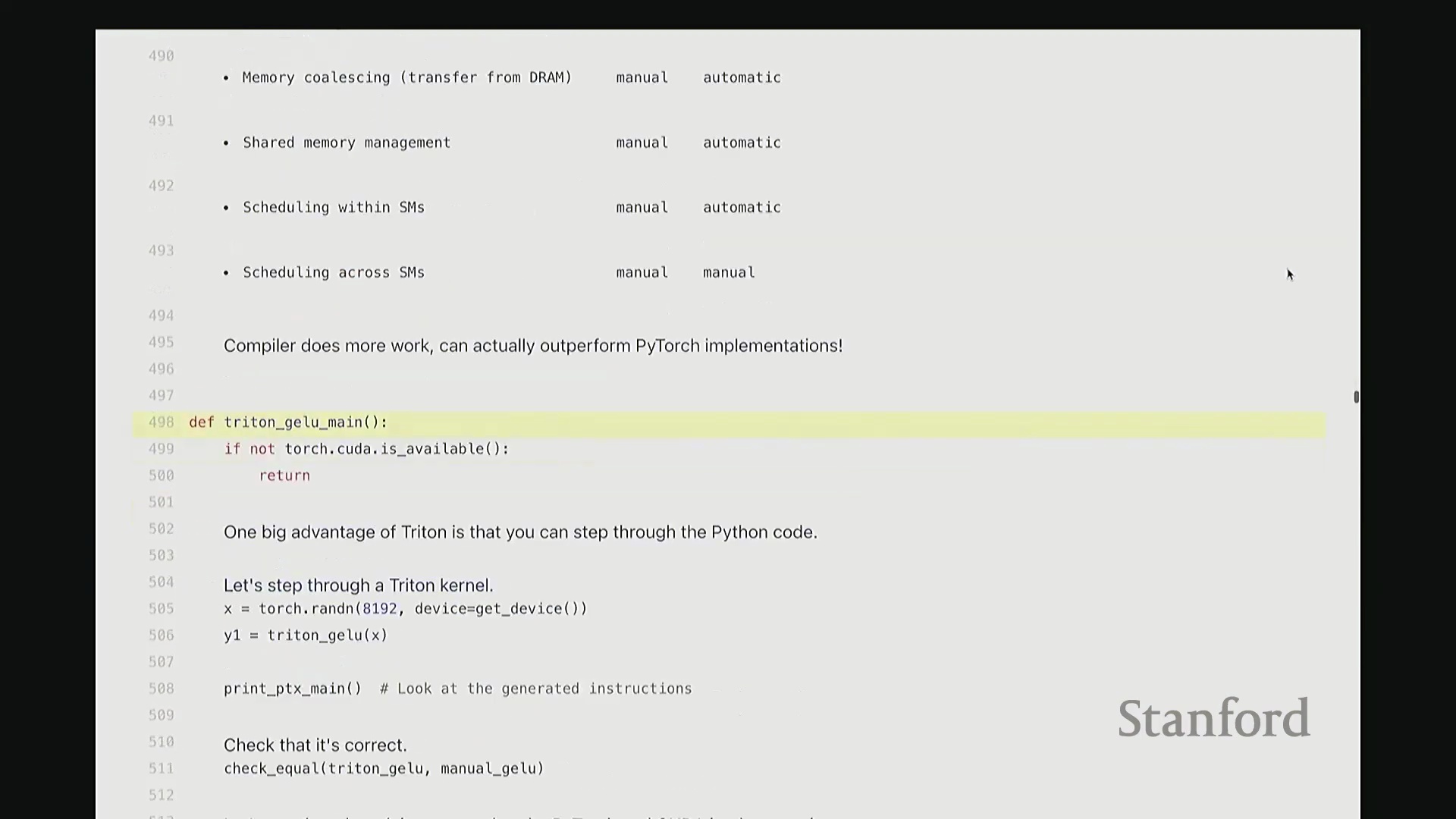
相信大家已熟悉上述流程。虽然不难,但若有一种更优雅的 Python 抽象来编写 CUDA 内核就更好了。这正是 Triton 的价值所在。Triton 提供了一个极佳的折中方案,使你无需手动管理 GPU 的底层细节。作为一种由 OpenAI 于 2021 年开发的领域特定语言(Domain-Specific Language, DSL),Triton 大幅降低了 GPU 编程的门槛。你几乎完全使用 Python 语法,无需再纠结于单个线程(Thread)的调度,而是直接以线程块(Thread Block)为抽象单元进行思考。Triton 编译器会自动处理许多繁琐但可优化的底层细节。例如,它能自动实现内存合并访问(Memory Coalescing)。回想一下,从 DRAM 读取数据时,硬件倾向于以突发模式(Burst Mode)一次性加载多个相邻数据。因此,理想情况下内存访问应合并为对连续元素的批量读取。Triton 会自动处理此类合并优化。此外,当多个线程需协作使用共享内存(Shared Memory)时,Triton 也会自动管理 SM 内的共享内存分配与同步。在单个 SM 内部,线程的启动与同步均被自动化。然而,跨 SM 的调度仍需手动配置。因此,Triton 的编程模型是以 SM 为核心进行设计,编译器则接管了大量底层硬件细节。Triton 的优势在于,其在许多场景下的性能可显著超越 PyTorch 原生实现。它接近手写 CUDA 的性能,但你仍能享受完整的 Python 生态。我认为一个常被低估的优点是:如代码所示,它完全基于 Python。你可以轻松进行单步调试(Step-through Debugging),开发体验极佳。接下来,我们将逐步拆解一个 Triton 内核。同样以 GeLU 为例,这次我们使用 Triton 实现。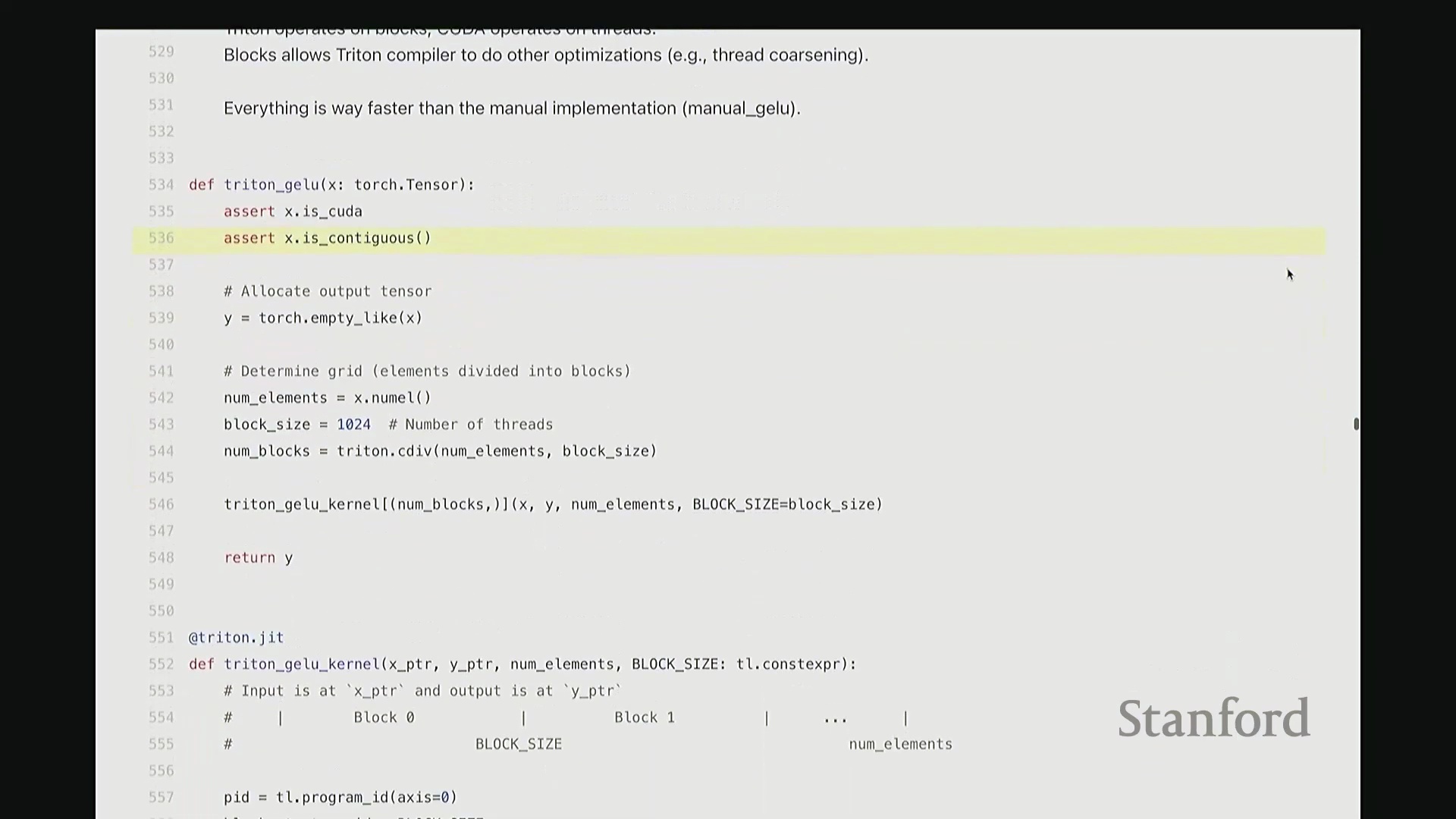
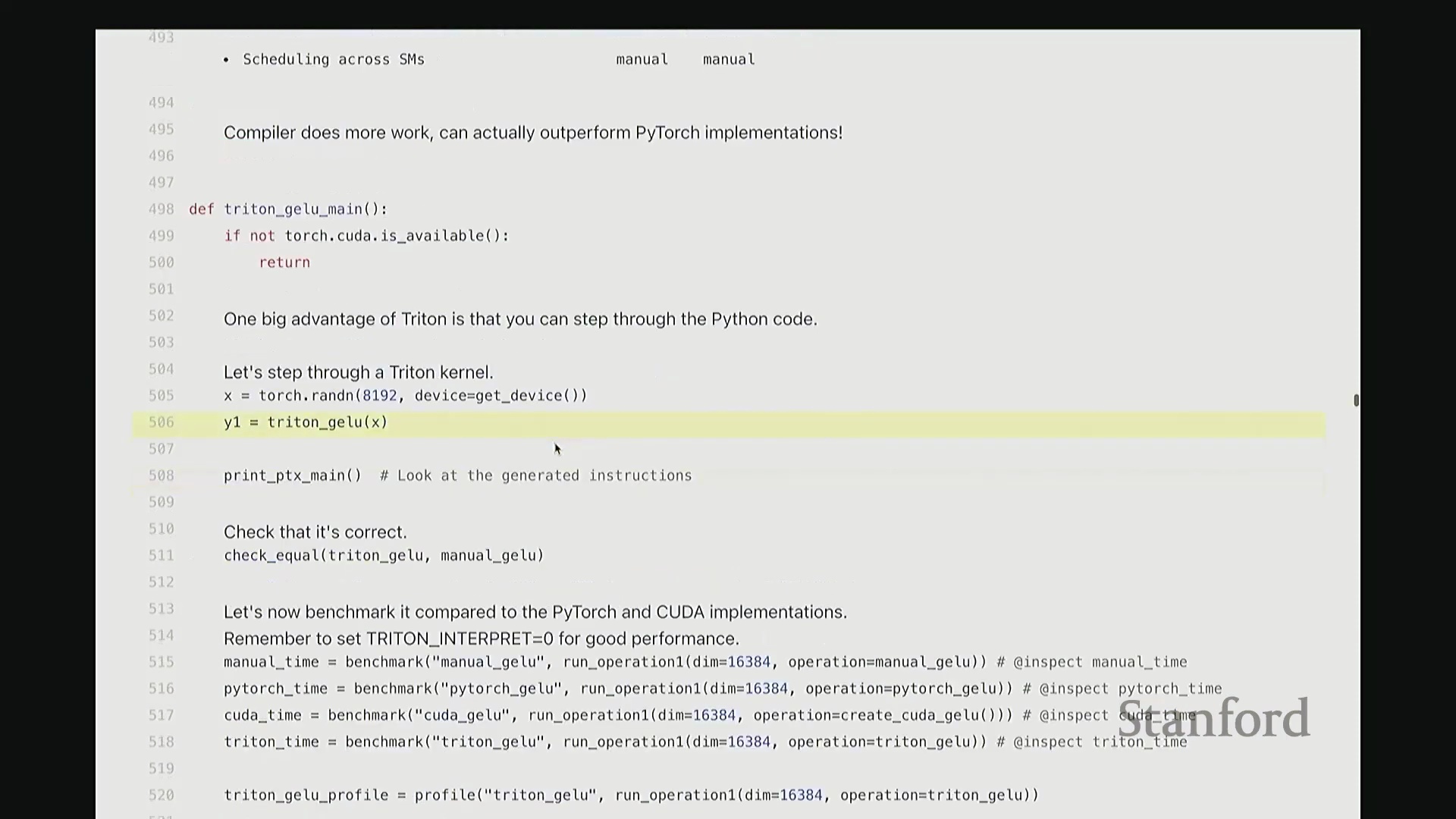
编写向量化 Triton 内核
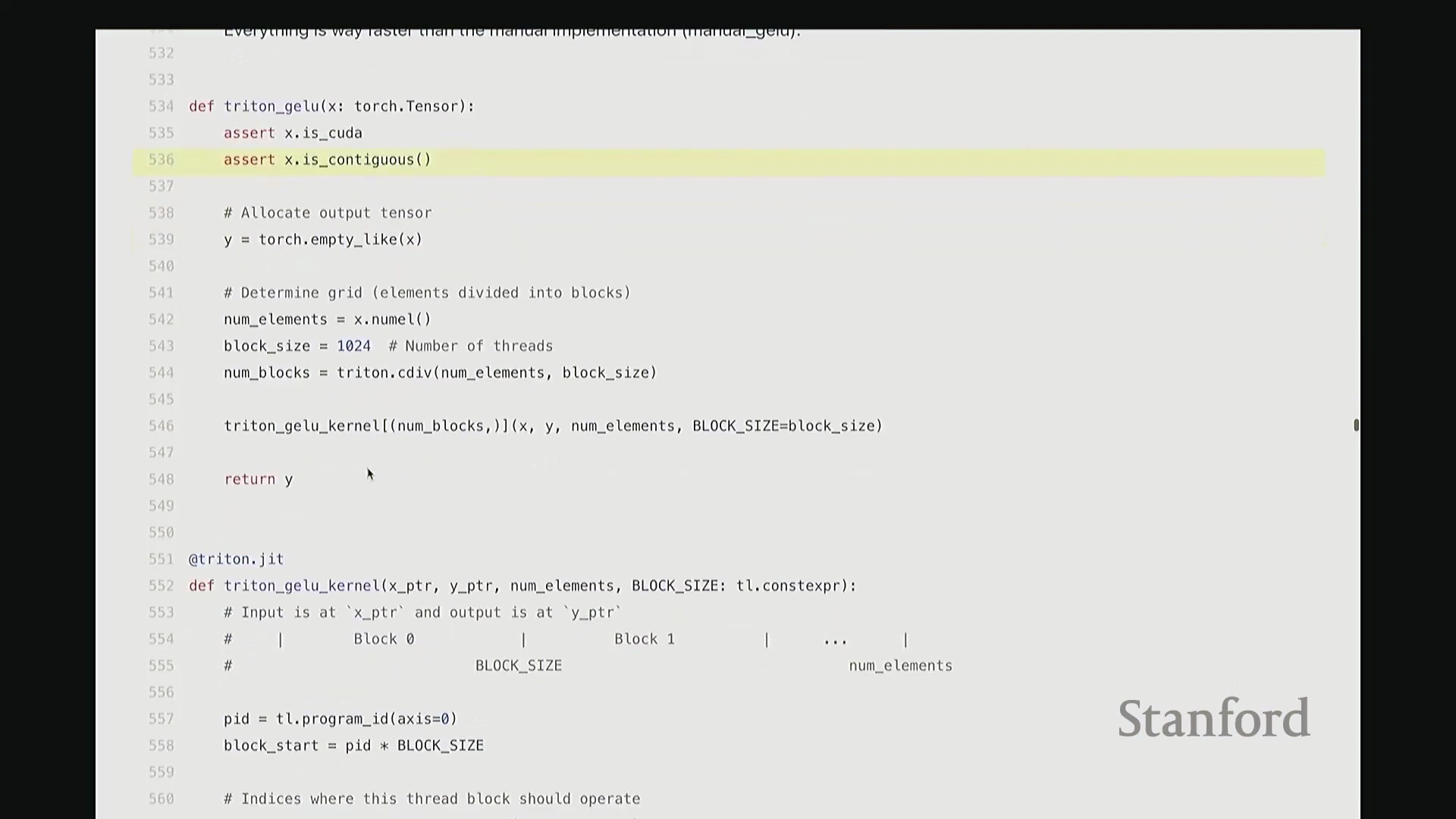
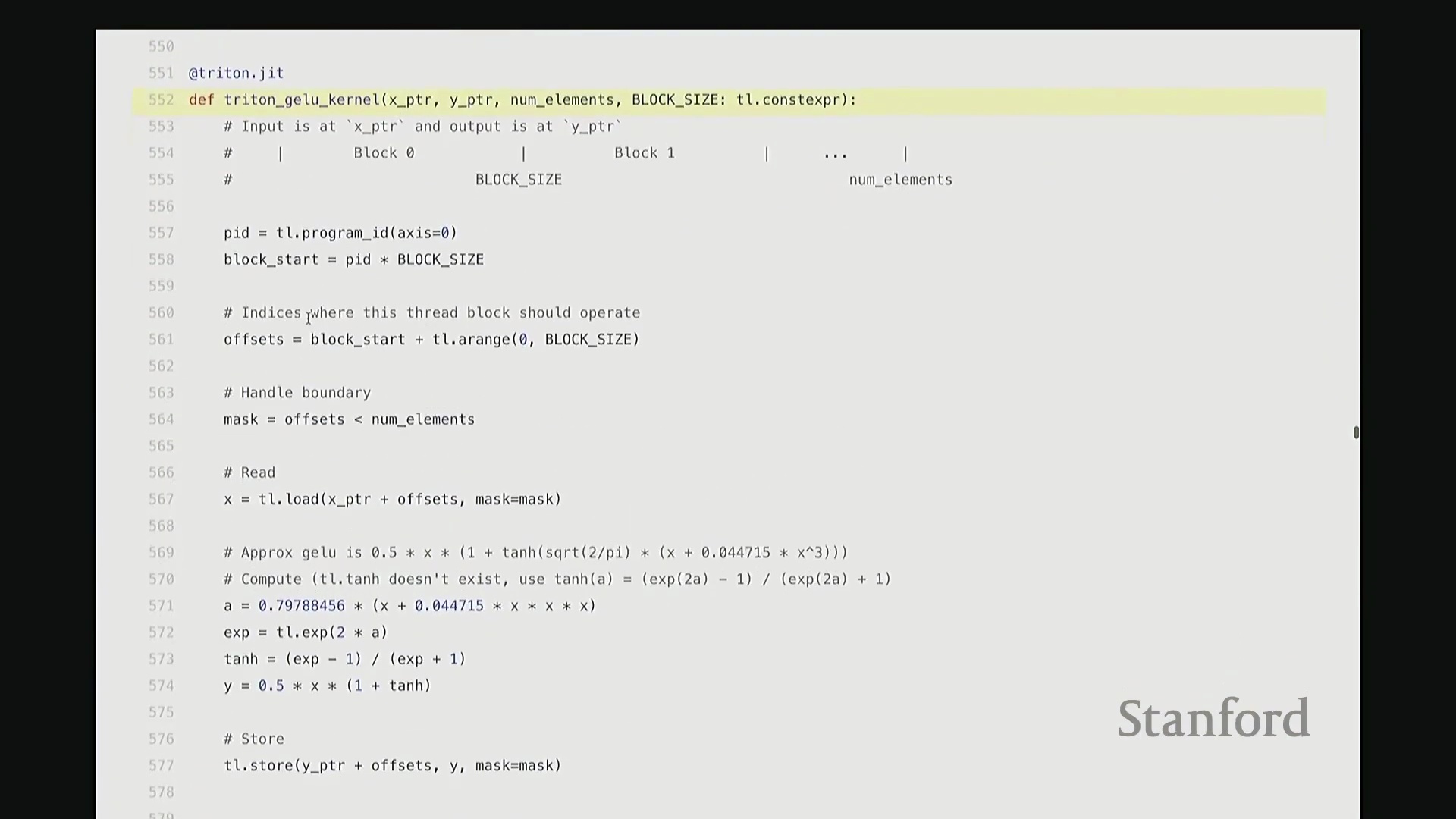
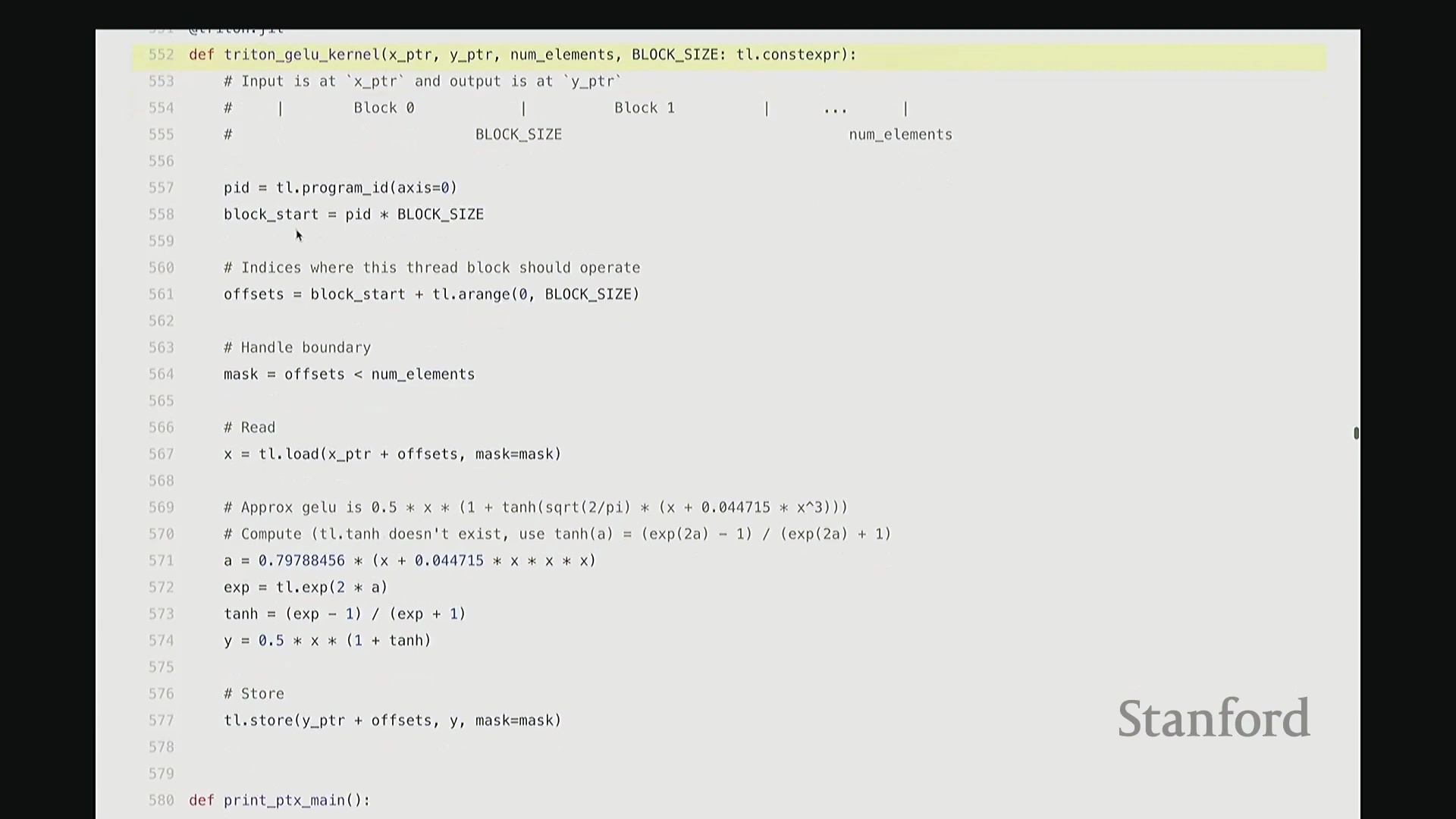
我尽量保持此代码结构与前述 CUDA 版本一致。可将其视为运行于 CPU 的主机端代码。这是 Triton 版的 GeLU 包装函数(Wrapper Function),接收 torch.Tensor 类型的输入 x。代码顶部包含两项断言检查(Assertion Checks)。同样使用 empty_like 分配输出张量 y,并复用了相同的索引计算逻辑。甚至连内核启动的语法也与之前高度相似:我配置了 num_blocks,并将块大小置于末尾。虽然不再使用 CUDA 的三重尖括号语法,但本质上传递的是完全相同的启动参数。现在,聚焦 triton_gelu_kernel 函数。它将执行与之前完全相同的任务,但 Python 代码显得极为优雅。其编程模型如下:输入数据由 x_ptr 指向,y_ptr 指向输出缓冲区起始地址。block_size 定义块大小,n_elements 定义数组边界。请看第 557 至 561 行的索引计算。此前我们用 i = ... 计算单个索引,此处逻辑相同,用于计算当前线程块的全局起始偏移:block_id * block_size。假设当前为第 1 个块,该计算将定位至数组中部。接下来确定块内偏移量。但请注意关键区别:此处传入的并非单个标量偏移,因为 Triton 的编程抽象层级是线程块(Thread Block)而非单一线程。这意味着偏移量实际上是一个向量(Vector)。该向量化操作将由块内多个线程并行处理。因此,偏移量计算为块起始位置加上一个范围向量(0 至 block_size-1 的序列)。如此一来,该偏移量向量一次性涵盖了当前块内所有线程对应的全局坐标。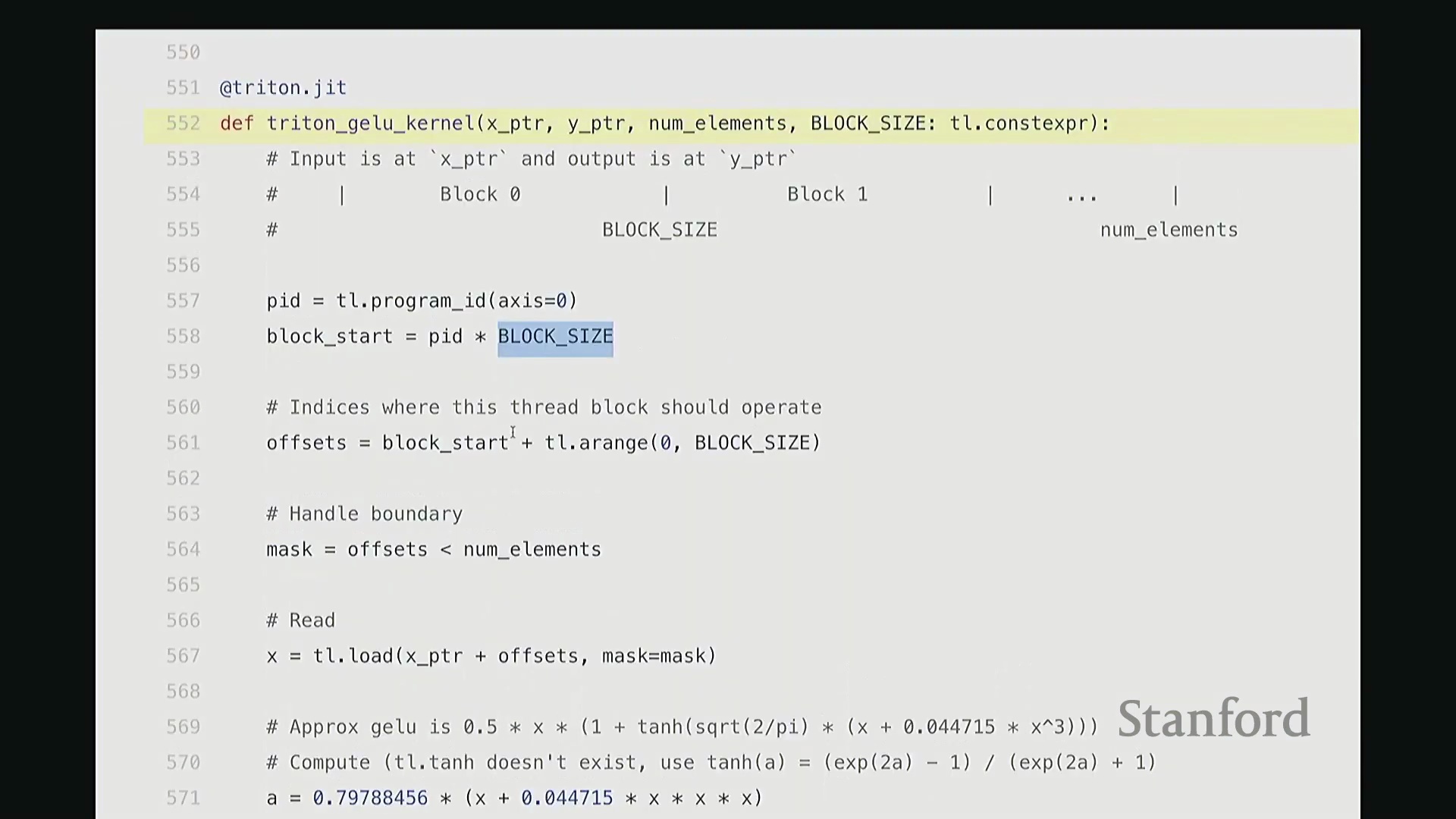
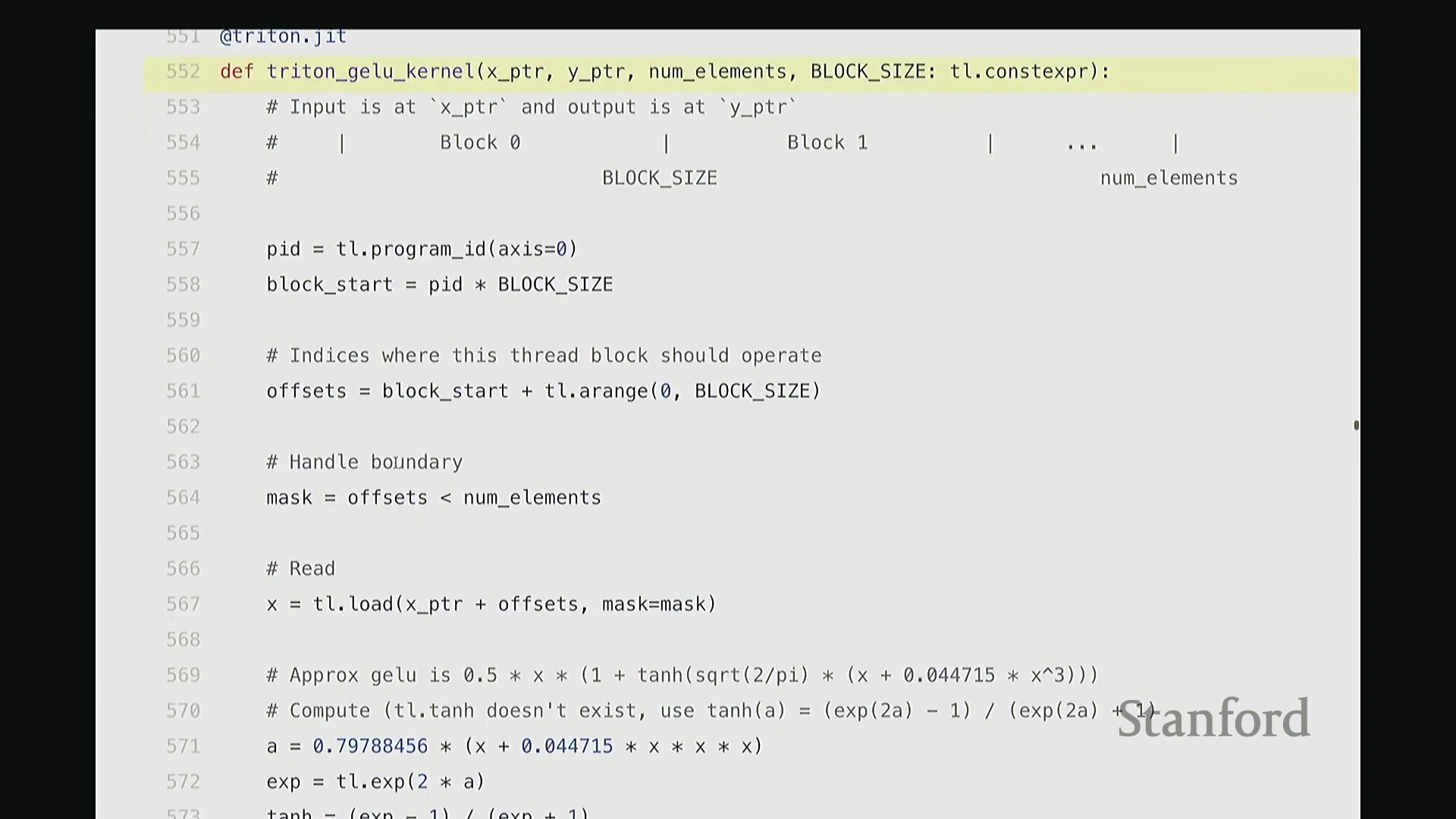
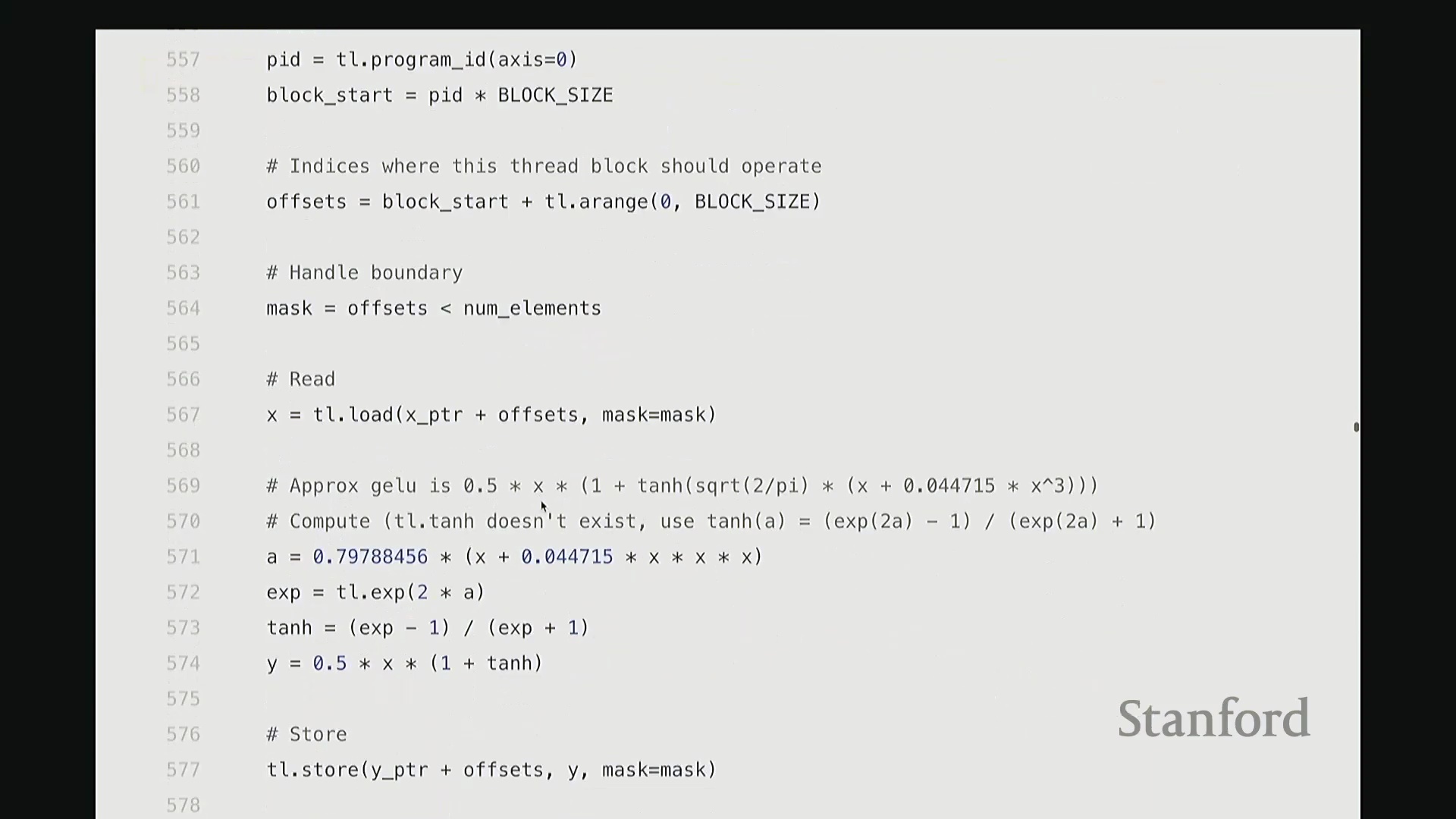
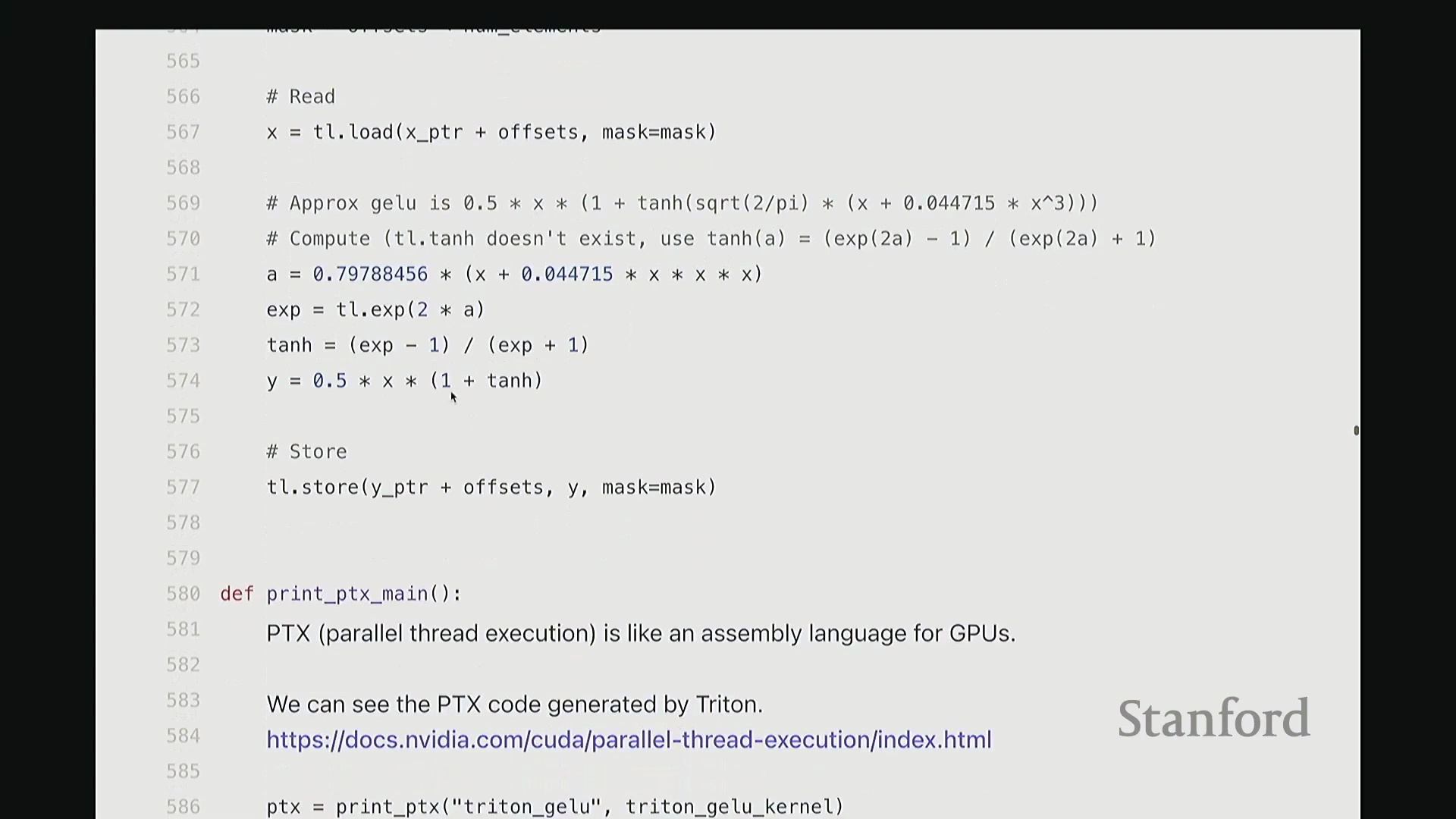
当然,处理数组末尾时可能发生越界。因此,我们需要引入掩码(Mask)来过滤超出有效范围的元素。接下来,通过单次向量化操作批量加载数据。将 x_ptr 与偏移量向量相加,结合掩码,即可安全加载所需数据至临时张量 x 中。基于该临时向量,我们执行与先前完全一致的 GeLU 数学运算。此处未直接调用内置 tanh,而是手动展开计算,但你可验证其数学等价性。计算结果存入临时变量 y。随后,需将结果写回输出缓冲区。计算目标地址 y_ptr + offset,将 y 存储至该地址。整体逻辑与前述代码高度相似,但这是彻底的向量化(Vectorized)实现。我们一次性处理整个线程块的数据块,思维模式从单一线程(Thread-level)跃升至块级(Block-level)。尽管抽象层级不同,核心计算逻辑并无本质差异。至此,Triton 版 GeLU 已编写完成。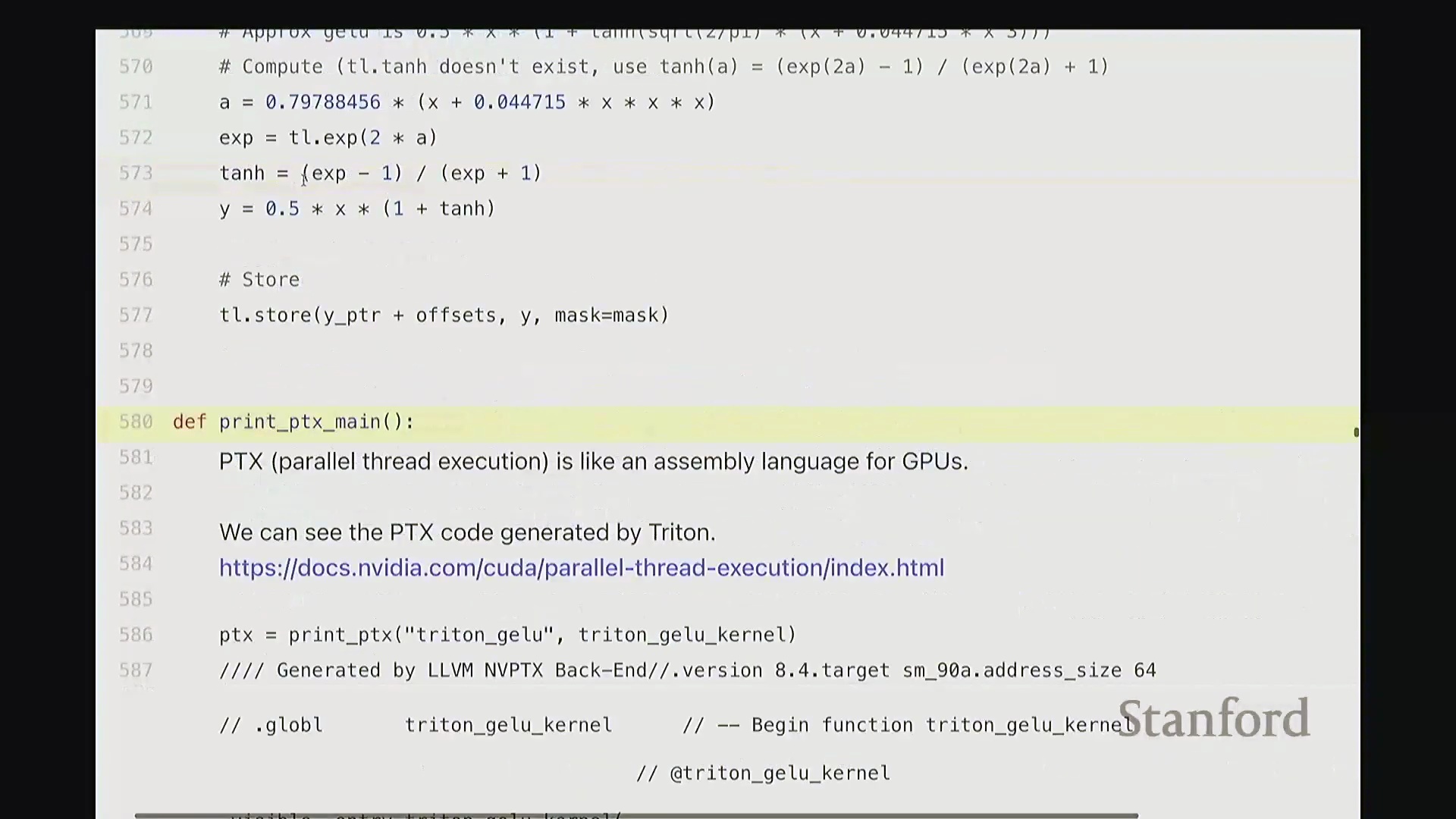
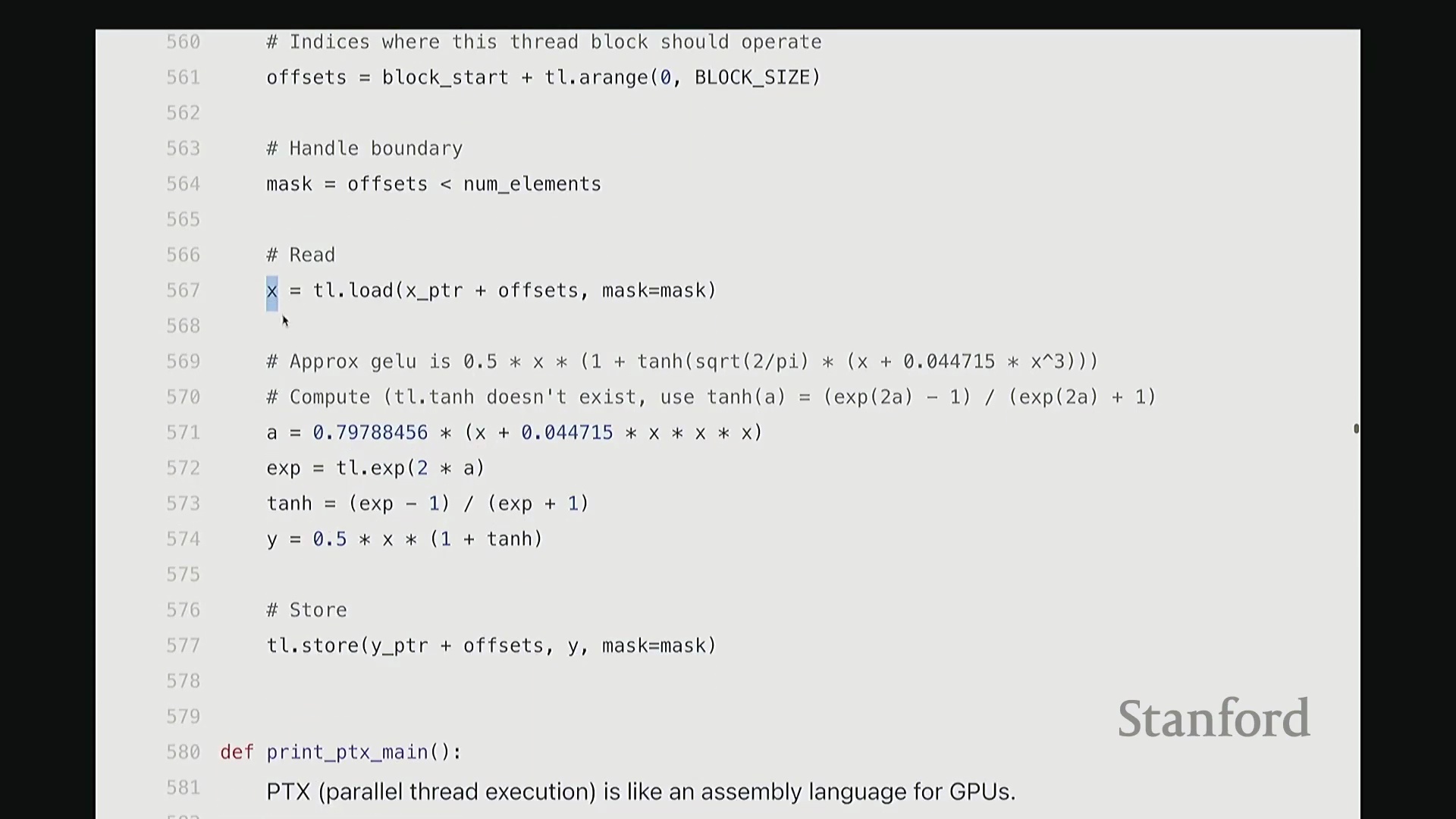
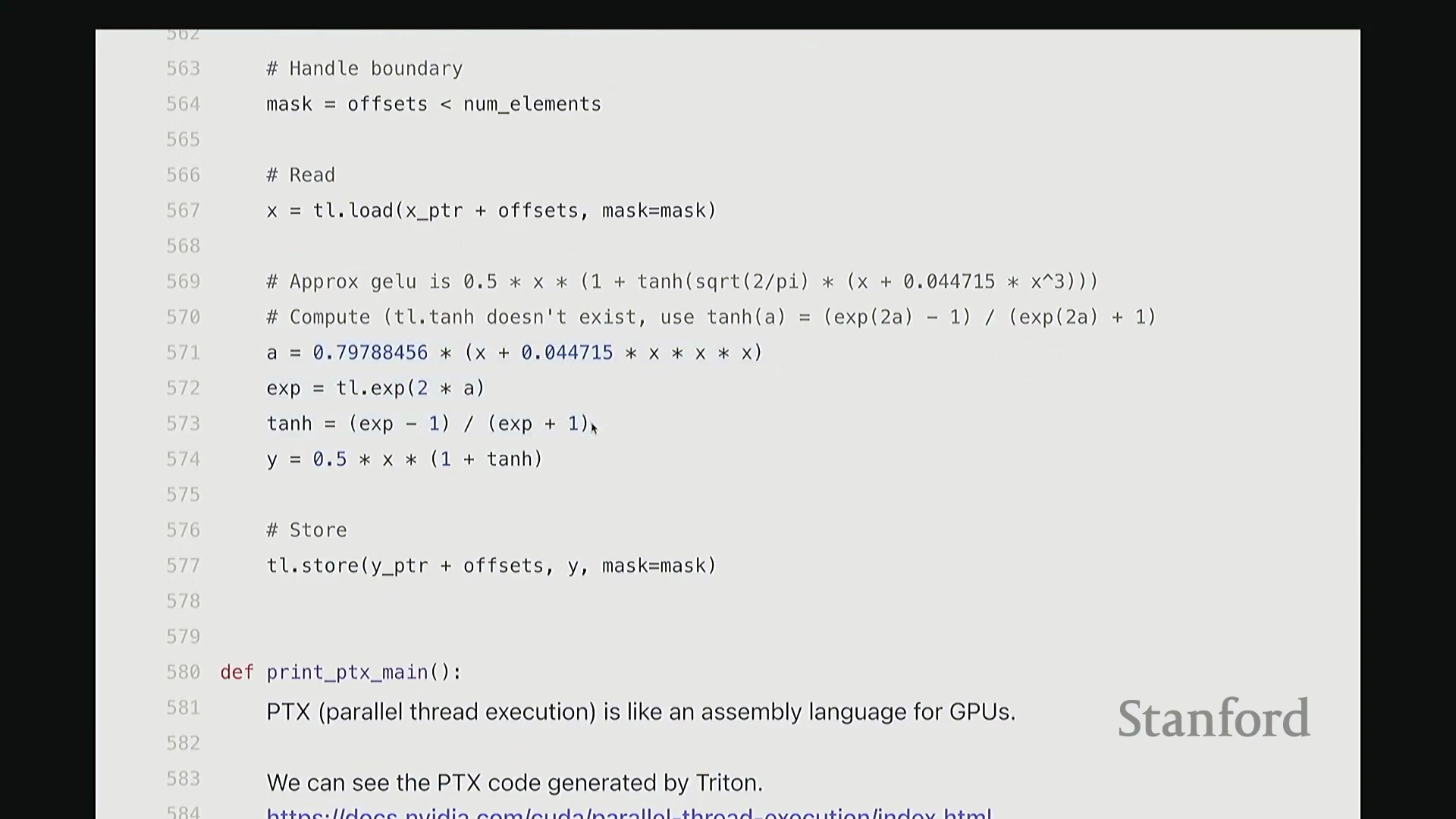
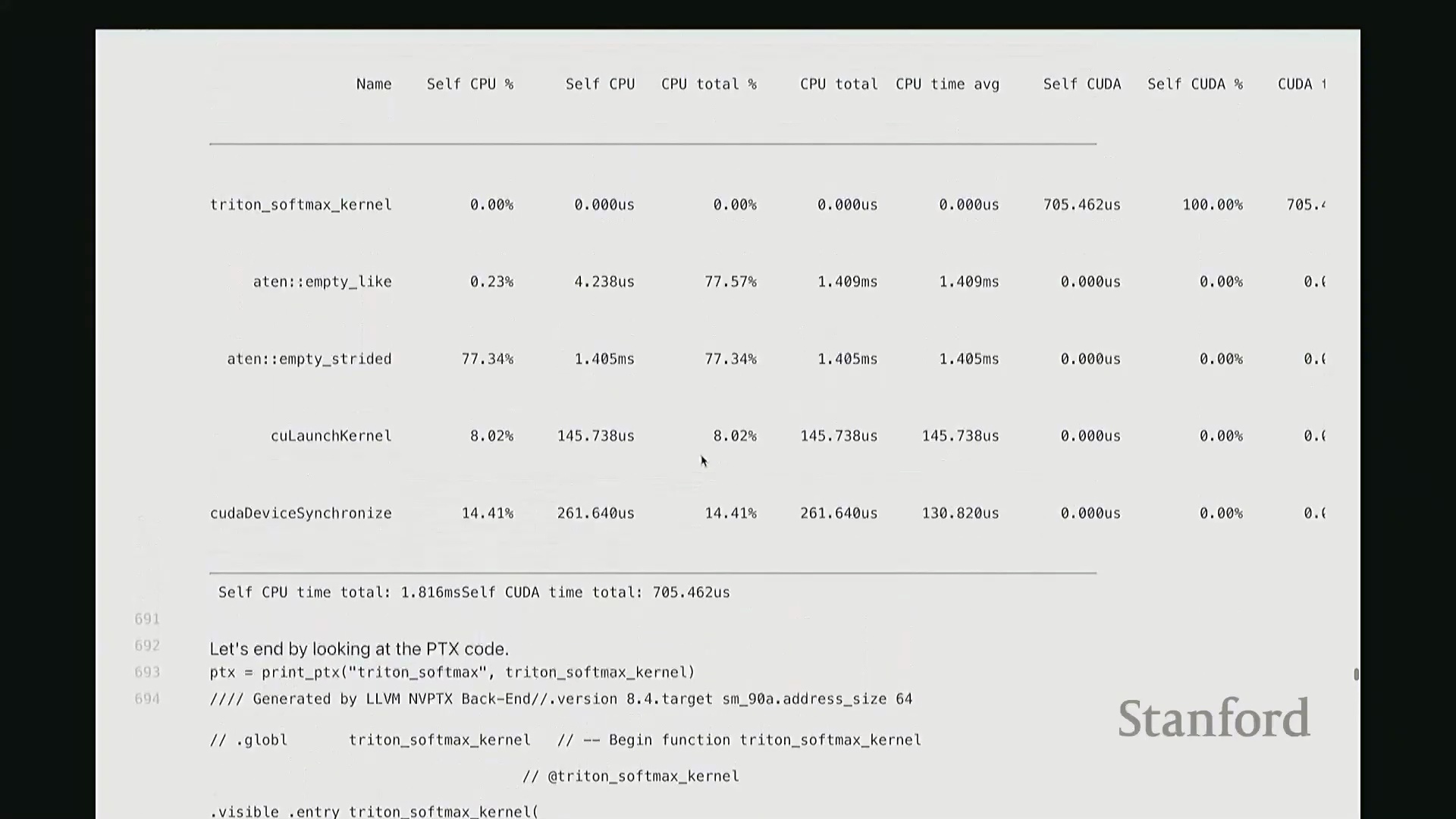
查看生成的 PTX 代码
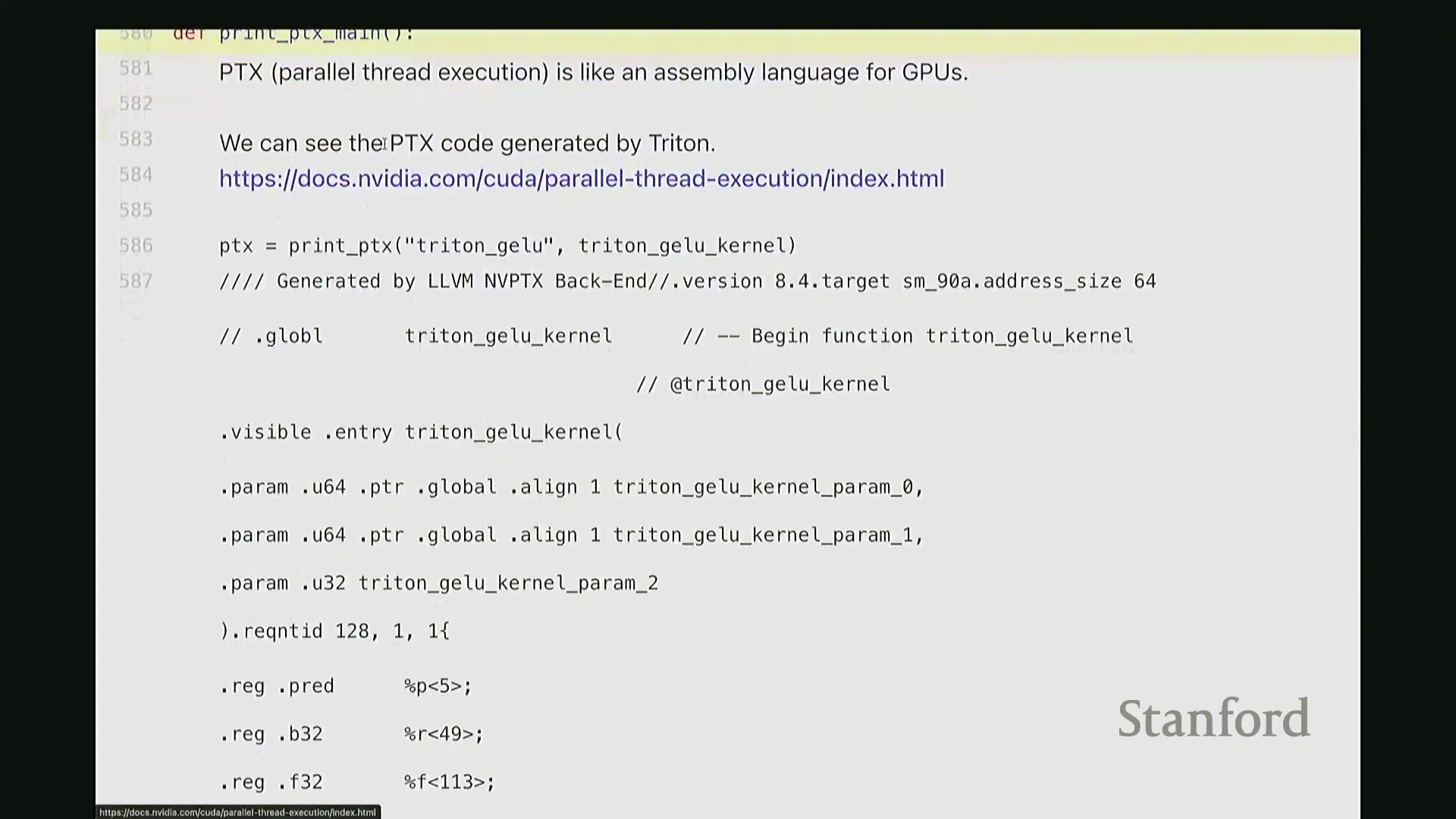
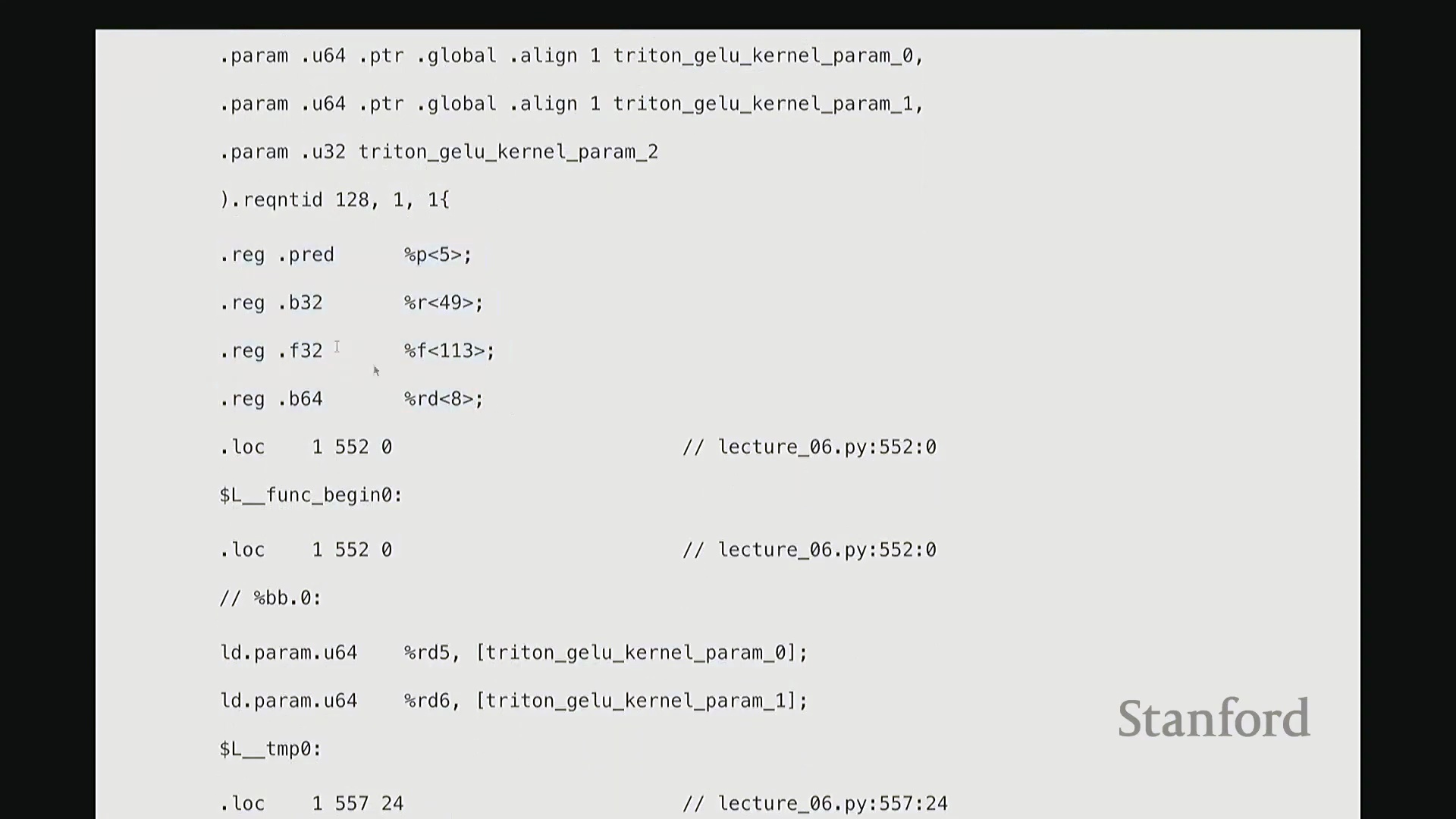
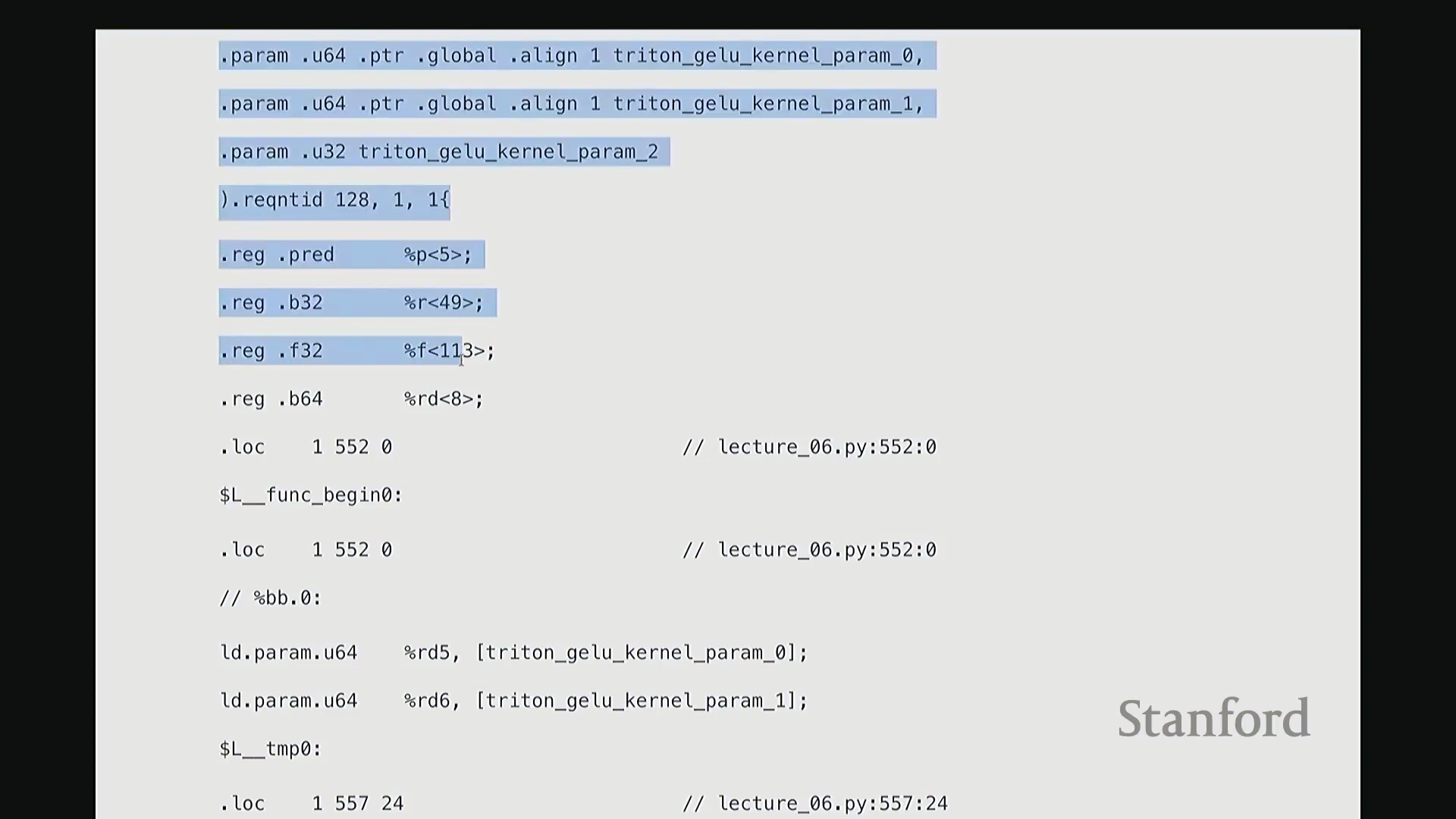
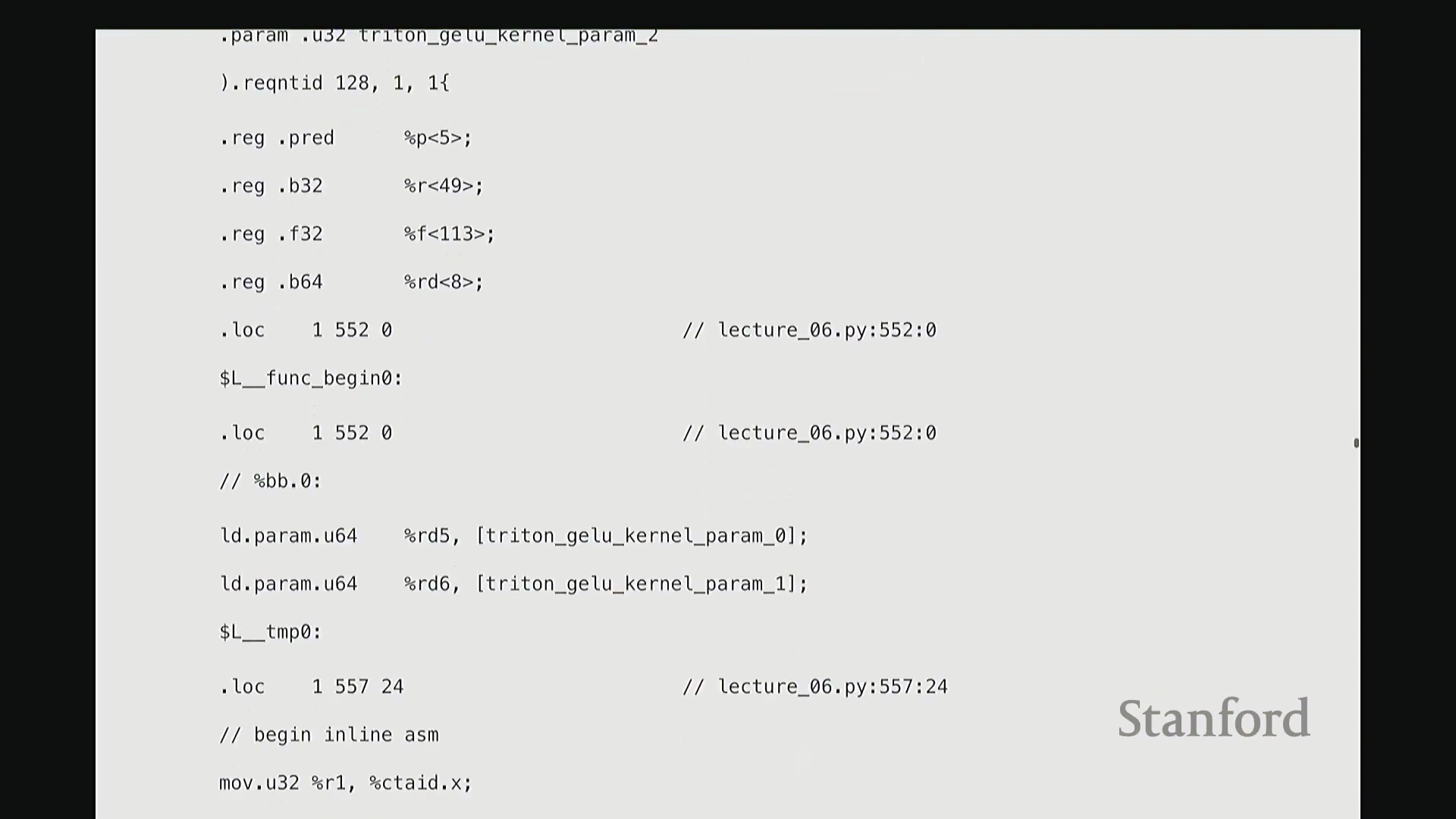
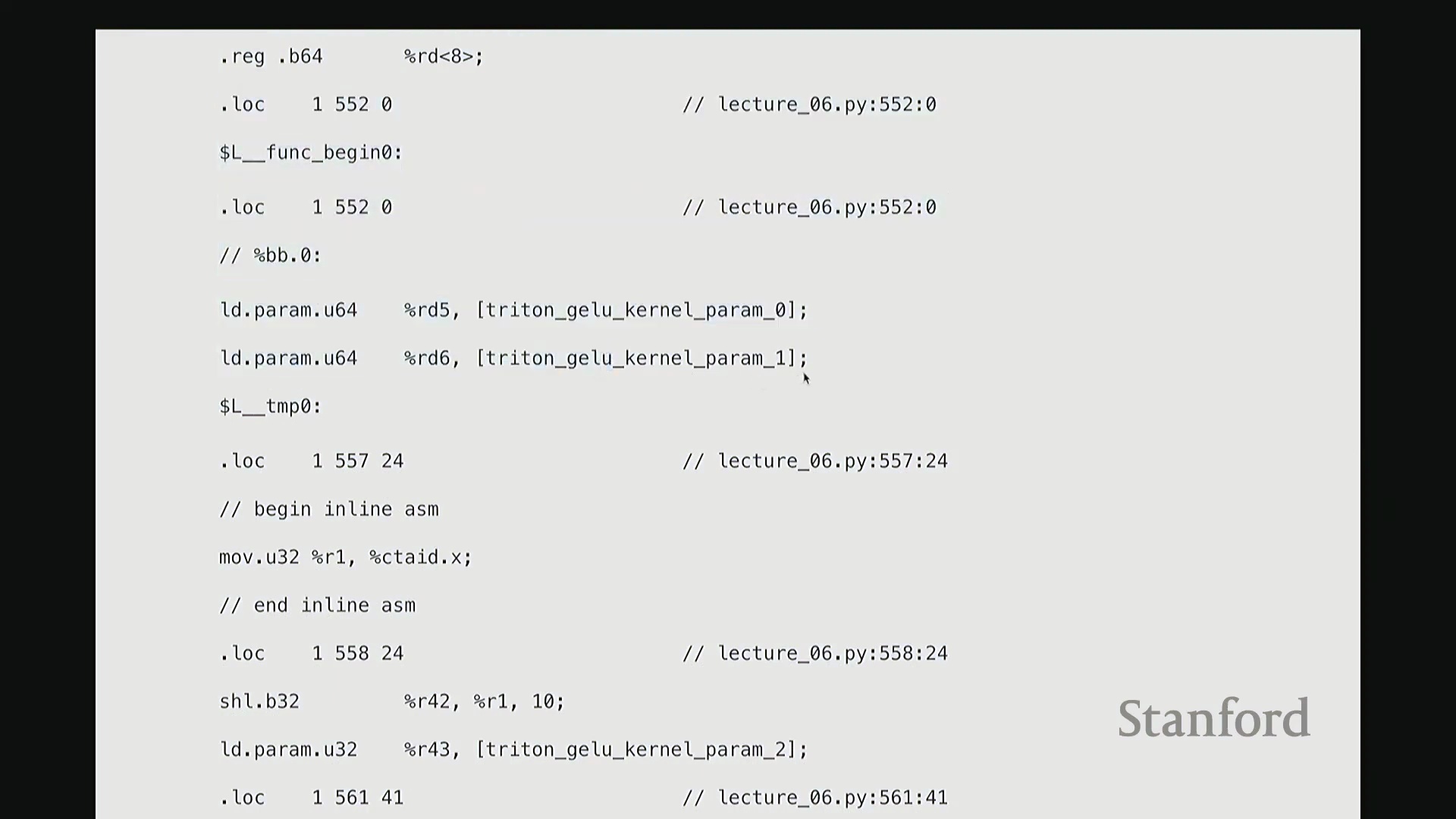
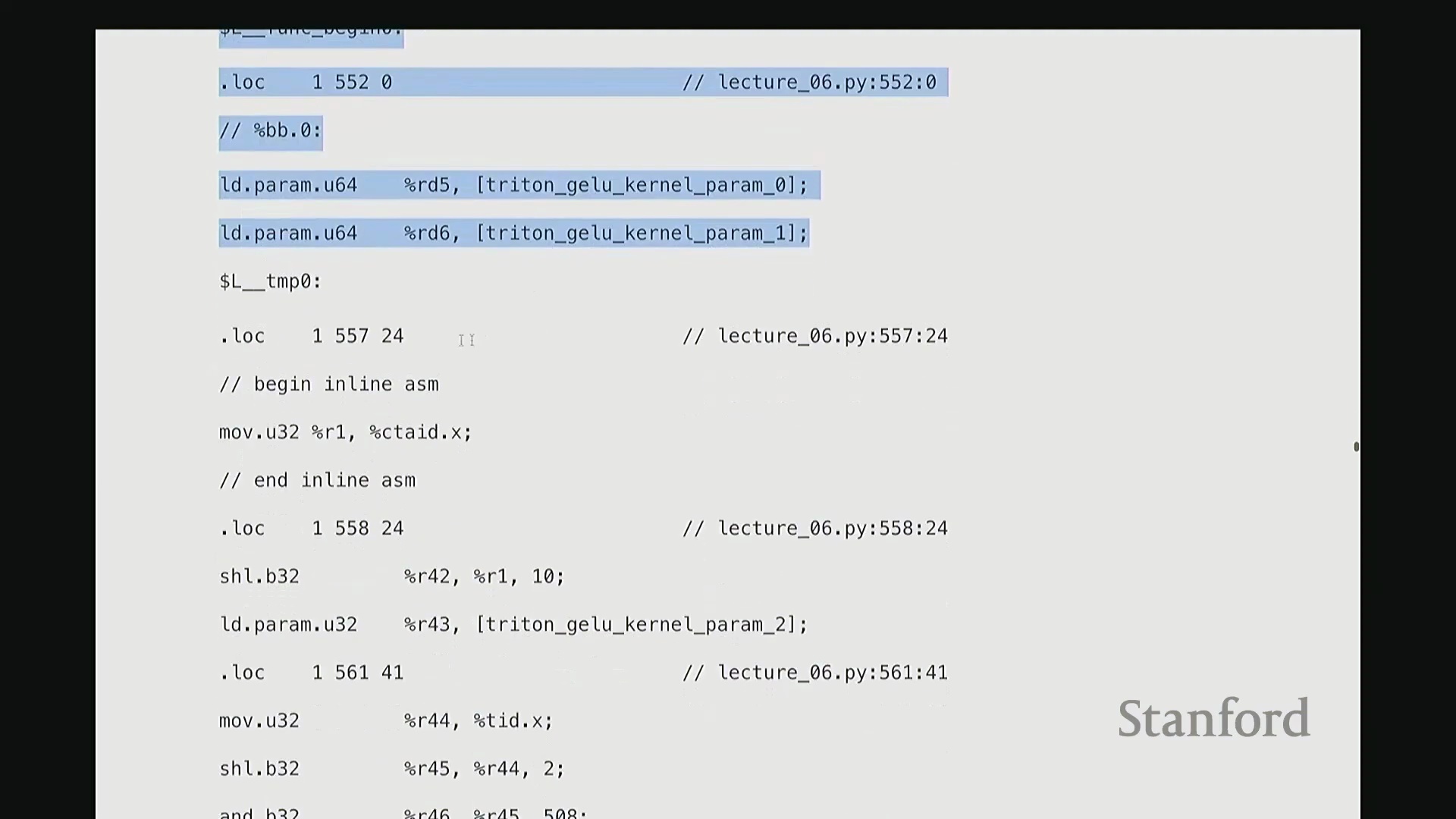
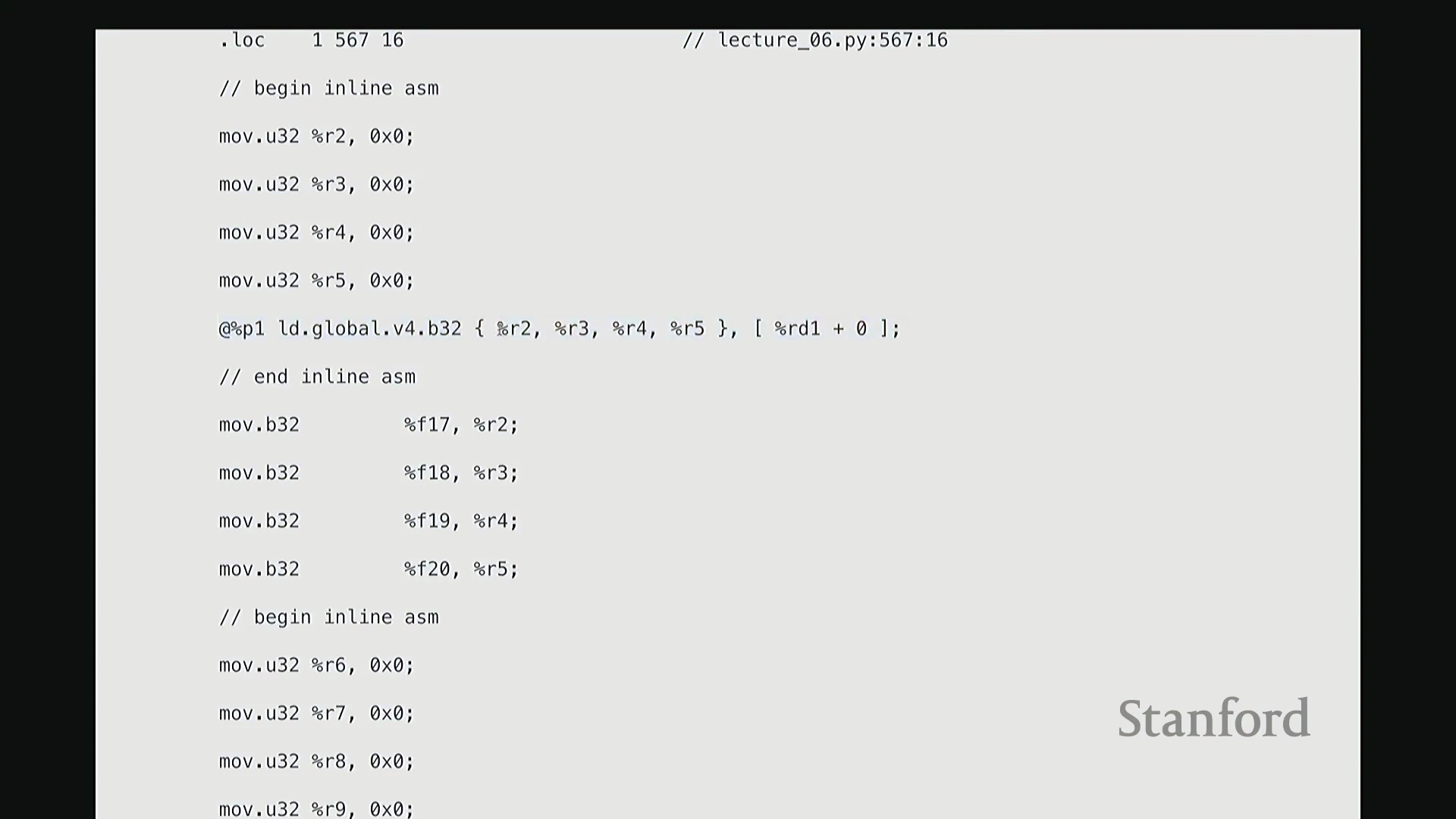
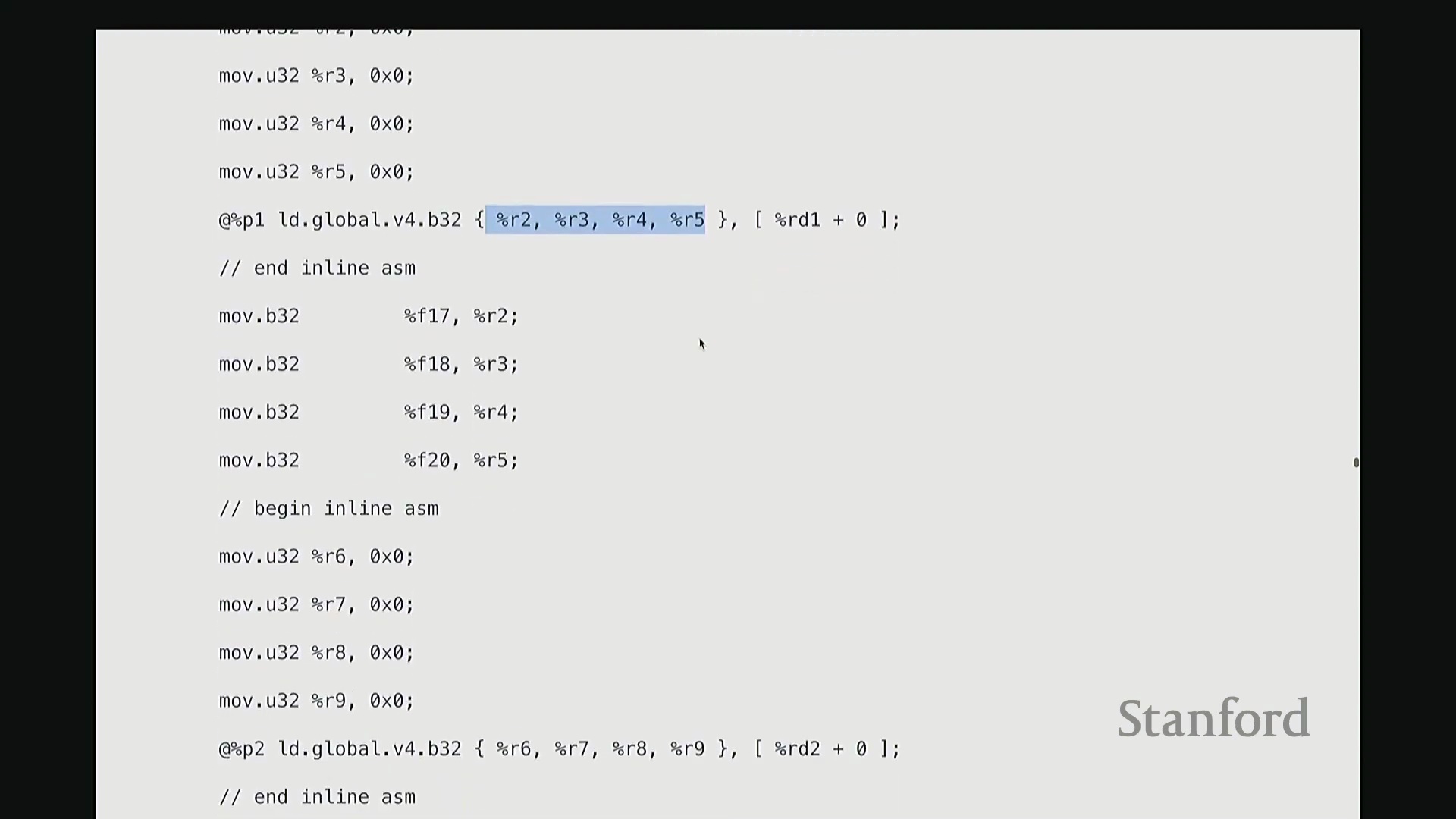
这部分我将快速带过。最后一项内容。为避免过多细节导致疲劳,我只提取几个关键点。但 Triton 还有一个非常强大的特性:它最终会编译为底层、接近机器码的 GPU 指令集。我们完全可以在 Triton 编译器生成代码后,直接查看其输出的 PTX (Parallel Thread Execution) 中间代码。这非常有趣,能直观揭示 GPU 在线程级别(Thread-level)的实际执行逻辑。这是 Triton 为 GeLU 内核自动生成的 PTX 代码。初始阶段主要进行基础声明:分配存储空间与中间变量寄存器。例如,PTX 中的 .b 类型表示位/字节(Bit/Byte)数据,此处声明了 32 位字节空间;.f 表示用于浮点运算的浮点型(Float)寄存器;此外还分配了另一组 64 位寄存器。至此,临时计算所需的全部寄存器(Register)已准备就绪。随后进入索引计算阶段。抱歉,此处实为加载内核参数:输入指针 x_ptr 与输出指针 y_ptr 被载入寄存器。接着,计算 Triton 内核的全局索引偏移量。向下滚动,可见 ld.global 指令(语音识别可能误作 LV global,实为 PTX 的全局内存加载指令)。该指令负责将数据从 x_ptr 指向的全局内存加载至临时寄存器。其语义为:以寄存器 rg1 中的地址为基址,连续加载数据至 r2, r3, r4, r5 寄存器。注意,它一次性加载了四个值。这得益于编译器自动优化的内存合并访问(Memory Coalescing)。既然硬件能以“零额外开销”批量读取相邻的四个值,我们理应一次性完成处理。随后,代码将对后续数据块执行相同的加载与计算流程……
从 PTX 代码与线程执行看底层细节
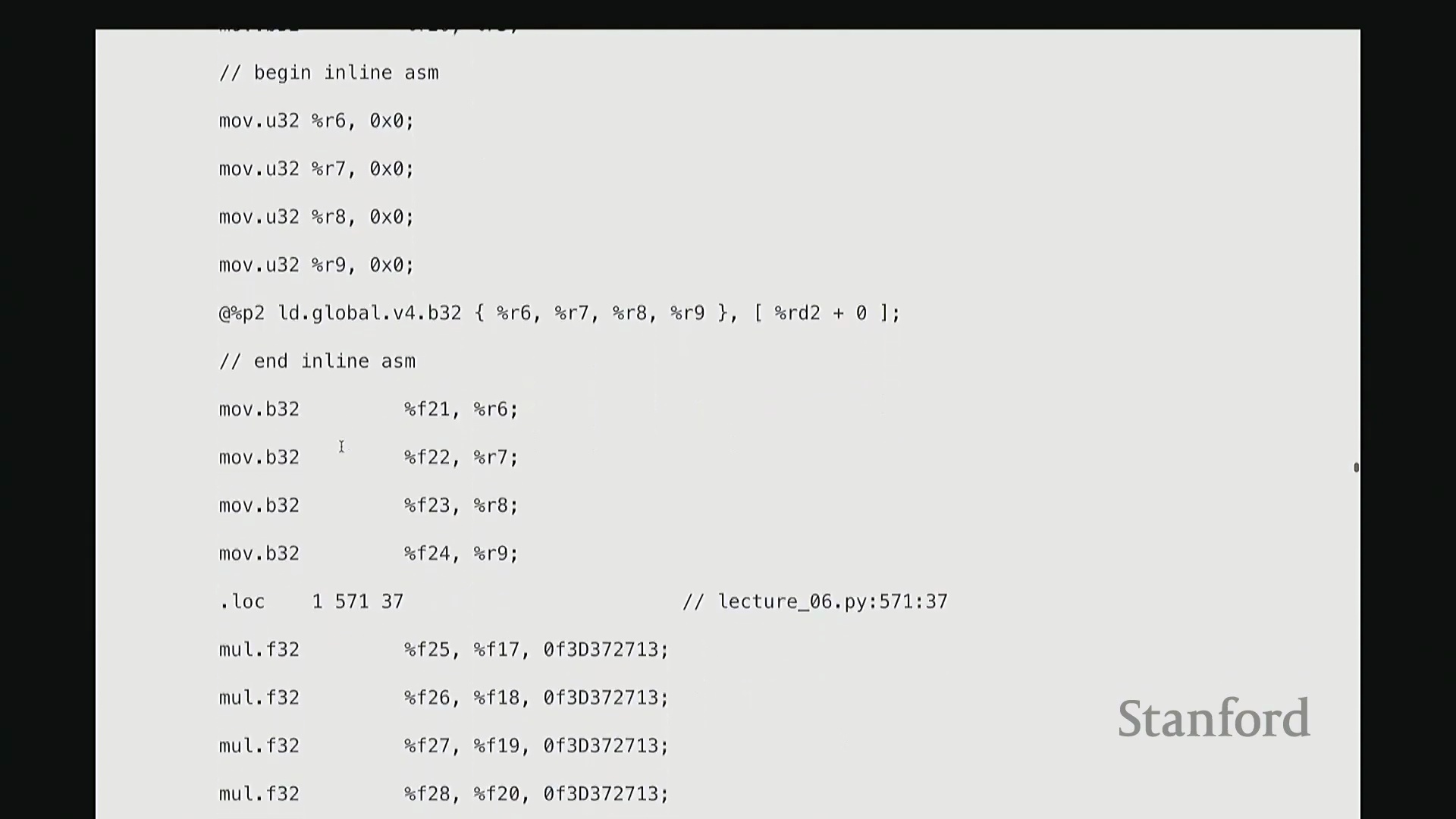
生成的 PTX (Parallel Thread Execution) 汇编代码清晰揭示了 GPU 执行浮点运算(Floating-Point Operations)的精确指令序列。例如,用于计算 tanh 的 mul.f32(32位浮点乘法指令)、常数乘法以及指数函数的底数转换操作(如乘以 log2(e) 以完成自然底数转换)。
 每个线程高效地并行处理四个数值,充分利用寄存器(Register)进行超高速的本地临时存储,从而避免访问延迟较高的全局内存(Global Memory)。
每个线程高效地并行处理四个数值,充分利用寄存器(Register)进行超高速的本地临时存储,从而避免访问延迟较高的全局内存(Global Memory)。
 这种深度依赖寄存器且采用合并内存访问(Memory Coalescing)的模式,确保了编译后的内核能够以极低的开销和极高的吞吐量(Throughput)稳定运行。
这种深度依赖寄存器且采用合并内存访问(Memory Coalescing)的模式,确保了编译后的内核能够以极低的开销和极高的吞吐量(Throughput)稳定运行。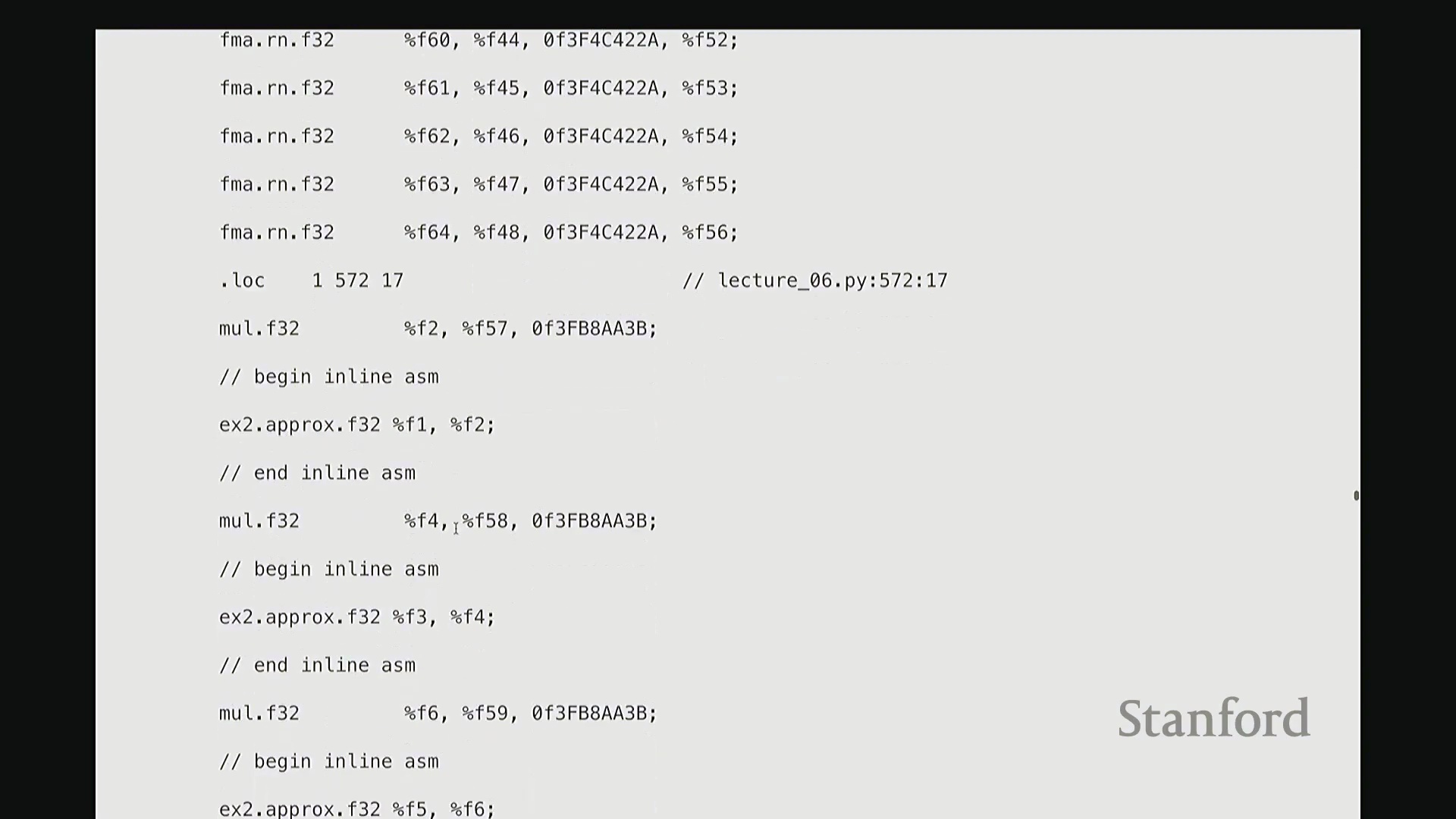

基准测试对比与 Triton 的优势
在对 GeLU (Gaussian Error Linear Unit) 算子进行基准测试(Benchmarking)时,朴素的纯 PyTorch 逐元素实现耗时约 8.1 毫秒(ms),而高度优化的原生 PyTorch 函数仅需 1.1 毫秒。自定义 CUDA 内核与 Triton 实现的性能表现相当,均稳定在 1.84 毫秒左右。
 尽管 Triton 在此例中并未显著超越手写 CUDA 内核,但其核心优势在于卓越的开发体验(Developer Experience):开发者可直接使用 Python 语法编写内核,由编译器自动处理内存合并访问与共享内存(Shared Memory)管理。更重要的是,Triton 最终仍会编译生成单一、完全融合的内核(Fully Fused Kernel),在性能剖析(Profiling)视图中独占 100% 的 GPU 计算时间。
尽管 Triton 在此例中并未显著超越手写 CUDA 内核,但其核心优势在于卓越的开发体验(Developer Experience):开发者可直接使用 Python 语法编写内核,由编译器自动处理内存合并访问与共享内存(Shared Memory)管理。更重要的是,Triton 最终仍会编译生成单一、完全融合的内核(Fully Fused Kernel),在性能剖析(Profiling)视图中独占 100% 的 GPU 计算时间。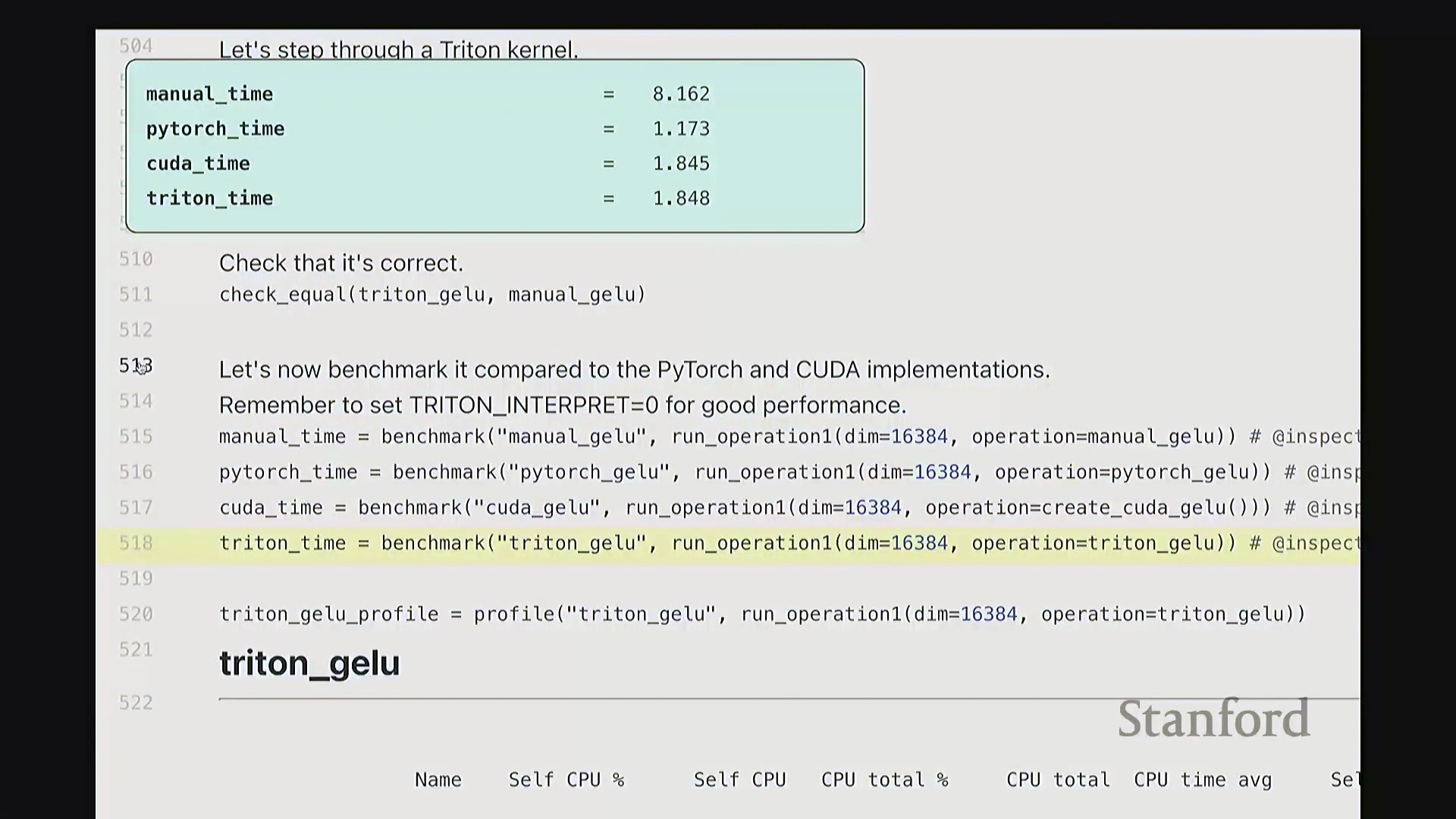

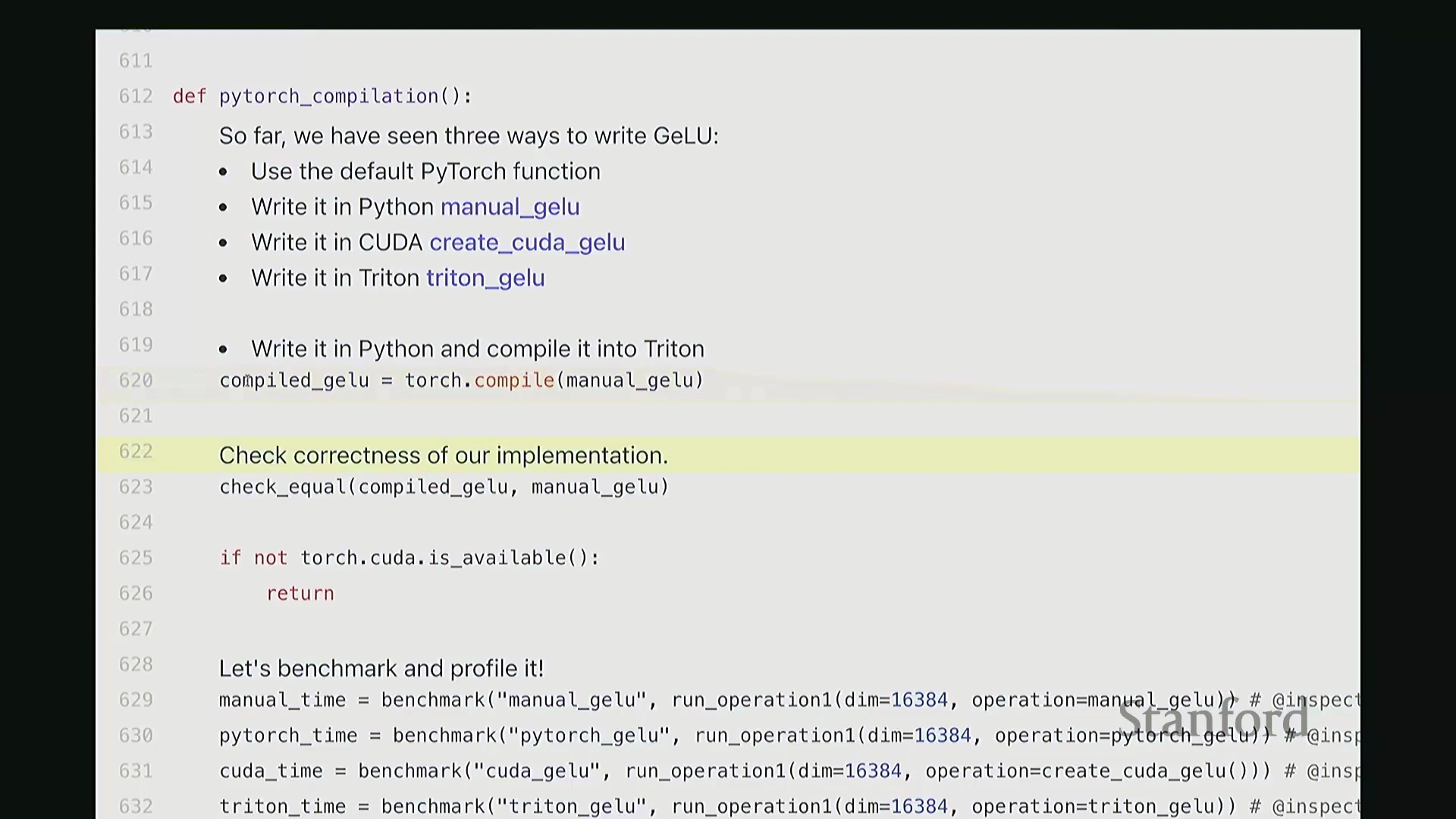
利用 Torch Compile 实现自动融合
诸如 torch.compile 之类的现代即时编译(Just-In-Time, JIT)编译器能够自动应用内核融合(Kernel Fusion)等高级优化,彻底免去手动底层编程的繁琐。将其应用于 GeLU 函数时,该编译器通过底层自动生成高度优化的融合内核,将运行时间压缩至约 1.47 毫秒,略微超越了自定义 CUDA 与 Triton 的实现。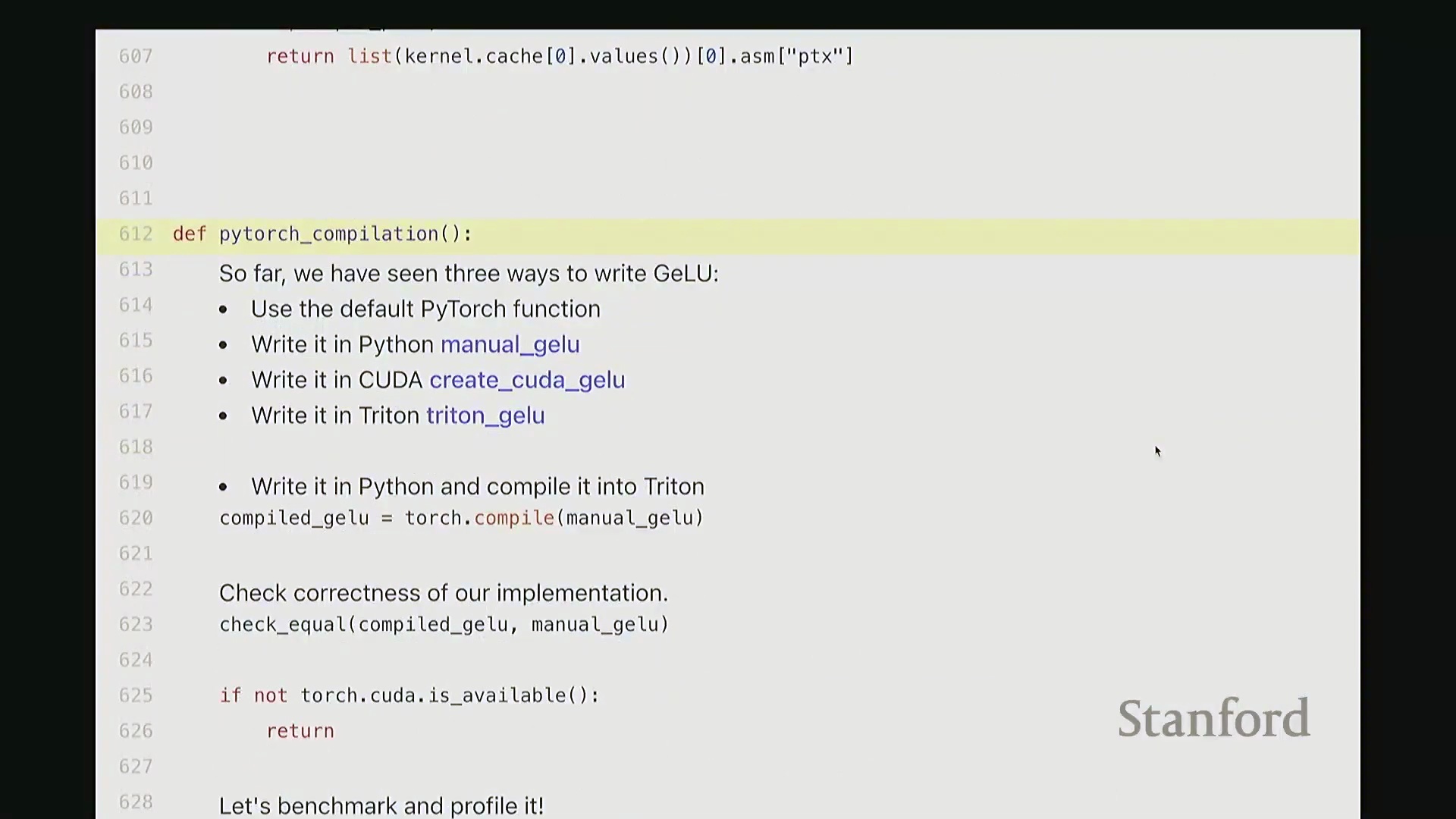
torch.compile 在标准算子融合与矩阵乘法(Matrix Multiplication)内核调度方面表现卓越,但对于高度定制化且针对特定硬件架构深度优化的算法(例如 Flash Attention 的某些变体),开发者可能仍需编写自定义内核。实际工程建议如下:对于模型中的绝大多数算子,应优先依赖 torch.compile 进行自动化优化;仅当性能剖析明确揭示出编译器无法消除的特定瓶颈时,才需深入使用 Triton 或 CUDA 进行手动调优。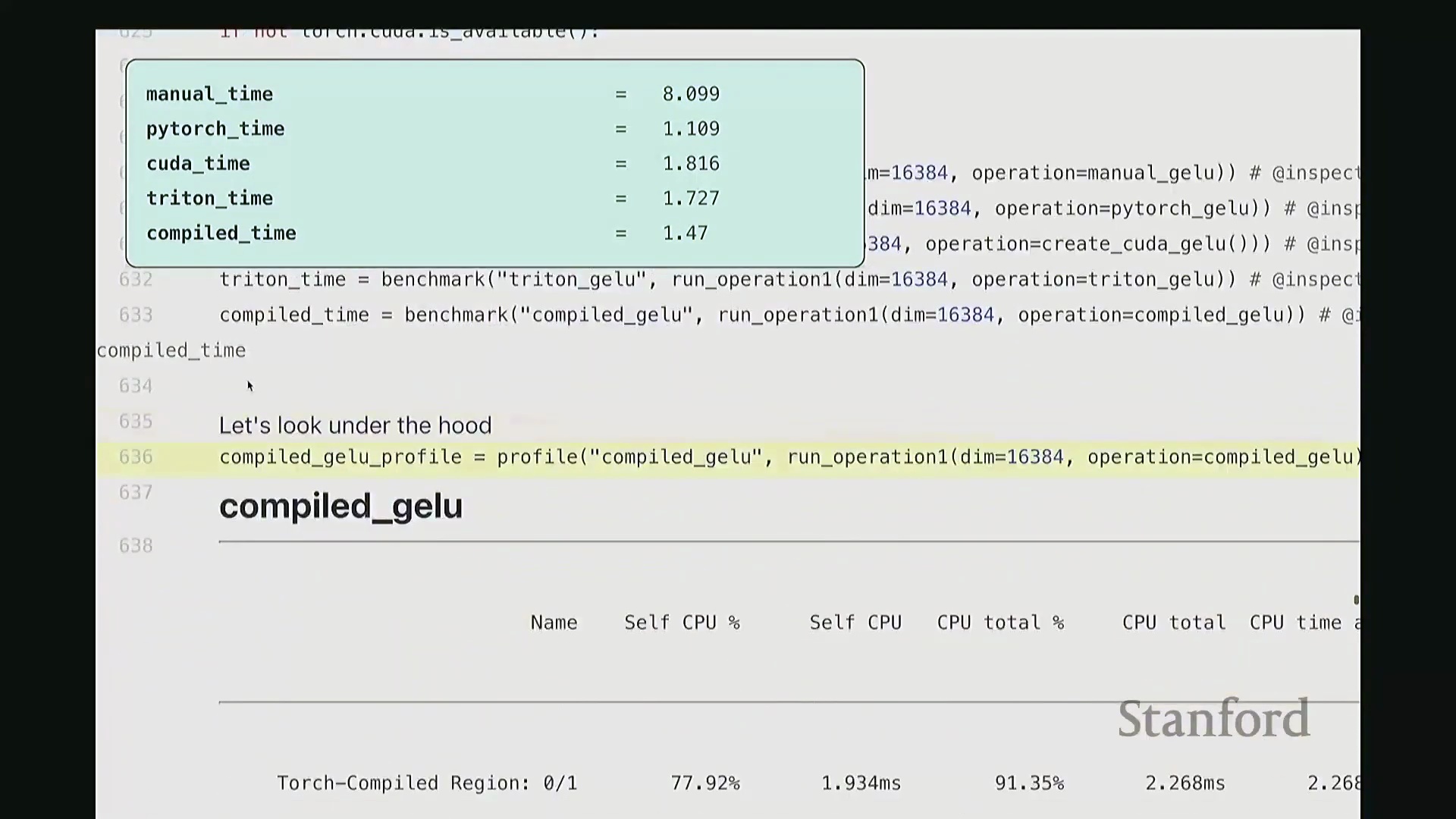



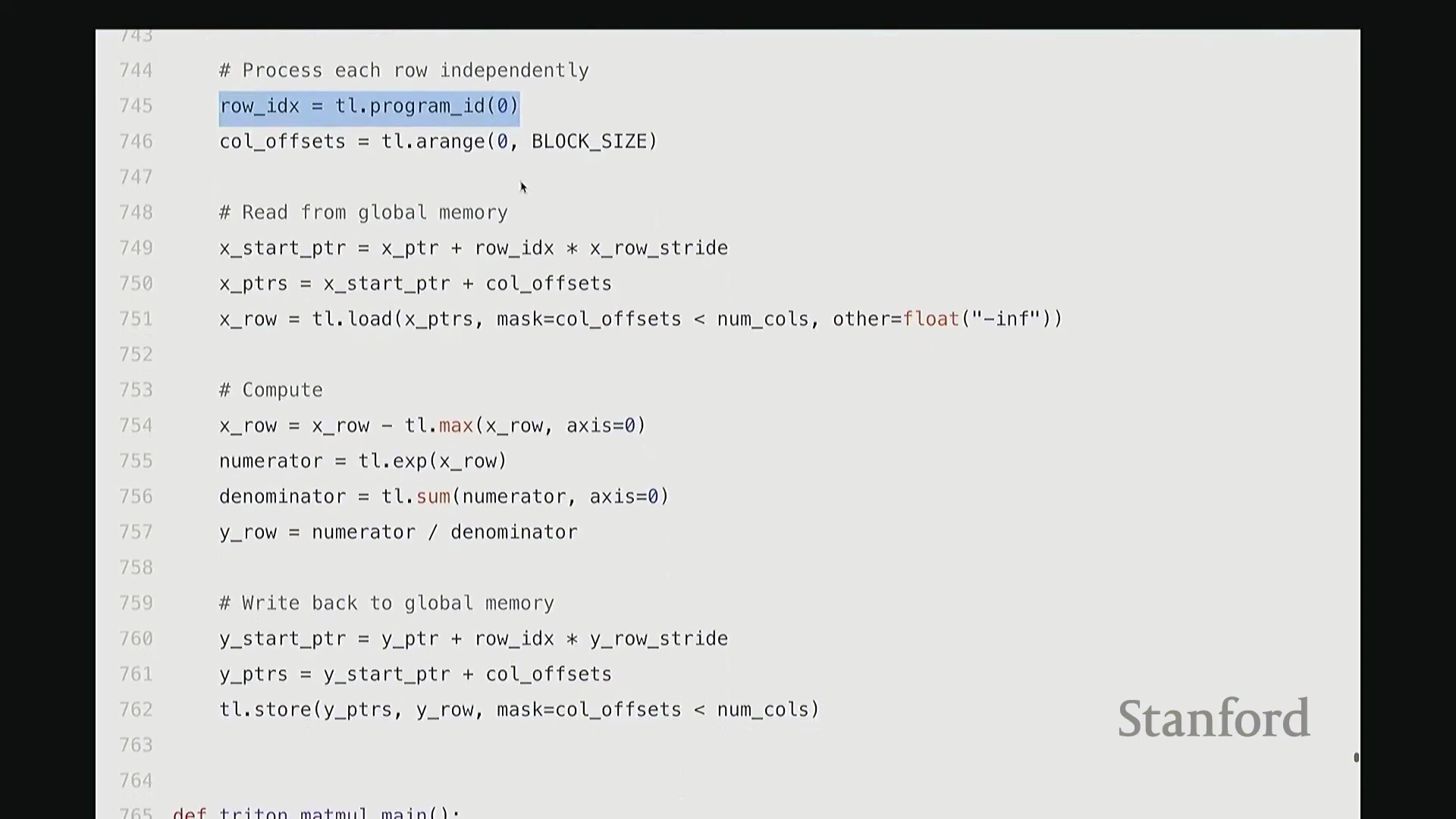
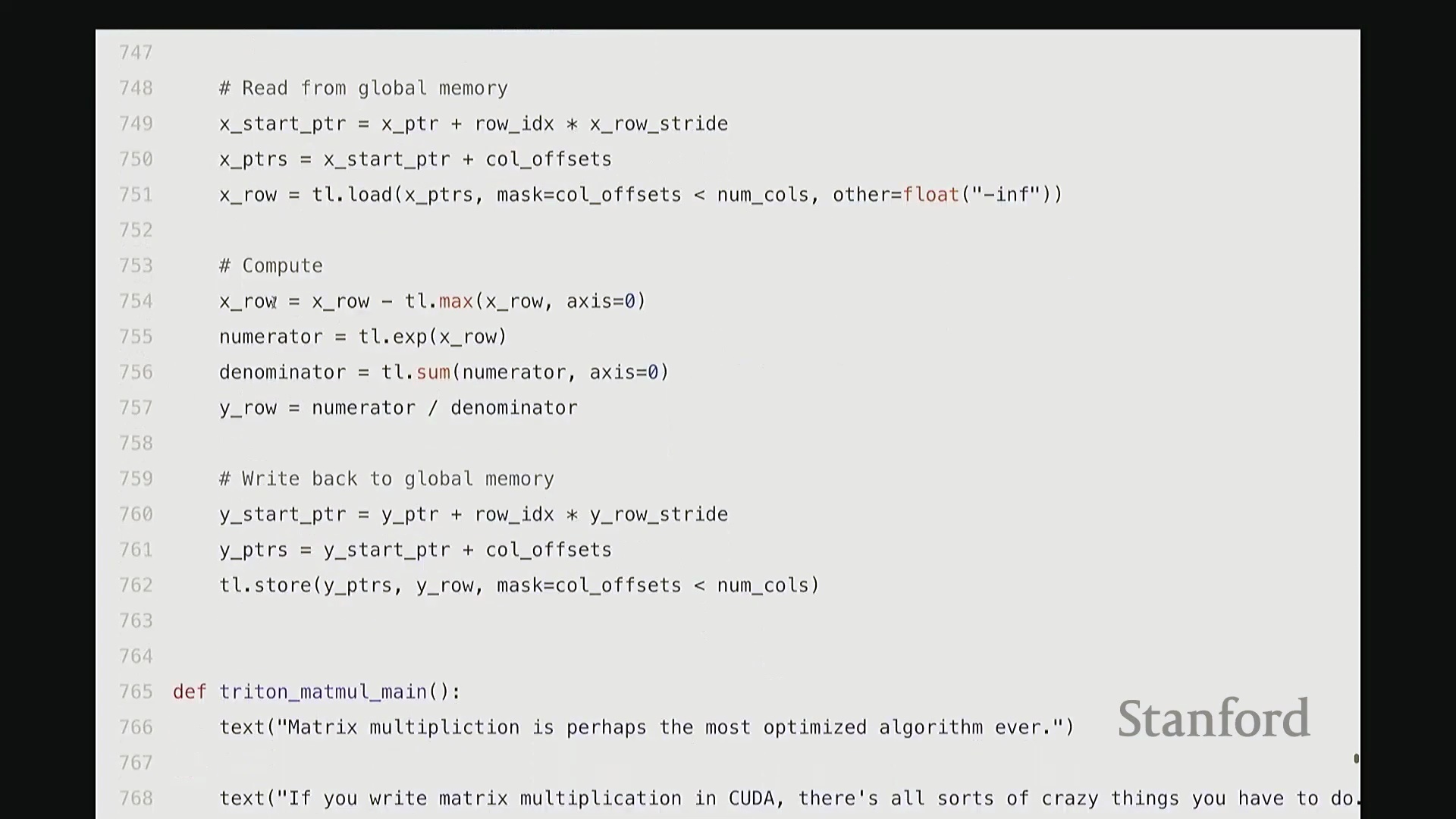
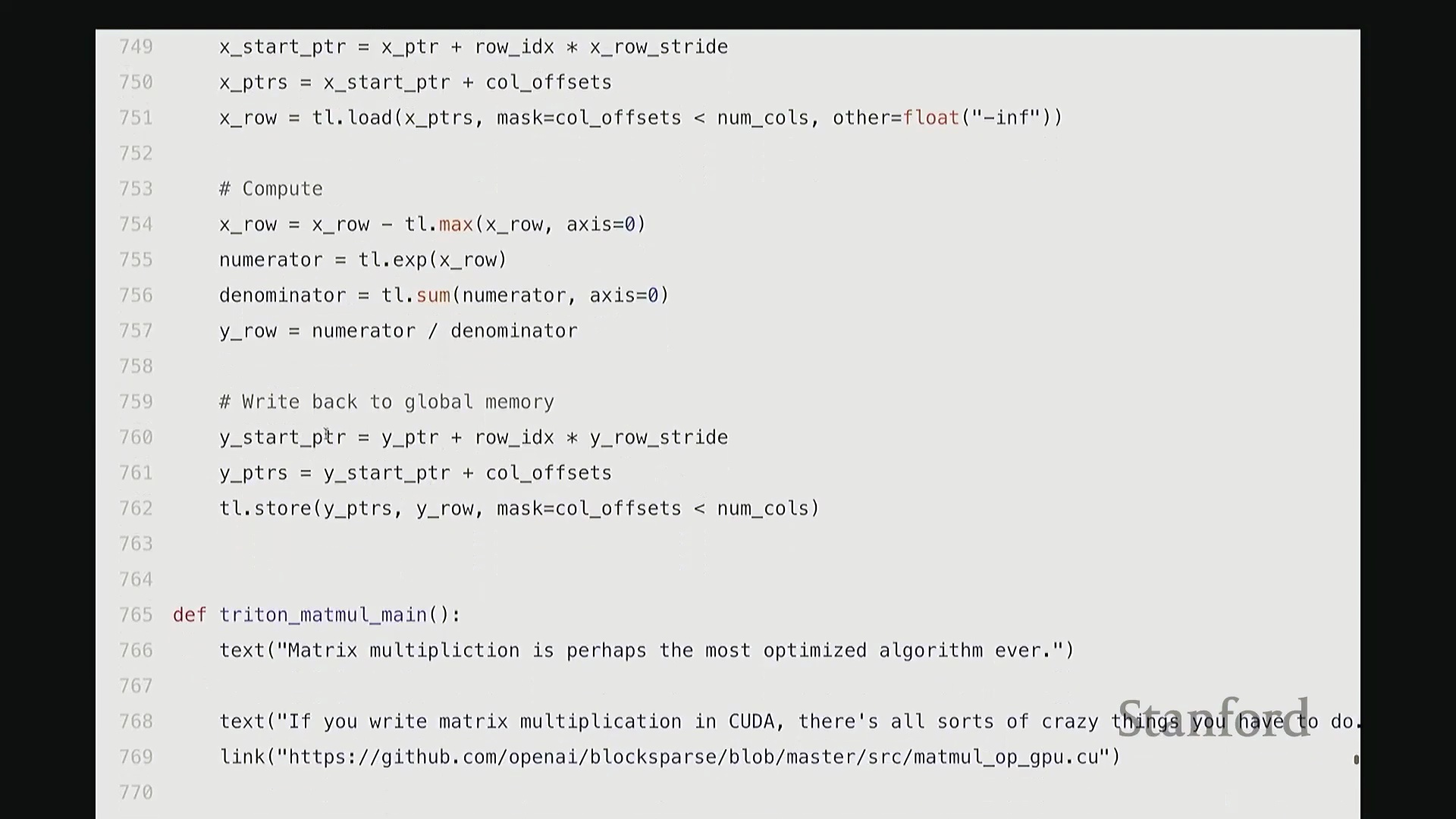
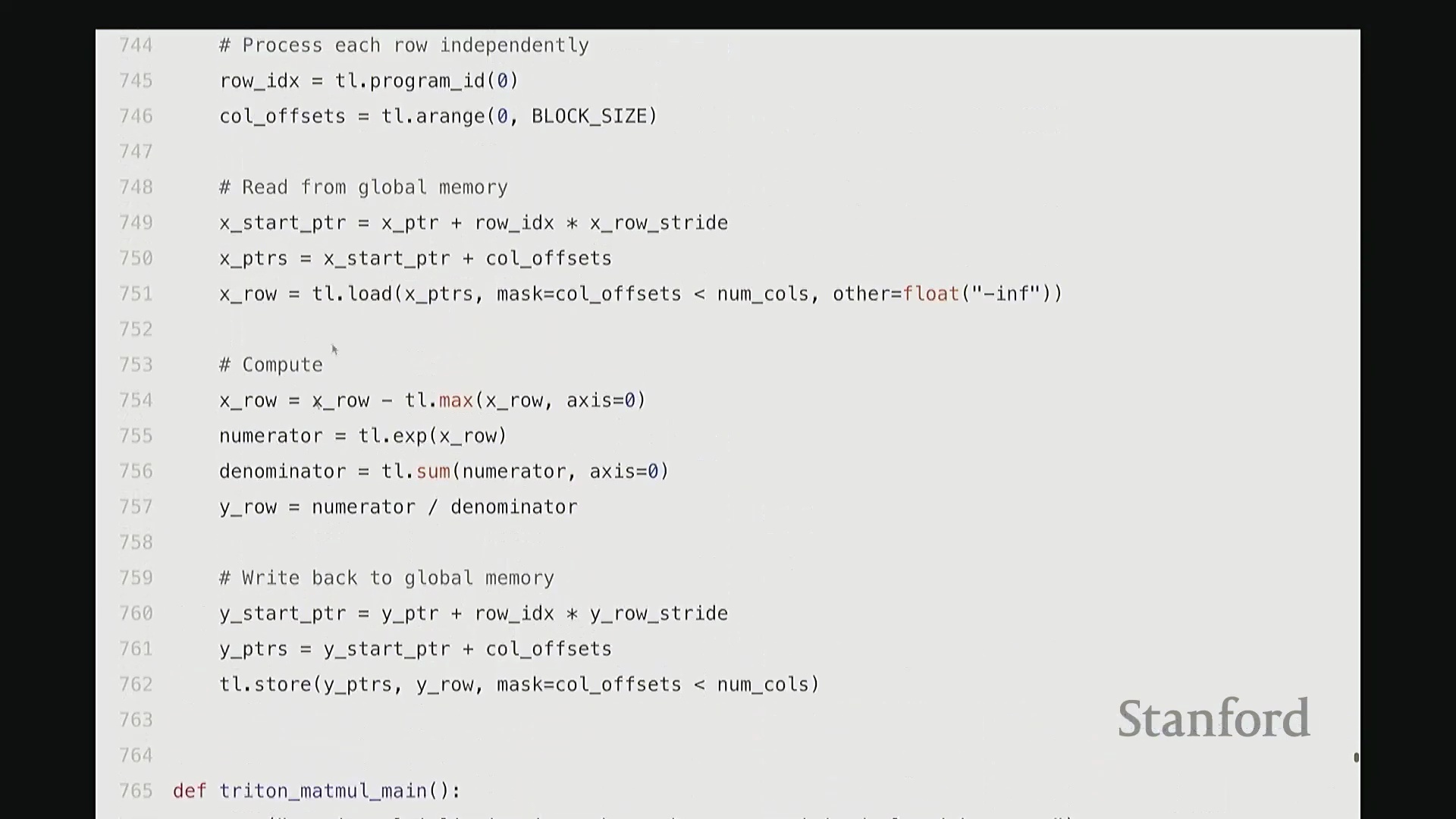
设计归约内核:Triton 中的 Softmax
相较于简单的逐元素操作(Element-wise Operations),Softmax 的计算引入了归约(Reduction)步骤,即必须对输入矩阵每一行的所有数值进行聚合运算。在 Triton 中,一种高效的策略是为矩阵的每一行分配一个独立的线程块(Thread Block),使其由单个流多处理器(Streaming Multiprocessor, SM)负责执行。同时,将块大小向上填充(Padding)至大于等于列数的最小 2 的幂次,以实现最优的内存对齐与硬件吞吐。
 每个线程块将分配到的整行数据加载至 SM 内部的高速共享内存中,随后执行标准的 Softmax 计算流程:减去行最大值(Row Max)、计算指数(Exponentiation)、执行归约求和(Sum Reduction)以及逐元素相除。最终,将归一化结果写回全局内存(Global Memory)。
每个线程块将分配到的整行数据加载至 SM 内部的高速共享内存中,随后执行标准的 Softmax 计算流程:减去行最大值(Row Max)、计算指数(Exponentiation)、执行归约求和(Sum Reduction)以及逐元素相除。最终,将归一化结果写回全局内存(Global Memory)。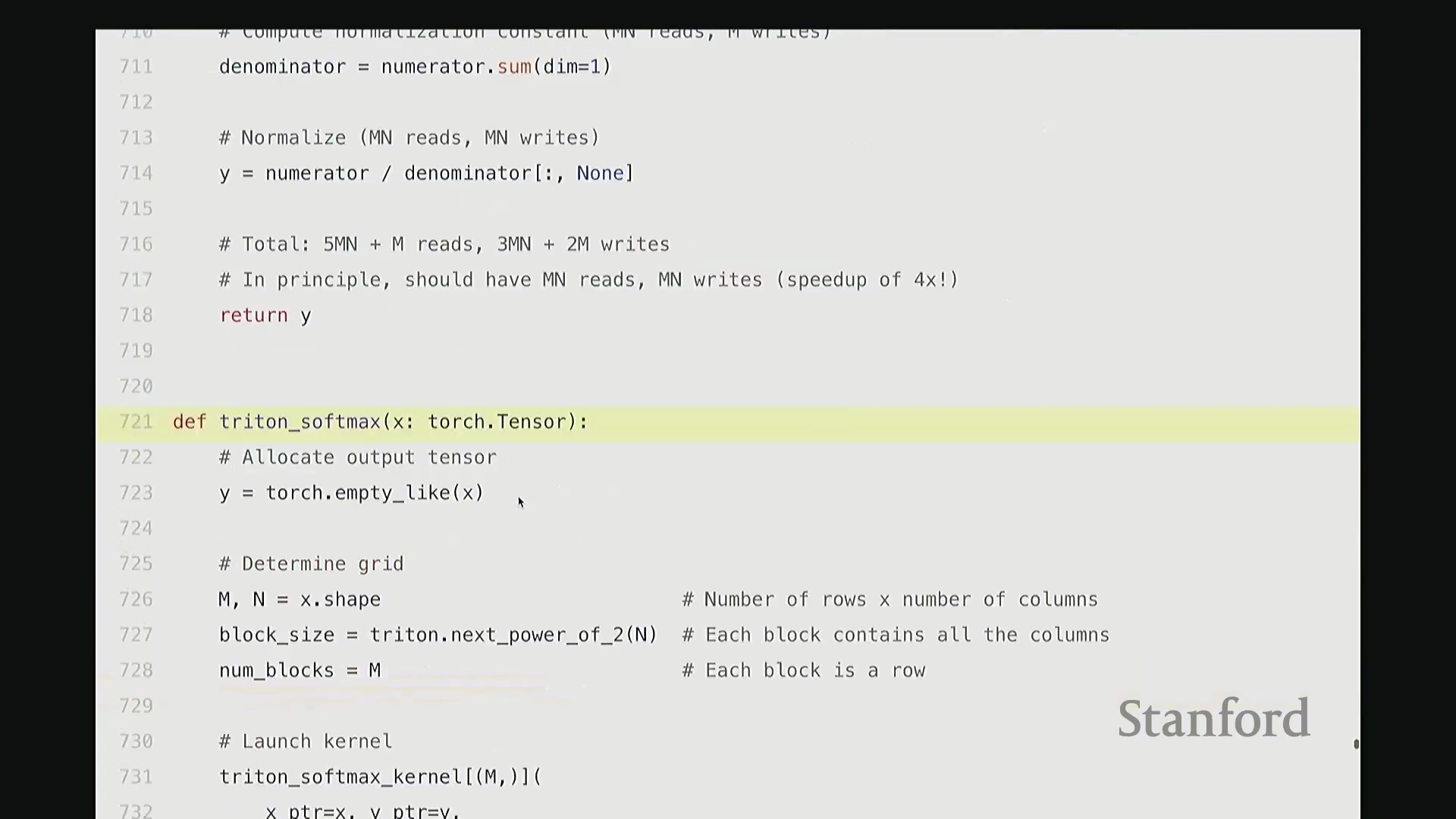
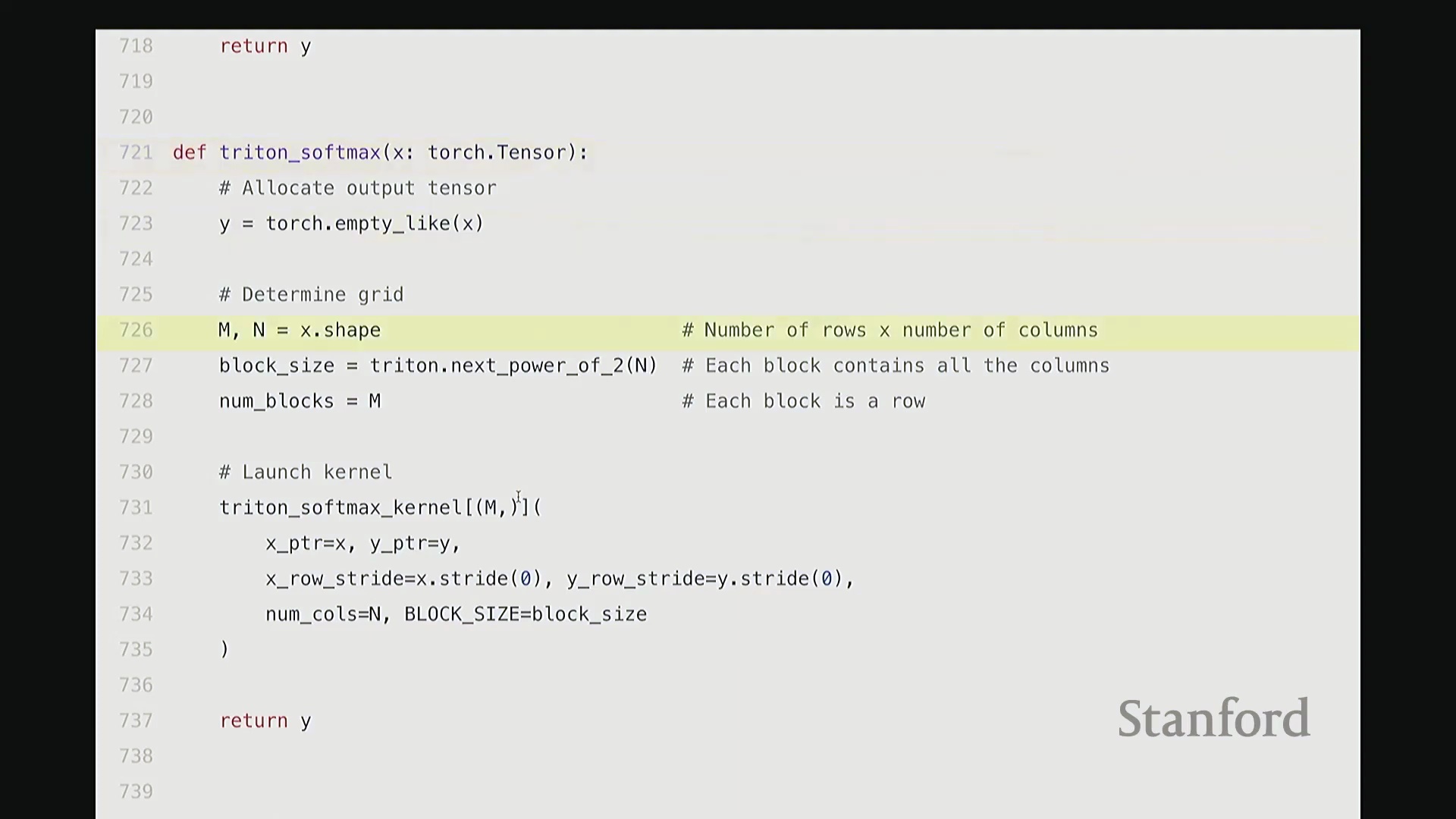 通过将所有归约操作严格限制在 SM 内部完成,该实现不仅保持了极高的代码可读性与 Python 风格的简洁性,更彻底避免了高昂的全局内存往返(Global Memory Round-trip)开销。
通过将所有归约操作严格限制在 SM 内部完成,该实现不仅保持了极高的代码可读性与 Python 风格的简洁性,更彻底避免了高昂的全局内存往返(Global Memory Round-trip)开销。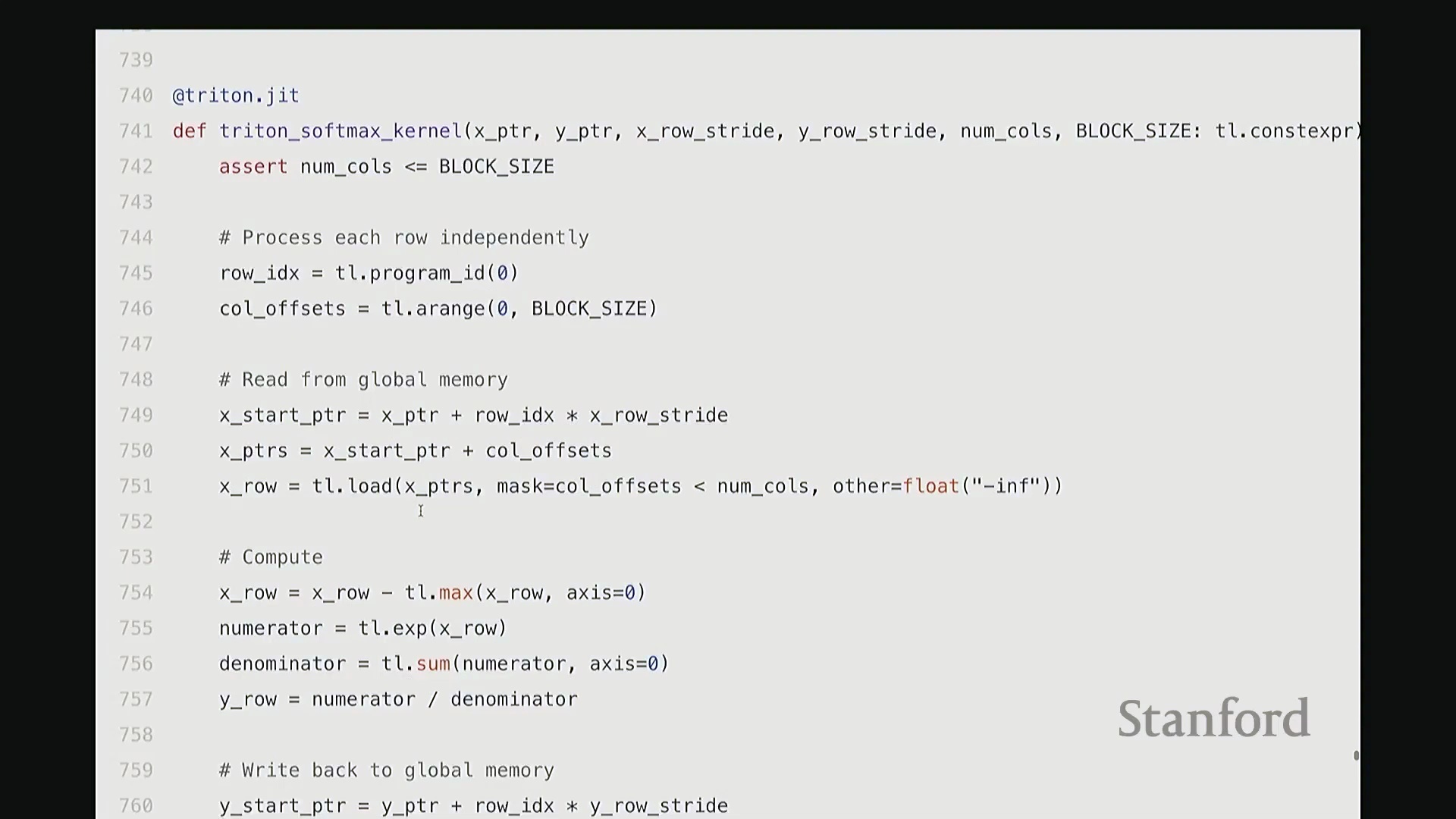
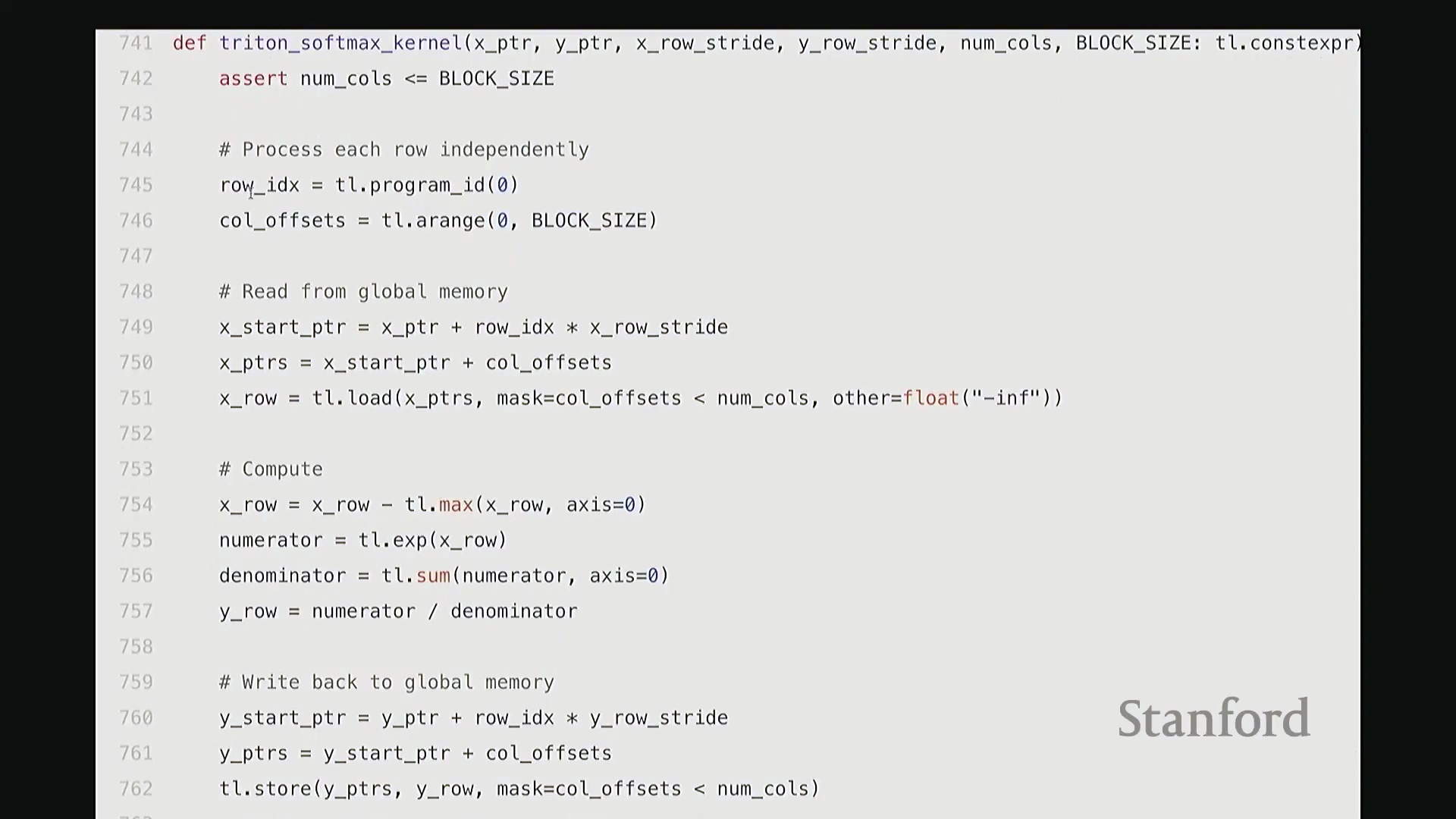
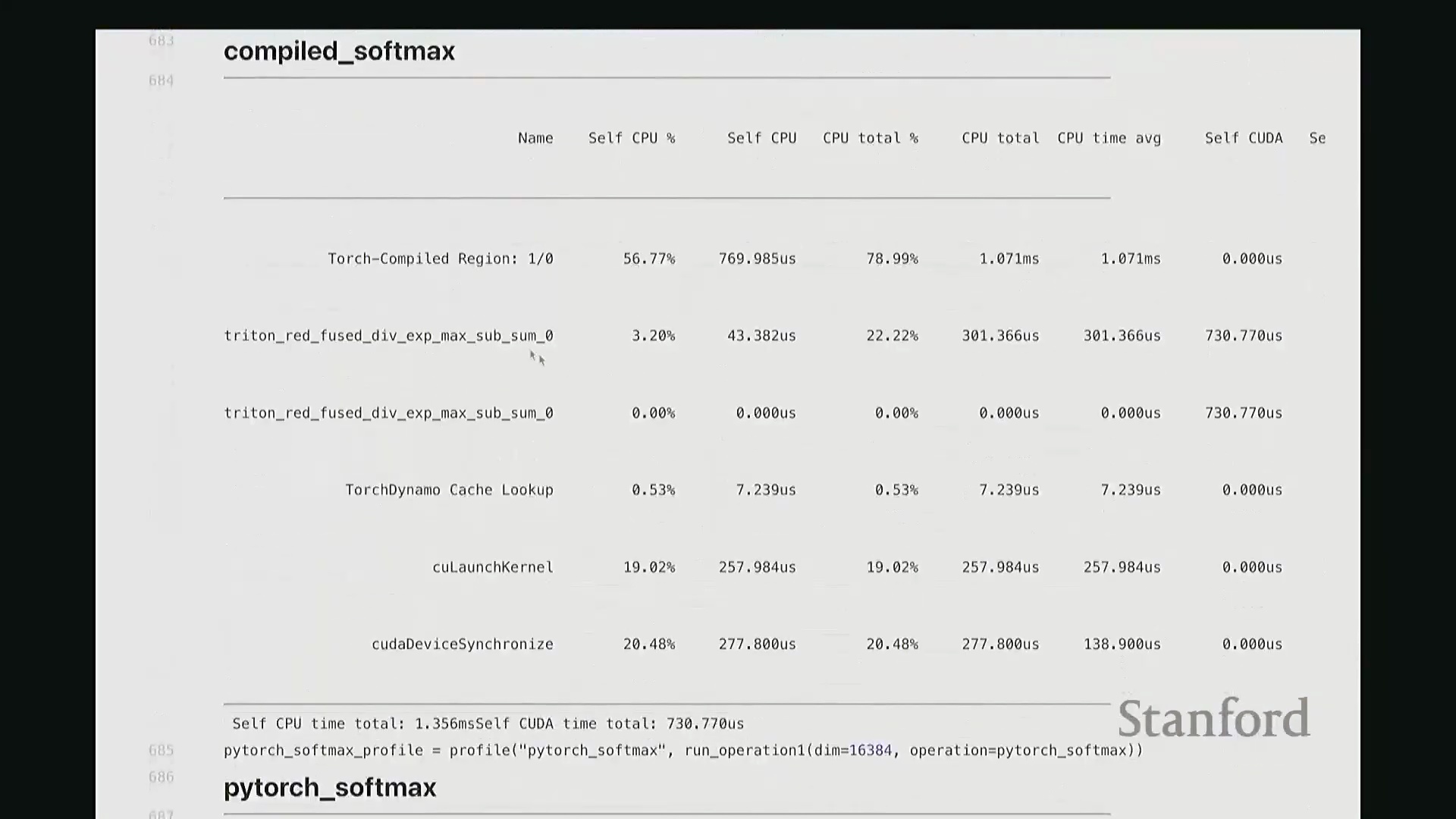
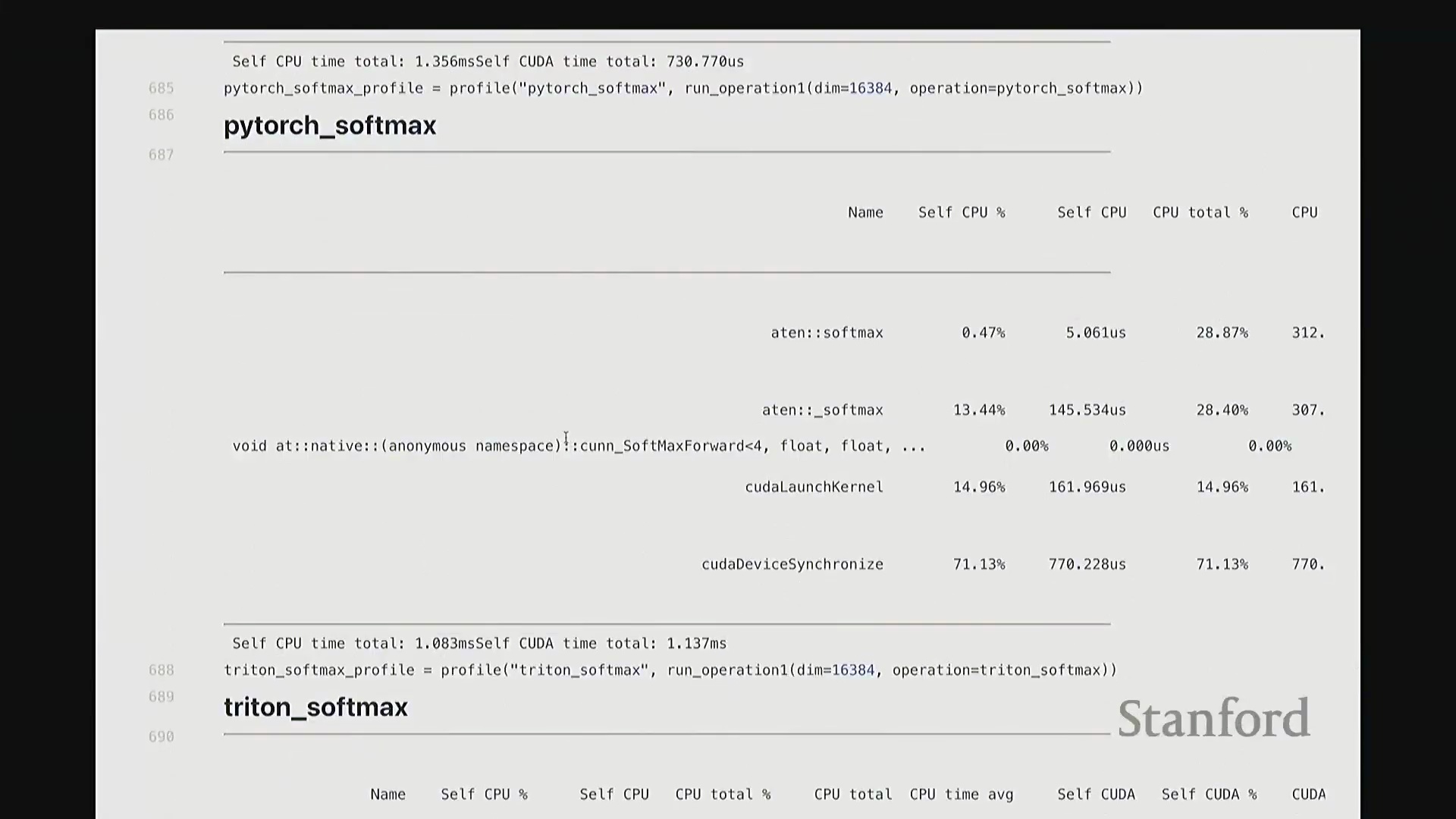
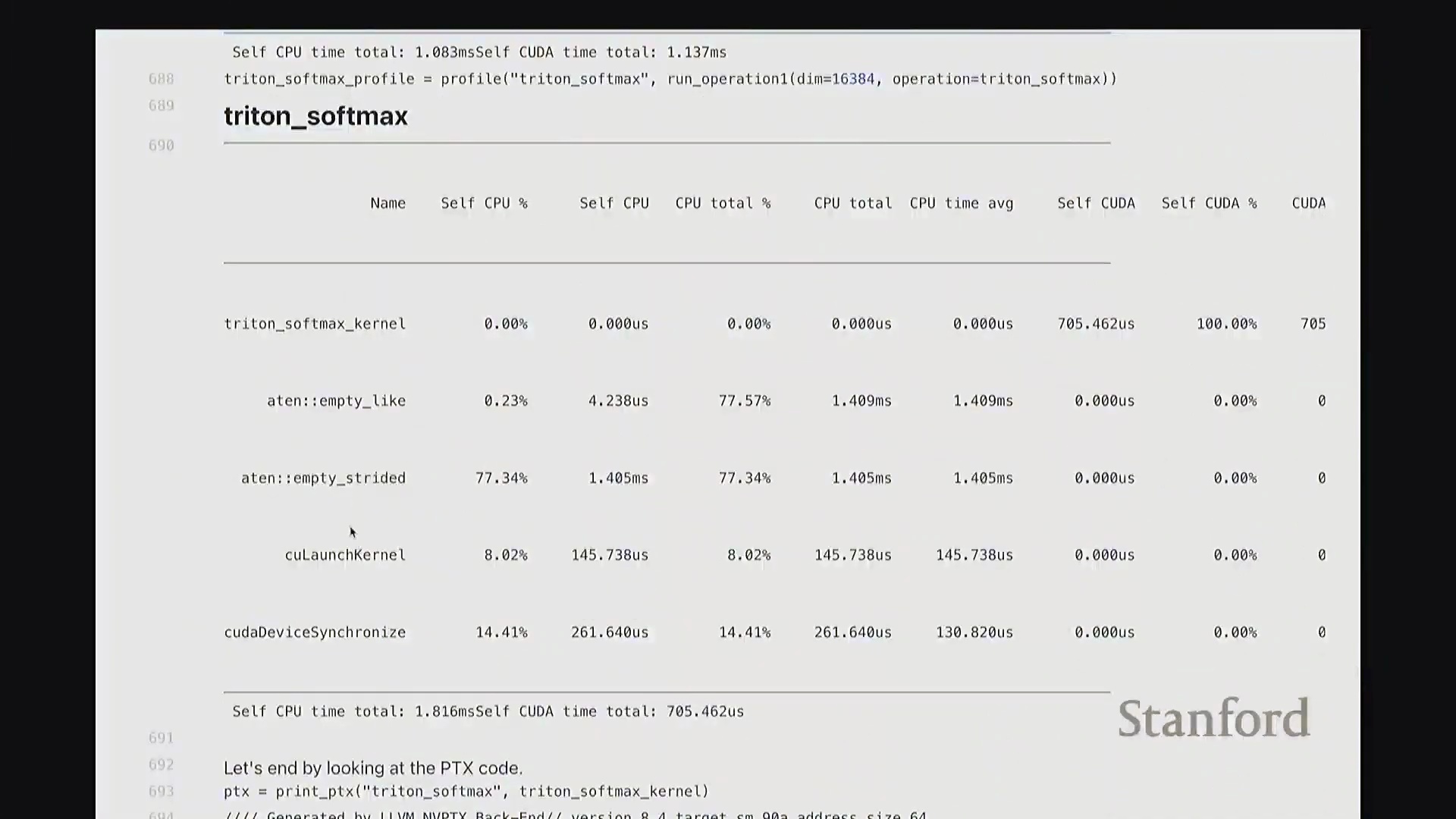
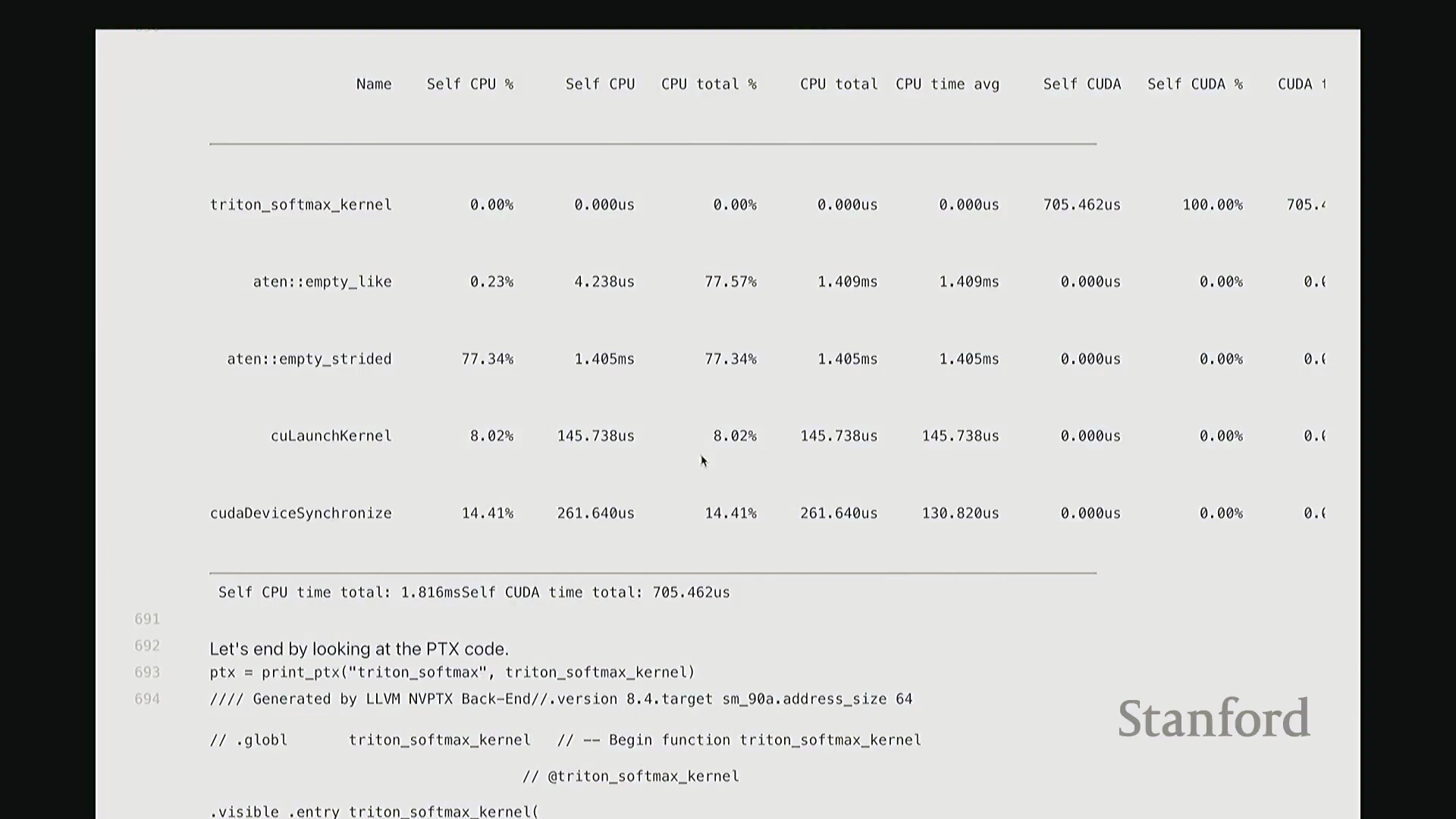
Softmax 性能基准测试与性能分析洞察
对 Softmax 的多种实现方案进行基准测试,充分暴露了朴素实现带来的严重性能损耗:由于内存访问碎片化且缺乏算子融合(Operator Fusion),手动编写的纯 PyTorch 版本耗时高达 3.7 毫秒。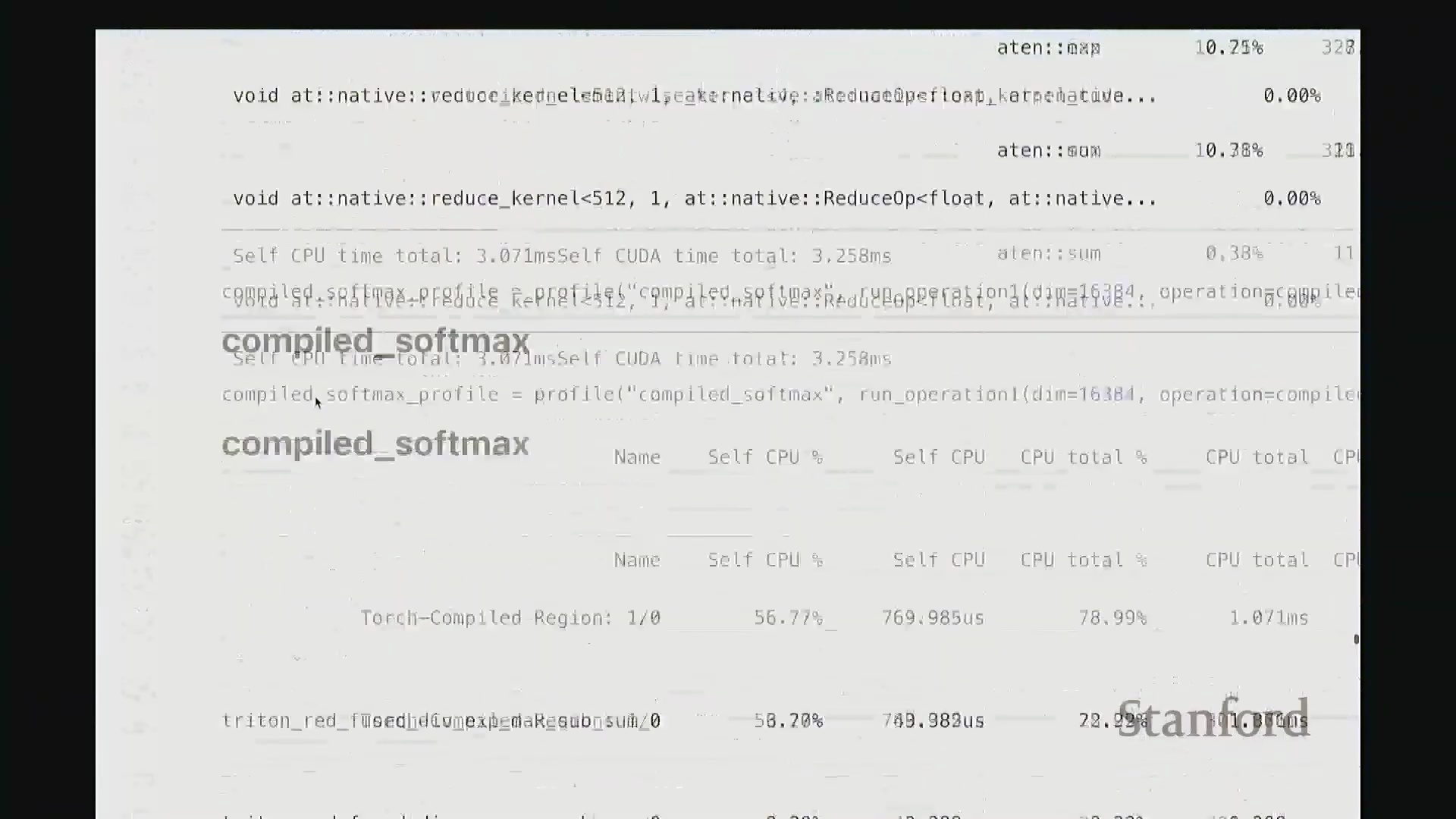
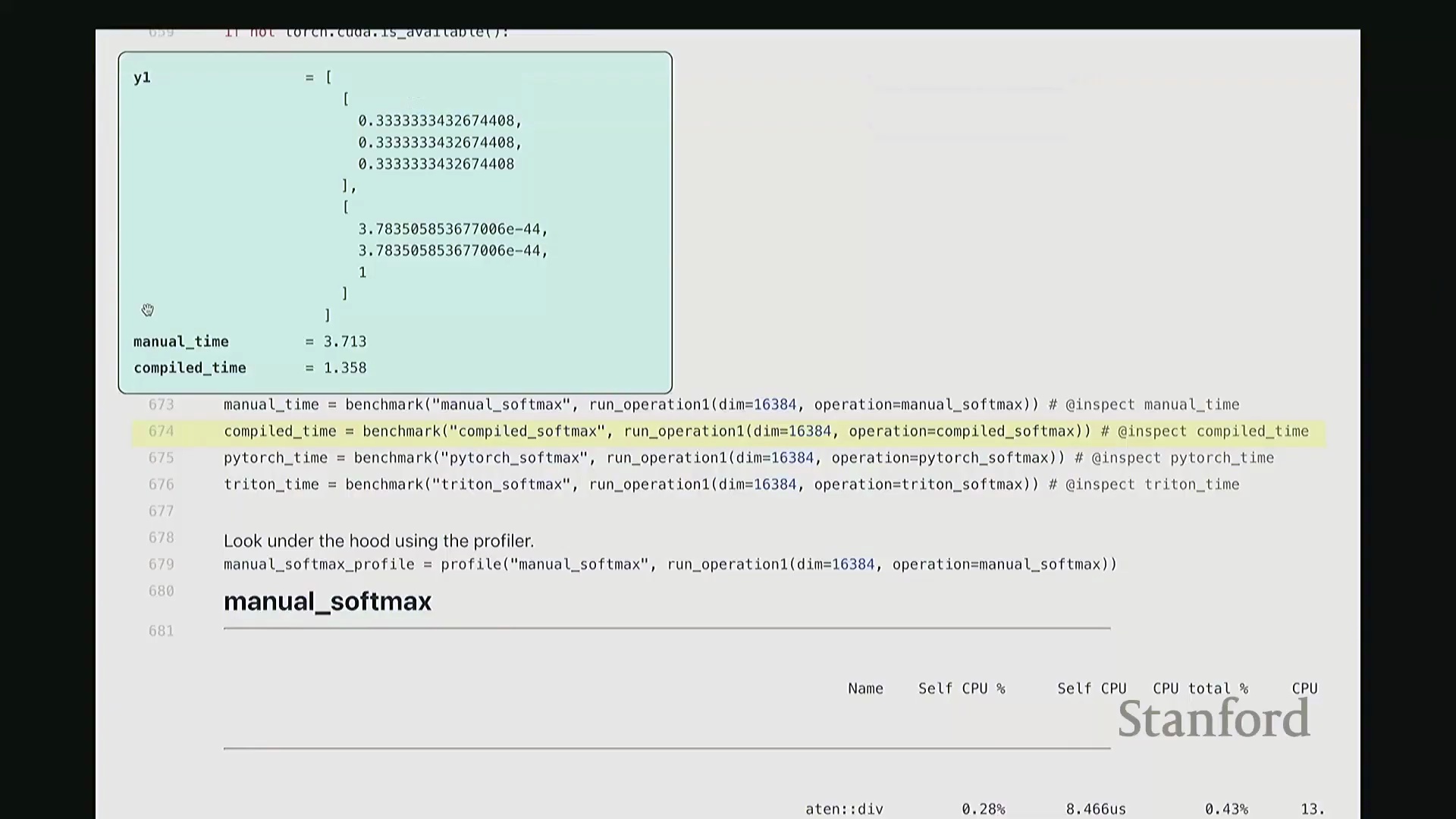 相比之下,
相比之下,torch.compile 凭借底层静态计算图优化(Static Graph Optimization)脱颖而出,以 1.3 毫秒的耗时取得最佳性能;其次是原生 PyTorch 实现(1.5 毫秒)与自定义 Triton 内核(1.9 毫秒)。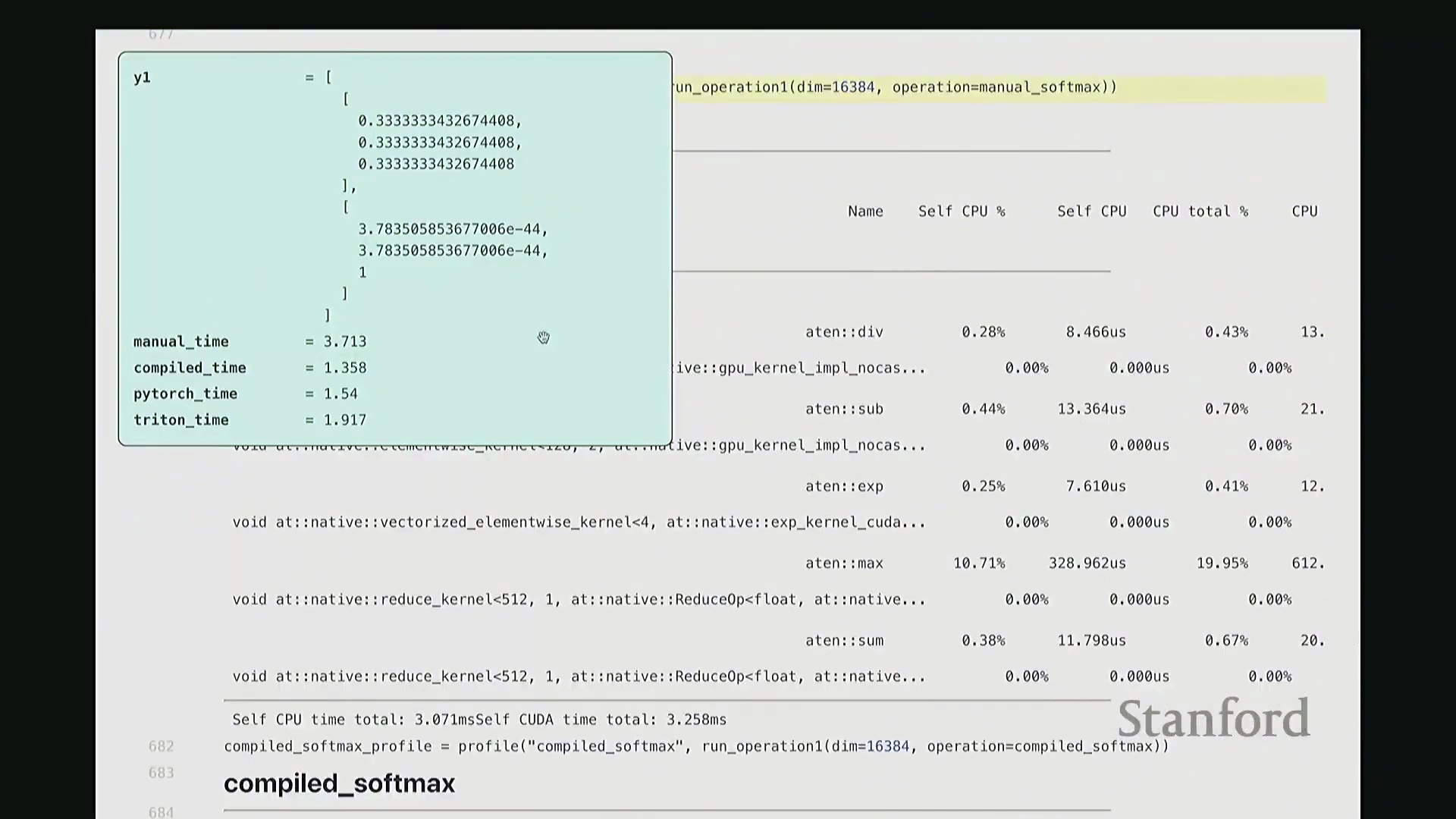 性能剖析时间轴直观印证了上述数据:手动实现呈现出大量零散、非连续的内核启动(Kernel Launch)与频繁的内存 I/O 操作;而
性能剖析时间轴直观印证了上述数据:手动实现呈现出大量零散、非连续的内核启动(Kernel Launch)与频繁的内存 I/O 操作;而 torch.compile、原生 PyTorch 及 Triton 版本均表现为单一、连贯的融合内核执行轨迹。这有力地证明,对于重度依赖归约操作的计算负载(Workload),算子融合是突破性能瓶颈的关键所在。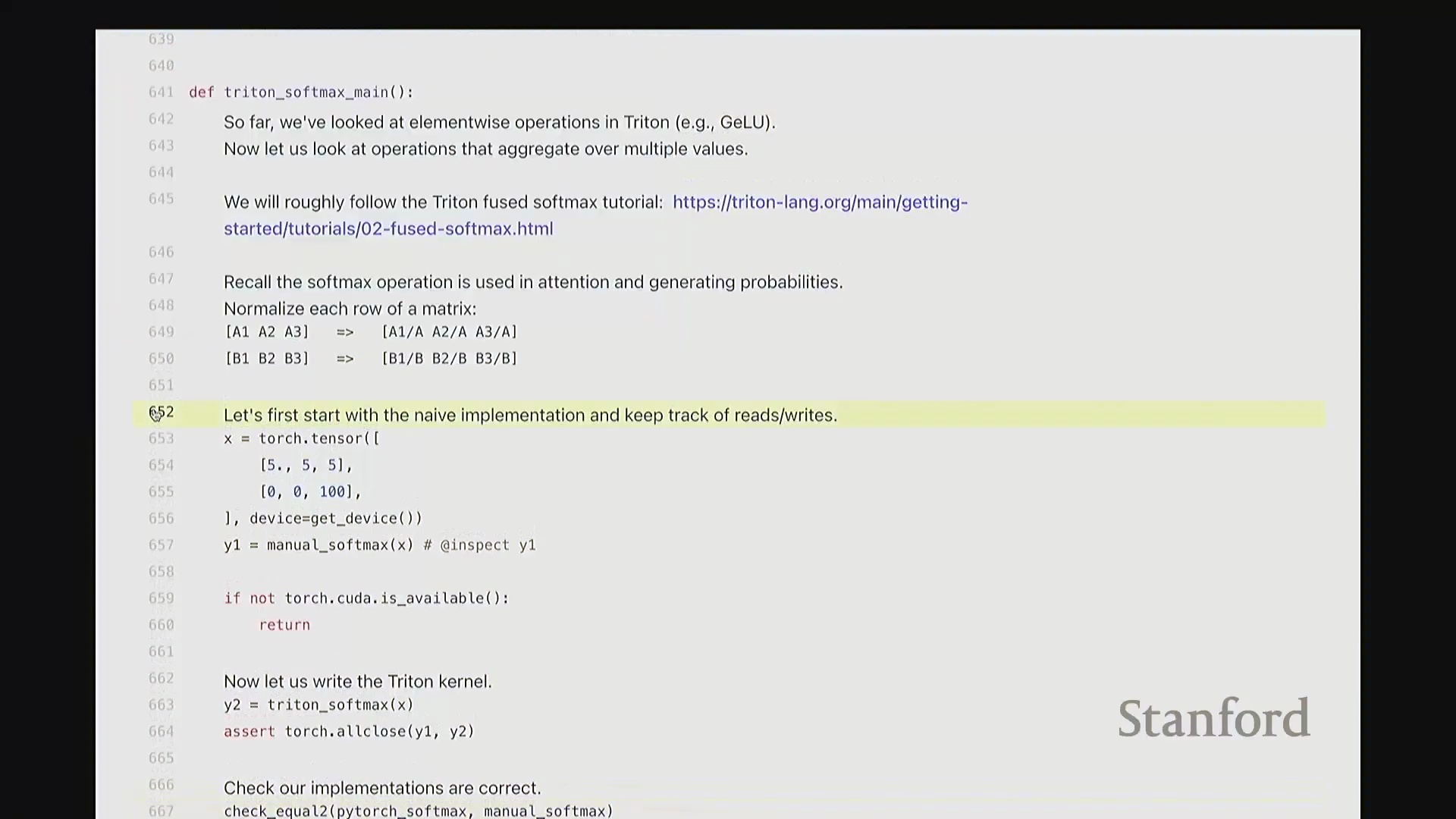
课程总结与结语
 鉴于课程时间有限,我将不再深入展开更多底层实现细节。希望本次内容已帮助大家对底层 GPU 编程(GPU Programming)建立起直观认知。掌握这些优化技术的核心目的,正是为了显著提升语言模型(Language Model)的运行效率。
鉴于课程时间有限,我将不再深入展开更多底层实现细节。希望本次内容已帮助大家对底层 GPU 编程(GPU Programming)建立起直观认知。掌握这些优化技术的核心目的,正是为了显著提升语言模型(Language Model)的运行效率。 也希望大家在完成实践作业(Assignment)的过程中能够乐在其中。谢谢大家!
也希望大家在完成实践作业(Assignment)的过程中能够乐在其中。谢谢大家!