ERaftGroup
讲座概览与效率重点
回顾上一讲关于语言模型(Language Model)和词元化(Tokenization)的内容,本讲将过渡到从零开始构建模型的实际实现。重点将放在 PyTorch 的核心基础组件上,包括张量(Tensor)、模型架构(Model Architecture)、优化器(Optimizer)以及训练循环(Training Loop)。课程将特别强调效率(Efficiency),尤其是模型开发过程中内存和计算资源的利用方式。





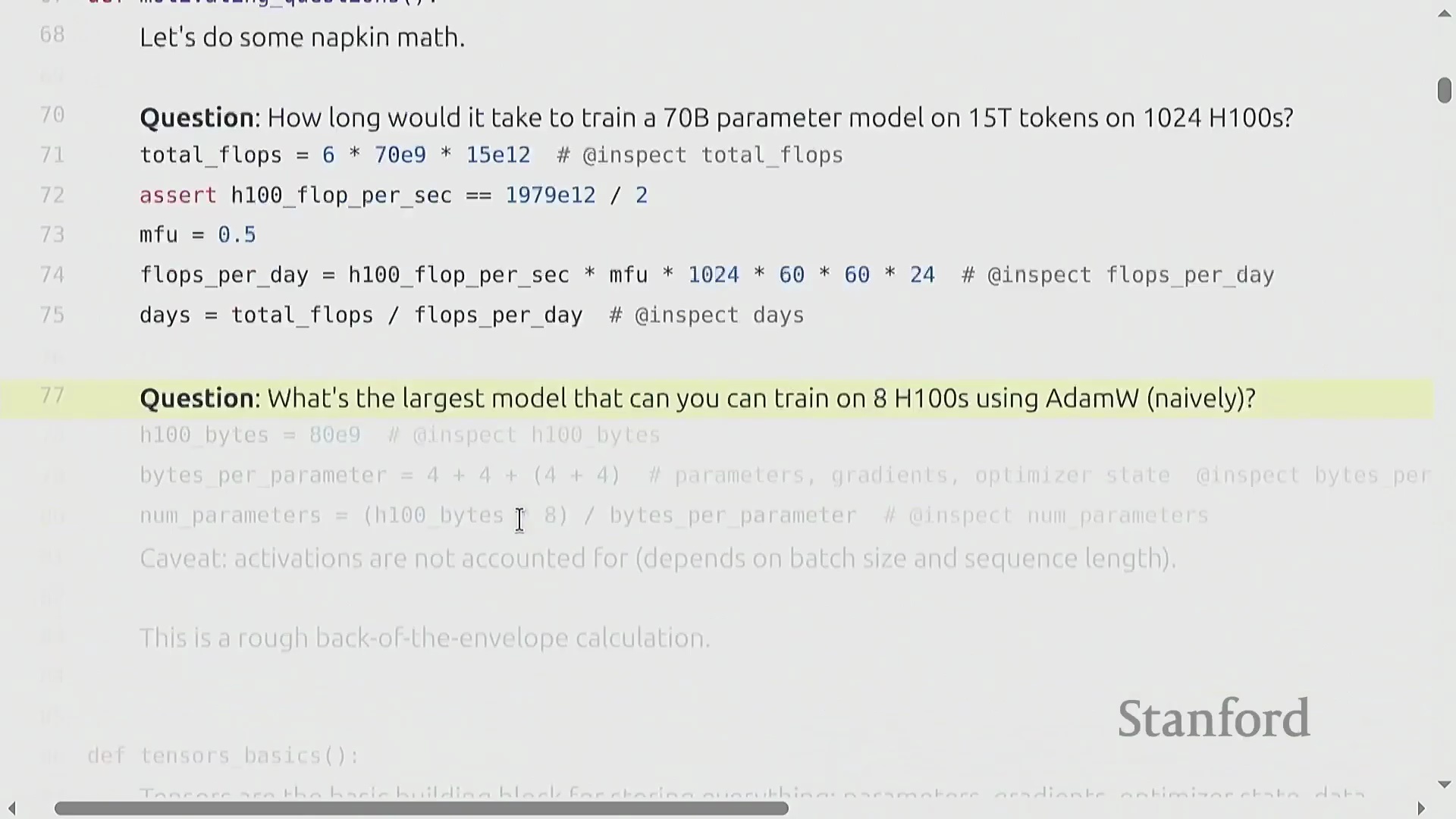
用于估算算力的“餐巾纸数学”
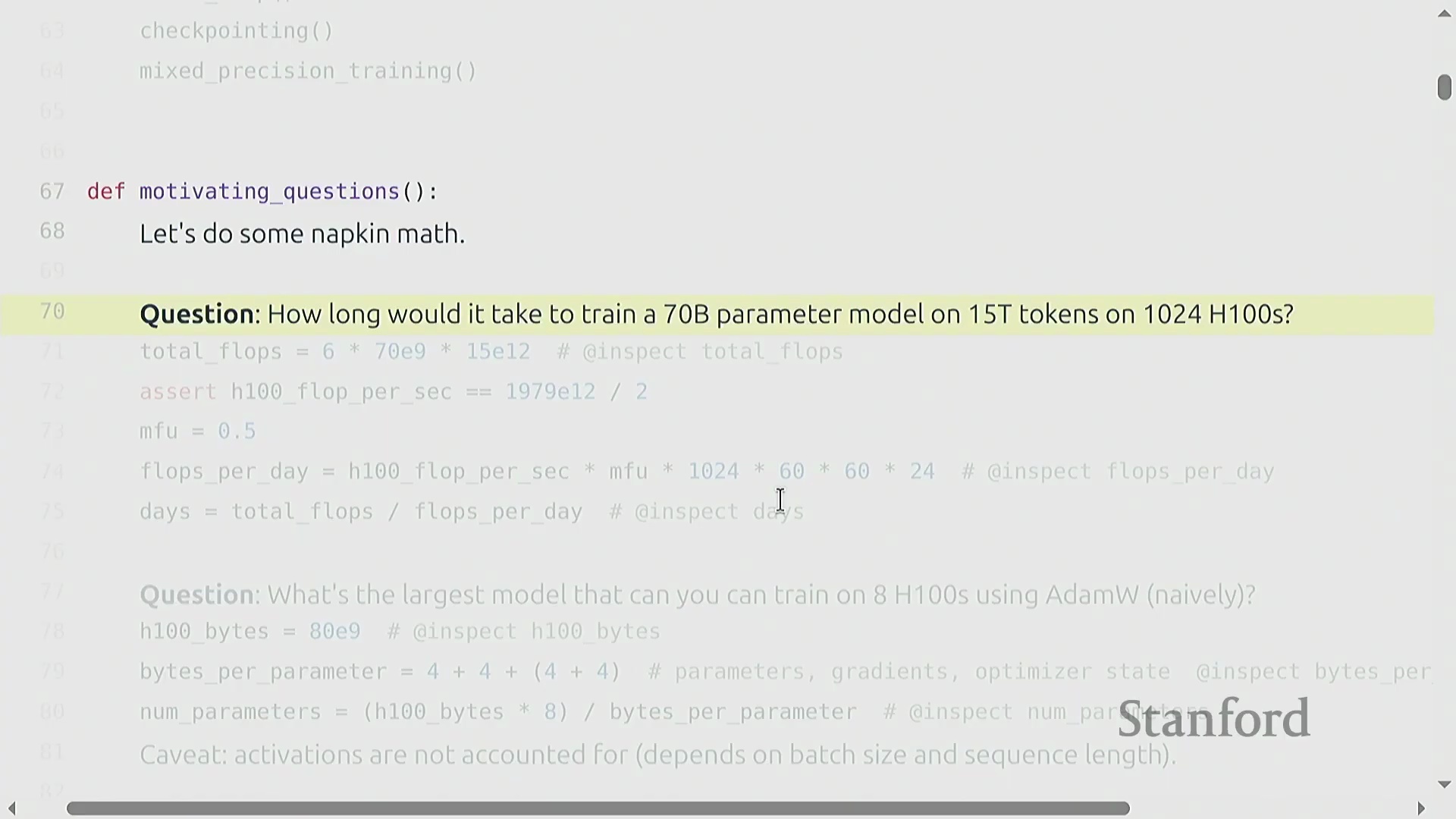
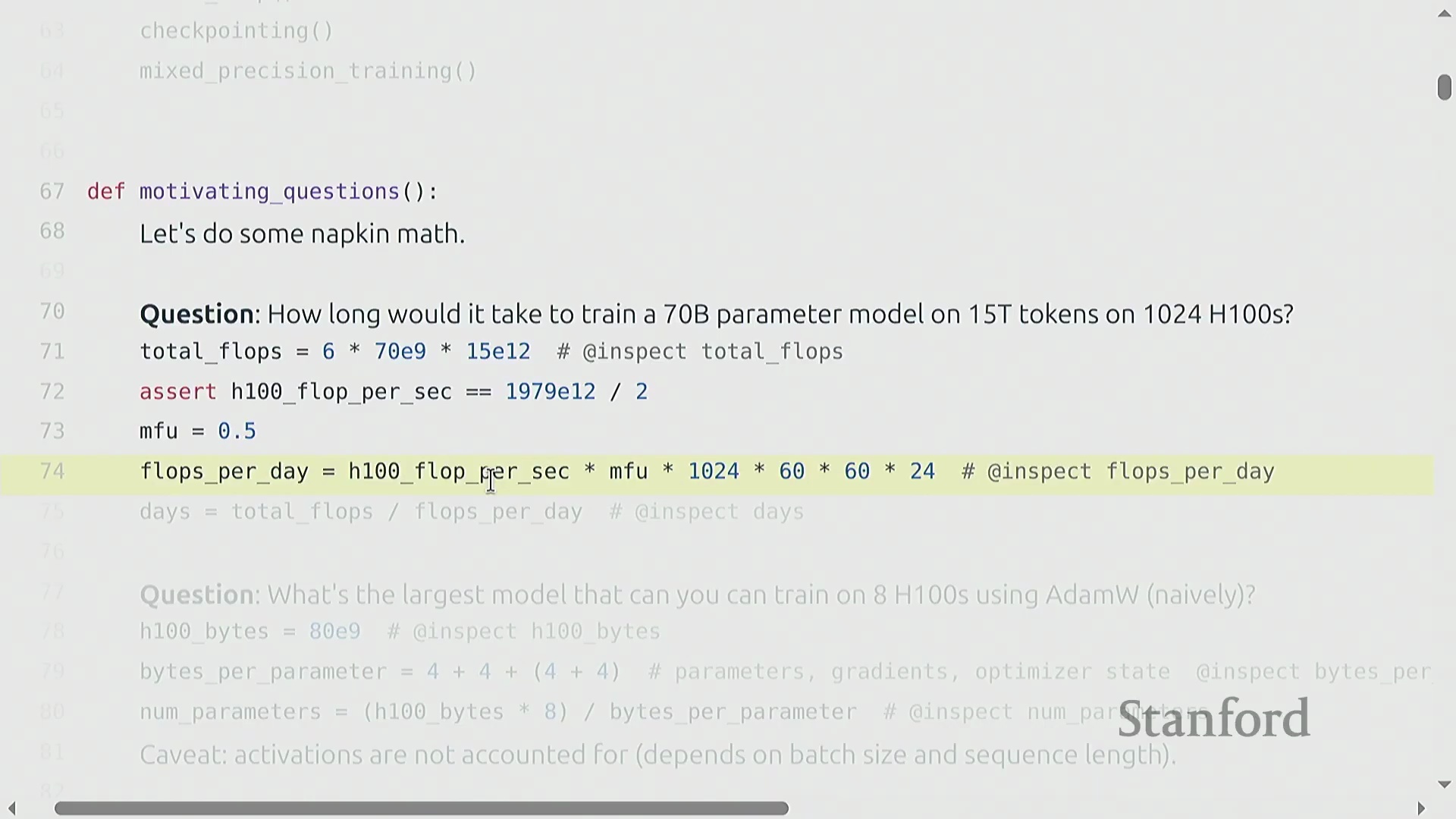
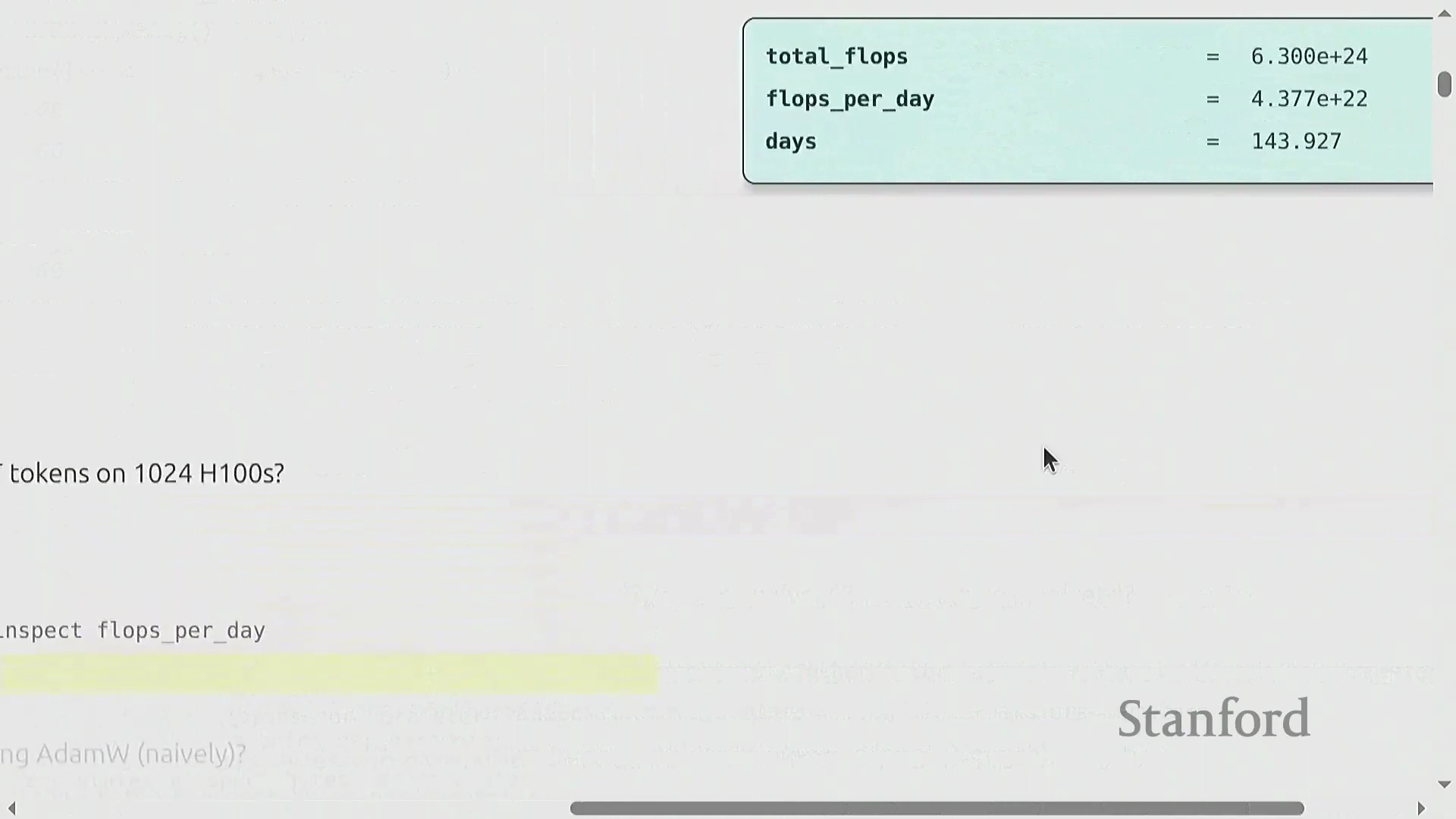
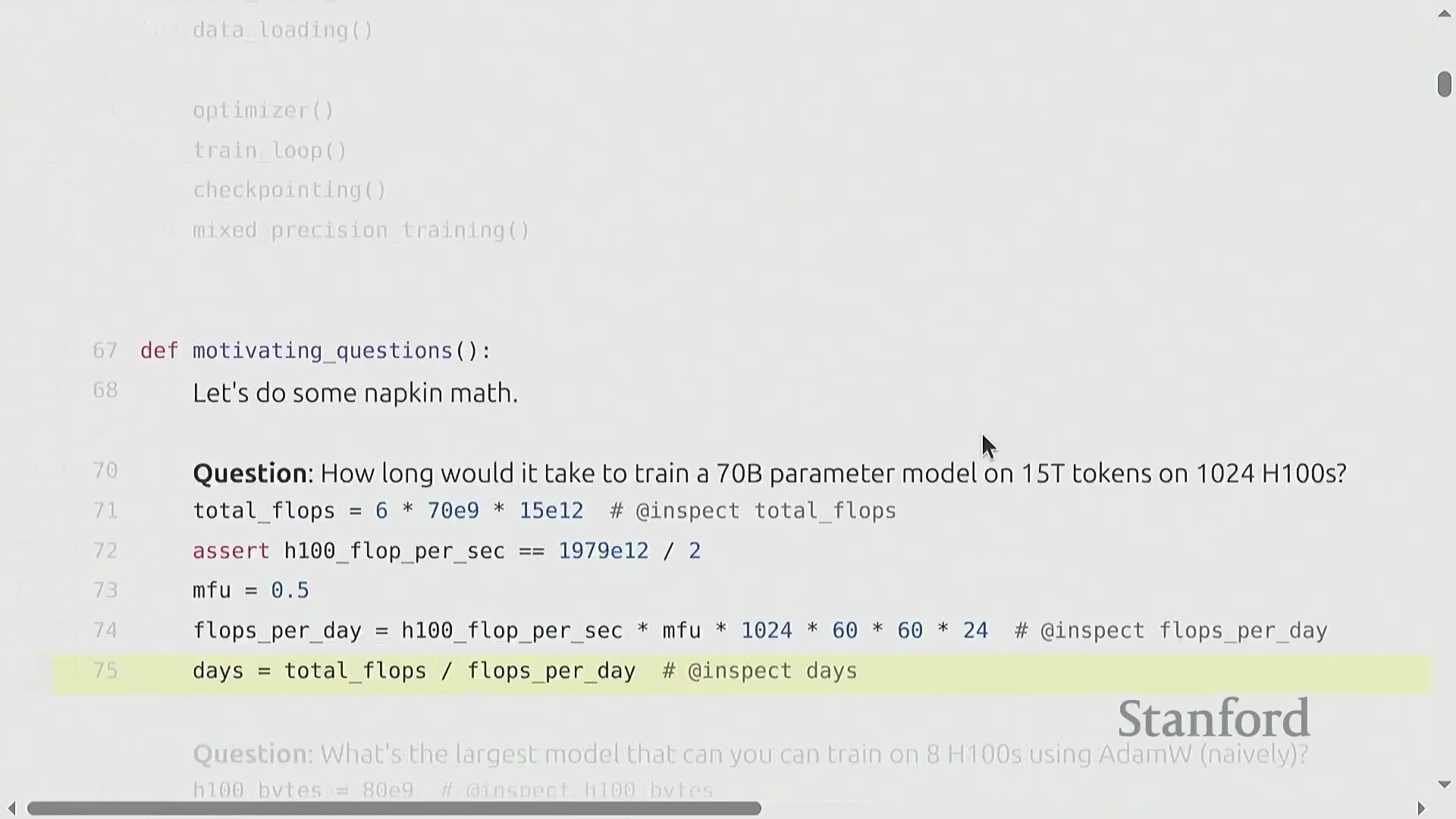
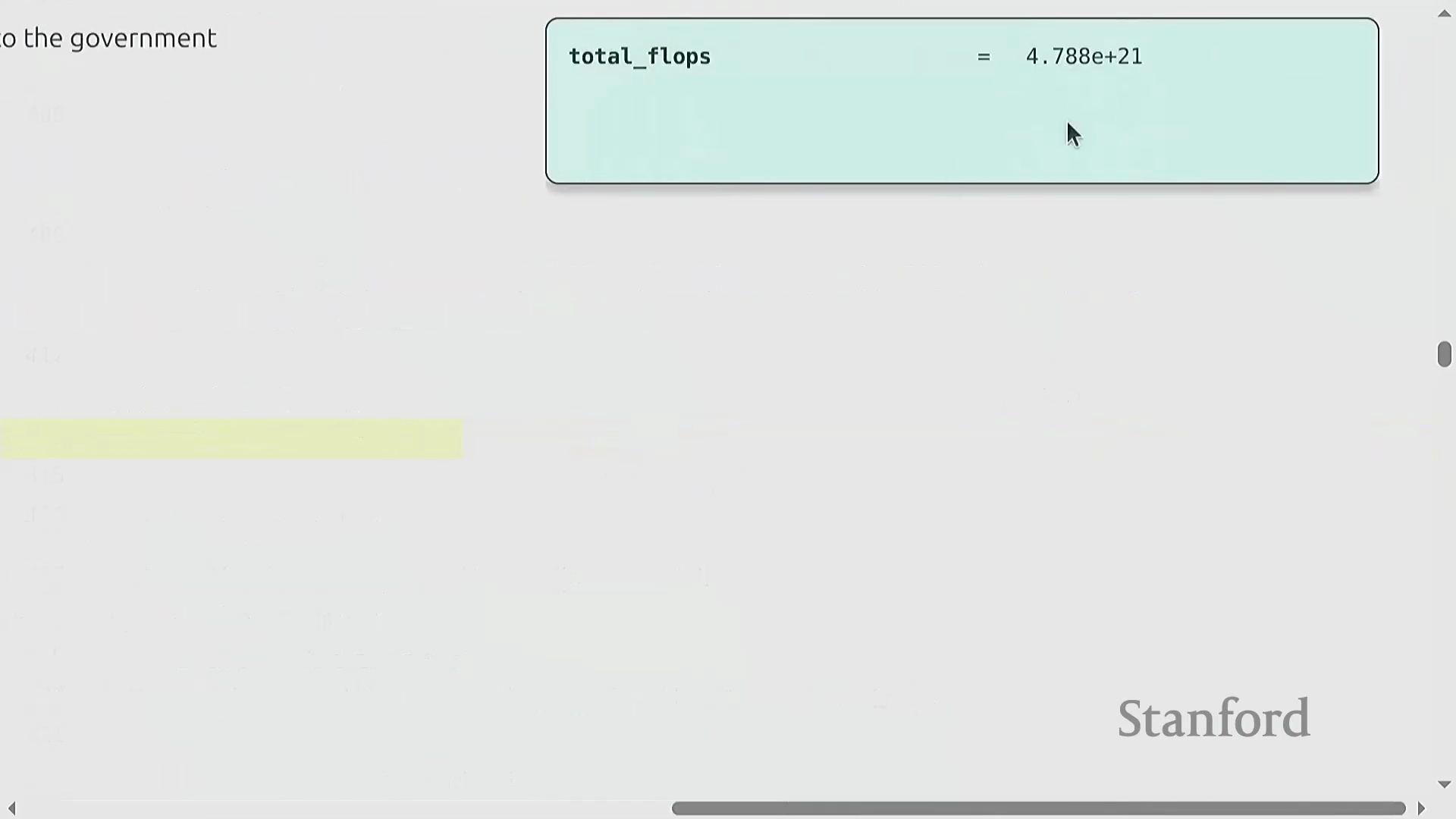
为了将理论概念与实际应用相结合,本讲引入了用于估算训练需求的“餐巾纸数学(Napkin Math)”(指粗略估算方法)。一个关键示例计算了使用 1,024 块 H100 图形处理器(GPU) 在 15 万亿词元上训练一个 700 亿参数 Transformer(Transformer) 模型所需的时间。总所需浮点运算次数(FLOPs)的估算公式为 6 × 参数量 × 词元量。将其除以硬件每日的 FLOPs 峰值算力(假设模型 FLOP 利用率(MFU)为 0.5),估算出的训练时间约为 144 天。掌握这些基础计算对于预测真实世界的训练规模至关重要。
内存限制与资源核算
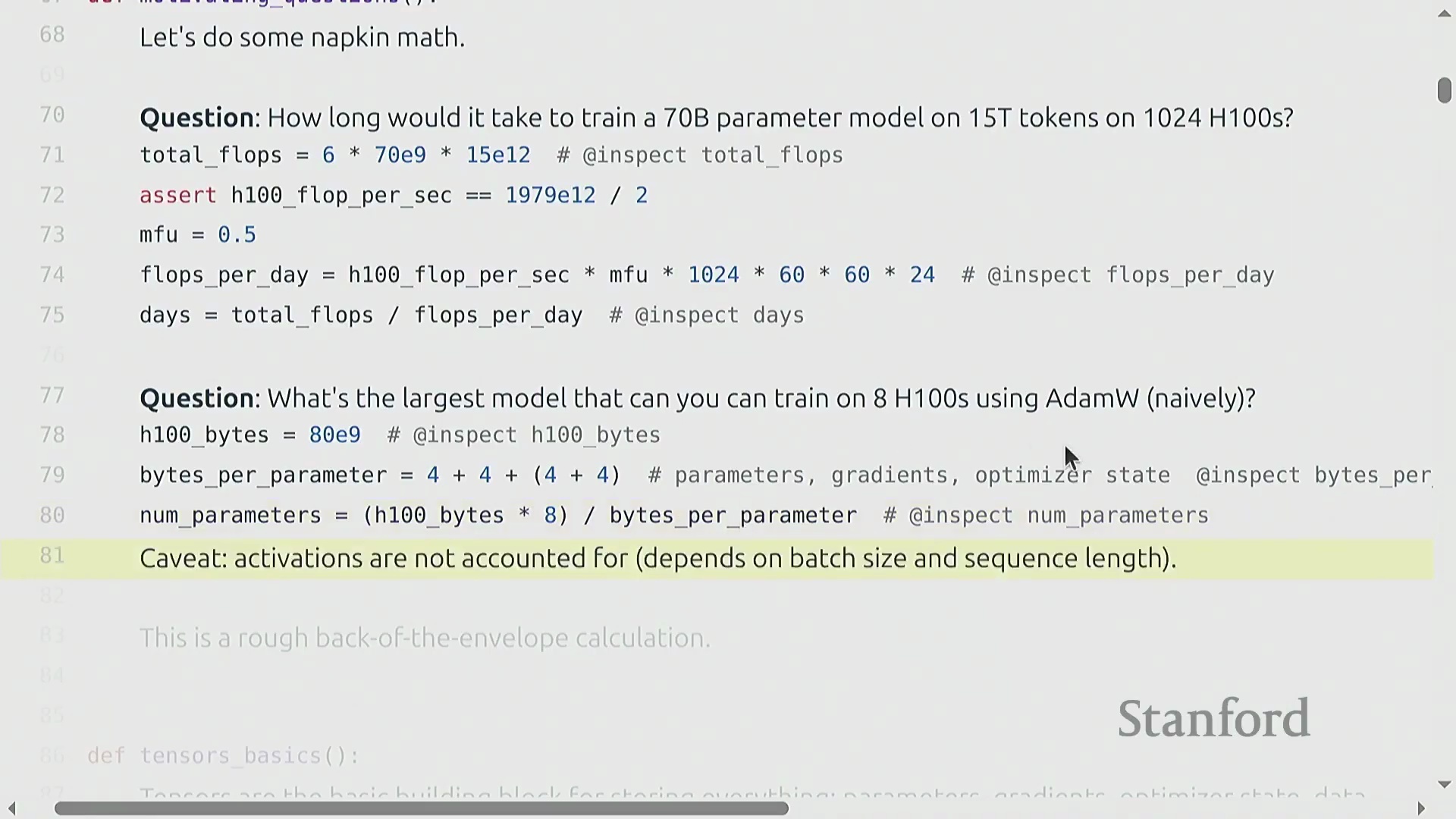
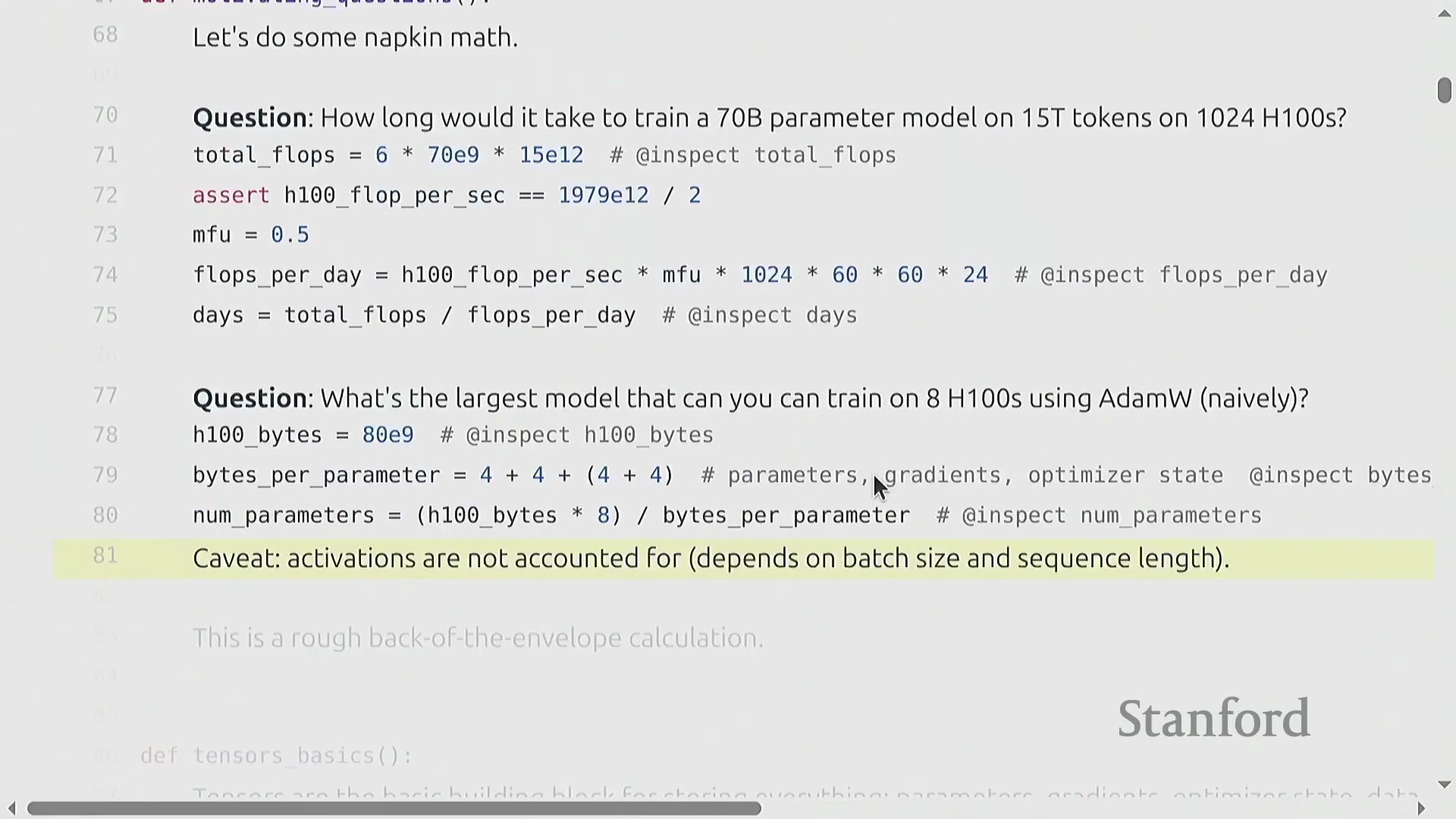
从计算转向内存,本讲探讨了在未使用高级优化技术的情况下,仅使用 AdamW 优化器(AdamW Optimizer)时,单块 H100 GPU(80GB 高带宽内存(HBM))可训练的最大模型规模。考虑到每个参数需占用 16 字节(涵盖权重(Weight)、梯度(Gradient)和优化器状态(Optimizer State)),粗略的估算表明参数量上限约为 400 亿,但这尚未计入激活值(Activation)占用的内存。随着模型规模的扩大,精确的资源核算直接转化为成本控制。详细的 Transformer 架构讲解将留到后续课程,当前重点将严格放在 PyTorch 运行机制与资源追踪上。
学习目标与自底向上策略
本课程的教学框架围绕三大支柱构建:底层机制(Mechanics)(在底层原语(Primitives)层面理解 PyTorch)、思维模式(Mindset)(严谨的资源核算)以及直觉(Intuition)(目前保持宽泛)。当前的首要任务是掌握技术与分析基础,而非急于深入高层模型设计的直觉。教学方法遵循严格的自底向上(Bottom-up)路径:从内存核算开始,过渡到计算核算(Compute Accounting),并逐步构建出完整的训练循环。
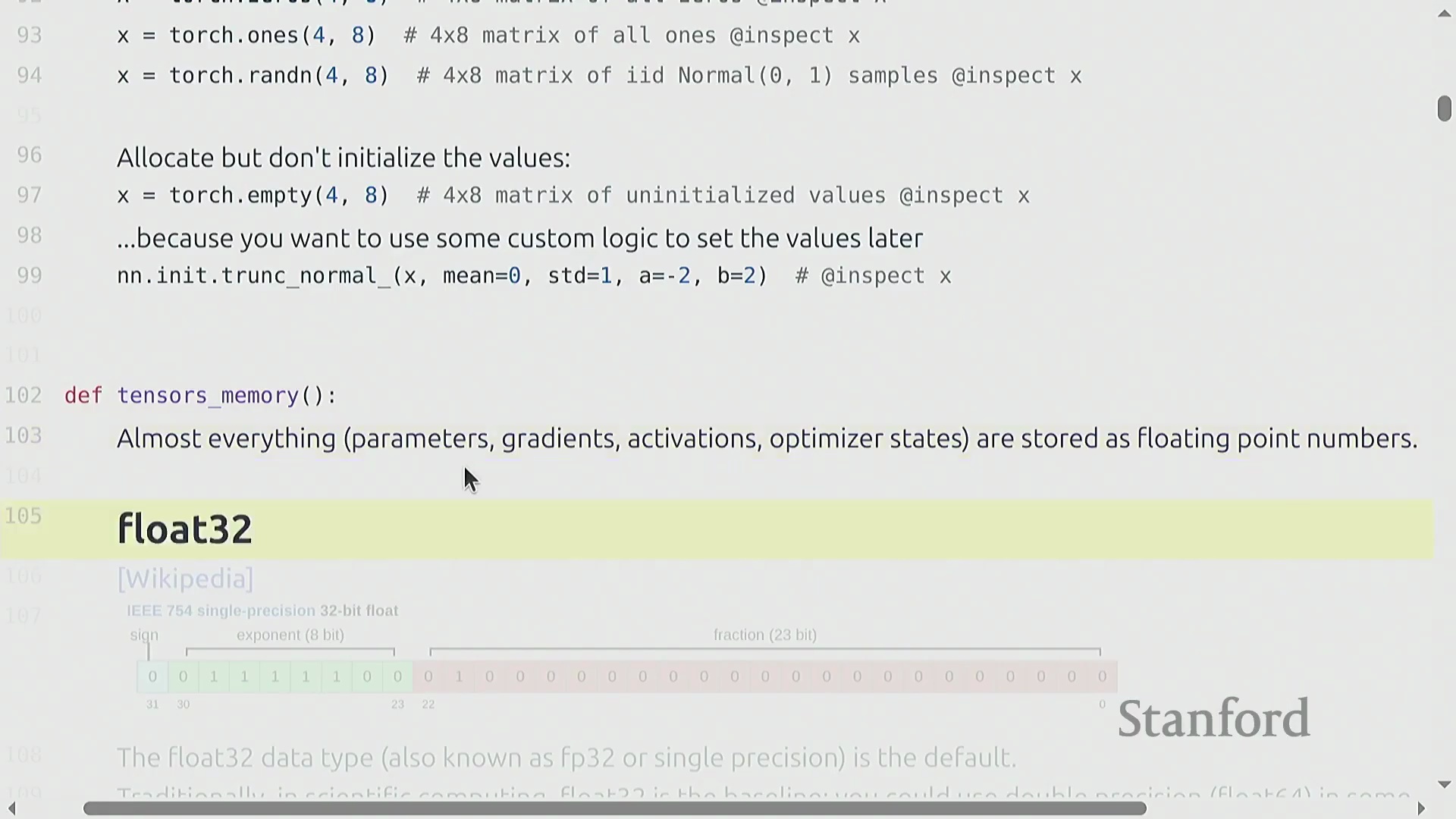
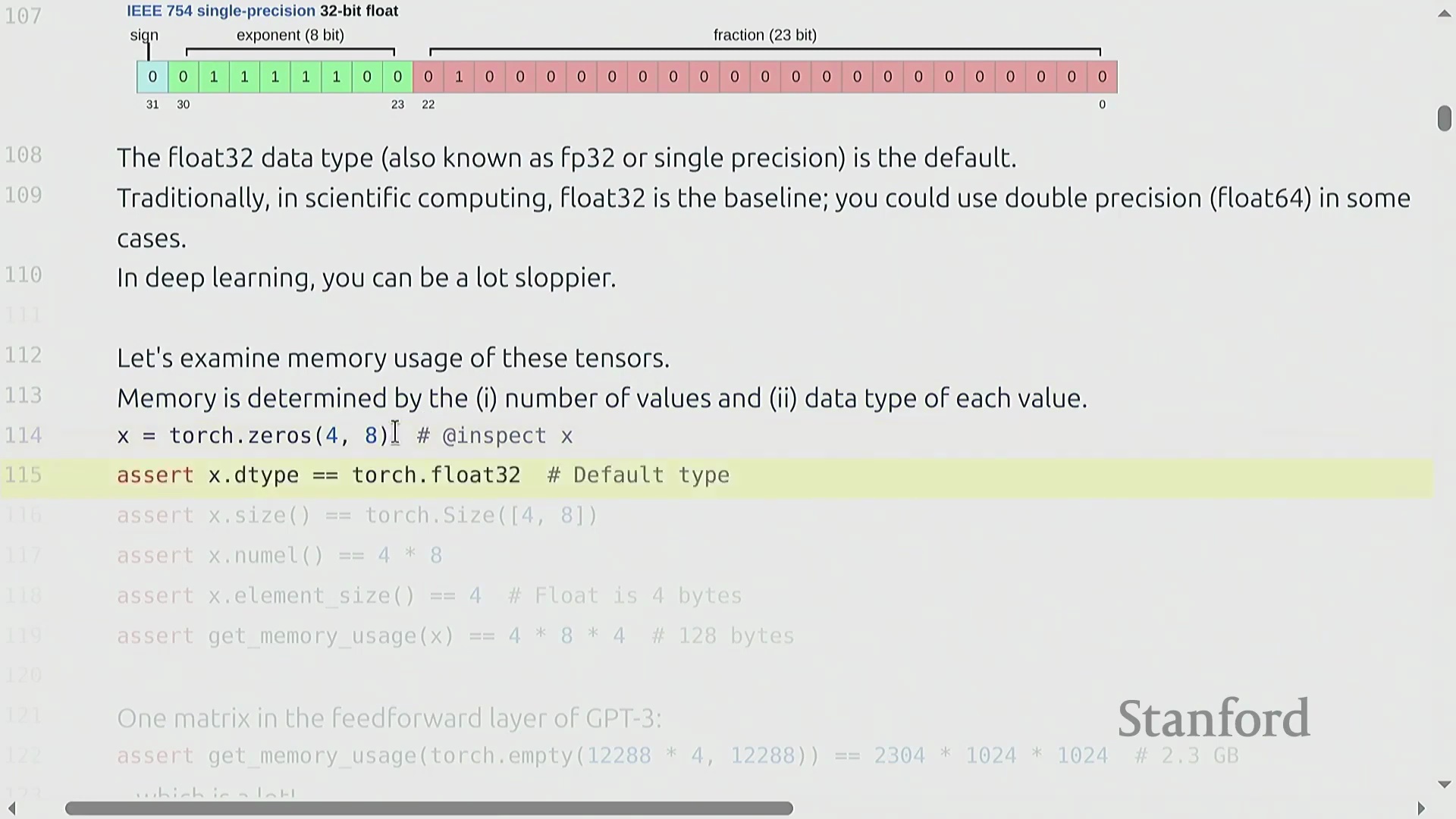
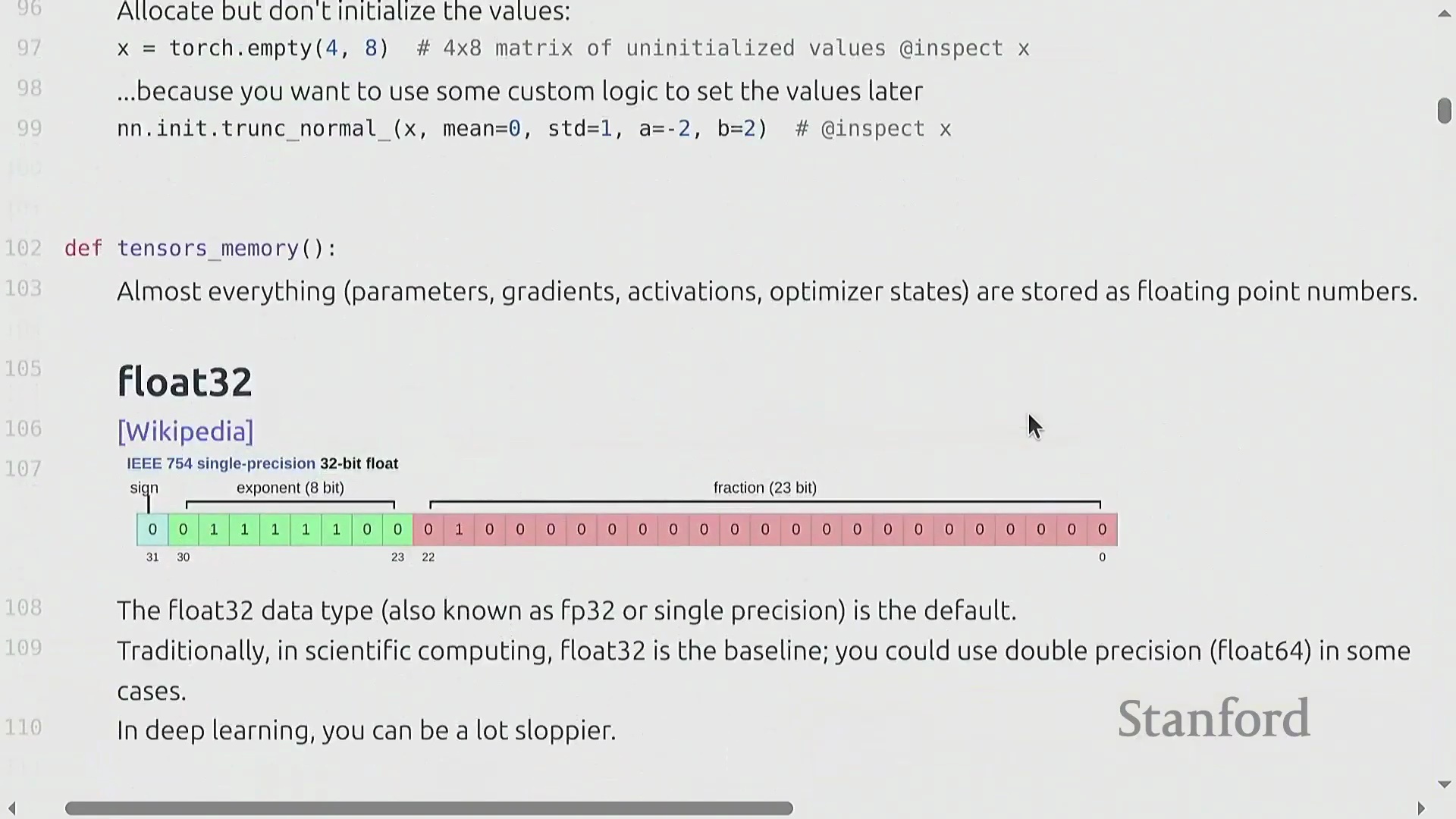
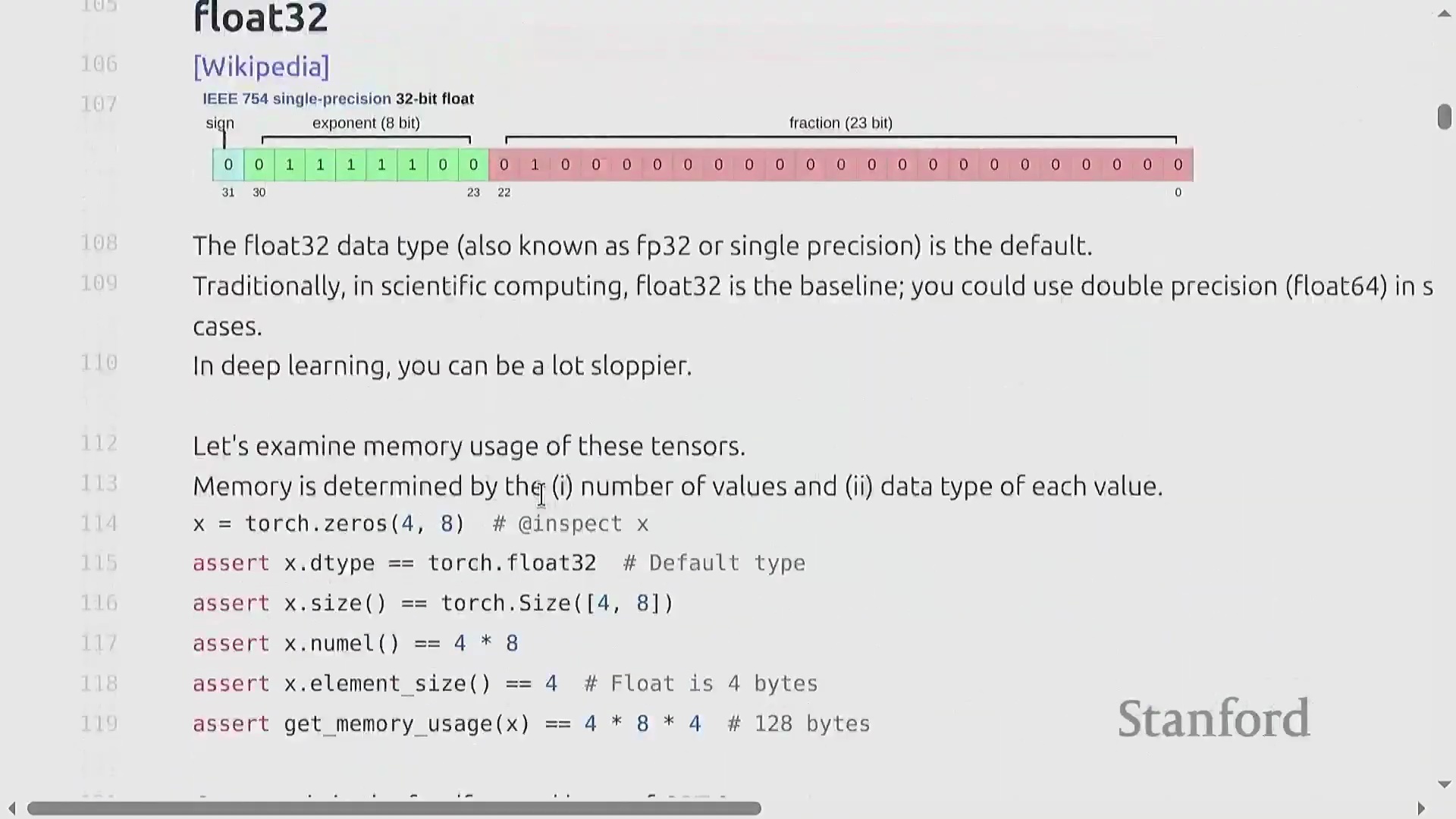
张量与 Float32 内存分配
张量(Tensor)是深度学习中用于存储参数、梯度、激活值和数据的基础原子单元。其内存占用计算非常直观:等于元素数量乘以所选数据类型的字节大小。默认数据类型为单精度浮点数(Float32/FP32),这是一种 32 位格式,包含 1 位符号位(Sign Bit)、8 位指数位(Exponent)和 23 位尾数位(Mantissa)。尽管科学计算常使用双精度浮点数(FP64),但在机器学习领域,FP32 被广泛视为“全精度(Full Precision)”。例如,一个 4×8 的张量仅占用 128 字节,但像 GPT-3 这样的大模型中的单个矩阵轻松就能达到 2.3GB,这凸显了内存优化为何如此关键。





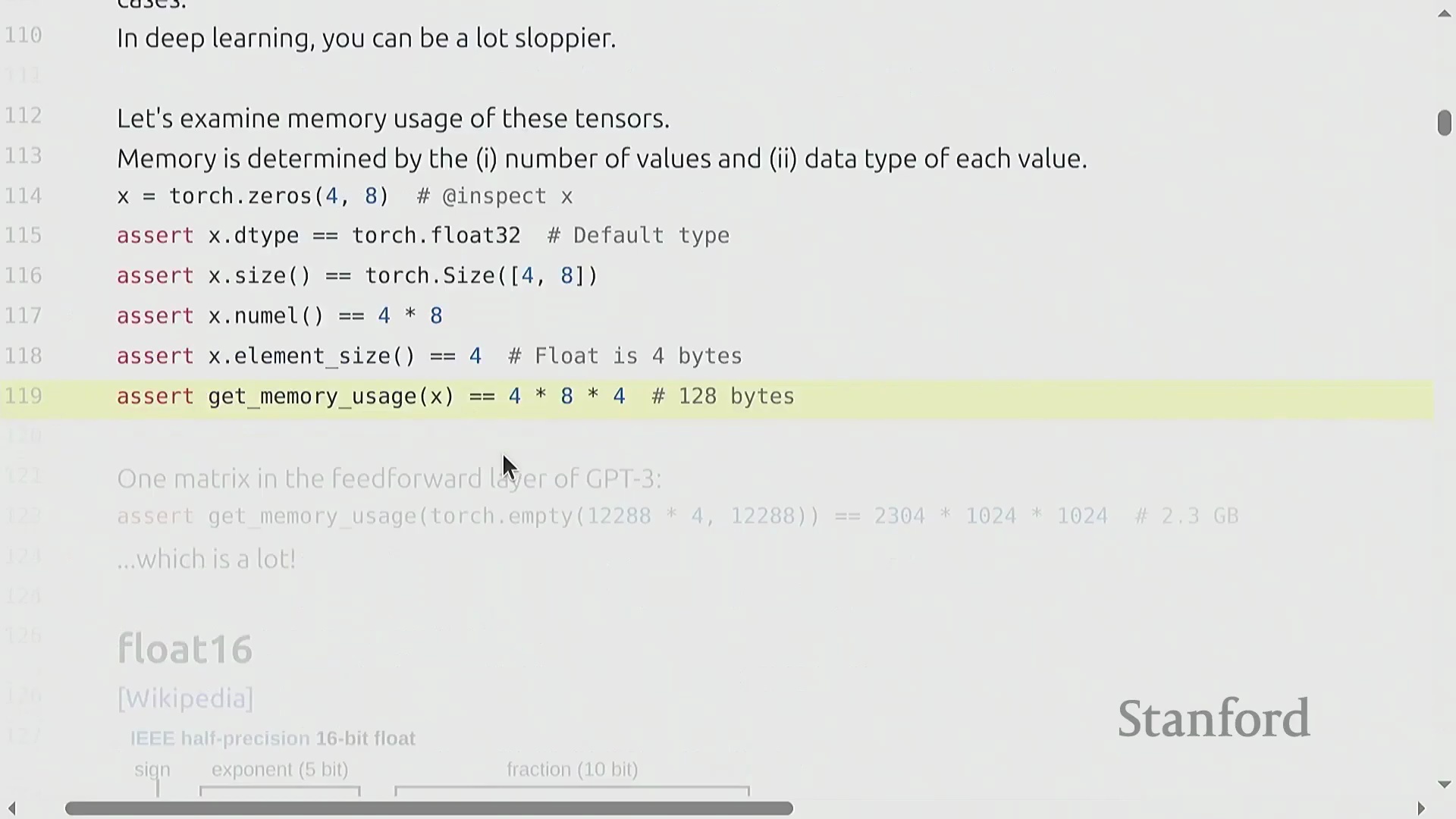
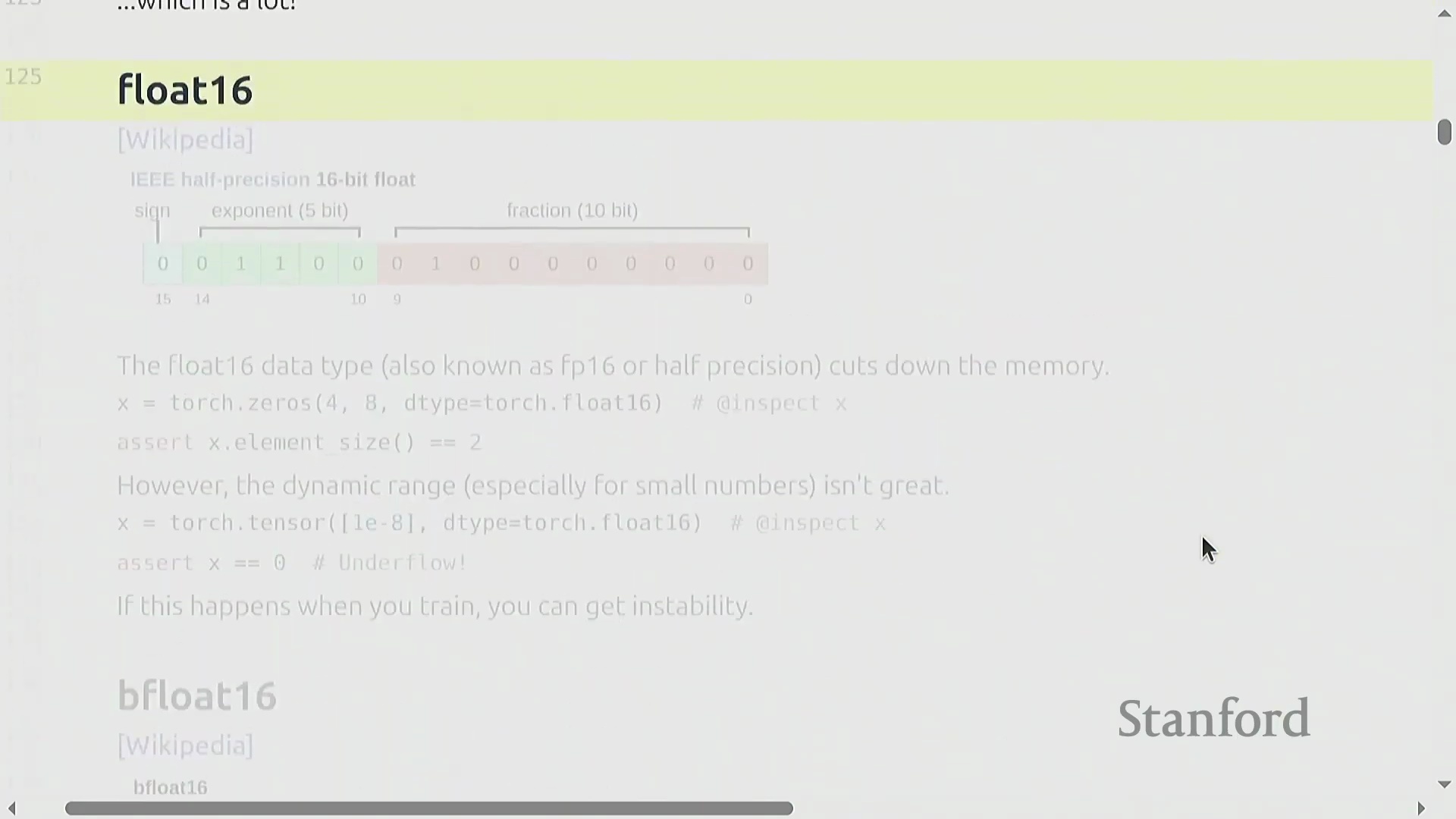
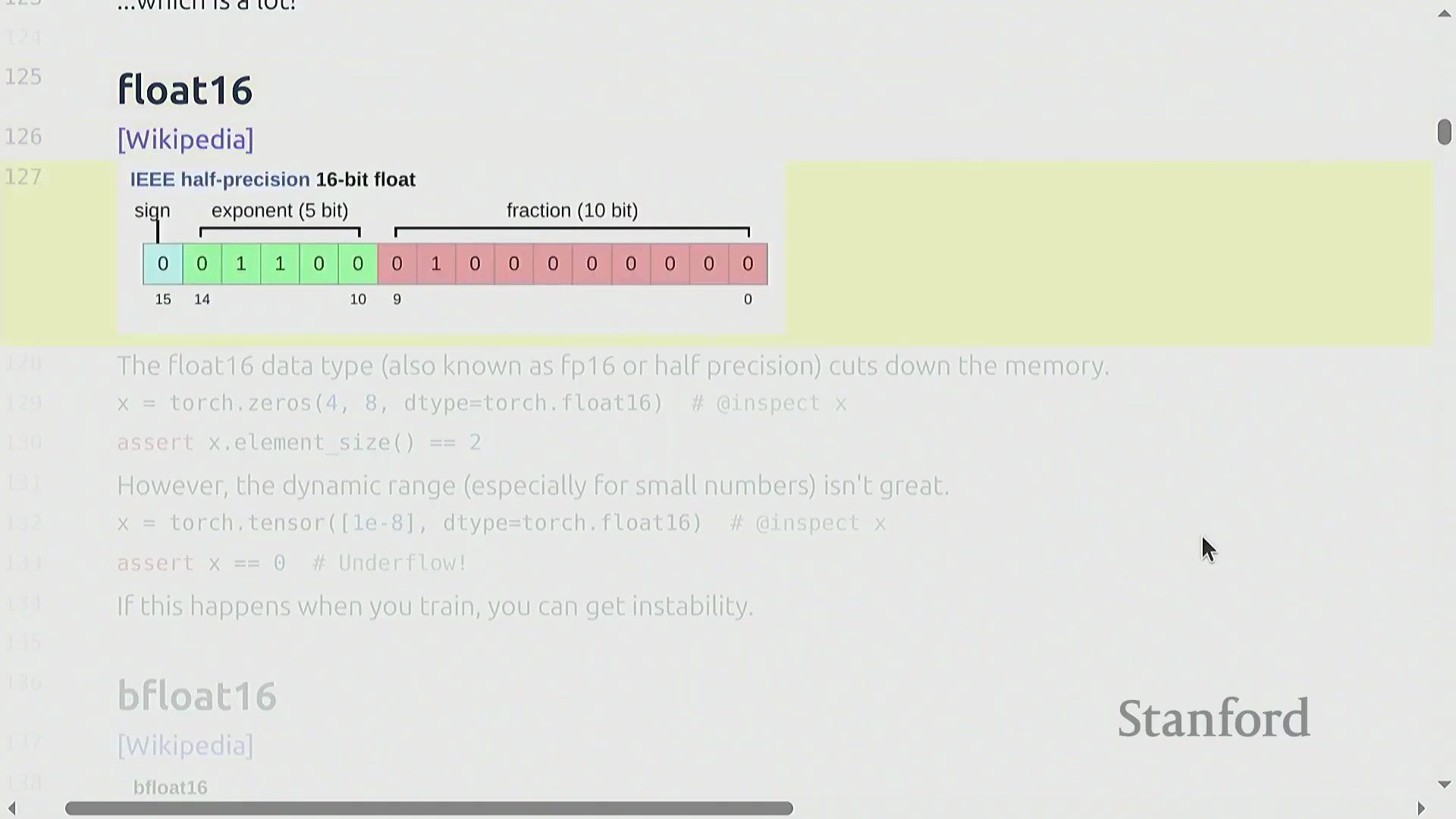
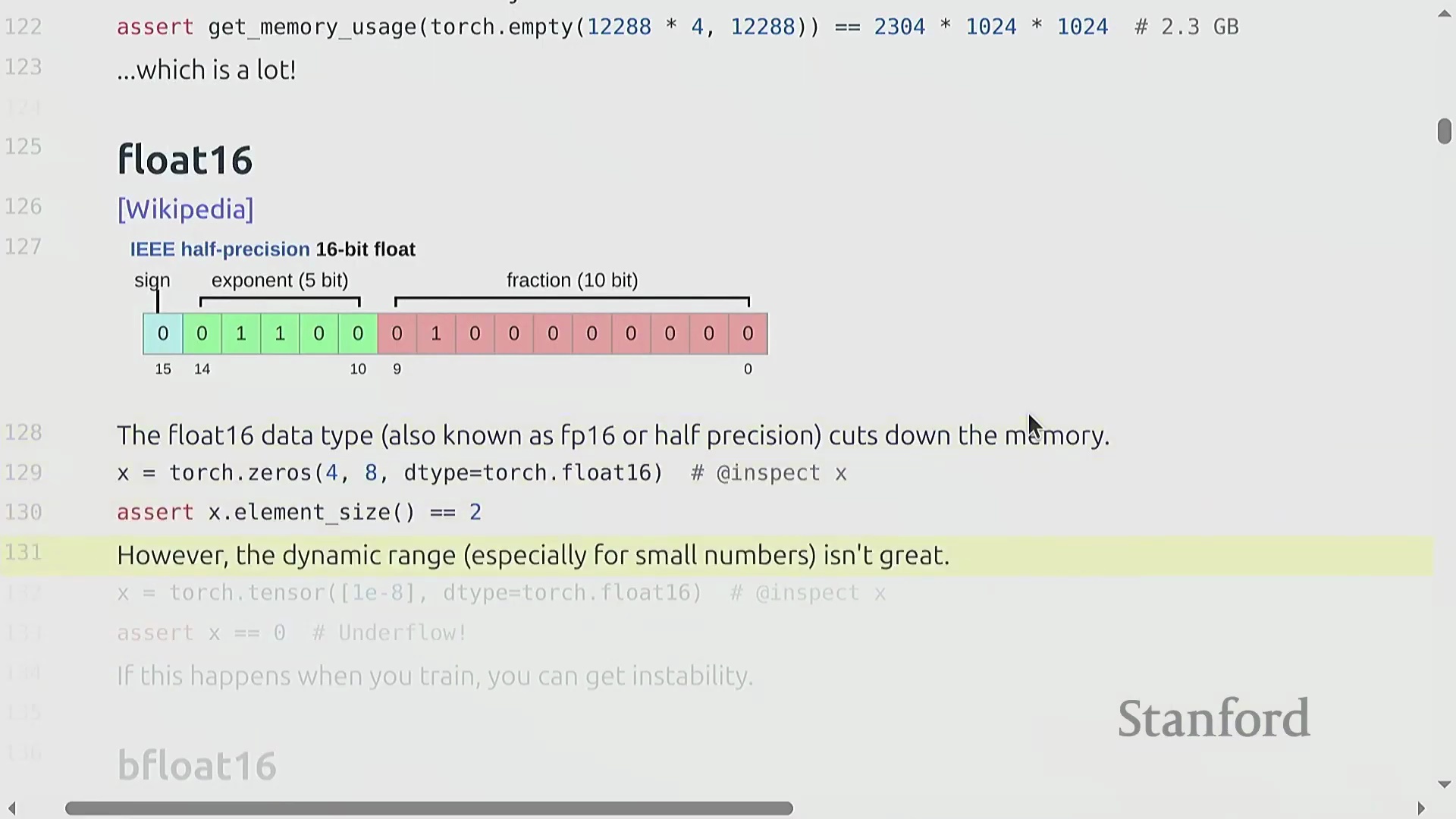
Float16 精度与动态范围的权衡
为降低内存消耗并加速计算,引入了半精度浮点数(Float16/Half Precision)。通过将格式压缩至 16 位(5 位指数,10 位尾数),它将内存需求减半。然而,这种压缩严重限制了动态范围(Dynamic Range)。极小的数值(如 1e-8)可能会向下舍入为零,导致下溢(Underflow),而较大的数值则面临上溢(Overflow)的风险。这些数值不稳定性使得直接采用 Float16 进行训练不适用于大规模模型,从而为更先进的混合精度训练(Mixed Precision Training)或其他浮点表示法铺平了道路。

BF16 与动态范围优先
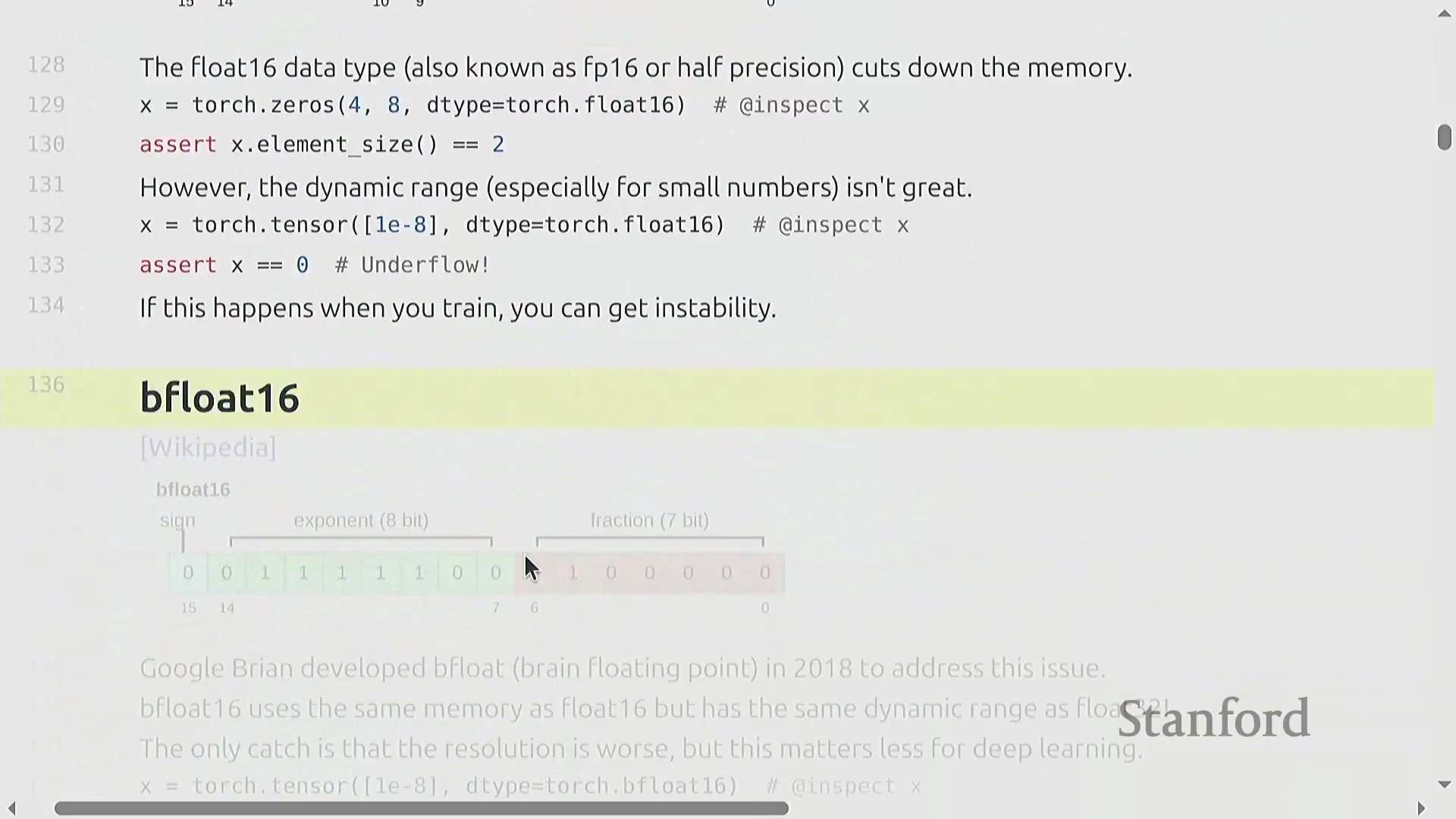
鉴于标准 float16 由于指数位受限而容易受到下溢(underflow)和上溢(overflow)的影响,本讲引入了 BFloat16(Brain Floating Point)。BF16 于 2018 年推出,它保持了与 float16 相同的 16 位内存占用,但将部分尾数位(mantissa)的比特重新分配给了指数位(exponent)。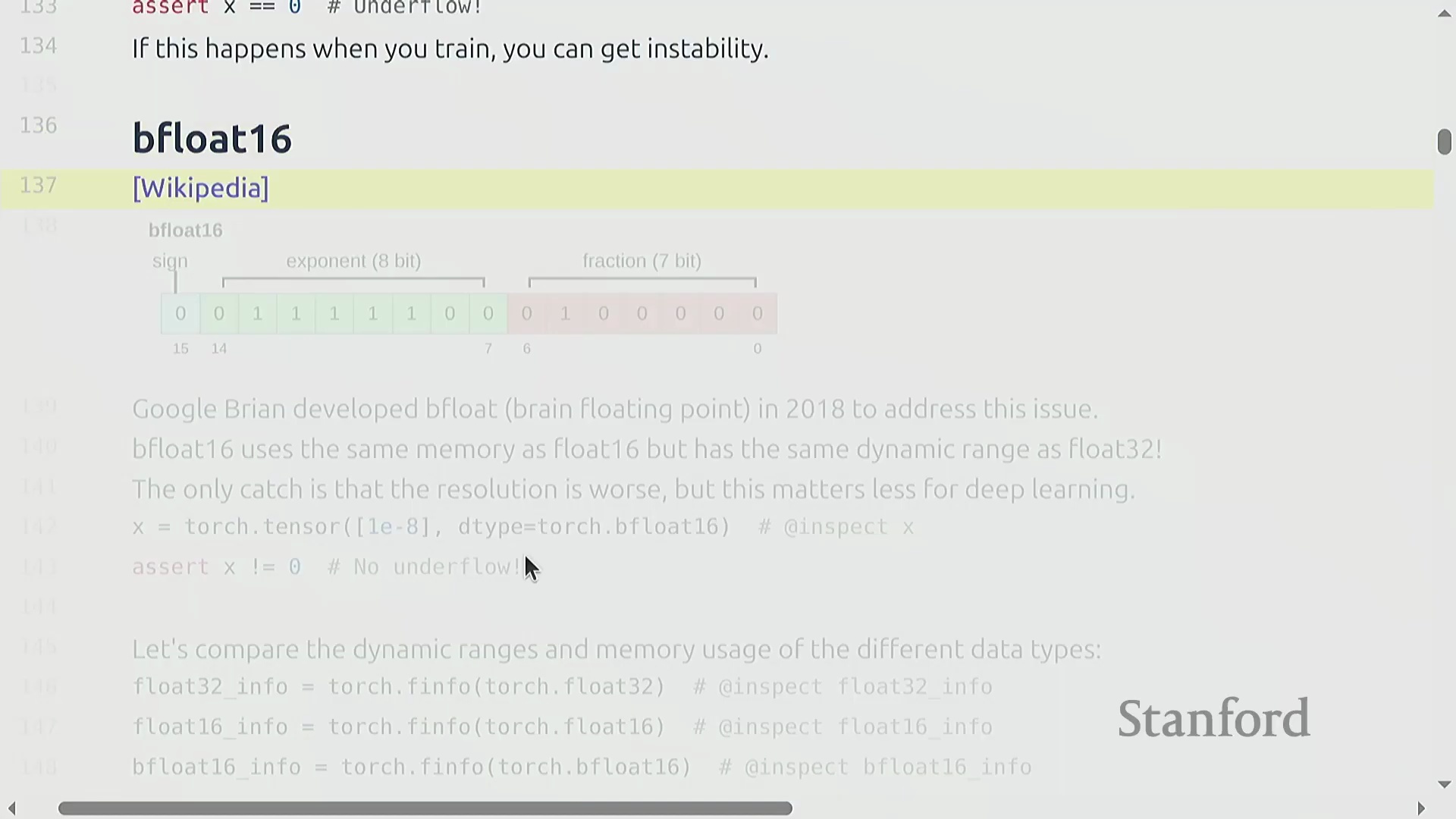
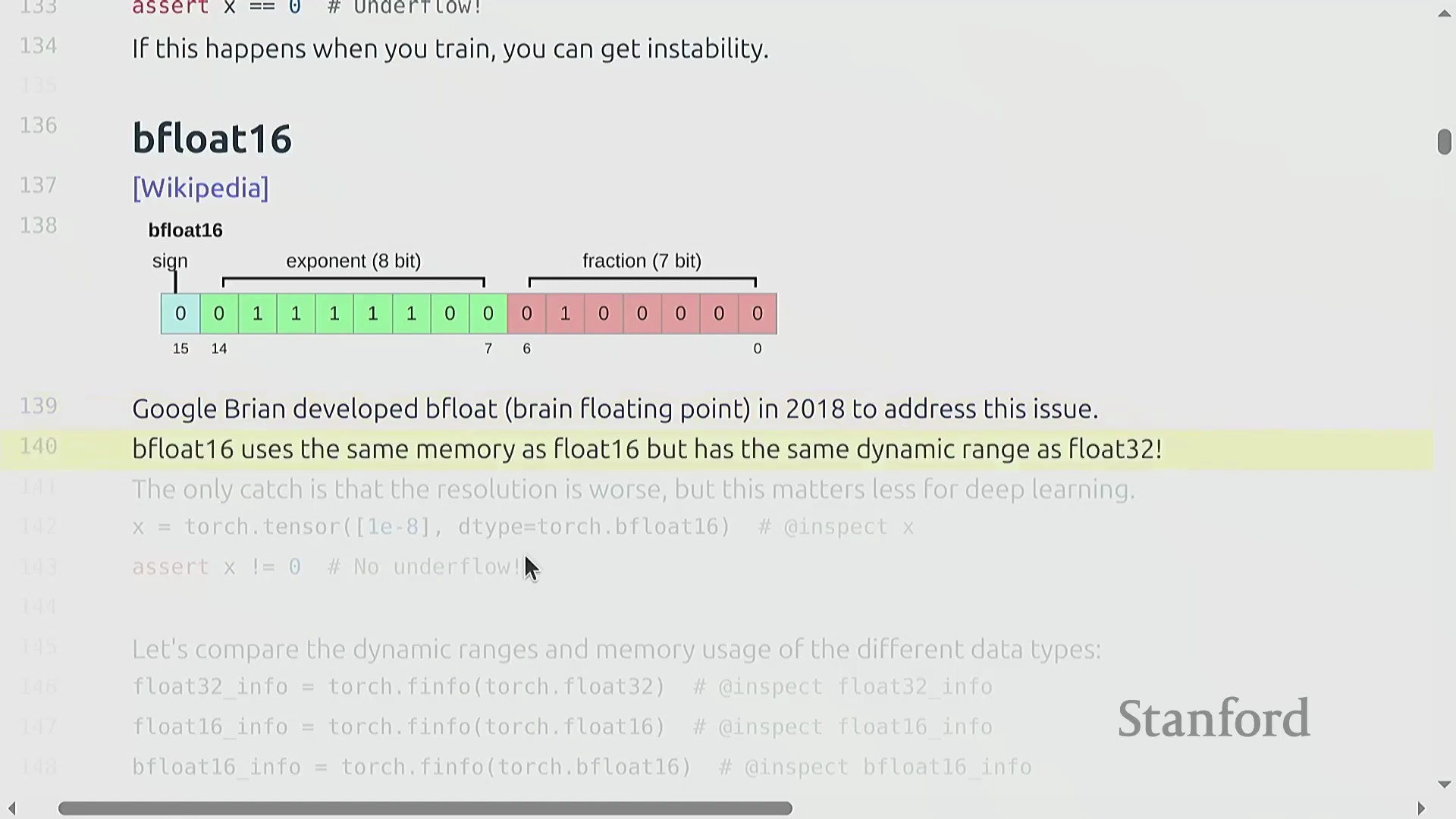 这种设计优先考虑动态范围而非绝对精度,非常契合深度学习模型对梯度噪声的容忍特性,同时也满足了稳定表示极大或极小数值的需求。尽管 BF16 牺牲了一定的精度,但这种权衡(trade-off)在神经网络训练中通常是可以接受的。例如,尝试在 BF16 中表示
这种设计优先考虑动态范围而非绝对精度,非常契合深度学习模型对梯度噪声的容忍特性,同时也满足了稳定表示极大或极小数值的需求。尽管 BF16 牺牲了一定的精度,但这种权衡(trade-off)在神经网络训练中通常是可以接受的。例如,尝试在 BF16 中表示 1e-8 时,它可以成功保留一个非零值,从而避免了 float16 中常见的灾难性下溢(catastrophic underflow)。
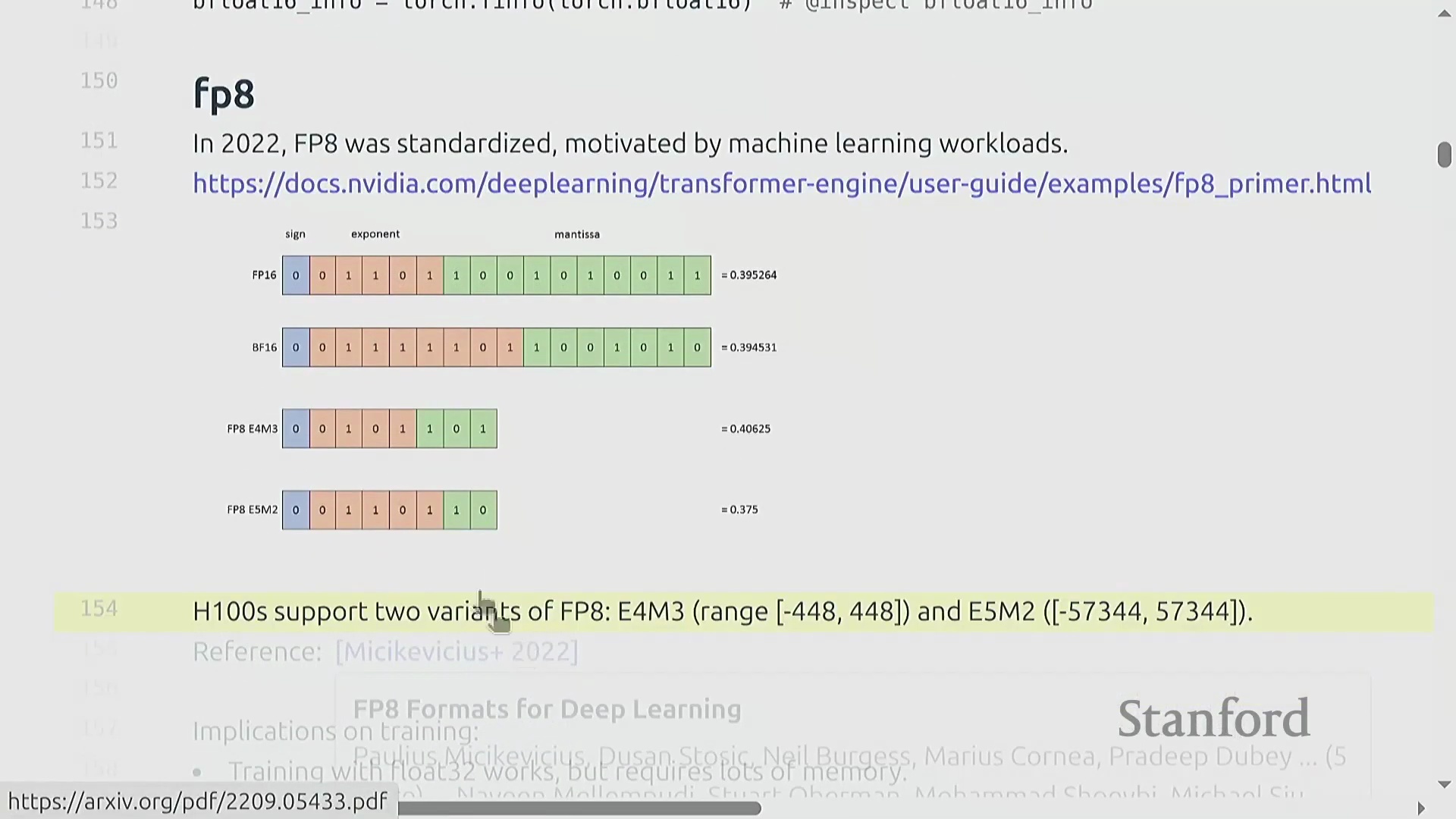
FP8 的采用与混合精度策略
低精度格式(Low-Precision Formats)的演进继续推进至 FP8,这是 NVIDIA 于 2022 年推出的 8 位浮点标准,并得到 H100 GPU 的硬件支持。由于可用比特位极其有限,FP8 提供了两种变体格式,分别针对精度或动态范围进行优化,但其数值表示能力仍相对粗糙。


 在实际应用中,训练策略已转向混合精度训练(Mixed Precision Training):使用
在实际应用中,训练策略已转向混合精度训练(Mixed Precision Training):使用 float32 存储主权重(Master Weights)和优化器状态(Optimizer States),以防止训练过程发散;同时利用 BF16(或 FP8)执行临时的前向传播(Forward Pass)和反向传播(Backward Pass)计算,因为在这些阶段,计算速度与内存节约至关重要。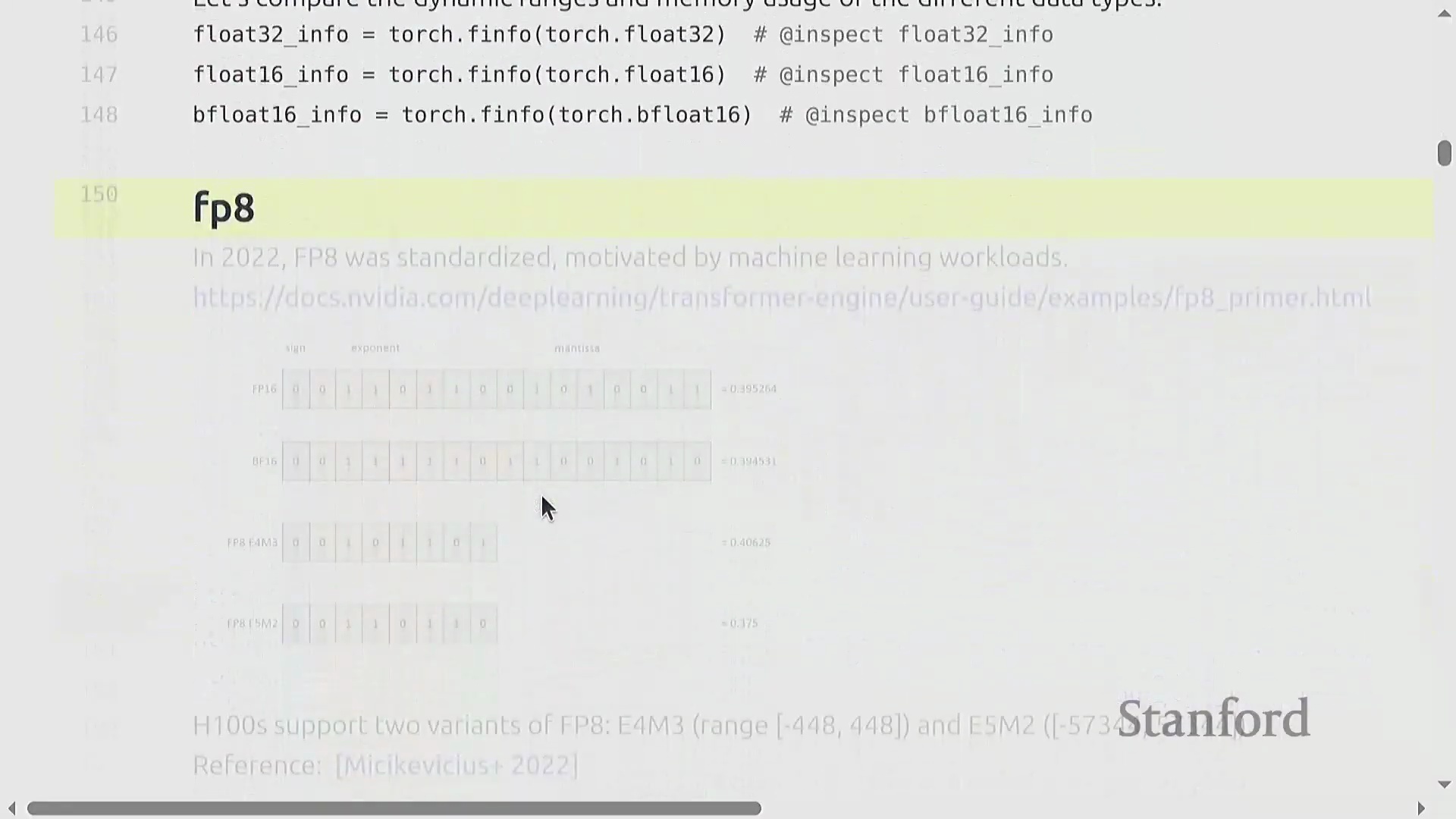

 更复杂的计算流水线甚至可以对特定模块应用不同的精度策略;例如,将注意力机制(Attention Mechanism)保持在
更复杂的计算流水线甚至可以对特定模块应用不同的精度策略;例如,将注意力机制(Attention Mechanism)保持在 float32 以维持数值稳定性,同时以 BF16 运行前馈网络层(Feed-Forward Network Layers)。
 讲座在问答环节进一步强调,模型参数应始终以
讲座在问答环节进一步强调,模型参数应始终以 float32(即主权重)驻留内存,而 BF16 仅作为执行计算密集型操作时的临时工作精度。


设备放置与 CPU-GPU 数据传输
本讲重点从内存精度转向计算设备放置(Device Placement)。默认情况下,PyTorch 张量驻留在 CPU 内存(RAM)中。尽管可以正常运行,但相比于 GPU 执行,其处理深度学习工作负载的速度要慢几个数量级。
 为充分利用硬件加速(Hardware Acceleration),必须通过
为充分利用硬件加速(Hardware Acceleration),必须通过 .to(device) 等方法将张量显式迁移至 GPU,此过程会在 PCIe 或 NVLink 总线上产生一次性数据传输开销(Data Transfer Overhead)。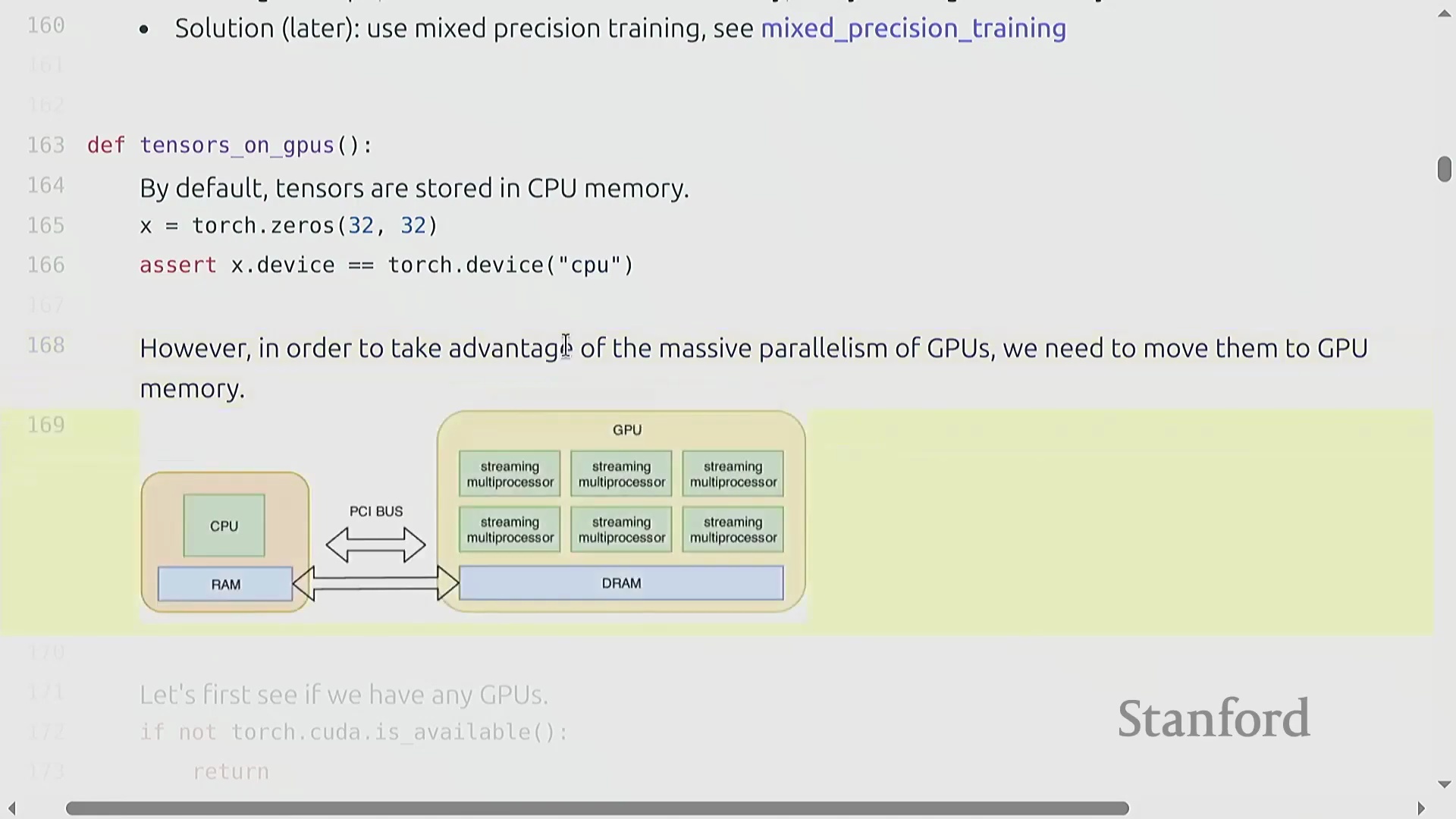 理解底层硬件架构至关重要;例如,H100 GPU 配备了 80GB 的高带宽内存(HBM)以及特定的缓存层级结构(Cache Hierarchy)。
理解底层硬件架构至关重要;例如,H100 GPU 配备了 80GB 的高带宽内存(HBM)以及特定的缓存层级结构(Cache Hierarchy)。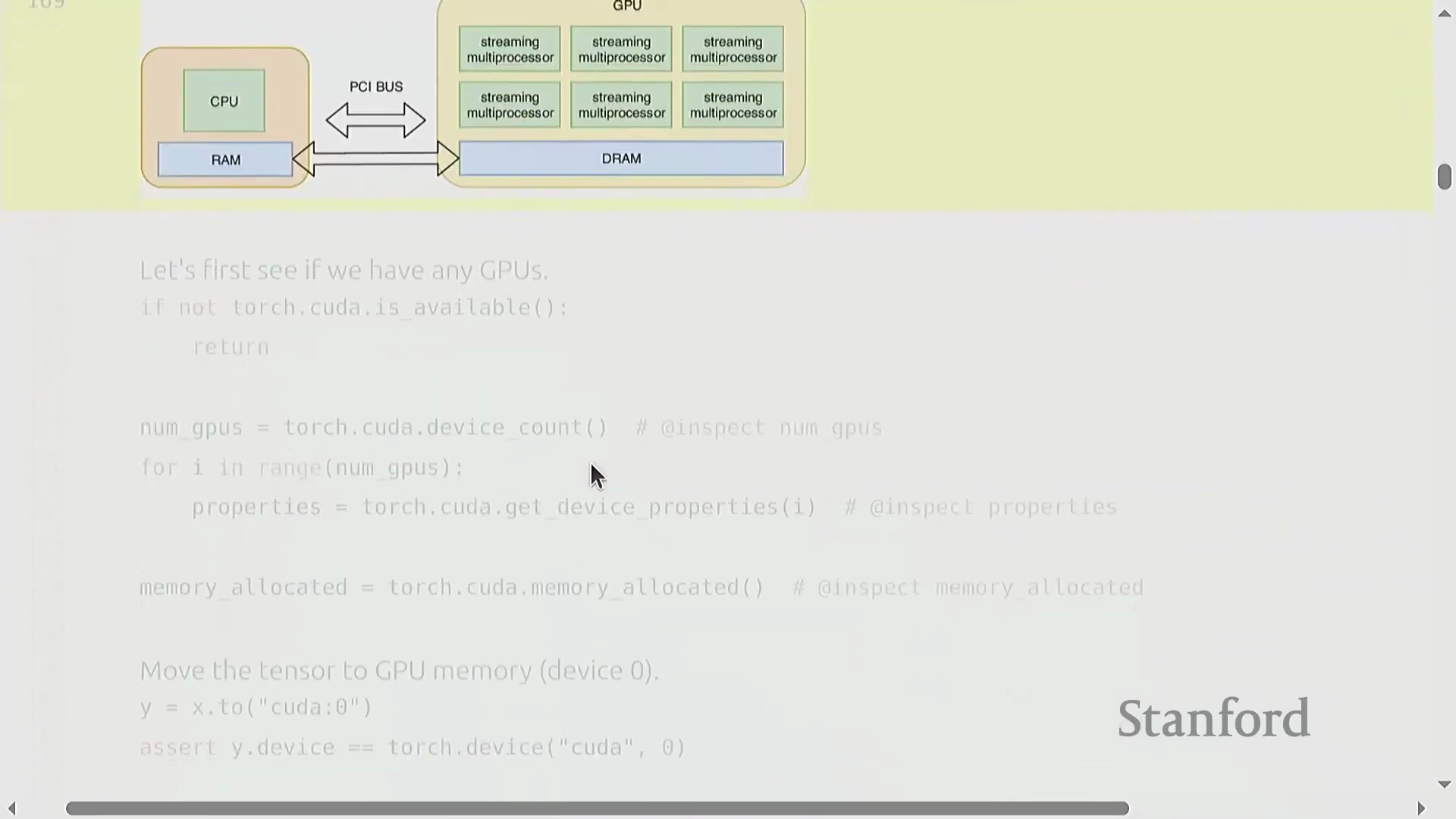
 开发者必须时刻追踪张量所在的物理设备,因为代码中的变量名本身无法反映数据实际存储于 CPU 还是 GPU。
开发者必须时刻追踪张量所在的物理设备,因为代码中的变量名本身无法反映数据实际存储于 CPU 还是 GPU。
 使用断言(Assertions)验证张量所在的设备,可有效避免隐性的性能瓶颈或运行时错误。
使用断言(Assertions)验证张量所在的设备,可有效避免隐性的性能瓶颈或运行时错误。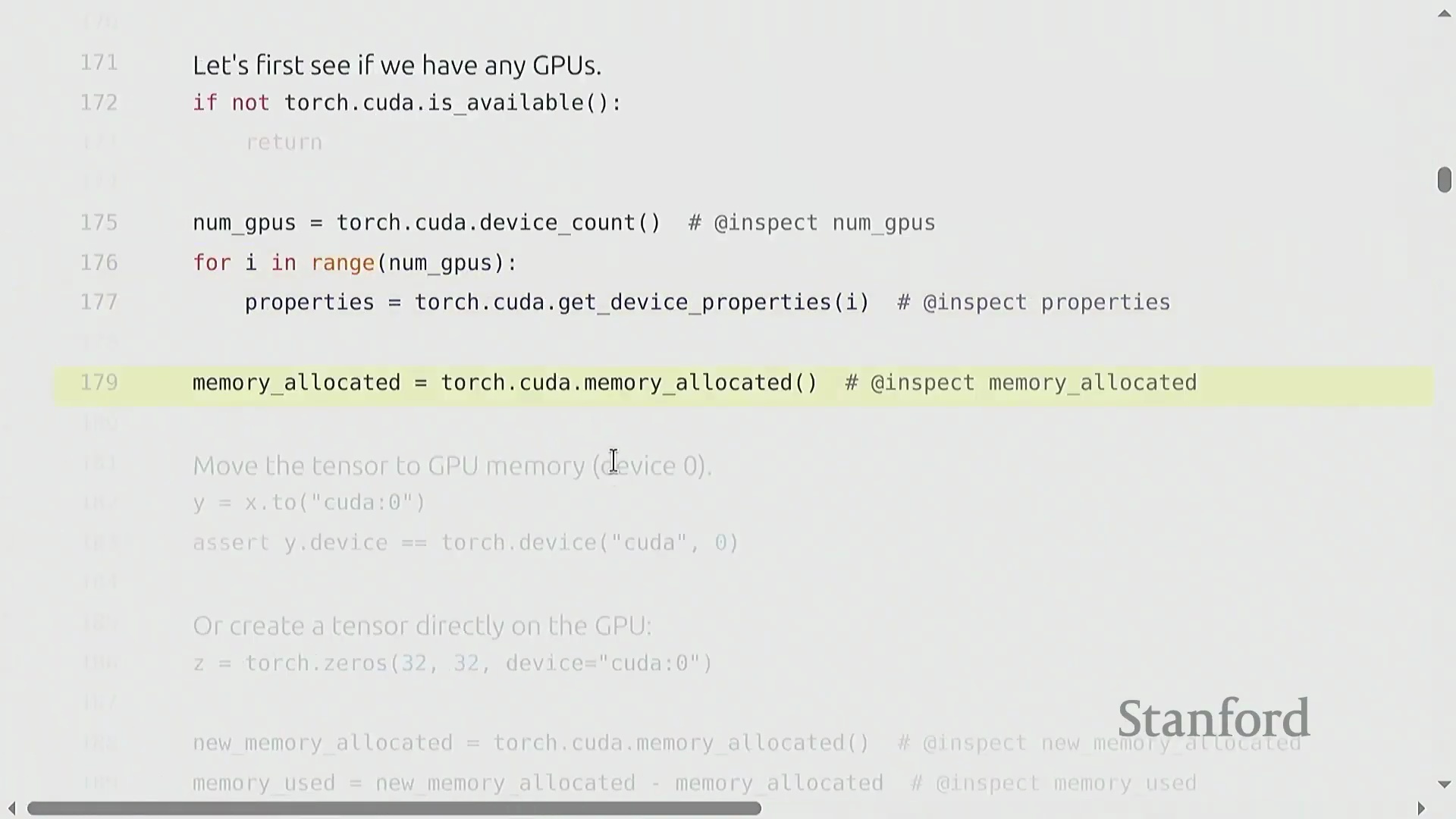
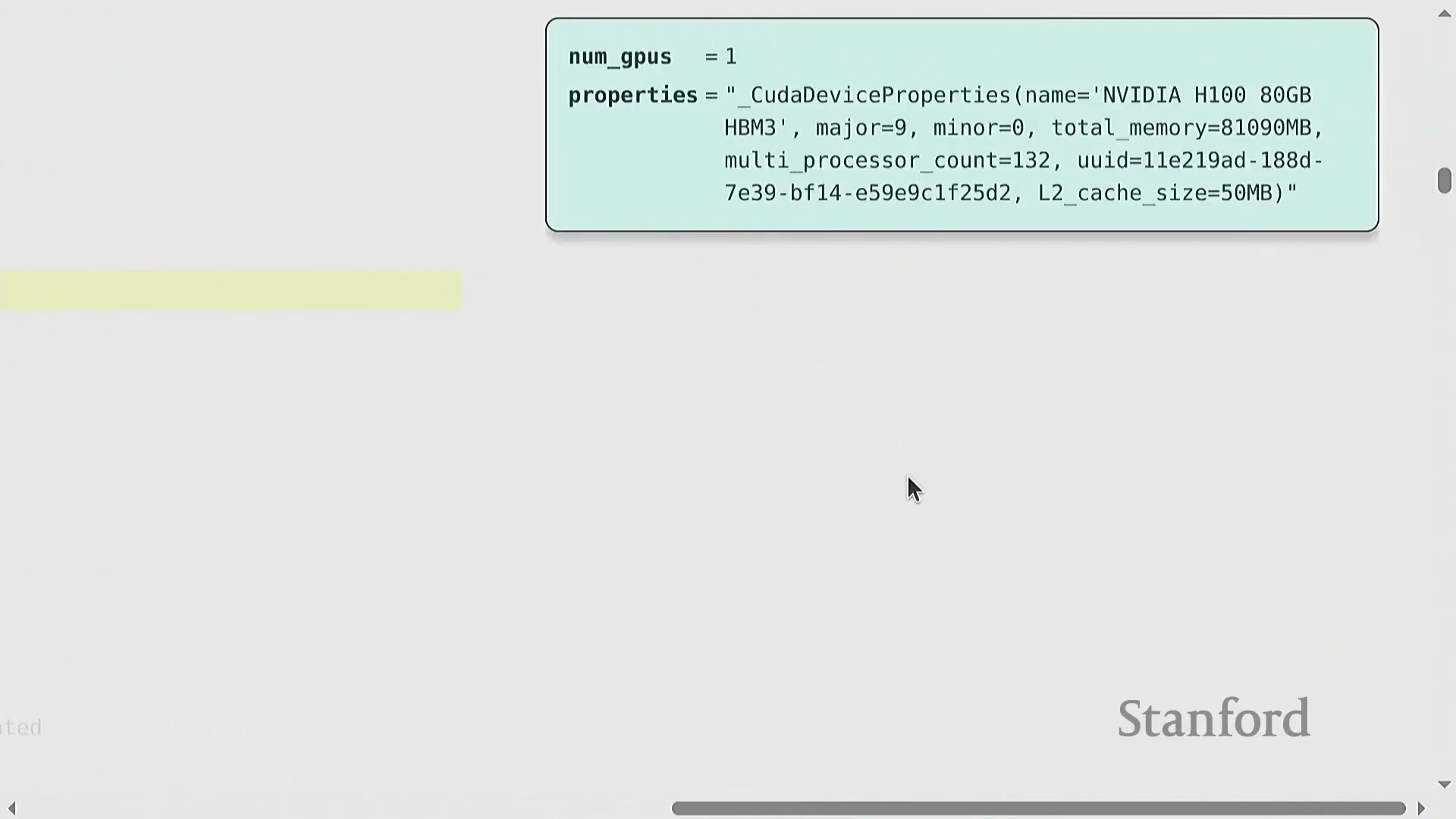
验证 GPU 内存分配
将张量成功放置在 GPU 上后,验证实际显存(GPU Memory)消耗至关重要。PyTorch 提供了监控 max_memory_allocated(最大已分配内存)的工具,使开发者能够验证资源消耗是否符合预期。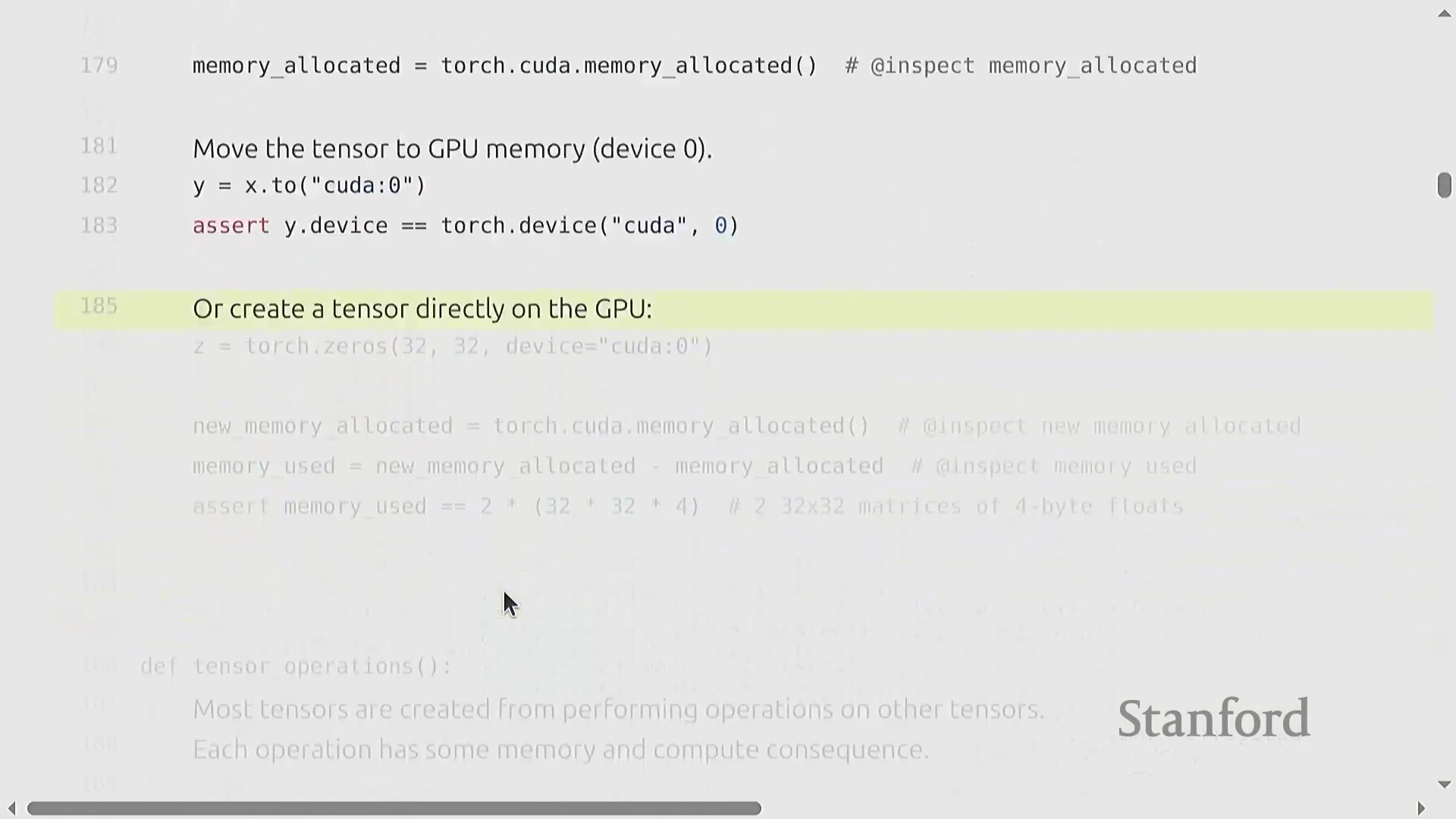 例如,直接在 GPU 上创建两个元素为 4 字节浮点数(float32) 的
例如,直接在 GPU 上创建两个元素为 4 字节浮点数(float32) 的 32x32 矩阵,应导致显存精确增加 192 字节。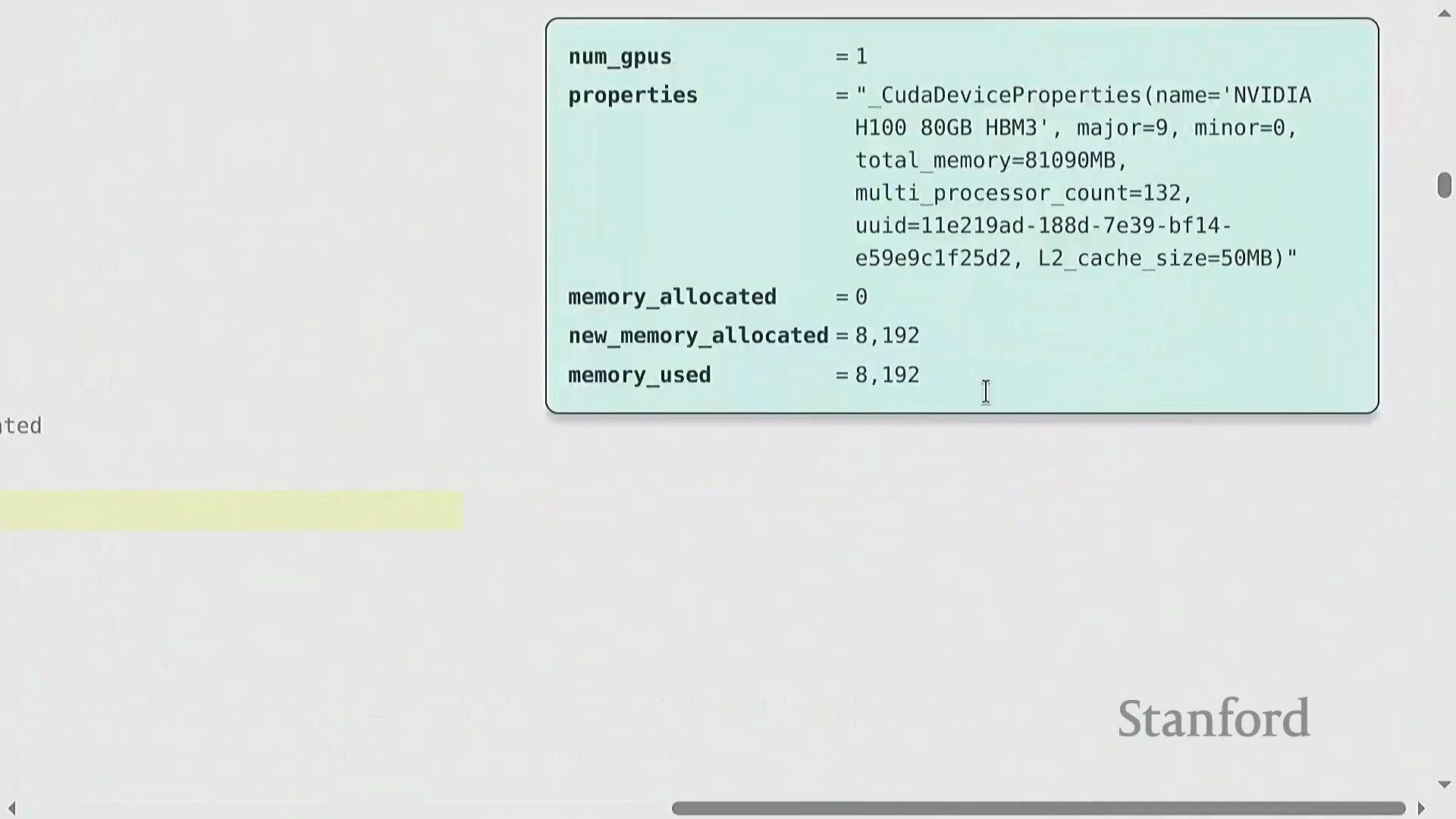
 该验证步骤确保了代码行为与预期一致,并为评估后续操作的内存开销建立了基准。
该验证步骤确保了代码行为与预期一致,并为评估后续操作的内存开销建立了基准。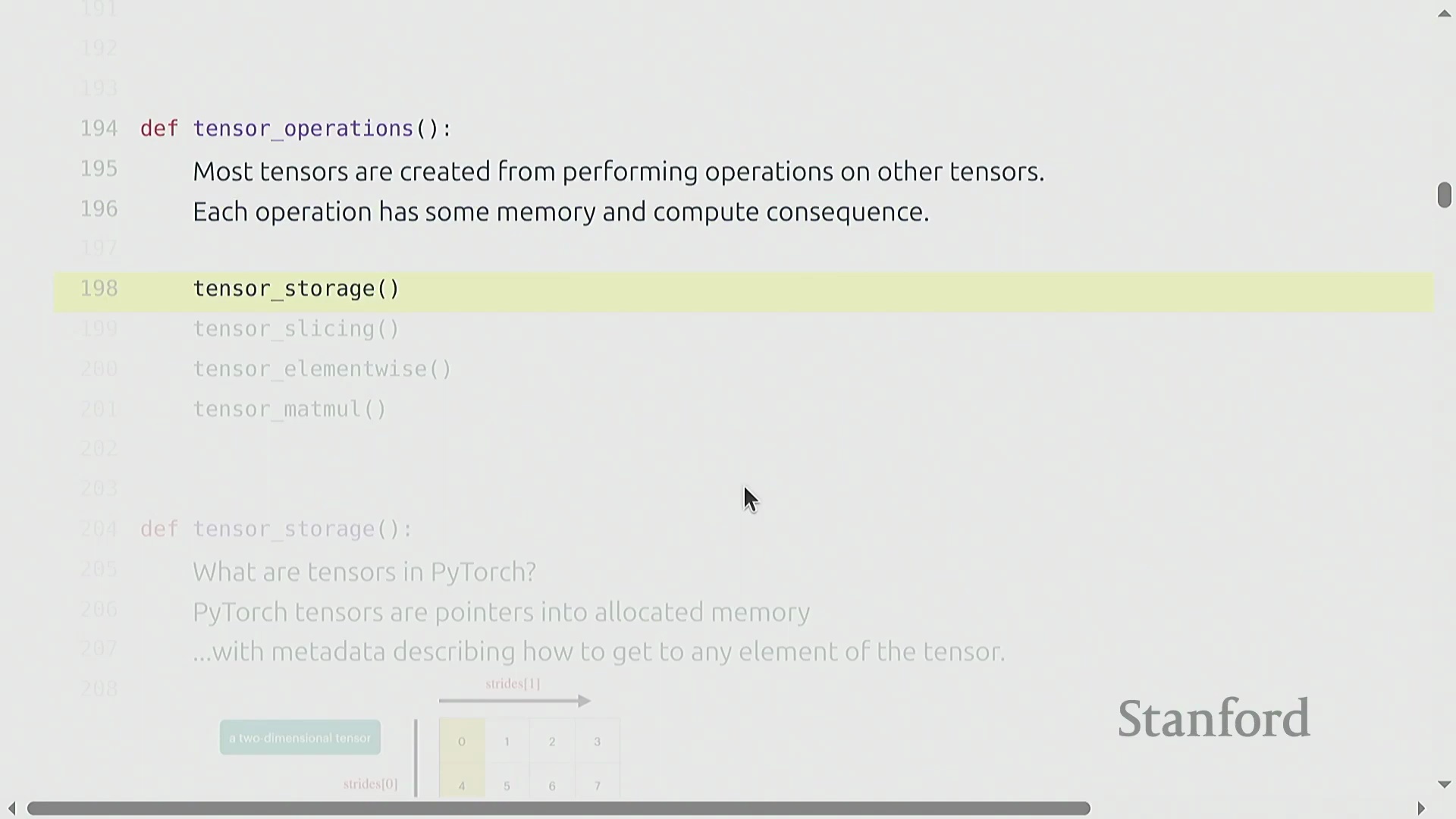
张量架构:内存布局与步幅
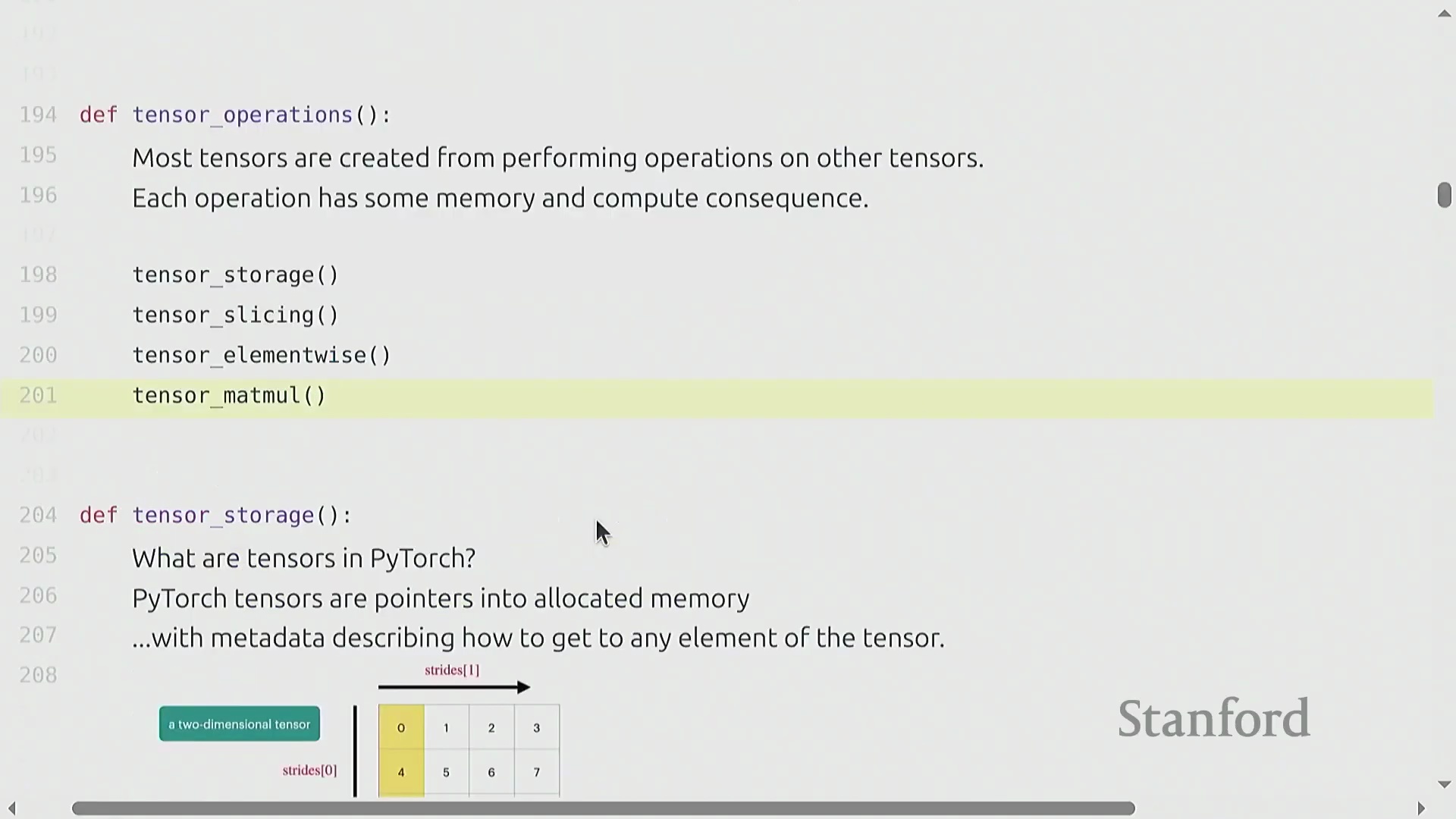
在底层,PyTorch 张量并非纯粹的数学抽象,而是指向已分配连续内存块的指针,并配有相应的元数据(Metadata)。
 多维矩阵(例如 4x4)在物理内存中会被展平(Flattened)为一维数组。张量的元数据包含步幅(Strides),它规定了在遍历每个维度时需要跳过多少个内存单元。
多维矩阵(例如 4x4)在物理内存中会被展平(Flattened)为一维数组。张量的元数据包含步幅(Strides),它规定了在遍历每个维度时需要跳过多少个内存单元。
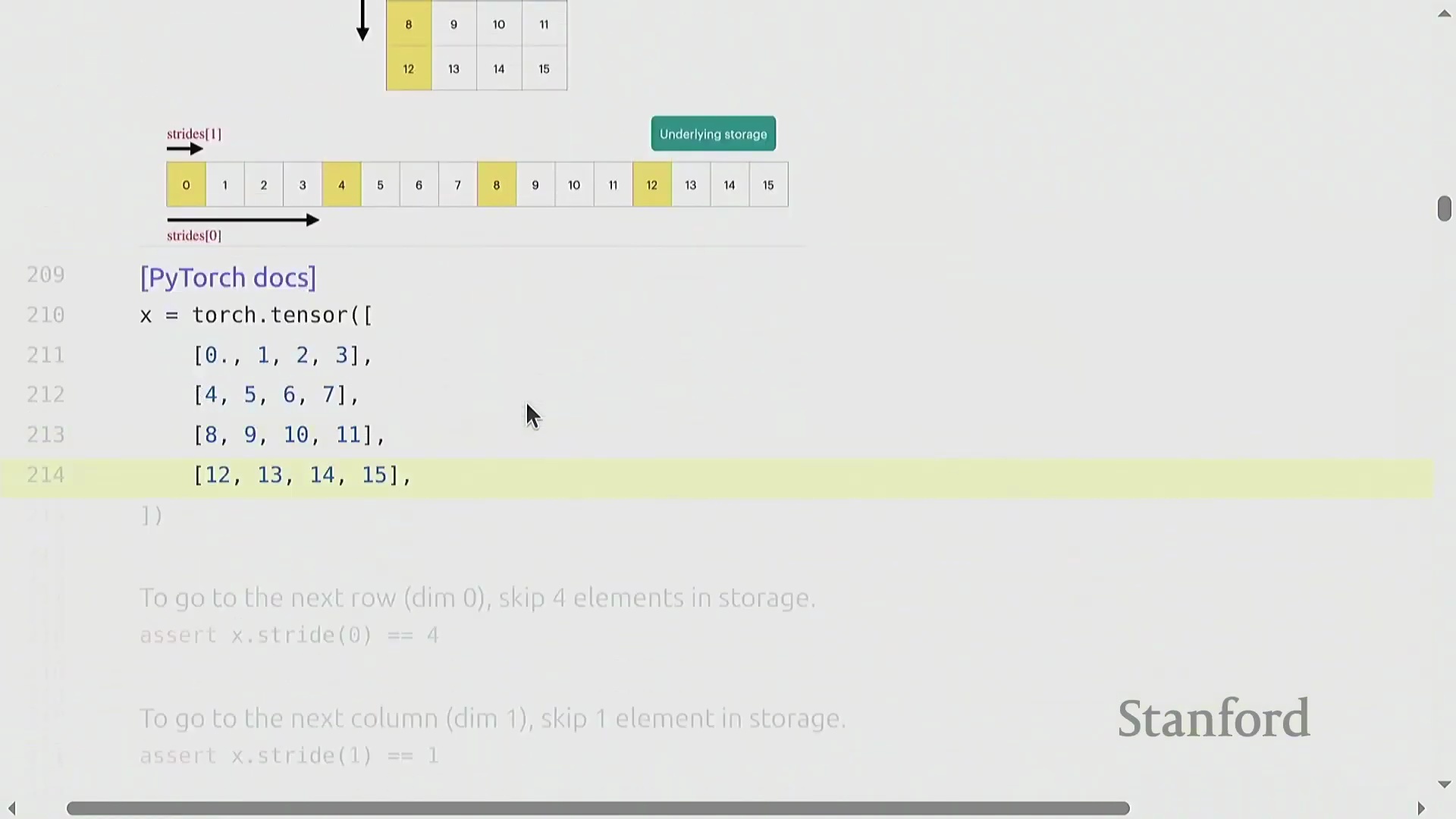
 以行优先(Row-Major)存储的 4x4 矩阵为例,
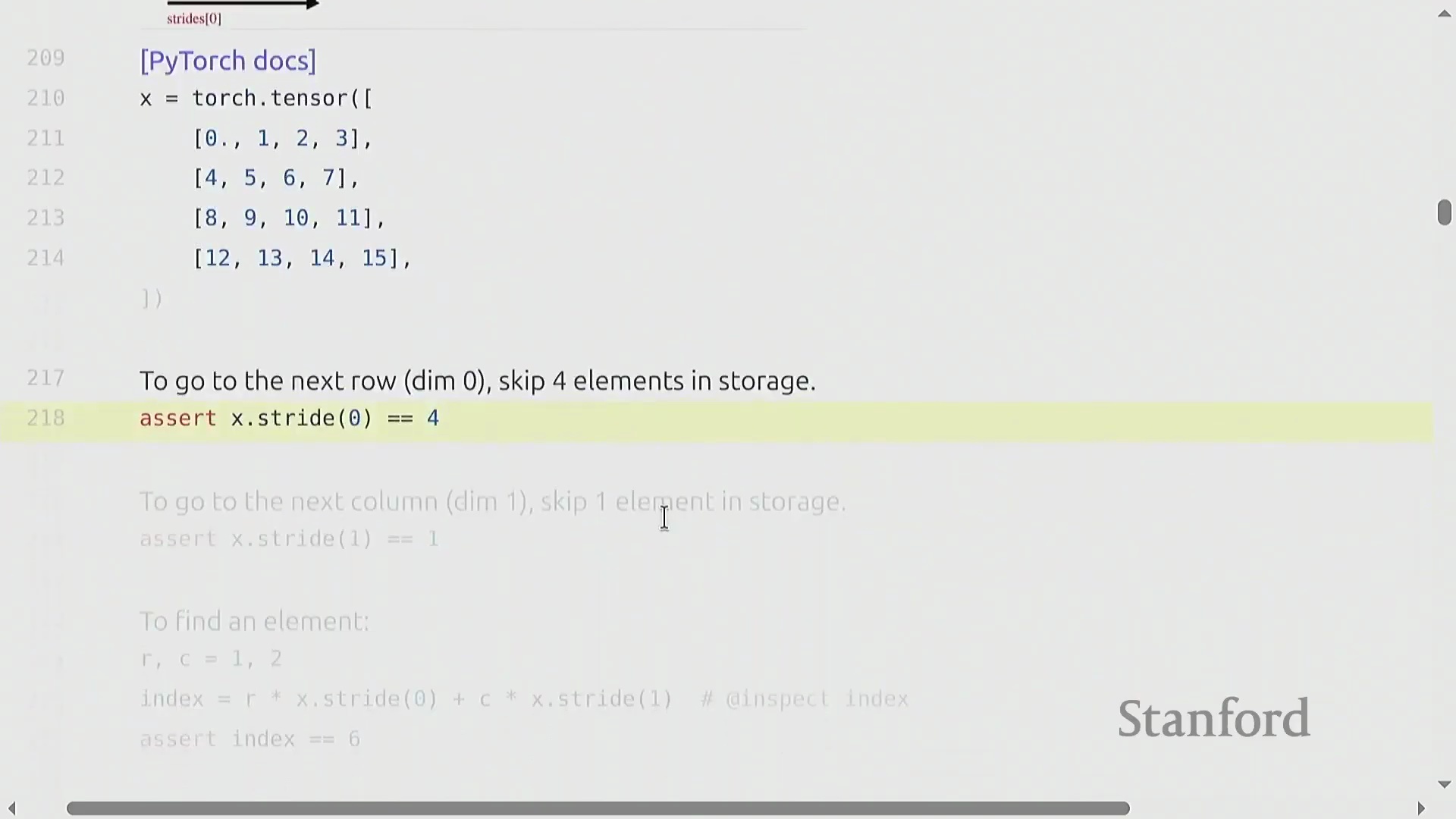
以行优先(Row-Major)存储的 4x4 矩阵为例,stride[0] 为 4(沿行向下移动需跨越 4 个元素),stride[1] 为 1(在同一行内移动仅需跨越 1 个元素)。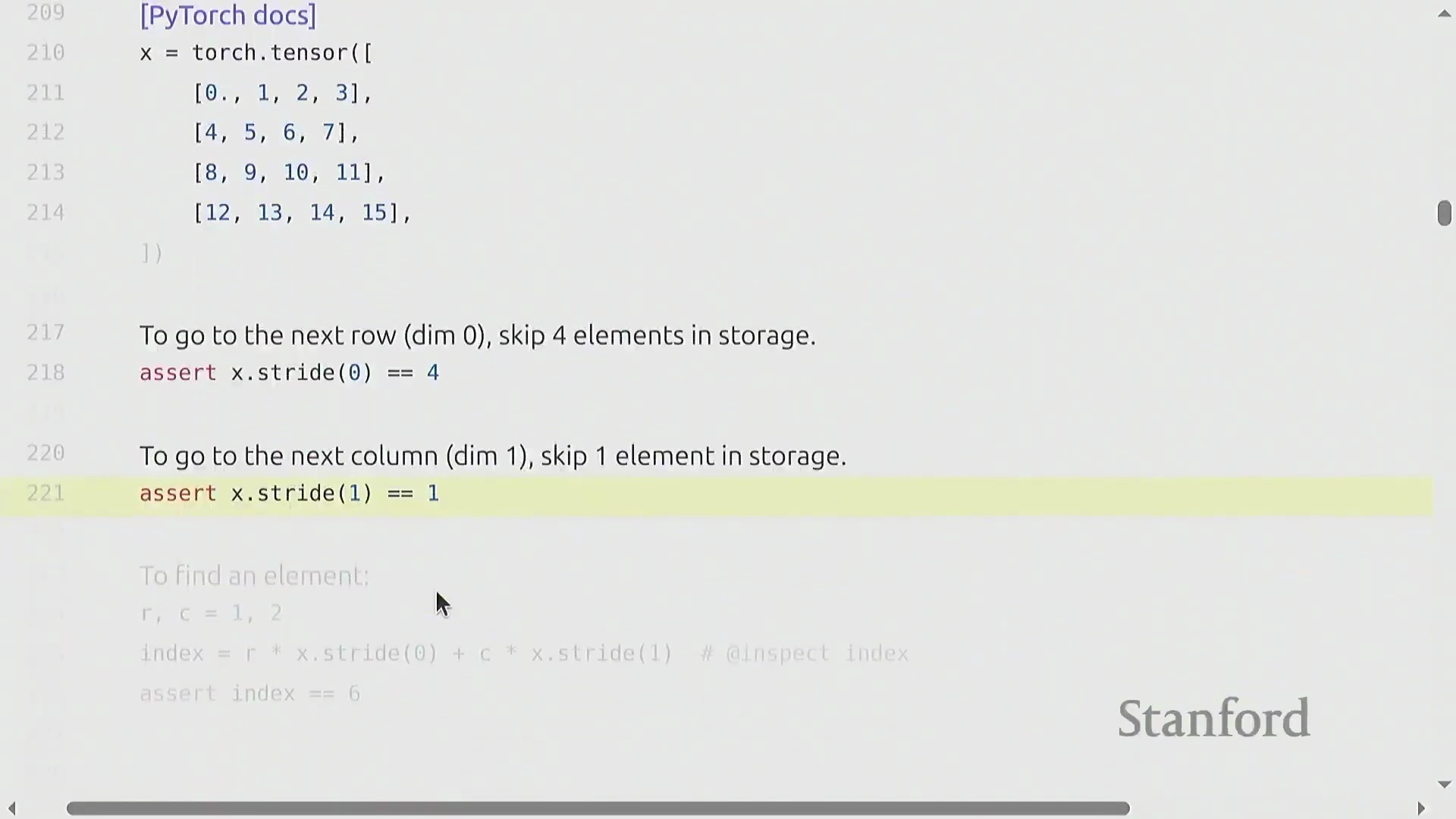 访问索引
访问索引 (i, j) 处的元素只需通过公式 i * stride[0] + j * stride[1] 计算偏移量。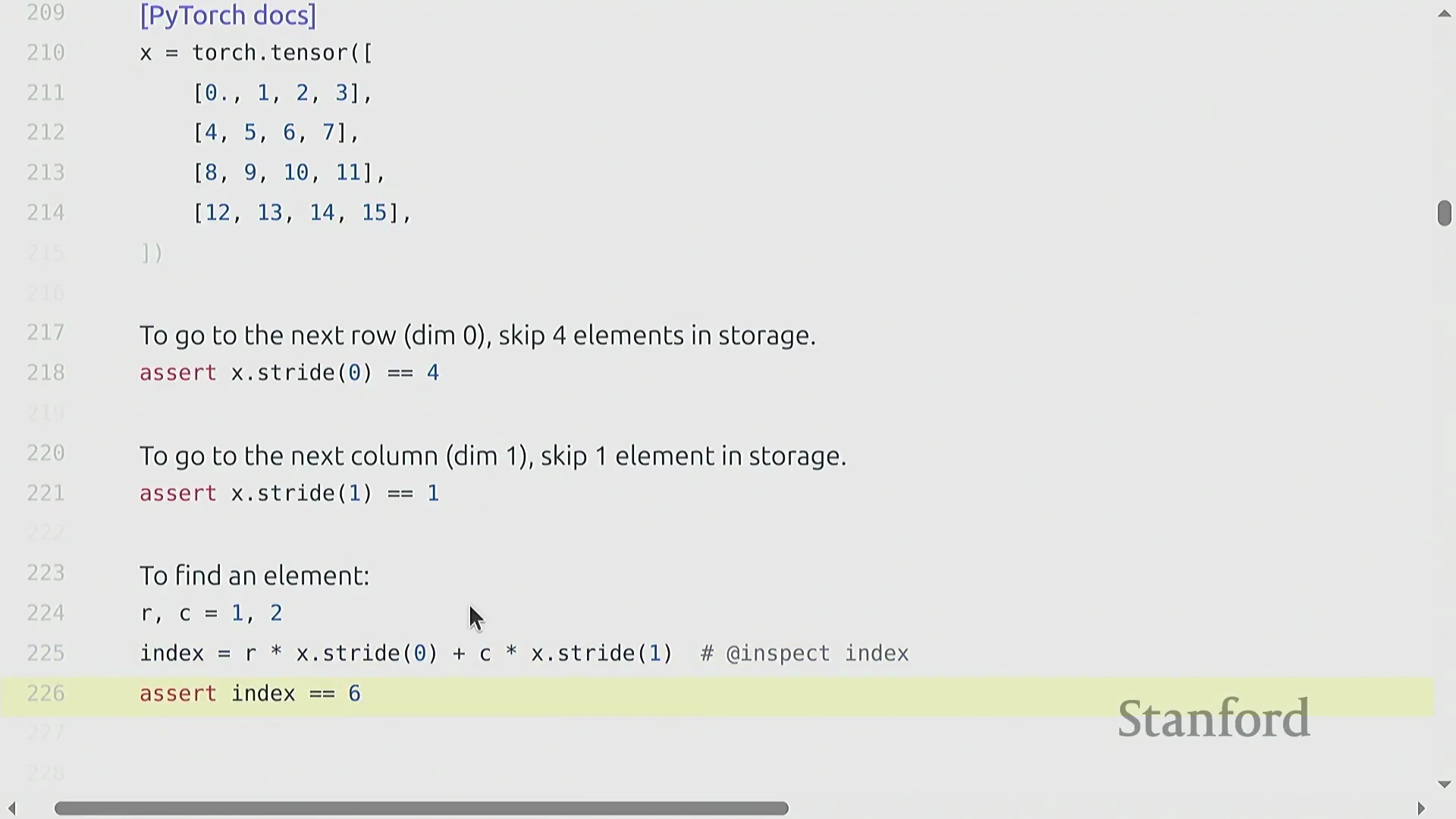
 深入理解此类内存布局,是优化数据访问模式及最小化缓存未命中(Cache Misses)的基础。
深入理解此类内存布局,是优化数据访问模式及最小化缓存未命中(Cache Misses)的基础。
张量视图与共享内存安全
由于张量依赖指针和步幅机制,许多 PyTorch 操作(如切片(Slicing)、索引(Indexing)或转置(Transposing))并不会触发新的内存分配(Memory Allocation)。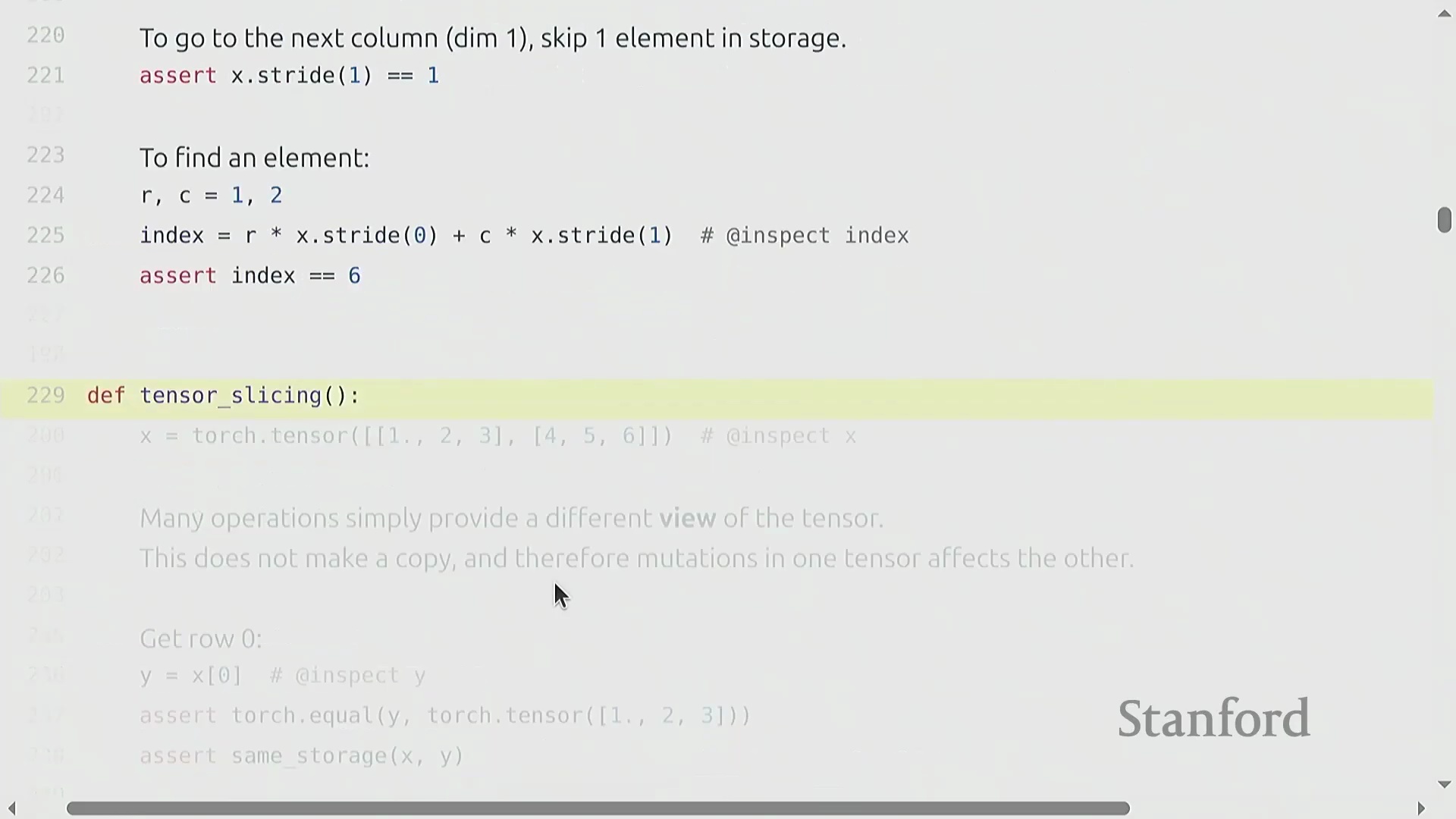
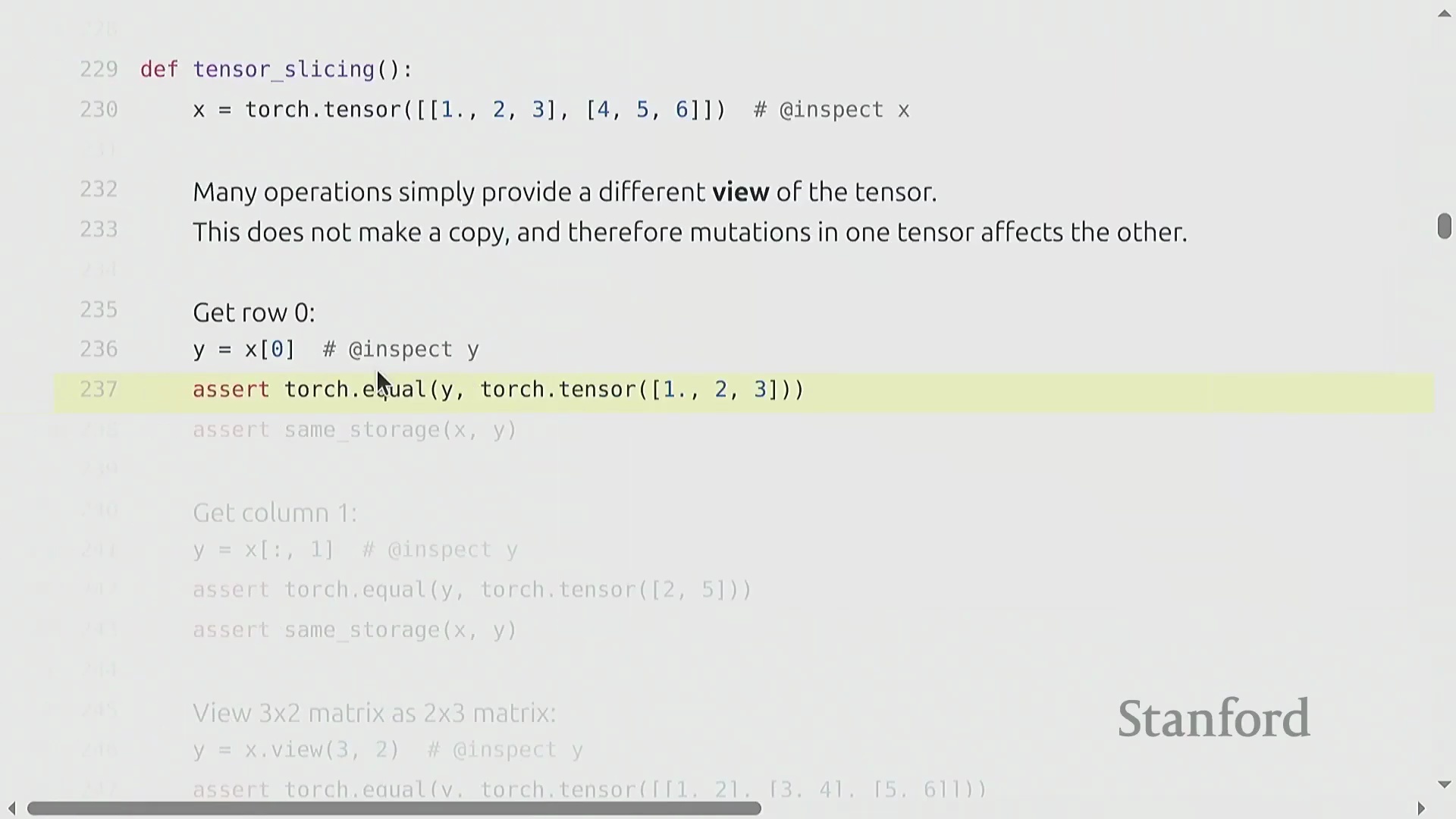
 相反,它们会生成视图(Views):新的张量对象与原始张量共享底层数据存储(Underlying Storage),仅拥有独立的元数据(如形状(Shape)和步幅)。
相反,它们会生成视图(Views):新的张量对象与原始张量共享底层数据存储(Underlying Storage),仅拥有独立的元数据(如形状(Shape)和步幅)。 该设计避免了高昂的数据复制(Data Copying)开销,但也引入了一个关键注意事项:原地修改(In-place Operations)。若对视图进行修改,变更将直接反映在原始张量及其他所有共享该存储的视图上。
该设计避免了高昂的数据复制(Data Copying)开销,但也引入了一个关键注意事项:原地修改(In-place Operations)。若对视图进行修改,变更将直接反映在原始张量及其他所有共享该存储的视图上。 开发者必须高度重视共享存储机制,以避免在训练过程中引发意外的副作用或梯度损坏(Gradient Corruption)。
开发者必须高度重视共享存储机制,以避免在训练过程中引发意外的副作用或梯度损坏(Gradient Corruption)。
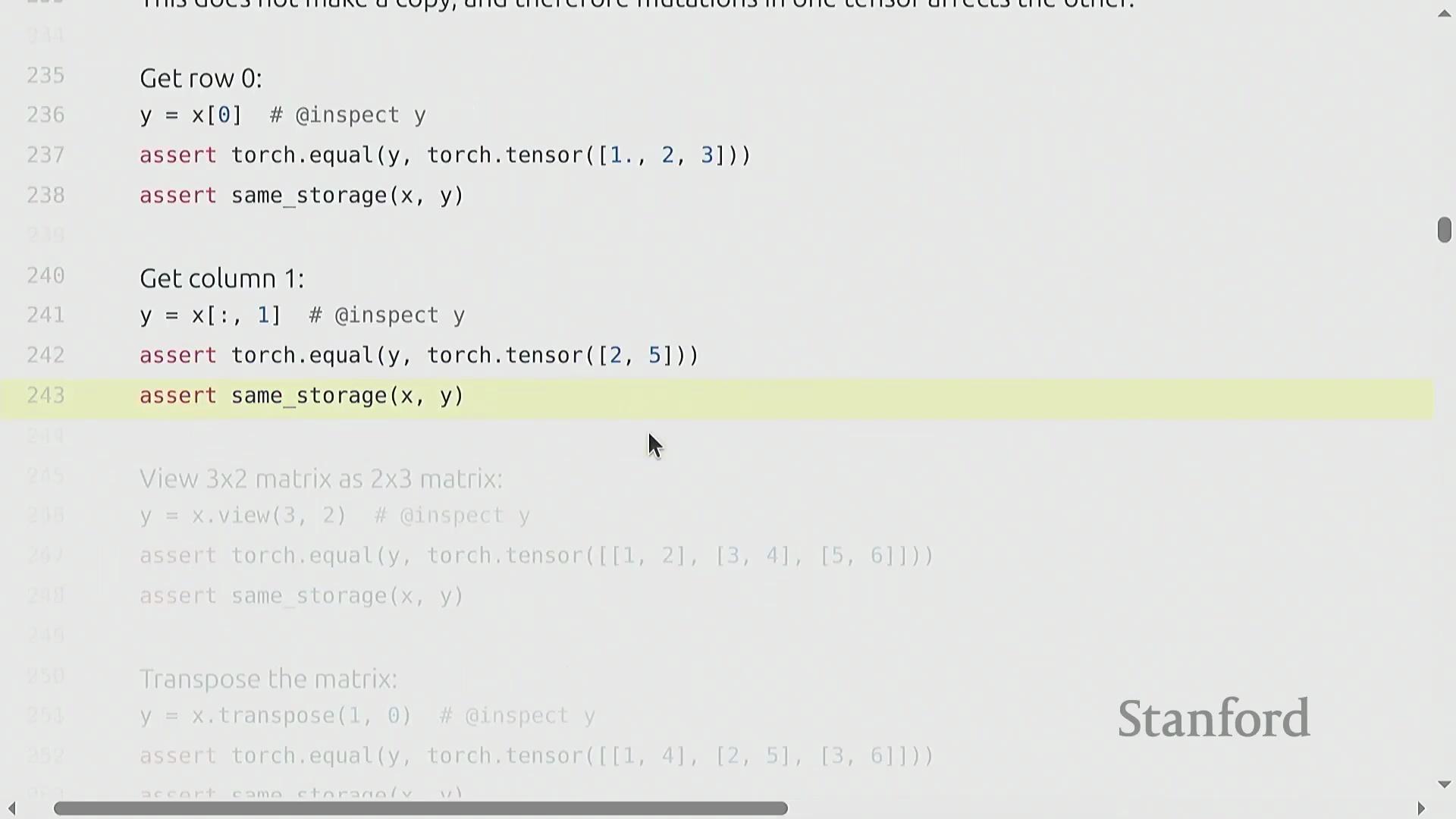
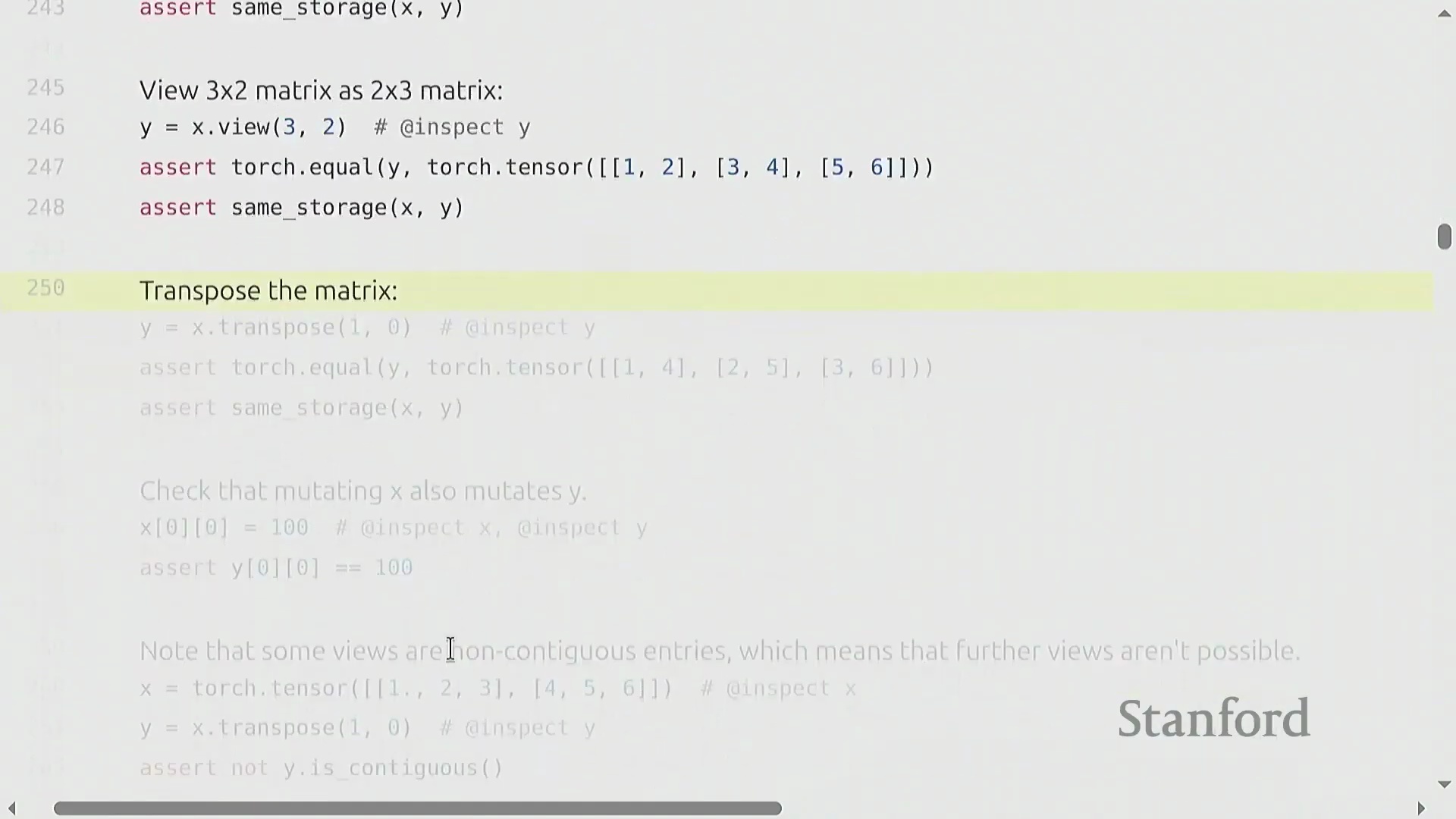
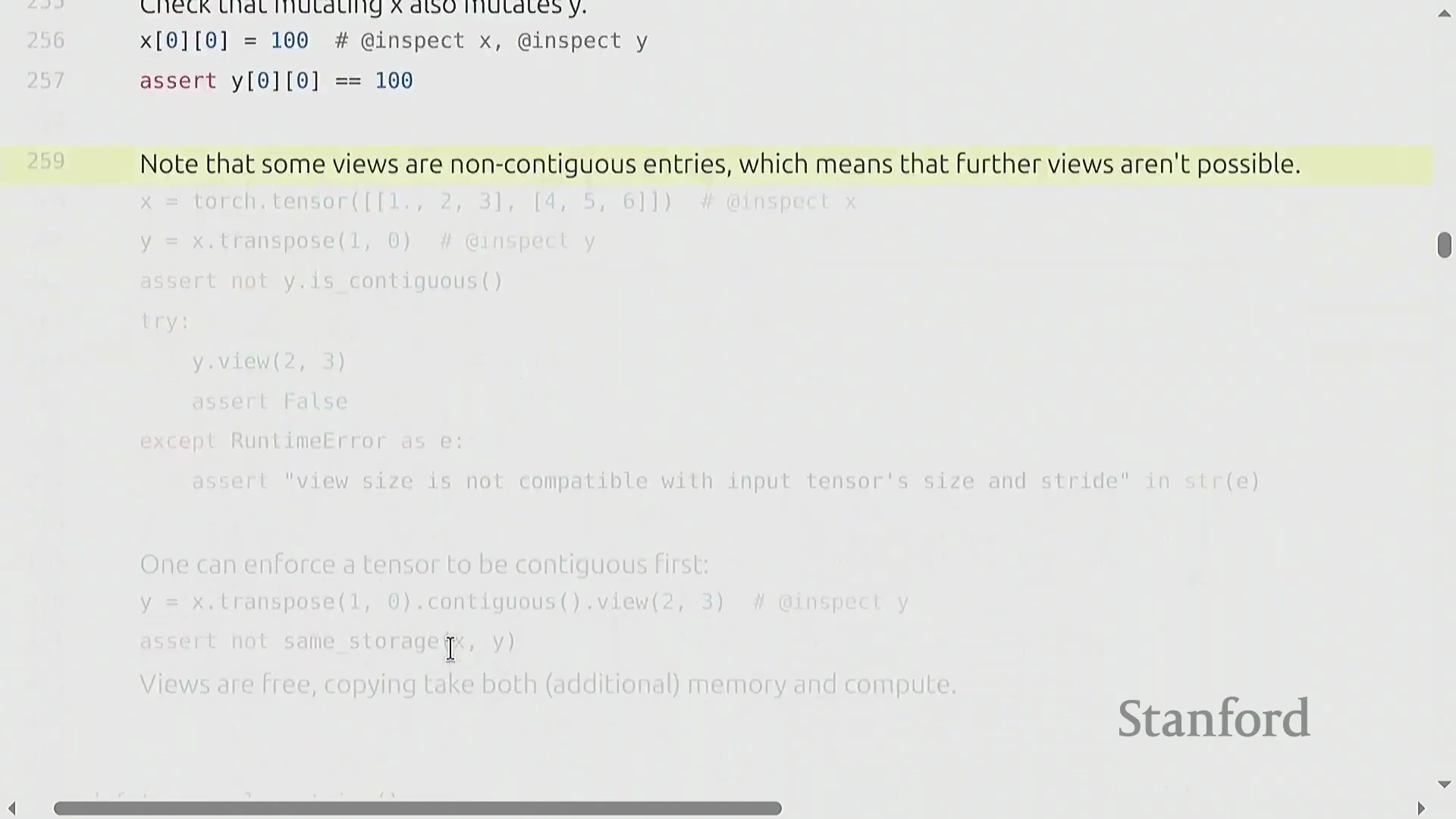
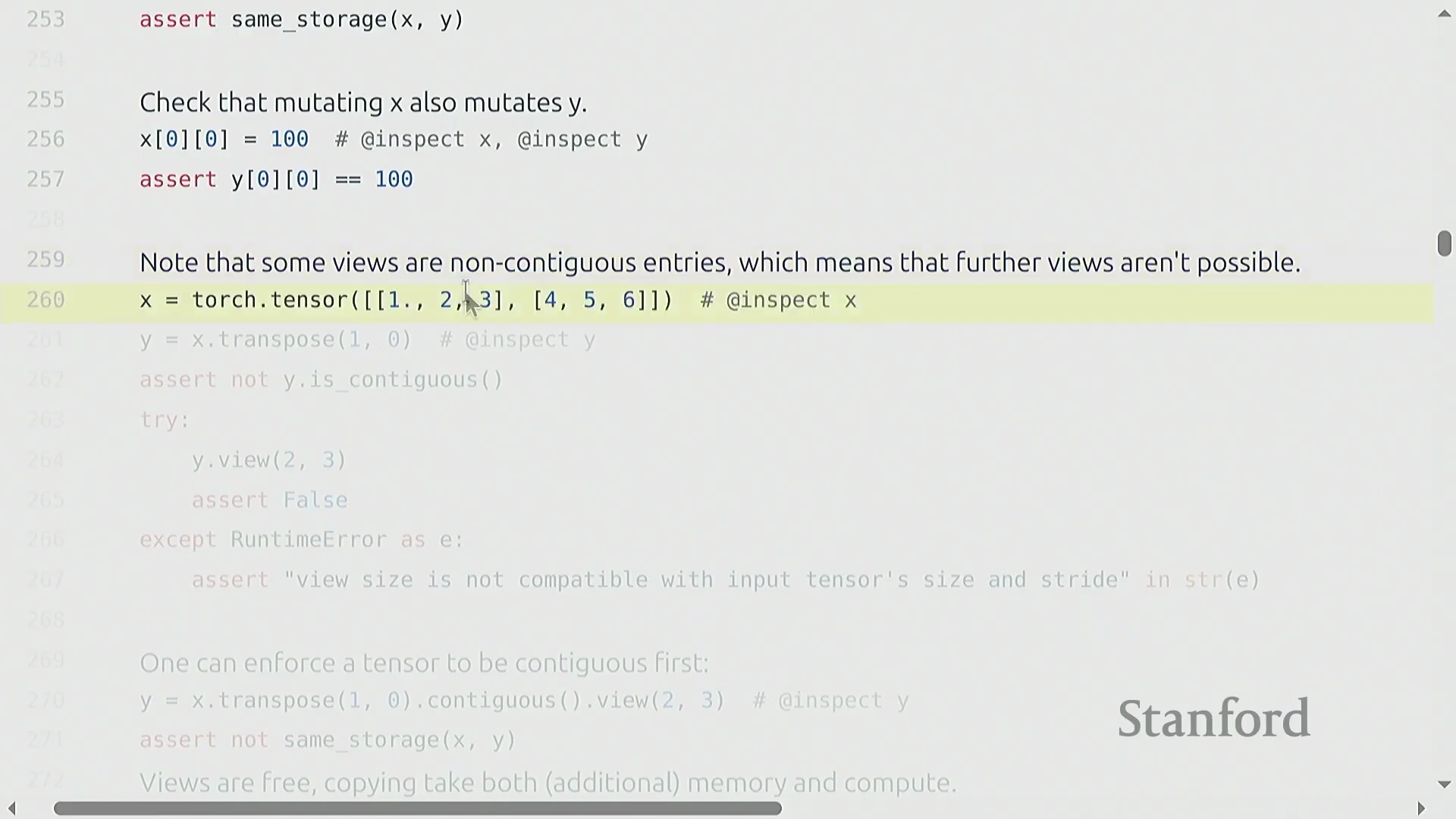
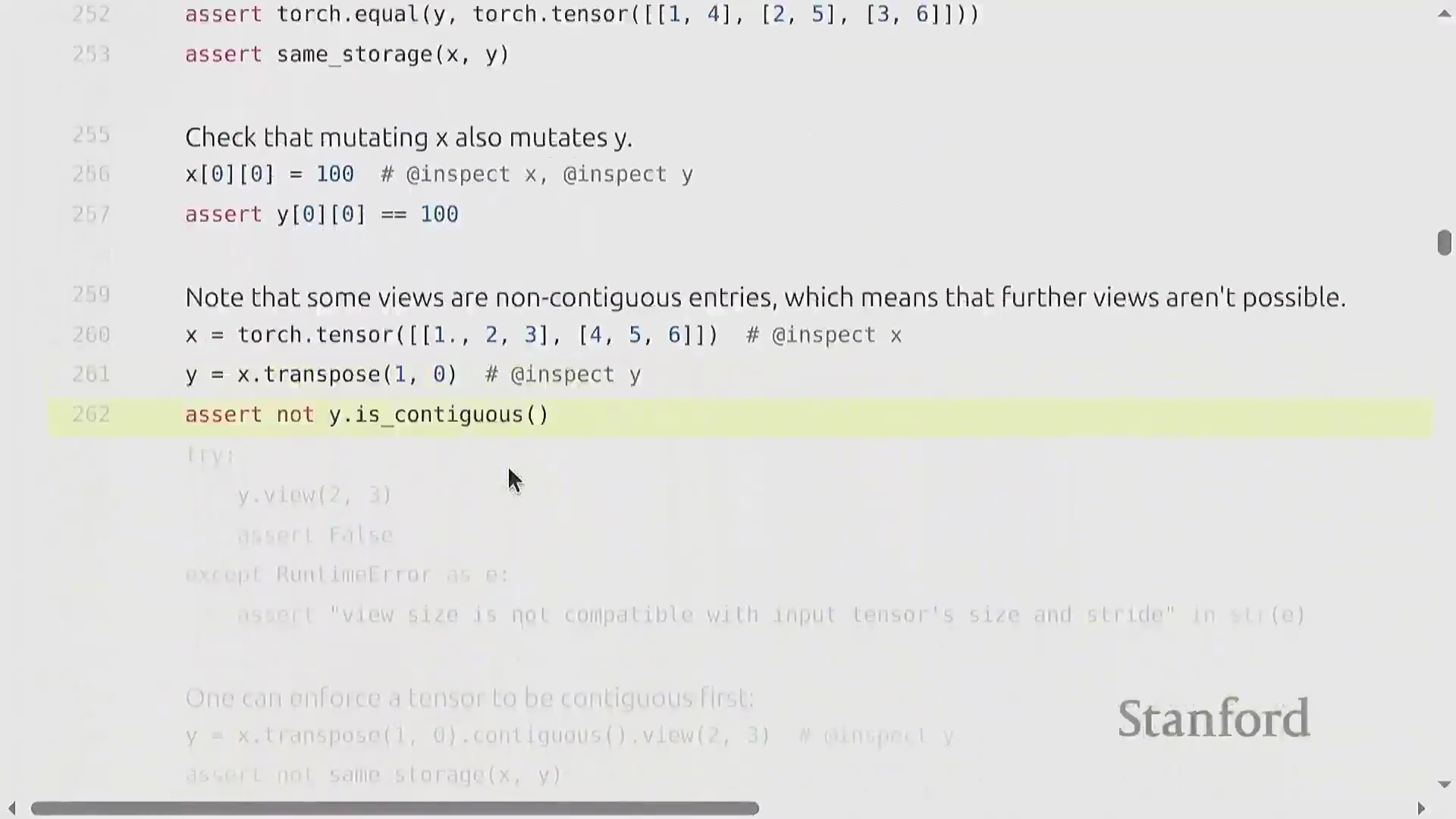
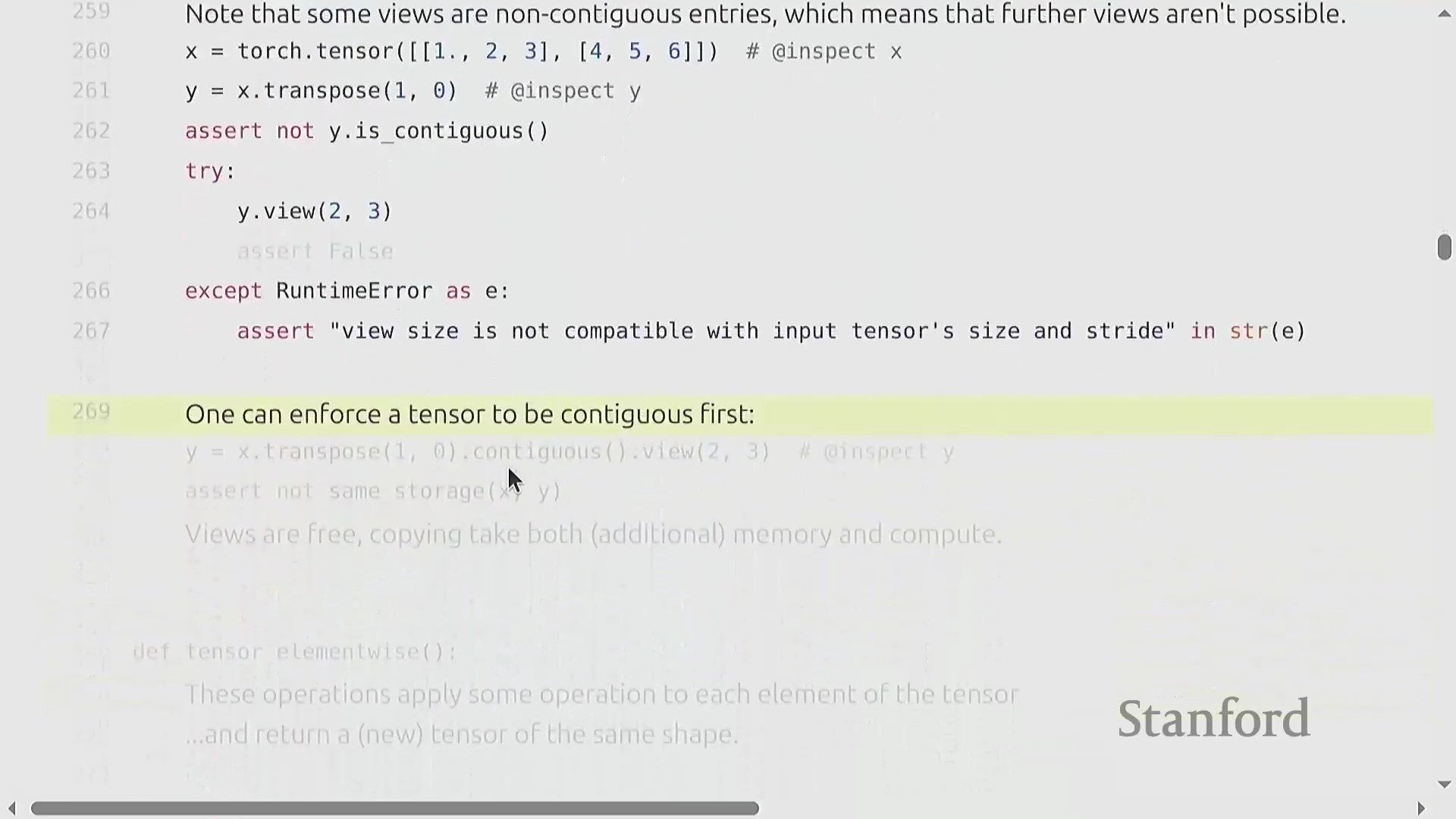
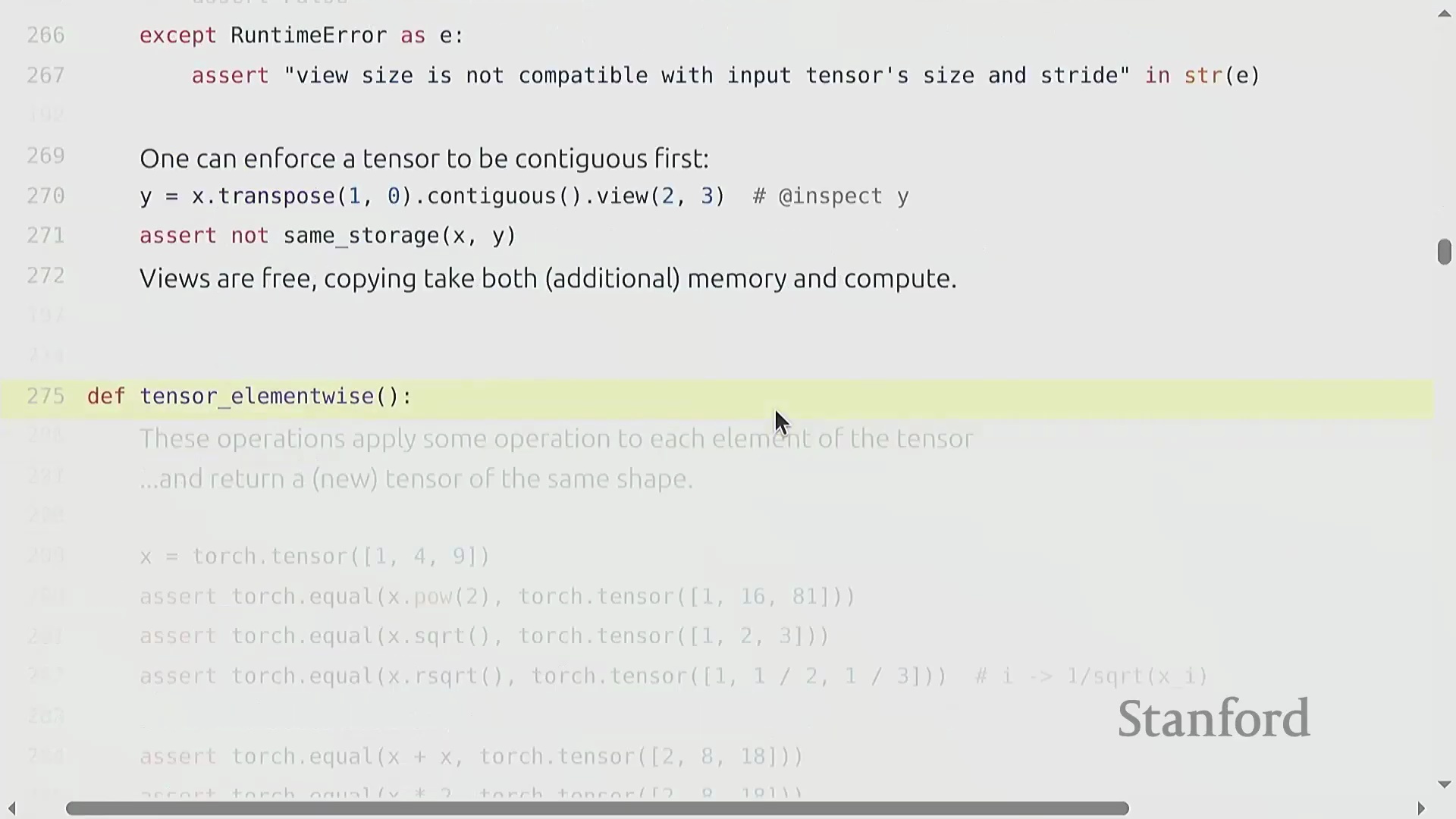
张量视图、存储与连续性
索引(Indexing)(如 x[0])、切片(Slicing)、.view() 和 .transpose() 等操作不会分配新内存(Memory Allocation)。相反,它们会创建视图(Views)——即指向相同底层数据存储(Underlying Storage)的新张量对象。你可以使用 .storage() 方法来验证这一行为。由于视图共享内存(Shared Memory),对任一视图的修改都会立即反映在原始张量及其他所有派生视图上。然而,这种高效机制依赖于张量在内存中保持连续(Contiguous)布局。转置(Transpose)等操作会重新排列内存步幅(Memory Strides),从而破坏张量的连续性。尝试在非连续(Non-contiguous)张量上调用 .view() 会引发运行时错误。要解决此问题,必须调用 .contiguous() 方法。该方法会将数据物理复制(Physical Copy)到全新的连续内存块中,从而切断原有的共享存储链接。尽管视图操作本身无额外开销且能显著提升代码可读性,但开发者仍需保持警惕,因为 .contiguous() 或 .reshape() 可能会在后台隐式触发内存分配。


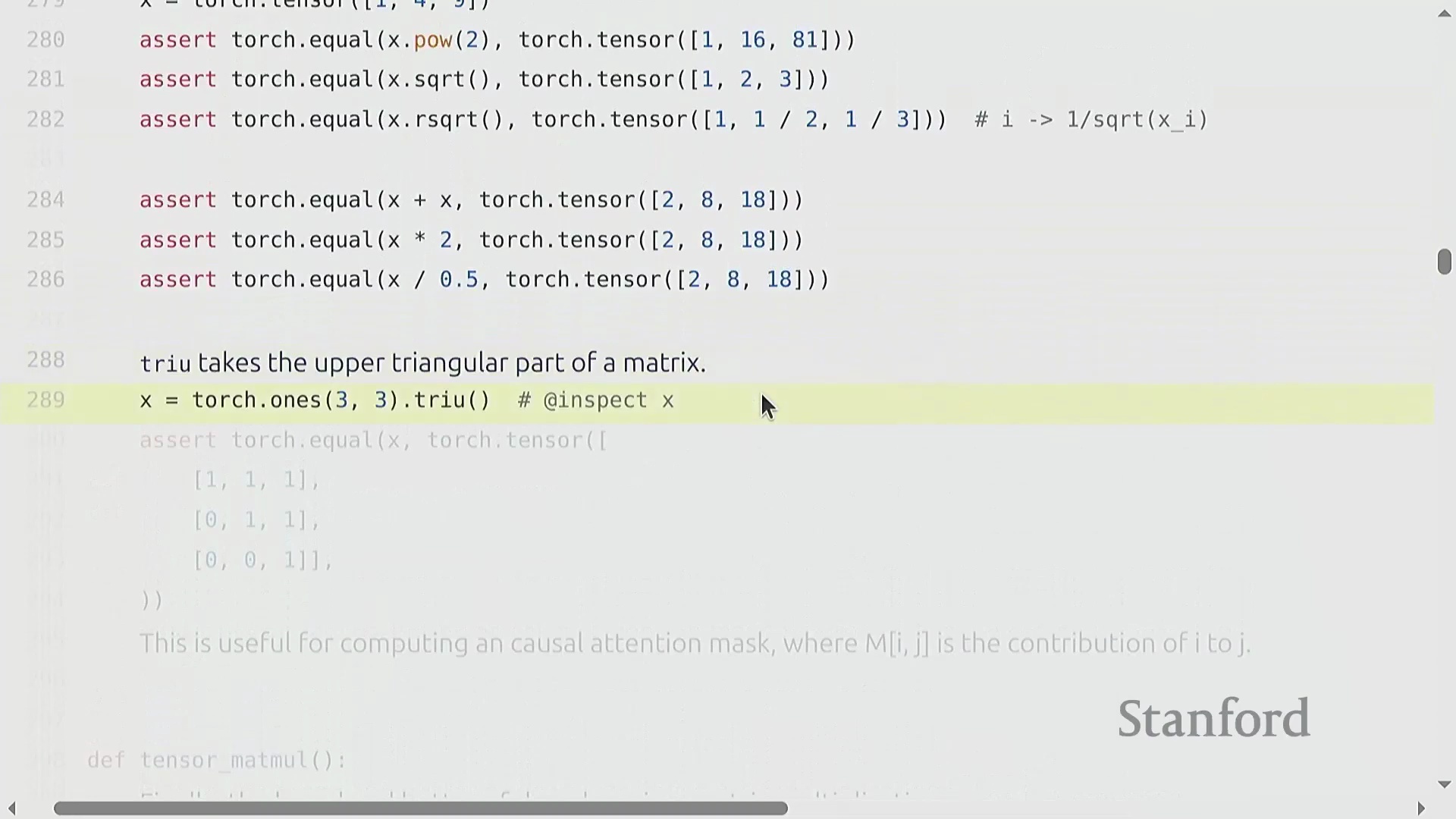
逐元素操作与批量矩阵乘法
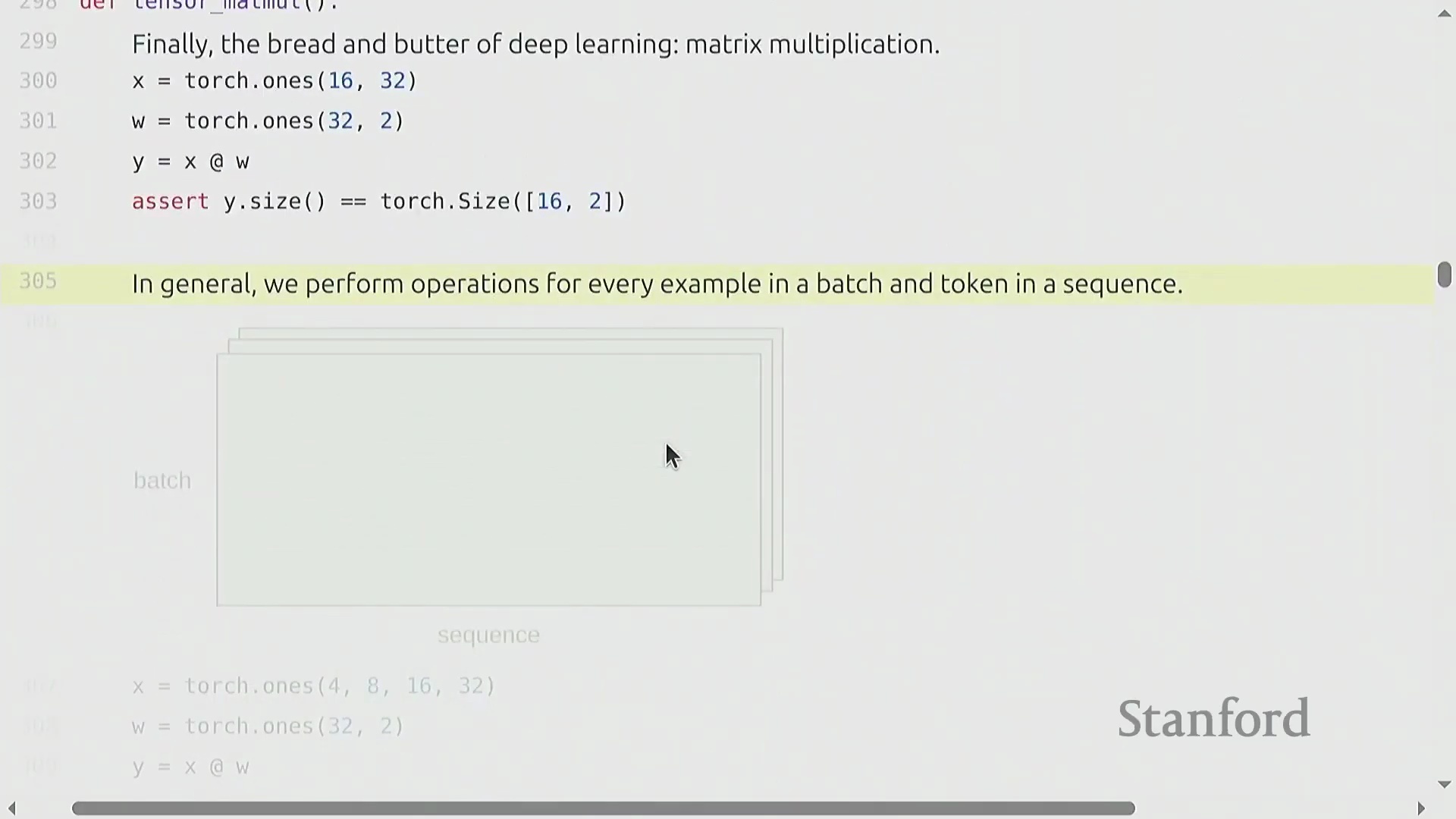
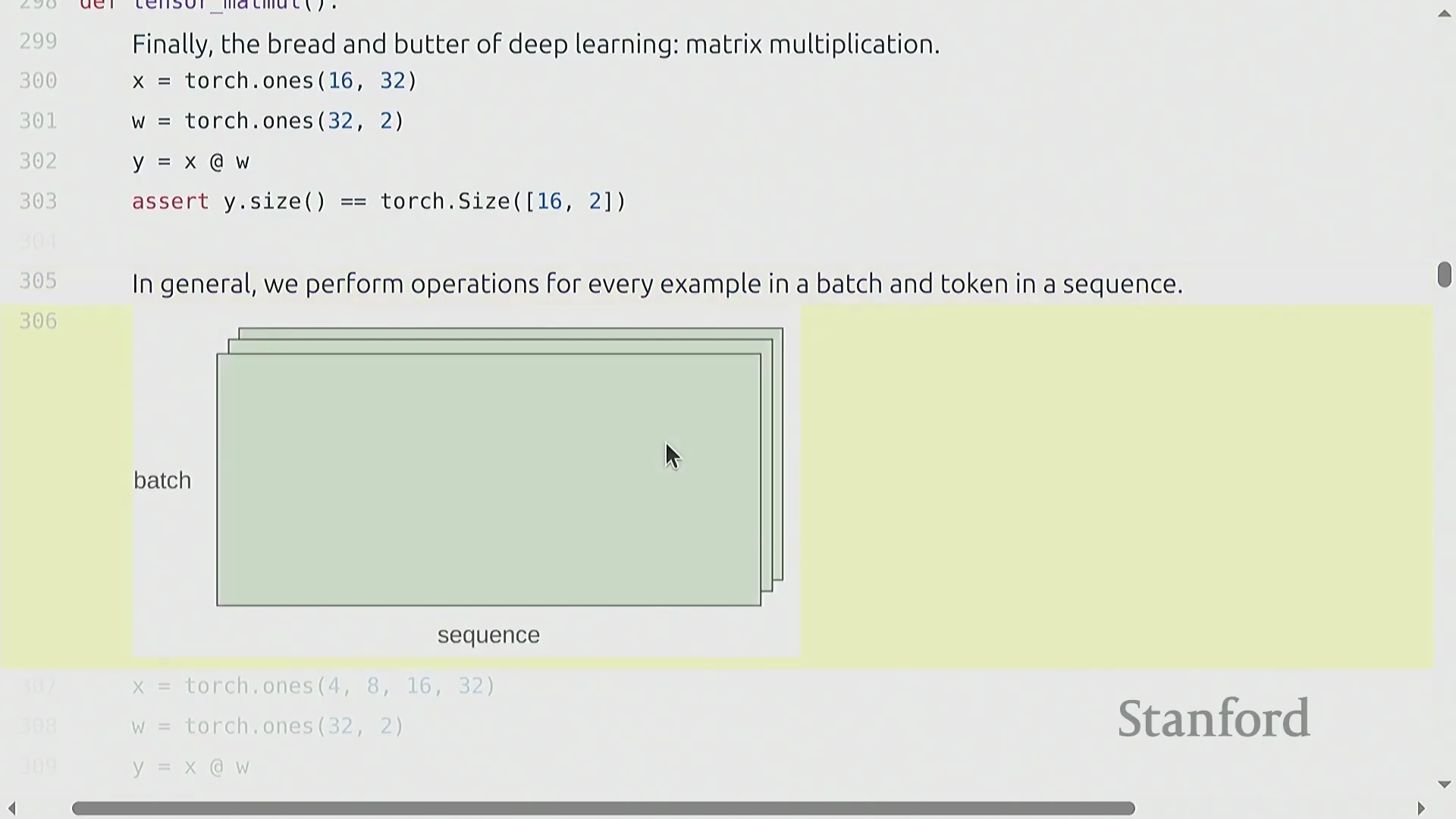
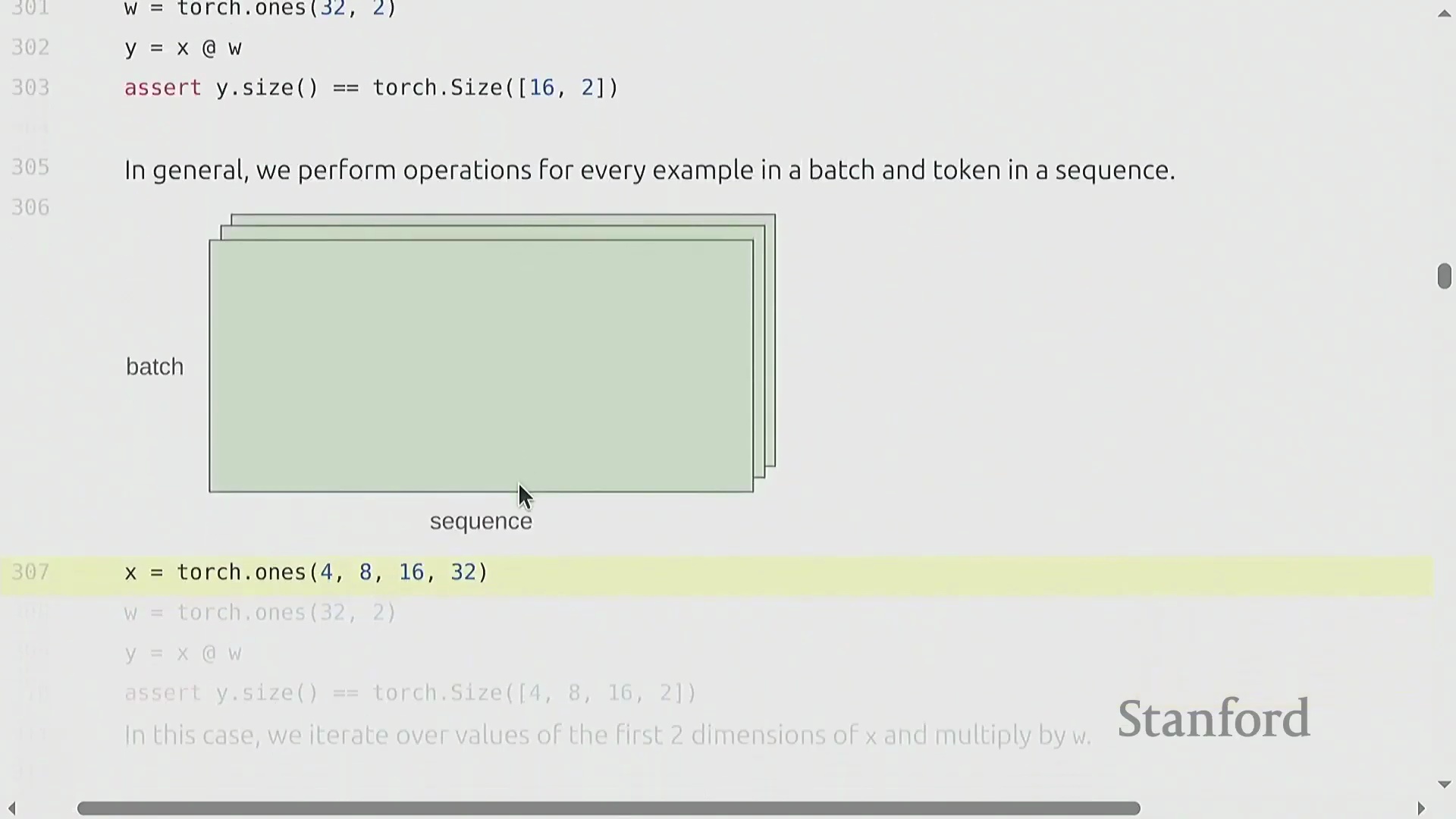
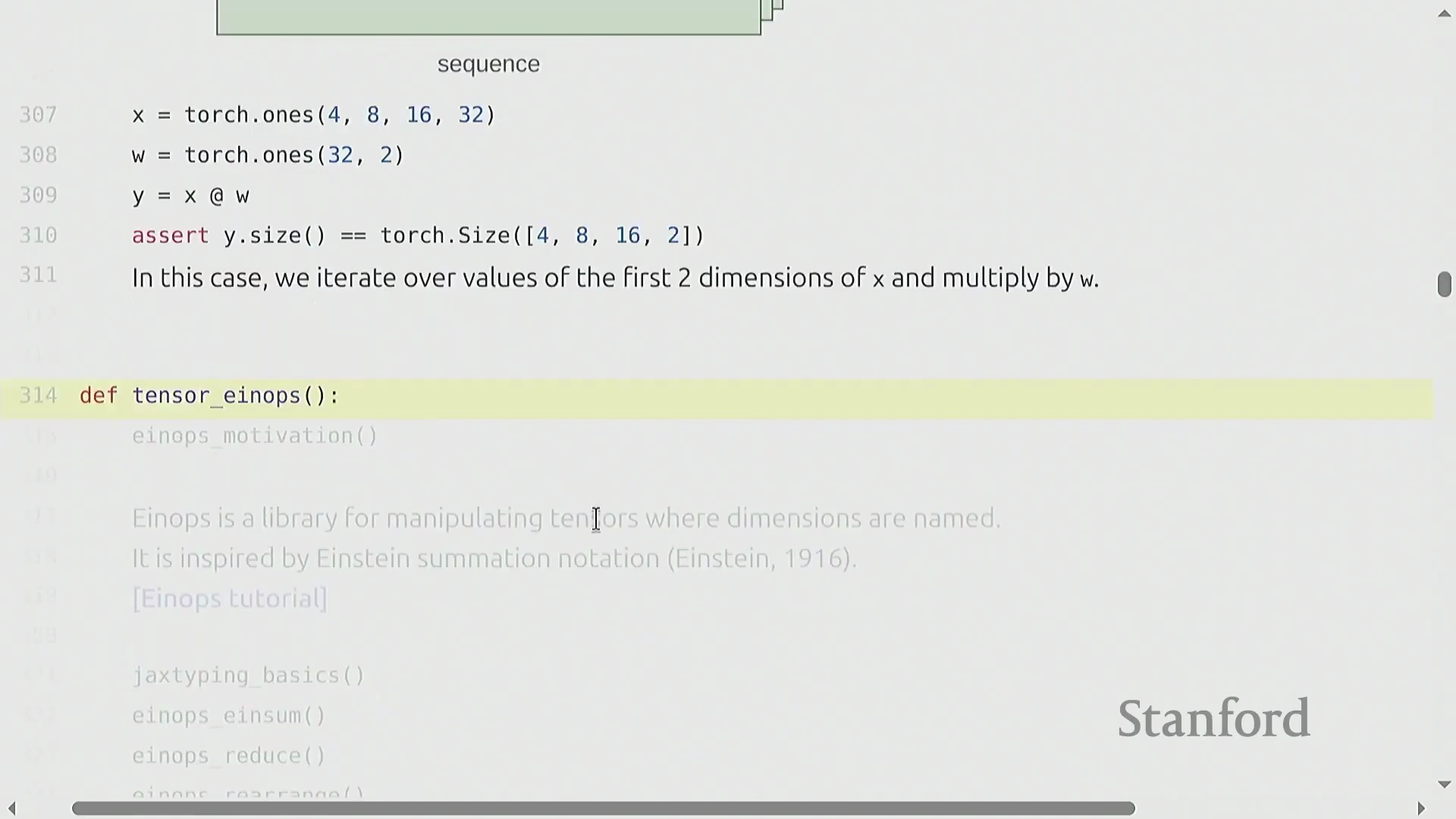
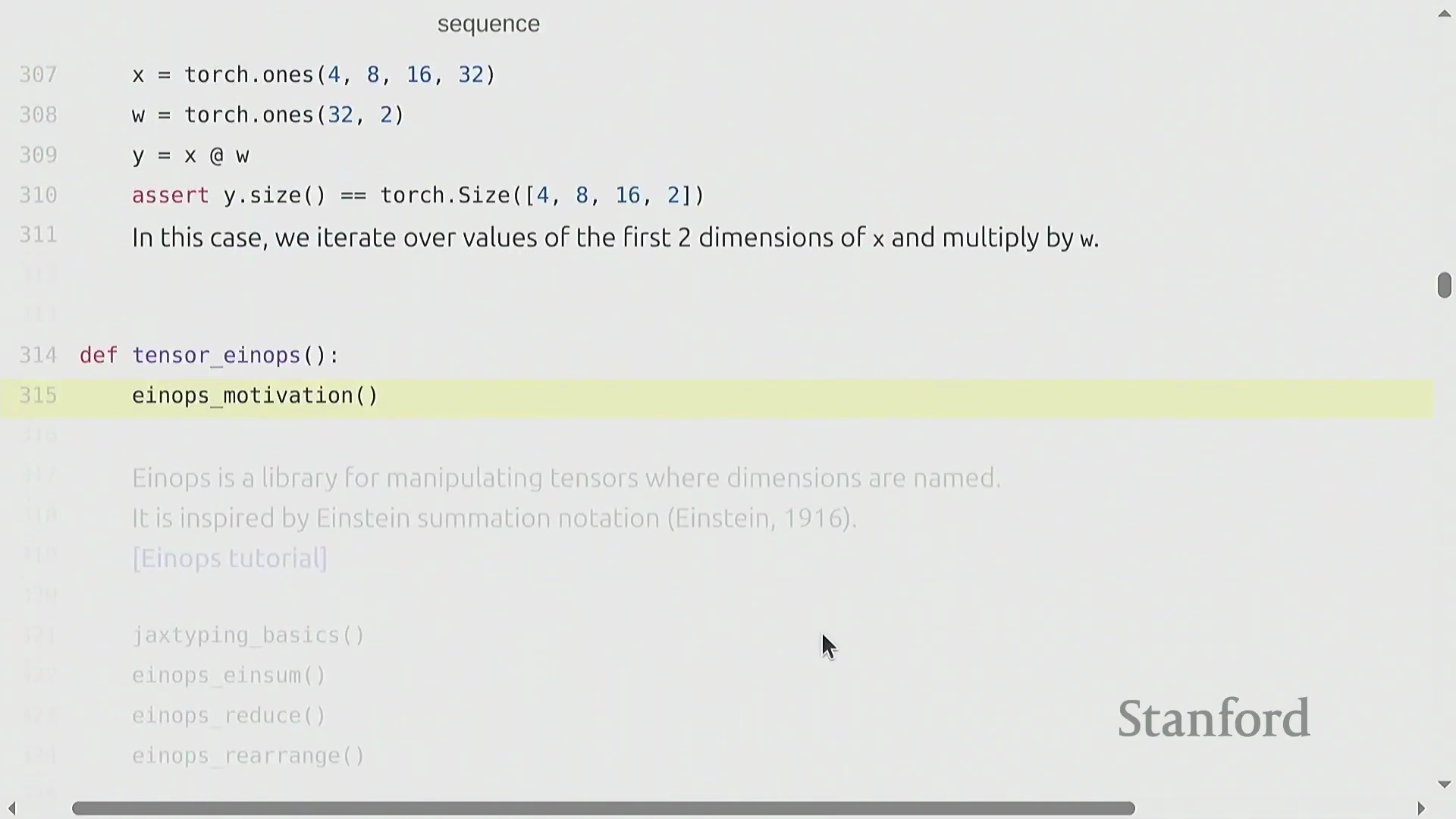
与视图操作不同,逐元素操作(Element-wise Operations)(如基础算术运算或调用 torch.triu)总是会分配新张量以存储计算结果。torch.triu 在生成 Transformer(Transformer) 架构所需的因果注意力掩码(Causal Attention Masks)时尤为关键。然而,深度学习(Deep Learning)的核心计算基石是矩阵乘法(Matrix Multiplication)。虽然标准的 matmul 主要用于二维矩阵,但 PyTorch 能够高效处理批量矩阵乘法(Batched Matrix Multiplications)。在语言建模(Language Modeling)任务中,张量通常具有 (batch, sequence, features) 的多维结构。当将张量 (B, S, 16, 32) 与二维权重矩阵 (32, 2) 相乘时,PyTorch 会自动在批次(Batch)和序列(Sequence)维度上执行广播(Broadcasting)操作。该机制将相同的线性变换(Linear Transformation)同时应用于每个样本中的每个词元(Token),从而消除了显式 Python 循环的开销,并最大化了硬件利用率(Hardware Utilization)。

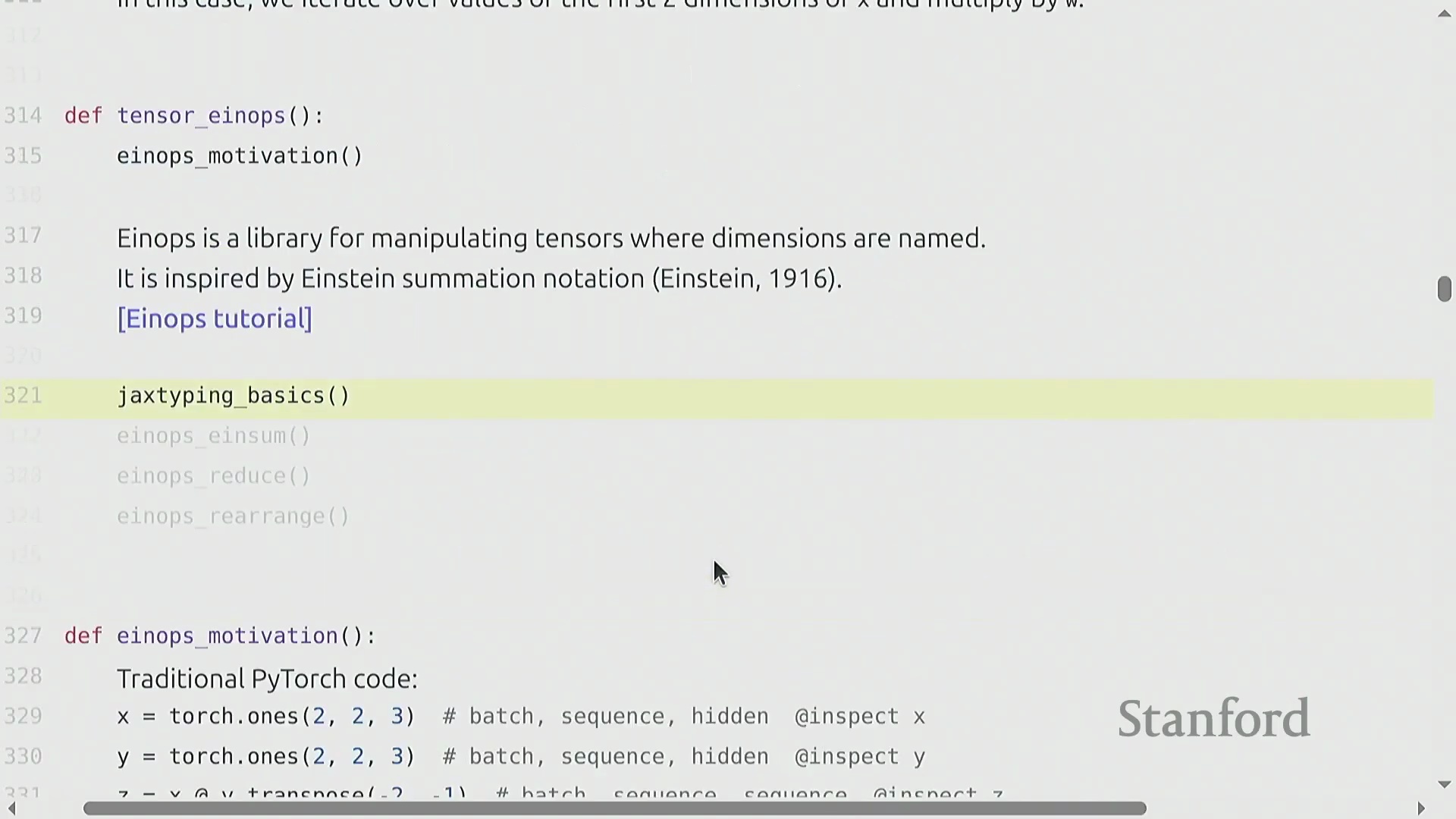
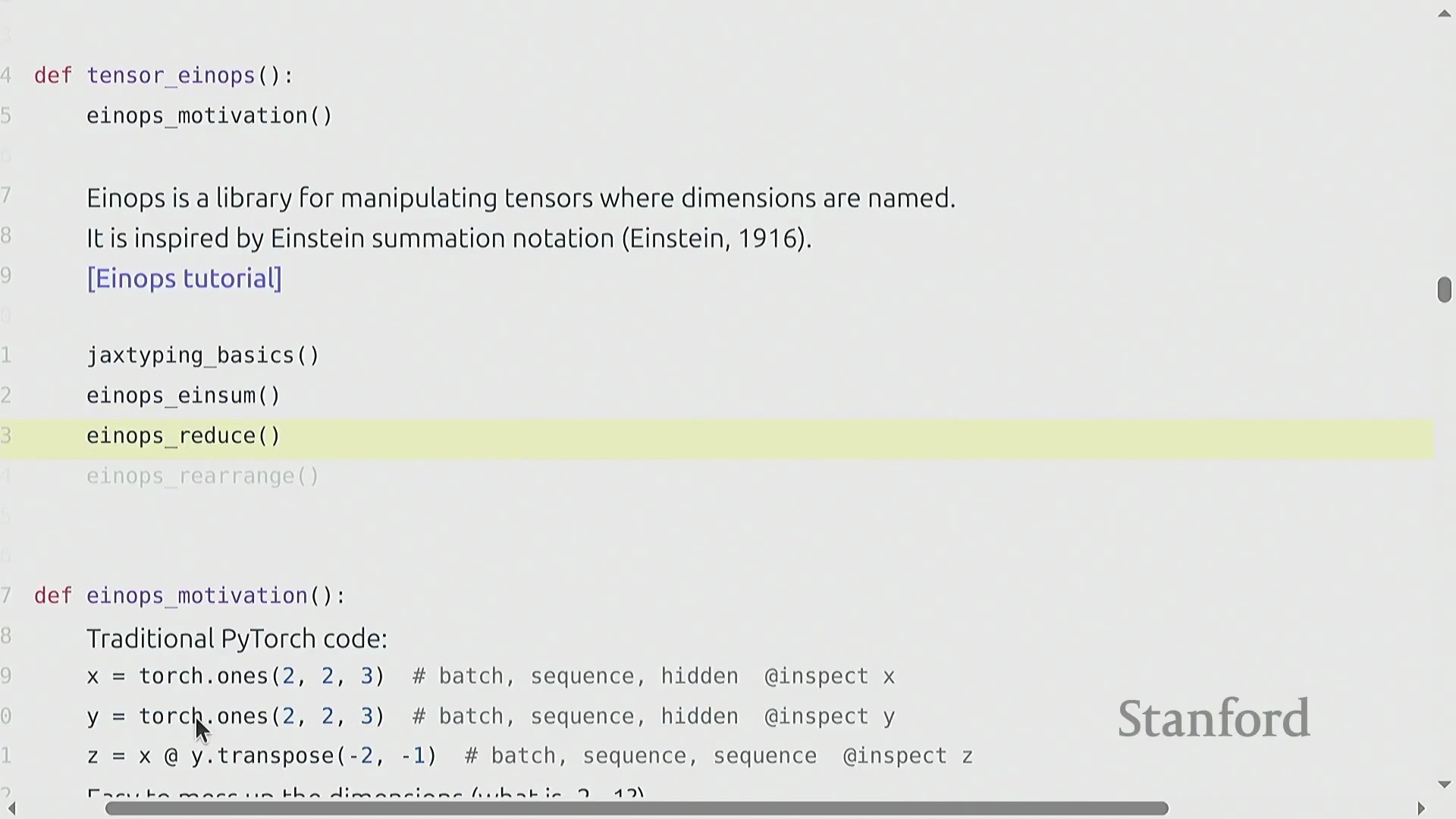
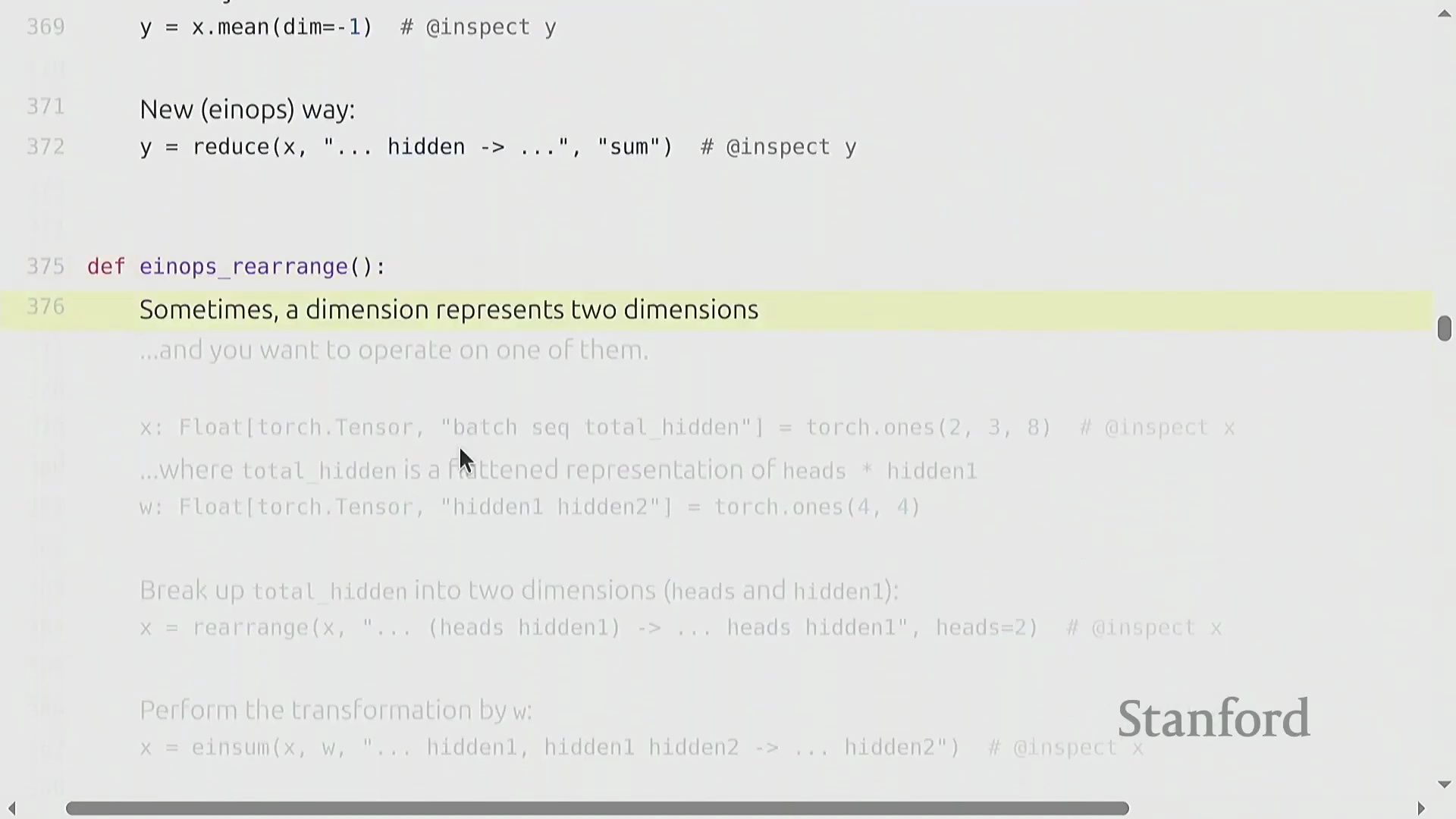
使用 Einops 解决维度歧义
随着张量操作日益复杂,依赖负索引(Negative Indexing)(例如 x.transpose(-2, -1))极易引发错误。诸如 -1 或 -2 之类的维度索引晦涩难懂,且配套代码注释极易过时,最终导致调试过程异常繁琐。einops 库通过使用语义化的人类可读名称替代数字索引,有效解决了这一痛点。其设计灵感直接来源于爱因斯坦求和约定(Einstein Summation Notation)。这种范式转变极大地提升了代码的清晰度与长期可维护性。为获得更严格的类型安全(Type Safety),开发者常将此类命名维度与 jaxtyping 等库结合使用。后者支持直接在函数签名(Function Signatures)中注解张量形状,从而为张量操作提供了一套自文档化(Self-documenting)的解决方案。
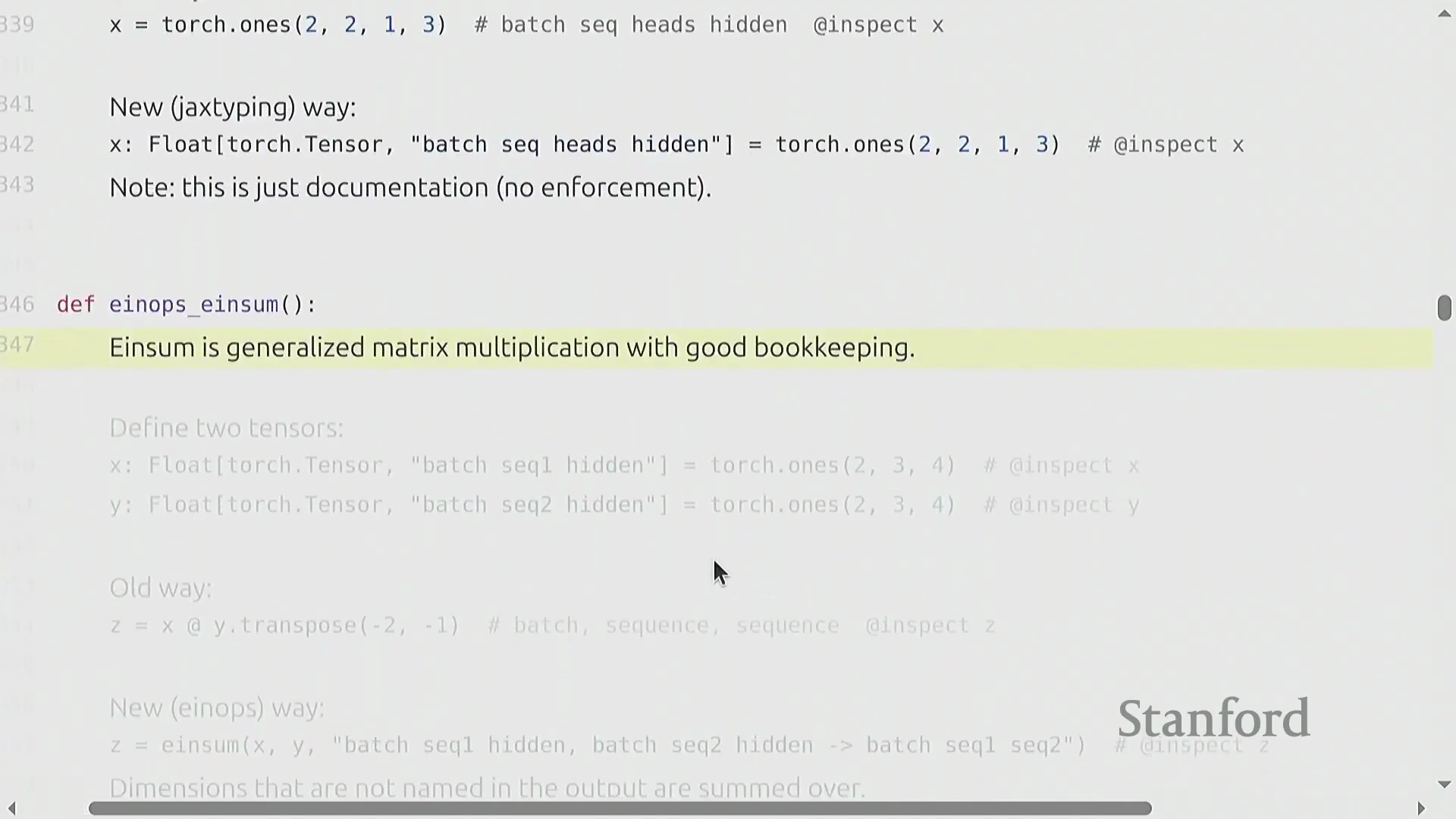
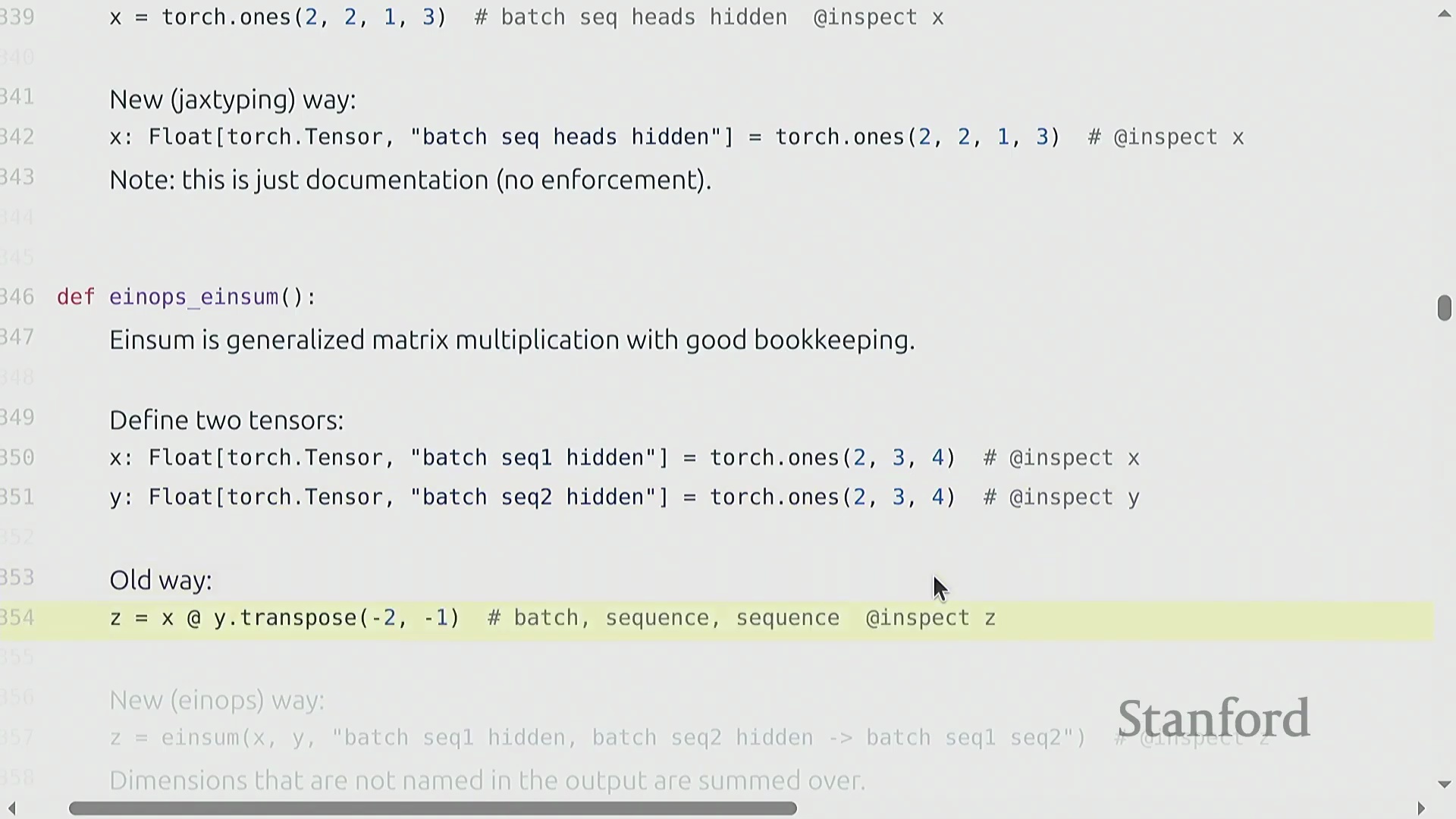
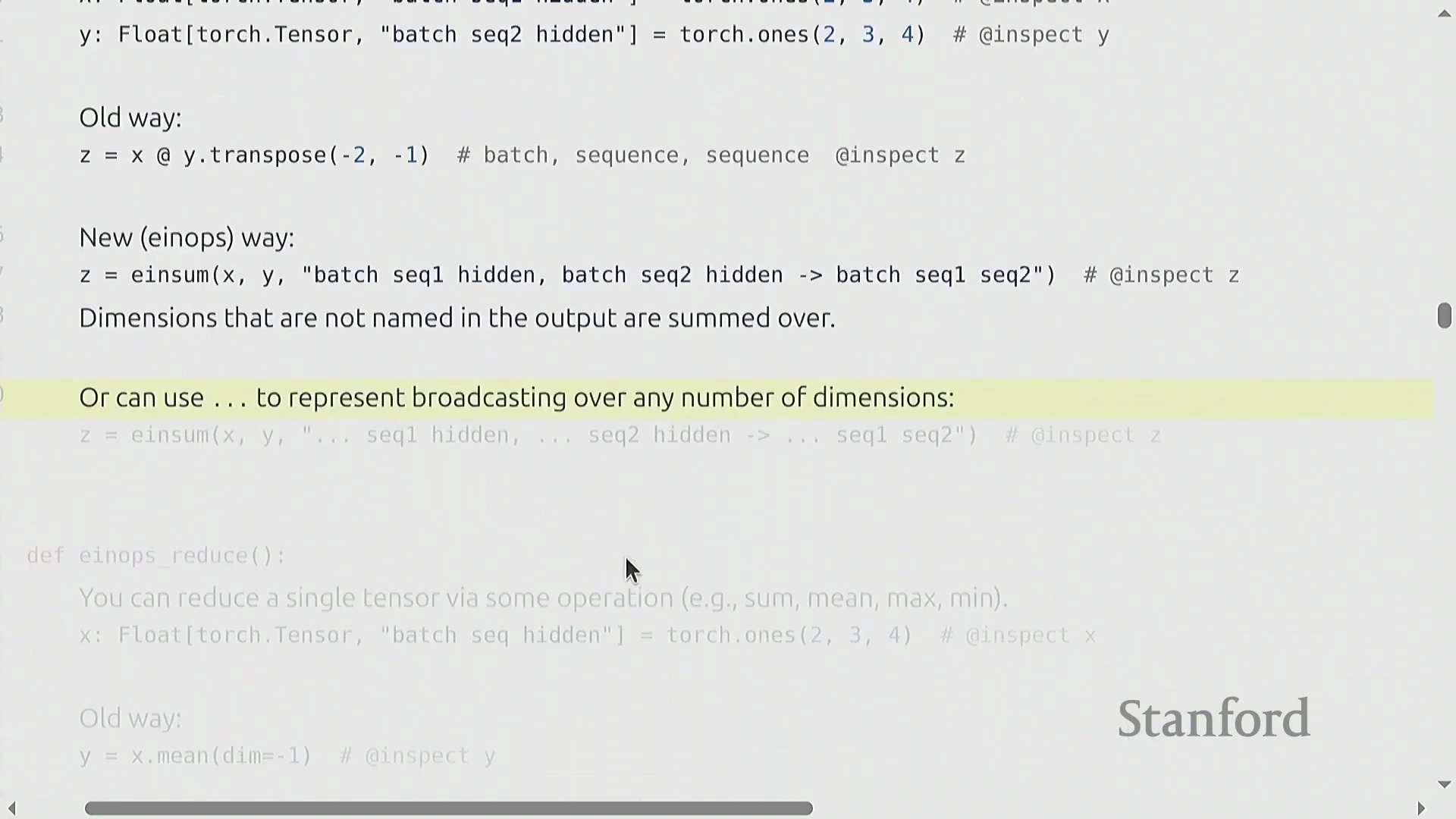
使用 Einsum 与编译进行高级缩并
基于命名维度的理念,torch.einsum 堪称“广义矩阵乘法”,内置了自动维度追踪(Dimension Tracking)与广播机制。开发者无需手动执行张量重塑(Reshape)、维度重排(Permute)或转置操作,只需在单一字符串表达式中显式声明输入与输出维度即可。例如,表达式 "b s h1, b s h2 -> b h1 h2" 指示 PyTorch 遍历 b(批次(Batch))和 s(序列(Sequence))维度,对 h 维度执行逐元素相乘,并对输出格式中未指定的维度自动执行缩并求和(Contraction)。此外,通过使用省略号 ...,可灵活地在任意数量的前导维度上进行广播,使操作能够自适应不同的张量阶数(Tensor Rank)。针对代码可读性与执行性能存在冲突的常见担忧实则毫无根据:当结合 torch.compile 使用时,einsum 会经过高度优化。底层编译器会智能规划最高效的缩并顺序(Contraction Order)与内存布局,确保高表现力、易读的代码直接转化为高性能的机器指令。


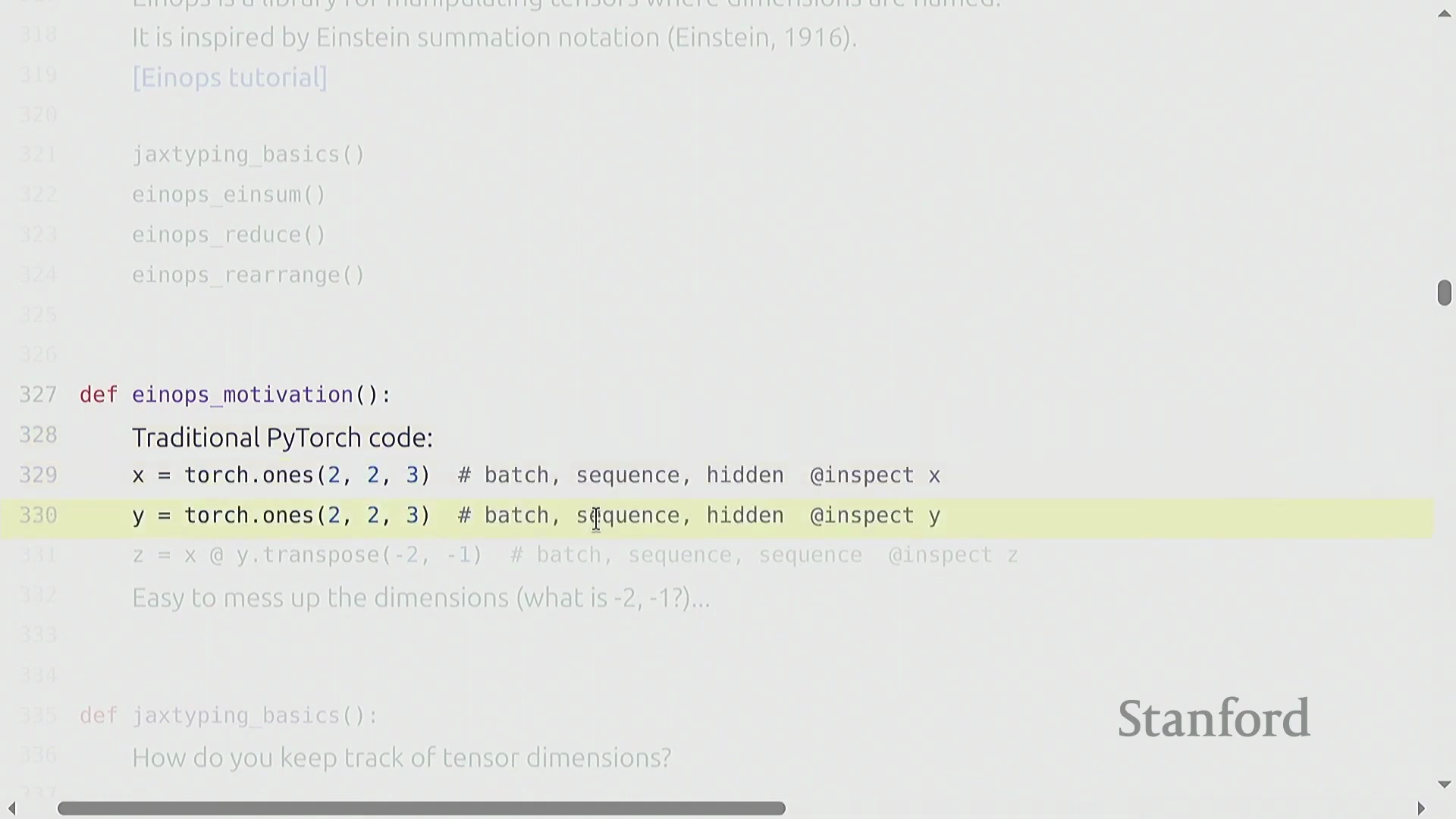




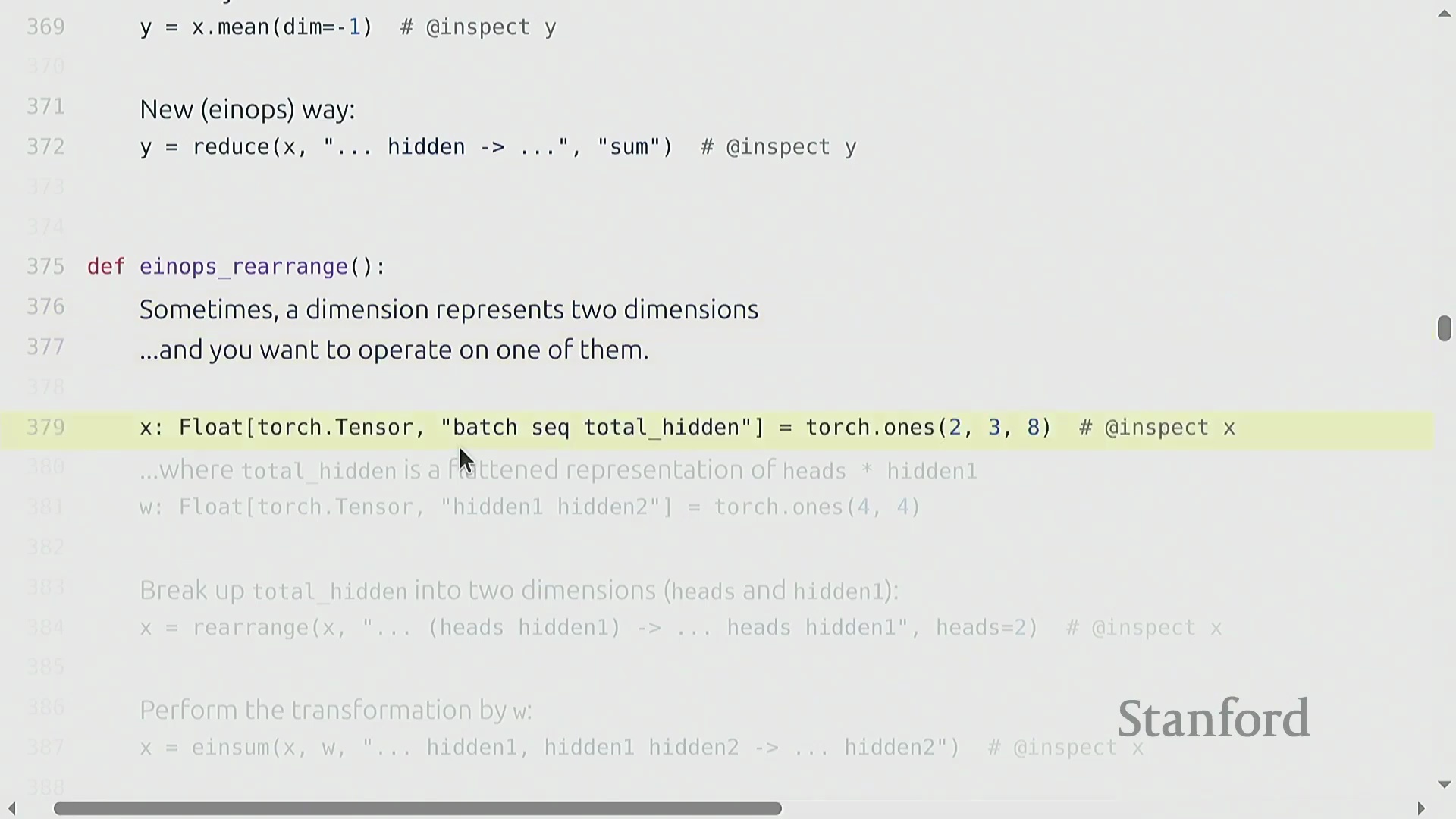
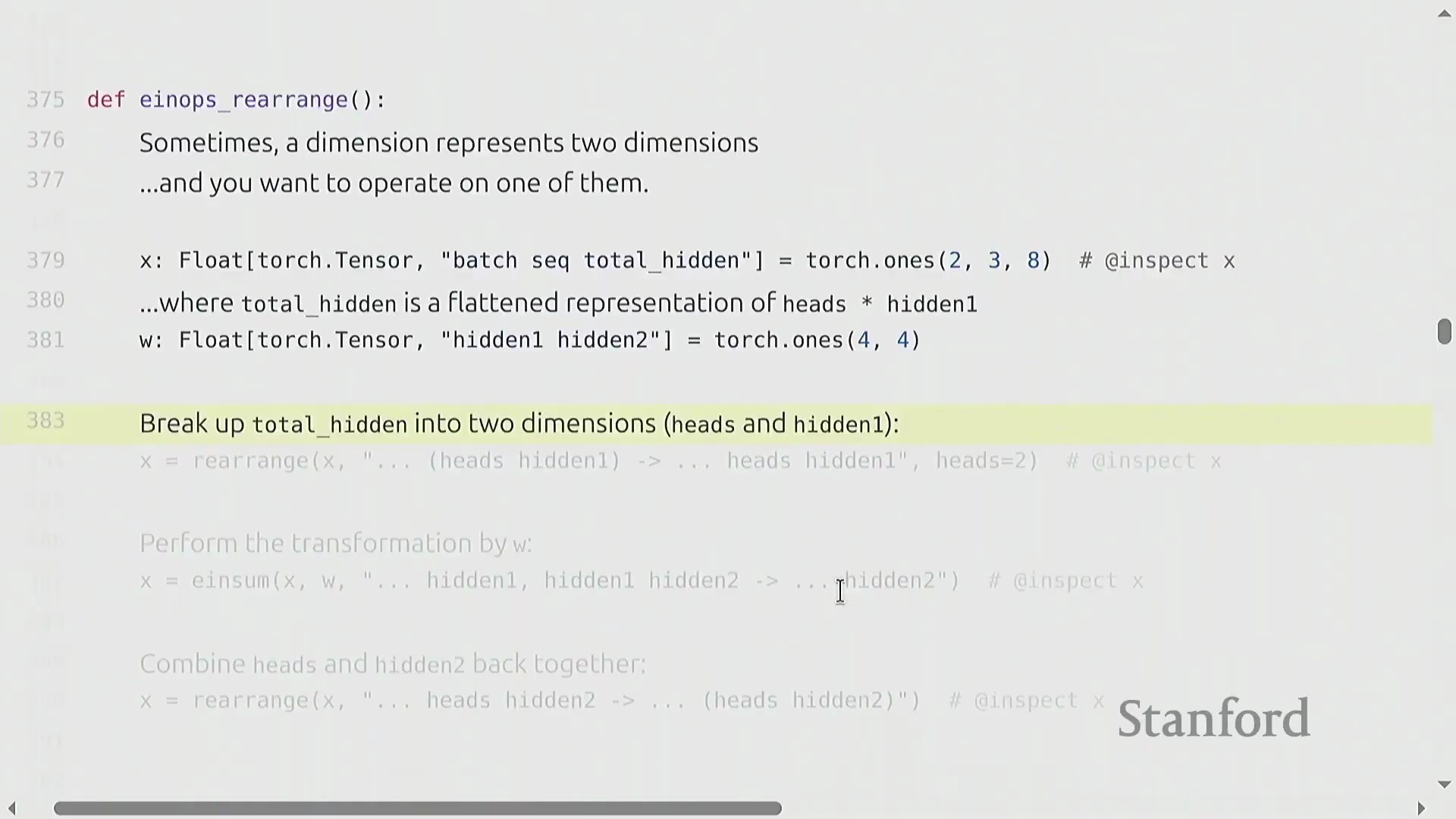
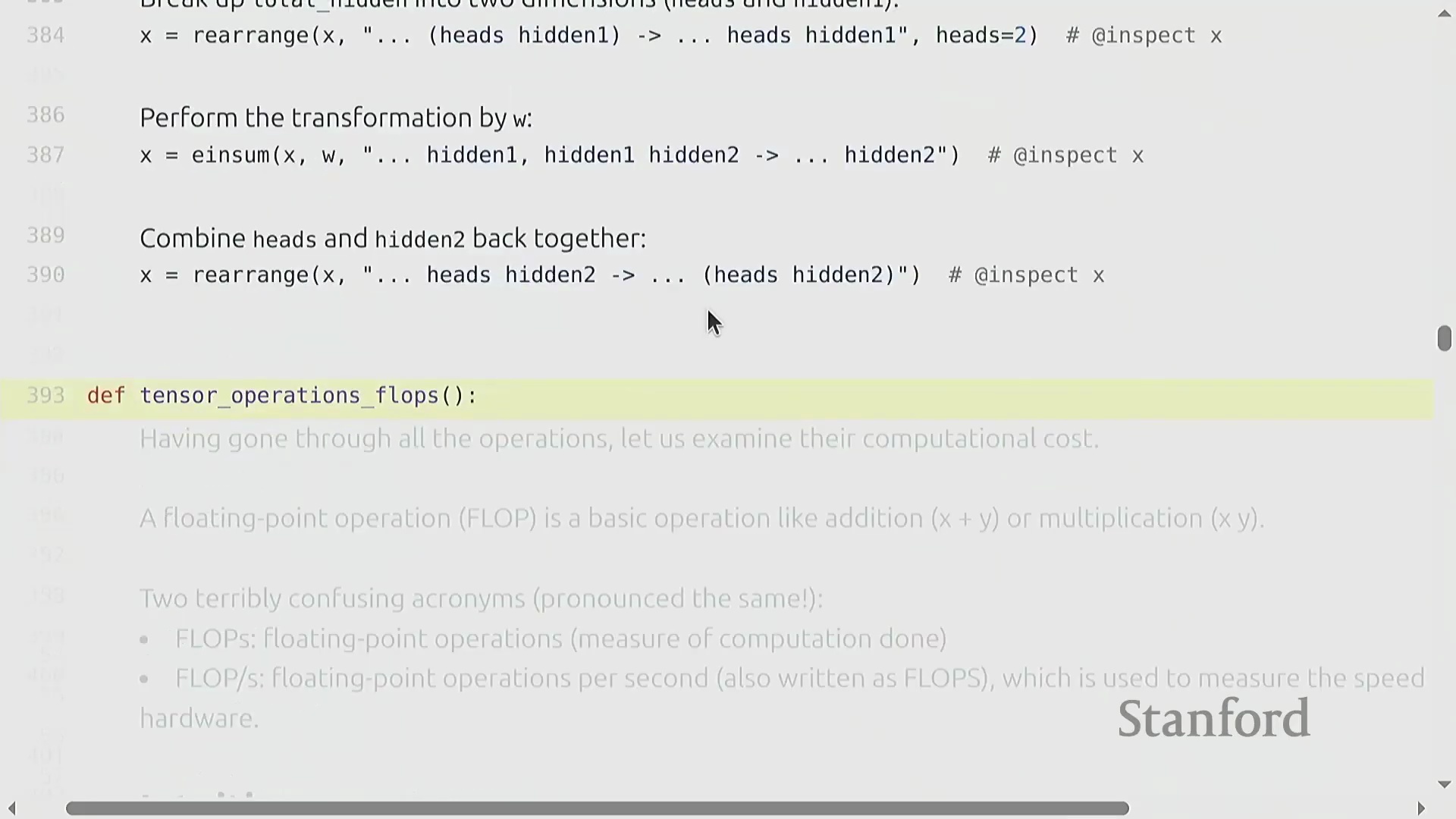
使用 Einops 进行高级张量操作
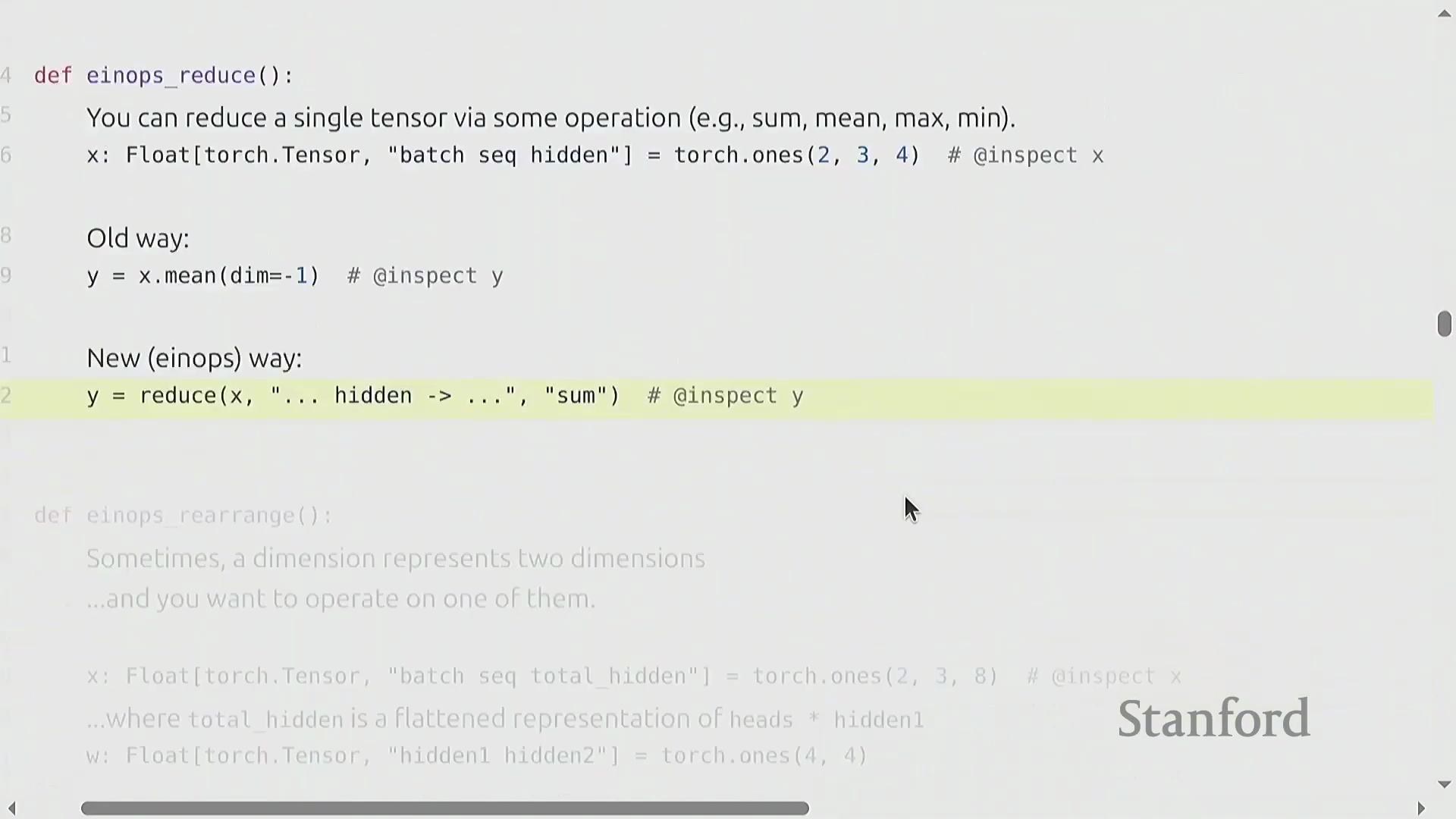
基于命名维度(Named Dimensions),einops(Einops) 库提供了强大的工具,用于聚合和重塑张量,从而摆脱对晦涩数字索引的依赖。reduce(Reduce) 操作允许你以清晰易读的方式沿指定命名维度执行聚合操作(例如,对 hidden 维度求和)。面对更复杂的场景(例如单个维度编码了多个逻辑轴,如展平后维度为 8 的 heads × hidden 向量),rearrange(Rearrange) 函数能够优雅地完成数据的解包、变换与重组。你可以拆分某一维度,在新生成的轴上应用 einsum(Einsum) 缩并(Contraction) 操作,随后再将其展平。这些操作本质上充当了高级视图(Advanced Views),要求显式声明维度尺寸以确保拆分无歧义。与传统的 view 或 transpose 链式调用相比,它们极大提升了代码的可读性与清晰度。强烈建议参考官方教程以熟练掌握这些模式,它们已在现代 Transformer(Transformer) 架构实现中得到广泛应用。

理解 FLOPs 与 FLOP/s 及模型规模背景
在进行算力核算(Compute Accounting)时,关键在于区分 FLOP(Floating Point Operations,浮点运算次数,表示总计算工作量) 和 FLOP/s(Floating Point Operations per Second,每秒浮点运算次数,用于衡量硬件吞吐量)。为避免概念混淆,本讲座在表述吞吐量时始终显式标注 /s。历史大语言模型(Large Language Models) 的规模数据提供了直观参照:训练 GPT-3 约需 3e23 次 FLOPs,而 GPT-4 的估算值高达 2e25 次。如此庞大的数值已引起监管机构的高度重视。例如,美国曾出台一项现已撤销的行政命令,要求对训练算力超过 1e26 FLOPs 的模型进行报备;欧盟《人工智能法案》(EU AI Act) 亦设定了 1e25 FLOPs 的监管阈值。深入理解这些数量级,有助于更准确地评估训练基础模型(Foundation Models) 所需的算力资源。
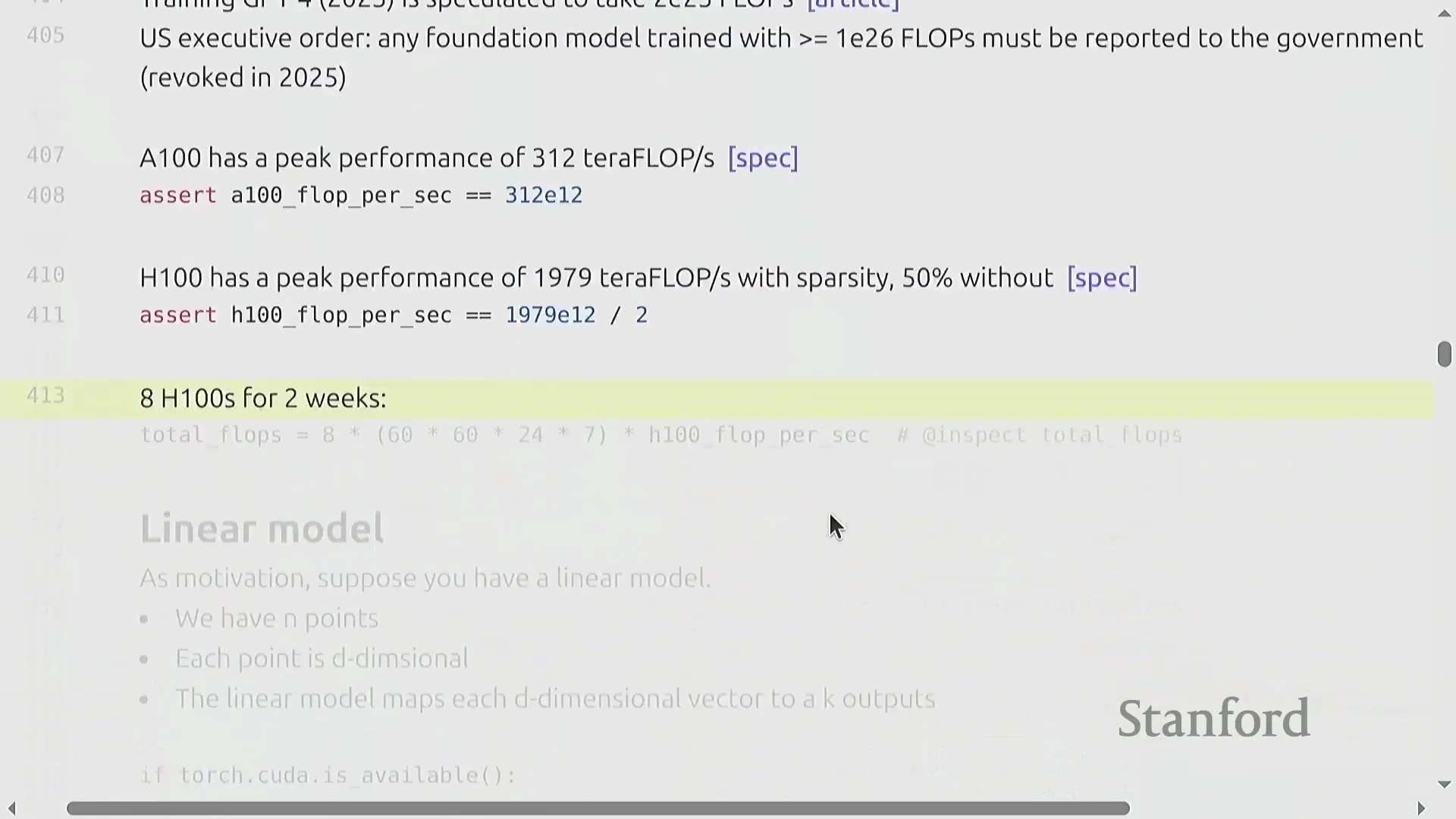
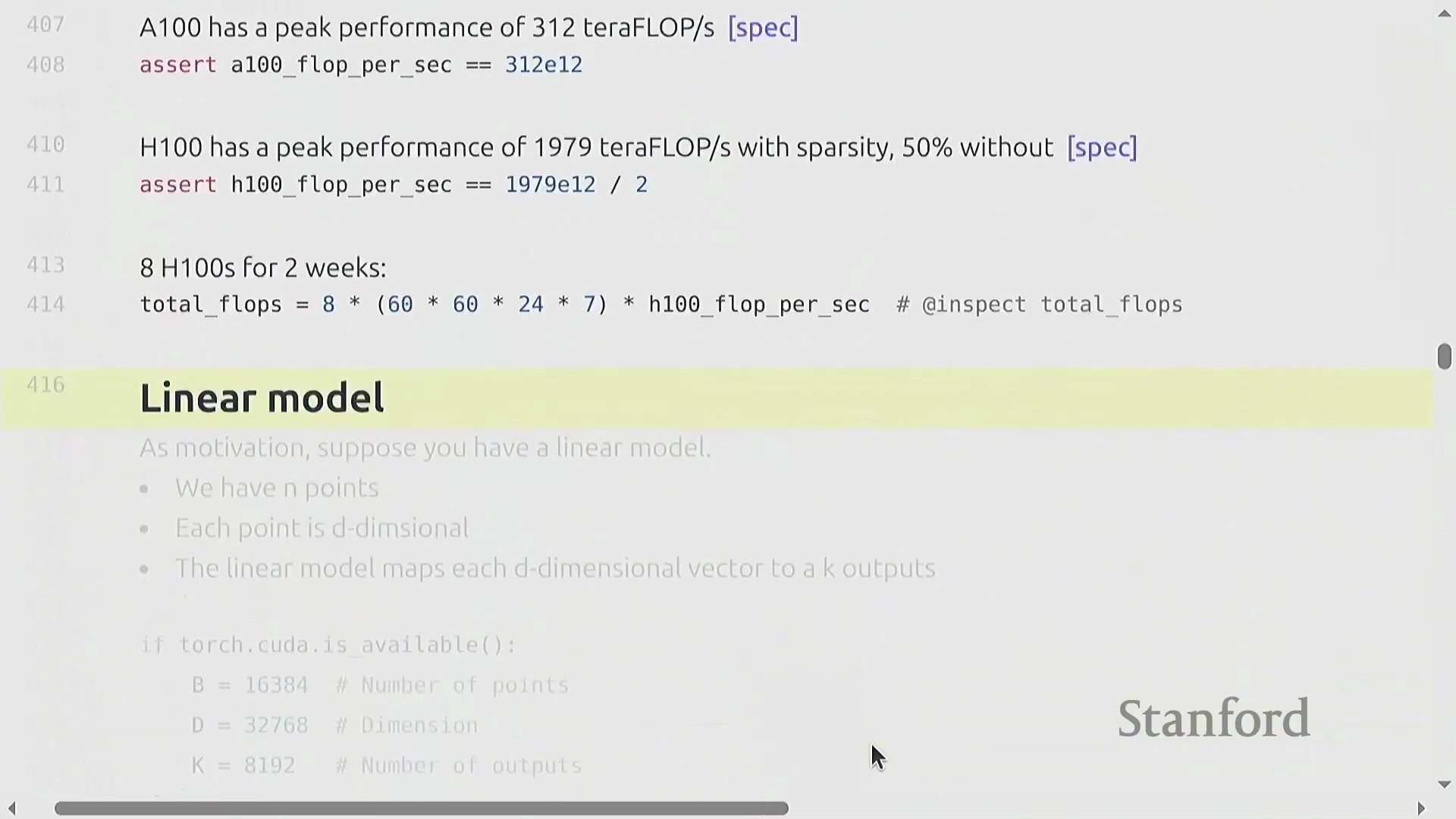
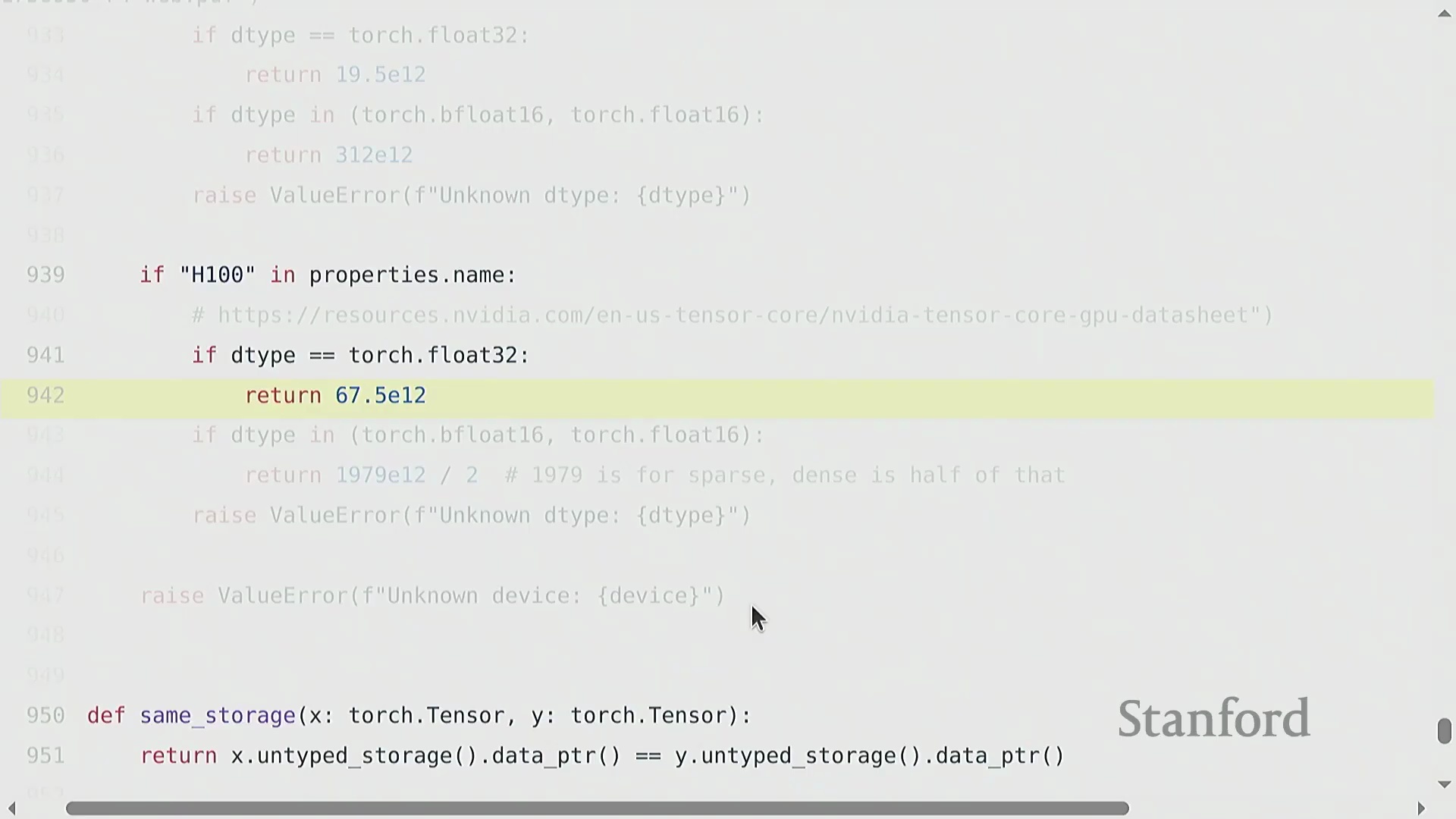
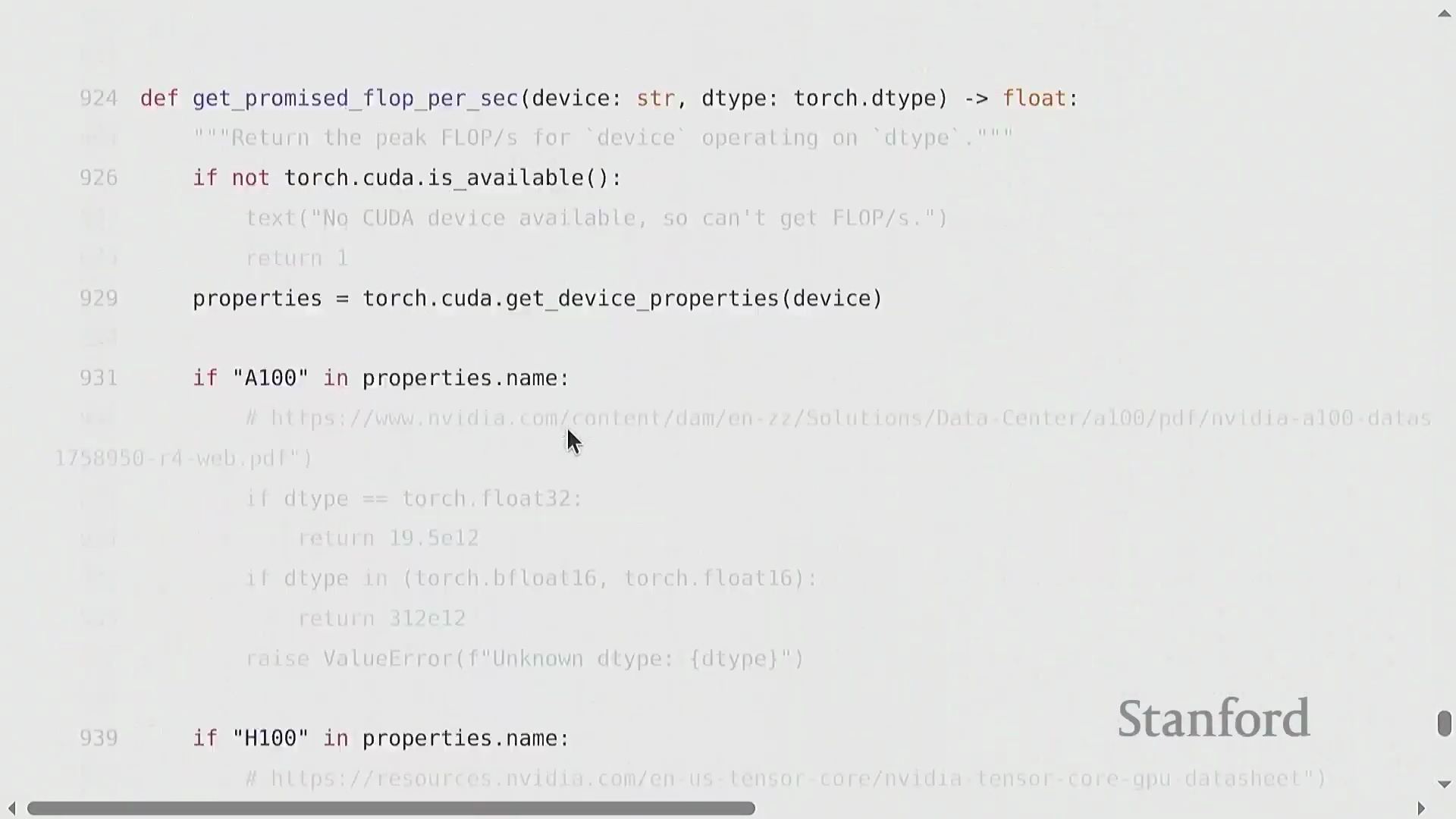
硬件现实:精度、峰值规格与稀疏性
硬件的峰值吞吐量规格高度依赖于数值精度(Numerical Precision) 与工作负载结构。以 NVIDIA A100 为例,其峰值算力约为 312 TFLOP/s,而 H100 的宣传峰值则高达约 1979 TFLOP/s。然而,H100 的这一峰值数据基于 2:4 结构化稀疏性(Structured Sparsity) 假设(即每四个连续元素中恰好有两个为零)。该稀疏模式在标准稠密(Dense) 模型训练中极少被有效利用。对于常规稠密工作负载,其实际可达峰值通常仅为宣传值的一半左右(约 989 TFLOP/s)。更为关键的是,相较于 BF16 或 FP16,使用 FP32(Single Precision) 时 GPU 的算力会骤降数个数量级。现代 AI 加速器(AI Accelerators) 已针对低精度数学运算进行了深度优化,采用 FP8 格式能够进一步释放更高的吞吐量。务必仔细查阅硬件规格表以确认各精度模式下的算力表现,因为现代 AI 芯片在设计上已有意降低了 FP32 的性能优先级。

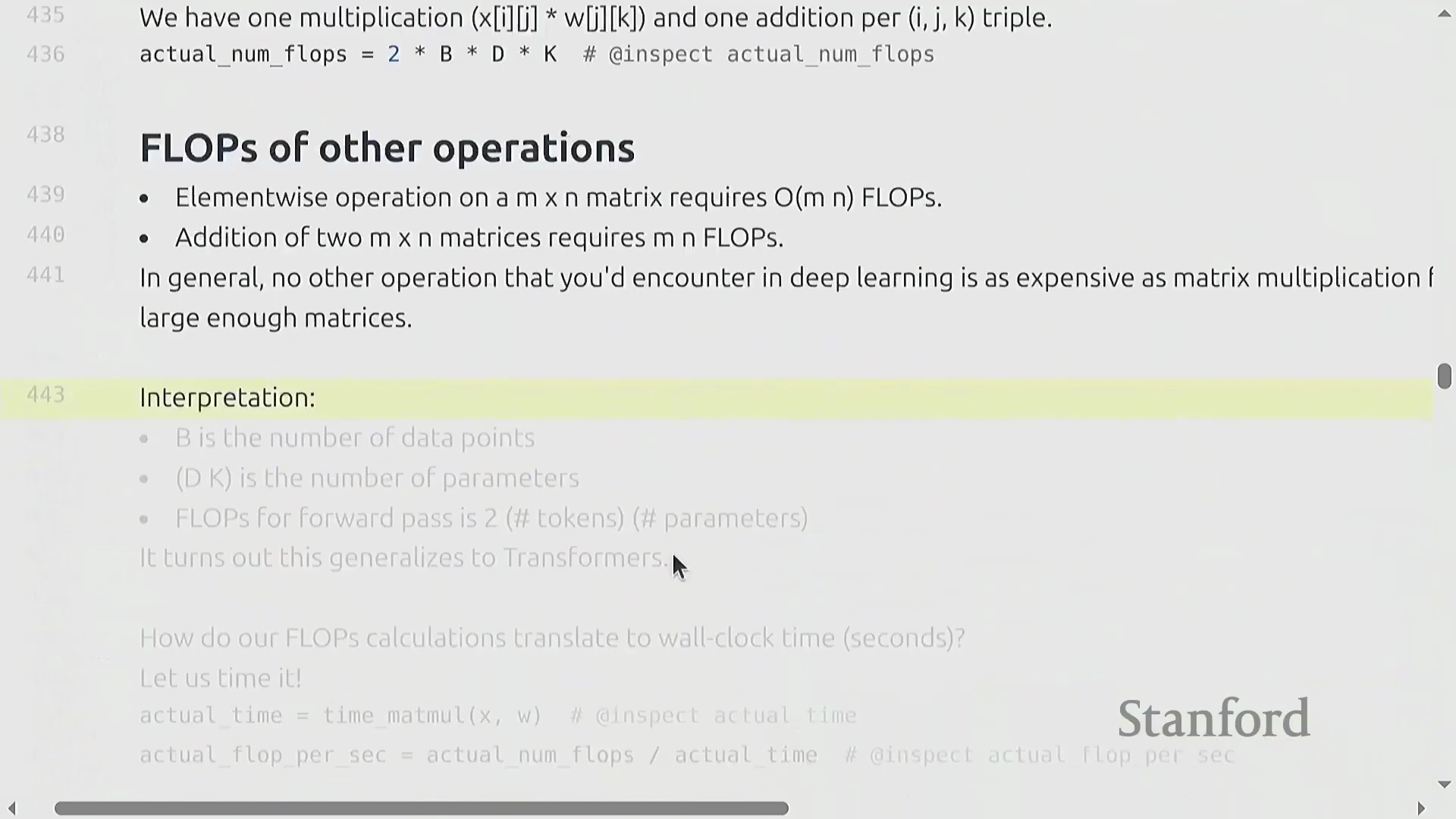
计算核算与矩阵乘法的主导地位
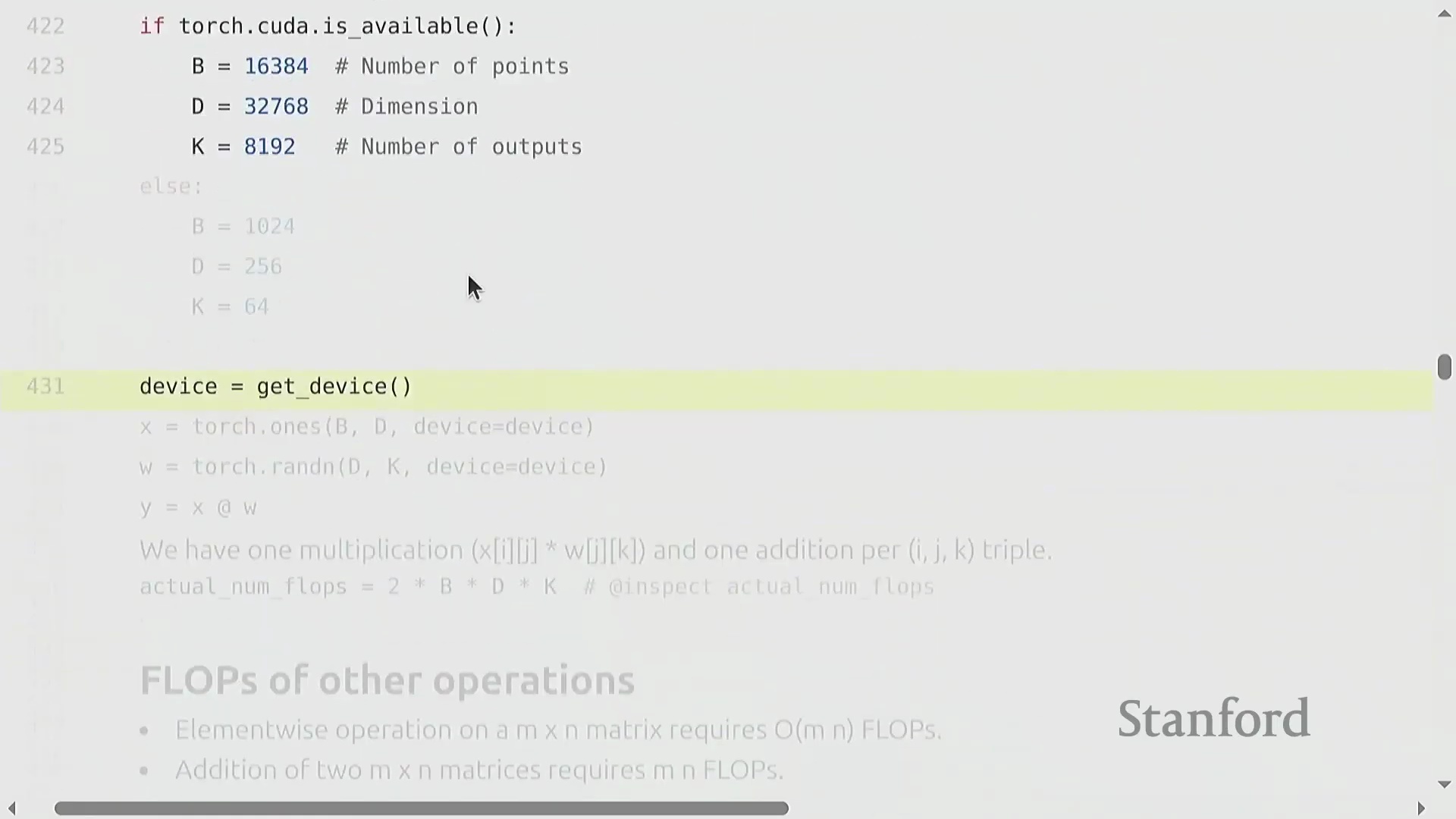
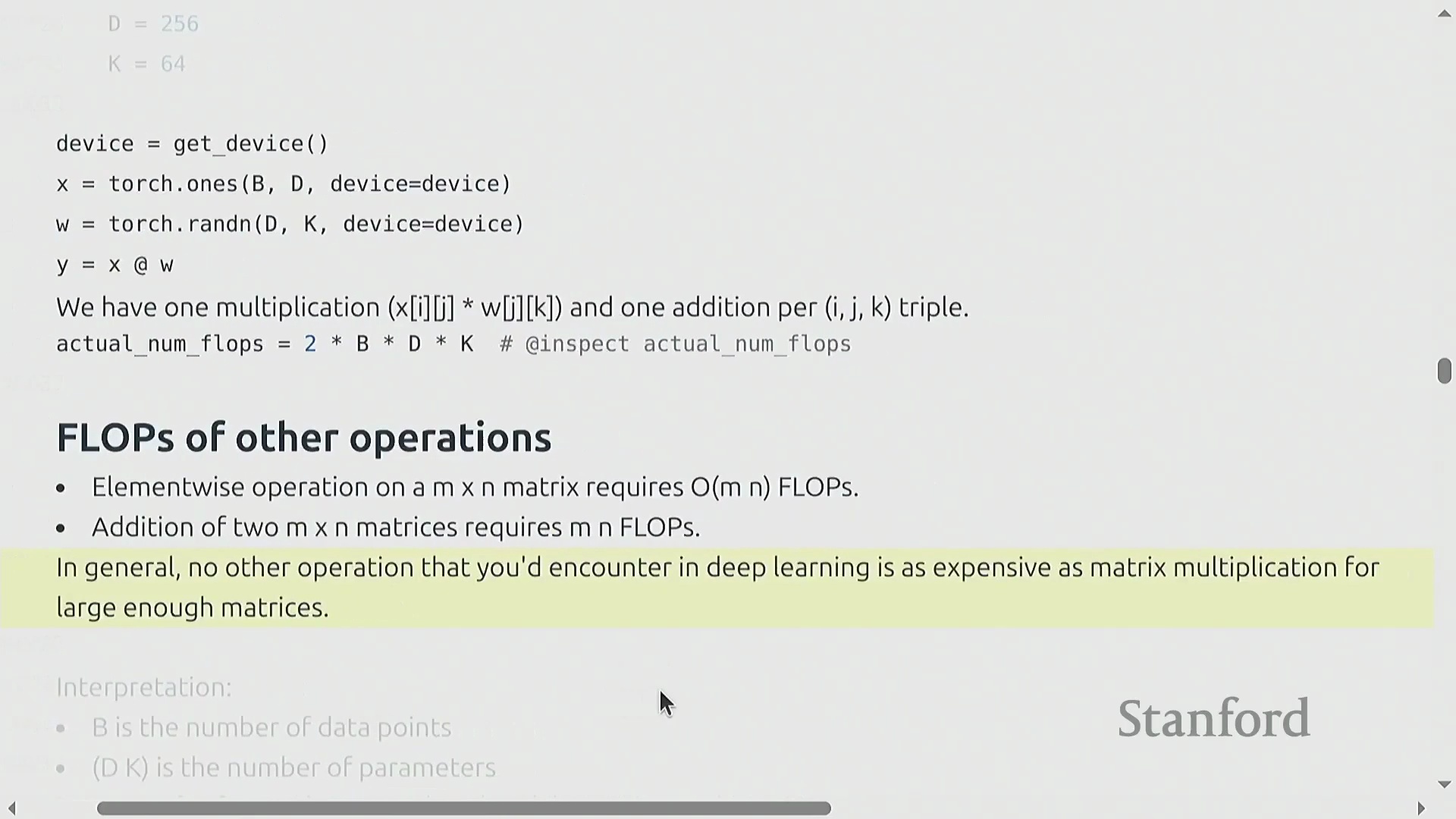
一旦明确主导计算的操作——矩阵乘法(Matrix Multiplication),进行粗略的算力估算(即“餐巾纸数学”(Napkin Math))便十分直接。以一个简单的线性层(Linear Layer) 为例,其通过 (D, K) 的权重矩阵(Weight Matrix) 对 (B, D) 的输入张量(Input Tensor) 进行映射。生成每个输出元素需执行一次乘法与一次加法,因此总计算成本恰好为 2 × B × D × K 次 FLOPs。当张量规模足够大时,该矩阵乘法的计算量将远超逐元素操作(Element-wise Operations)、归一化(Normalization) 或激活函数(Activation Functions) 所带来的线性计算开销。因此,在评估训练效率的粗略估算中,核心焦点在于统计前向传播(Forward Pass) 与反向传播(Backward Pass) 过程中的矩阵乘法次数。尽管在矩阵极小或批次大小(Batch Size) 极小时,其他操作的影响不可忽略,但在现代深度学习工作负载(Deep Learning Workloads) 中,矩阵乘法(matmul) 始终主导并决定了整体算力消耗的上限。







矩阵乘法的主导地位与 FLOP 估算
矩阵乘法(Matrix Multiplication)从根本上主导了深度学习(Deep Learning)的计算成本。尽管硬件供应商和底层库(Libraries)采用了高度优化的算法及针对特定张量形状(Tensor Shapes)的专门优化,但粗略估算公式 2 × B × D × K 依然是“餐巾纸数学(Napkin Math)”的黄金标准。在机器学习语境中,B 代表批次中的样本数(或词元数量),D × K 则代表权重矩阵(Weight Matrix)的参数数量。因此,前向传播(Forward Pass)的计算需求大致正比于 2 × 词元量 × 参数量。值得注意的是,只要序列长度(Sequence Length)不过于庞大,这种线性关系便能很好地泛化至 Transformer 等复杂架构。





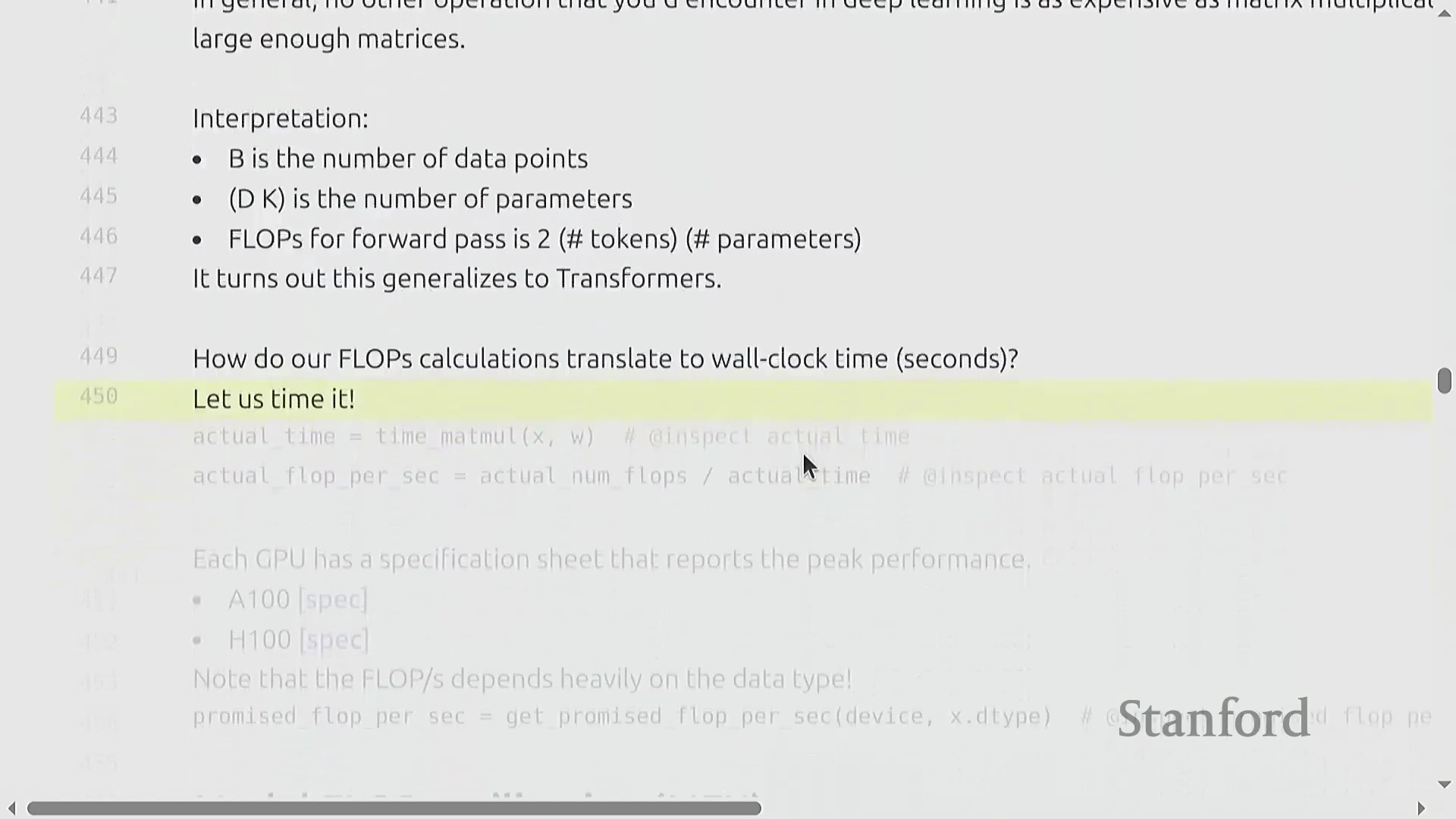
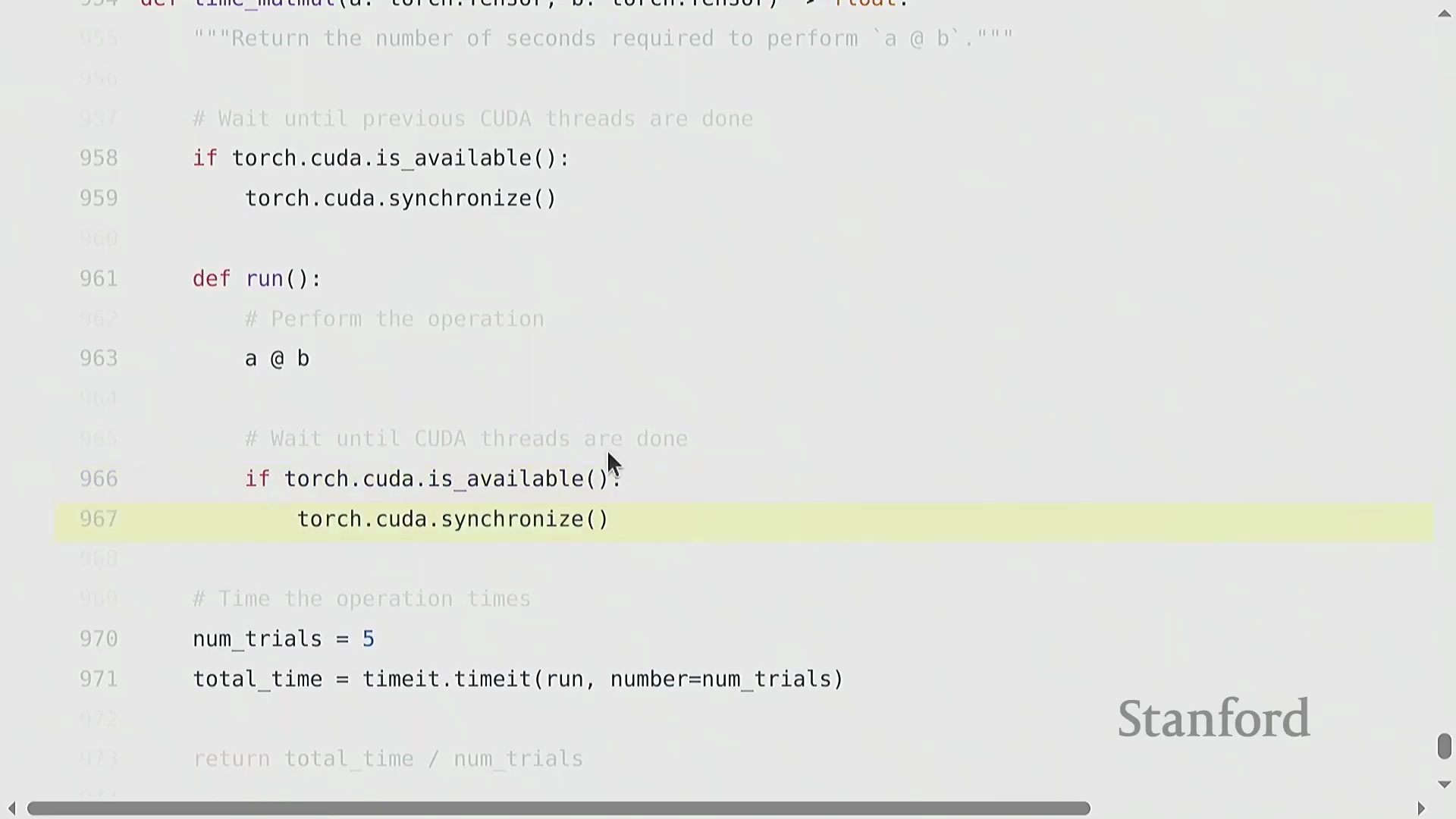
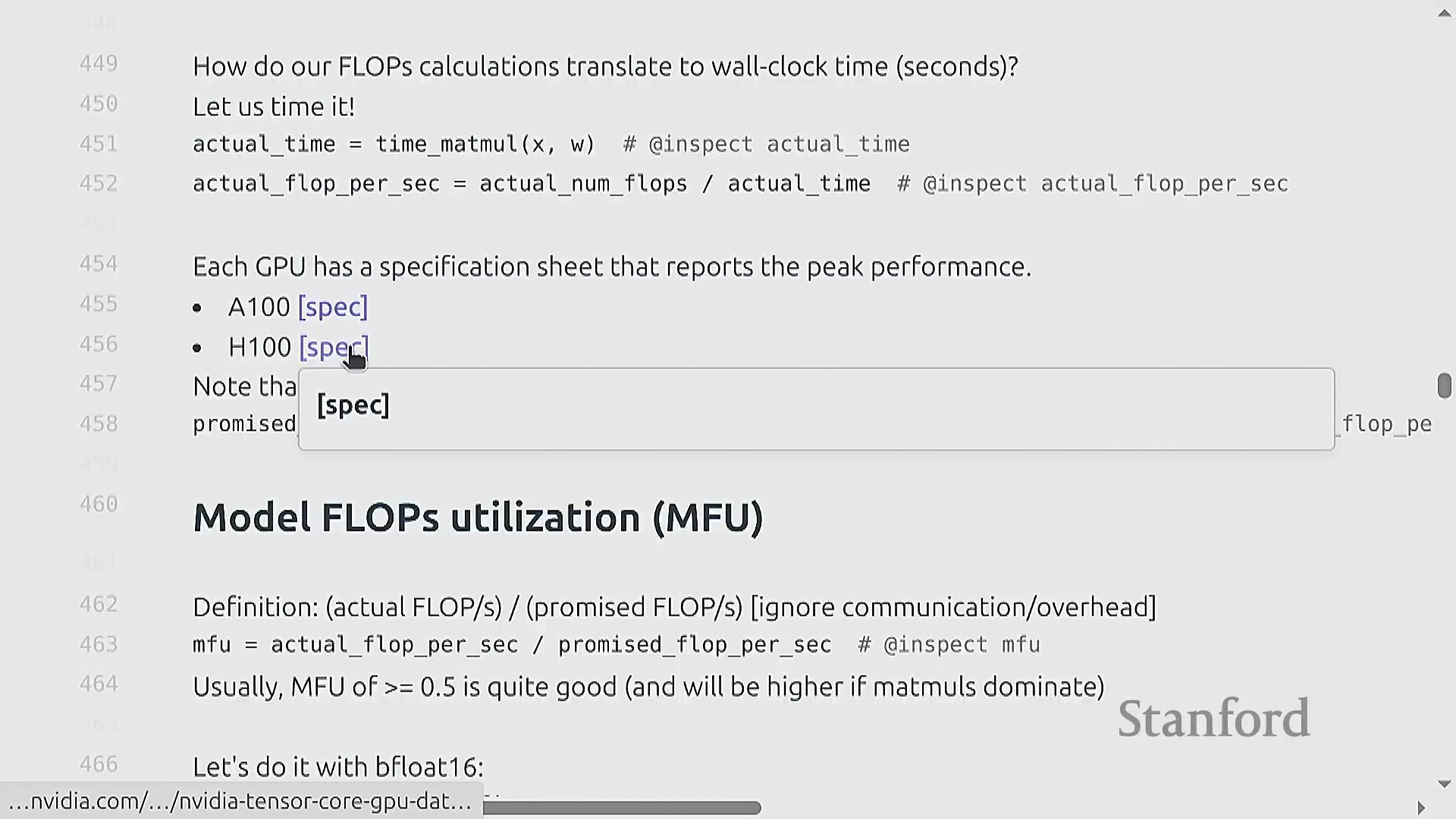
将计算量转化为实际运行时间
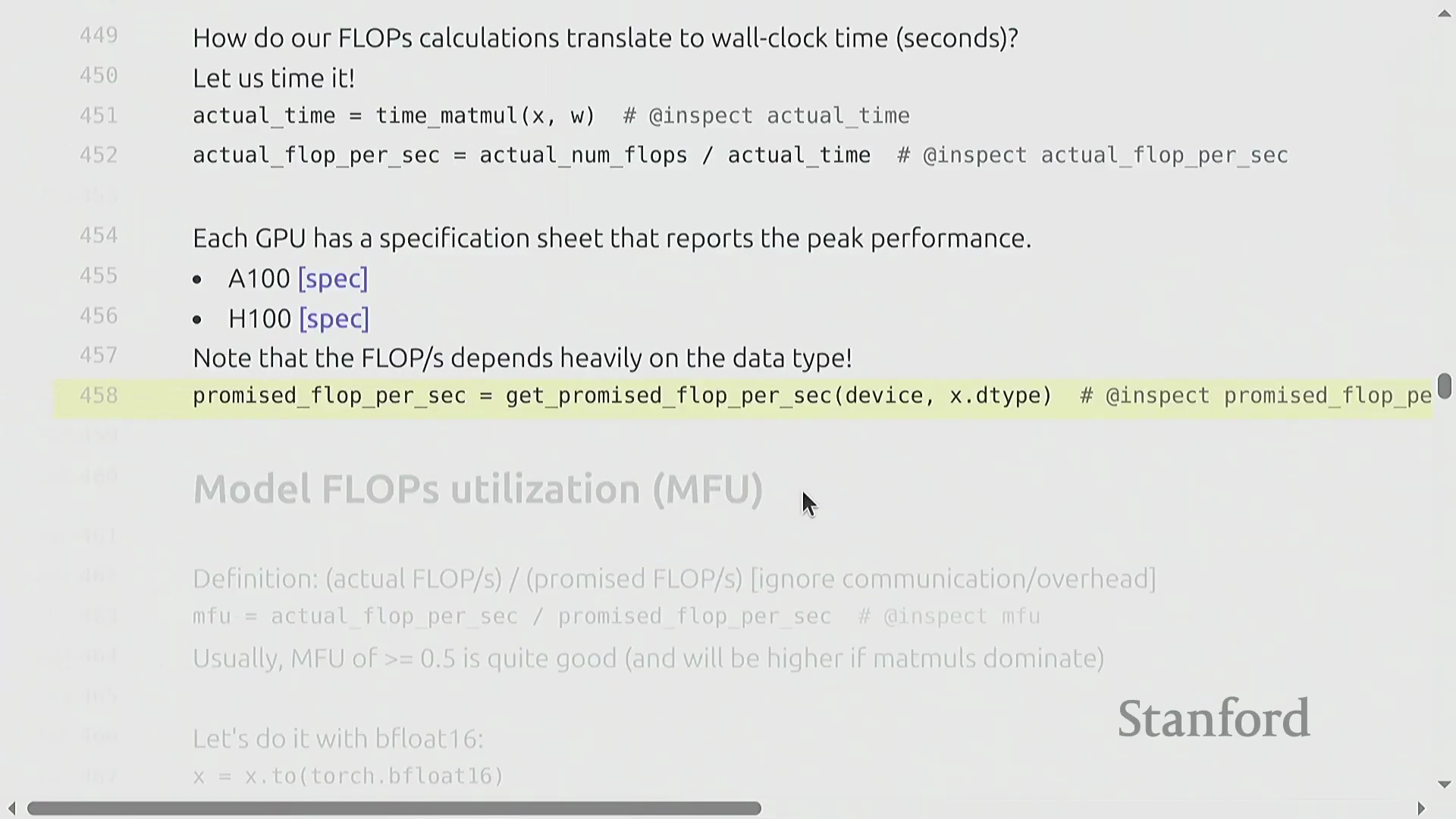
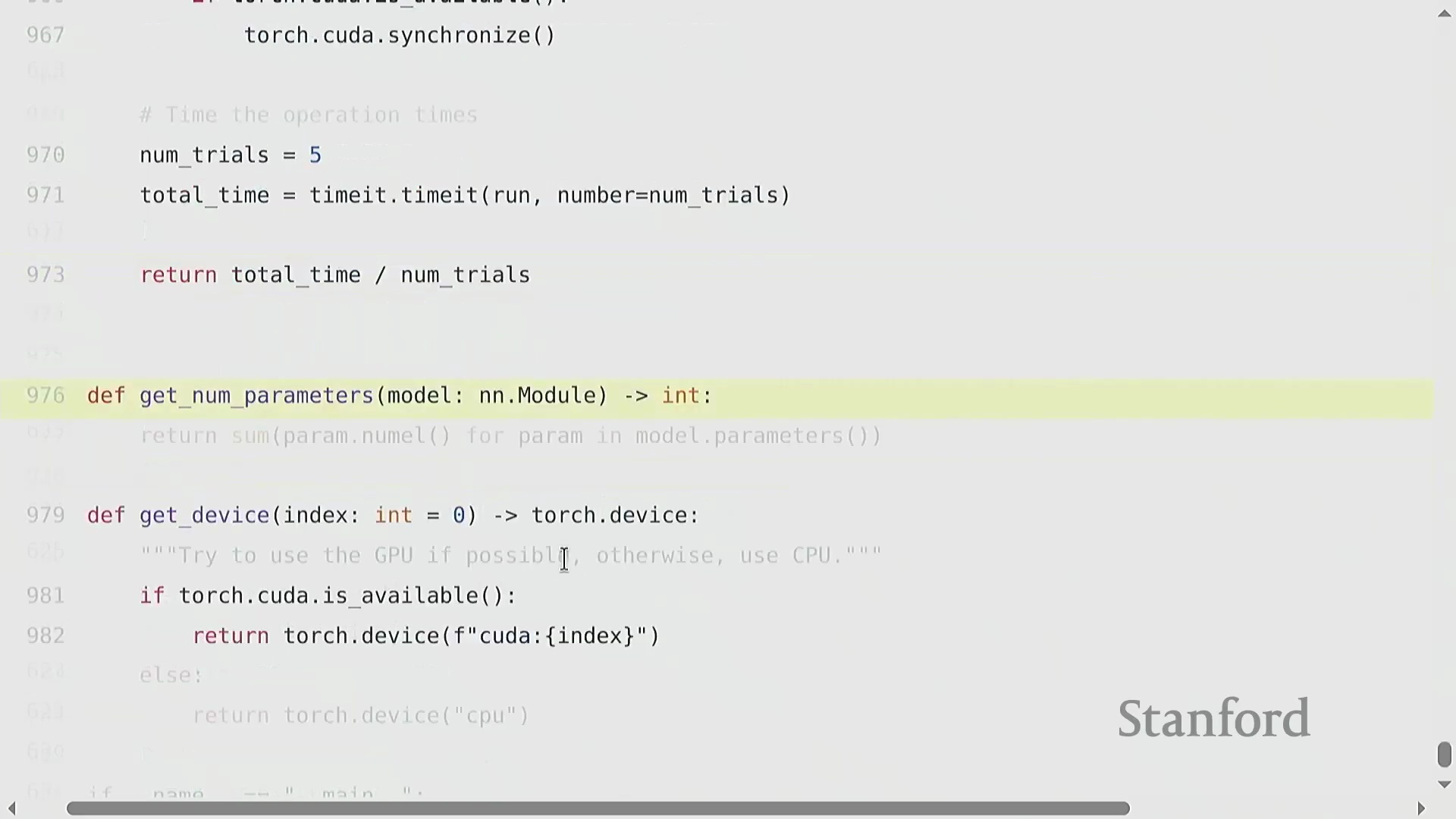
为将理论浮点运算次数(FLOPs)与现实世界的训练时长关联起来,实测基准测试(Benchmarking)至关重要。通过对特定矩阵乘法操作进行多次计时(Timing),可推导出以 FLOP/s 为单位的实际吞吐量(Throughput)。将观测吞吐量与厂商宣传的规格说明书(Specifications)进行对比,即可揭示理论峰值性能(Peak Performance)与实际执行效率之间的差距。该测量结果构成了现代 AI 工程中一项关键效率指标的基础。


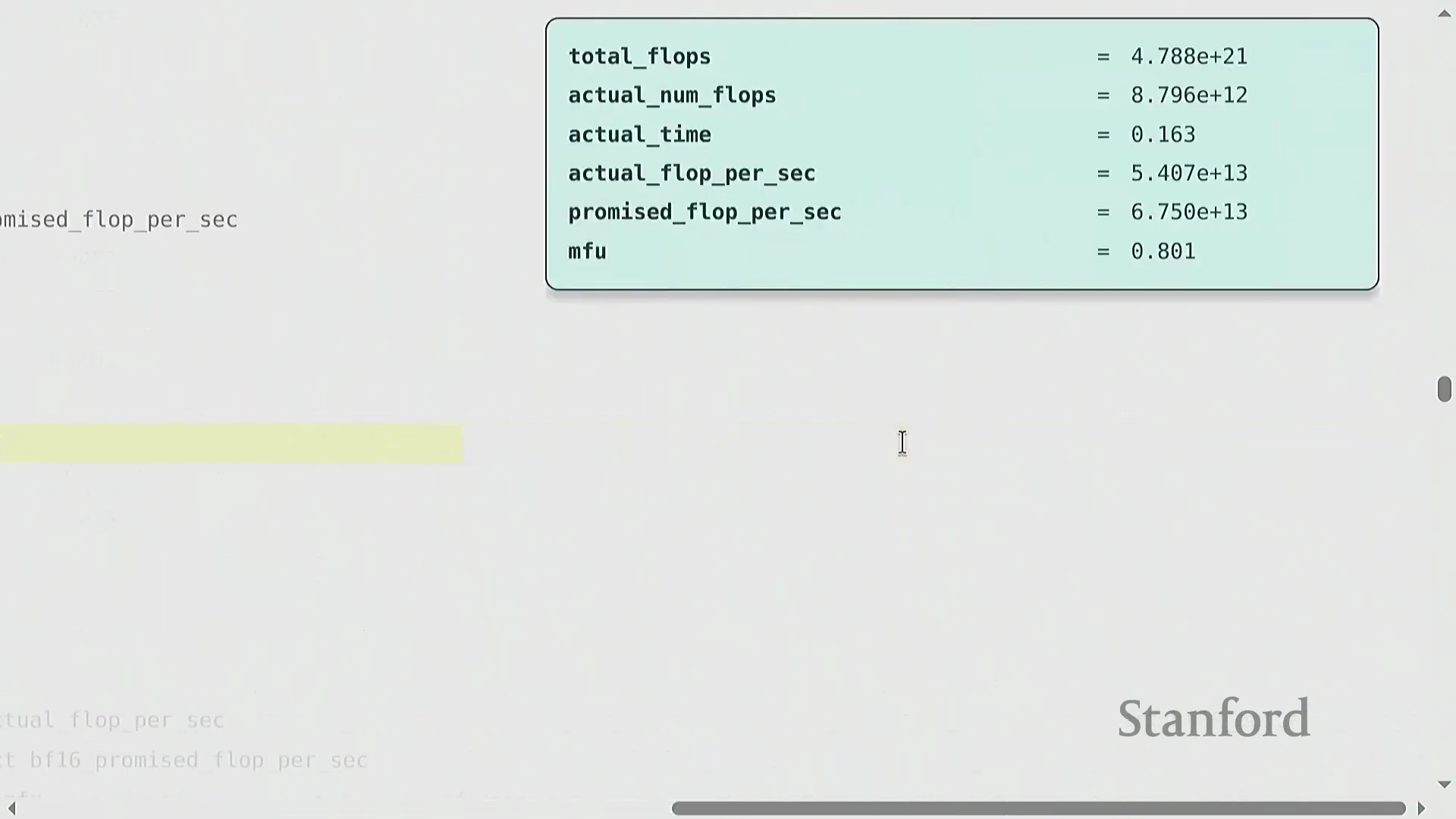
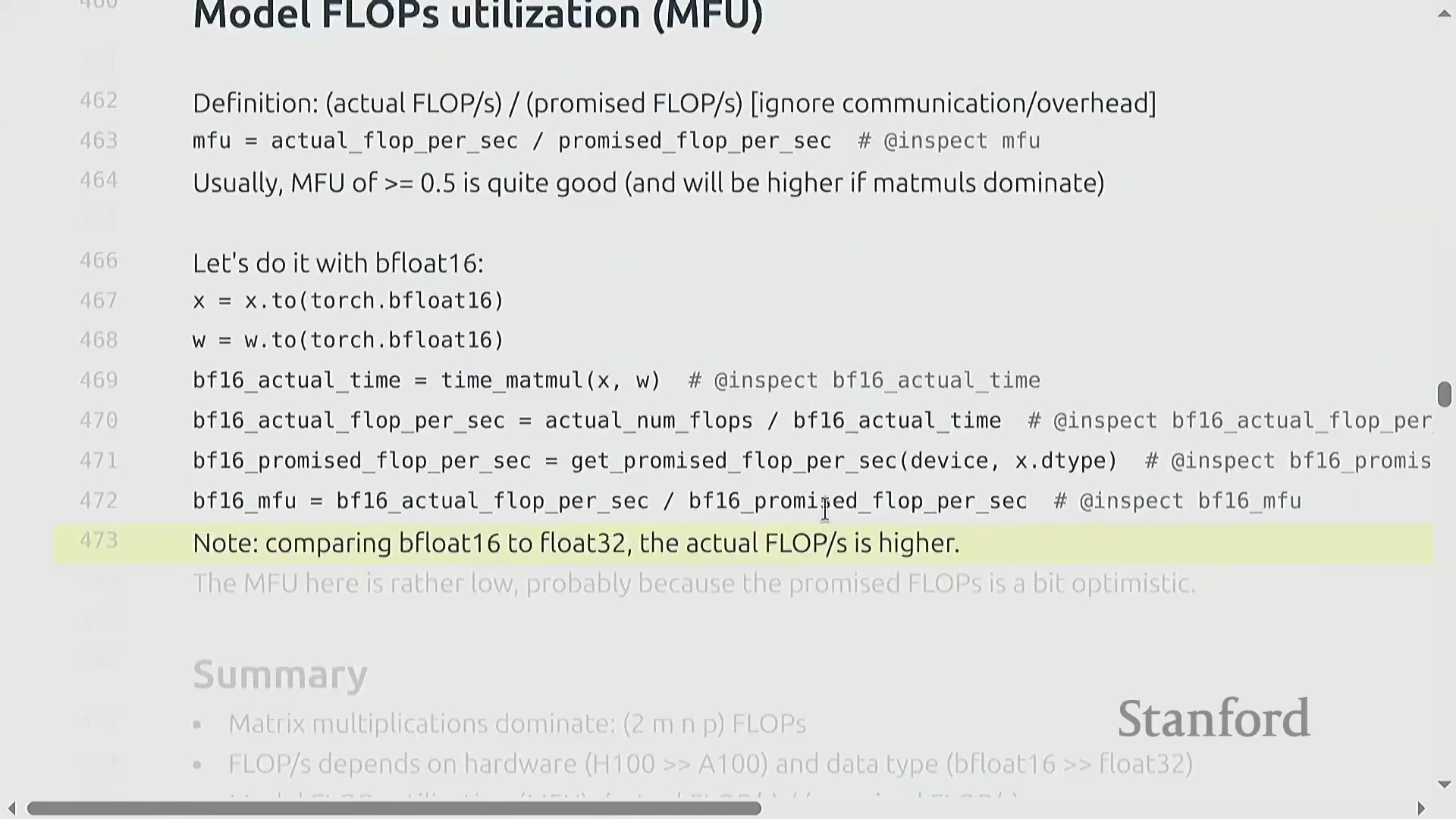
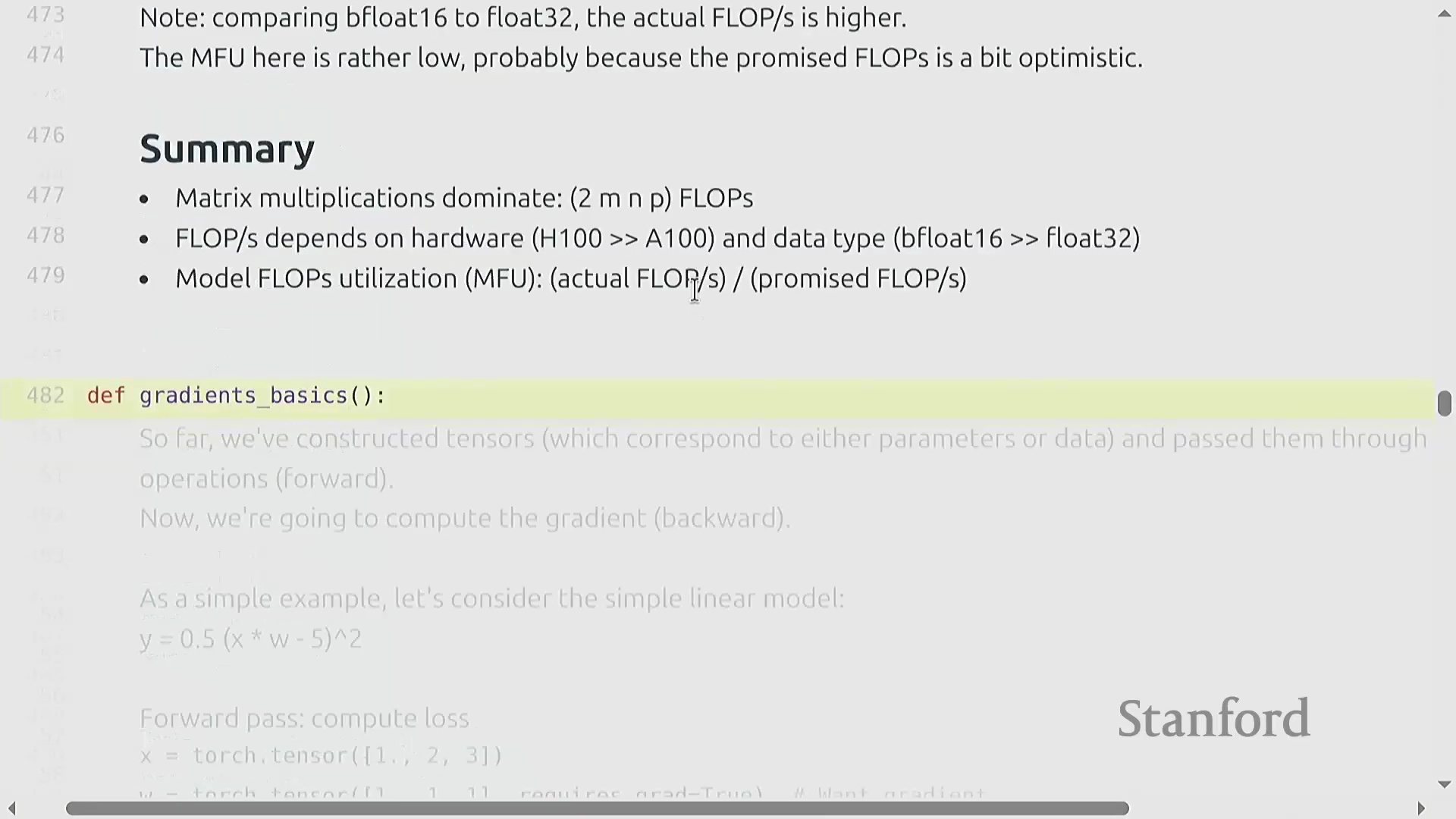
模型 FLOP 利用率(MFU)
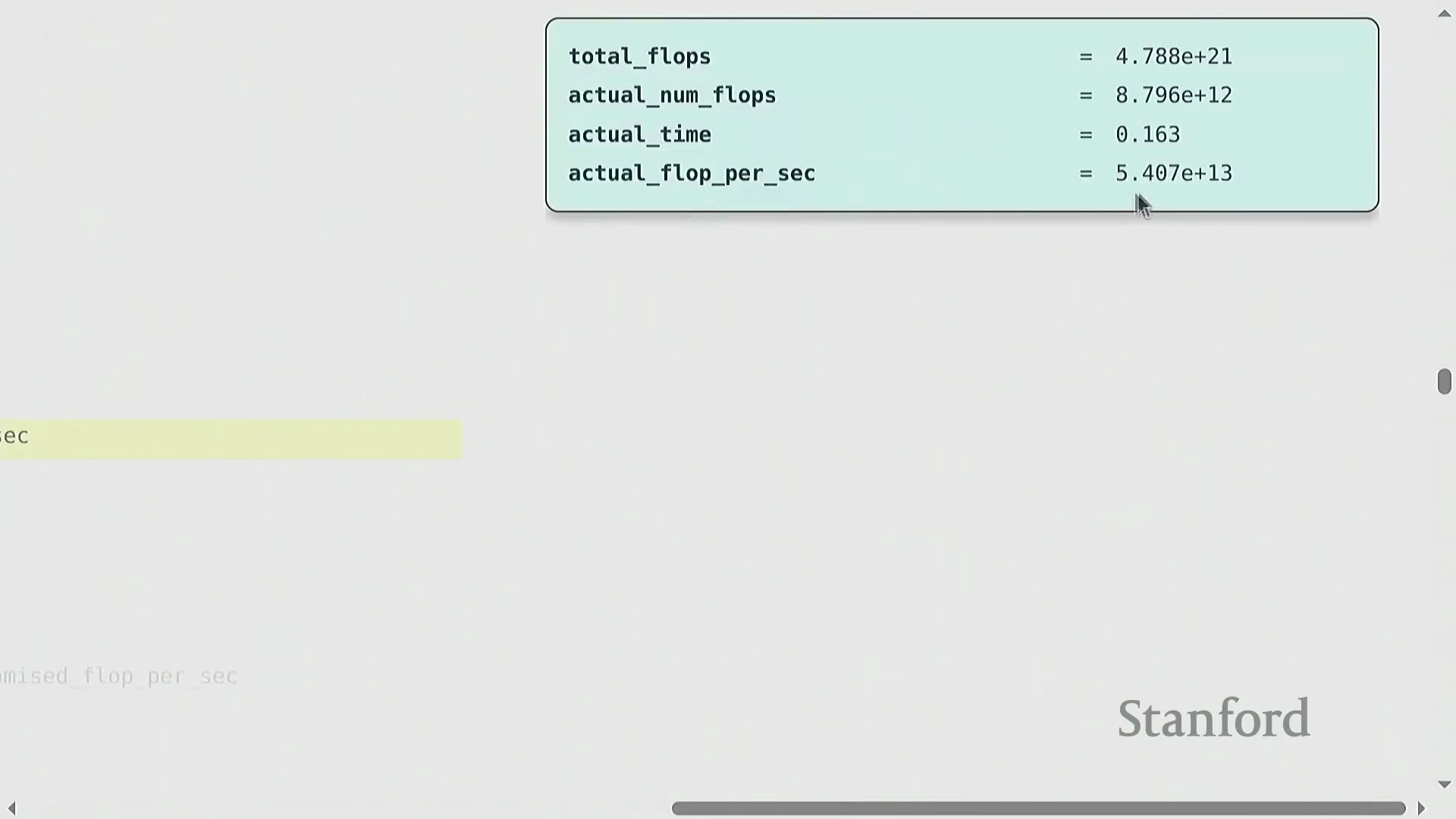
模型浮点运算利用率(Model FLOP Utilization, MFU)量化了硬件的有效利用程度。其计算公式为 (实际有效 FLOPs / 执行时间) / 理论峰值 FLOP/s。通常情况下,MFU 超过 0.5 即视为表现优异,若能达到 0.8 则极为出色。由于不可避免的通信开销(Communication Overhead)、内存数据搬运(Memory Movement)以及非矩阵乘法操作,实际 MFU 理论上无法达到 100%。关键在于,MFU 衡量的是模型计算复杂度(Model Complexity)而非原始硬件活动状态;它仅统计模型在数学上必需的操作,从而确保开发者不会因采用缓存(Caching)或重计算(Rematerialization)等能减少实际工作量的优化技术,而在效率评估中处于劣势。



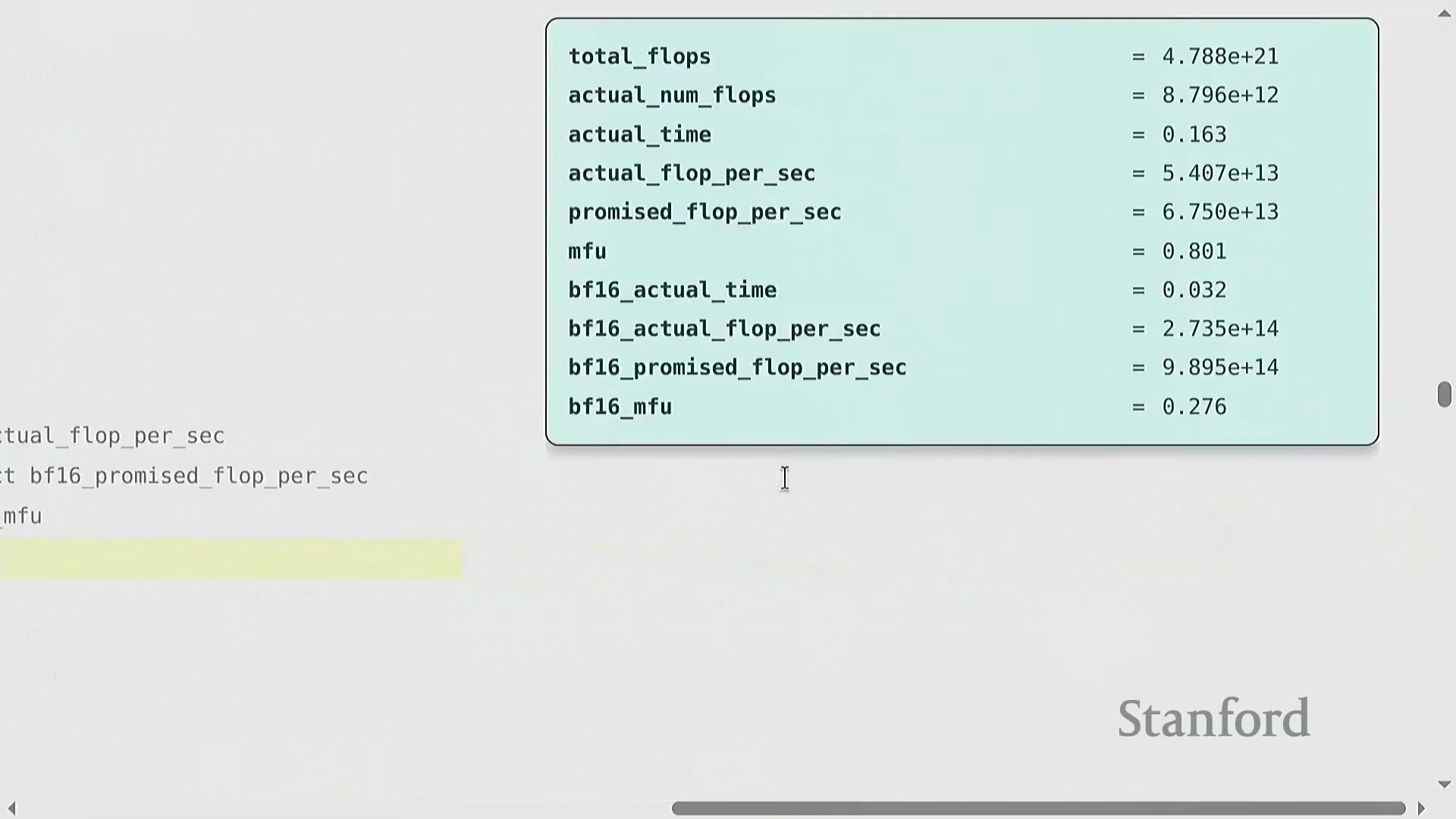
精度权衡与实测基准测试
从 FP32(Single Precision)切换至 BF16(Brain Floating Point)虽会大幅缩短实际运行时间(例如从 0.16 秒降至 0.03 秒),但测得的 MFU 却可能反常地偏低。这是因为硬件厂商针对低精度模式宣传的峰值 FLOP/s 过于激进,实际代码往往难以企及。核心教训很明确:切勿盲目迷信营销规格表。务必针对具体工作负载(Workload)进行基准测试,因为内存带宽(Memory Bandwidth)、算子内核(Kernel)开销及特定精度的计算瓶颈共同决定了实际性能。尽管 PyTorch 等现代框架(尤其是结合 torch.compile 使用时)能够自动将计算操作路由(Routing)至张量核心(Tensor Cores)等专用硬件,但实测验证依然是不可或缺的底线。


计算核算总结与反向传播
总而言之,矩阵乘法(Matrix Multiplication)决定了核心计算成本,其规模大致按 2 × 批次大小(Batch) × 特征维度(Features) 进行缩放。硬件吞吐量高度依赖于硬件架构代际(Hardware Generations)与数值精度(Numerical Precision),而 MFU 则是衡量工程实现效率的标准指标。然而,完整的模型训练(Model Training)并非仅靠前向传播(Forward Pass)。为构建完整的资源核算(Resource Accounting)视图,我们必须将梯度(Gradients)计算纳入考量,这也标志着本讲将转入对反向传播(Backward Pass)与优化步骤(Optimization Steps)的深入分析。


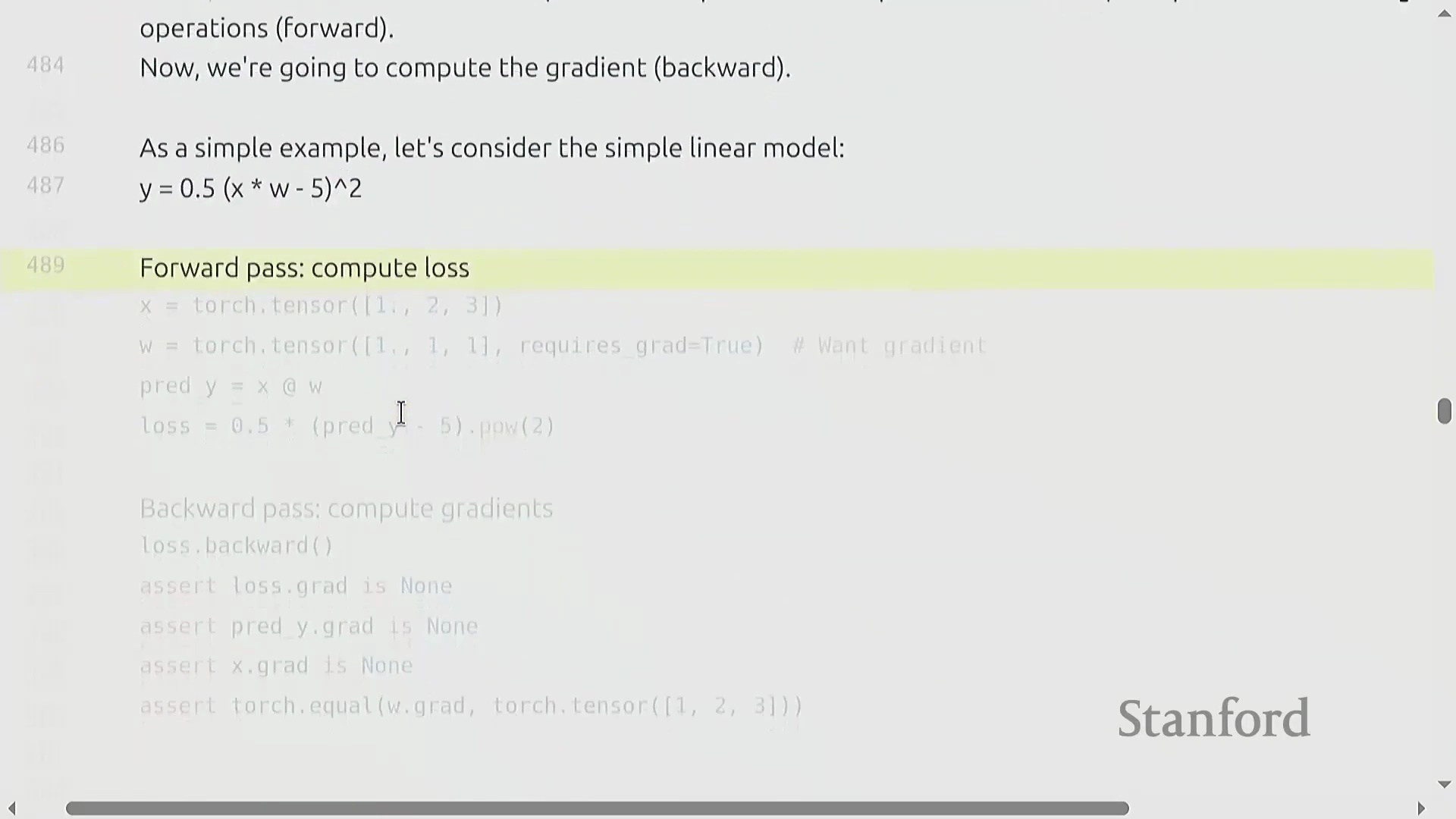
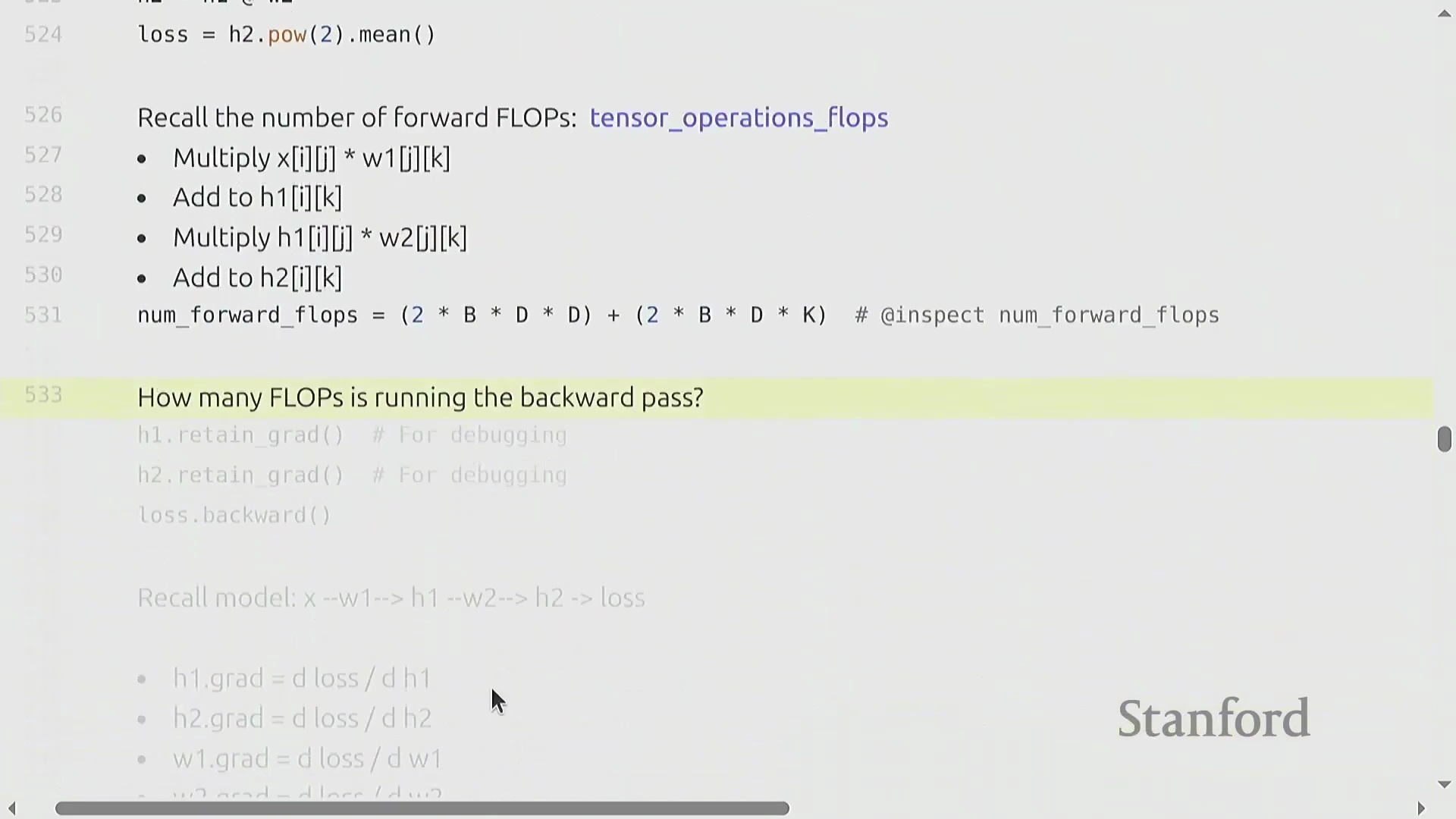
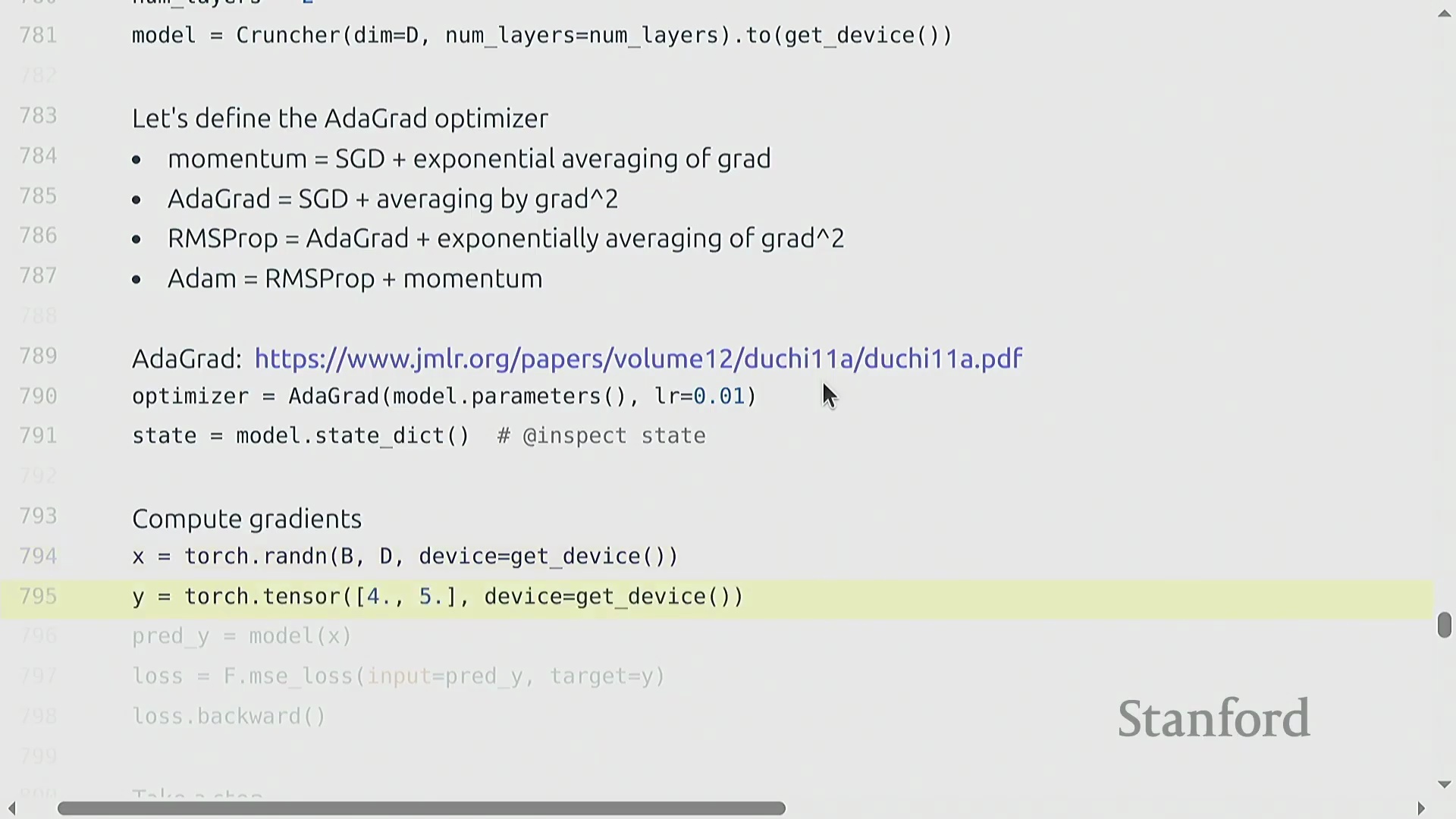
计算梯度与反向传播
虽然前向传播(Forward Pass)和矩阵乘法(Matrix Multiplication)主导了我们对计算量的初步理解,但模型训练从根本上依赖于通过反向传播(Backward Propagation)来计算梯度(Gradients)。以一个包含均方误差(Mean Squared Error, MSE)损失的简单线性模型为例,PyTorch 通过调用 loss.backward() 自动完成该过程,并将计算结果填充至每个张量的 .grad 属性(Attribute)中。核心的工程问题并非如何计算梯度,而是计算梯度在浮点运算次数(FLOP)上的计算开销究竟有多大。

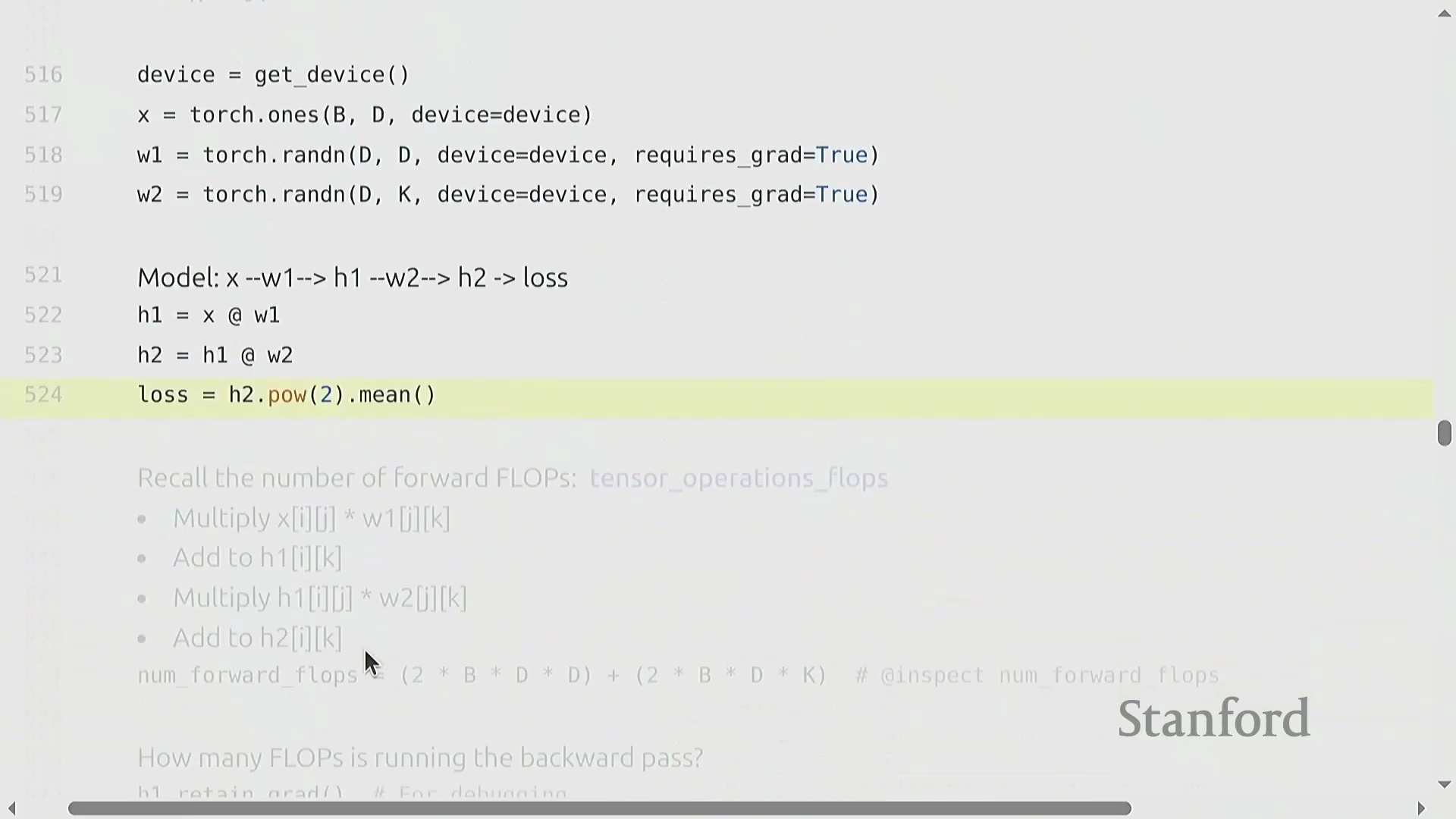
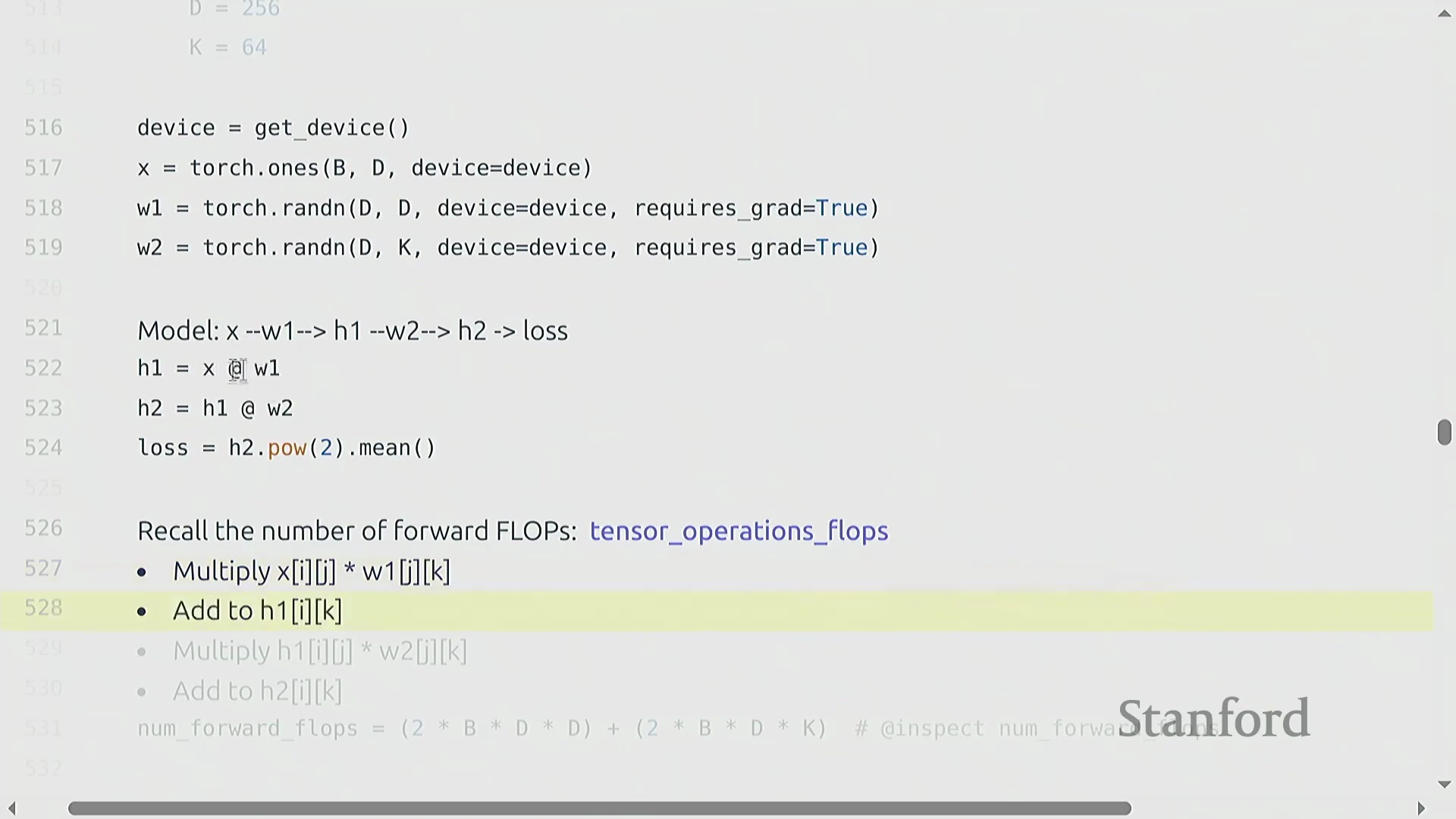
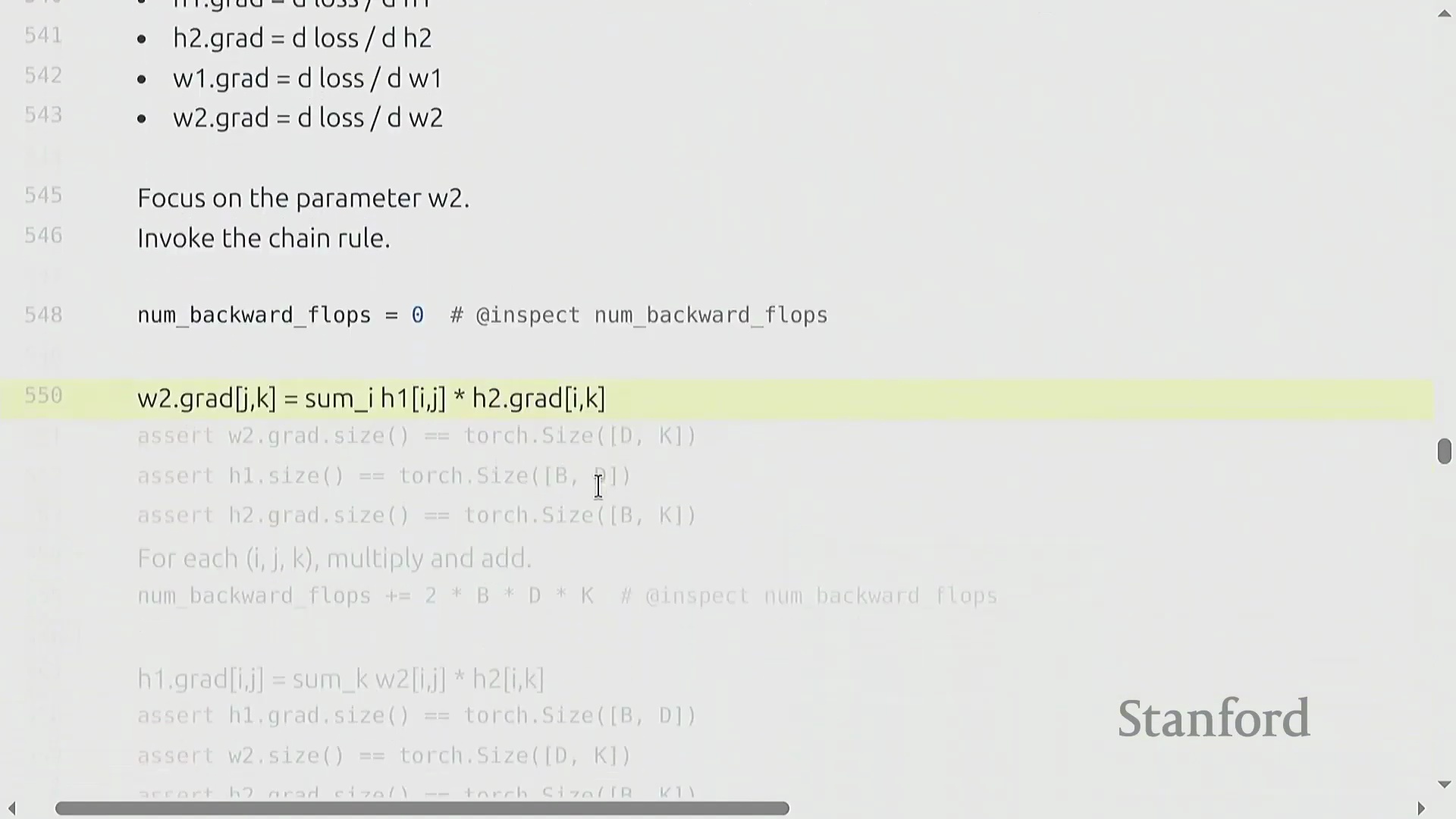
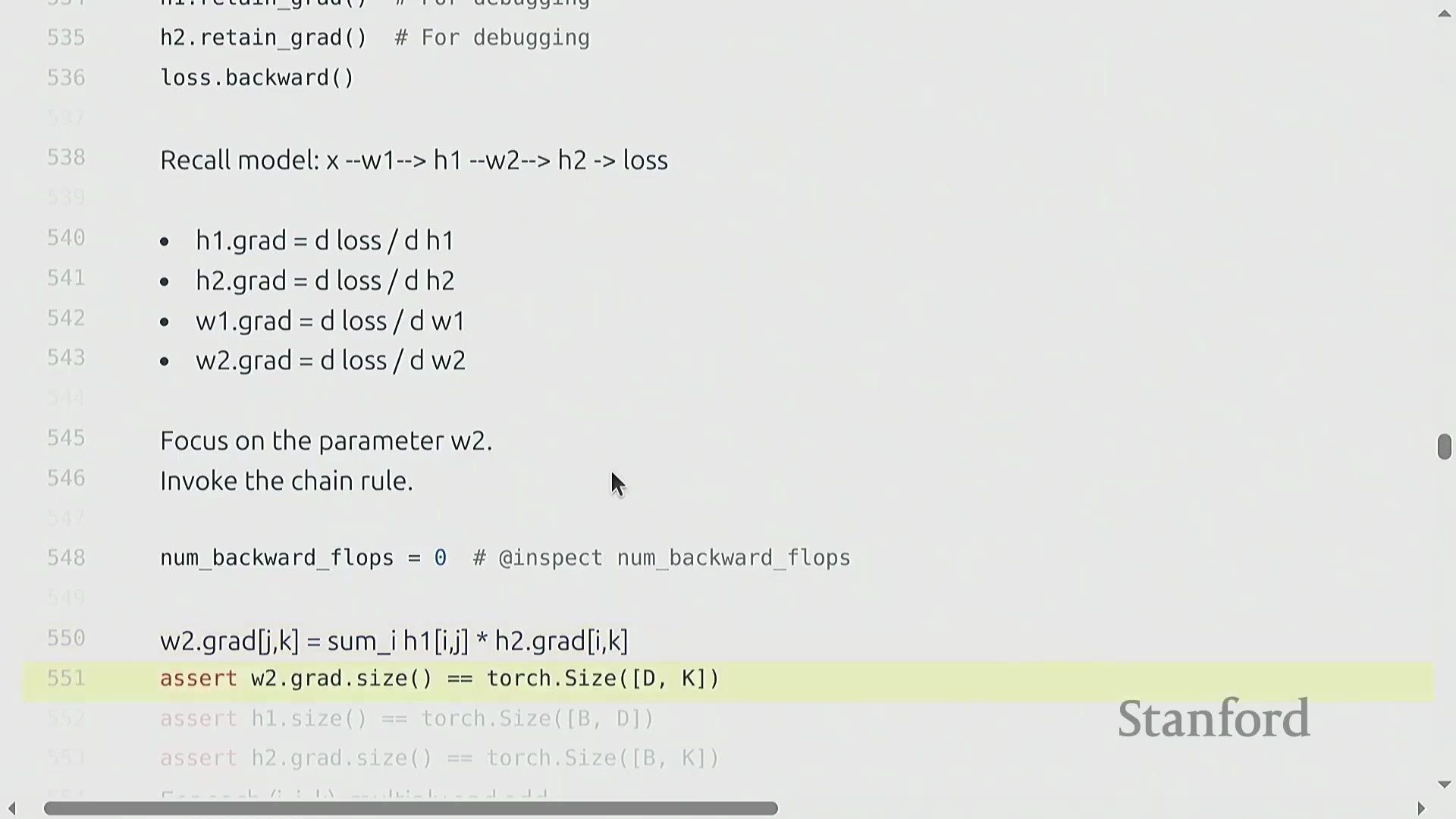
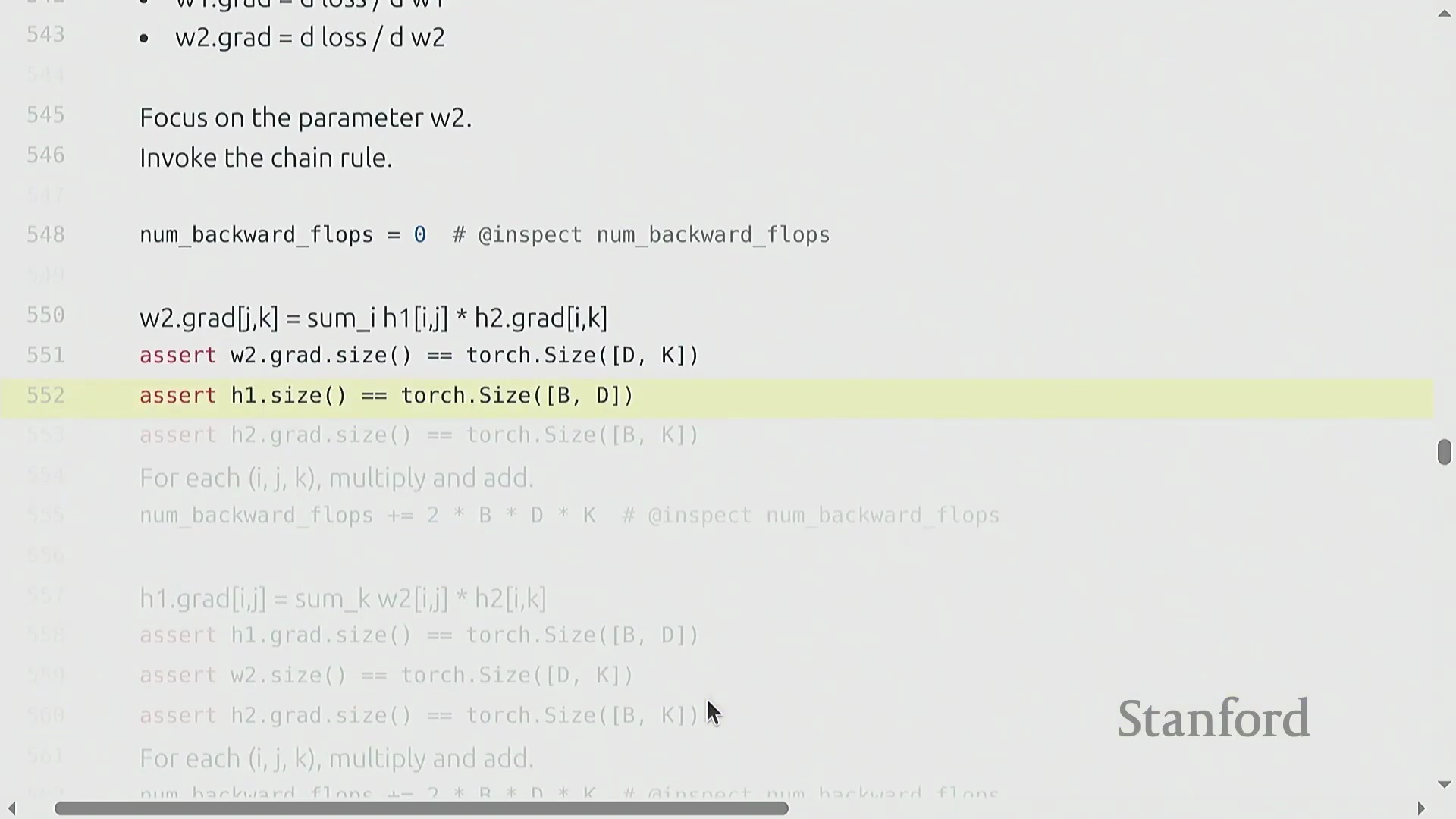
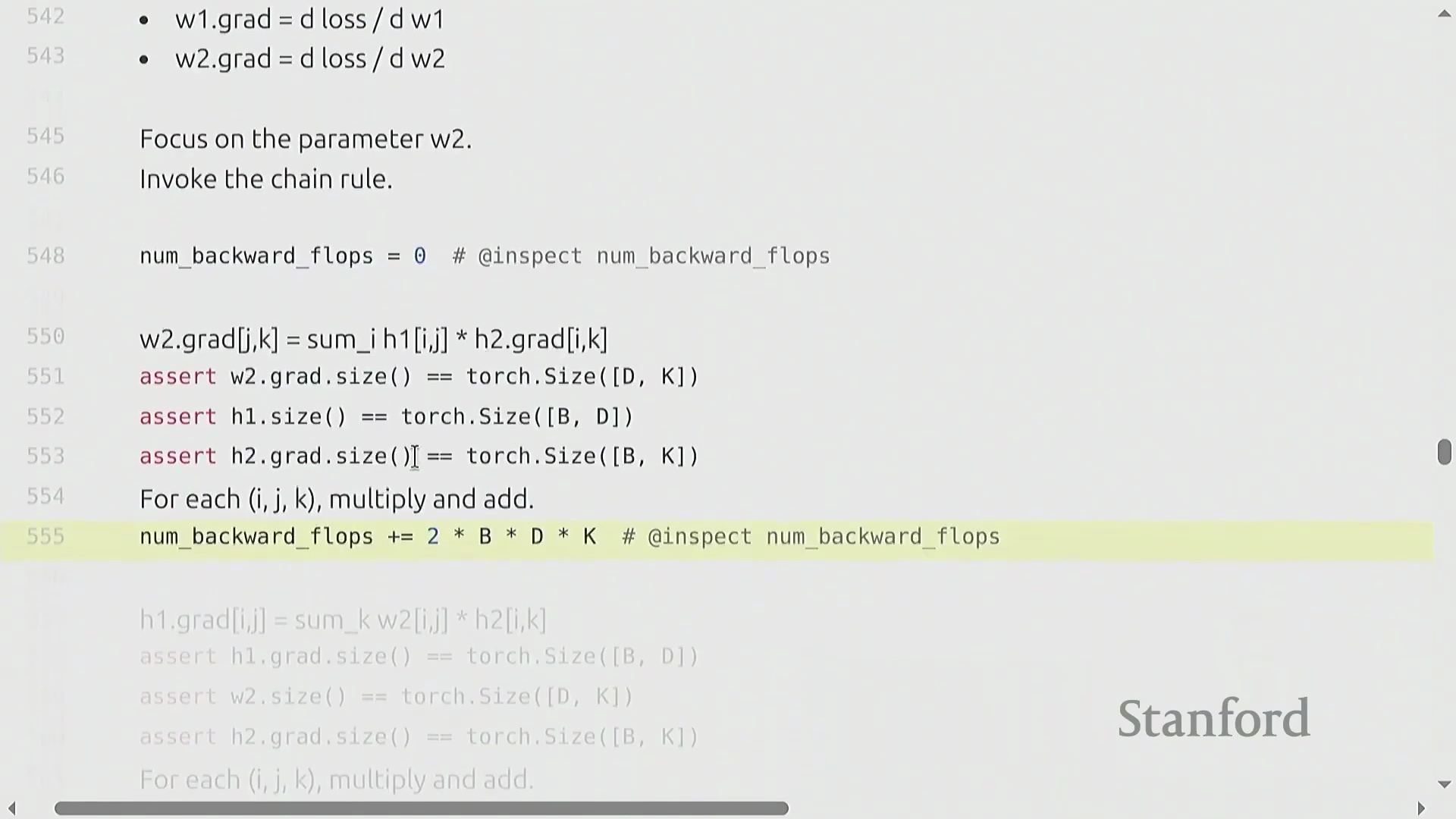
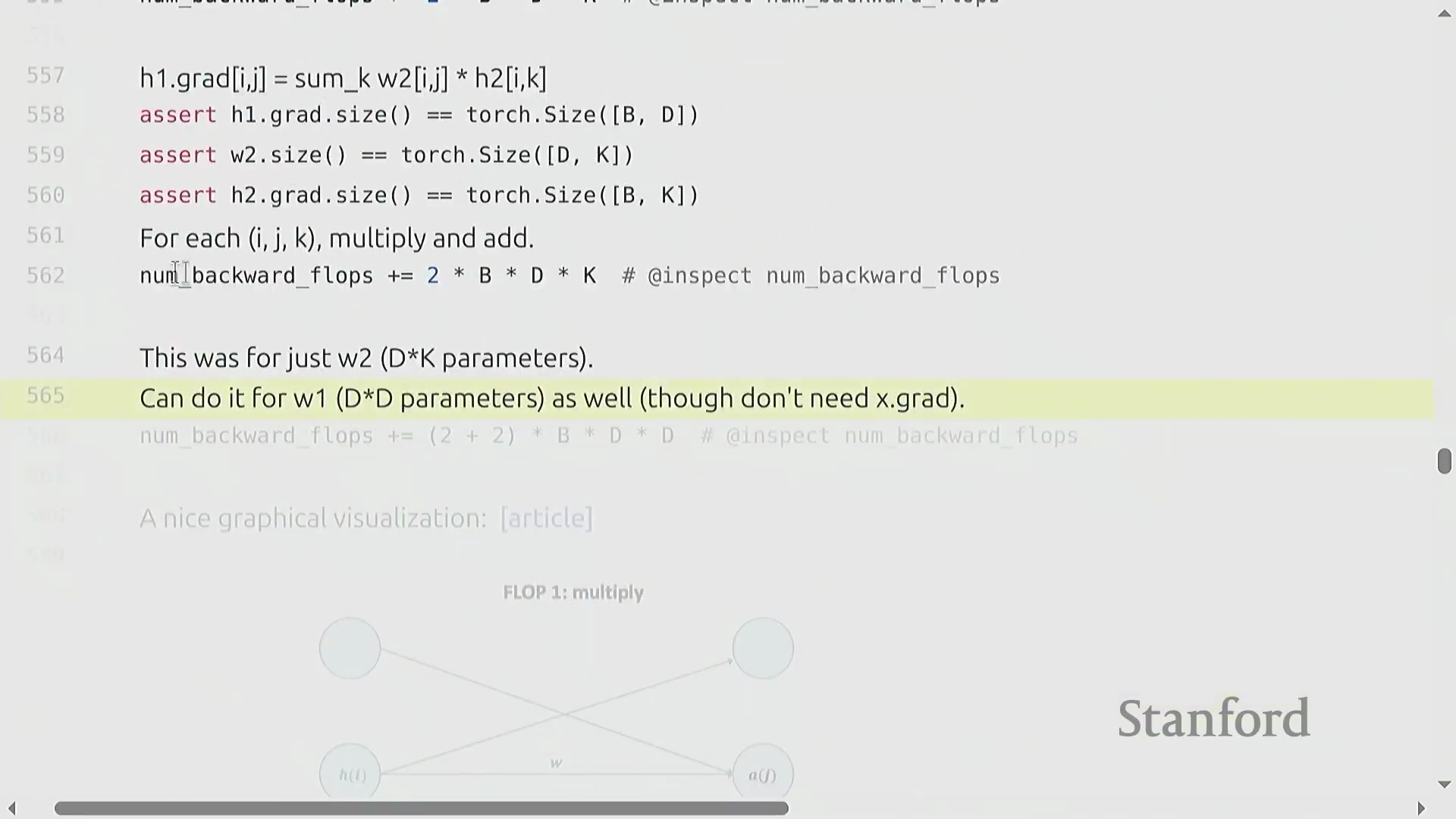
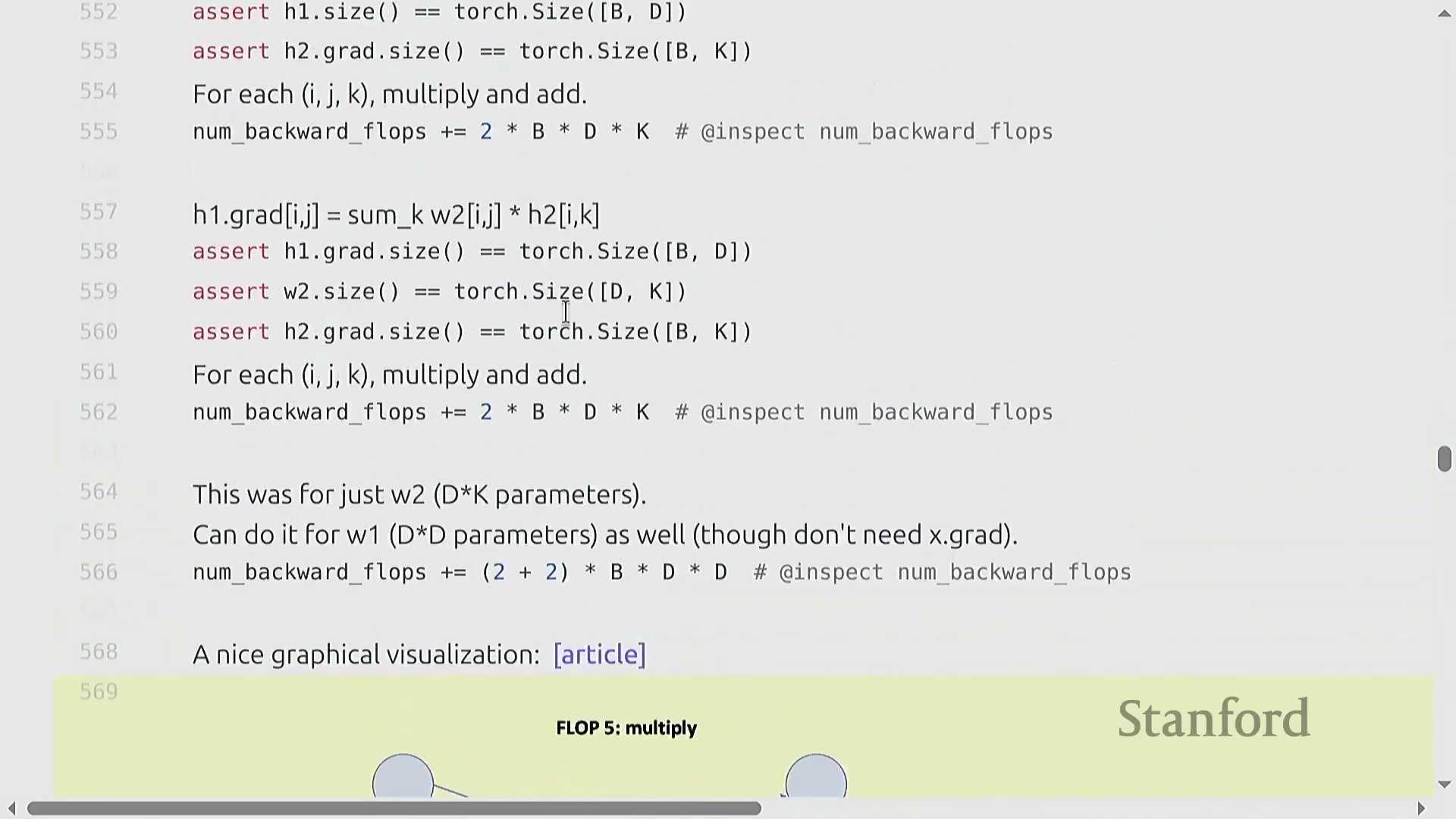
两层网络的 FLOP 核算
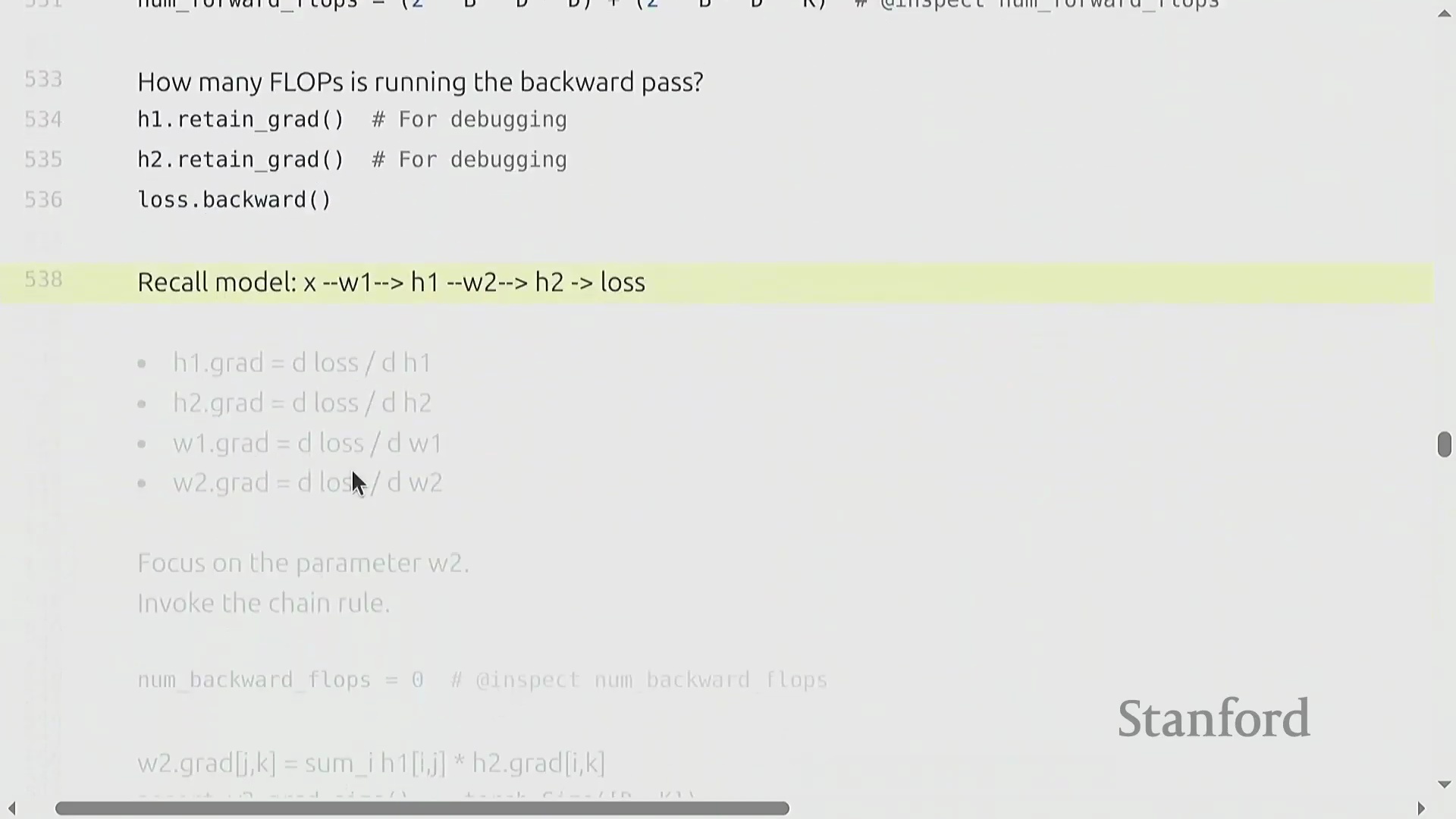
为推导计算成本,我们考虑一个两层线性网络(Two-Layer Linear Network):输入 x (B × D) 经过权重矩阵(Weight Matrix) w1 (D × D) 生成隐藏状态(Hidden State) h1,随后 h1 再经过 w2 (D × K) 生成 h2,并最终计算损失(Loss)。其前向传播的计算成本为 2 × B × D² + 2 × B × D × K 次 FLOPs。在反向传播过程中,我们应用链式法则(Chain Rule)。计算权重梯度 dw2 需要将 h1 与 dh2 相乘,其成本为 2 × B × D × K 次 FLOPs。为继续反向传播,我们还必须计算激活梯度 dh1,这涉及将 w2 与 dh2 相乘,额外产生 2 × B × D × K 次 FLOPs 的开销。因此,仅计算第二层的梯度就需要 4 × B × D × K 次 FLOPs。
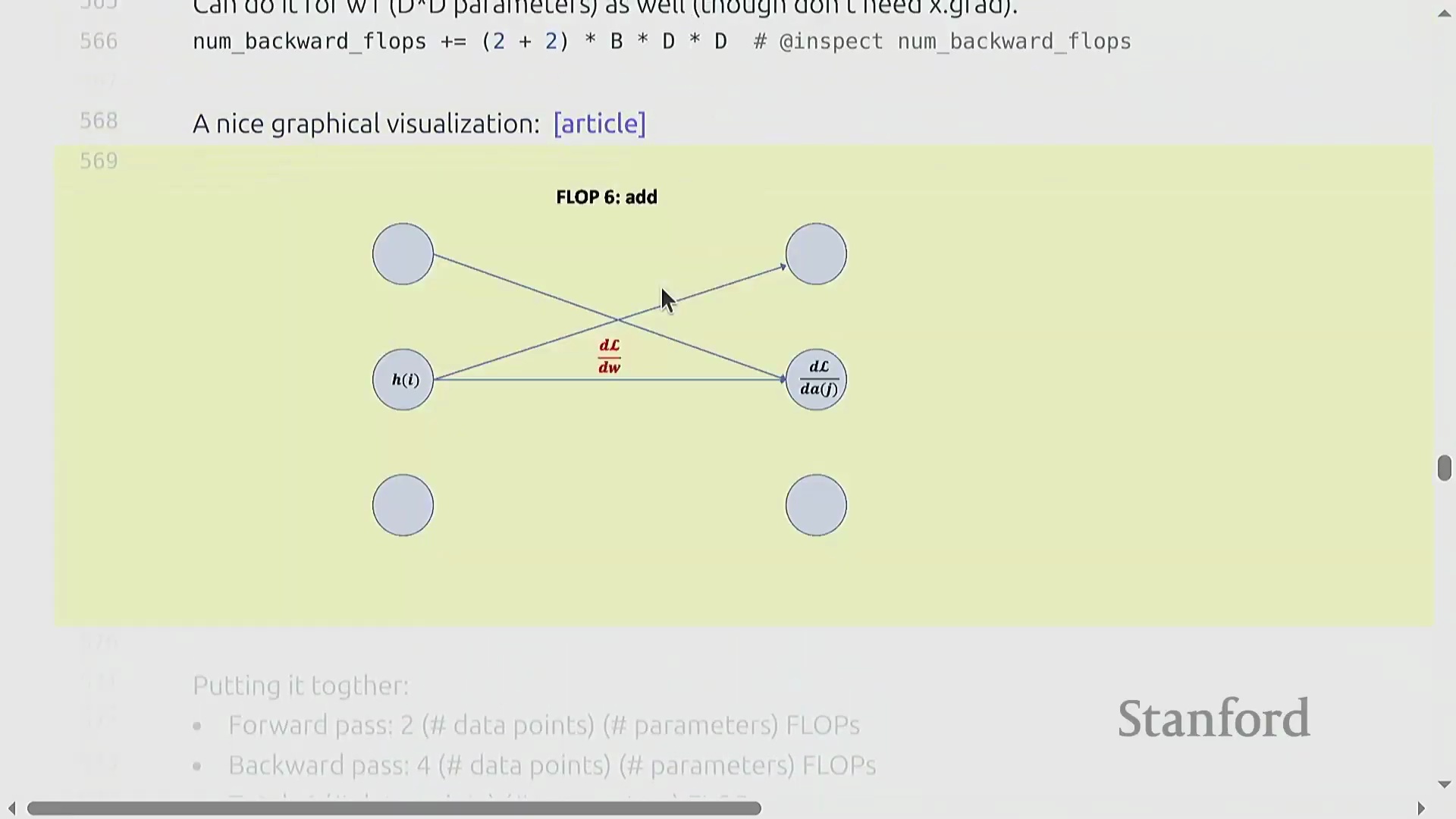
反向传播可视化与 6x 法则
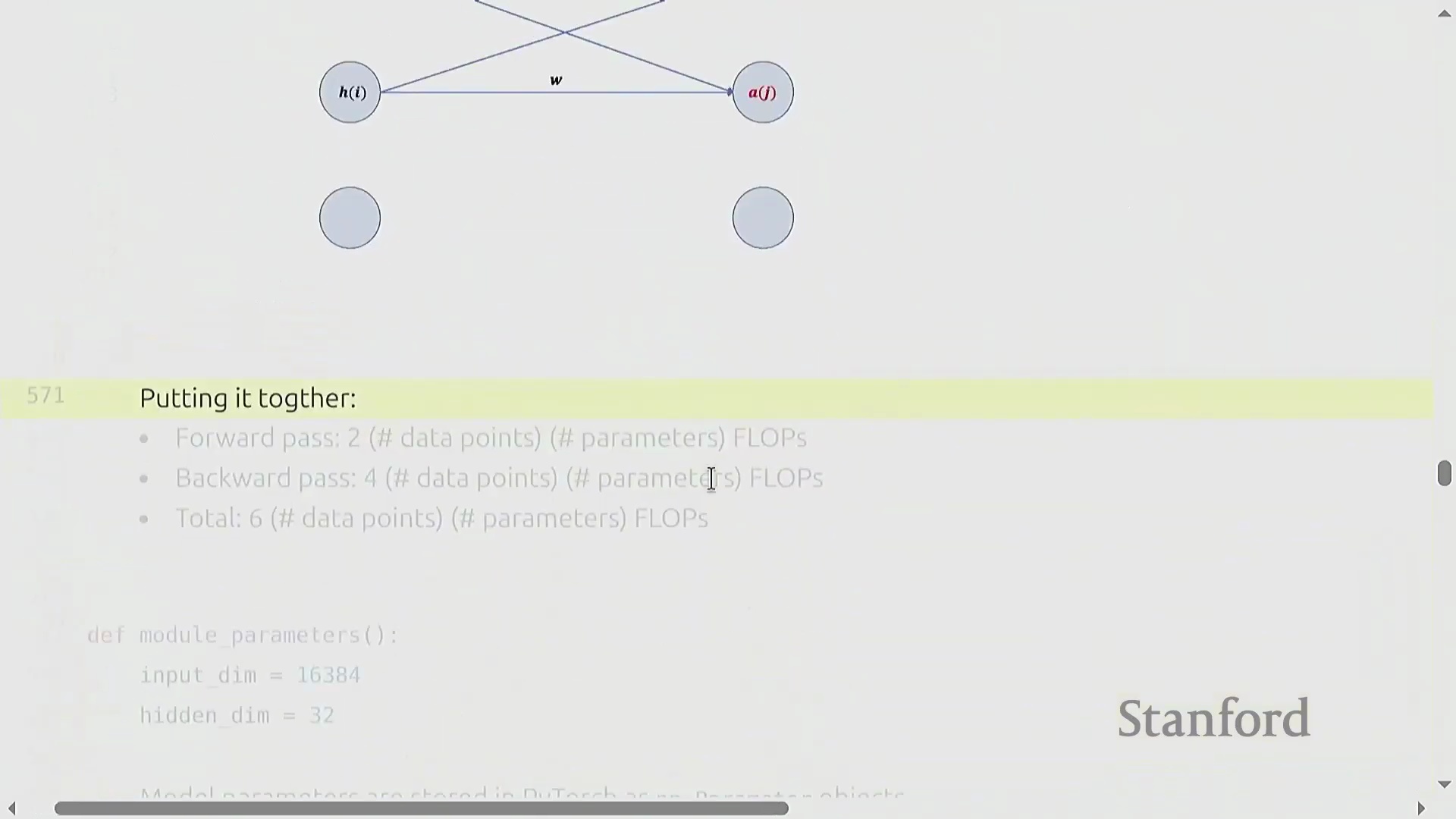
纯符号化(Symbolic)的链式法则可能略显晦涩,但将数据流(Data Flow)可视化能清晰揭示其内在模式。在前向传播中,激活值(Activations)流经权重矩阵。在反向传播中,梯度反向流动:权重梯度(Weight Gradients)由上游梯度(Upstream Gradients)与前一层激活值相乘得到,而激活梯度(Activation Gradients)则由上游梯度与转置(Transpose)后的权重矩阵相乘得到。因此,网络中的每一层都需要执行两次反向矩阵乘法,使其计算成本达到前向传播的两倍。最终结果表明,反向传播的成本恒定为 4 × 参数量(Parameters) × 数据点数(Data Points)。将前向传播(2×)与反向传播(4×)的开销相加,便得出了训练总 FLOP 的基础法则:6 × 参数量 × 词元量(Tokens),这有力地验证了最初的“餐巾纸数学(Napkin Math)”估算。





总结与过渡到 PyTorch 模型构建
总而言之,一个标准的训练步骤(Training Step)在前向传播中消耗 2 × 词元量 × 参数量 次 FLOPs,在反向传播中消耗 4 × 词元量 × 参数量 次 FLOPs,总计呈现 6× 的线性关系。该比例能可靠地近似大多数模型架构(Model Architecture)的计算成本(在此类架构中,计算量与参数量成正比增长),除非遇到大规模权重绑定(Weight Tying)等特殊情况。随着理论资源核算(Resource Accounting)的完成,讨论重点将从 FLOP 计数转向实际代码实现:在 PyTorch 中构建真实的神经网络组件(Neural Network Components),并深入理解框架如何正式注册(Register)与管理参数。


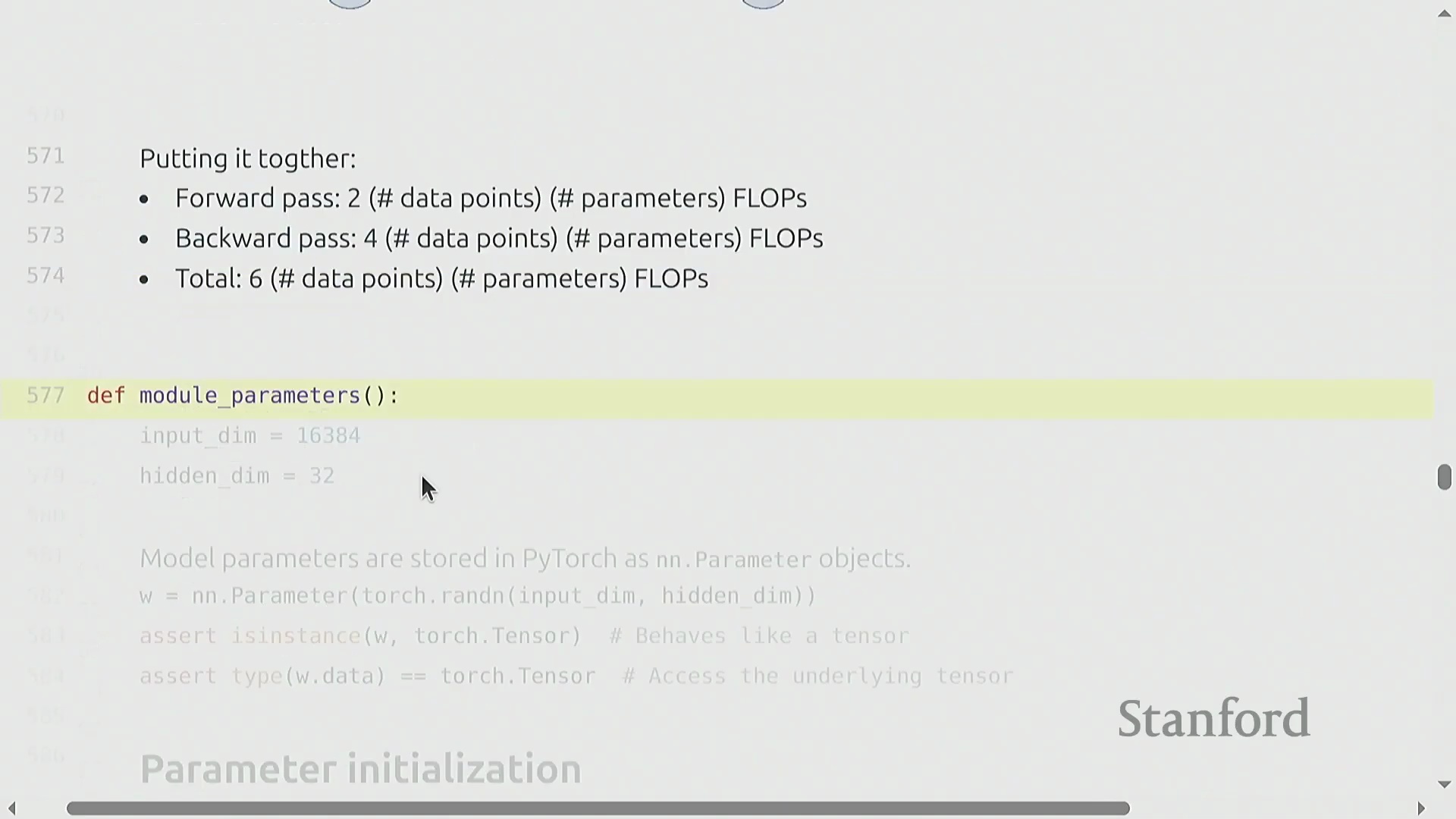

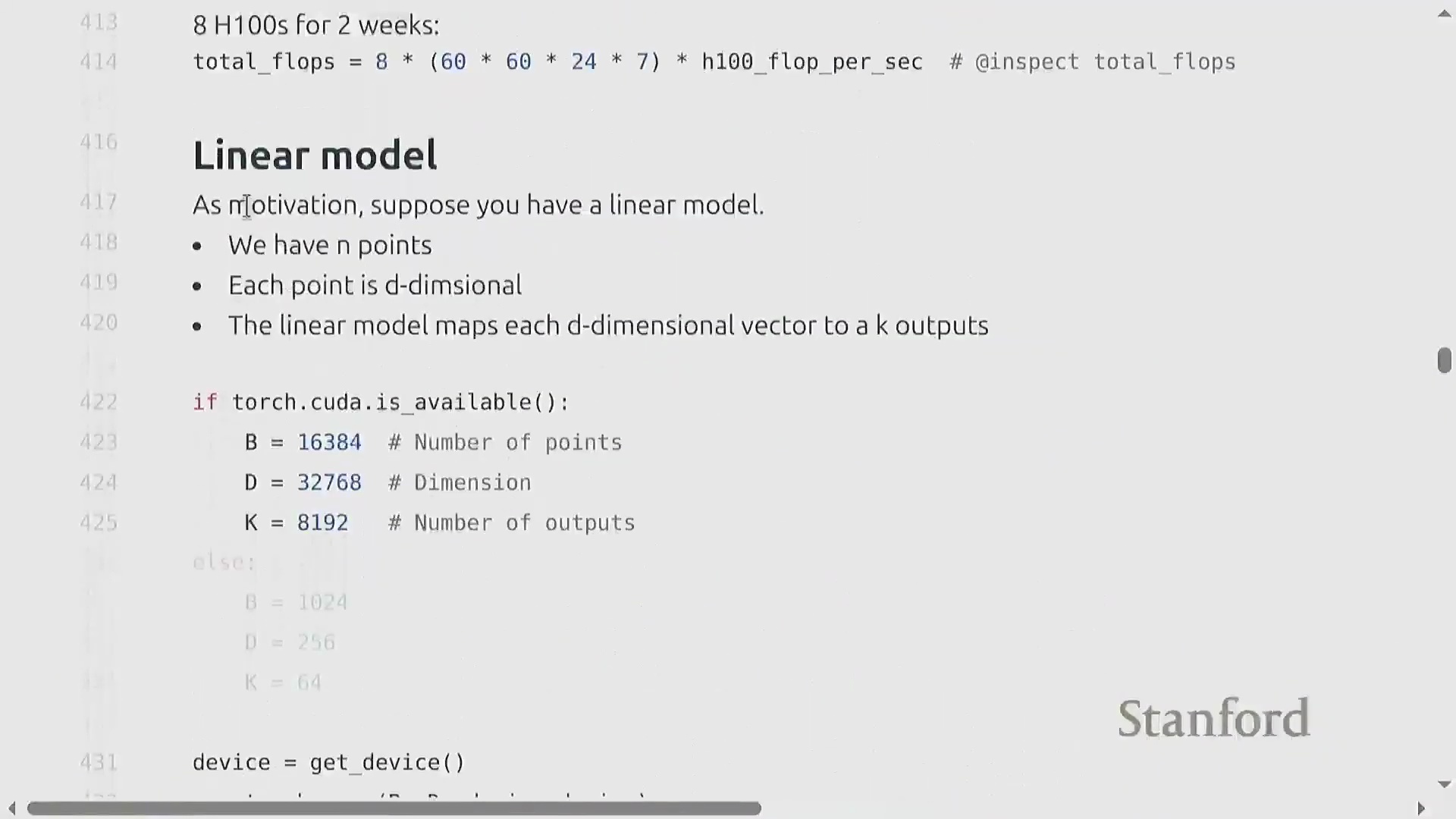
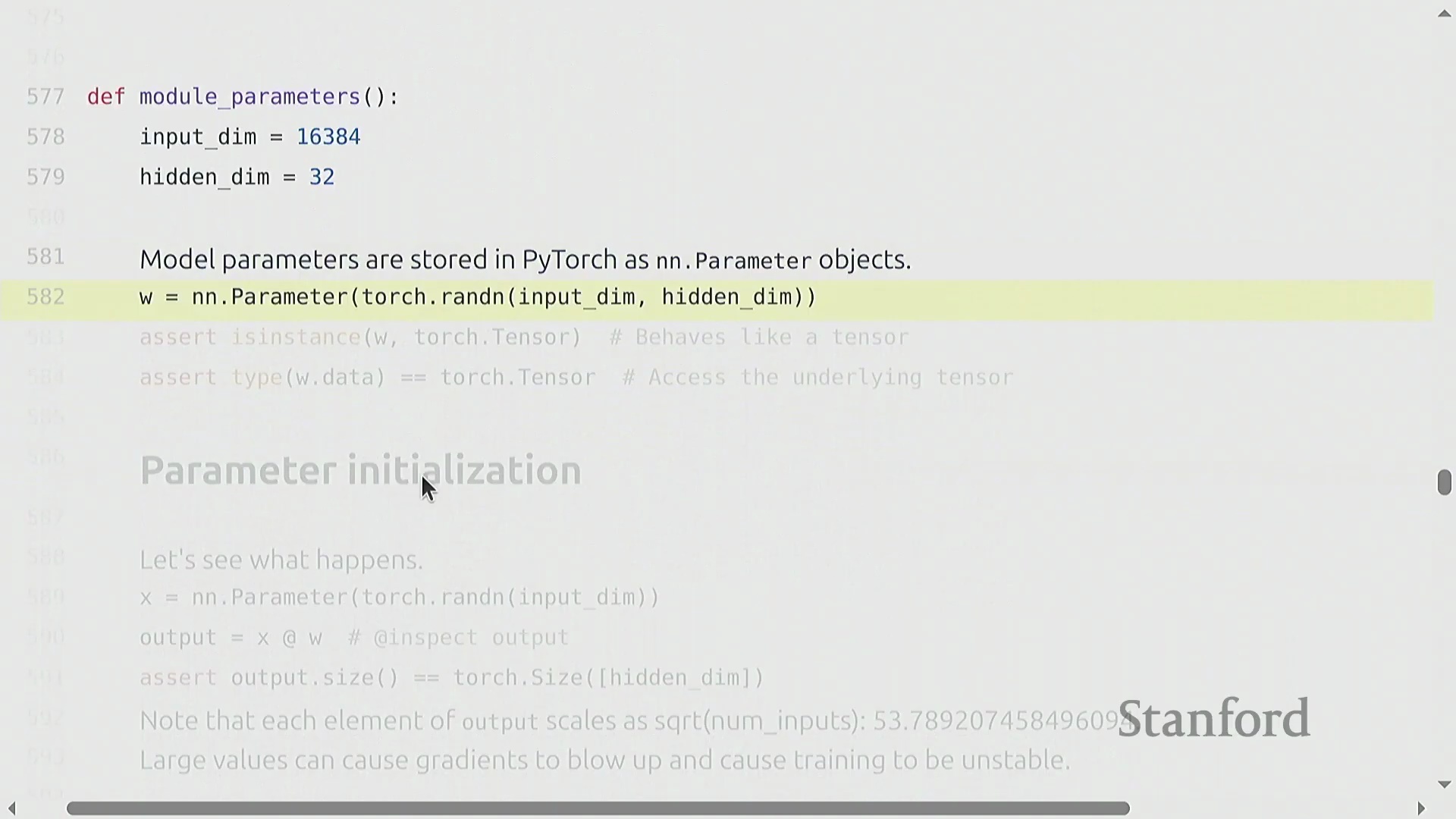
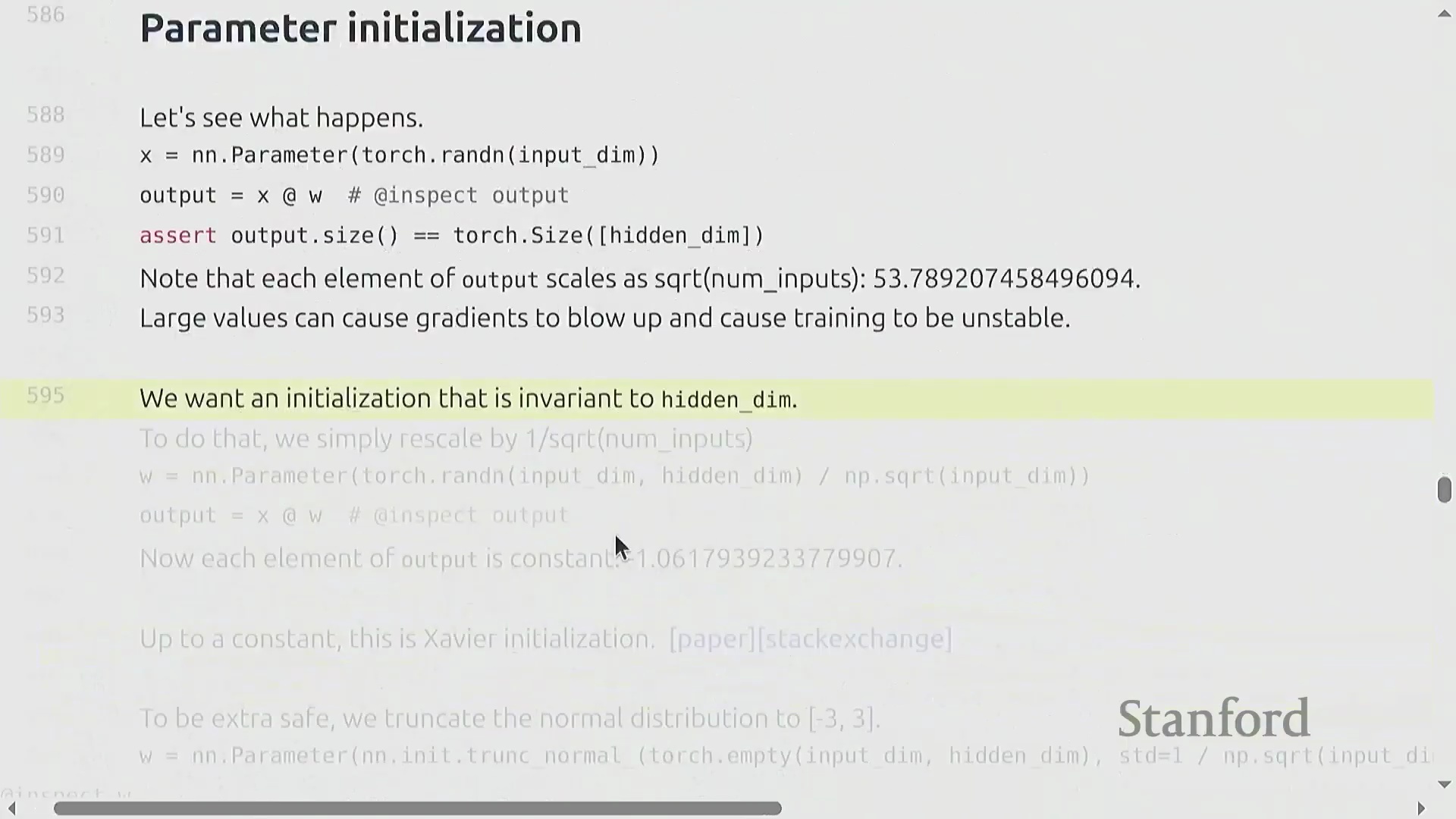
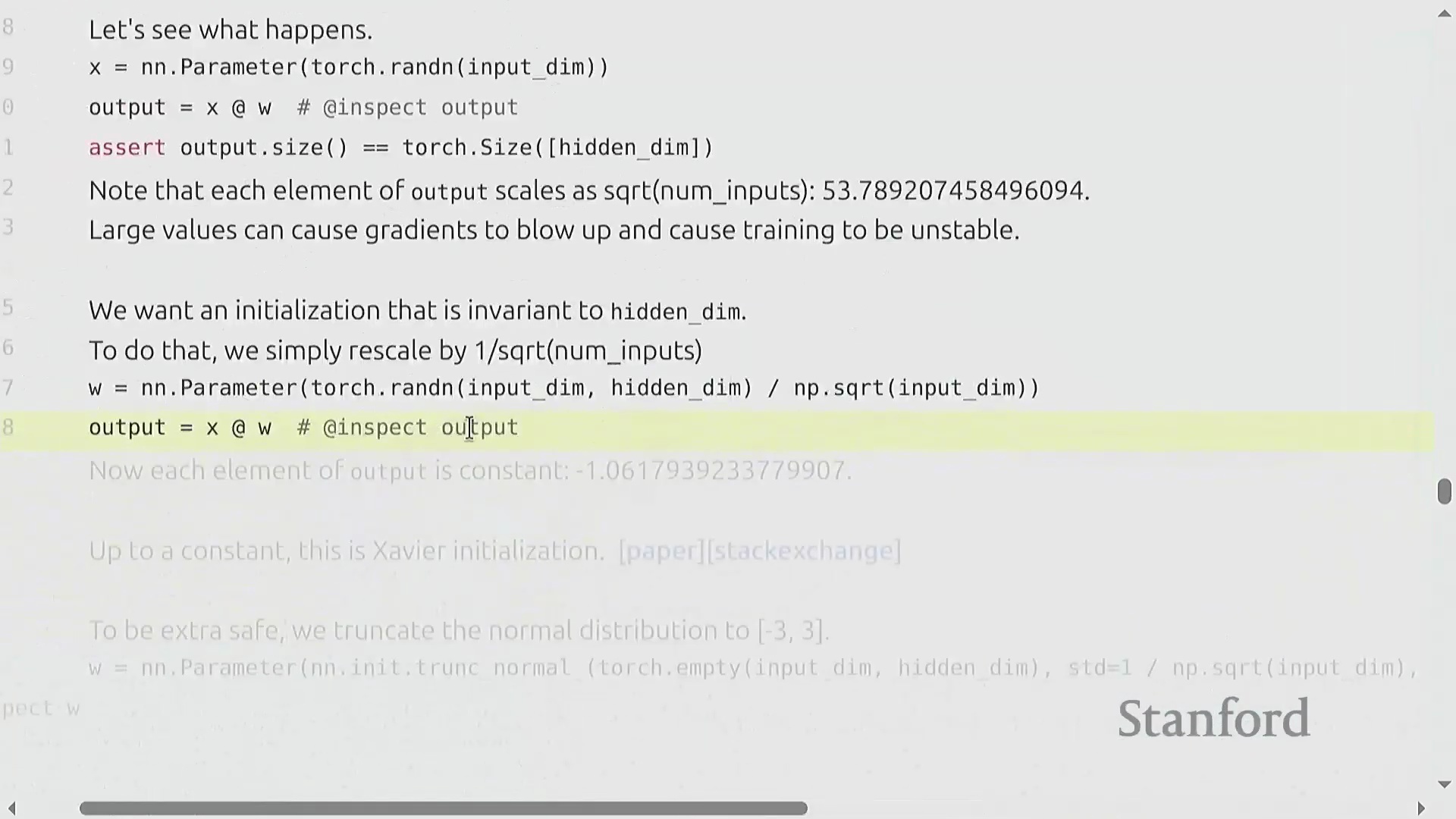
参数初始化与方差稳定性
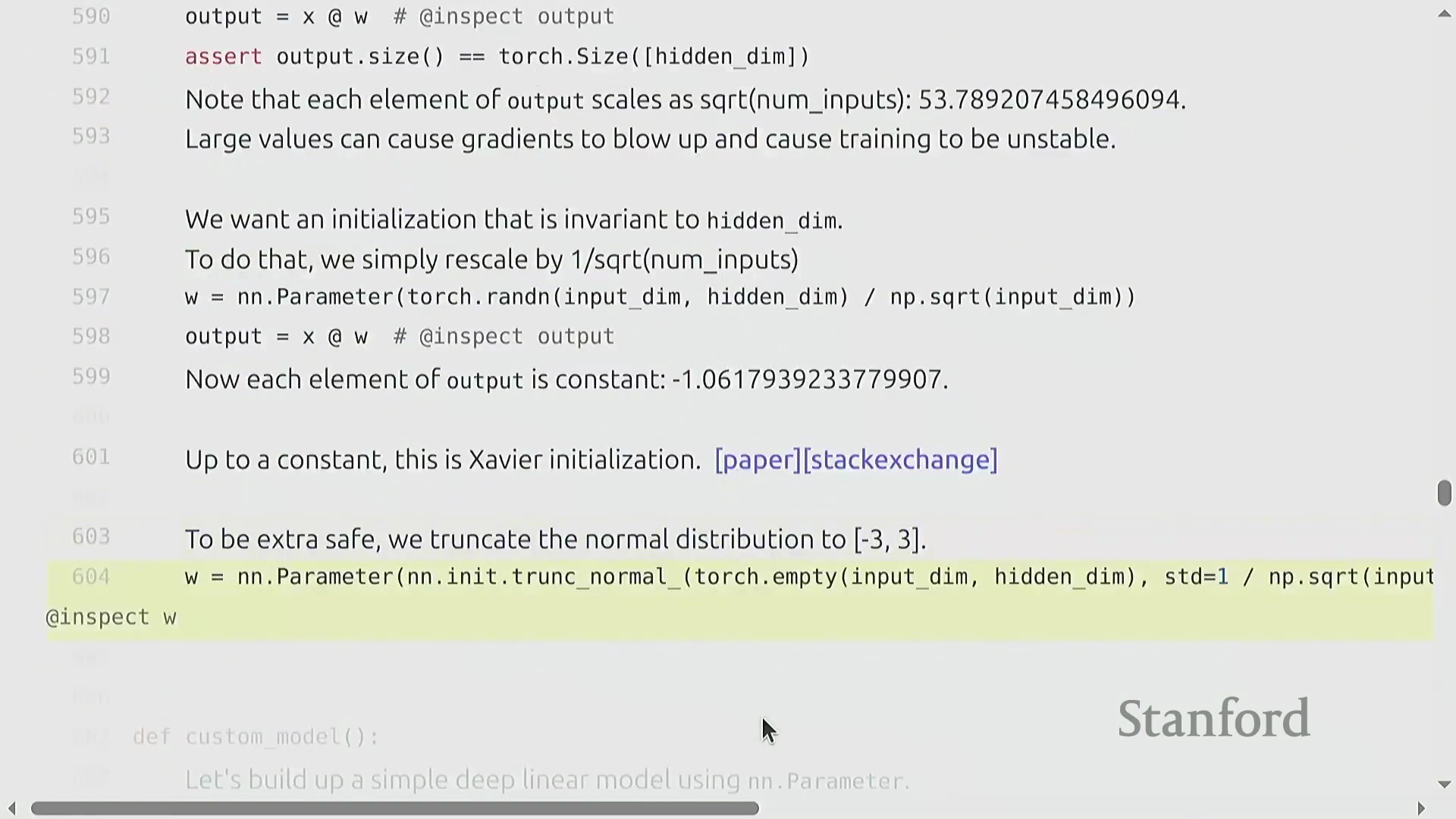
朴素的参数初始化(Parameter Initialization)方法(例如从标准正态分布(Standard Normal Distribution)中采样权重)会导致深度网络(Deep Networks)中的训练动态(Training Dynamics)不稳定。随着输入维度(Input Dimension)的增加,层输出的方差会随隐藏维度(Hidden Dimension)的平方根成比例放大,从而引发激活值爆炸(Exploding Activations)。为抵消这一影响,必须将权重按 1 / sqrt(input_dimension) 的比例进行重新缩放(Rescaling)。这项基础技术被称为 Xavier 初始化(Xavier Initialization)或 Kaiming 初始化(Kaiming Initialization),它能确保无论网络层宽如何,激活值的方差均能保持稳定。为防范正态分布无界尾部(Unbounded Tails)带来的潜在风险,实践中通常会对初始化数值进行截断(Truncation)(例如限制在 [-3, 3] 区间内),以防止极端异常值(Outliers)破坏模型初始的前向传播(Forward Pass)。

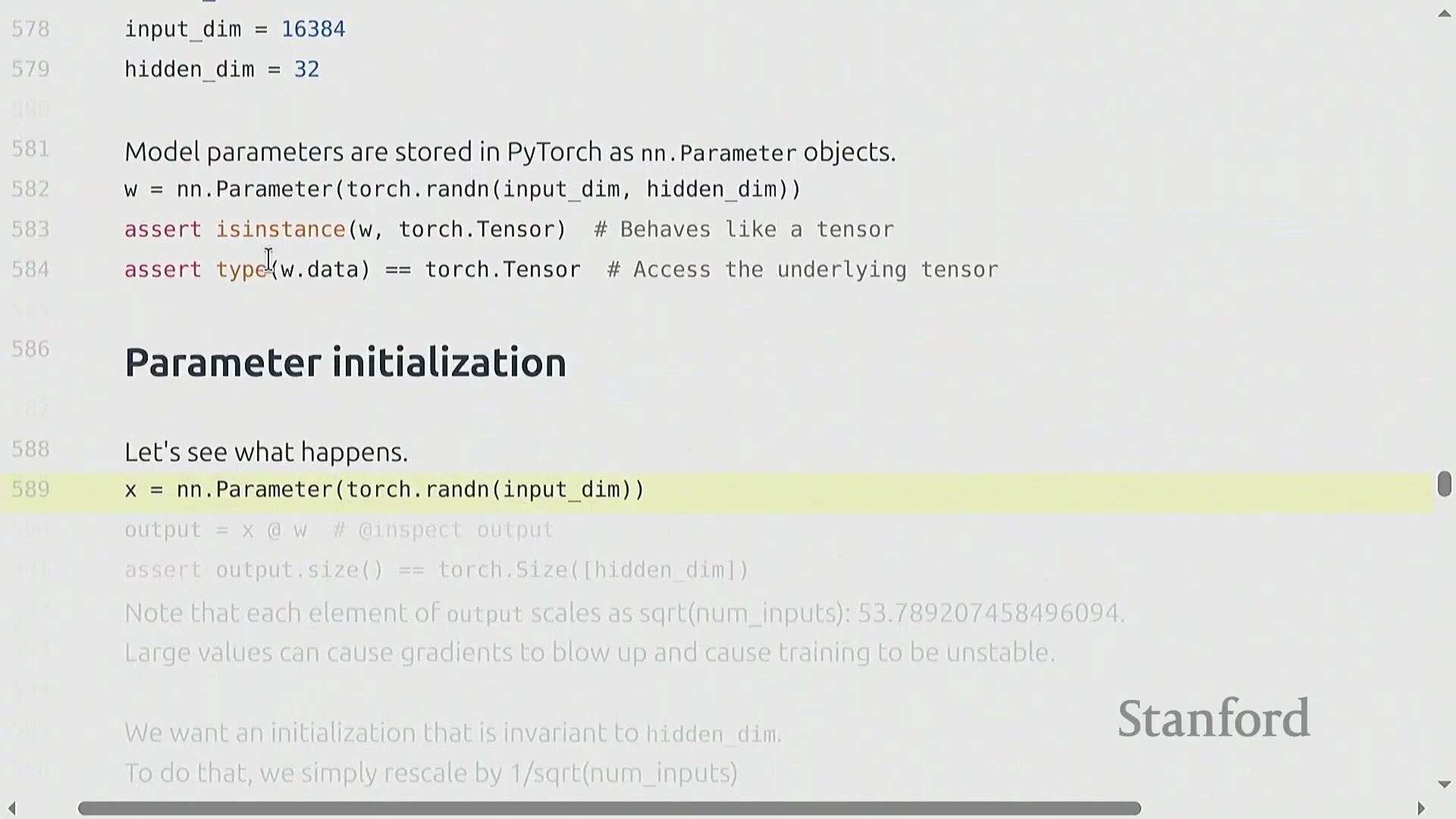

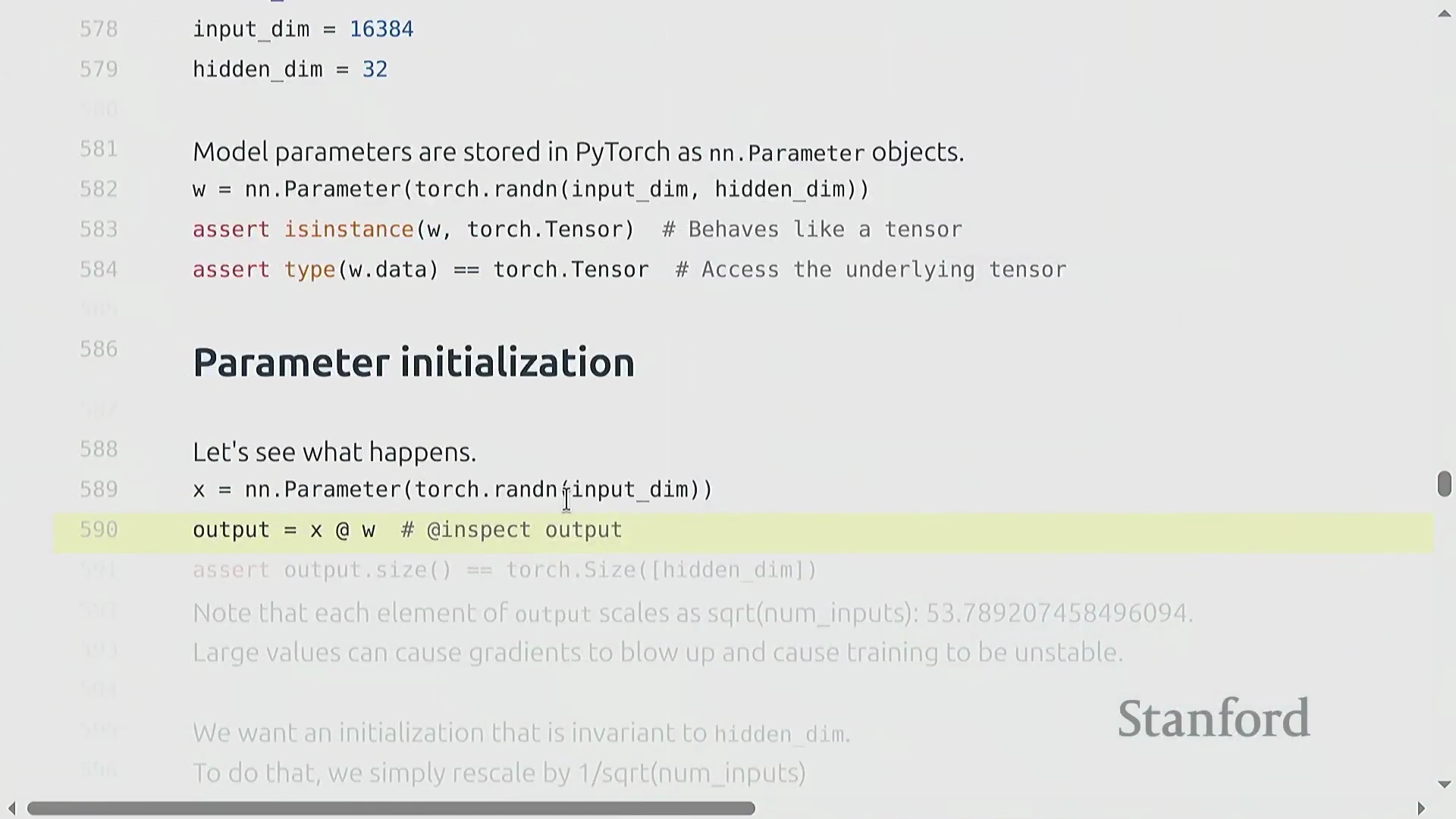
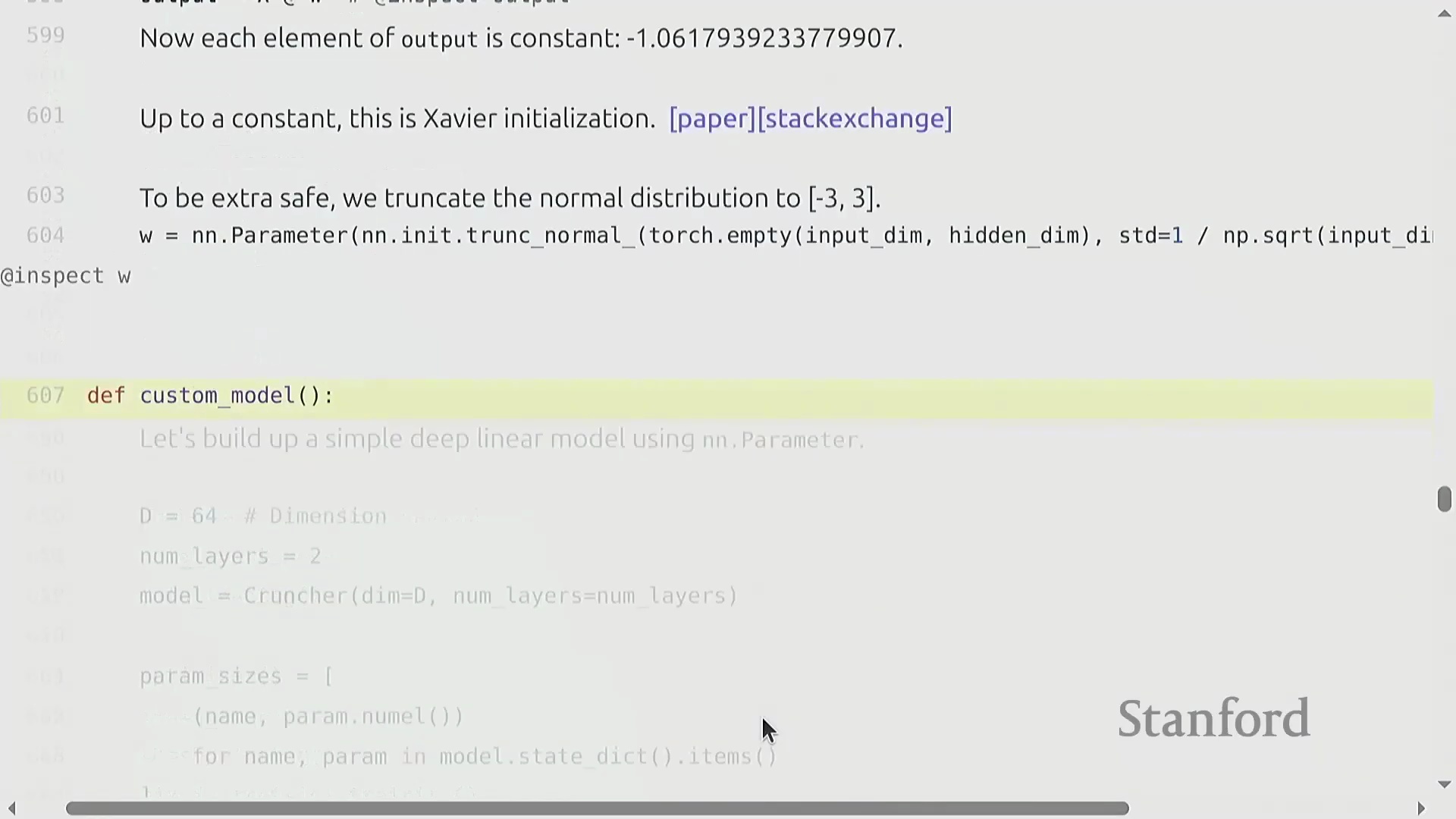
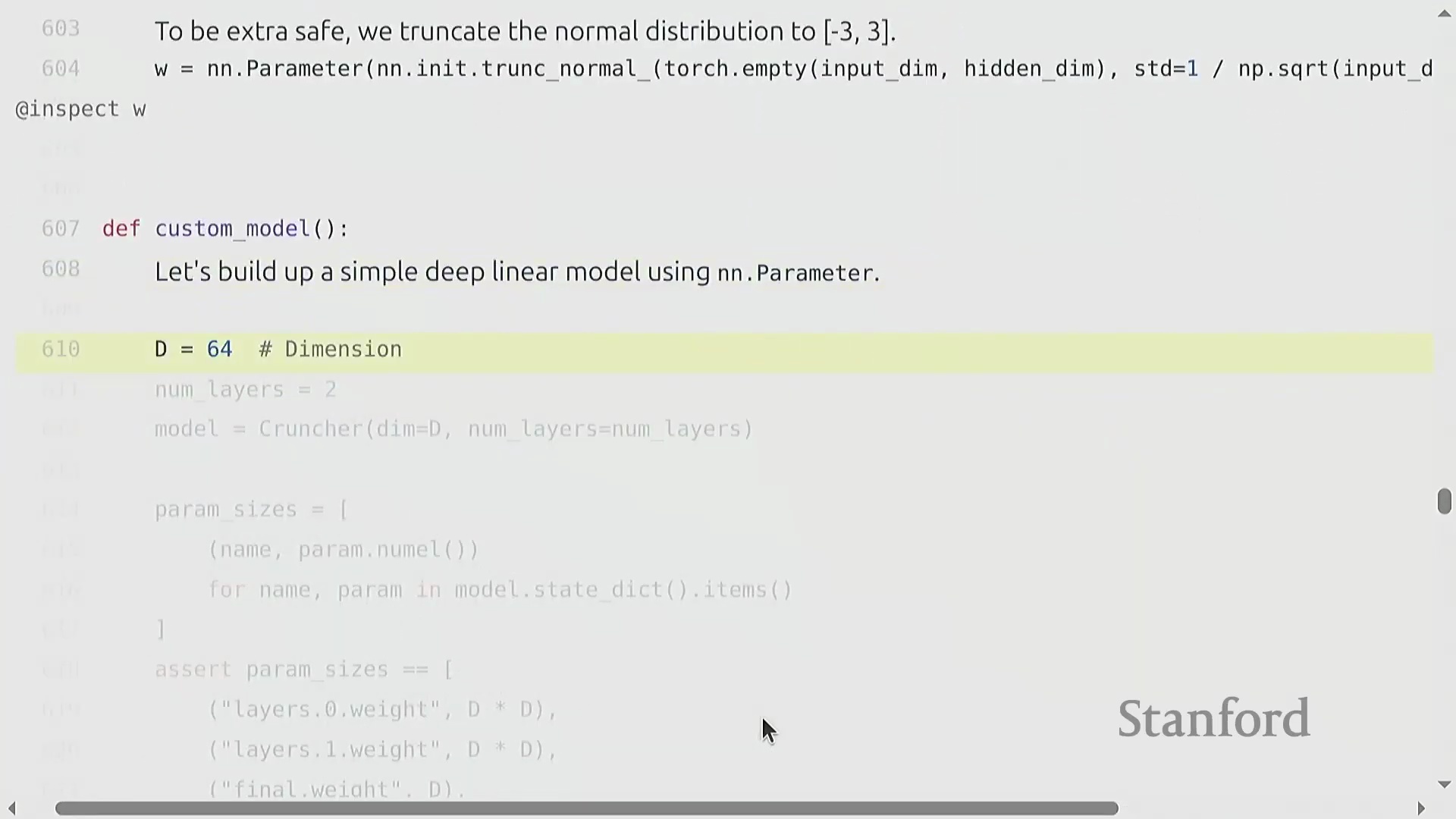
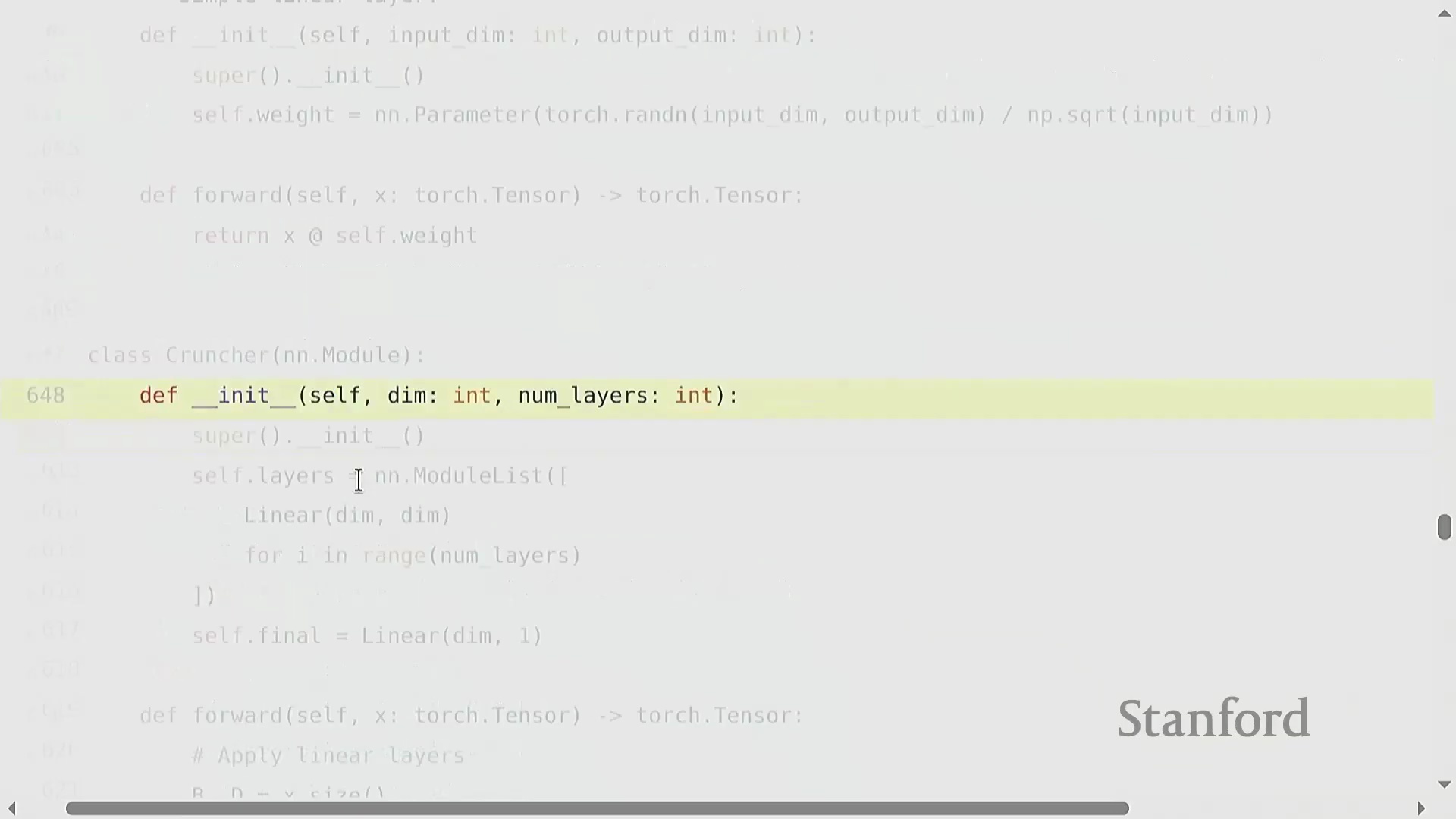
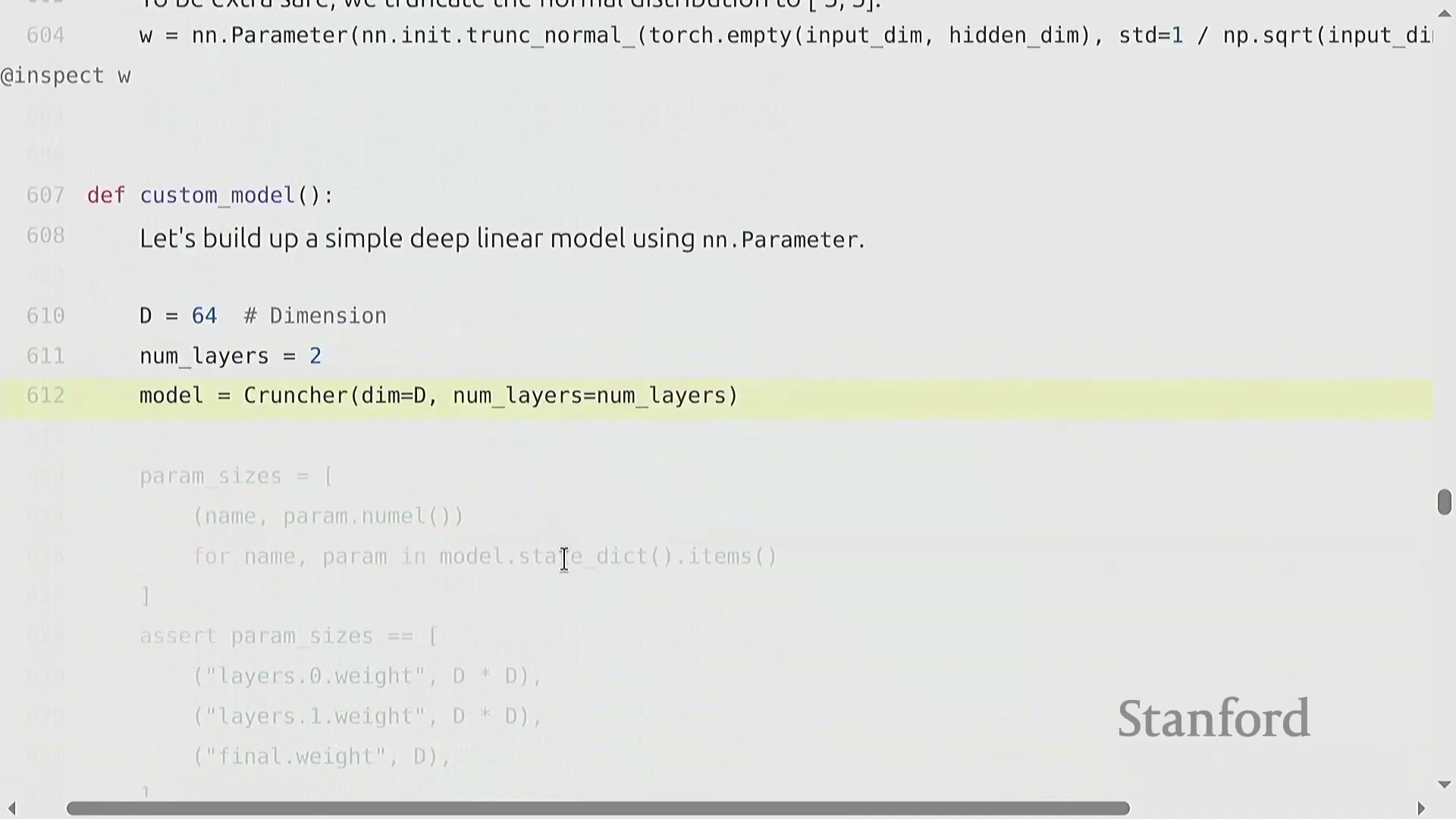
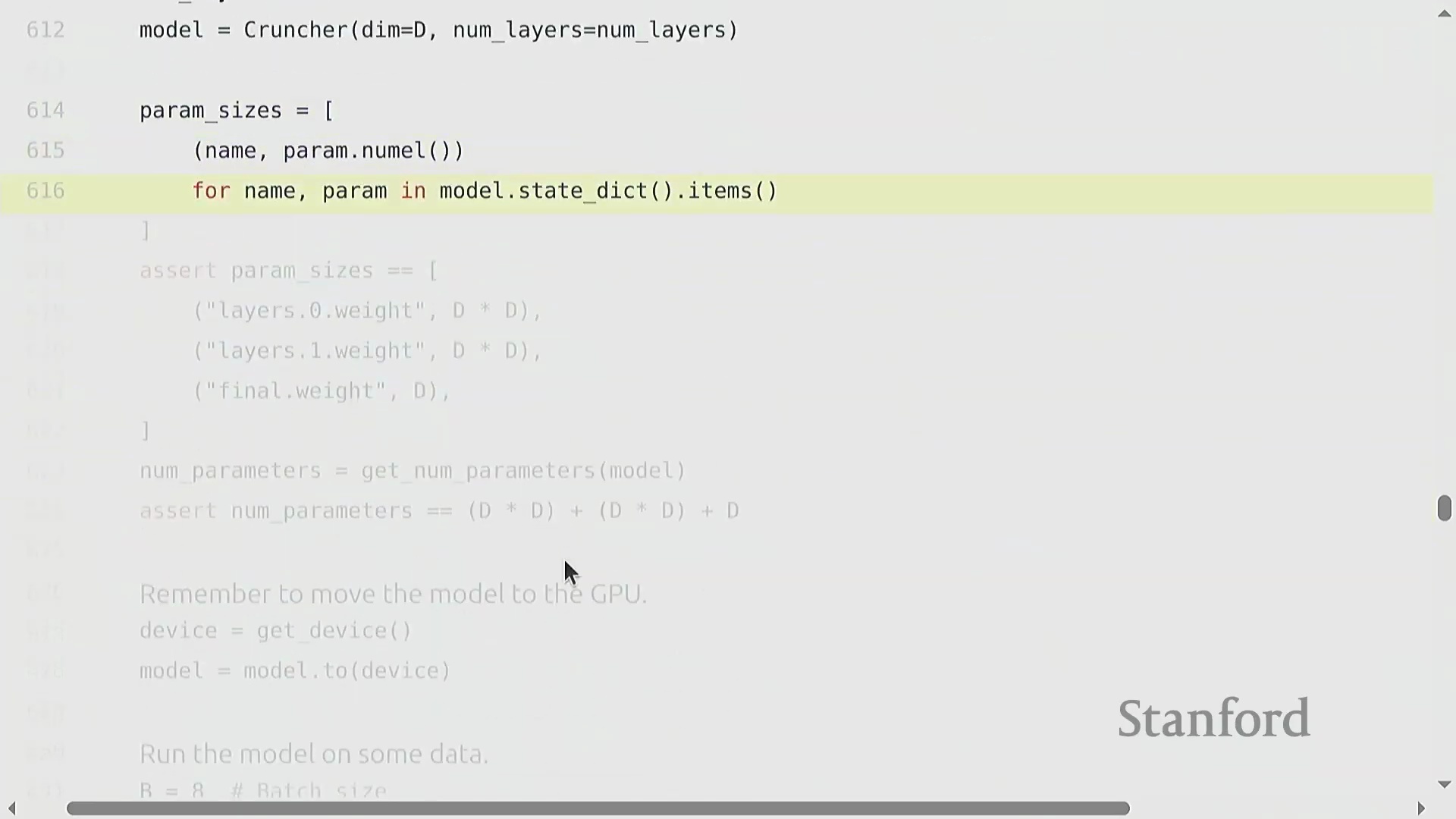
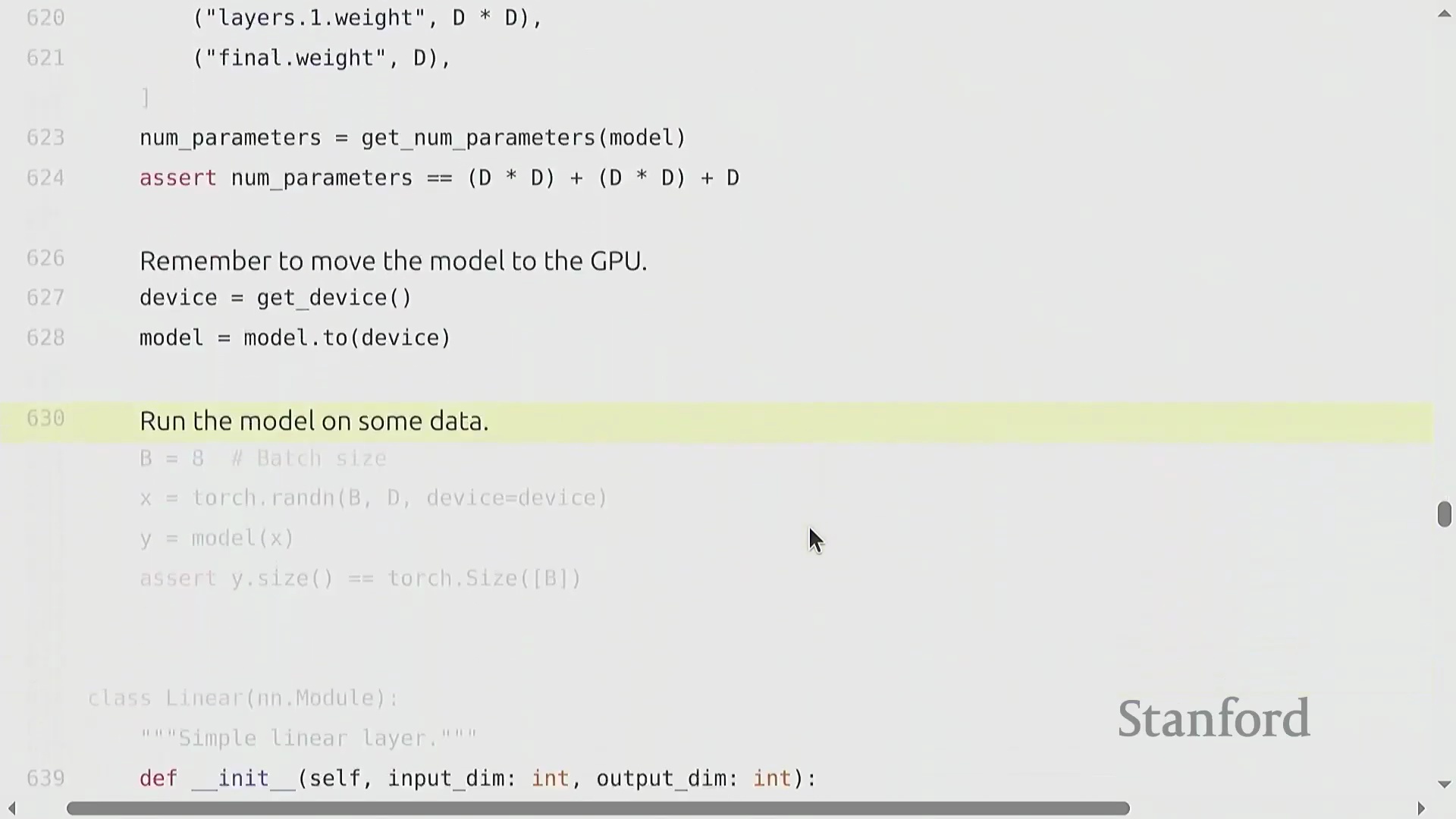
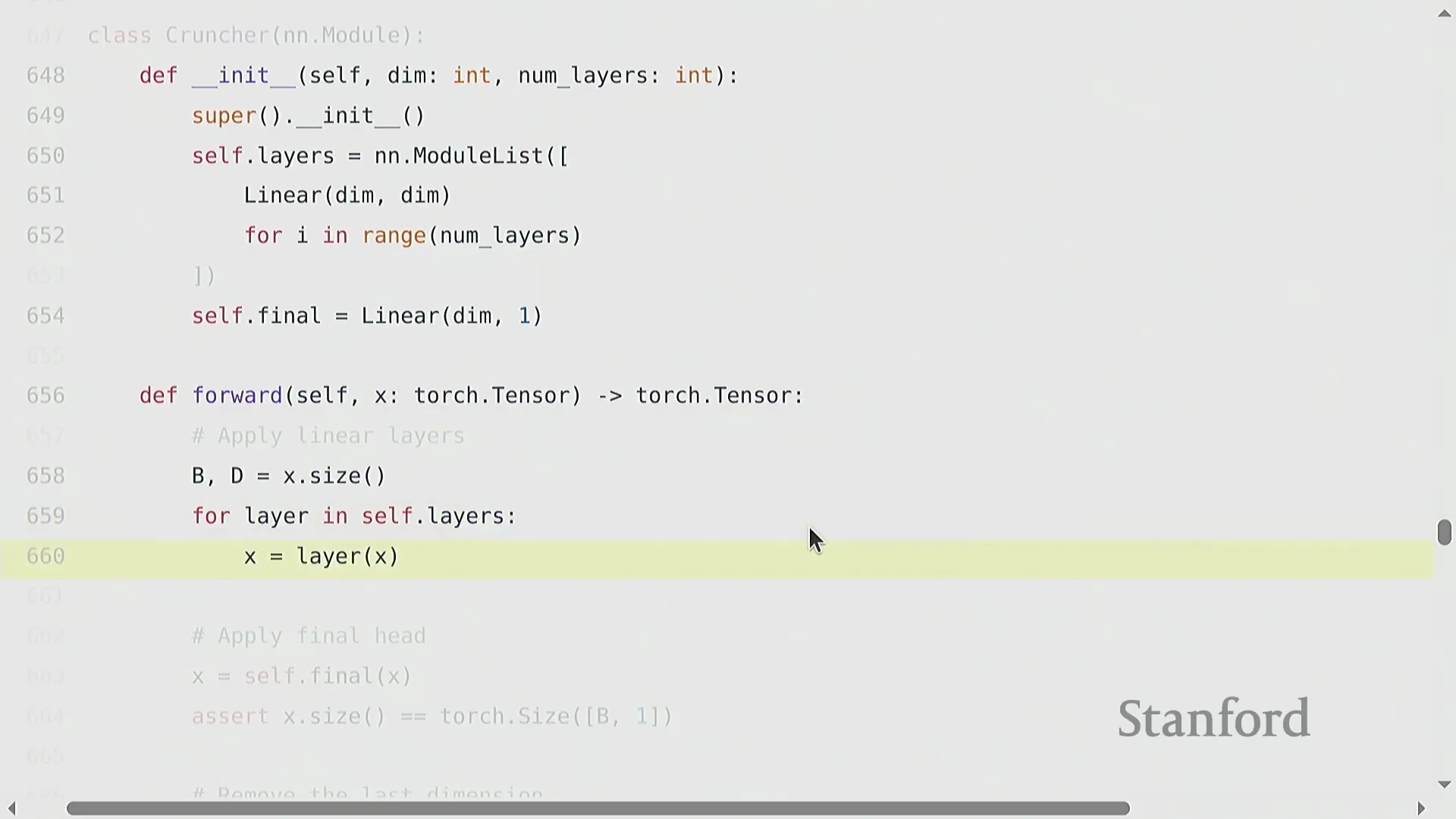
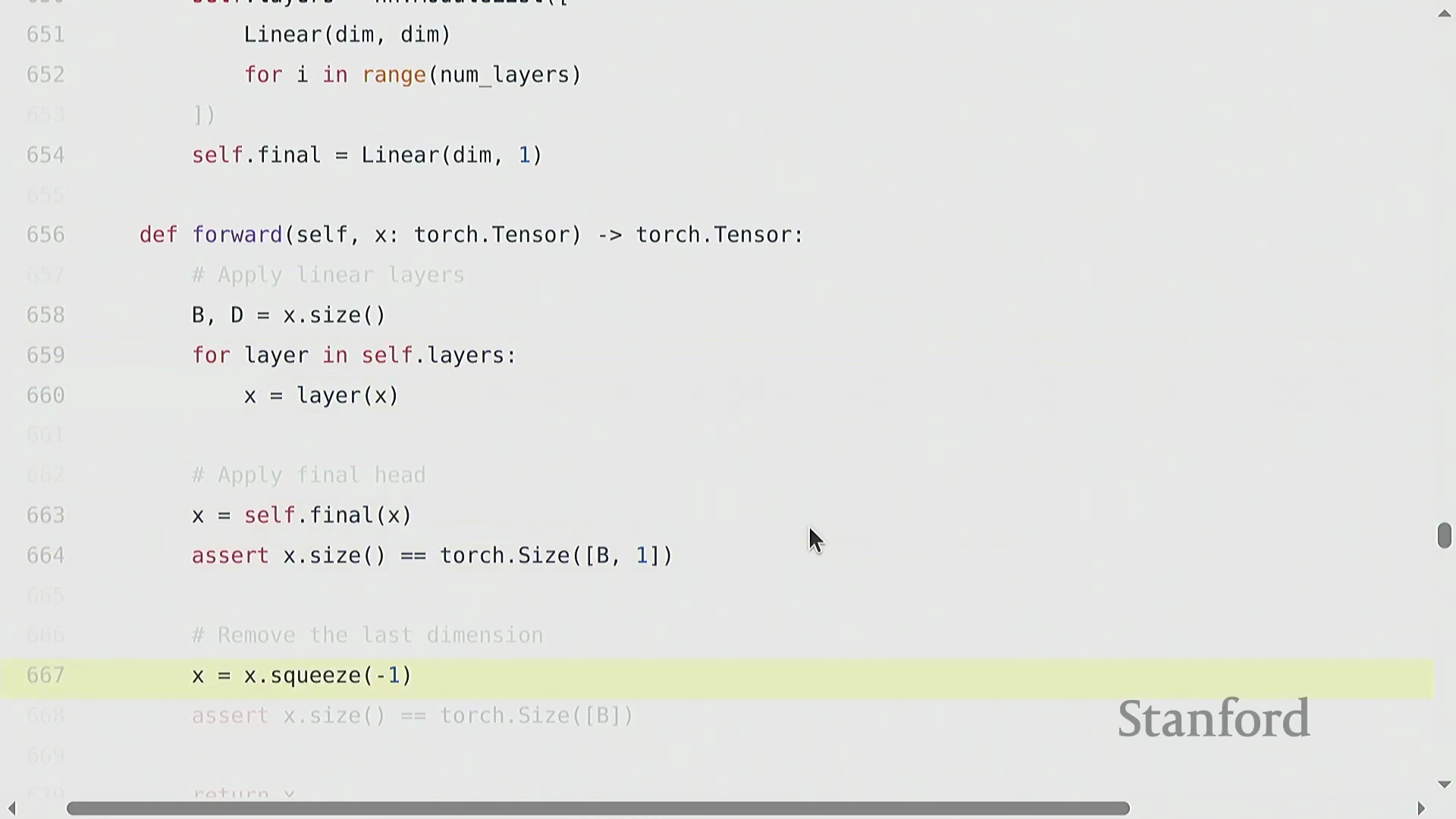
自定义模型架构与可复现性
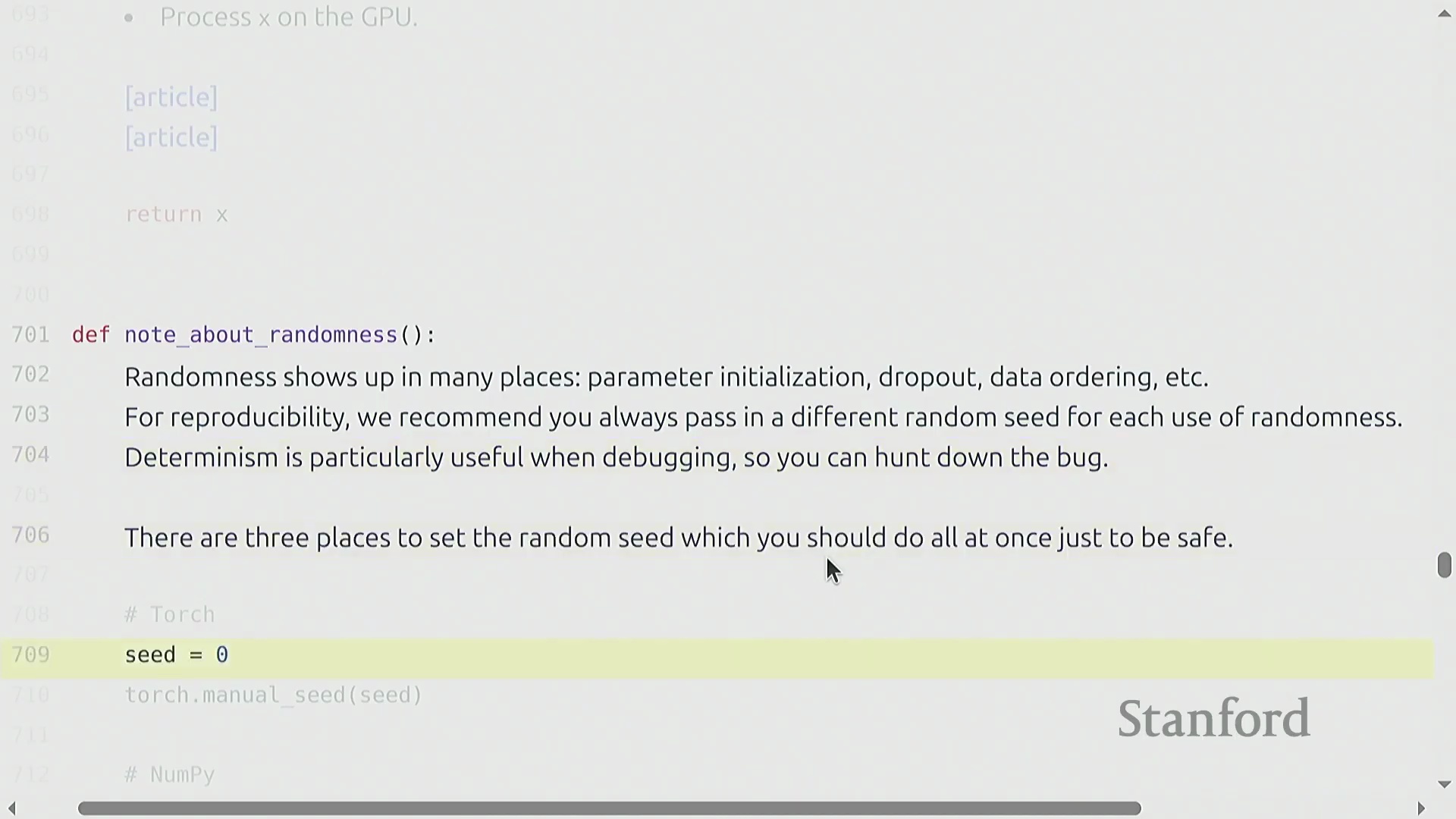
构建诸如多层线性网络“Cruncher”之类的自定义模型架构(Custom Model Architecture),需要堆叠 torch.nn.Parameter 对象,并定义一个按序执行矩阵乘法的前向传播(Forward Pass)逻辑。此时,参数量(Parameter Count)的计算变得极为直观(例如 d^2 + d^2 + d),且模型通常会被迁移至图形处理器(GPU)以加速计算。然而,深度学习(Deep Learning)固有的随机性(Stochasticity)(源于权重初始化、Dropout掩码(Dropout Mask)以及数据打乱(Data Shuffling))使得调试过程异常困难。一项关键的最佳实践(Best Practice)是严格固定所有相关库(如 PyTorch、NumPy 及 Python 内置的 random 模块)的随机种子(Random Seed),以确保程序具备确定性执行(Deterministic Execution)能力。此外,为不同的随机源(Random Sources)分配独立的随机种子,有助于更精准地定位错误究竟源自数据流水线(Data Pipeline)还是模型逻辑本身。
使用 Memmap 实现内存高效的数据加载
语言建模(Language Modeling)数据集通常过于庞大,无法直接全部载入系统内存(System Memory)。例如,Llama 数据集的规模高达约 2.8 TB。若尝试将此类海量数据完全加载至内存,不仅不可行,还会直接导致进程因内存溢出(Out-Of-Memory, OOM)而崩溃。业界的标准解决方案是将分词后的整数序列(Tokenized Integer Sequences)序列化(Serialization)为扁平二进制文件(Flat Binary File),并通过 numpy.memmap 进行访问。这种内存映射(Memory Mapping)技术构建了一个虚拟数组接口(Virtual Array Interface),支持按需(On-Demand)从磁盘读取数据,而非一次性预加载。结合自定义的 PyTorch Dataset 与 DataLoader,memmap 能够实现高效的流式批次采样(Streaming Batch Sampling),从而在避免耗尽物理内存(Physical Memory)的前提下完成数据供给。



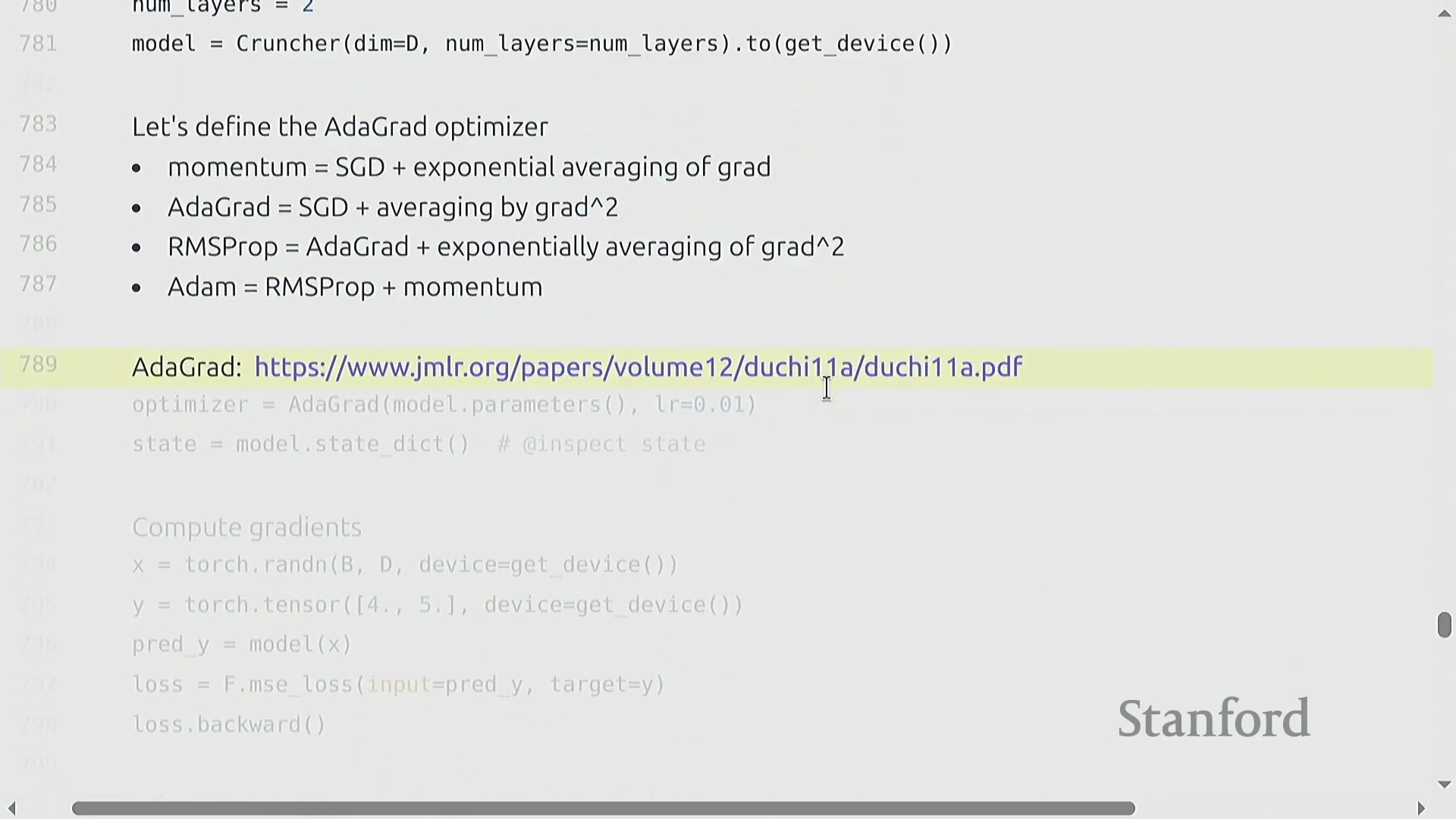
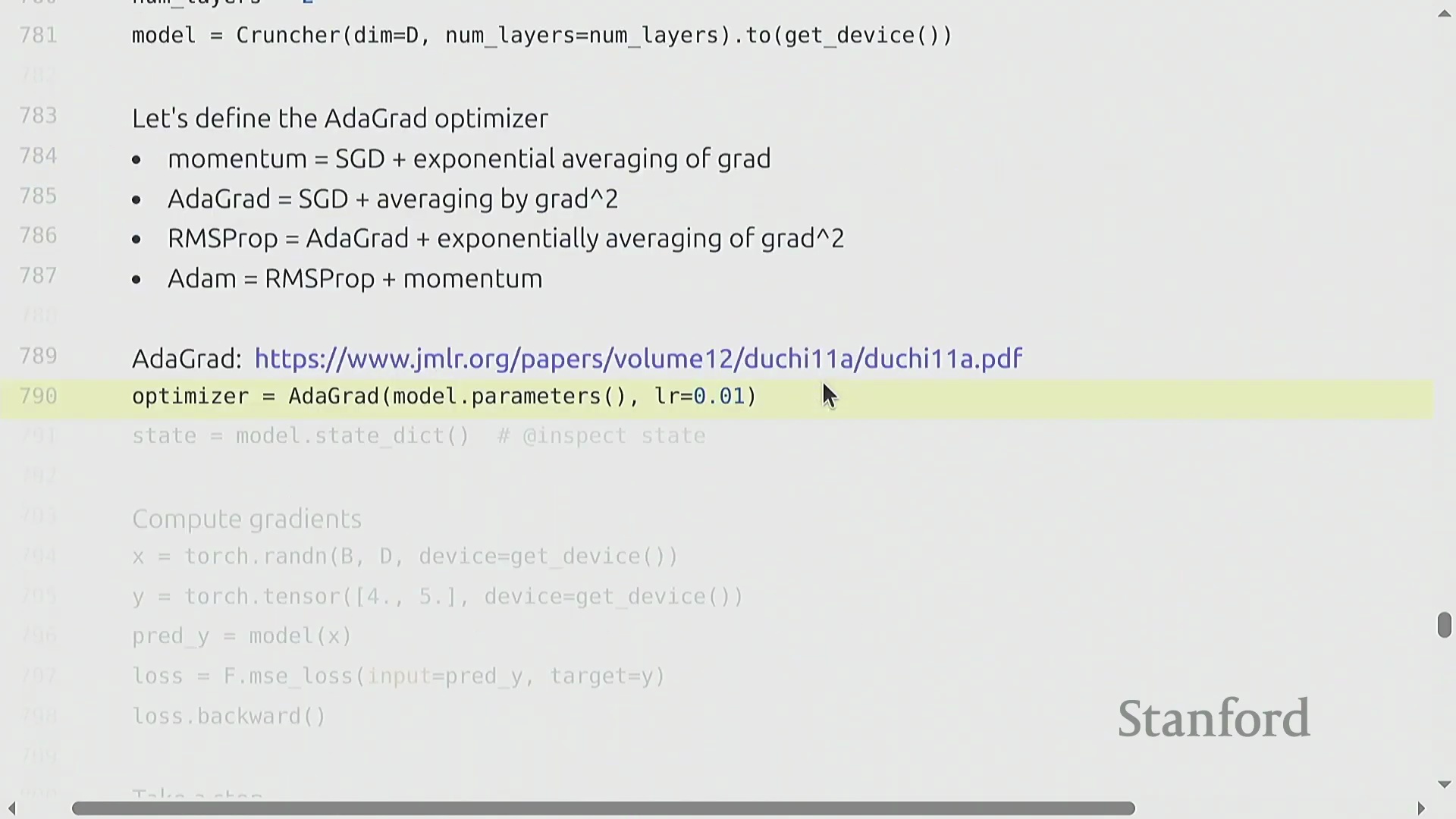
优化器算法与 PyTorch 自定义实现
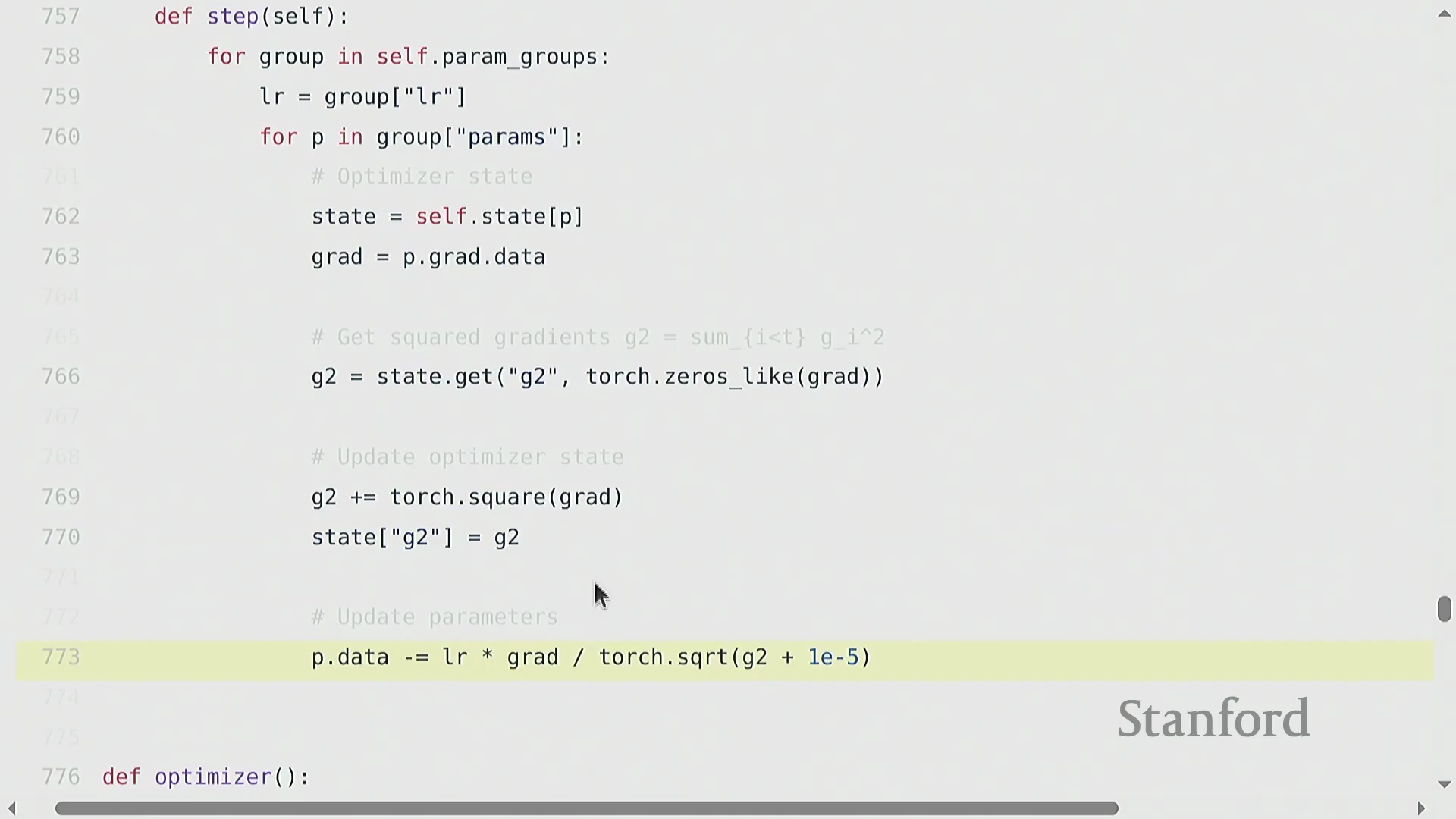
优化器(Optimizer)决定了如何将计算出的梯度(Gradients)转化为模型参数的更新(Parameter Updates)。其算法演进始于随机梯度下降(Stochastic Gradient Descent, SGD),随后发展出动量法(Momentum)(利用梯度的指数移动平均(Exponential Moving Average, EMA)来平滑更新轨迹)、自适应梯度算法(Adagrad)(依据历史平方梯度的累积和动态缩放学习率(Learning Rate))以及均方根传播算法(RMSprop)(通过平方梯度的衰减移动平均改进 Adagrad 的累积问题)。自适应矩估计优化器(Adam) 融合了上述思想,同时维护梯度的一阶矩(First Moment)与二阶矩(Second Moment)估计。若要在 PyTorch 中实现类似 Adagrad 的自定义优化器,需继承 torch.optim.Optimizer 基类。其构造函数(Constructor)负责初始化参数组(Parameter Groups)并创建 state 字典以跟踪状态。核心的 .step() 方法会遍历参数组,检索或更新状态变量(例如记录平方梯度累积的 g2),应用学习率更新规则,并直接修改各参数张量(Parameter Tensors)的 .data 属性以完成权重更新。
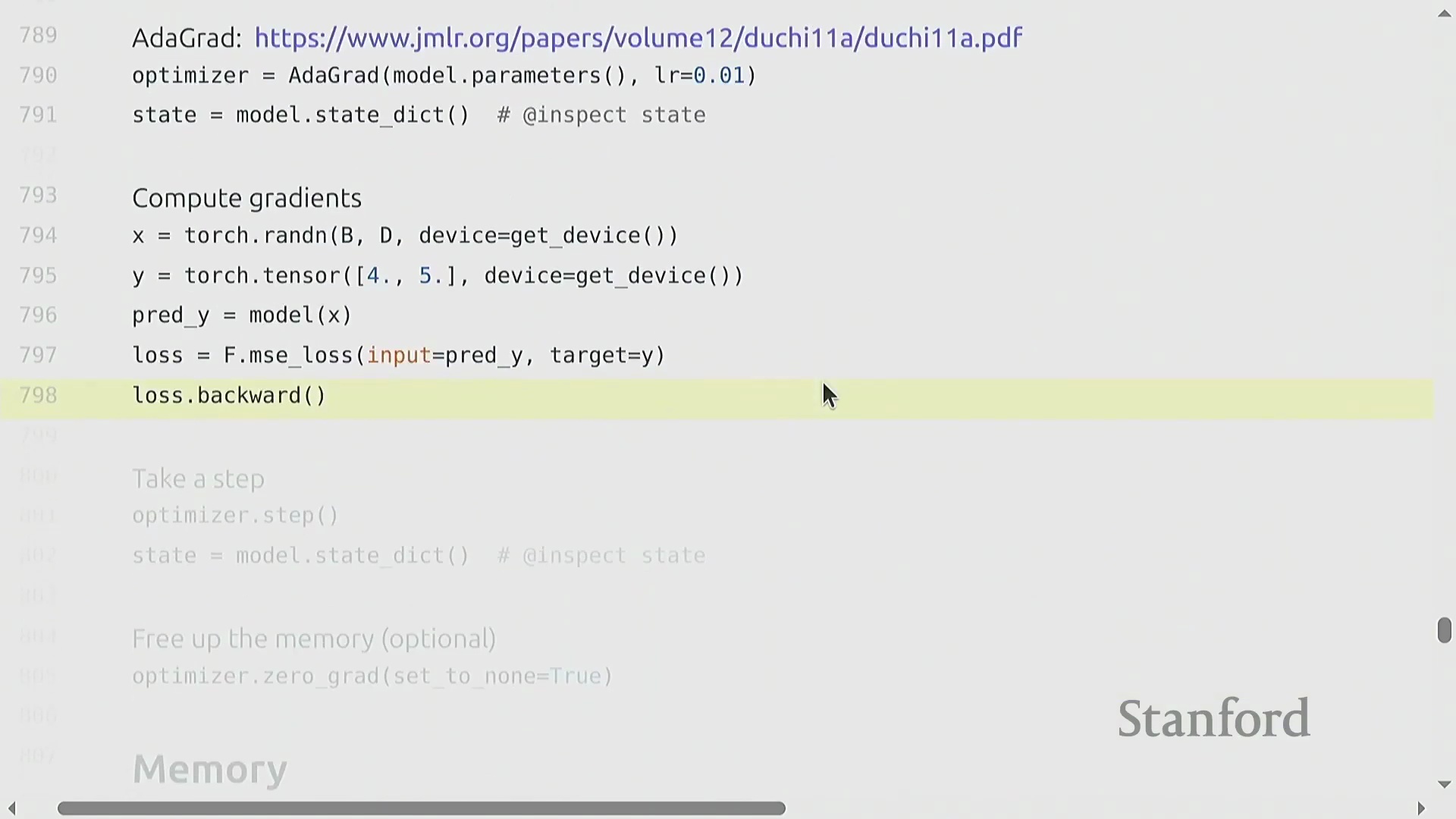
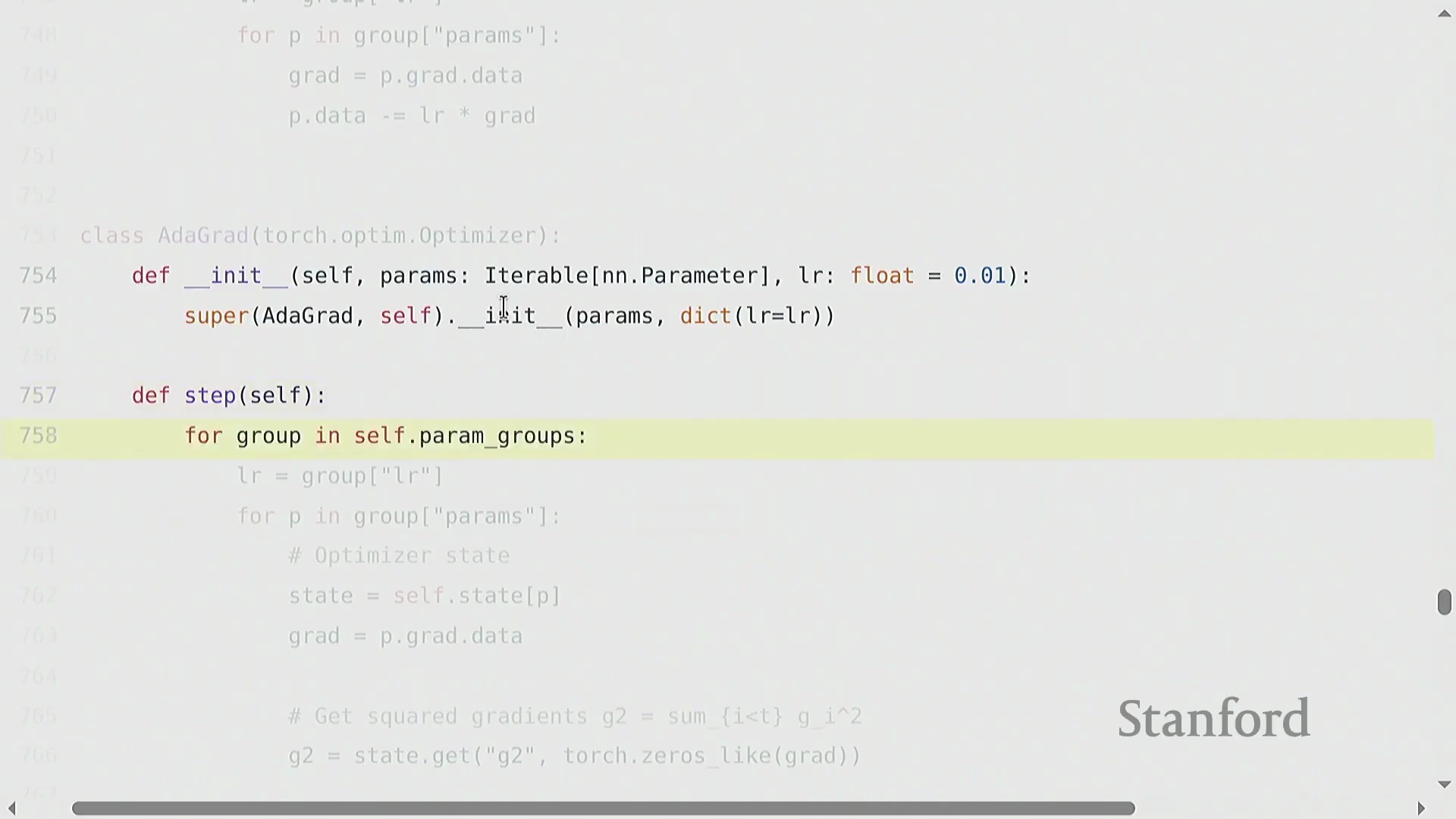
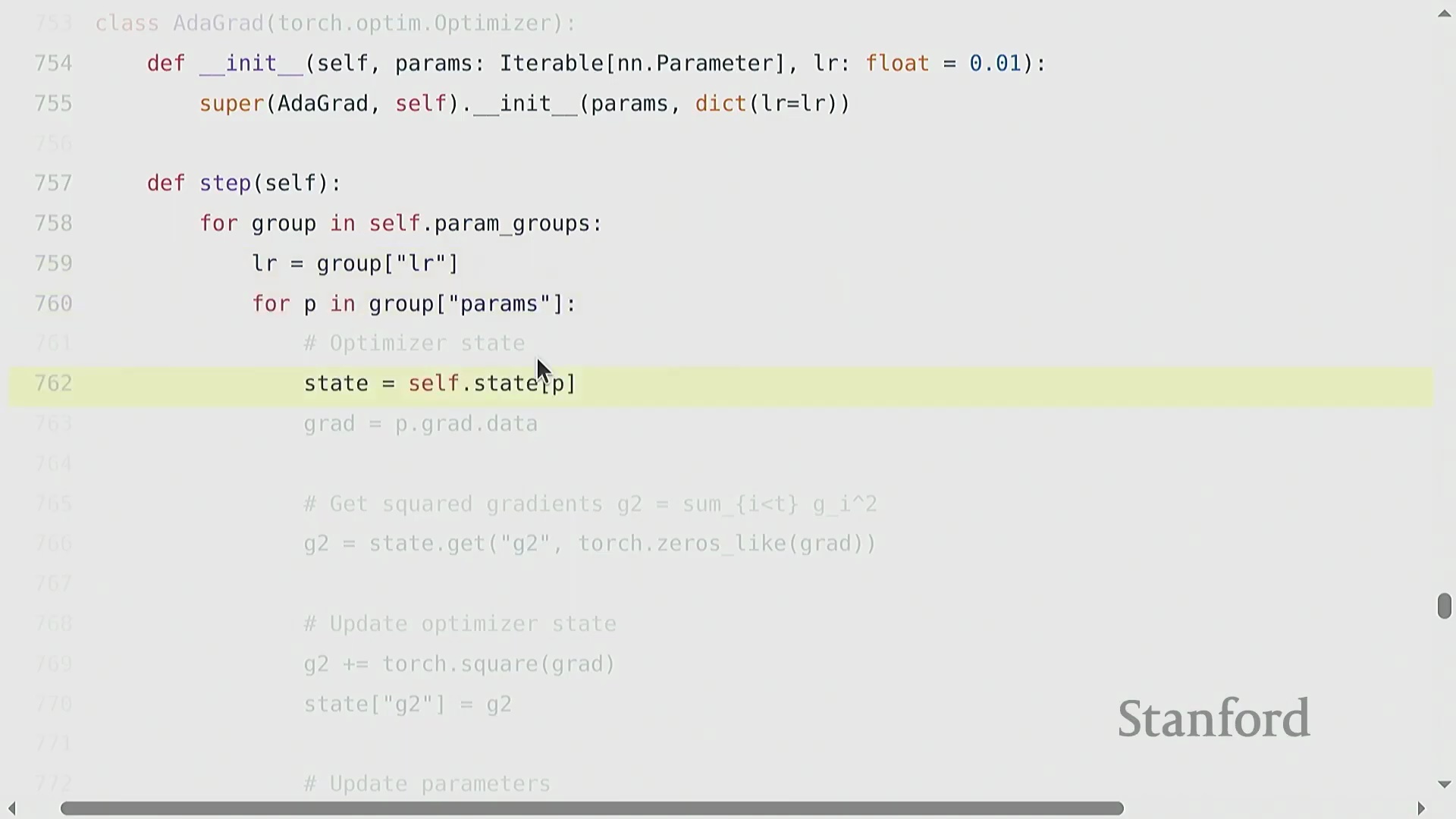
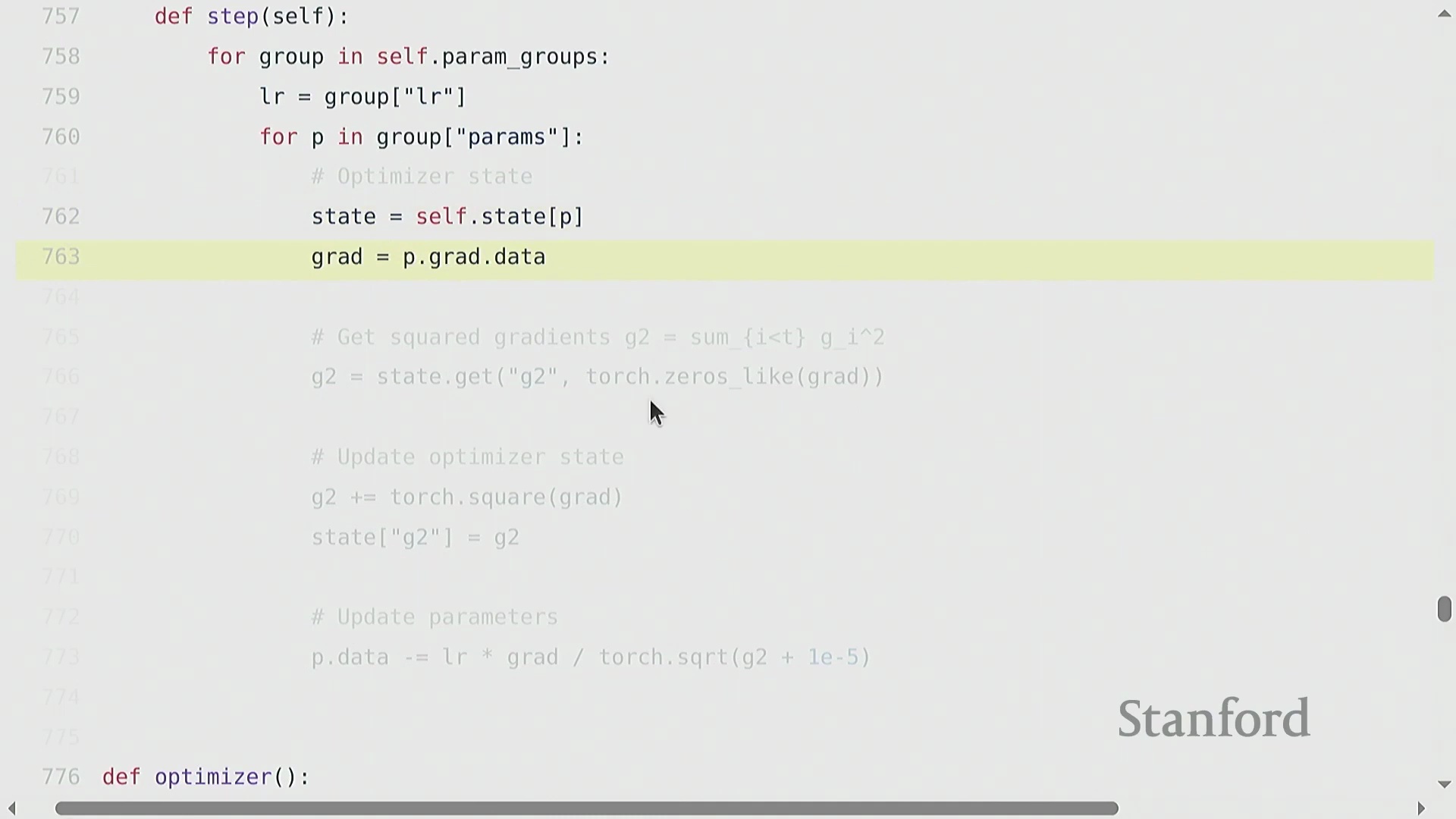
优化器状态管理与内存清理
在通过反向传播(Backward Propagation)计算出梯度(Gradients)后,优化器(Optimizer)会根据梯度及运行状态统计量(如 Adagrad 中累积的平方梯度)对学习率(Learning Rate)进行缩放,进而更新模型参数。该优化器状态(Optimizer State)在训练迭代期间通常保存于状态字典中,以保留历史梯度信息。关键在于,一旦 optimizer.step() 执行完毕,开发者应显式清理中间内存缓冲区(Intermediate Memory Buffers)。尽管在小型脚本中此步骤常被忽略,但在模型并行(Model Parallelism)等分布式训练(Distributed Training)范式中,由于 GPU 显存(GPU Memory)被严格划分,高效管理内存显得至关重要。

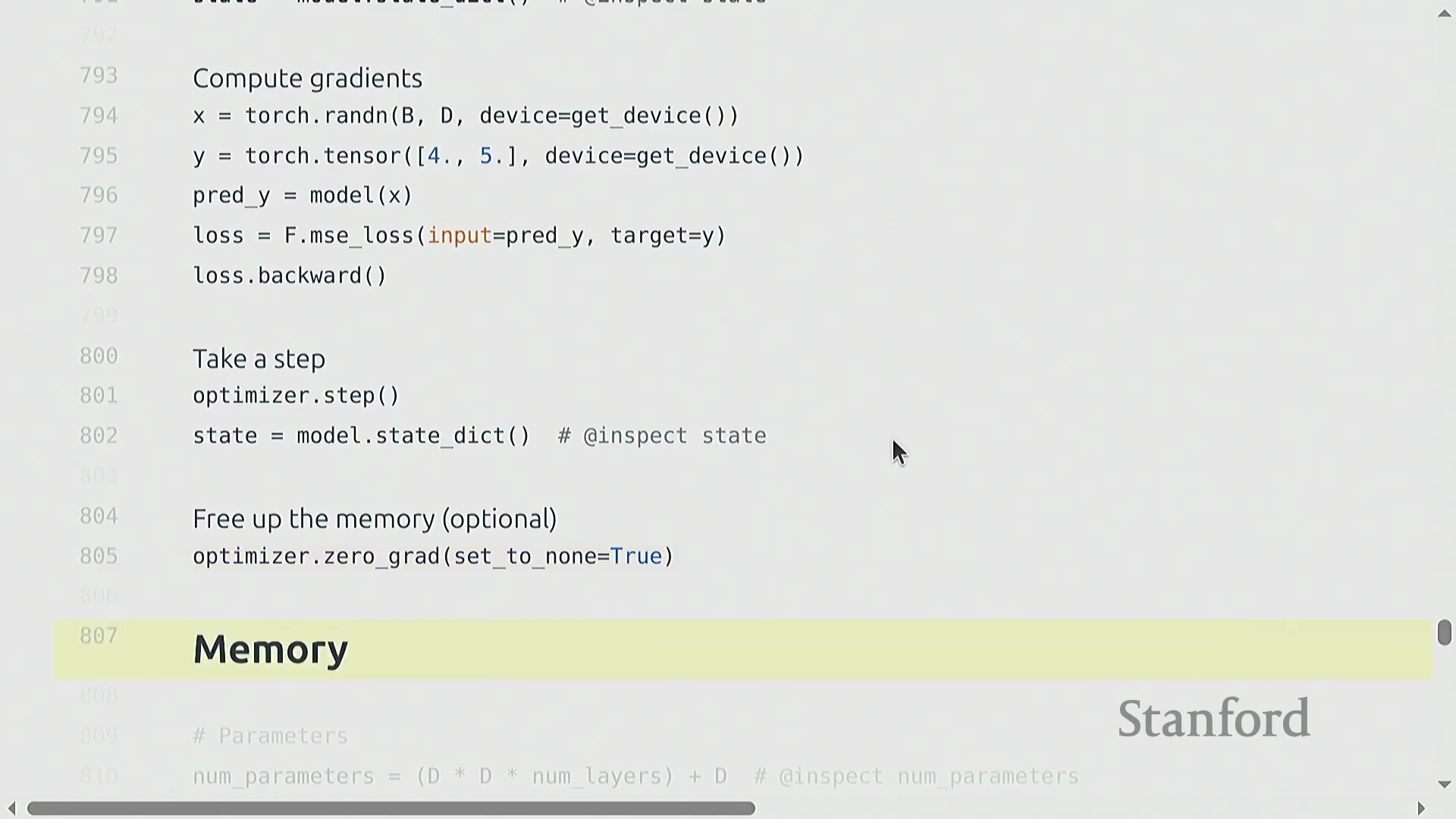
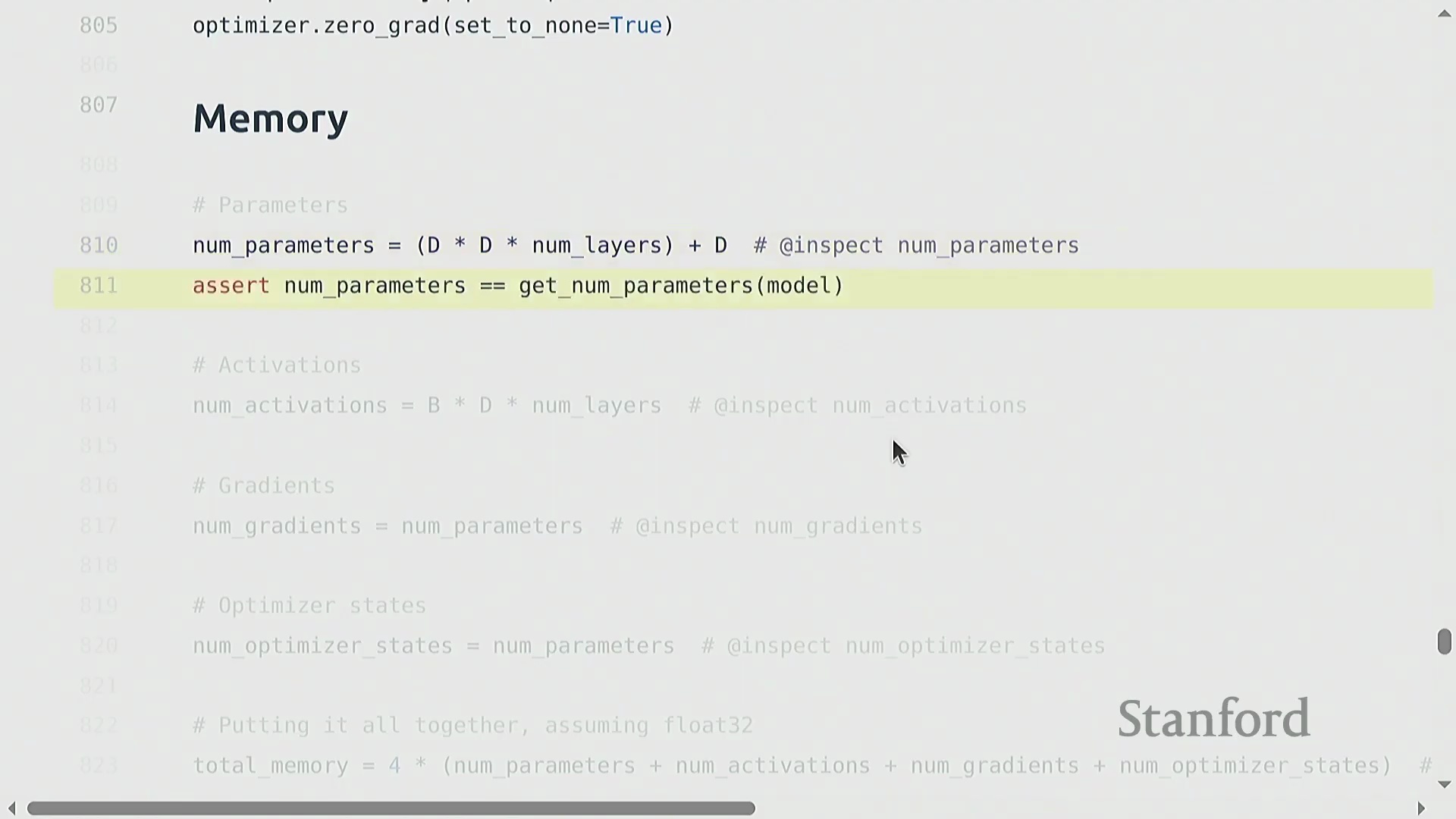
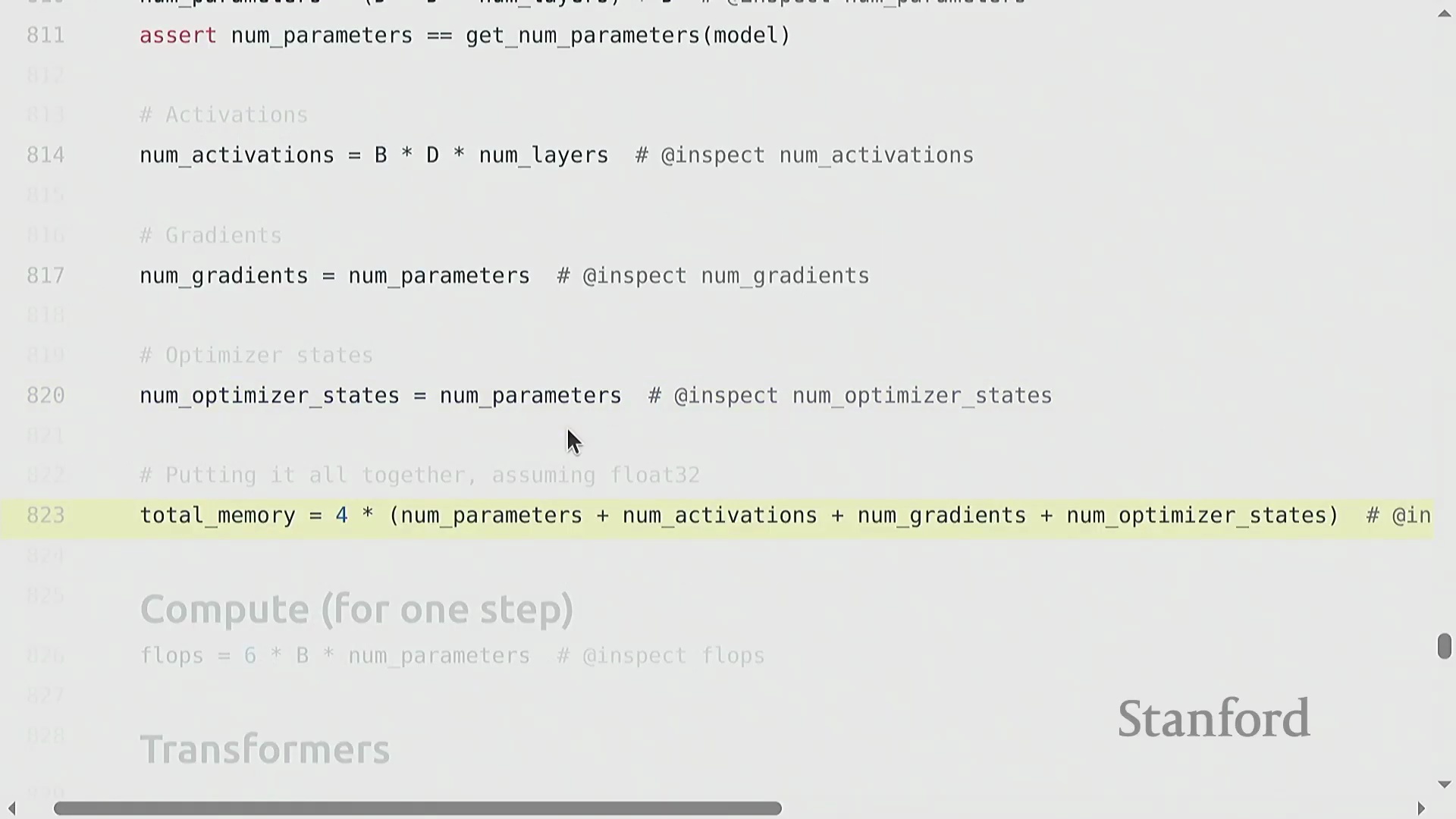
全面的内存核算
对 GPU 显存(GPU Memory)消耗进行严格拆解,可归纳为四大核心组成部分:模型参数(Parameters)、激活值(Activations)、梯度(Gradients)以及优化器状态(Optimizer State)。对于多层线性模型,参数内存随 d² × layers 线性增长。激活值在前向传播(Forward Pass)期间必须被缓存(Cached),以便在反向传播时计算导数,其内存占用随 batch_size × d × layers 扩展。梯度的形状(Shape)与对应参数完全一致。Adagrad 等优化器通过维护额外的状态张量(如平方梯度累积值)引入了显著开销,通常会使参数相关的内存占用翻倍。将上述所有组件的总量乘以数据类型的字节大小(FP32 为 4 字节),即可精确估算出模型的内存需求。

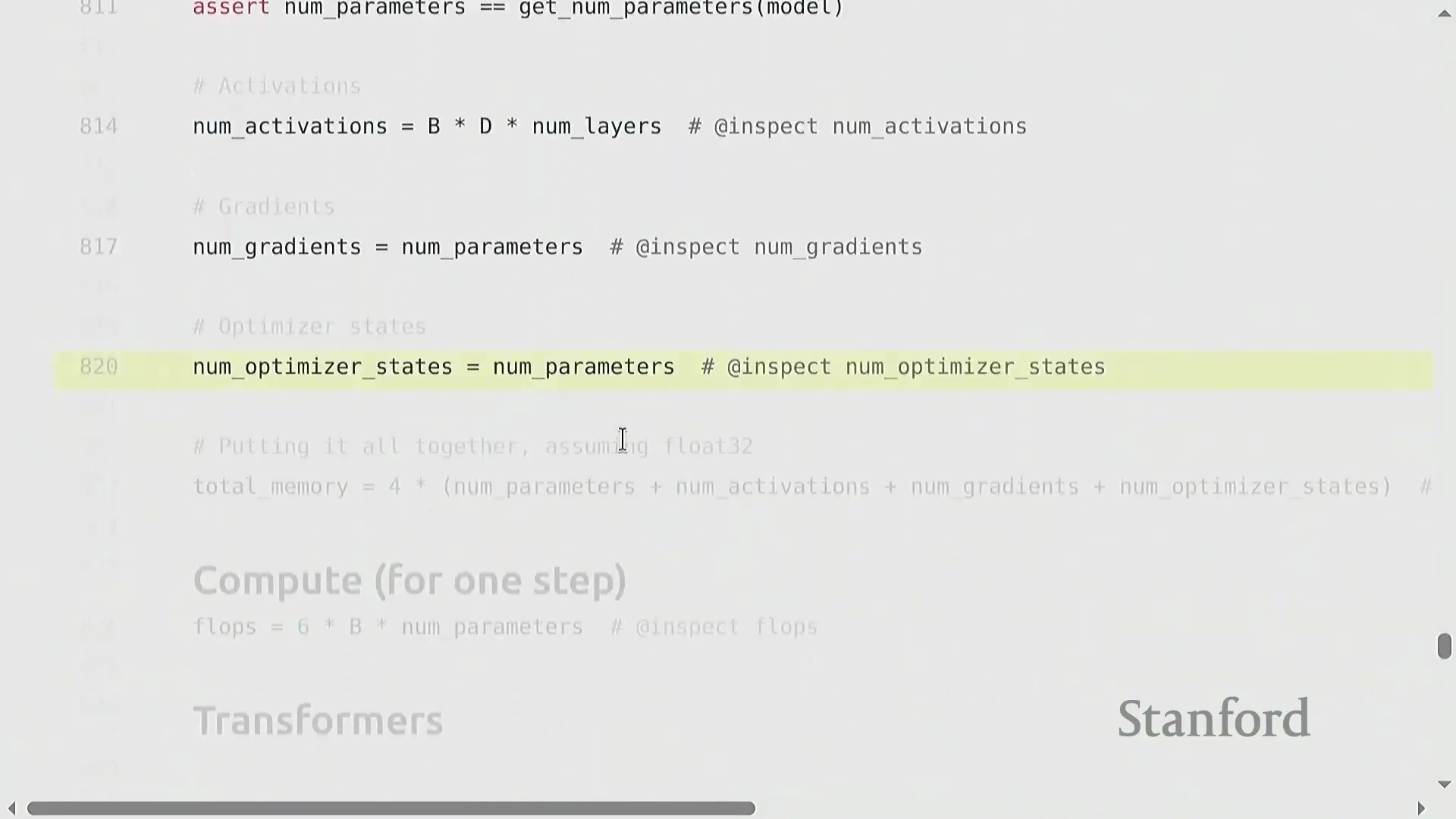
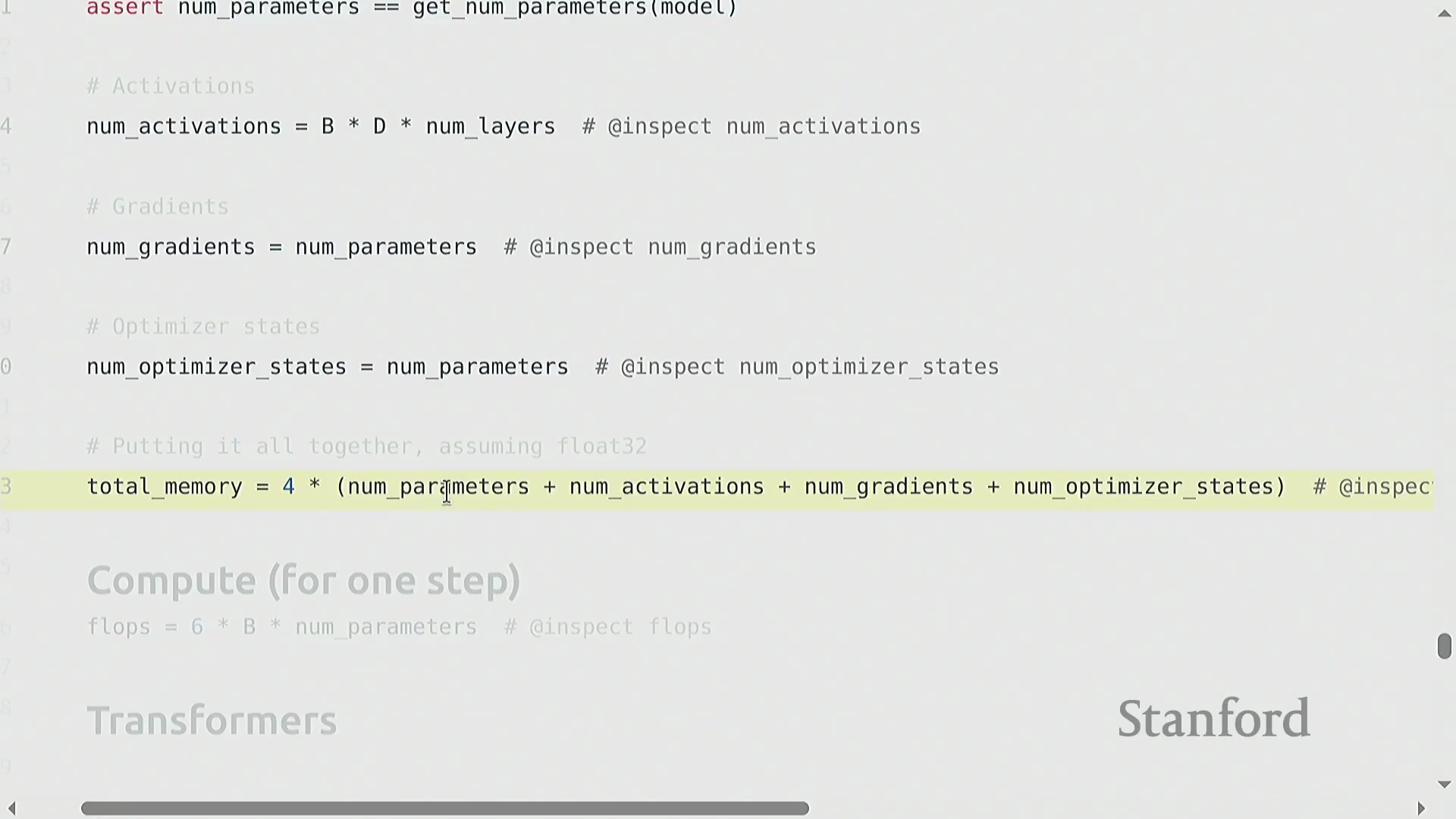
6x FLOP 法则与激活检查点
结合前向传播(2 × 参数量 × 词元量)与反向传播(4 × 参数量 × 词元量),我们确立了训练过程的基础计算量公式:6 × 参数量 × 词元量。这一“餐巾纸数学(Napkin Math)”基准能够可靠地估算绝大多数模型架构的总计算成本。初学者常对为何必须在前向传播中缓存激活值感到困惑。根据链式法则(Chain Rule),这是严格必要的,因为每一层的梯度计算均高度依赖其前向传播的输出值。然而,可通过激活检查点(Activation Checkpointing)(亦称重计算技术)来有效缓解显存瓶颈。该高级优化策略会在前向传播后主动丢弃中间激活值,并在反向传播阶段按需重新计算,从而巧妙地以少量的额外计算开销换取显著的内存空间节省。



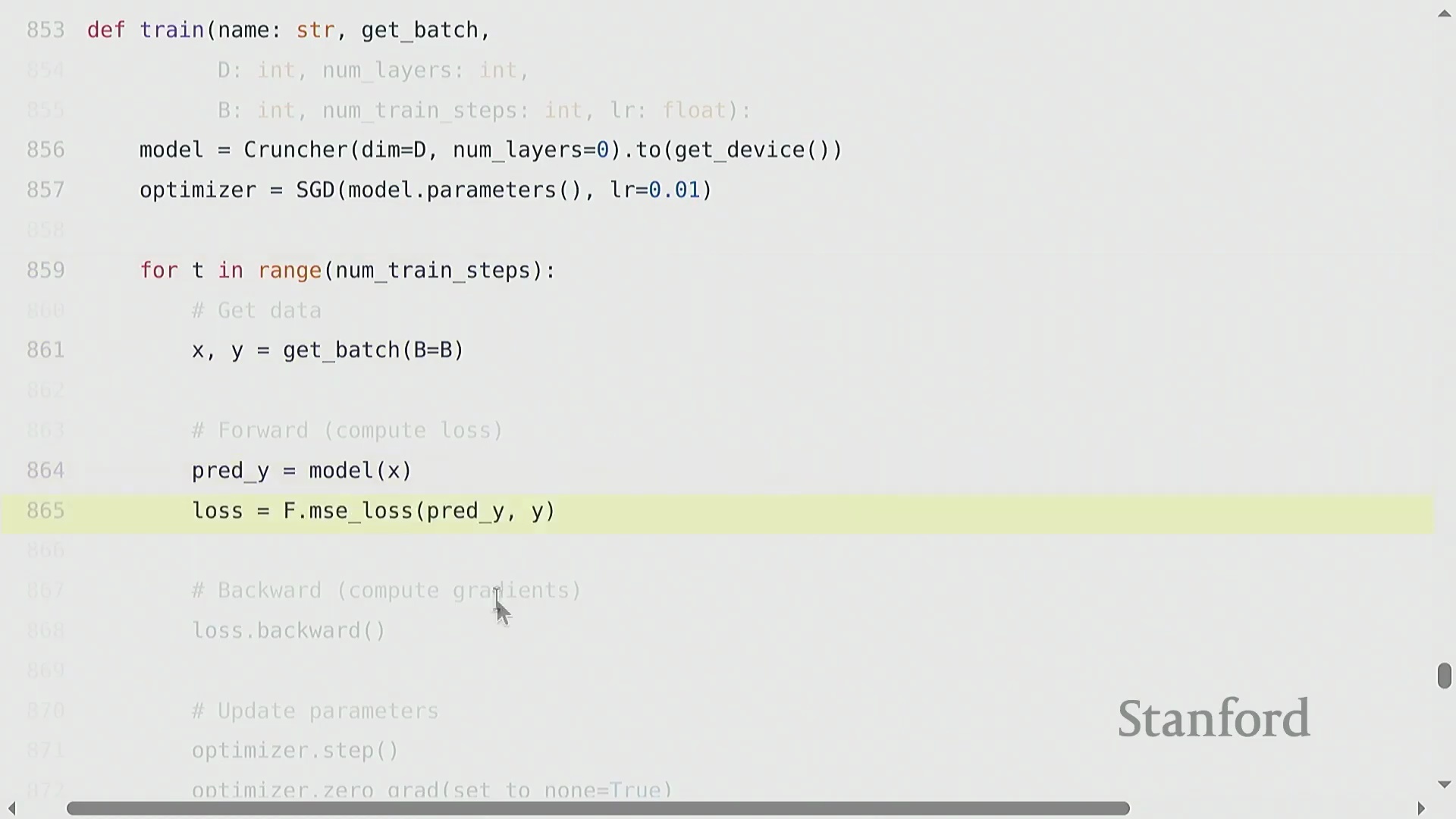
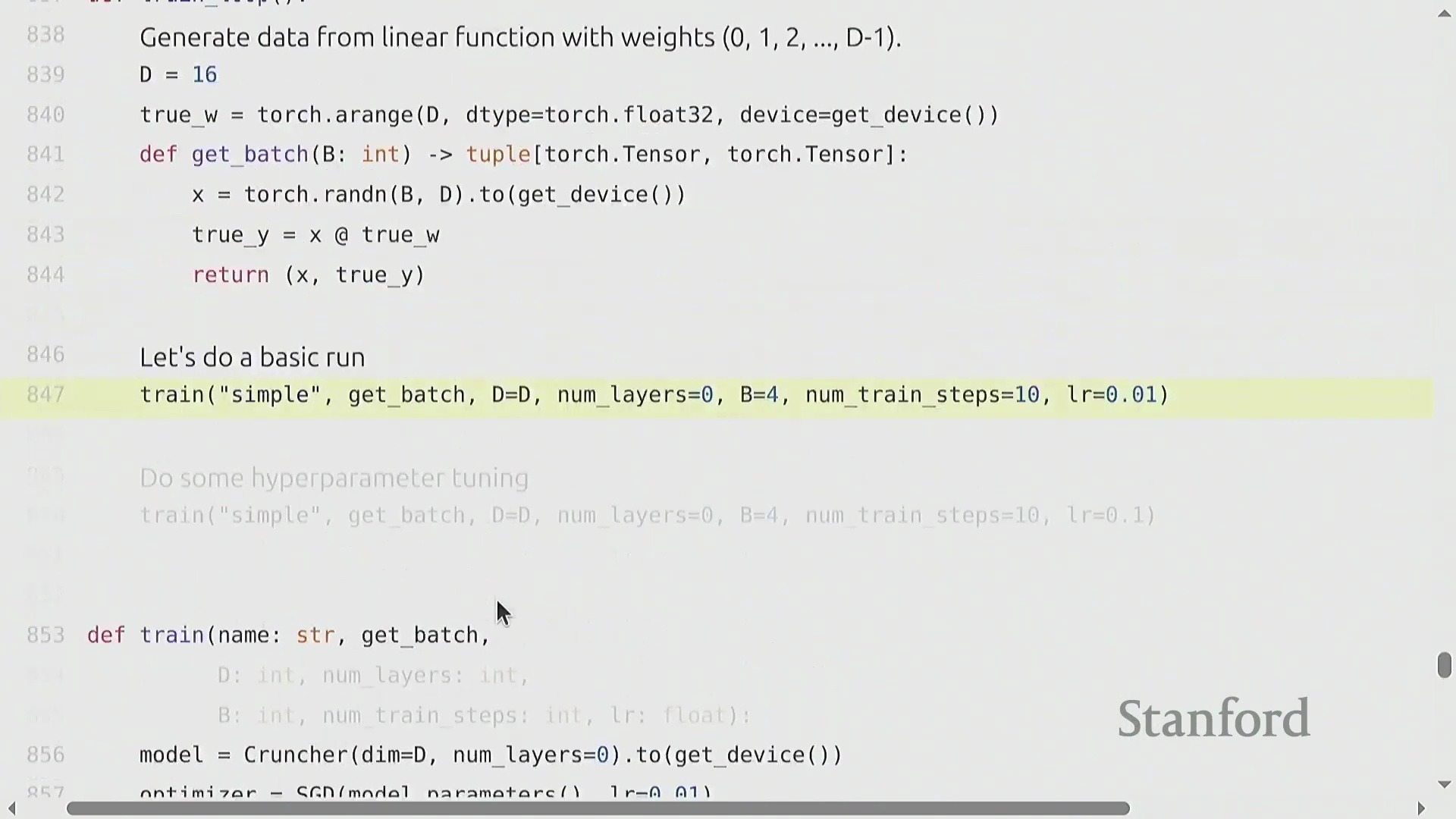
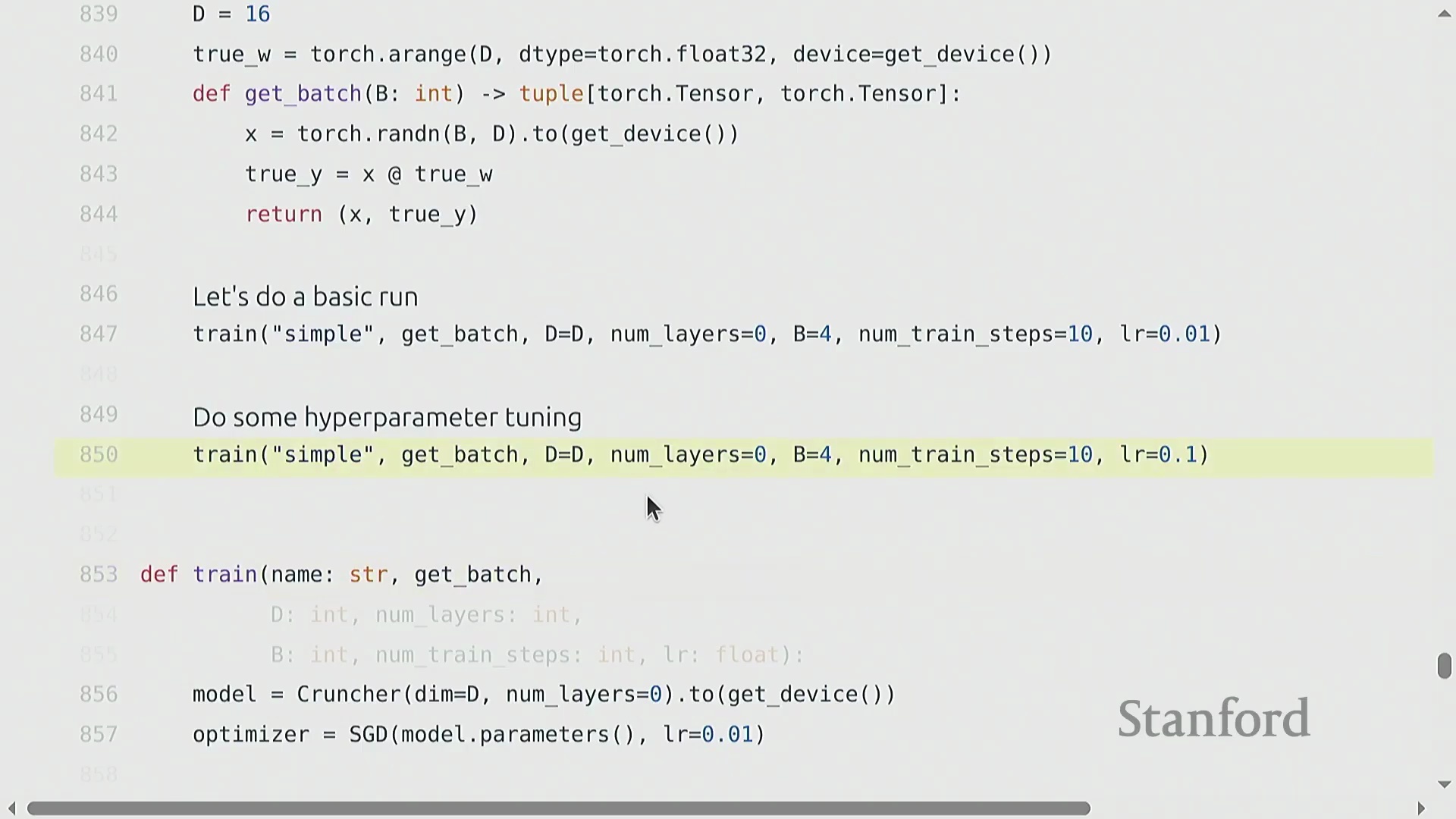
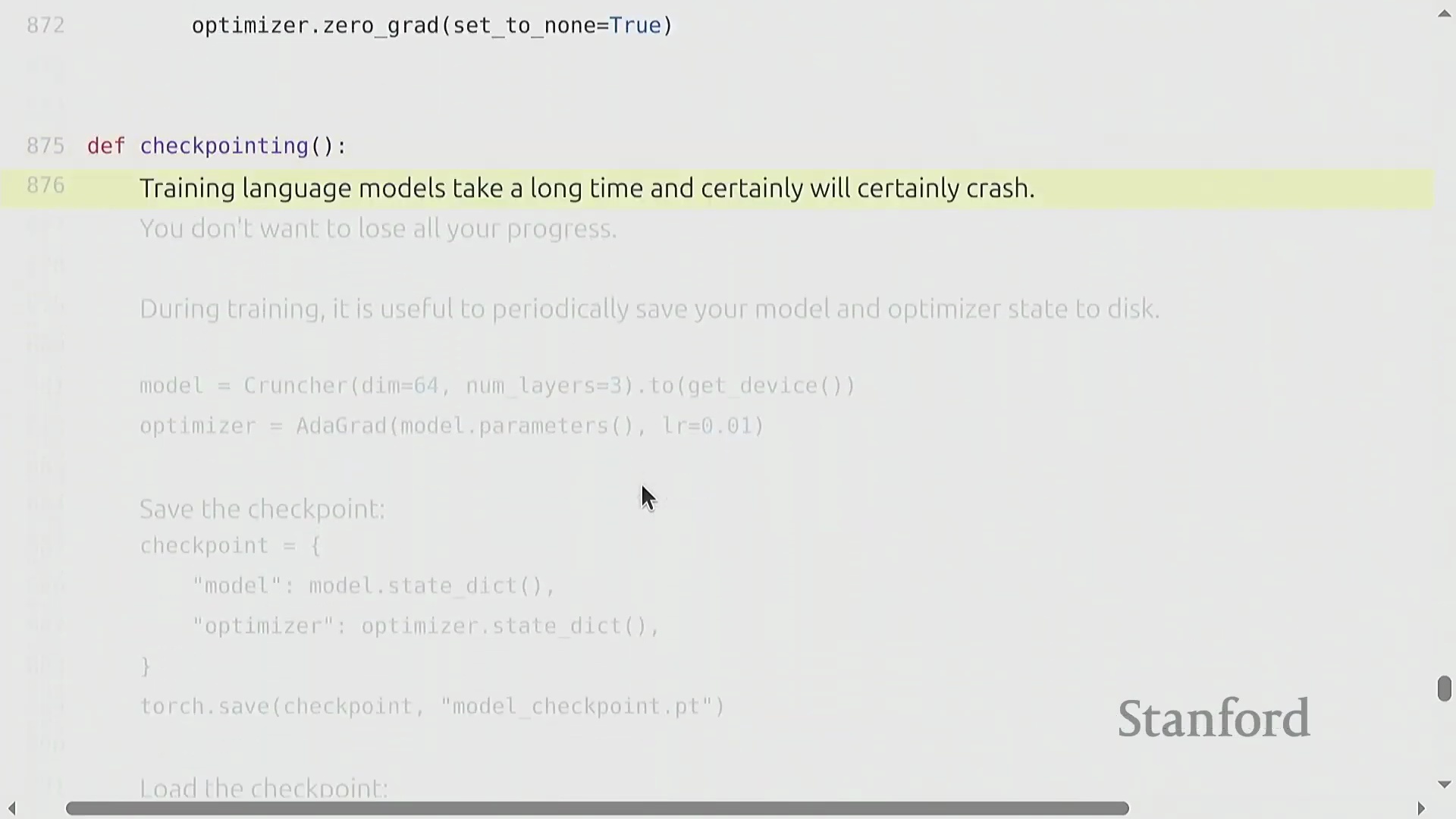
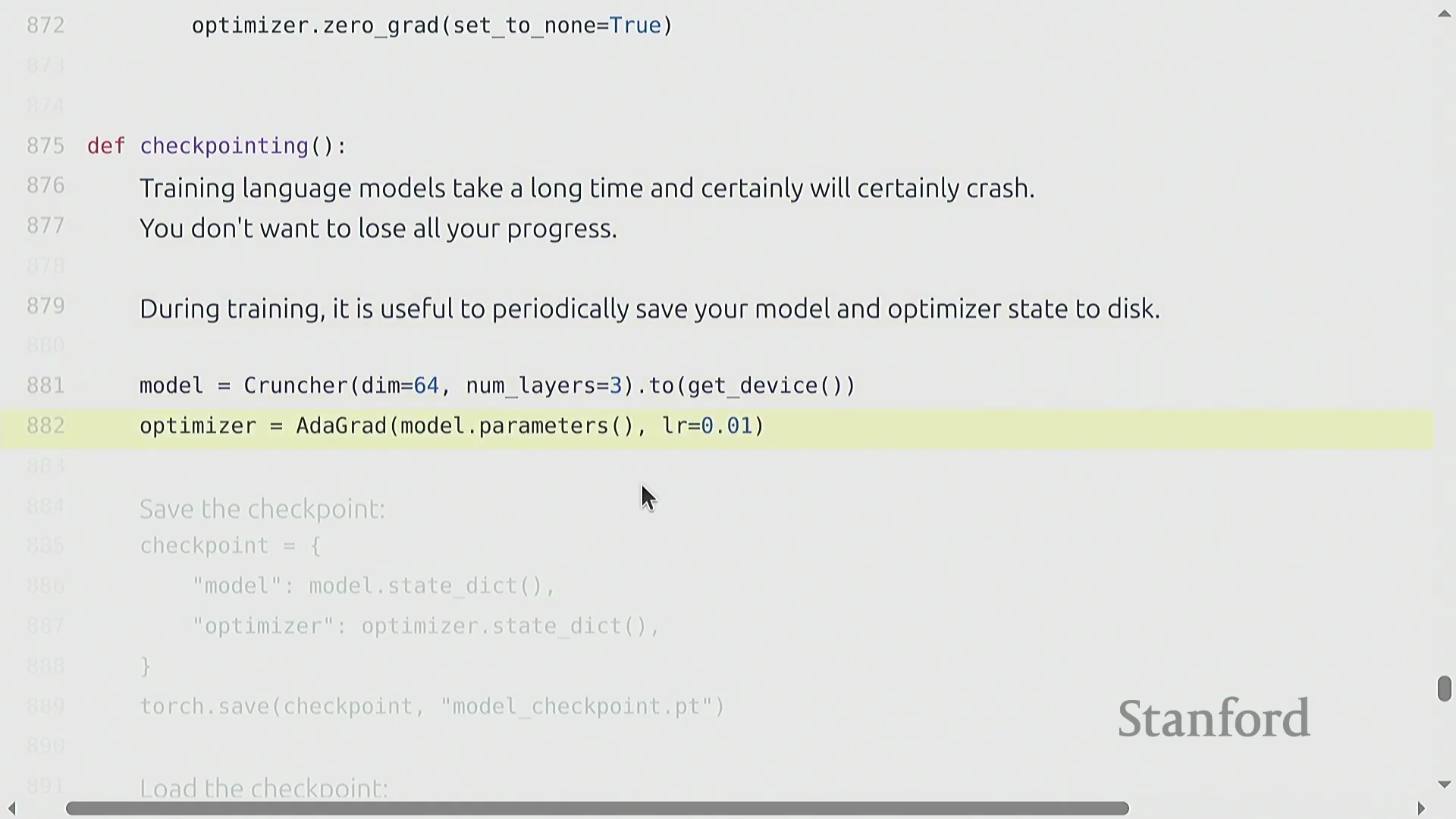
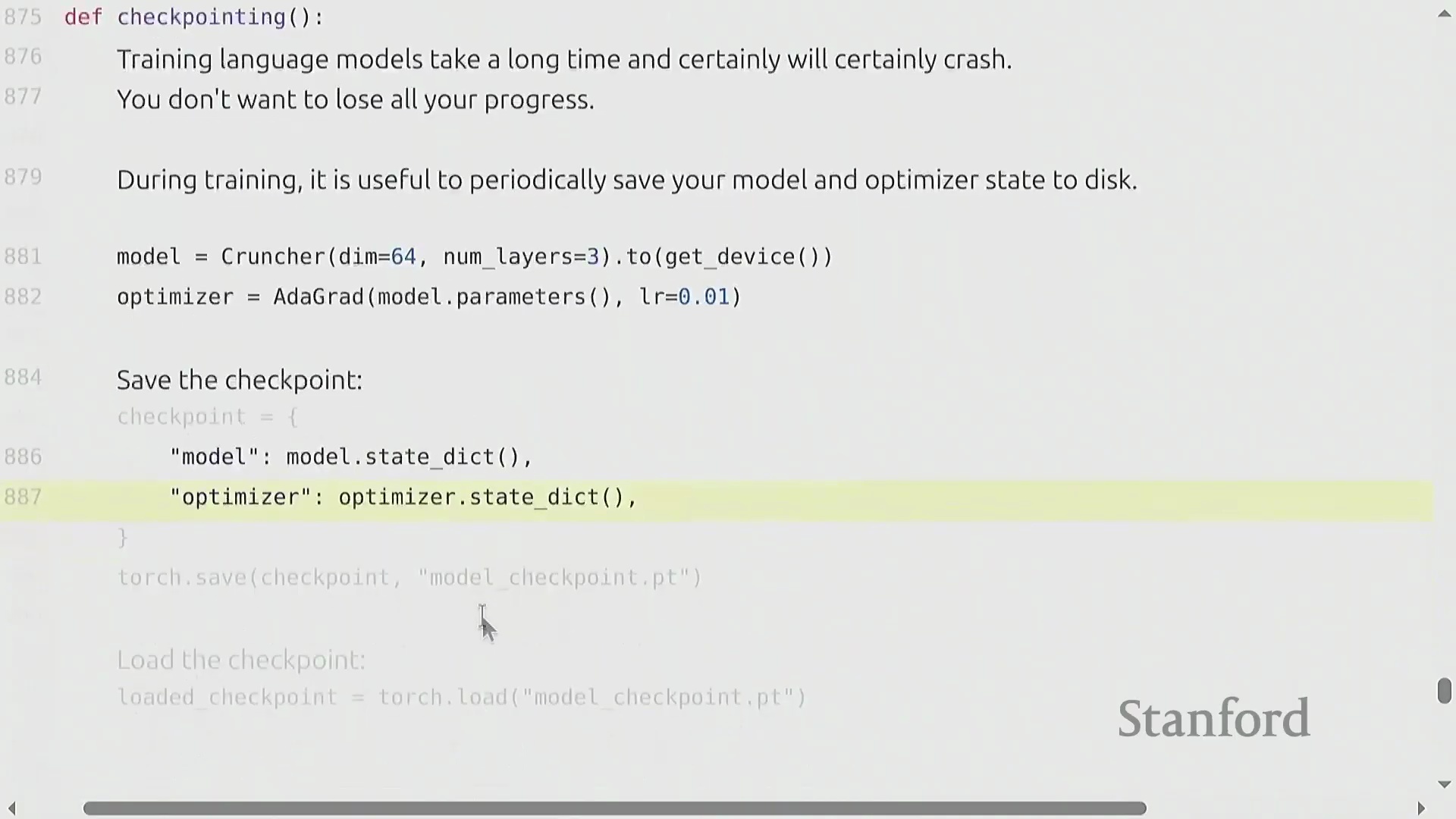
标准训练循环与稳健的检查点机制
核心训练流水线(Training Pipeline)遵循高度标准化的循环逻辑:初始化模型与优化器,加载数据批次(Batch),执行前向传播以计算损失(Loss),调用 backward() 自动填充参数的 .grad 张量,最后执行 optimizer.step() 完成权重更新。鉴于大模型训练往往耗时数天至数周,且极易受硬件故障或软件异常中断,稳健的检查点机制(Checkpointing)不可或缺。最佳实践(Best Practice)要求定期持久化保存的不仅是模型的权重状态字典(state_dict),还必须包含优化器状态、学习率调度器(Learning Rate Scheduler)状态以及当前的全局迭代步数(Global Step)。此类完整快照(Snapshot)可确保训练任务在遭遇中断后,能够从精确的断点处无缝、无损地恢复(Resume)。

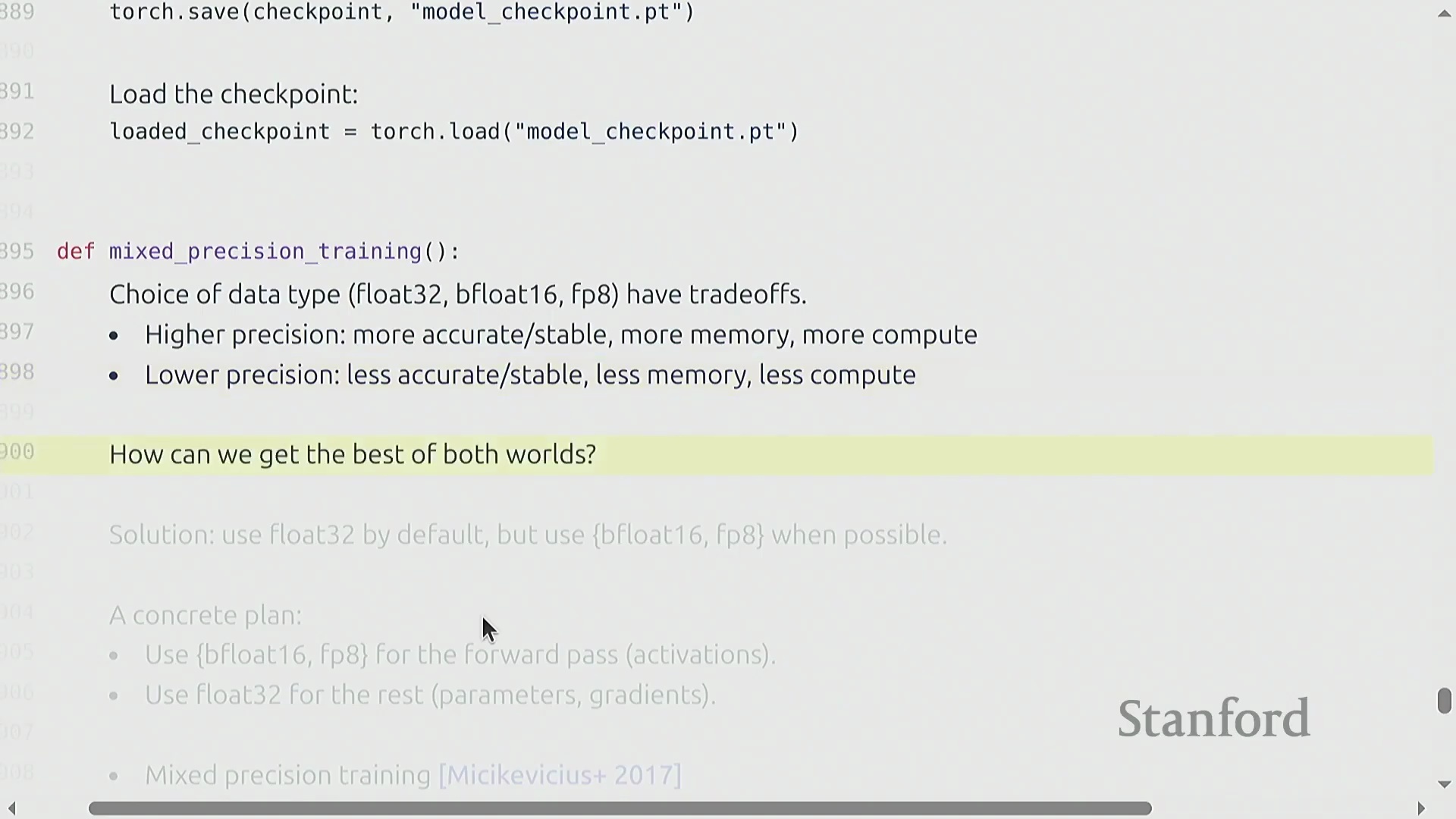
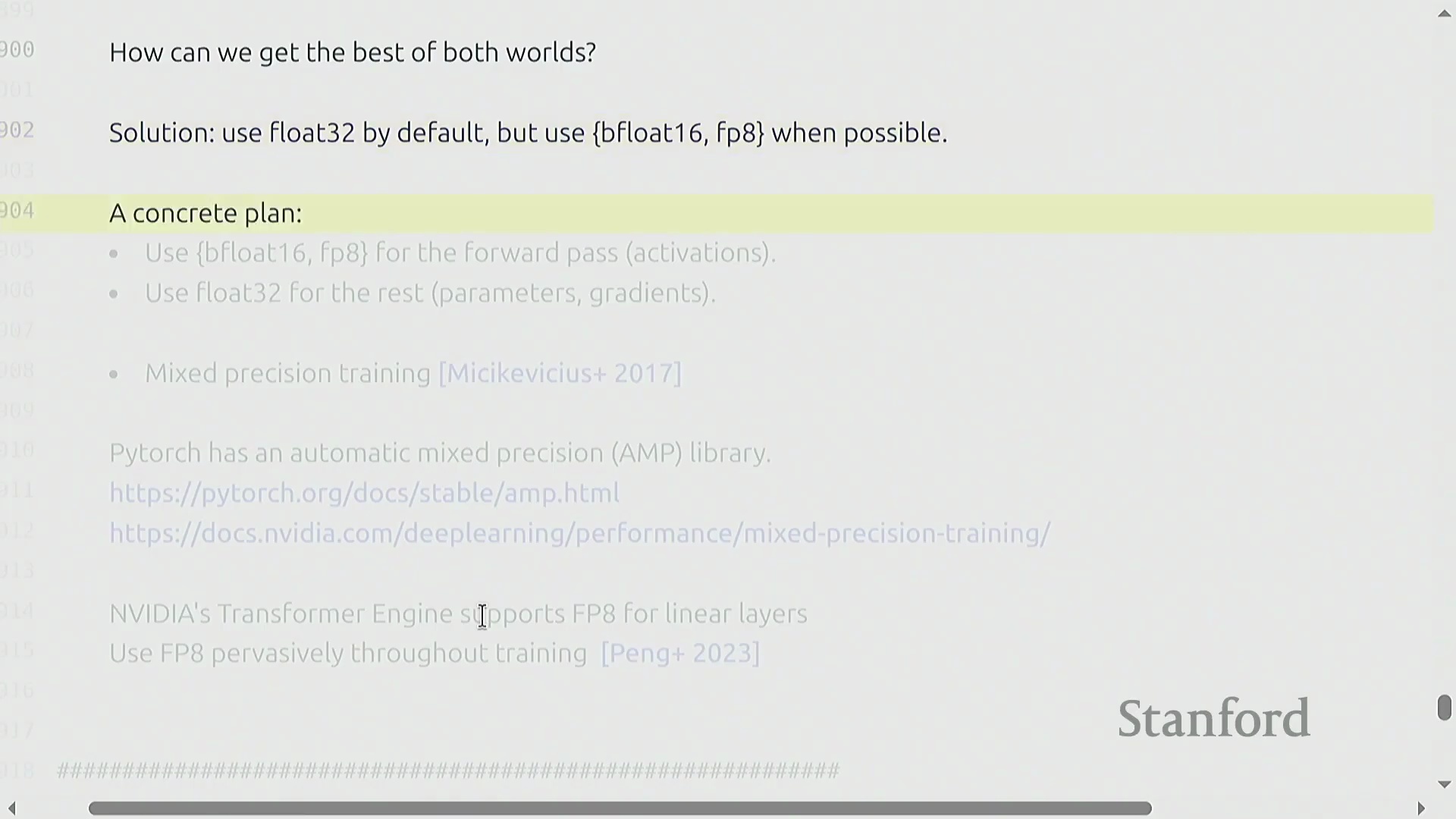
混合精度策略与 PyTorch 自动化
数值精度(Numerical Precision)的选取涉及一项基础的工程权衡(Trade-off):高精度格式(如 FP32)可保障训练稳定性,而低精度格式(如 BF16、FP8)则能大幅提升计算吞吐量并将内存占用减半。现代训练流水线普遍采用混合精度训练(Mixed Precision Training)策略:通常保留 FP32 格式的主权重(Master Weights)与优化器状态以维持数值稳定,同时将激活值及前向/反向传播的计算过程降级至 BF16。PyTorch 提供的自动混合精度(Automatic Mixed Precision, AMP) 工具包将底层复杂性进行了高度抽象,开发者无需在代码中手动执行类型转换,框架即可自动、动态地管理数据精度。自 2017 年起,该方案已成为业界标准实践,也是充分释放现代 GPU 张量核心(Tensor Cores)算力的必备条件。


突破精度极限与最终总结
当前领域正持续探索低精度训练的边界(Limit)。最新研究证实,采用 FP8 甚至 INT4 格式进行模型训练已切实可行,但这高度依赖复杂的数值稳定技术(Numerical Stability Techniques)以防止梯度崩溃(Gradient Collapse)或训练发散。这一技术演进深刻体现了系统工程(Systems Engineering)与模型架构设计之间的重要协同效应:现代神经网络架构在研发初期,便日益注重与底层硬件特性的协同优化(Co-design)。此外,必须严格区分训练(Training)与推理(Inference)阶段的不同需求;尽管在超低精度下直接训练模型极具挑战,但训练后量化(Post-Training Quantization, PTQ) 等技术已允许模型在保持性能损失极小的前提下,实现深度的量化部署。本讲至此系统梳理了从底层张量操作(Tensor Operations)、资源核算到完整训练循环的核心原理,为后续作业中将上述理论应用于完整 Transformer(Transformer) 架构的实践奠定了坚实基础。