ERaftGroup
课程介绍与教学理念
欢迎来到 CS336《从零构建语言模型》(Language Models from Scratch)。本课程旨在引导你完整实践语言模型的构建全流程,涵盖从数据系统(Data System)到模型训练(Model Training)的各个环节。Percy 与 Tatsu 两位主讲教师,以及 Roman 和 Marcel 等助教团队,共同强调了一个核心理念:若要真正理解人工智能(Artificial Intelligence),你必须亲手构建它。本学期课程规模已显著扩大,助教人数增加了 50%,且所有讲座视频均将在 YouTube 上公开,以促进深度技术知识的普及。






弥合研究鸿沟
为何要专门开设一门从零构建模型的课程?当前,人工智能(AI)研究界正面临与底层技术日益脱节的风险。尽管提示词交互(Prompting)等高级抽象方法释放了新的模型能力并大幅降低了入门门槛,但这些抽象在本质上属于“泄漏抽象”(Leaky Abstractions)。与传统编程或操作系统不同,黑盒模型(Black-box Models)对其内部运行机制几乎不提供任何透明度。前沿的 AI 基础研究依然要求对数据、计算系统(Systems)和模型架构(Architectures)具备全栈式(Full-stack)的深入理解。设立本课程正是为了夯实这些基础技术栈,并贯彻一项核心理念:唯有亲手构建系统,方能真正理解其原理。





前沿模型规模的现实
现代 AI 教育面临的一大挑战在于语言模型的快速工业化(Industrialization)与规模化(Scale)。据报道,GPT-4 等前沿模型(Frontier Models)参数量已达数万亿级别,训练成本高达数亿美元,且高度依赖庞大的专有 GPU 集群(Proprietary GPU Clusters)。此外,出于商业竞争与安全考量,科技公司极少公开其模型架构或训练细节。因此,在学术环境中复现并训练尖端模型完全不具现实可行性。尽管本课程将专注于构建较小规模的模型,但必须明确指出:小规模模型(Small-scale Models)的行为规律与扩展特性,往往无法直接外推(Extrapolate)至超大规模模型。



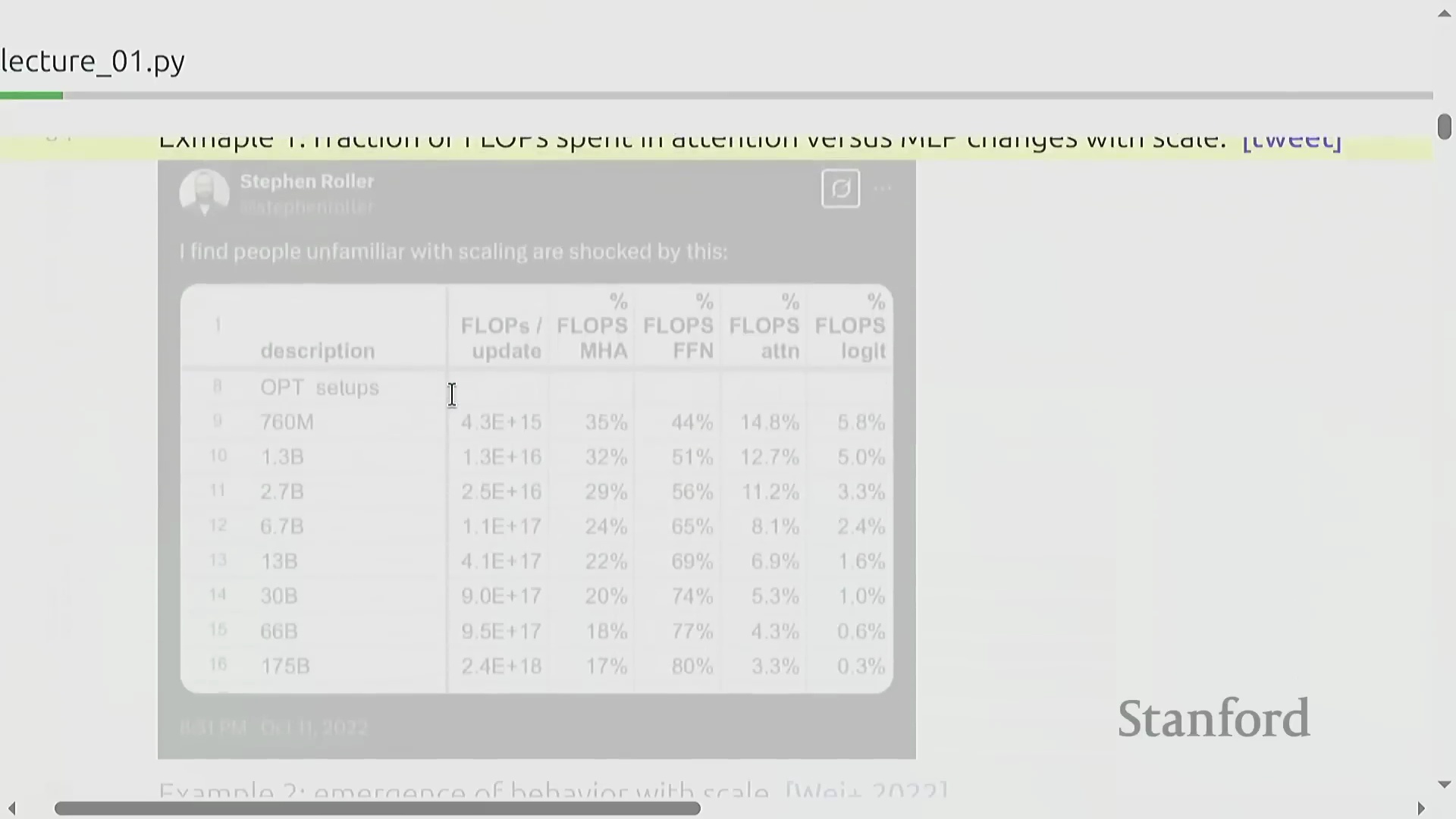
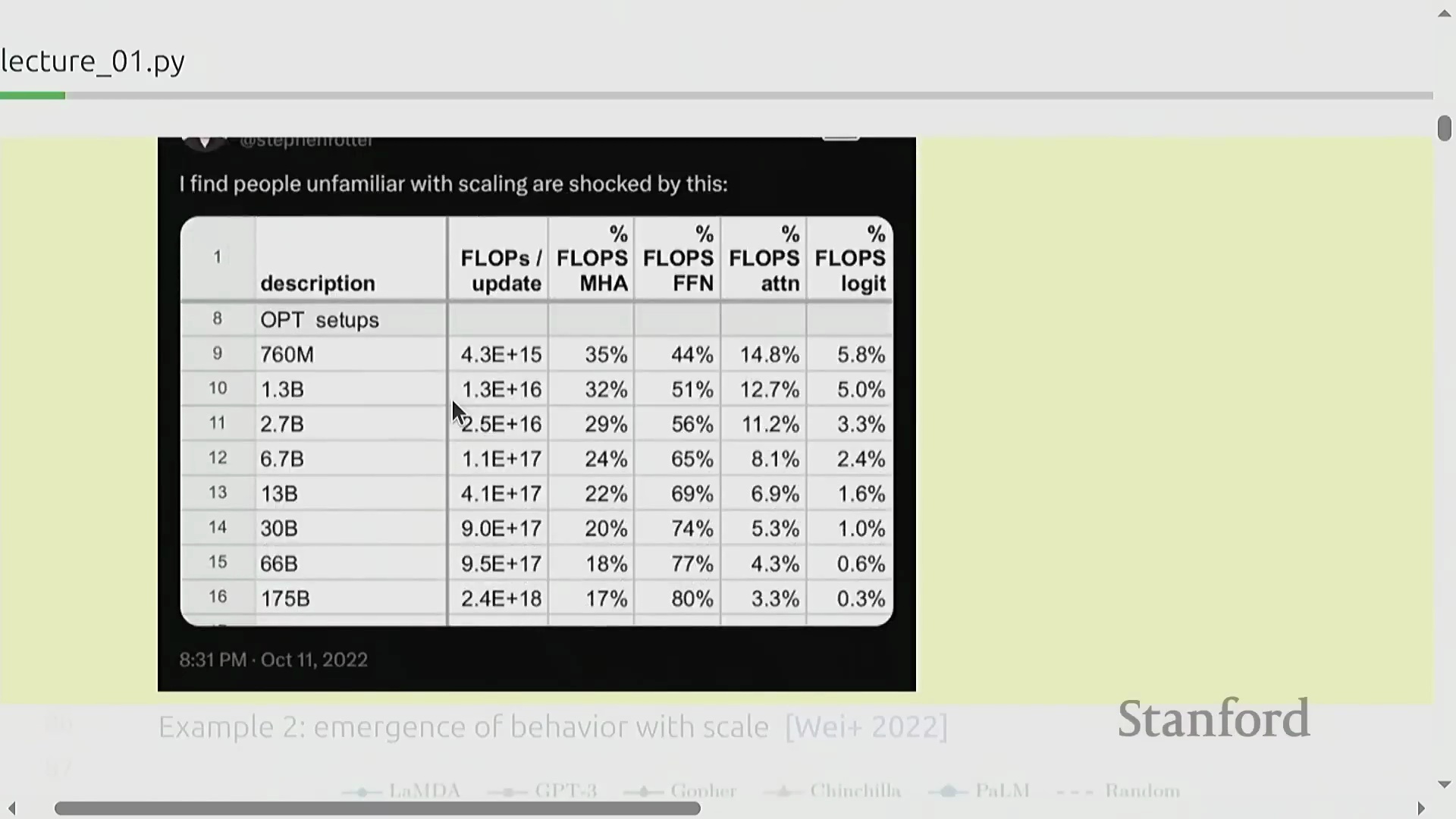
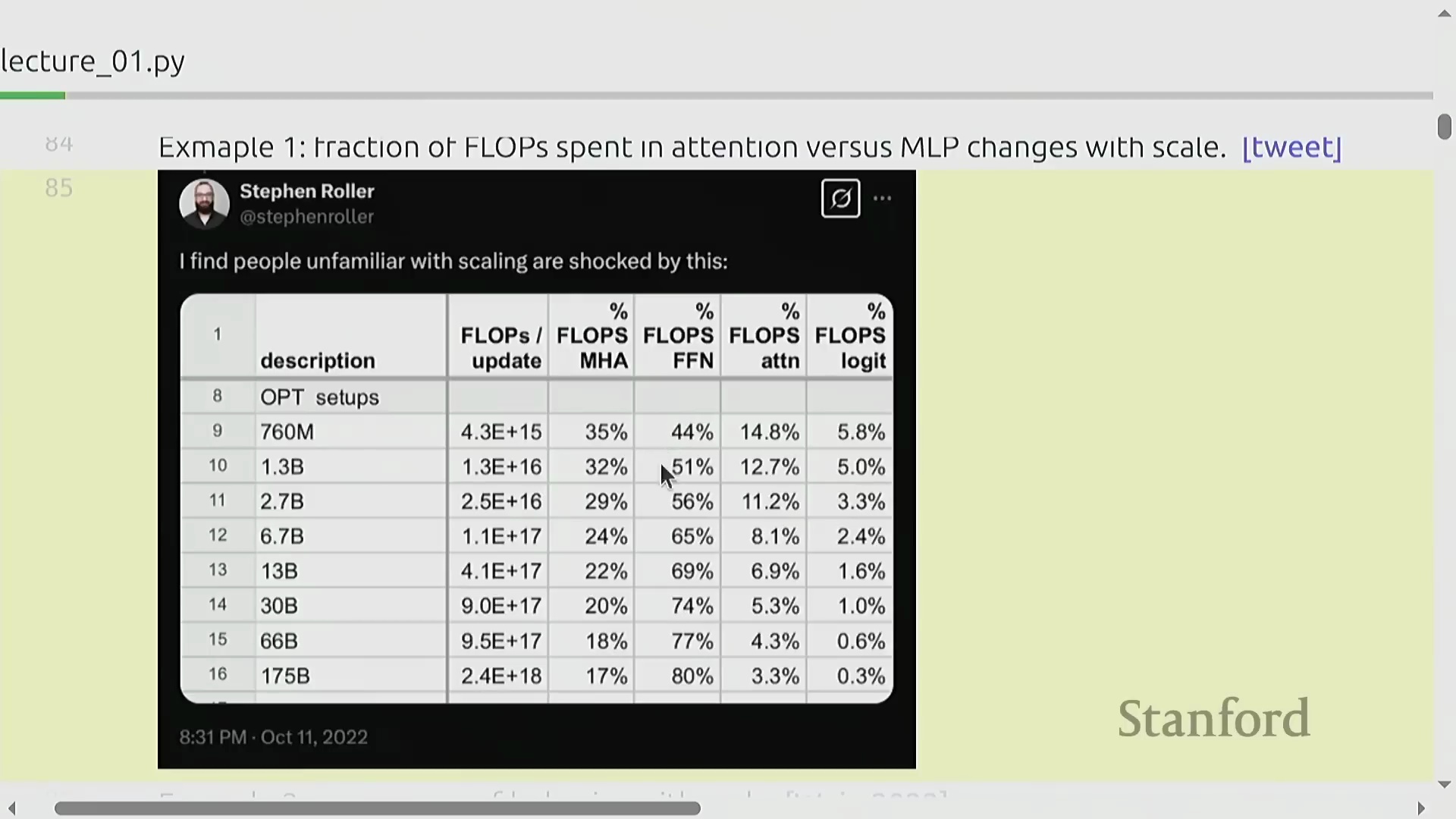
为何小模型的性能并非总是线性扩展
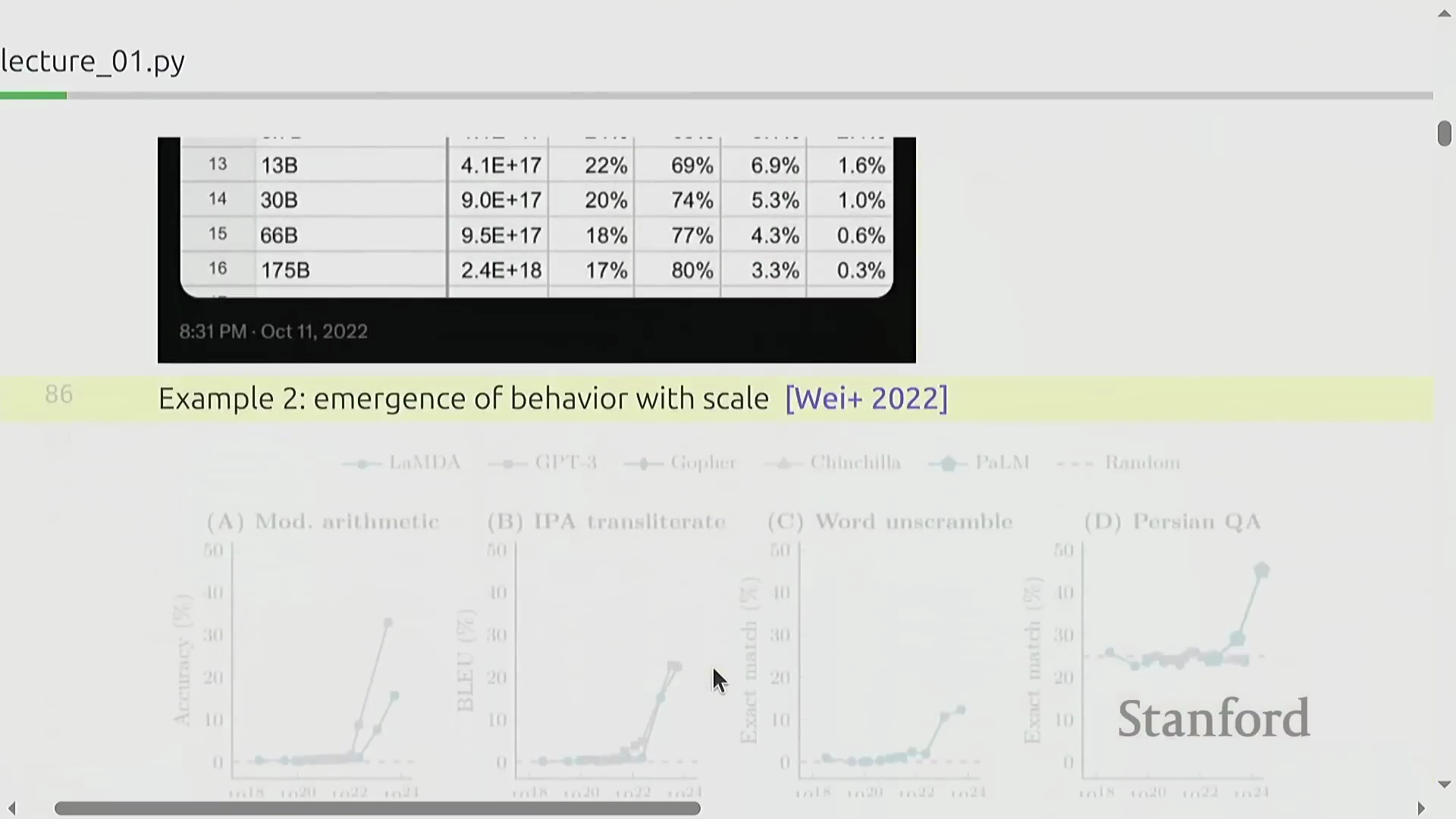
深入理解 AI 需要准确认识到计算瓶颈与模型能力如何随规模动态变化。在小规模模型中,浮点运算次数(FLOPs)大致均匀分配于注意力层(Attention Layers)与多层感知机层(Multilayer Perceptron, MLP)之间;但在前沿规模下,MLP 层的计算开销将占据绝对主导地位。因此,在小规模阶段过度优化注意力机制可能会偏离正确的研究方向。此外,诸如上下文学习(In-context Learning)等许多高级能力均属于涌现能力(Emergent Abilities):它们在模型跨越特定的算力阈值之前,通常会保持隐匿状态。若仅局限于研究小模型,极易得出某些技术“无效”的错误结论,这也进一步凸显了严肃对待规模扩展规律(Scaling Dynamics)的必要性。

核心学习目标:底层机制、思维方式与直觉认知
尽管受限于计算规模,本课程仍致力于传授三类核心知识。首先是底层机制(Mechanics):你将系统学习 AI 的基础构建模块,亲手实现 Transformer 等核心架构,并掌握模型并行(Model Parallelism)等面向硬件的高效优化技术。其次是思维方式(Mindset):我们将培养“规模优先”(Scaling-first)的工程思维,专注于从现有硬件中压榨极致性能,并将算力扩展视为推动 AI 研究的首要驱动力。最后是直觉认知(Intuitions):我们将深入探讨数据选择与架构设计决策如何影响模型质量。尽管此部分内容存在一定局限性——因为小规模环境下的最优配置往往无法直接迁移至大规模模型——但扎实掌握前两大领域,将为你未来的研究与工程实践奠定坚实基础。



经验现实与真正的“苦涩教训”
人工智能的发展具有极强的经验性(Empirical Nature)。尽管许多架构设计选择背后均有理论支撑,但真正推动领域进步的往往是反复的实验验证(Experimental Validation)。例如,SwiGLU 激活函数(Activation Function)之所以被业界广泛采用,并非源于严密的数学推导,而是因为它在实验中始终能带来更优的性能表现——其原作者曾幽默地将这一经验性成果归功于“上帝的仁慈”。最后,我们需要澄清一个关于“苦涩教训”(Bitter Lesson)的常见误解。该理论并非断言算法设计无关紧要,或声称唯有资金投入才是决定性因素。其核心洞见在于:具备良好扩展性(Scalability)的算法才是实现技术突破的关键。将精妙的算法设计与海量算力(Compute)深度融合,而非孤立依赖单一要素,始终是推动 AI 持续演进的根本路径。





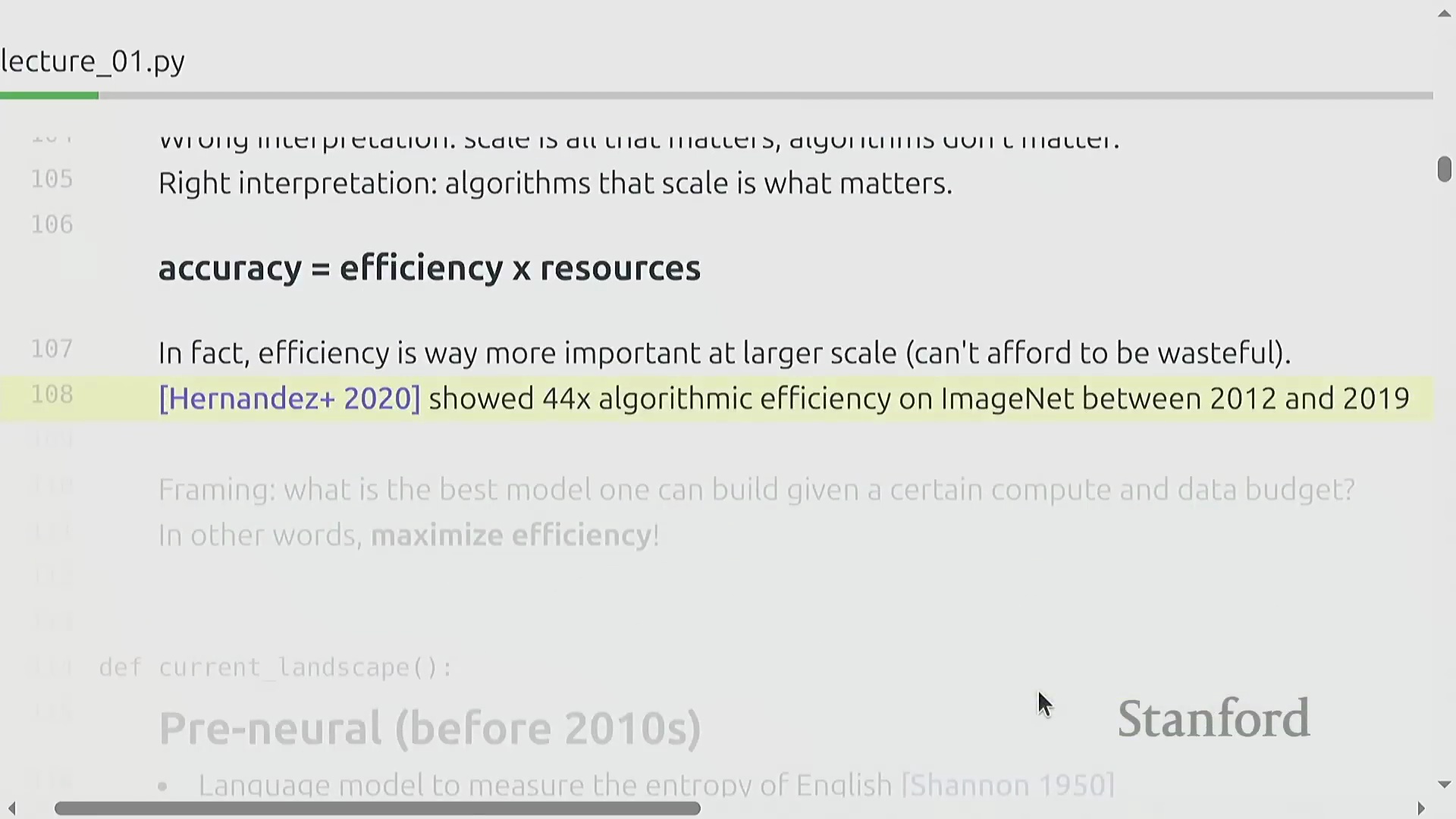
规模化下算法效率的关键作用
模型的性能从根本上取决于算法效率(Algorithmic Efficiency)与计算资源(Compute)的投入。在耗资数亿美元的前沿模型(Frontier Models)训练规模下,效率的重要性呈指数级上升,这与可在本地环境中反复迭代调试(Local Iterative Debugging)的研究模式截然不同。与“单纯依靠扩大规模就能推动技术进步”的常见误解相反,历史上算法的改进速度始终快于硬件的演进。2020年的一项研究证实,2012年至2019年间算法效率提升了44倍,其增速甚至超越了摩尔定律(Moore’s Law)。这充分表明,若缺乏持续的算法优化,训练成本将变得难以承受。这也进一步证明,在追求模型规模的同时,算法创新依然不可或缺。




在固定算力预算下优化模型精度
理想的研究范式应从盲目追求无限扩展,转向解决一个约束优化问题(Constrained Optimization Problem):即在固定的算力预算(Compute Budget)与数据预算内,实现尽可能高的模型精度。无论研究机构规模大小,这一框架均具有普适性,因为它直接衡量了单位资源投入所产出的模型性能。尽管增加资金投入确实能训练出更强大的模型,但研究人员的核心目标始终是持续提升底层算法效率,从而在现实约束下最大化模型性能(Model Performance)。



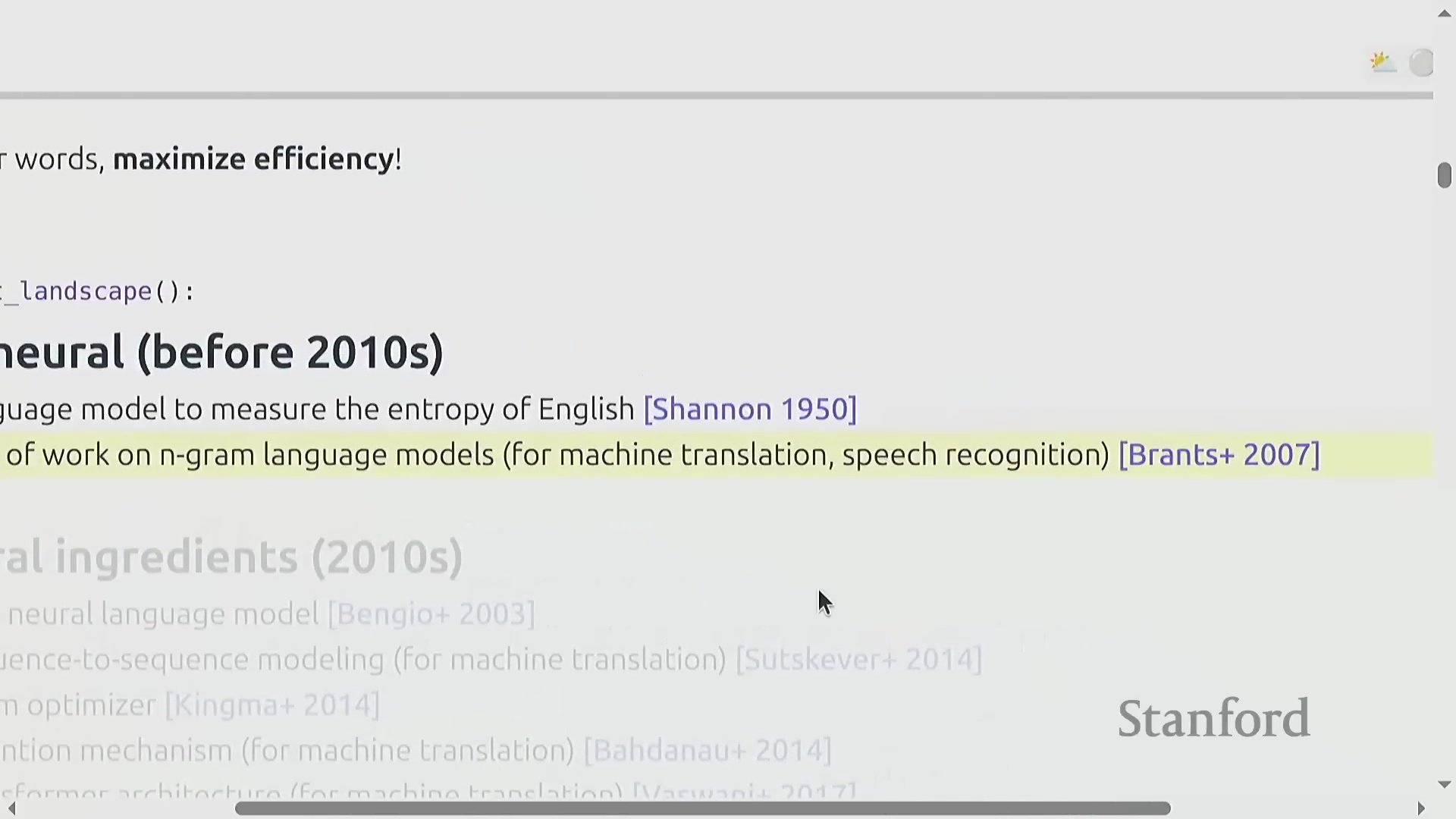
语言模型的历史渊源
语言模型(Language Models)的发展历史悠久,其起源可追溯至香农(Shannon)对英语信息熵(Information Entropy)的开创性估算工作。在历史上,这类模型主要作为机器翻译(Machine Translation)和语音识别(Speech Recognition)等更大规模自然语言处理(Natural Language Processing, NLP)系统的核心组件。值得注意的是,早在2007年,谷歌便使用超过两万亿词元(Token)的语料训练了庞大的5-gram模型,这一数据规模直到近年才被现代神经网络模型(Neural Network Models)追平。然而,这类基于统计的N-gram方法在模型架构深度上有所欠缺,无法展现出当今深度学习系统(Deep Learning Systems)所特有的涌现能力(Emergent Abilities)。


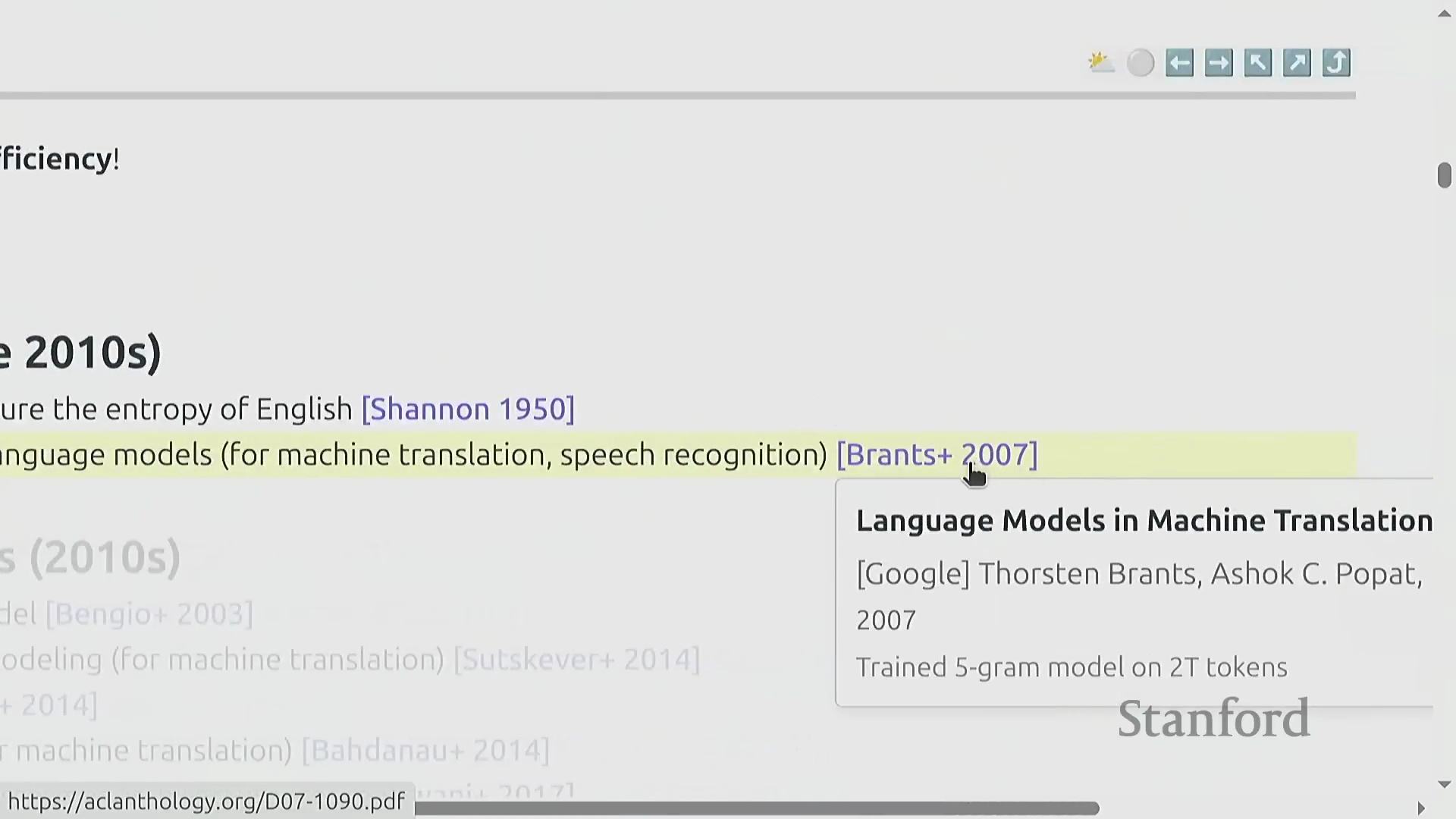
深度学习革命与核心要素
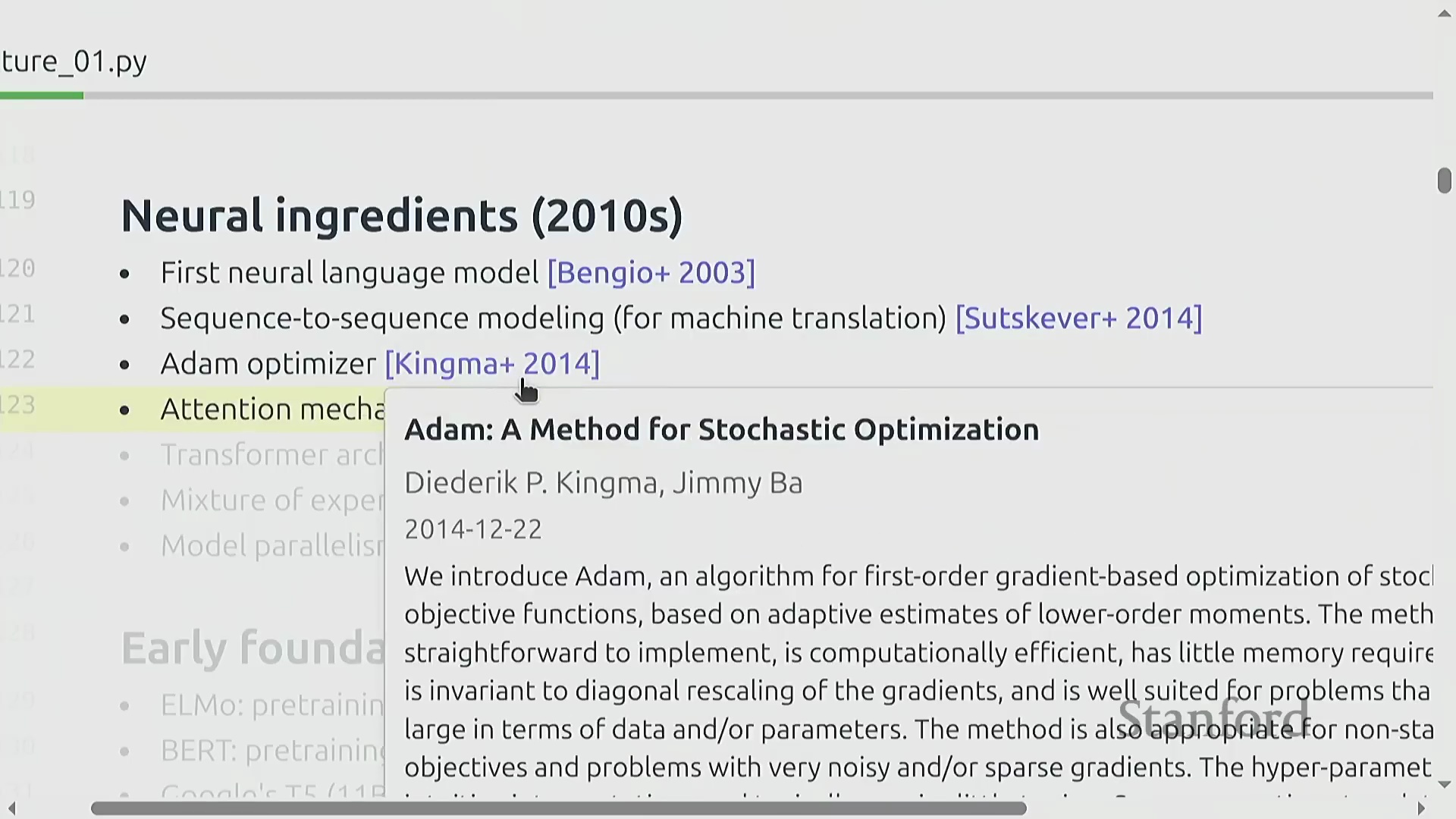
2010年代见证了深度学习(Deep Learning)革命,现代人工智能的核心基础组件在此期间逐步汇聚。关键的里程碑包括:首个神经网络语言模型(Neural Network Language Model, 2003年)、序列到序列(Sequence-to-Sequence, Seq2Seq)架构、至今仍被广泛使用的Adam优化器(Adam Optimizer),以及最初为机器翻译研发的注意力机制(Attention Mechanism)。这些技术突破最终在2017年发表的Transformer架构论文中达到了集大成的高潮。与此同时,研究人员开始探索混合专家模型(Mixture of Experts, MoE),并率先开创了模型并行(Model Parallelism)技术,成功训练出千亿参数模型以完成概念验证(Proof of Concept)。至2020年,构建现代大语言模型(Large Language Models, LLMs)所需的所有核心技术要素在理论上已全部齐备。
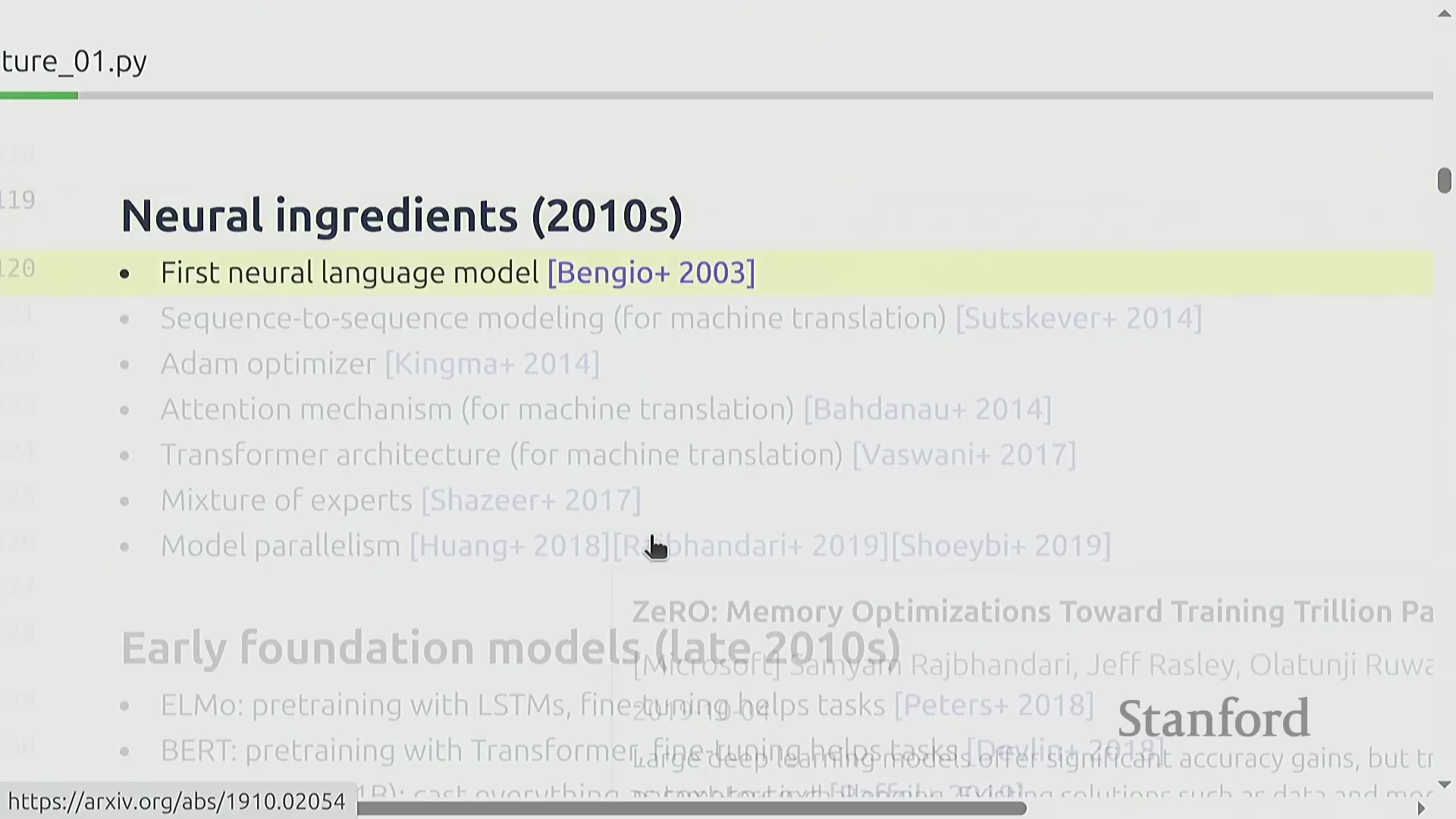
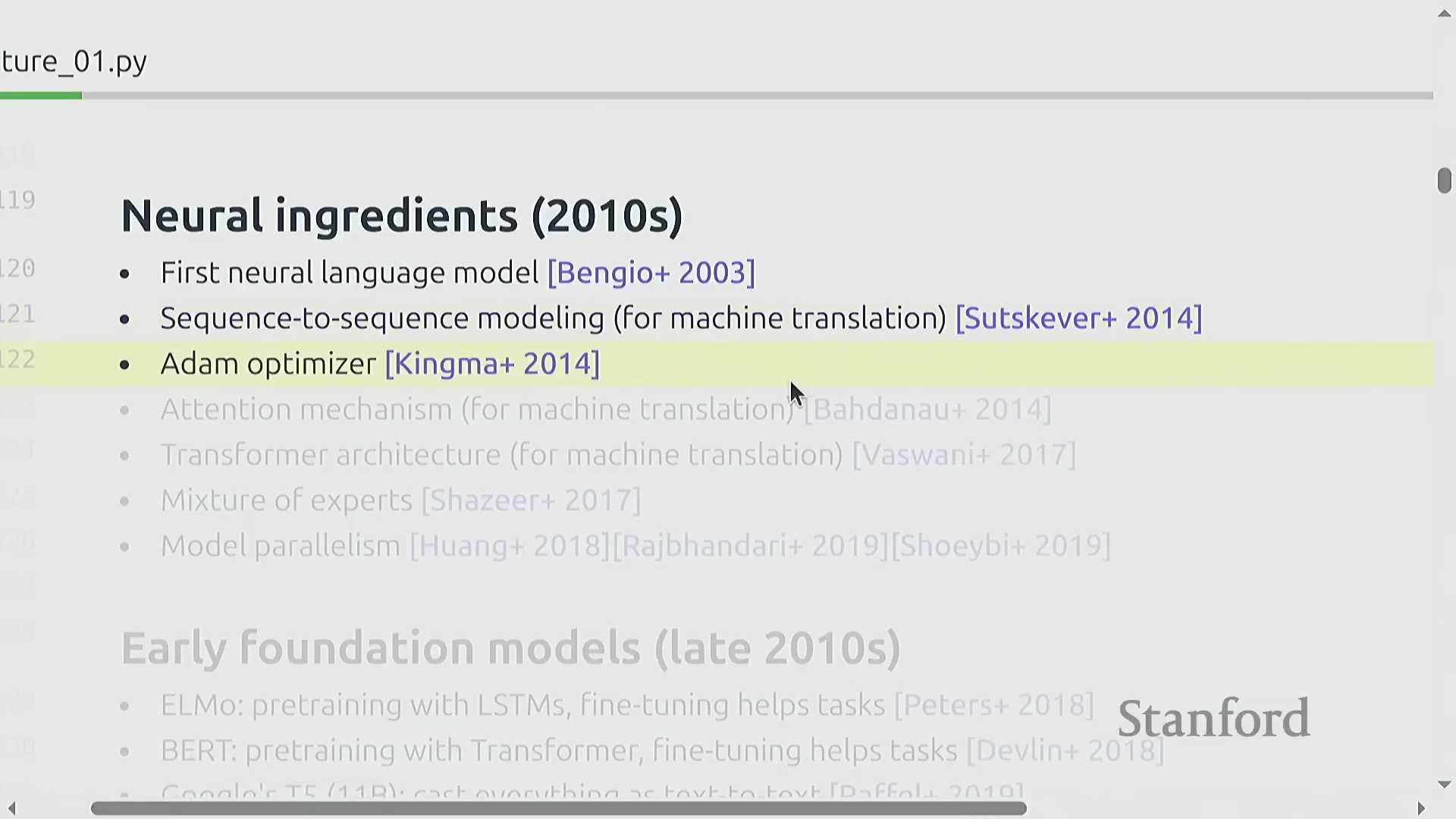

基础模型与开放/封闭生态
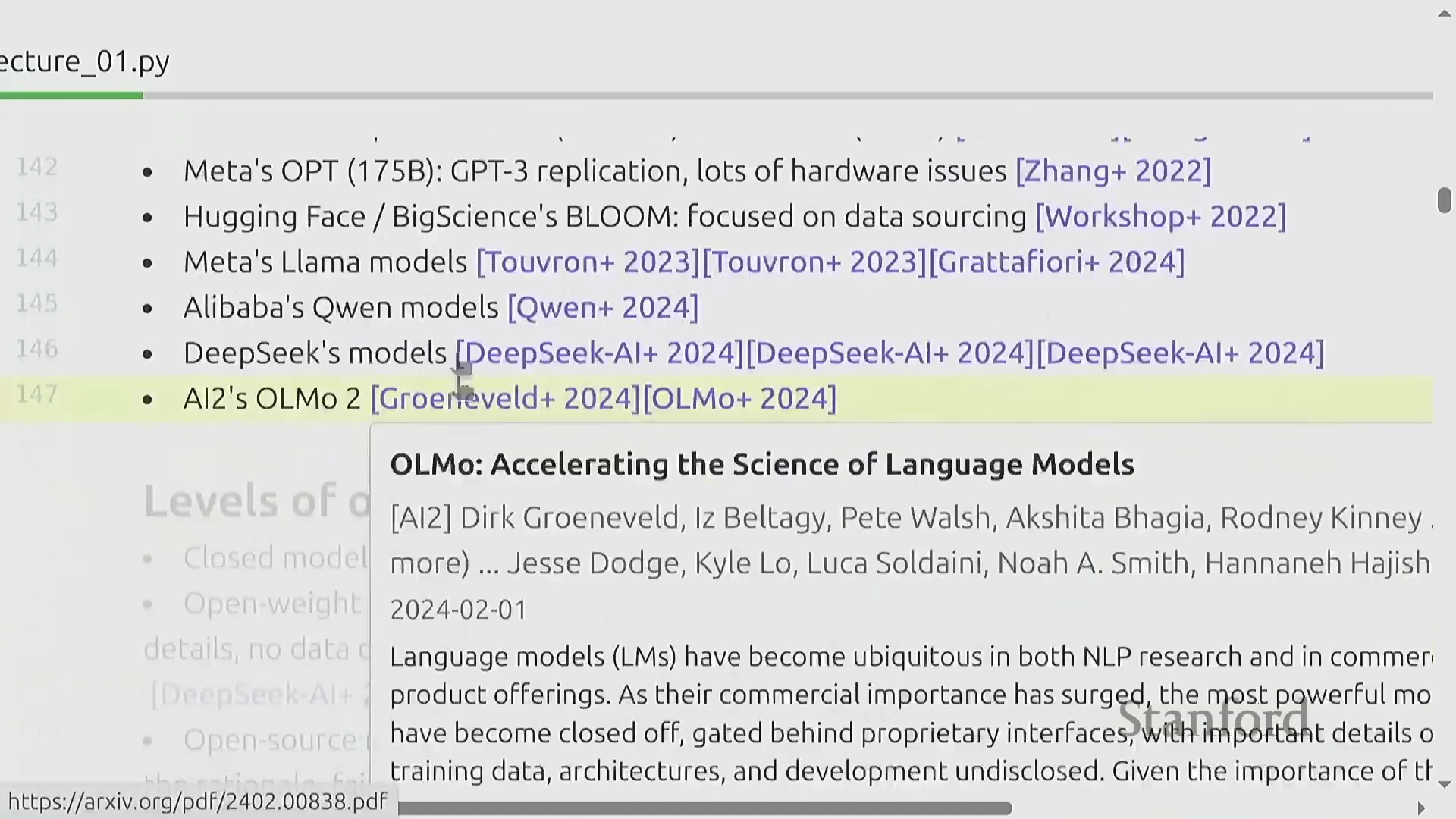
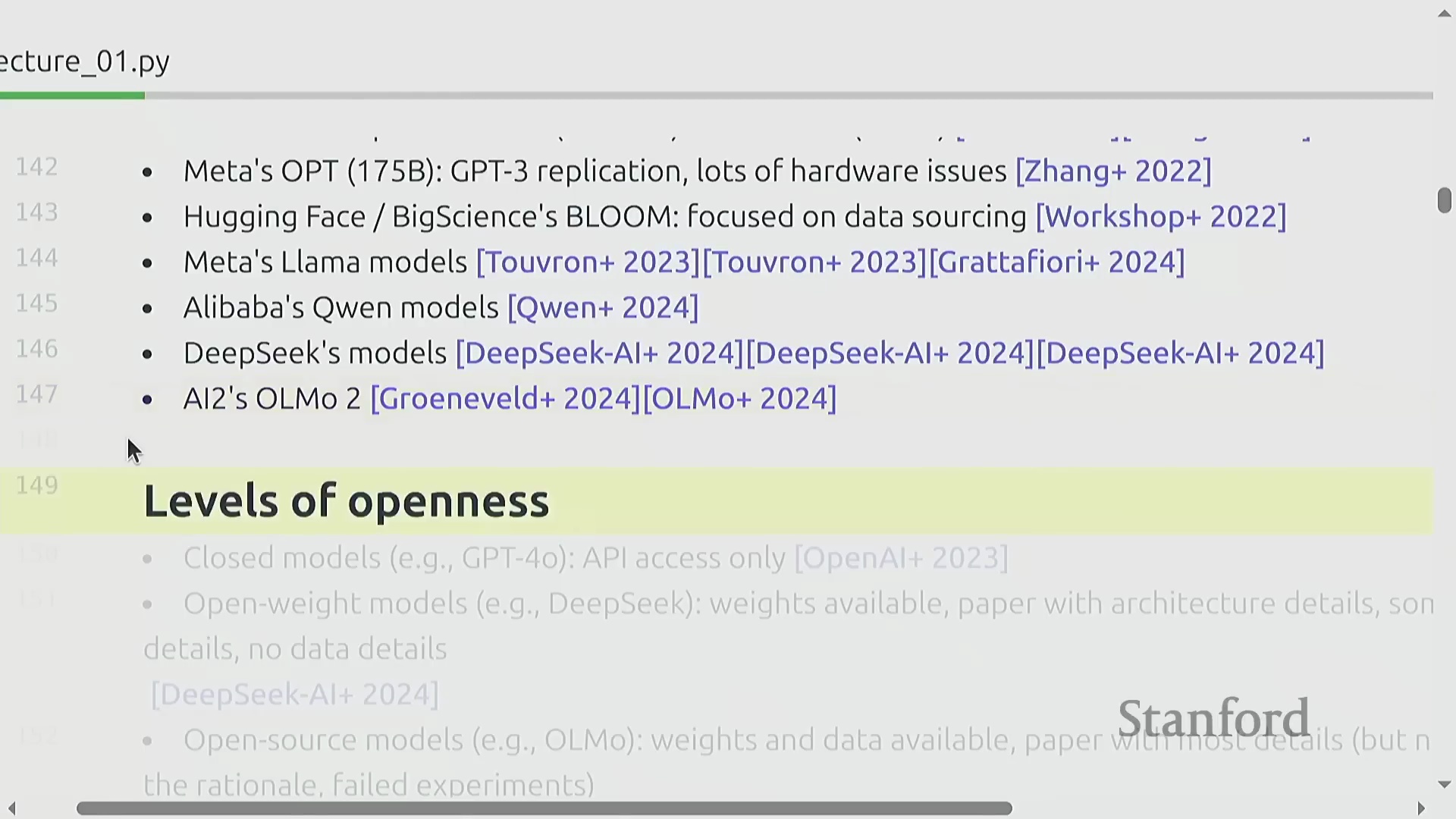
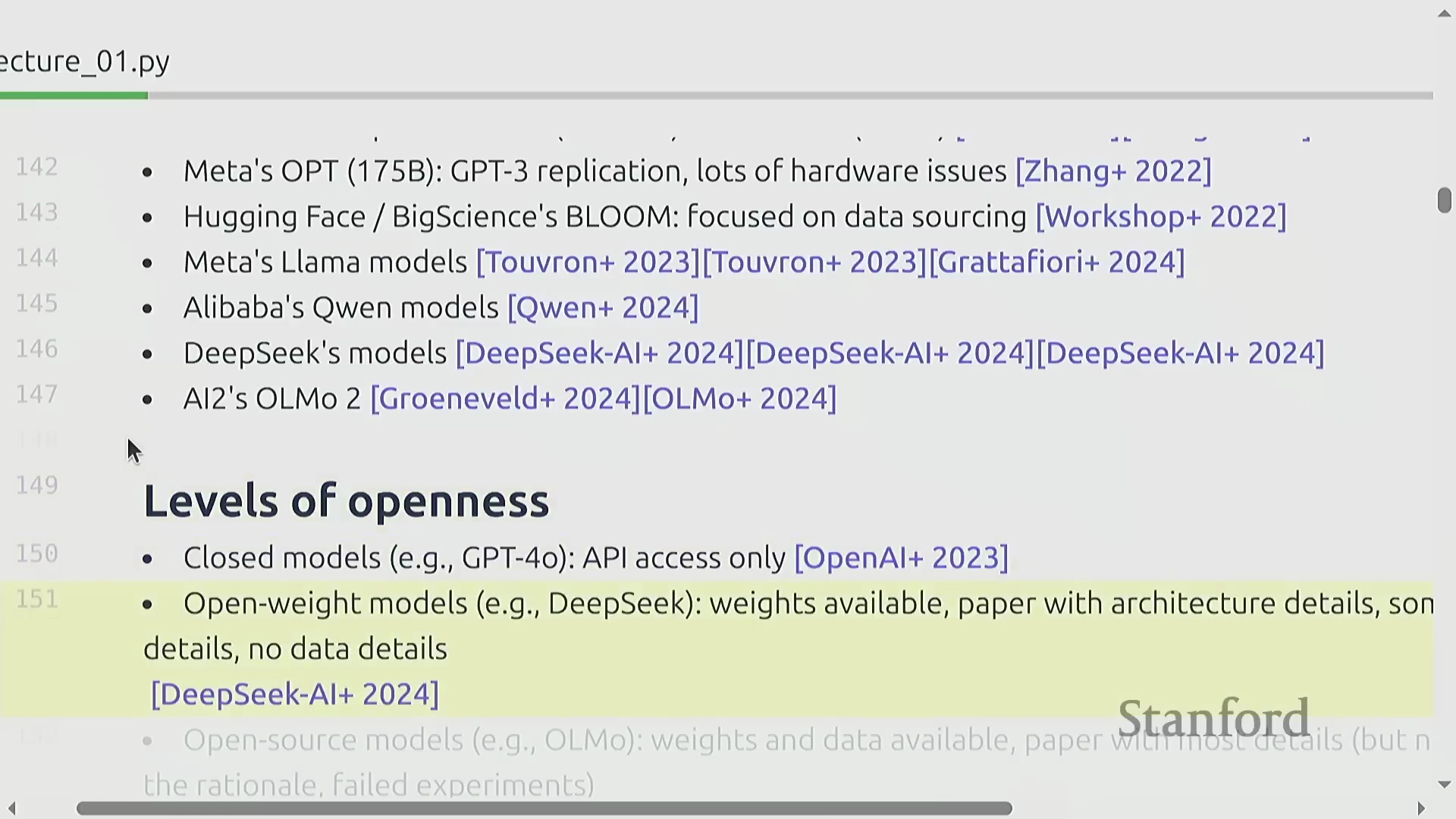
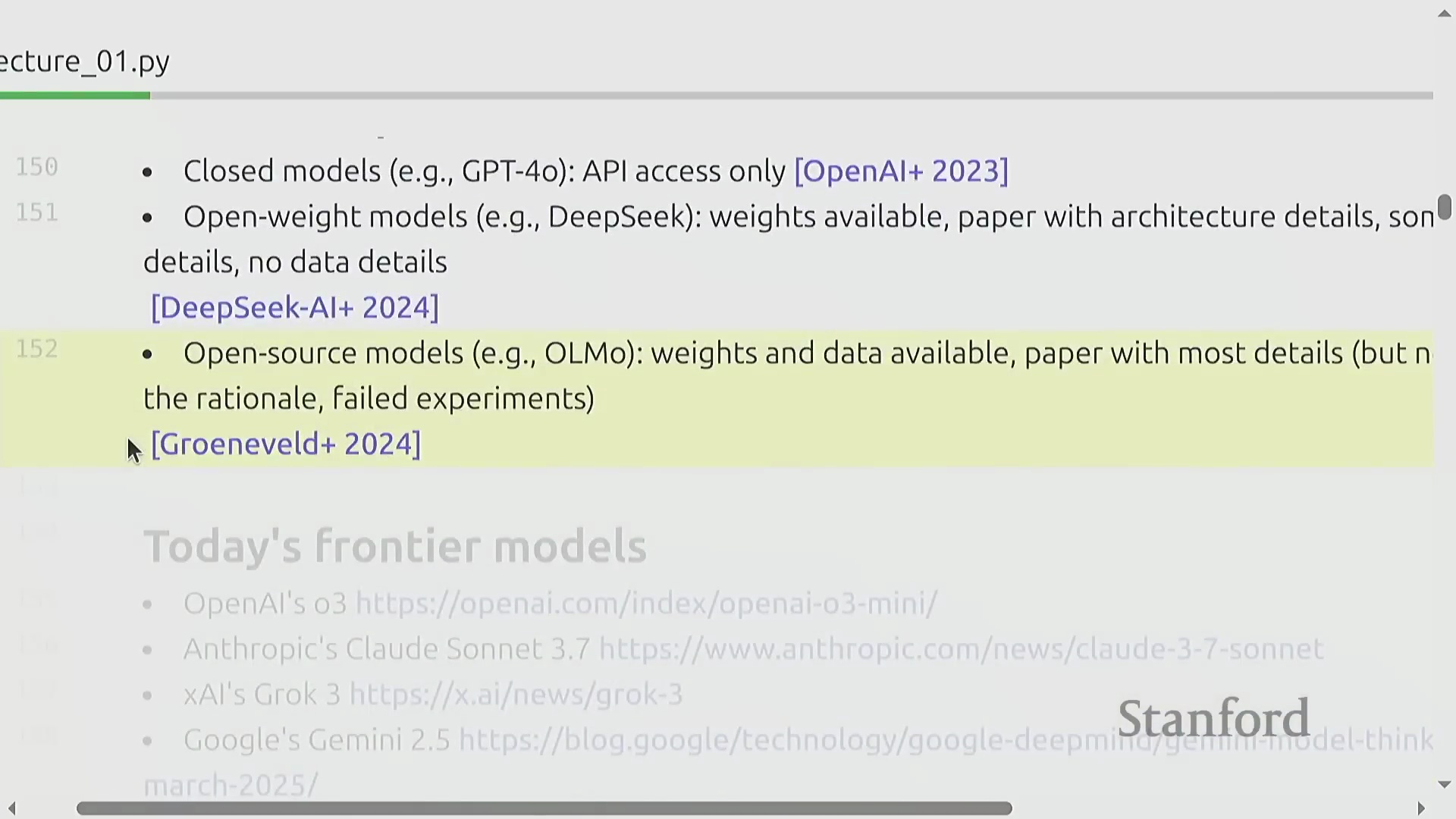
2010年代末,ELMo、BERT和T5等基础模型(Foundation Models)迅速崛起,充分证明了在海量文本语料库上经过预训练(Pre-training)的模型,能够有效泛化并适应多种下游任务(Downstream Tasks)。随后,OpenAI将这些技术要素与严谨的工程实践相结合,并严格遵循缩放定律(Scaling Laws),相继推出了GPT-2与GPT-3模型。这一时期的市场主要由封闭生态、仅提供应用程序接口(Application Programming Interface, API)调用的模型所主导。然而,一场并行的开源运动(Open-source Movement)也迅速兴起,由EleutherAI、Meta的早期探索、BLOOM项目,以及后来的DeepSeek和阿里巴巴等机构共同推动。这股力量推动了行业生态向开放权重(Open-weight)模型转变,逐渐形成了一个涵盖封闭系统、开放权重发布,直至完全开源项目(共享模型权重、训练数据及详尽架构文档)的开放光谱(Openness Spectrum)。
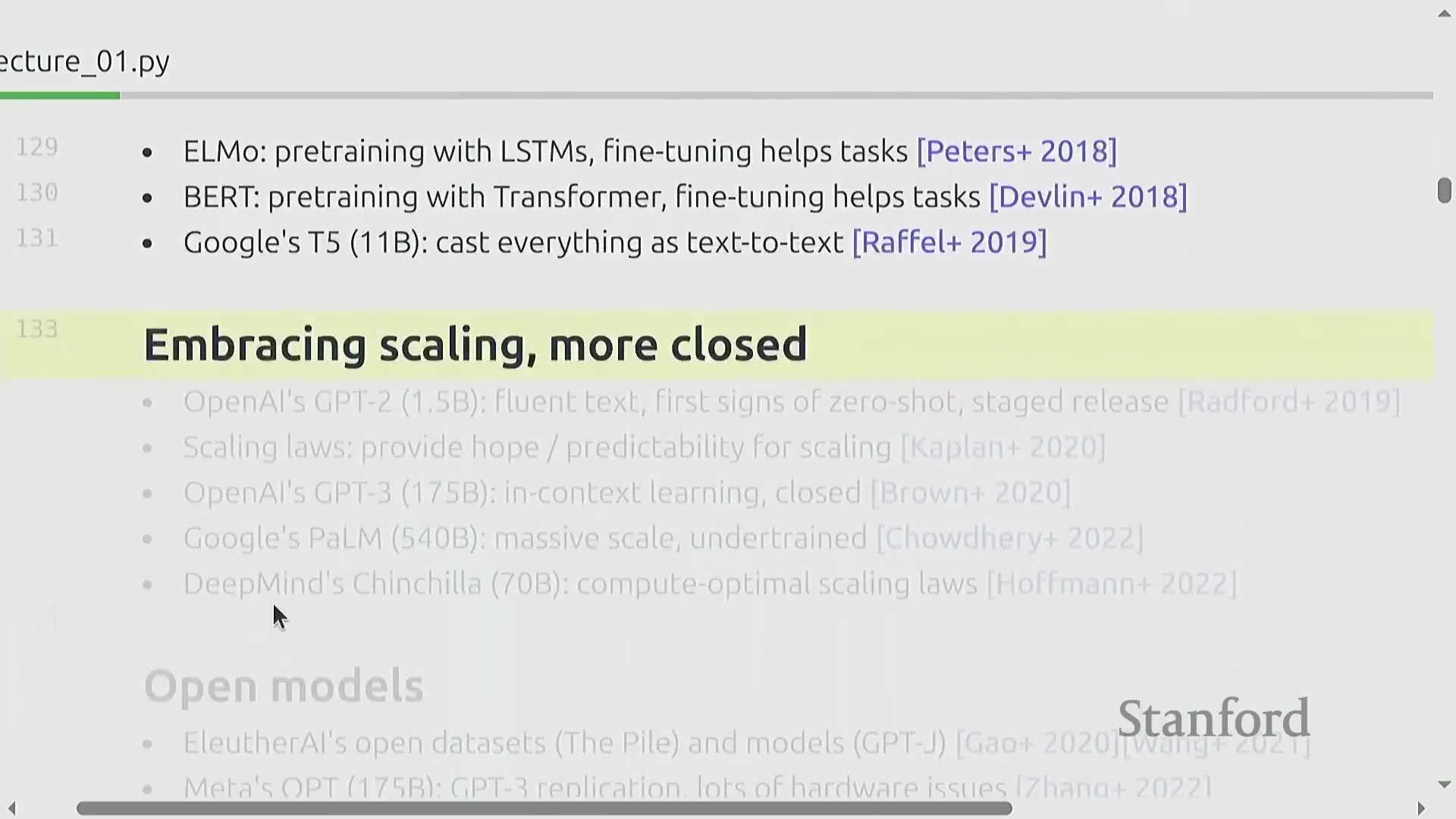

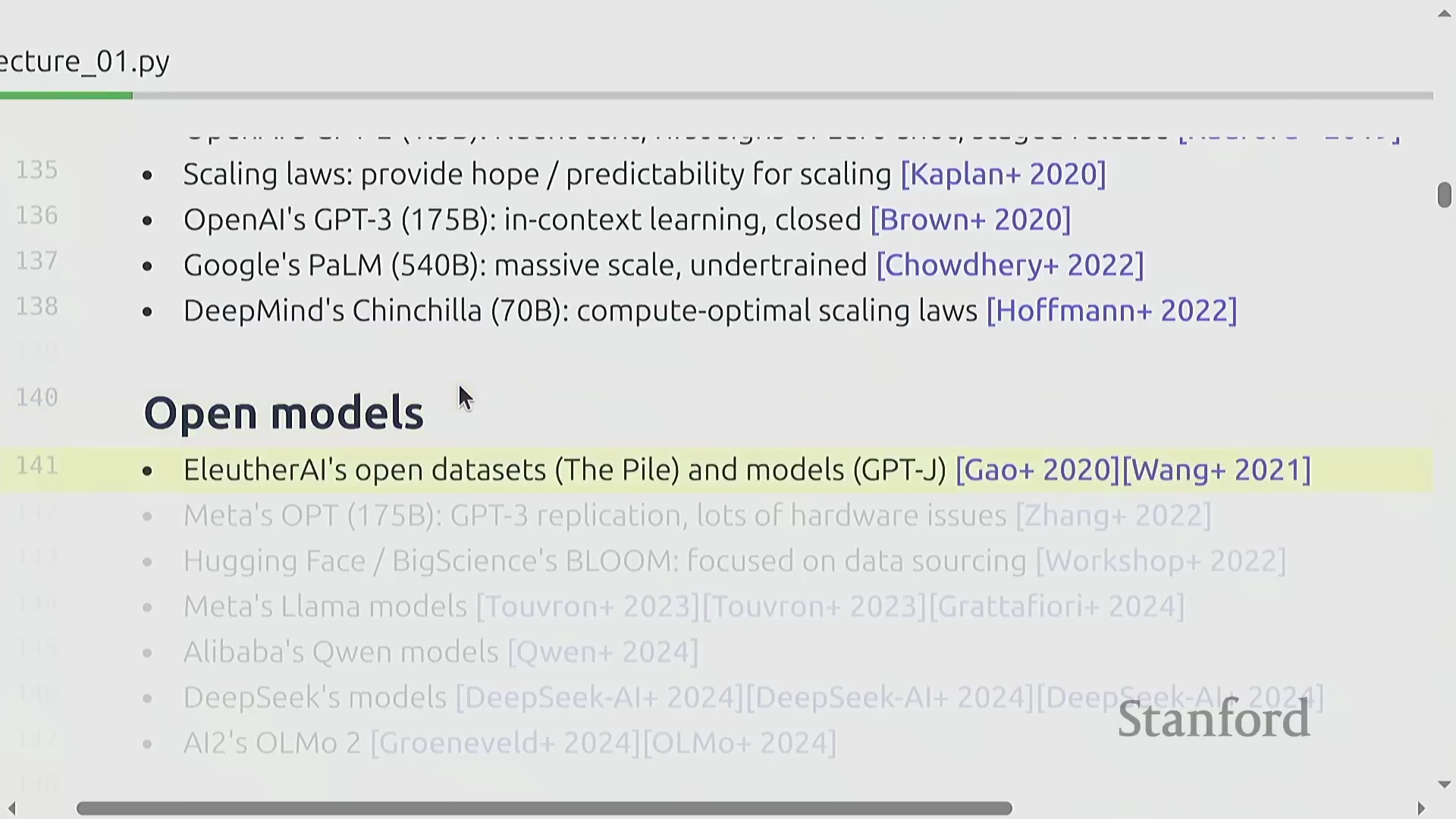
现代格局与课程目标
当前的人工智能产业格局,主要由OpenAI、Anthropic、xAI、Google、Meta和DeepSeek等机构的前沿模型(Frontier Models)所构成的竞争生态所定义。本课程将系统性地回顾塑造这些系统的核心技术组件,追溯其技术演进脉络,并演示如何复现与逼近业界前沿的最佳实践(Best Practices)。通过整合开源社区的公开研究成果,并深入剖析闭源模型可获取的技术信息,学员将建立起对现代语言模型构建方法的全面认知。

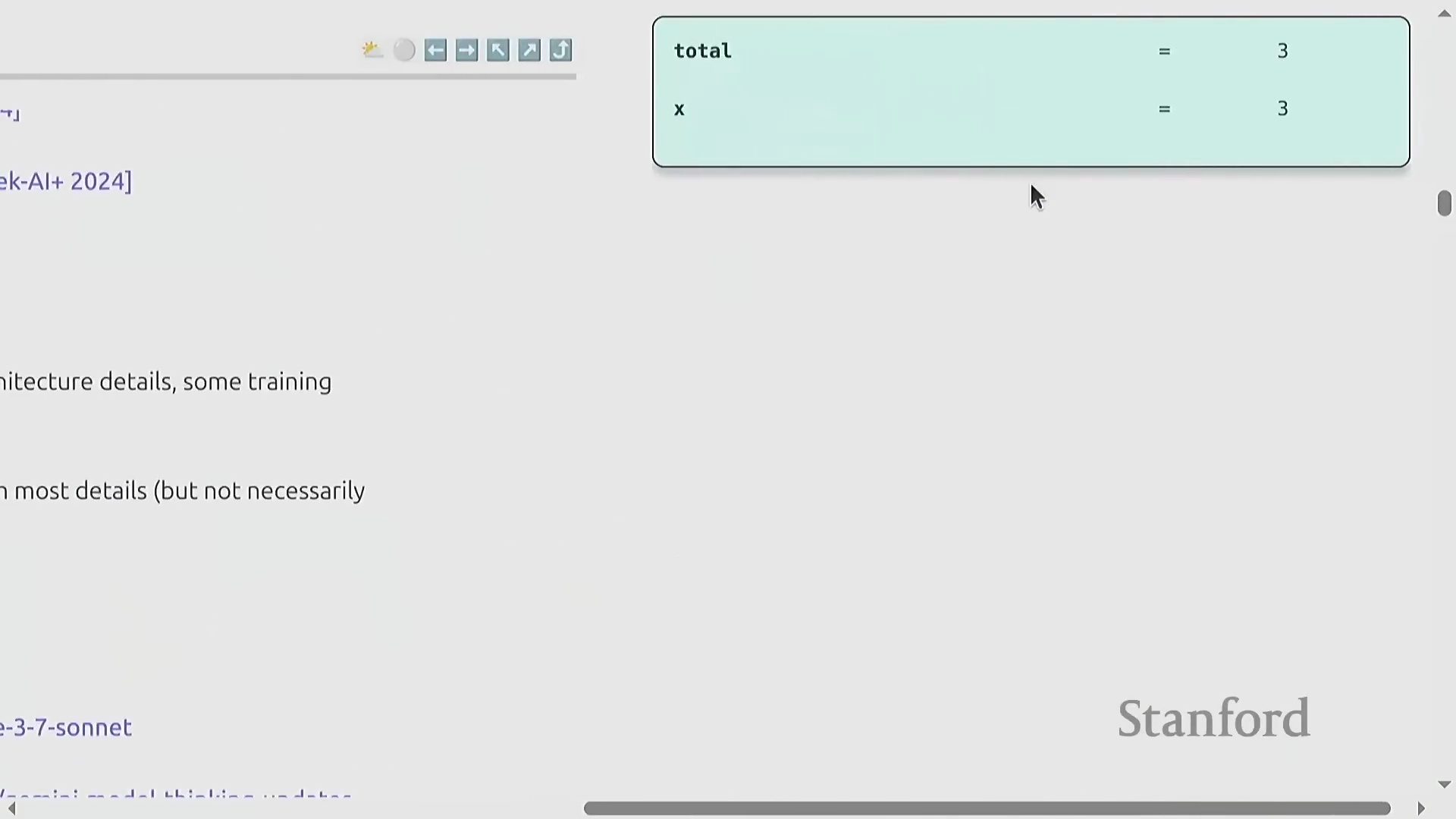
“可执行讲义”形式与课程成果
本课程采用了一种基于Python构建的创新“可执行讲义(Executable Lecture)”形式。该形式支持逐步推演,能够实时展示代码执行过程、环境变量(Environment Variables)配置以及分层模块的交互导航,从而在理论概念与工程实践之间搭建起坚实的桥梁。针对学员的常见疑问,我们在此明确说明:尽管完成本课程将为你奠定扎实的技术基础,并培养引领前沿AI研发所必需的工程思维,但要真正训练出顶尖级别的模型,仍需要巨额资金投入,以及学术界难以提供的专项工程资源(Engineering Resources)与基础设施支持。

课程期望与目标受众
尽管我们强烈鼓励各位在未来能够引领团队并构建前沿模型(Frontier Models),但本课程仅是这段漫长技术旅程中奠定基础的第一步。作为一门严谨的五单元课程,其课业负荷经过刻意设计,强度极高;单次作业的工作量可能相当于一门标准自然语言处理(Natural Language Processing, NLP)课程的总工作量及其期末项目之和。本课程专为那些对深入理解人工智能(Artificial Intelligence, AI)系统底层原子级组件(Atomic-level Components)抱有强烈求知欲的学生量身定制。课程结束后,学员的研究工程(Research Engineering)能力以及对大规模机器学习(Machine Learning)系统的驾驭能力将得到显著提升。然而,本课程不推荐给以下几类人群:本季度需优先处理其他研究任务者、仅追逐最新技术趋势而忽视基础原理者,或实际需求仅通过提示词交互(Prompting)或模型微调(Fine-tuning)现有模型即可满足的人群。

课程安排、开放获取与 AI 政策
所有课程资料、作业及讲座录像均将免费在线开放,确保注册学生与远程学习者均能无障碍获取(Open Access)。该课程明年亦计划继续开设。为支持实践训练,本课程使用了由 Together AI 慷慨赞助的 H100 GPU 计算集群(Compute Cluster)。强烈建议学员仔细阅读集群使用指南并尽早启动作业,以免在截止日期临近时遭遇计算资源瓶颈。关于 Cursor 或 GitHub Copilot 等 AI 编程辅助工具(AI Coding Assistants),尽管其功能强大,但过度依赖极易导致跳过关键推导步骤,从而干扰深度学习过程。课程虽允许使用此类工具,但附带明确警告:学员必须对自身的知识掌握程度与学习成效承担全部责任。

作业结构与开发工作流
课程体系共包含五次核心作业,严格遵循“从零构建”(Build from Scratch)的教学理念。课程不会提供大量现成的脚手架代码(Scaffolding Code),学员需从空白文件起步,并借助单元测试(Unit Tests)与接口适配器(Interface Adapters)来验证各组件的正确性。该方法旨在迫使学习者独立做出软件架构设计(Software Architecture Design)决策,这也是工程落地过程中的一项核心技能。推荐的标准工作流强调计算效率(Computational Efficiency):优先使用小规模数据集在本地环境进行原型开发(Prototyping)与调试(Debugging),以节约集群资源;随后再迁移至共享基础设施上进行模型精度与训练/推理速度的基准测试(Benchmarking)。部分作业将引入竞争性排行榜(Competitive Leaderboards),挑战学员在固定的训练预算(Training Budget)内,综合运用课堂理论与前沿外部研究成果,以优化模型的困惑度(Perplexity, PPL)指标。
效率驱动框架与五大支柱
课程体系围绕五大核心支柱(Five Core Pillars)展开,均聚焦于一个实际优化问题:在固定的算力(Compute)与数据约束下,最大化模型性能(Model Performance)。学员将直面真实的工程场景,例如:在两周周期内,获得海量的 Common Crawl 数据集与 32 张 H100 GPU,并需在此约束下做出关键的架构与系统运维(System Operations)决策。课程将系统性地涵盖词元化(Tokenization)策略、模型架构(Model Architecture)、系统级优化(System-level Optimization)以及数据筛选与清洗(Data Filtering and Curation)技术。每个教学单元均旨在为学员构建一套全面的决策工具箱(Decision-making Toolkit),助力大家在现实资源限制下,高效训练出高性能的语言模型(Language Models)。

第一单元:词元化(Tokenization)与 Transformer 架构
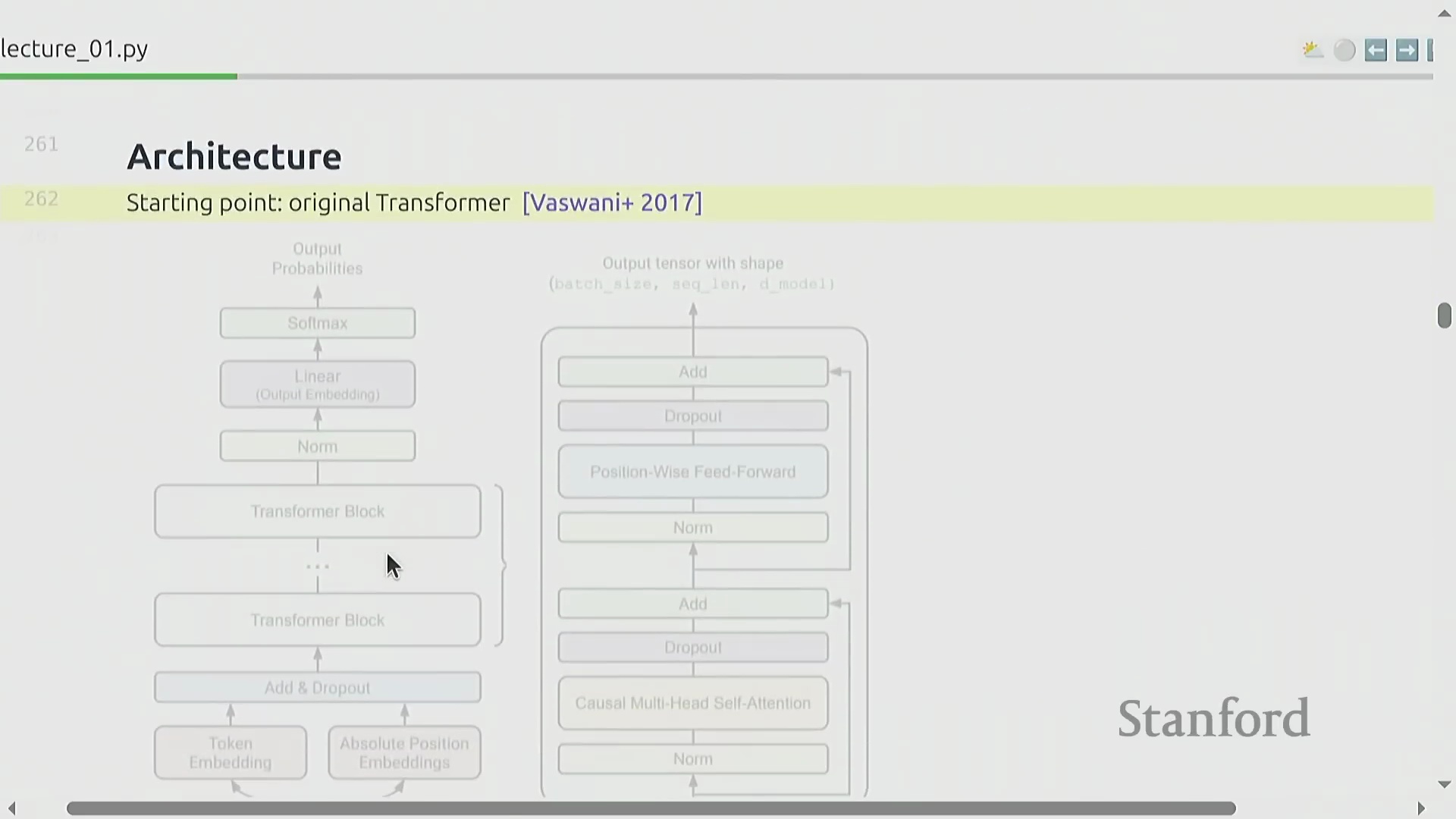
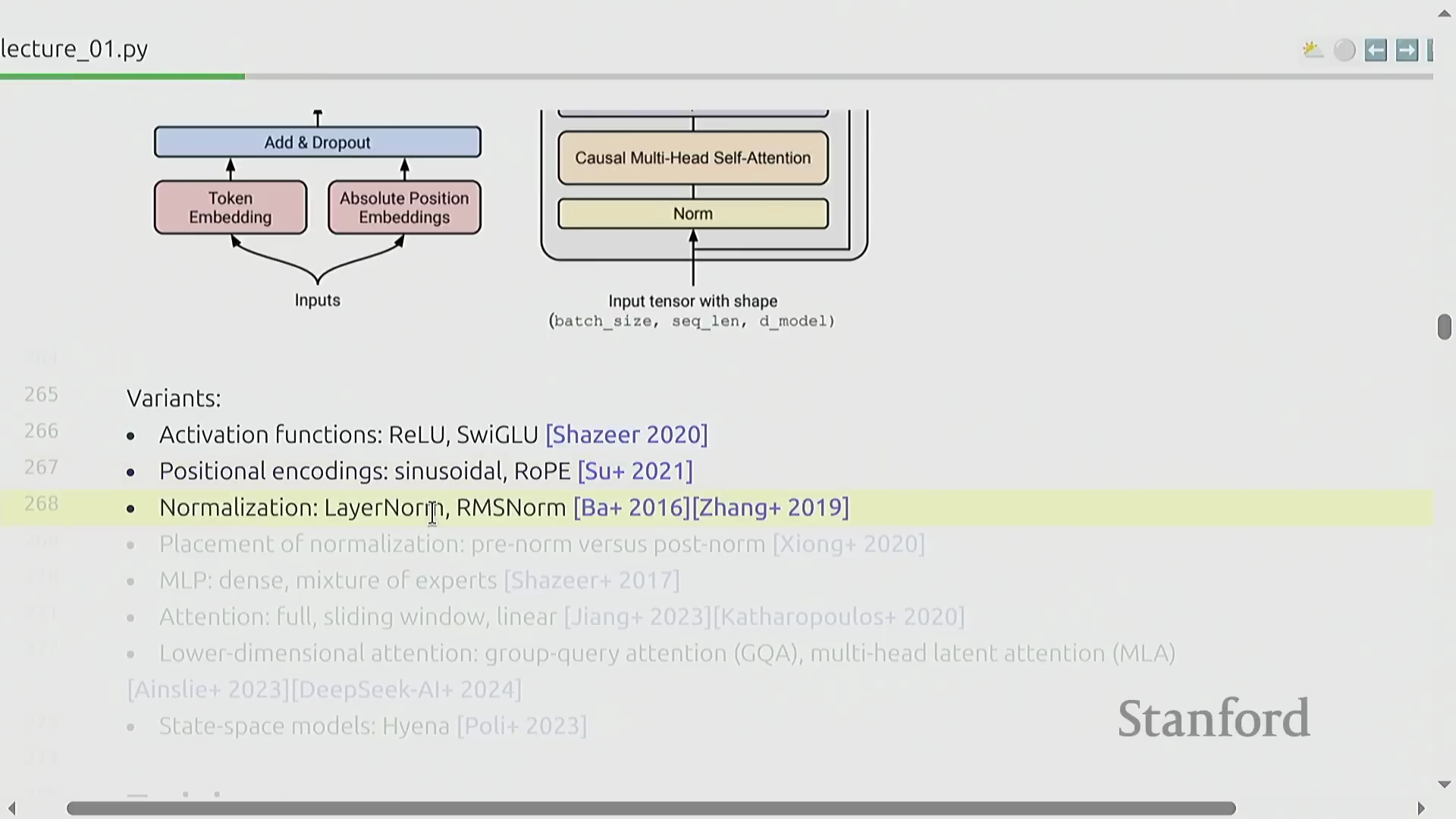
第一单元侧重于搭建一套功能完整的端到端训练流水线(End-to-End Training Pipeline),并首先从词元化工具(Tokenizer)入手。词元化工具负责将原始文本转换为整数序列(Integer Sequences),作为神经网络(Neural Networks)固定维度的数值型输入。课程将亲手实现字节对编码(Byte-Pair Encoding, BPE)算法,这是一种鲁棒性(Robustness)强且被业界广泛采用的行业标准。尽管直接处理原始字节的无词元化(Tokenization-free)新兴方法展现出一定潜力,但其有效性尚未在前沿模型规模(Frontier Scale)下得到充分验证。完成词元化模块后,学员将正式启动模型架构的构建,并以基础 Transformer 架构为起点。尽管自 2017 年问世以来,该架构历经诸多迭代与改进,但其核心设计范式——自注意力机制(Self-Attention Mechanism)、多层感知机(Multilayer Perceptron, MLP)层与层归一化(Layer Normalization)——依然是构筑当前几乎所有最先进(State-of-the-Art, SOTA)语言模型不可动摇的骨干网络。

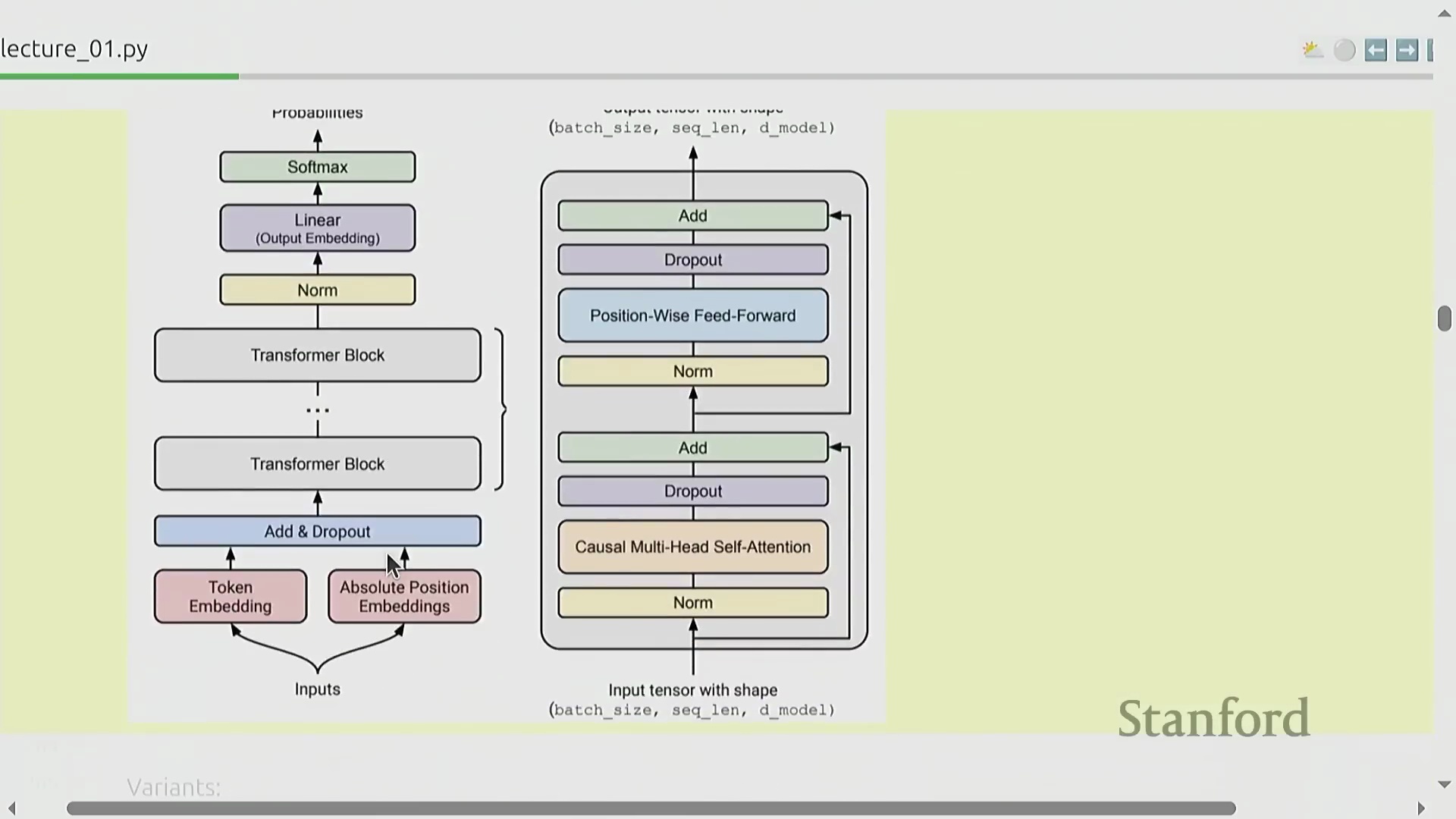
超越原始 Transformer 的架构优化
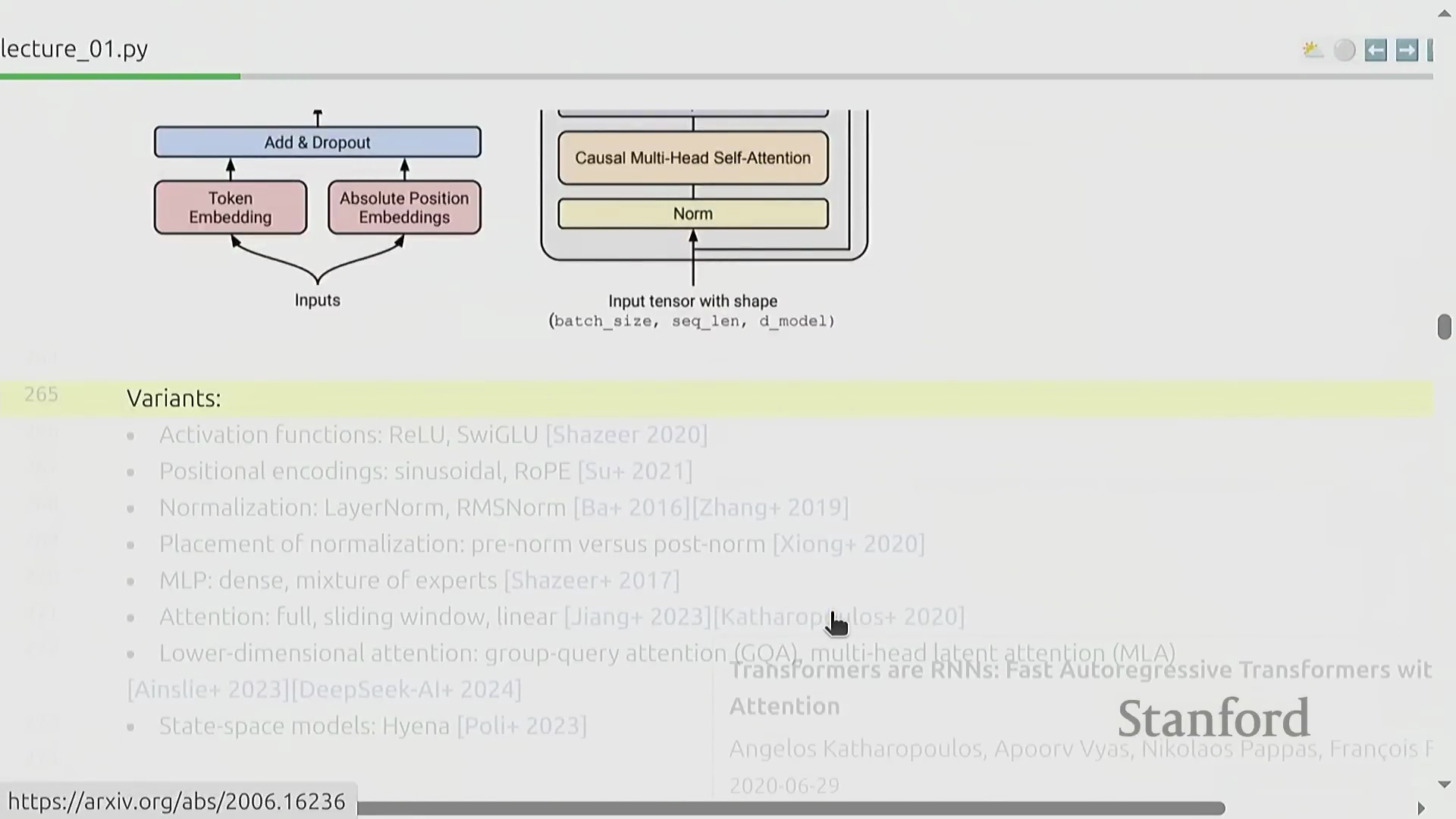
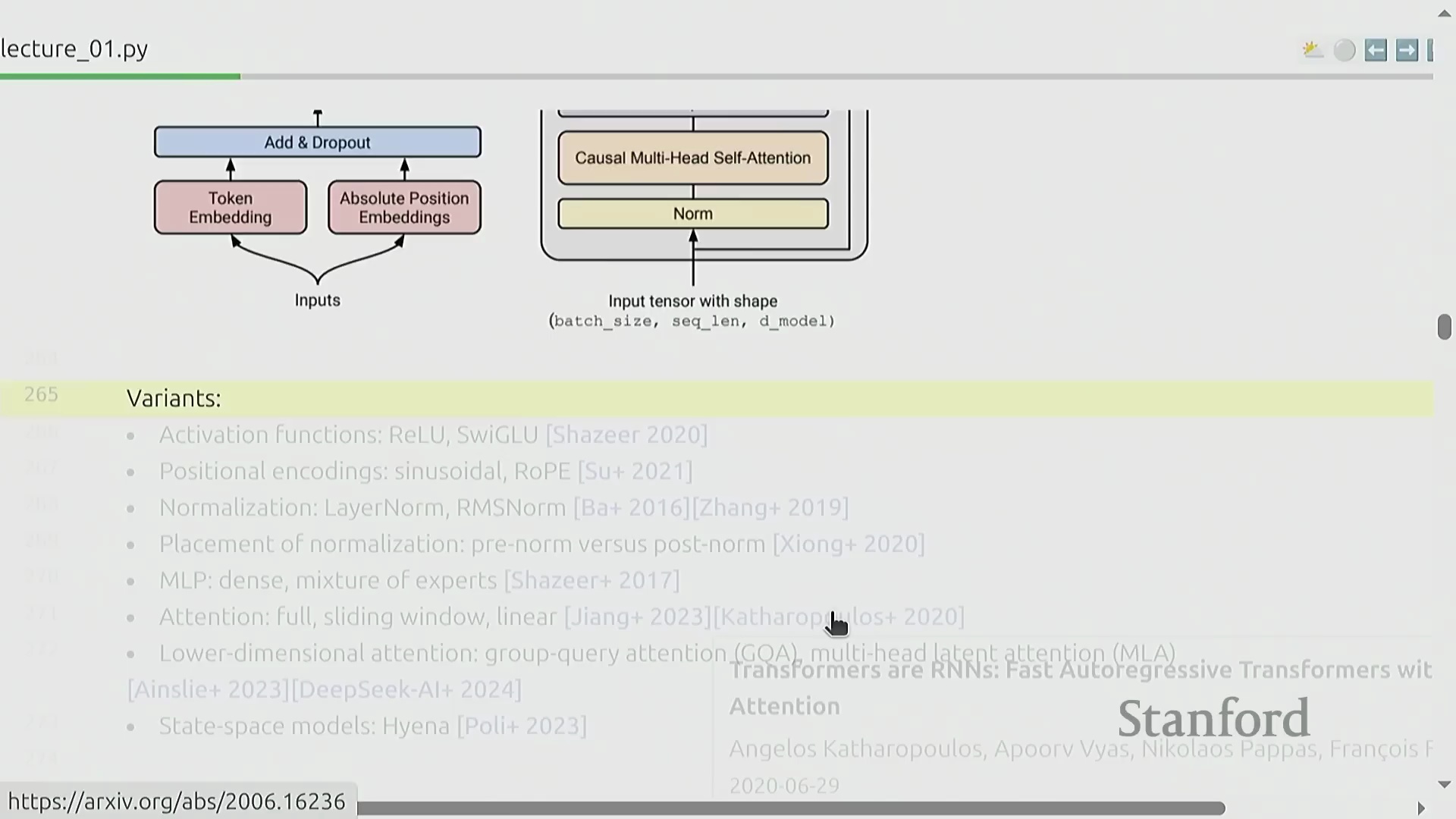
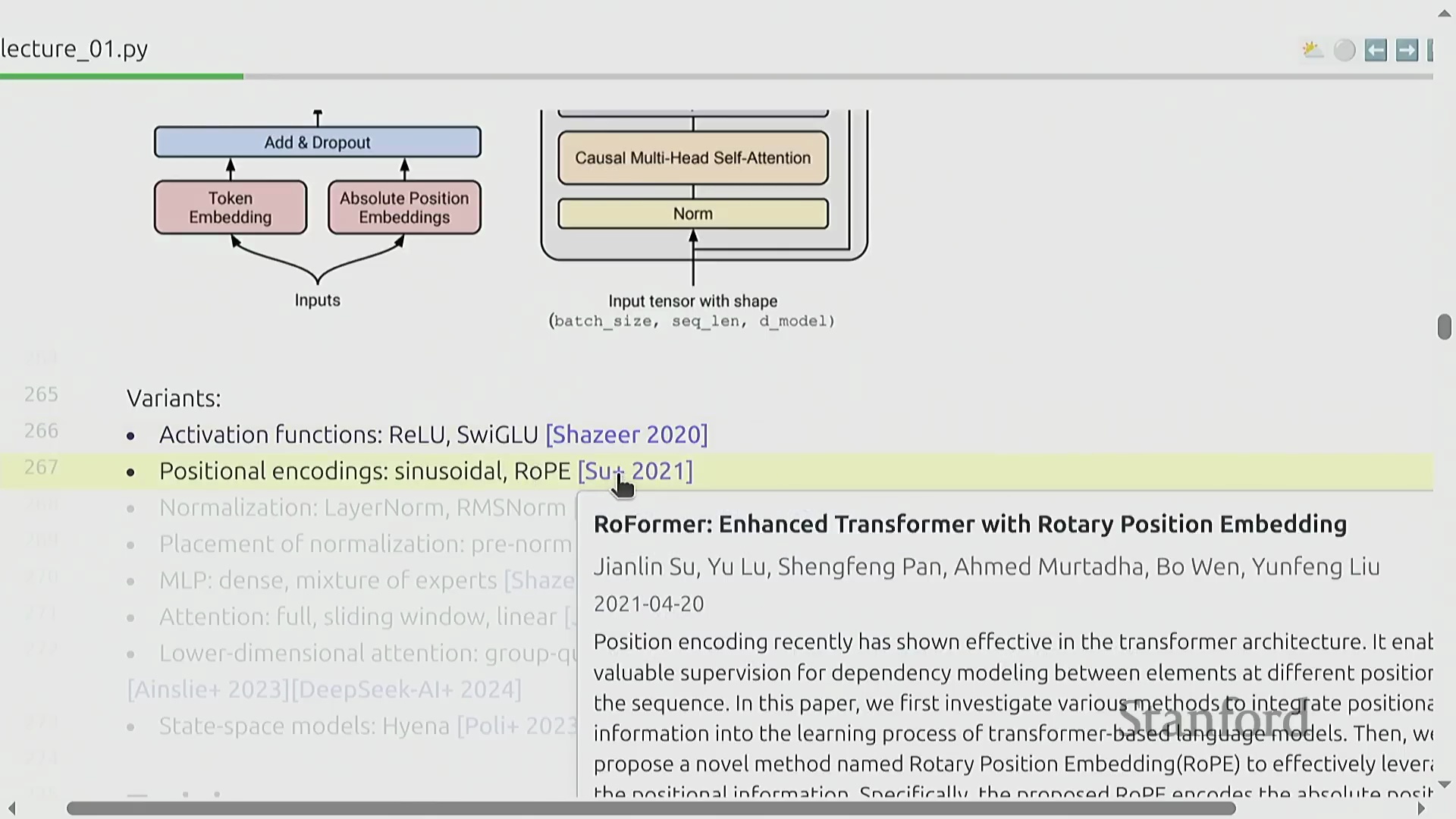
尽管 Transformer 的基础架构设计大体保持不变,但持续的架构优化(Architecture Optimization)在大规模训练(Large-scale Training)中带来了显著的性能提升。现代模型实现通常采用 SwiGLU 激活函数(Activation Function)替代传统方案,引入旋转位置编码(Rotary Position Embedding, RoPE),并使用 RMSNorm 实现更高效且稳定的归一化(Normalization)。归一化层的位置布局(Position Layout)也已相较于 2017 年的原始设计进行了调整。此外,密集多层感知机(Dense Multilayer Perceptron, MLP)层常被混合专家模型(Mixture of Experts, MoE)架构所取代,以提升参数效率(Parameter Efficiency);注意力机制(Attention Mechanism)也通过滑动窗口注意力(Sliding Window Attention)、线性注意力(Linear Attention)以及分组查询注意力(Grouped-Query Attention, GQA)与多潜在注意力(Multi-Latent Attention, MLA)等变体不断演进,有效缓解了计算复杂度随序列长度呈平方级增长(Quadratic Complexity Growth)的问题。状态空间模型(State Space Models, SSMs,如 Hyena)和混合架构(Hybrid Architectures)等替代范式,进一步拓宽了超越传统注意力机制的设计空间。



训练动态与作业 1:全栈实践
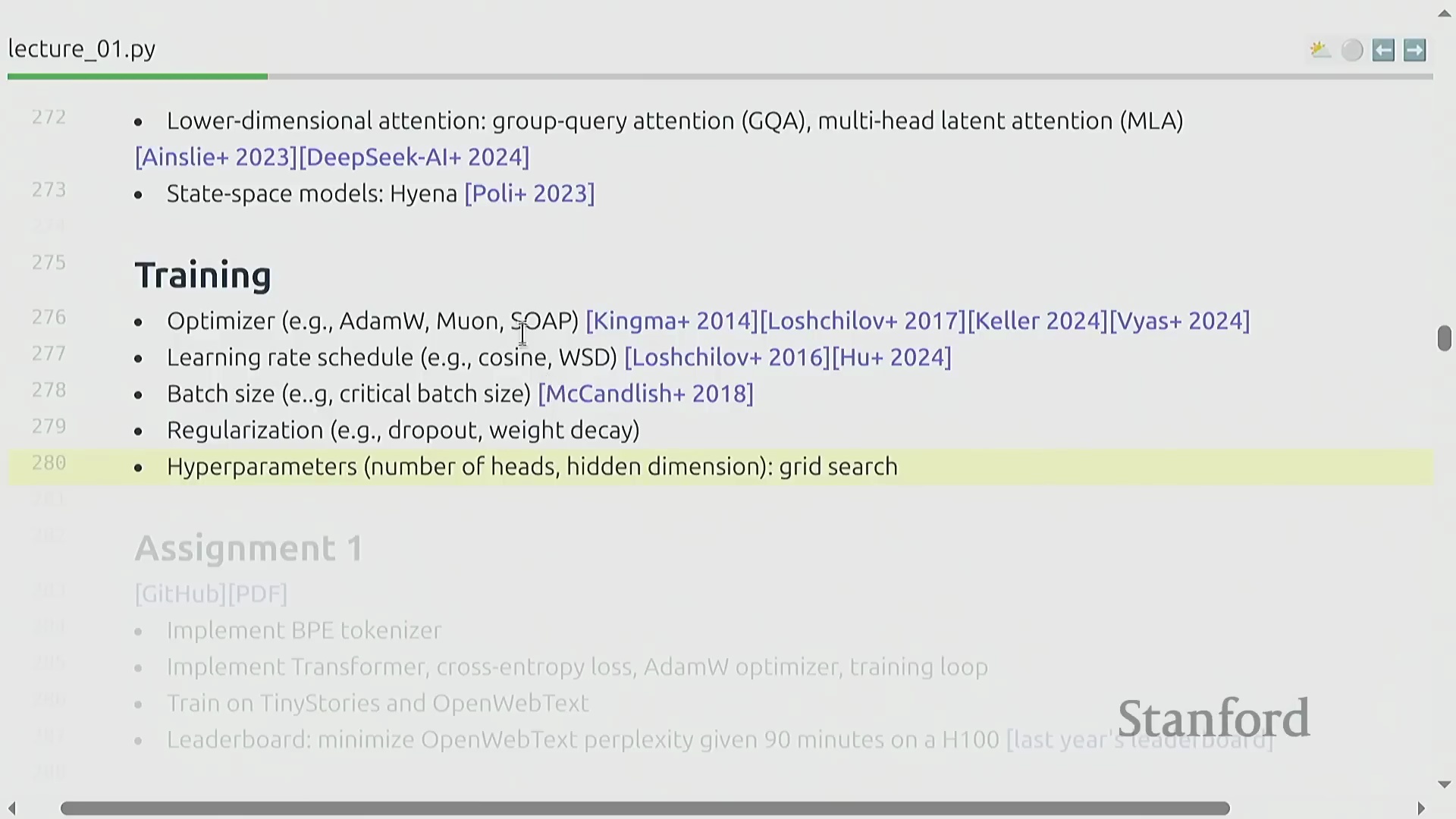
模型训练(Model Training)的成功高度依赖于精细的超参数调优(Hyperparameter Tuning)。AdamW 优化器(Optimizer)依然是行业标准,尽管 Muon 和 SOAP 等新兴优化算法也展现出极具竞争力的潜力。关键的调优变量涵盖学习率调度策略(Learning Rate Scheduling)、批次大小(Batch Size)以及正则化技术(Regularization Techniques)。在实践中,精心调优的超参数配置相较于未经优化的基线模型(Baseline Model),往往能带来数量级(Order of Magnitude)的性能差距。作业 1(Assignment 1)要求学生从零搭建完整的训练流水线(Training Pipeline):在严格限制使用 PyTorch 内置函数的条件下,独立实现字节对编码(Byte-Pair Encoding, BPE)分词器、Transformer 架构、交叉熵损失函数(Cross-Entropy Loss)以及 AdamW 优化器。模型将在 TinyStories 和 OpenWebText 等数据集上进行训练,学员将在排行榜(Leaderboard)上展开角逐,目标是在严格的 90 分钟 H100 计算资源预算(Compute Budget)内实现最低的困惑度(Perplexity)。




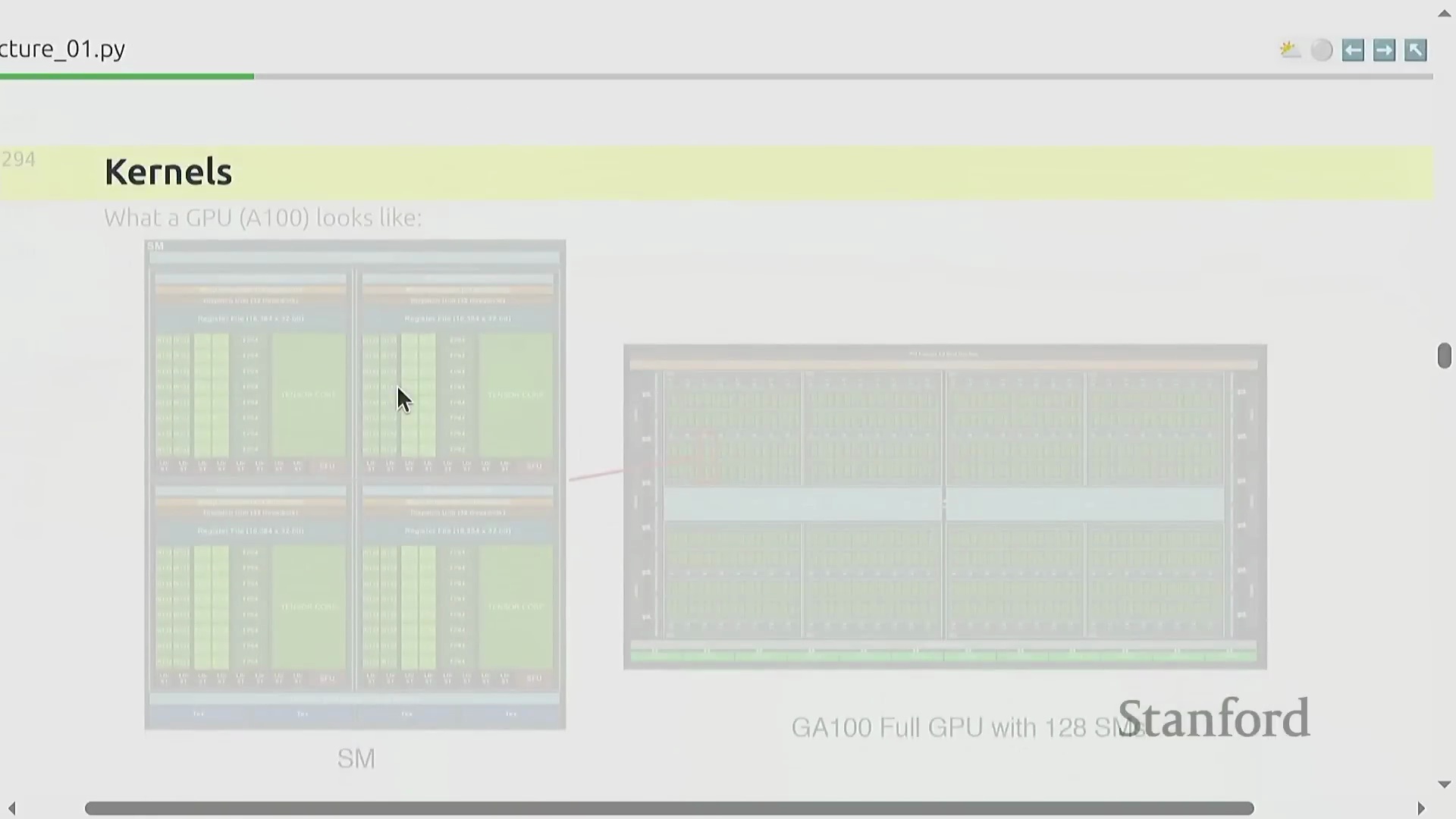
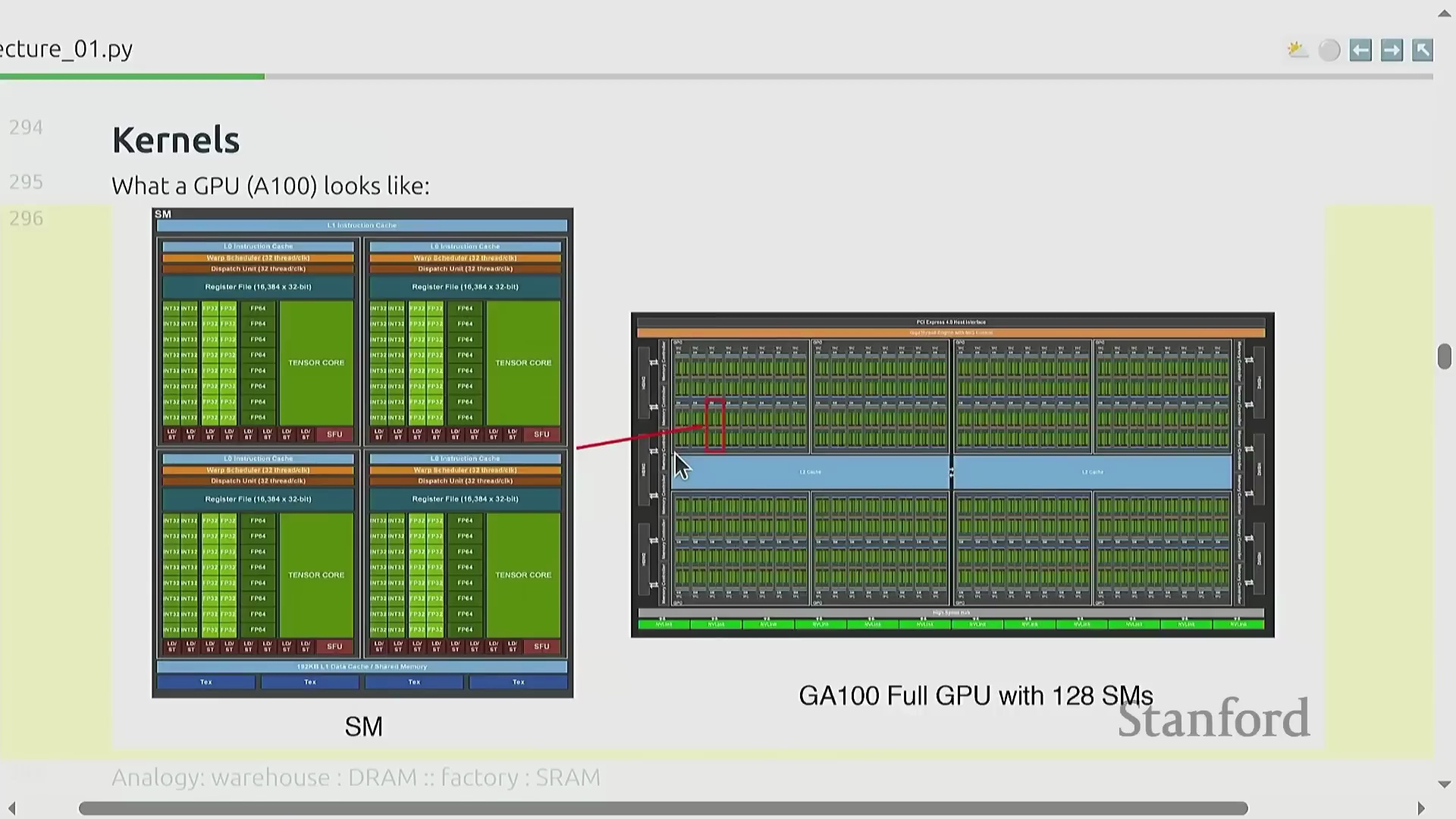
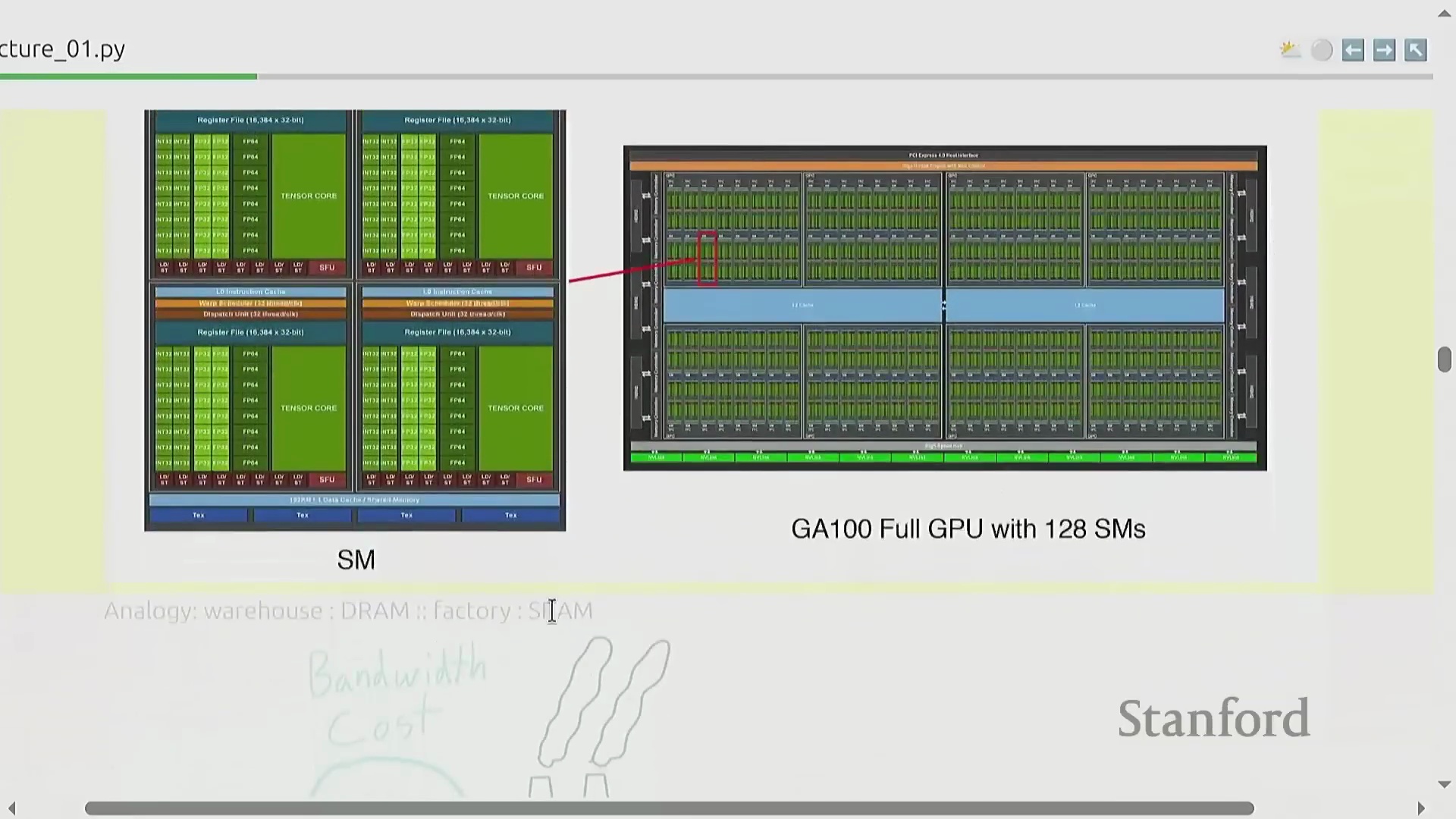
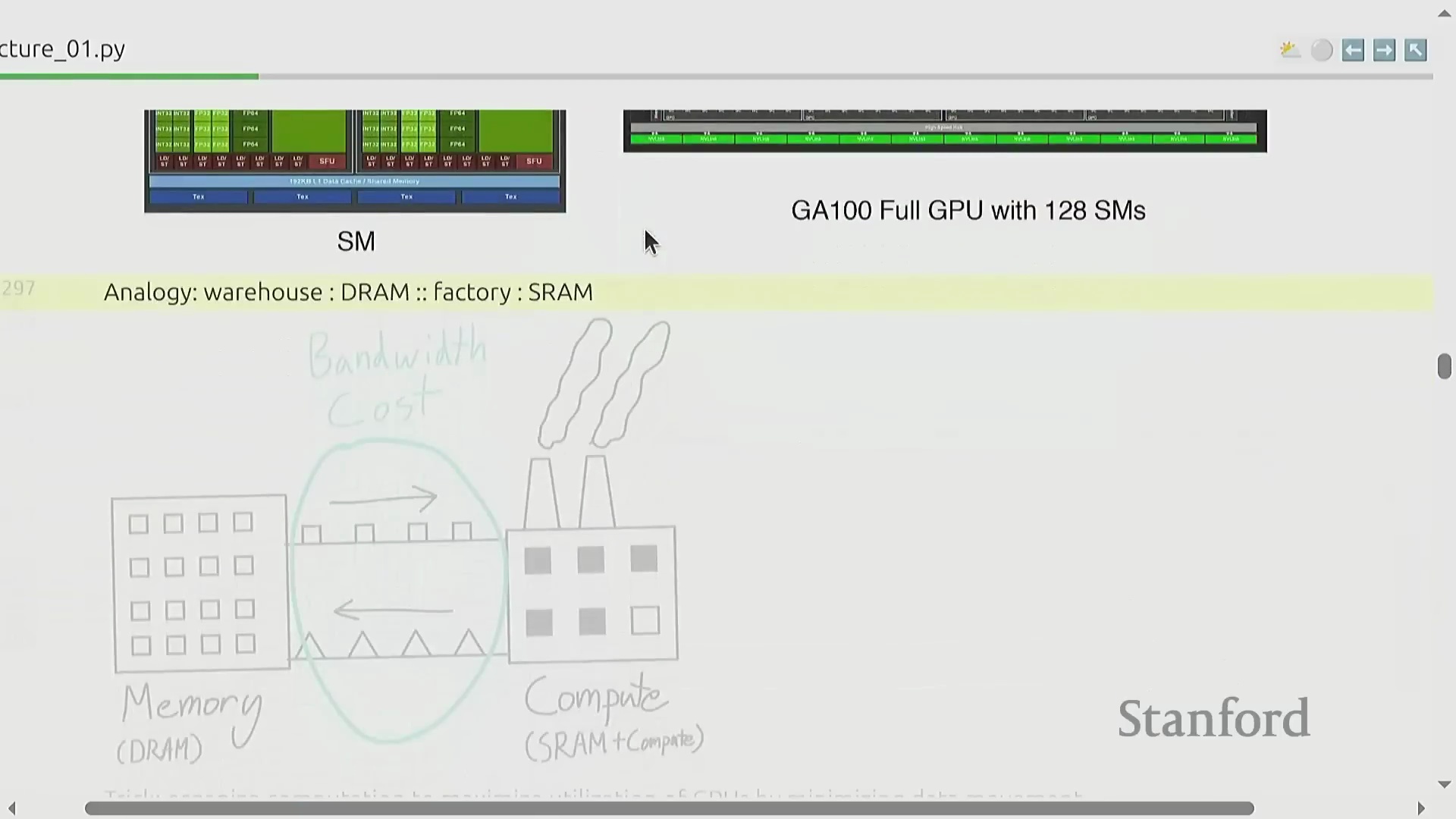
GPU 硬件、内存瓶颈与自定义内核
要最大化硬件效率(Hardware Efficiency),必须深入理解图形处理器(Graphics Processing Unit, GPU)的底层架构。计算核心(Compute Cores)位于芯片内部,而绝大多数模型参数和激活值(Activations)存储在片外内存(Off-chip Memory)中,这使得数据搬运(Data Movement)成为首要的性能瓶颈(Performance Bottleneck)。这类似于在仓库与工厂之间运输原材料,工程上的核心挑战在于如何高效编排矩阵乘法(Matrix Multiplication)等运算,从而在尽可能减少内存传输(Memory Transfer)的同时,最大化计算单元的利用率(Compute Utilization)。这通常通过底层计算内核(Kernel)优化来实现,例如算子融合(Operator Fusion)和内存分块(Memory Tiling)技术。本课程将采用 OpenAI 团队开源的基于 Python 的领域特定语言(Domain-Specific Language, DSL) Triton,指导学员编写高度定制且高效的 GPU 内核(GPU Kernels),以精准适配现代 AI 计算负载(AI Compute Workloads)。
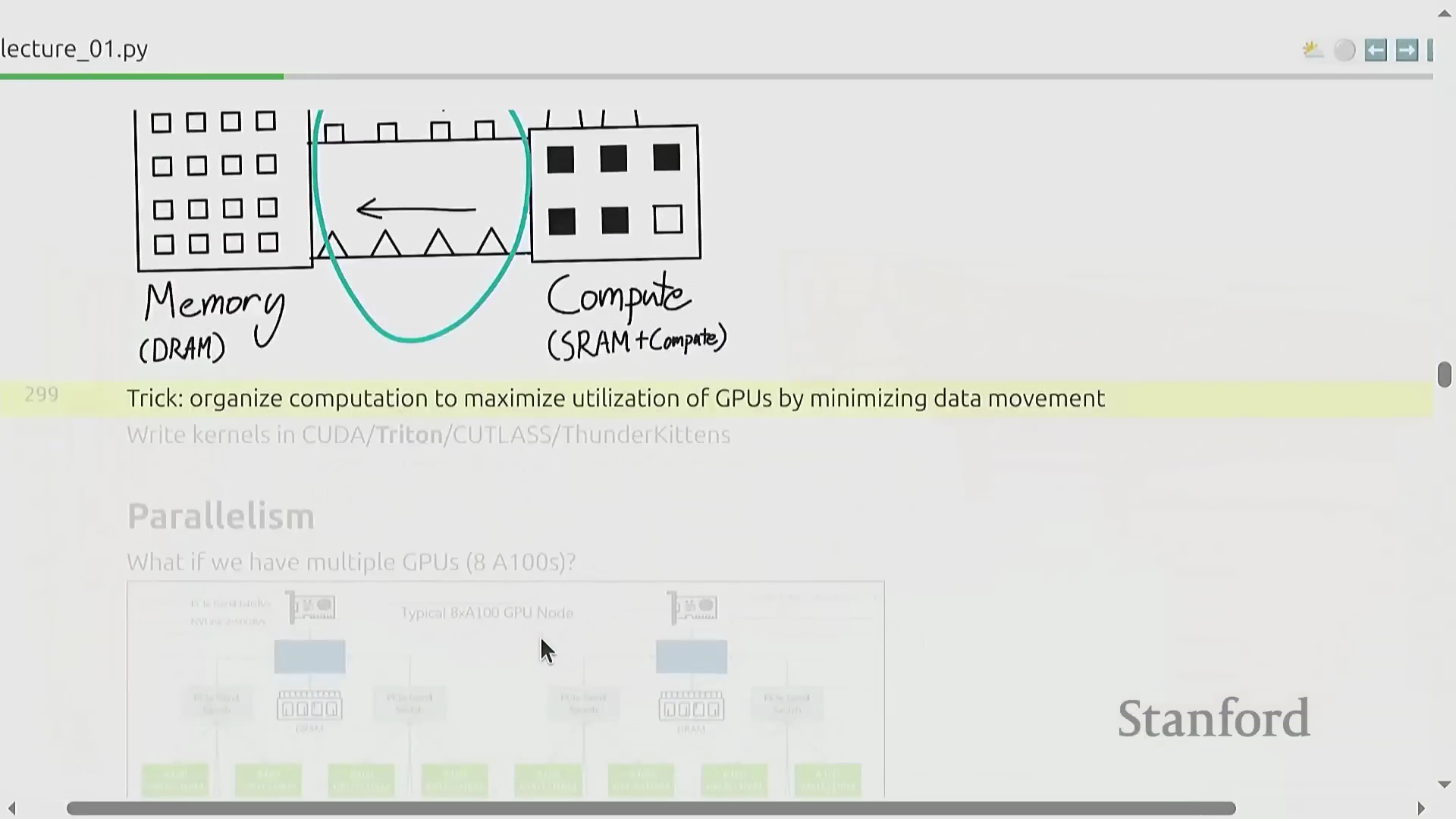
多 GPU 并行与分布式扩展
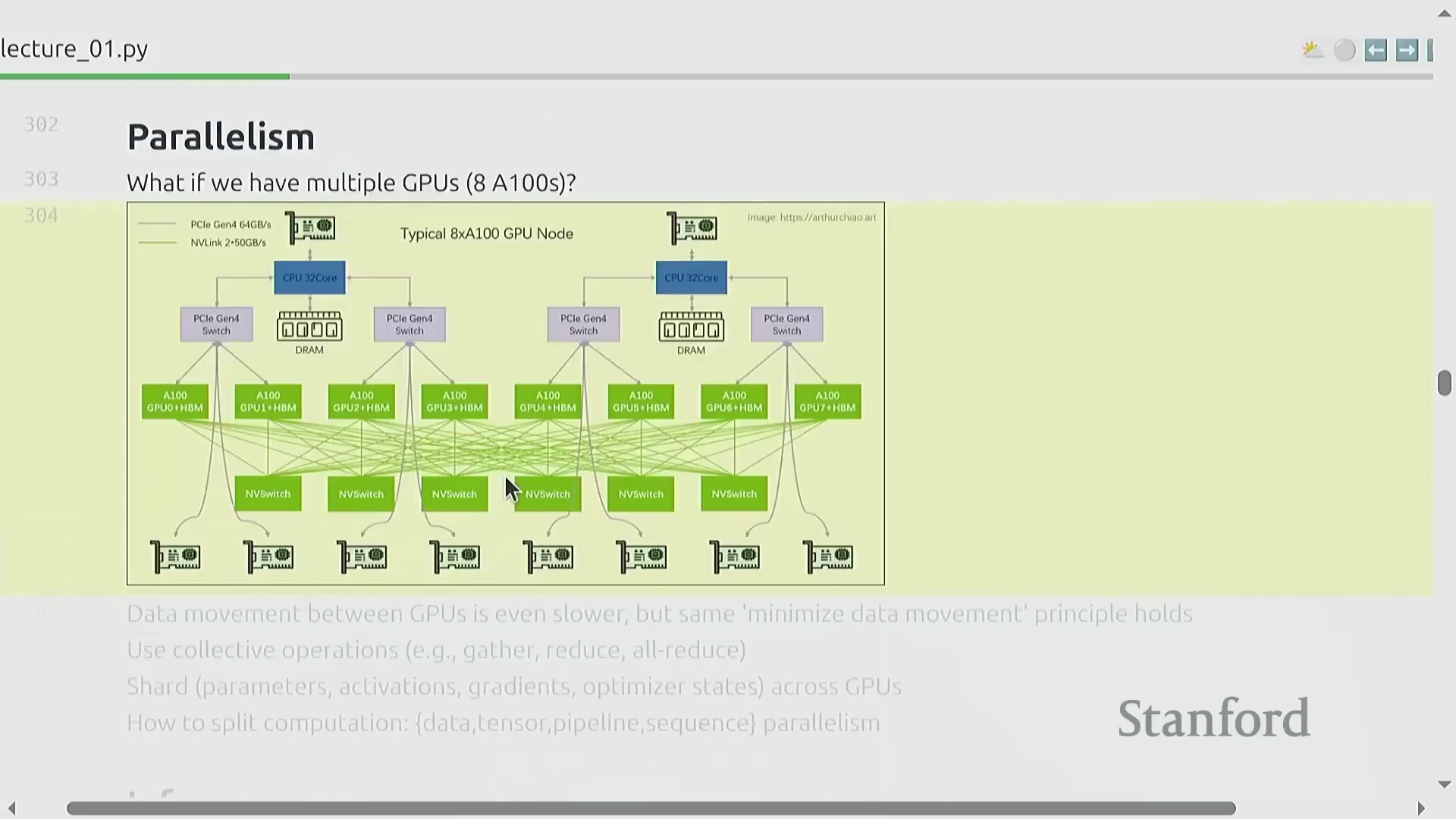
训练达到生产规模(Production-scale)的模型必须依赖互连的 GPU 集群(GPU Clusters)进行分布式扩展(Distributed Scaling)。即便在相对较小的规模(如 8 张 GPU)下,节点间通信开销(Communication Overhead)也会变得十分显著。尽管 NVLink 和 NVSwitch 等高速互连技术(High-speed Interconnects)能够有效降低通信延迟,但跨设备的数据传输速度依然远低于芯片内部的数据传输速率。高效的分布式训练(Distributed Training)要求根据硬件拓扑结构(Hardware Topology),对模型参数、梯度(Gradients)和激活值进行策略性切分(Sharding)。学员将深入学习基础的并行策略(Parallelism Strategies),包括数据并行(Data Parallelism)和张量并行(Tensor Parallelism),从而高效分配计算负载(Computational Load),并在前向传播(Forward Propagation)与反向传播(Backward Propagation)过程中最大限度地消除跨 GPU 通信瓶颈。
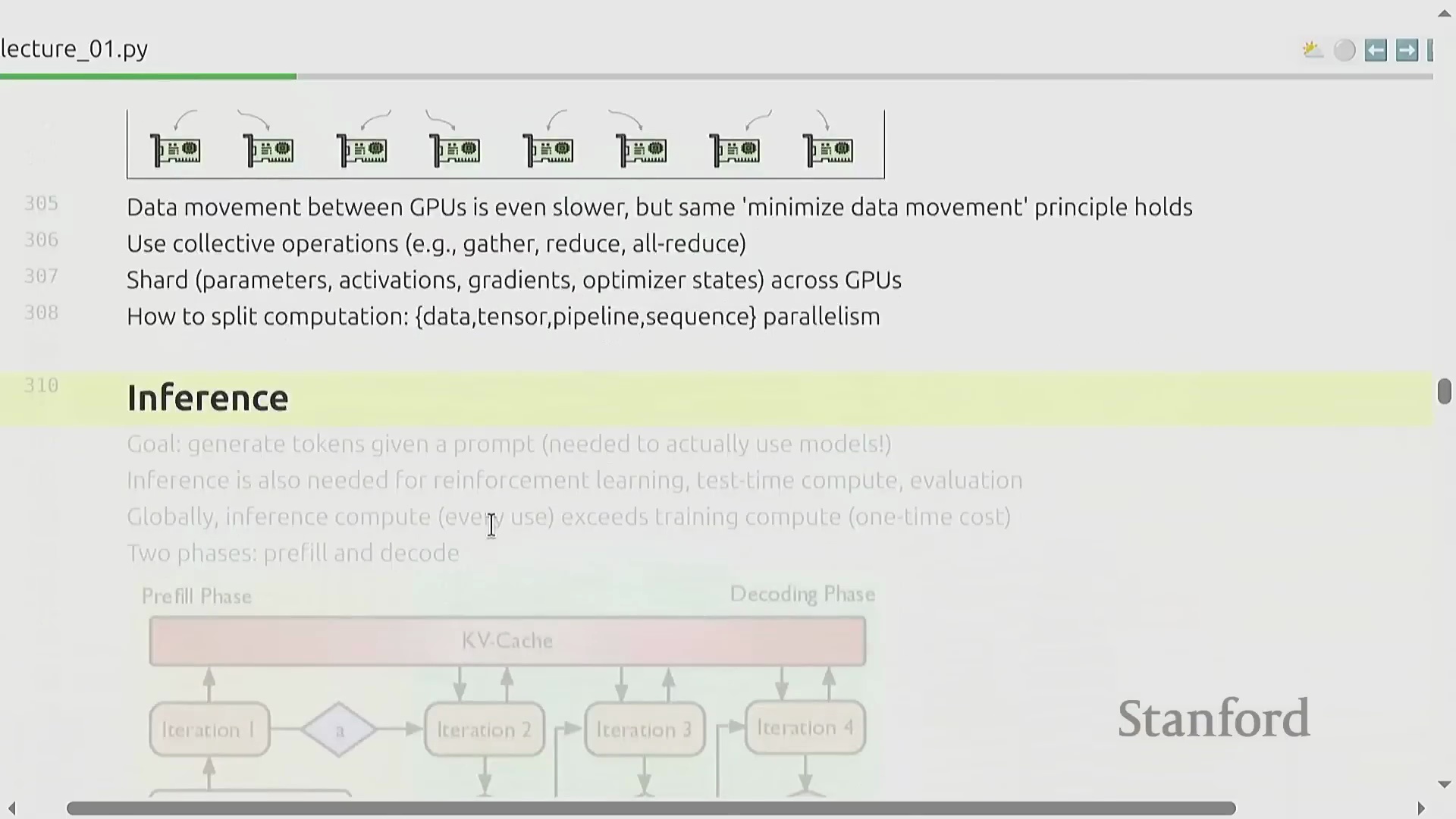
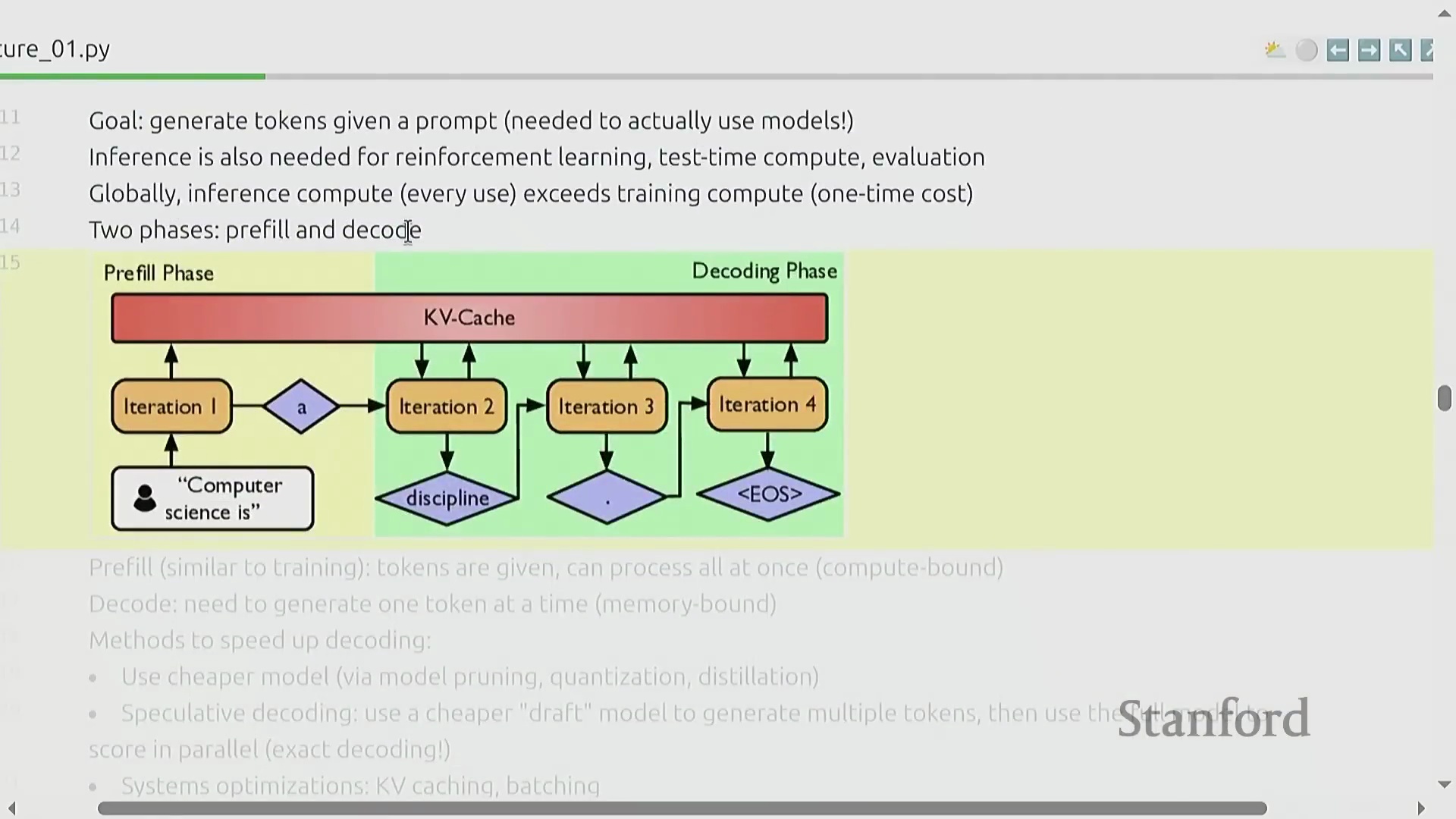
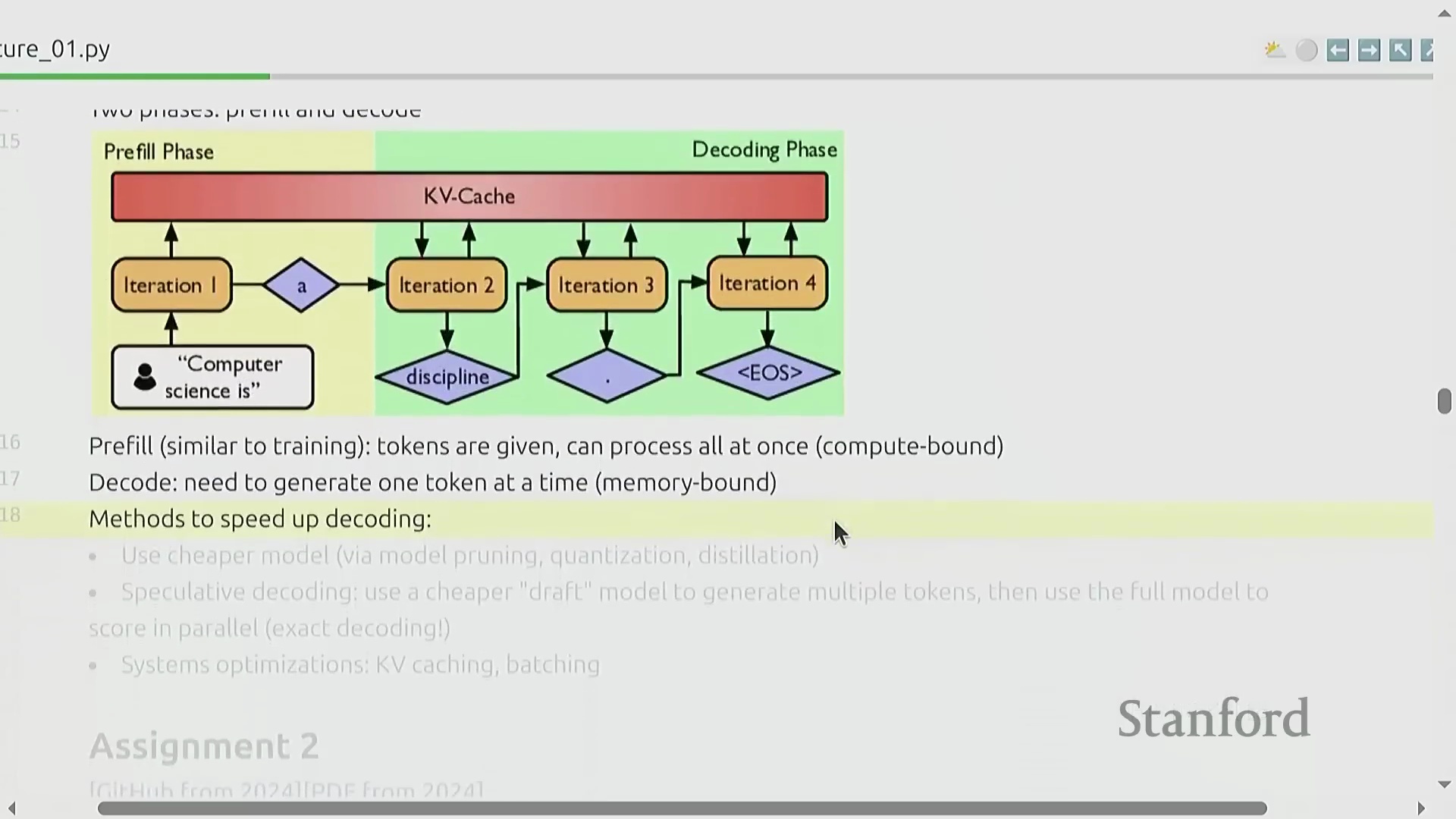
推理瓶颈与投机解码
随着人工智能技术的大规模普及,由于模型部署具有高频次调用及按使用量计费(Usage-based Billing)的特性,模型推理成本(Inference Cost)正迅速超越训练成本。模型推理过程通常分为两个截然不同的阶段:预填充阶段(Pre-fill Phase),输入提示词被并行处理,该阶段通常受算力限制(Compute-bound);以及解码阶段(Decode Phase),模型以自回归方式(Auto-regressive Manner)逐个生成词元(Token),该阶段严重受内存带宽限制(Memory-bound)。优化推理性能(Inference Performance)不仅对面向终端用户的应用至关重要,也是强化学习(Reinforcement Learning)与测试时计算扩展(Test-time Compute Scaling)策略的核心环节。先进的推理加速技术(Inference Acceleration Techniques)包括部署经过知识蒸馏(Knowledge Distillation)的轻量级模型,以及实现投机解码(Speculative Decoding):即由一个较小的草稿模型(Draft Model)快速生成候选词元序列,再由主模型(Target Model)进行并行验证(Parallel Verification)。该技术可在不牺牲生成质量(Generation Quality)的前提下,大幅提升推理吞吐量(Inference Throughput)。

系统级优化与性能剖析的必要性
在掌握底层计算内核(Kernels)与并行计算(Parallel Computing)的基础上,本课程着重强调实用的多GPU策略(Multi-GPU Strategies)。尽管像完全分片数据并行(Fully Sharded Data Parallel, FSDP)这类完整的模型并行框架从零构建极为复杂,但学员将亲手实现基础的数据并行(Data Parallelism)及简化版的分布式训练(Distributed Training)。至关重要的是,本课程致力于培养一种严谨的工程规范:持续进行基准测试(Benchmarking)与性能剖析(Profiling)。若缺乏对实现性能的实证反馈(Empirical Feedback)以及对系统瓶颈的精准定位,优化工作将如同盲人摸象,难以触及核心瓶颈。熟练掌握性能剖析工具的重要性,与编写高质量代码本身同等关键。

缩放定律与算力最优分配
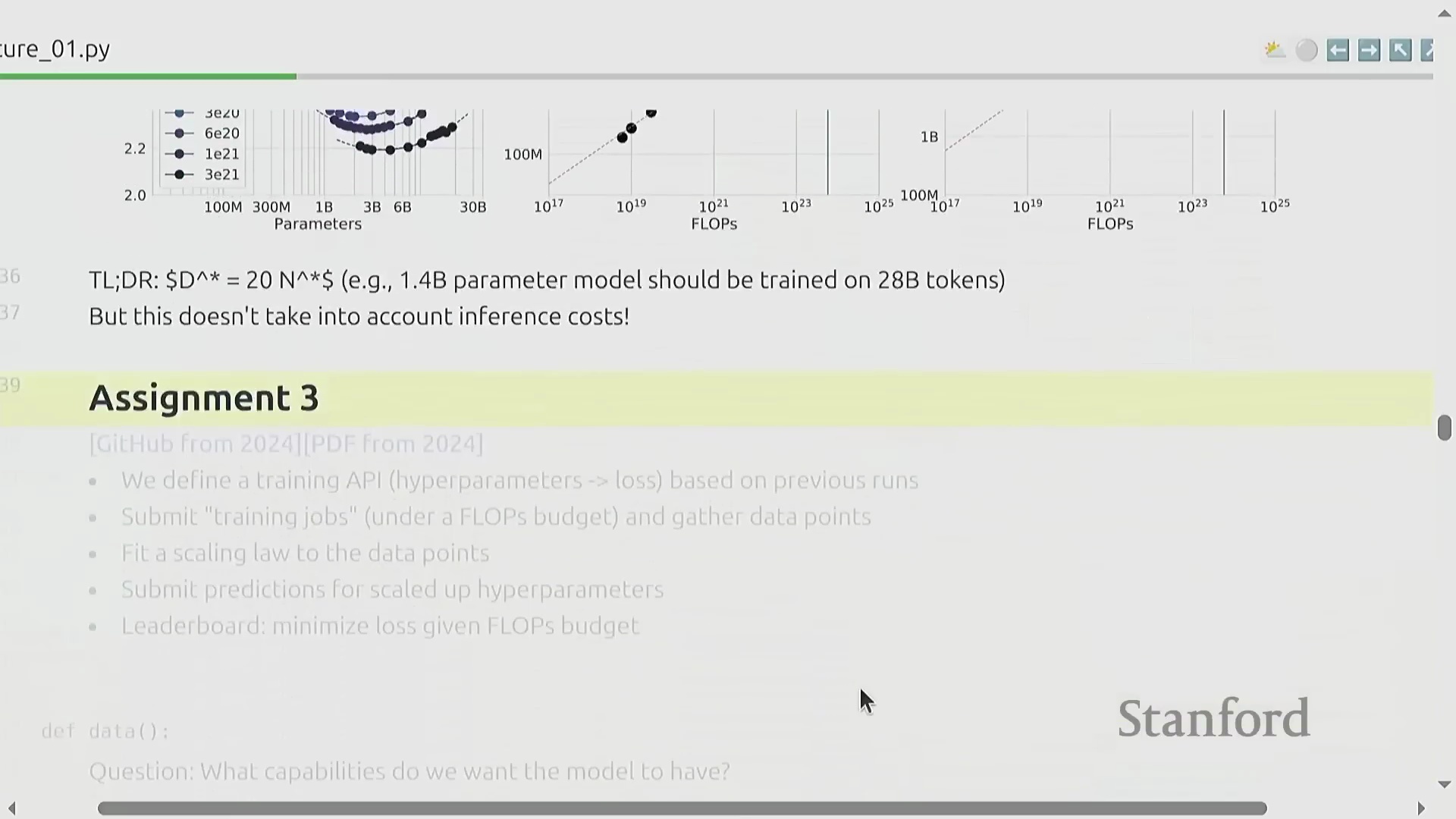
第三单元将重点转向缩放定律(Scaling Laws),探讨一个核心的资源分配(Resource Allocation)问题:在固定的算力预算(Compute Budget)下,模型参数量(Model Parameters)与训练数据量(Training Tokens)之间的最佳平衡点究竟何在?DeepMind 关于 Chinchilla 最优配置(Chinchilla-optimal)的开创性研究揭示,算力投入与模型性能之间存在高度可预测的幂律关系(Power-law Relationship)。由此衍生出一条极具实用价值的经验法则(Rule of Thumb):最优的训练词元数量应约为模型参数量的 20 倍。尽管该框架在优化目标上更侧重于最小化训练损失(Training Loss),而非直接考量下游推理成本(Downstream Inference Cost),但它为预测超大规模模型的性能表现提供了一套具有坚实数学依据的方法论。

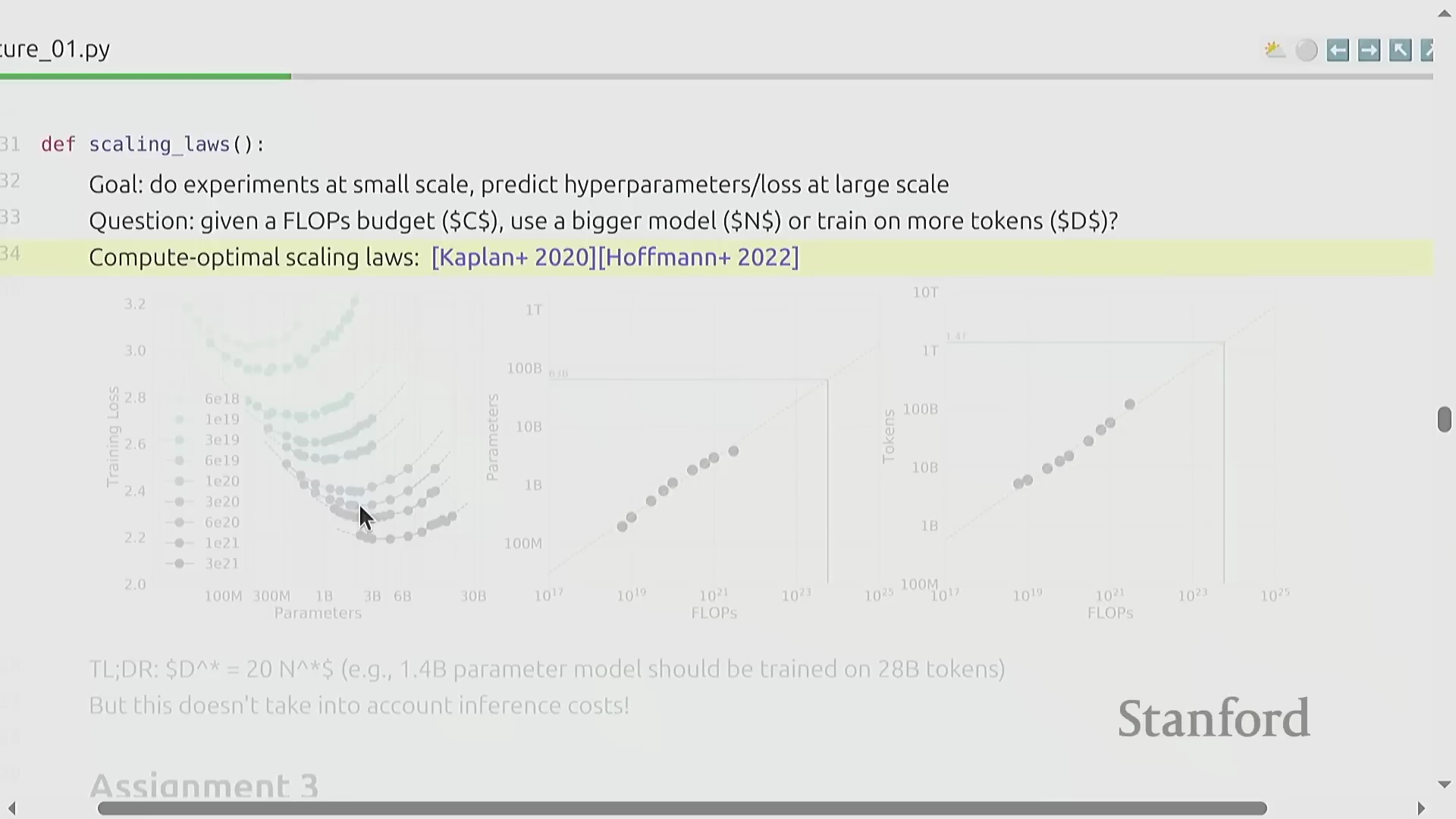
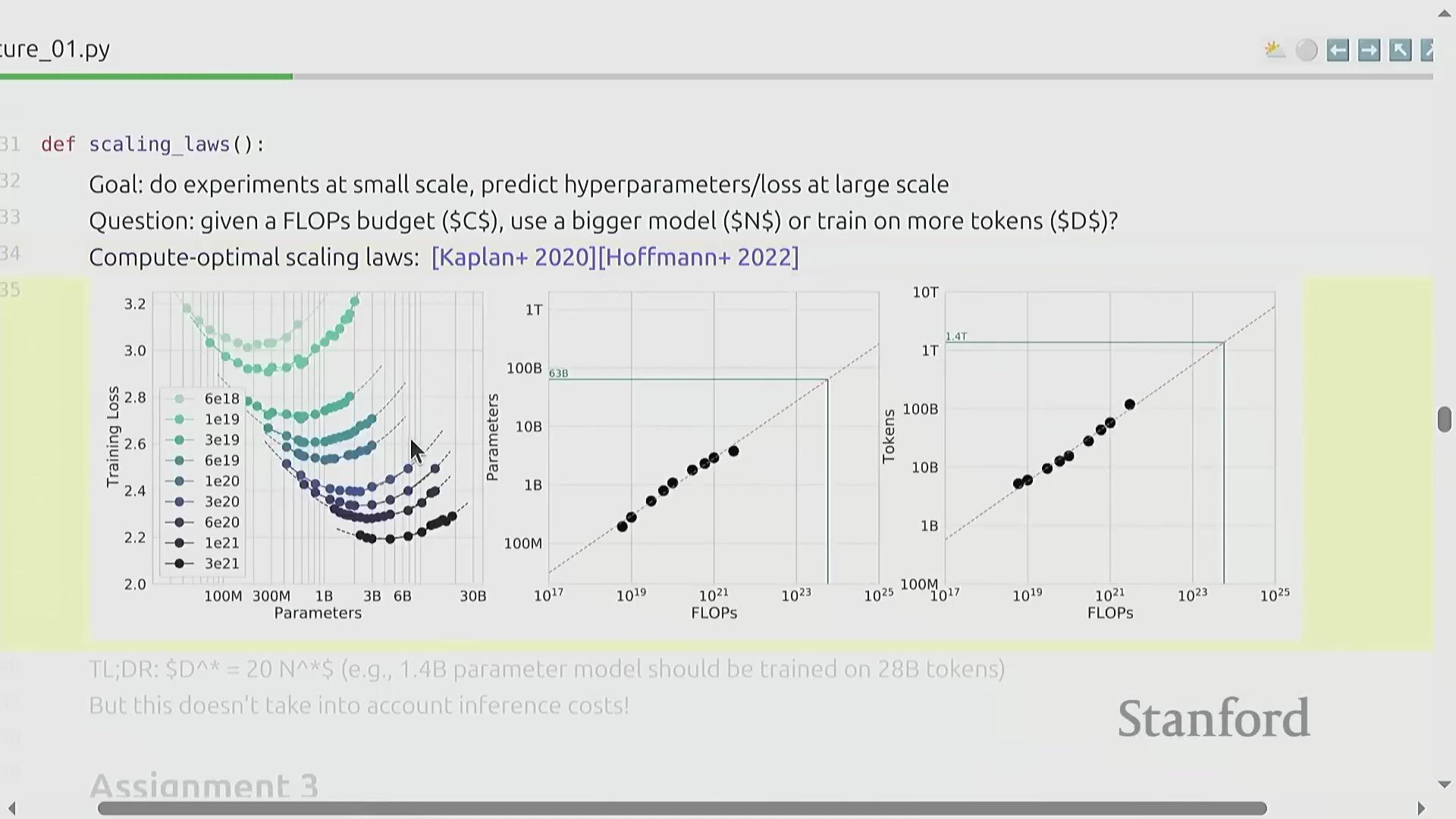
作业 3:约束条件下的实验设计
为帮助学员深入理解规模扩展的动态规律(Scaling Dynamics),作业 3(Assignment 3)将其置于一个高成本约束的模拟环境中。借助一个可根据给定超参数(Hyperparameters)快速返回损失值(Loss Values)的训练模拟接口(Training Proxy API),学习者必须在严格且有限的 FLOPs(浮点运算次数)预算内开展实验。其核心目标是策略性地执行小规模试点实验,利用采集的数据拟合缩放定律曲线(Scaling Law Curves),并据此外推(Extrapolate)出适用于大规模部署的最佳模型架构与训练配置。该练习高度还原了前沿 AI 实验室的真实运营约束(Operational Constraints),旨在教导学员如何科学规划实验优先级——在此场景下,每一次算力调用(Compute Invocation)都伴随着明确的成本,任何资源浪费都将直接制约最终的模型性能上限。

数据驱动的能力与评估框架
第四单元明确指出,数据构成(Data Composition)(而非单纯的模型架构)从根本上决定了模型的能力边界。使用多语言语料库(Multilingual Corpora)或高质量代码数据集进行训练,会直接赋予模型相应的跨语言或编程能力,这使得数据集混合配比(Data Mixture Ratios)成为一项至关重要的战略决策。在深入探讨数据获取(Data Acquisition)之前,课程首先系统讲解了严谨的模型评估方法。除了标准的困惑度(Perplexity, PPL)与大规模多任务语言理解基准(Massive Multitask Language Understanding, MMLU)等学术测试外,学员还将深入探索用于评估指令遵循能力(Instruction Following)、思维链推理(Chain-of-Thought, CoT)以及复杂智能体(Agentic)系统的各项量化指标。这些评估框架(Evaluation Frameworks)构成了不可或缺的反馈闭环(Feedback Loop),用于严格验证经过精心筛选的数据集是否真正转化为了预期的现实世界性能(Real-world Performance)。

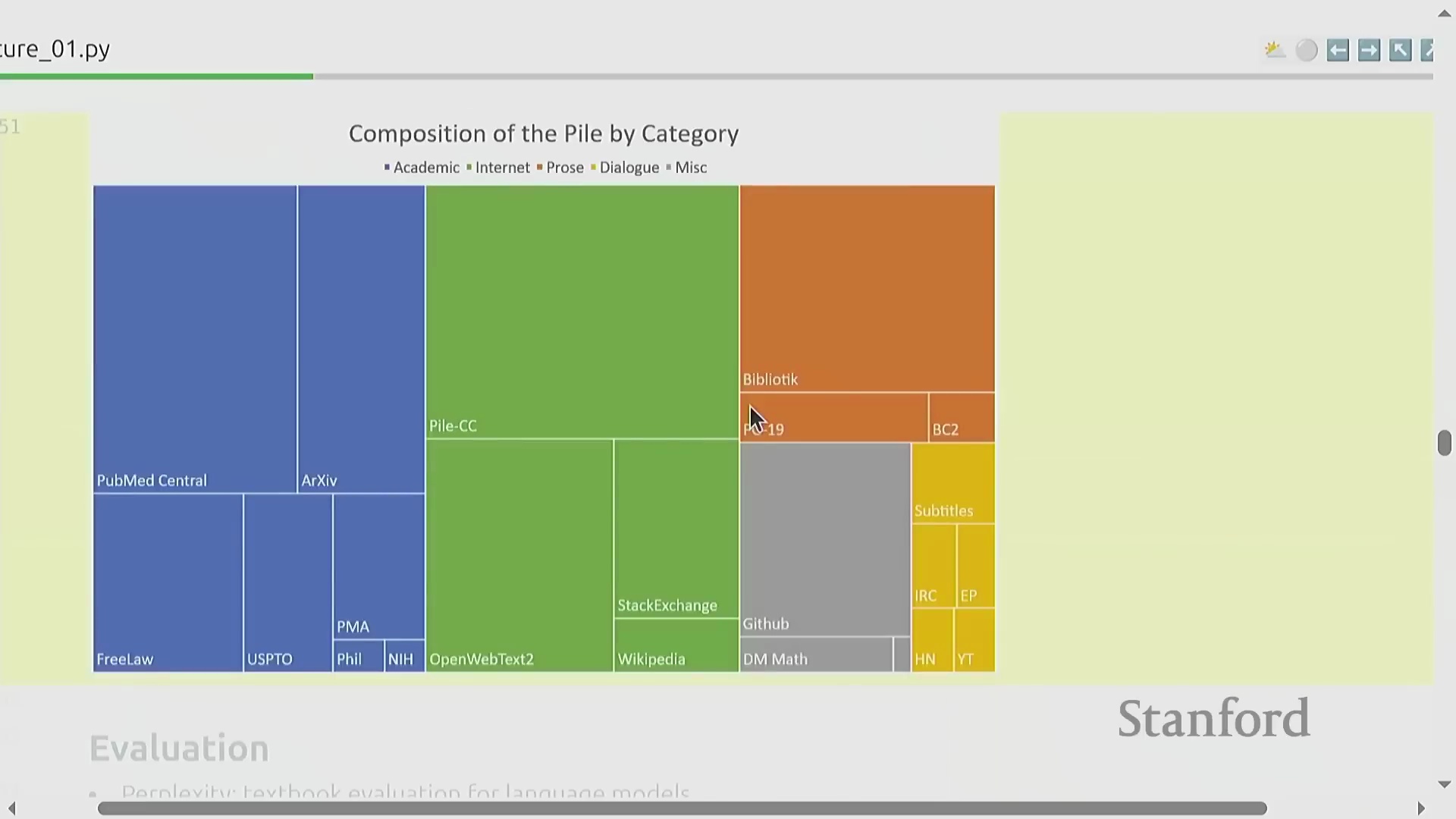


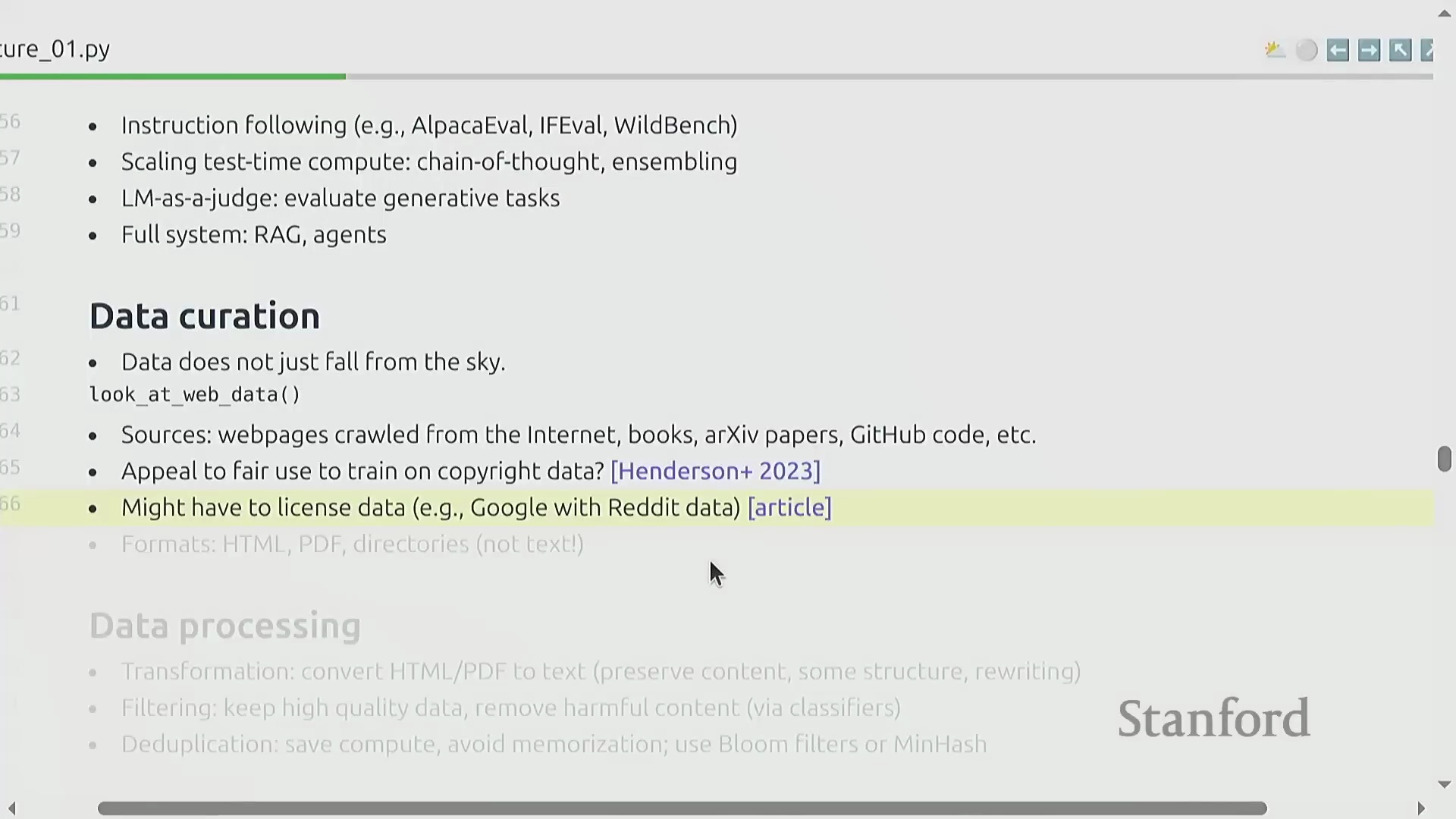
数据整理的现实:绝非“仅仅抓取互联网”
业界普遍存在一个误解,认为大语言模型仅仅是“在互联网原始数据上进行训练”。事实上,类似 Common Crawl 的原始网页爬取数据(Raw Web Crawl Data)充斥着大量低质内容、重复样板文本(Boilerplate Text)以及多语言混杂噪声。因此,数据整理(Data Curation)是一项高强度、多阶段的流水线工程,涵盖主动数据获取(Proactive Data Acquisition,通常涉及采购专有数据集)、法律合规审查(Legal Compliance Review)以及格式清洗与转换。将 HTML 或 PDF 文档解析为纯净文本本身就是一个有损过程(Lossy Process),必须谨慎操作以保留文档的层级与语义结构(Semantic Structure)。后续处理阶段则高度依赖基于分类器的质量过滤与安全评分(Classifier-based Filtering & Safety Scoring),并结合严格的近重复与精确去重处理(Deduplication),从而从杂乱无章的原始数据中,提炼出高信噪比(High Signal-to-Noise Ratio)的优质训练语料库。


作业 4:原始数据整理与过滤
作业 4(Assignment 4)通过提供原始的 Common Crawl 数据转储(Data Dumps),让学员直接深入数据处理流水线(Data Processing Pipeline)。其主要目标是将杂乱无章的网络爬取数据转化为高质量的训练语料。学员必须构建并训练自定义分类器(Custom Classifiers),实施严格的去重技术(Deduplication Techniques),并谨慎管理词元预算(Token Budget)。模型性能将通过竞争性排行榜(Competitive Leaderboard)进行评估,核心目标是最小化下游任务的困惑度(Perplexity)。该练习凸显了一个关键现实:模型质量从根本上受限于其训练语料库(Training Corpus)的质量与数据构成。

对齐过程:从基础模型到实用工具
预训练(Pre-training)阶段会生成一个具备巨大原始潜力的“基础模型(Base Model)”,其核心能力仅限于预测下一个词元(Next-Token Prediction)。模型对齐(Model Alignment)过程通过灌输三种关键行为——指令遵循(Instruction Following)、风格控制(Style Control)与安全护栏(Safety Guardrails)——将这种原始能力转化为面向终端用户的实用工具。与仅能机械续写提示词的基础模型不同,经过对齐的模型能够精准遵循用户指令,自适应调整输出格式(如控制长度、生成要点列表、切换语气等),并能安全地拒绝有害或违规请求。这一范式转变对于将底层的文本生成能力转化为可靠、可交互的 AI 助手(AI Assistants)至关重要。

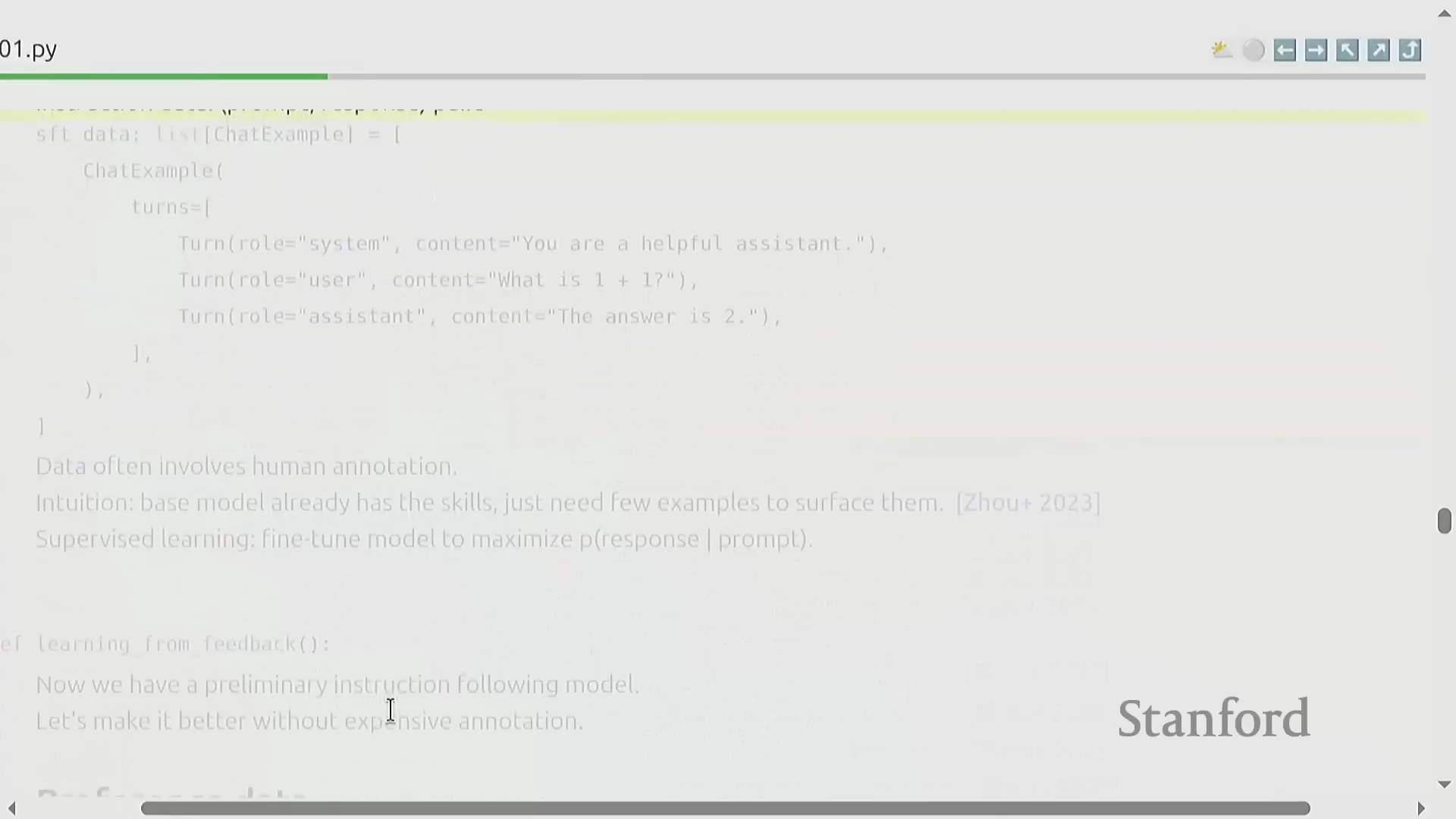
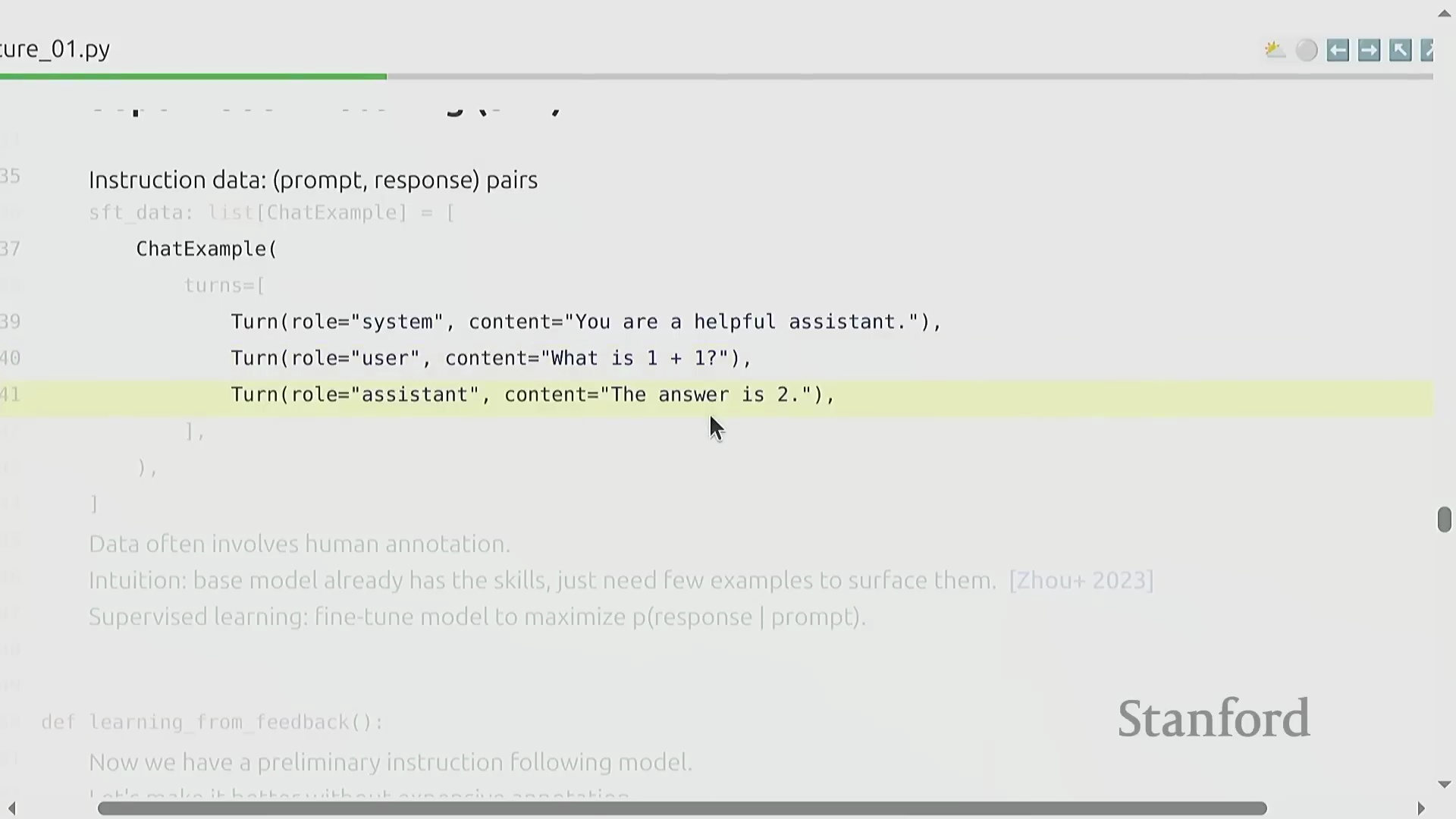
监督微调与偏好学习
模型对齐的第一阶段是监督微调(Supervised Fine-Tuning, SFT),其旨在充分激发基础模型已有的预训练知识。通过在高质量的“提示-回复”(Prompt-Response)配对数据上进行训练,即使是规模相对较小的数据集(约 1000 个样本)也能激发出强大的指令遵循能力。为了在不依赖昂贵人工标注的情况下实现超越 SFT 的性能,课程引入了反馈驱动学习(Feedback-driven Learning)。这主要包括两类机制:一是偏好数据(Preference Data),模型借此学习对生成结果进行对比排序(例如判断回复 A 优于回复 B);二是验证器(Verifiers),它利用形式化规则(适用于代码或数学问题)或辅助验证模型,自动为模型输出质量进行量化评分。
强化学习算法与作业 5 实现
不同的反馈信号需要匹配不同的优化算法(Optimization Algorithms)。尽管近端策略优化(Proximal Policy Optimization, PPO)在历史上曾占据主导地位,但诸如直接偏好优化(Direct Preference Optimization, DPO)等更为简洁的方法已被证实,仅凭偏好数据即可取得卓越的对齐效果。针对需要完整强化学习框架的验证器反馈,课程将引入并实现分组相对策略优化(Group Relative Policy Optimization, GRPO)。由 DeepSeek 提出的 GRPO 算法通过移除独立的评论家网络/价值函数(Value Function)简化了传统 PPO 流程,在保持对齐性能的同时显著降低了显存开销(Memory Overhead)。作业 5(Assignment 5)要求学员从零实现 SFT、DPO 和 GRPO 算法,并进行严格的消融与性能评估。尽管作业 1 与作业 2 在计算资源消耗与概念复杂度上最为艰巨,但课程最后两次作业在设计上力求兼具挑战性(Challenging)与高度的工程可控性(Controlled Scope)。

效率的核心驱动力与阶段转变
现代人工智能系统中,每一项架构设计与训练决策的根本驱动力皆是效率(Efficiency),尤其是在算力受限(Compute-constrained)的现实环境中。激进的数据过滤(Data Filtering)、字节对编码分词(Byte-Pair Encoding, BPE)、单轮次训练(Single-epoch Training)以及基于缩放定律的外推(Scaling Law Extrapolation),均旨在最大化单位浮点运算性能(Performance per FLOP)。然而,行业正经历一场显著的范式转变(Paradigm Shift):前沿研究机构正从“算力受限”阶段加速向“数据受限”(Data-constrained)阶段过渡。随着高质量训练数据逐渐成为稀缺瓶颈,未来的训练范式或将逐步摒弃严格的单轮次训练,转而采用多轮次训练策略(Multi-epoch Training)或不再单纯追求极致计算吞吐量的新型架构。深刻理解这种效率诉求与资源约束(Resource Constraints)之间的动态关系,对于准确预判下一波人工智能技术演进浪潮至关重要。


课程安排、评分与访问权限
所有课程的作业评分主要依赖于自动化单元测试(Automated Unit Tests),旨在严格验证所实现算法组件的正确性与代码结构完整性。我们鼓励学员在确保数学与算法准确性的前提下,专注于构建稳健、模块化的软件架构(Robust Software Architecture)。针对外部学习者与旁听学员,本课程开放了全部讲座资料、编程作业及 Canvas 学习管理平台(Canvas LMS)资源的访问权限,确保无论是否正式注册均能享有平等的学习机会。课程最后总结强调,尽管跨越初始技术门槛具有一定挑战,但通过对现代 AI 技术栈(Tech Stack)的系统性拆解与实战,本课程为学员构建与深度理解前沿语言模型提供了一套高度可复现的工程框架(Reproducible Engineering Framework)。


评分结构与词元化概述
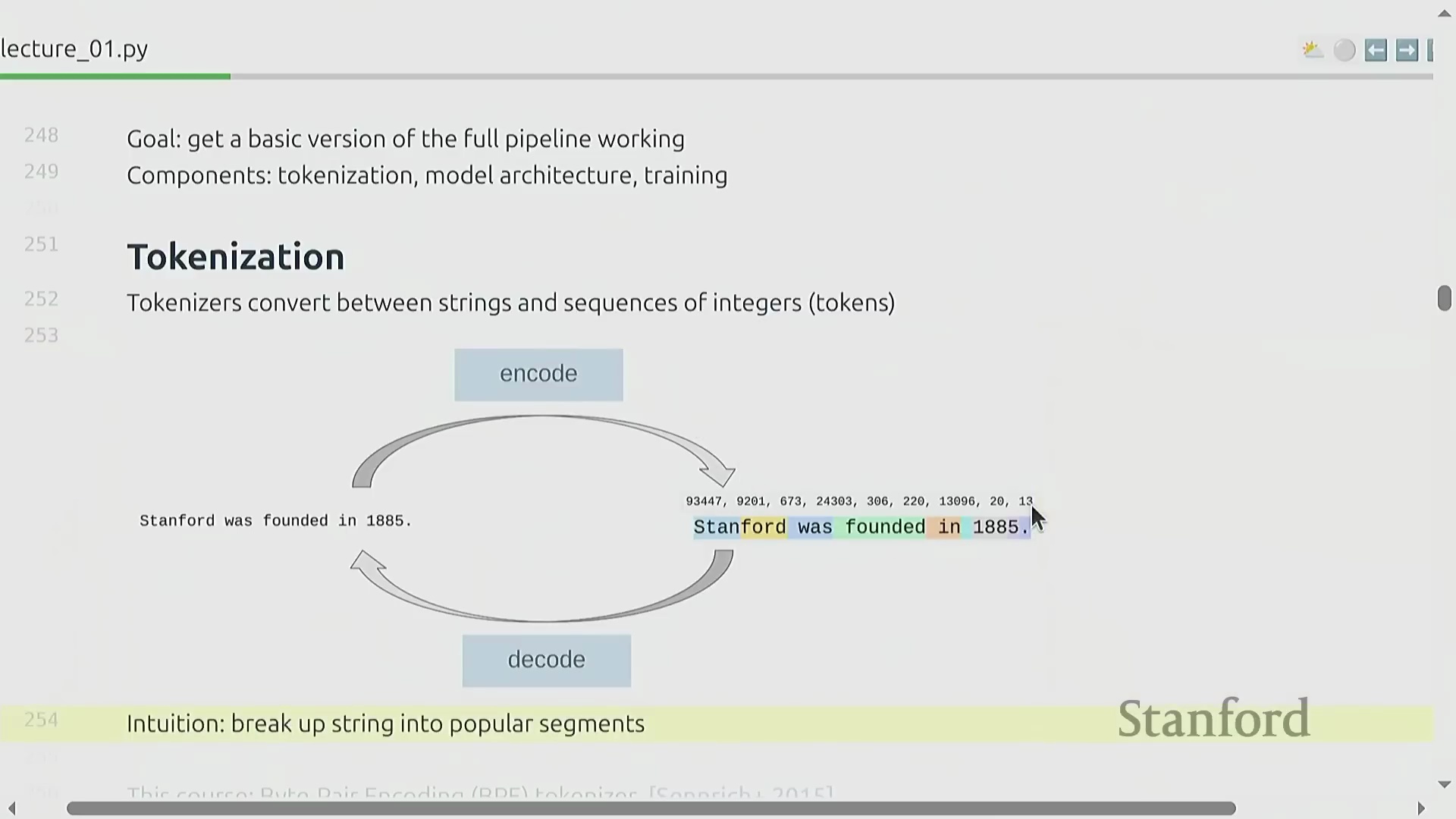
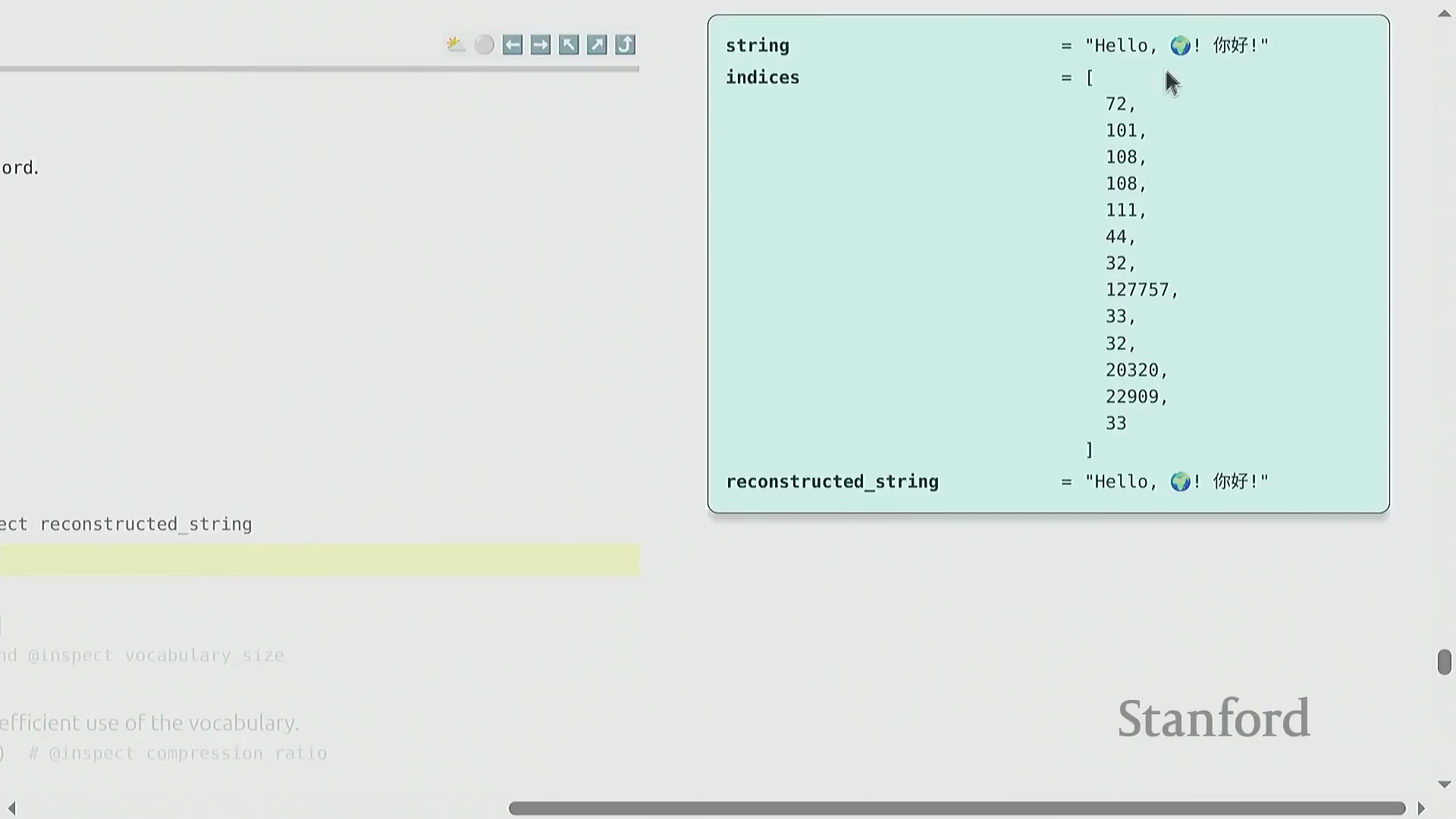
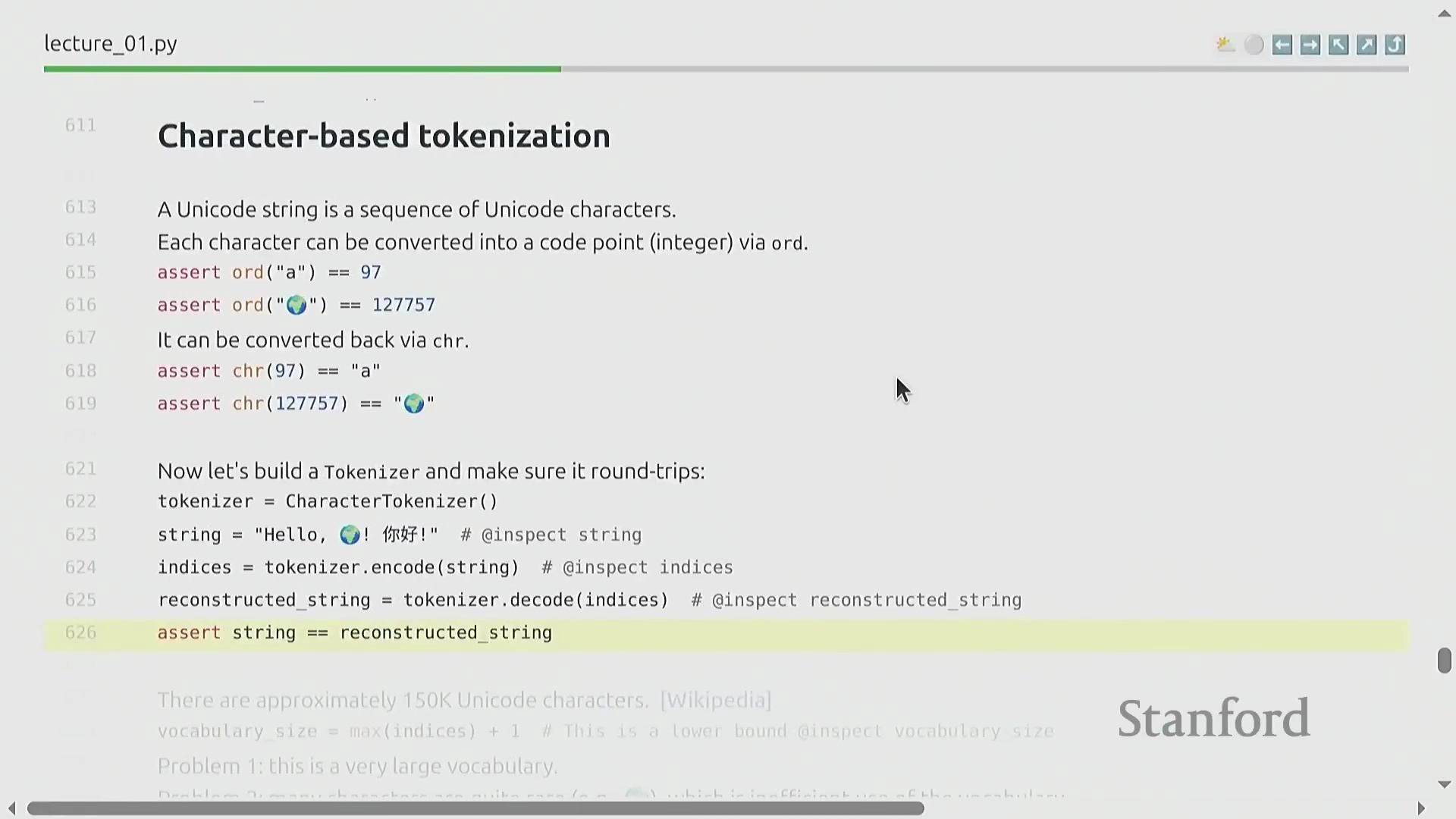
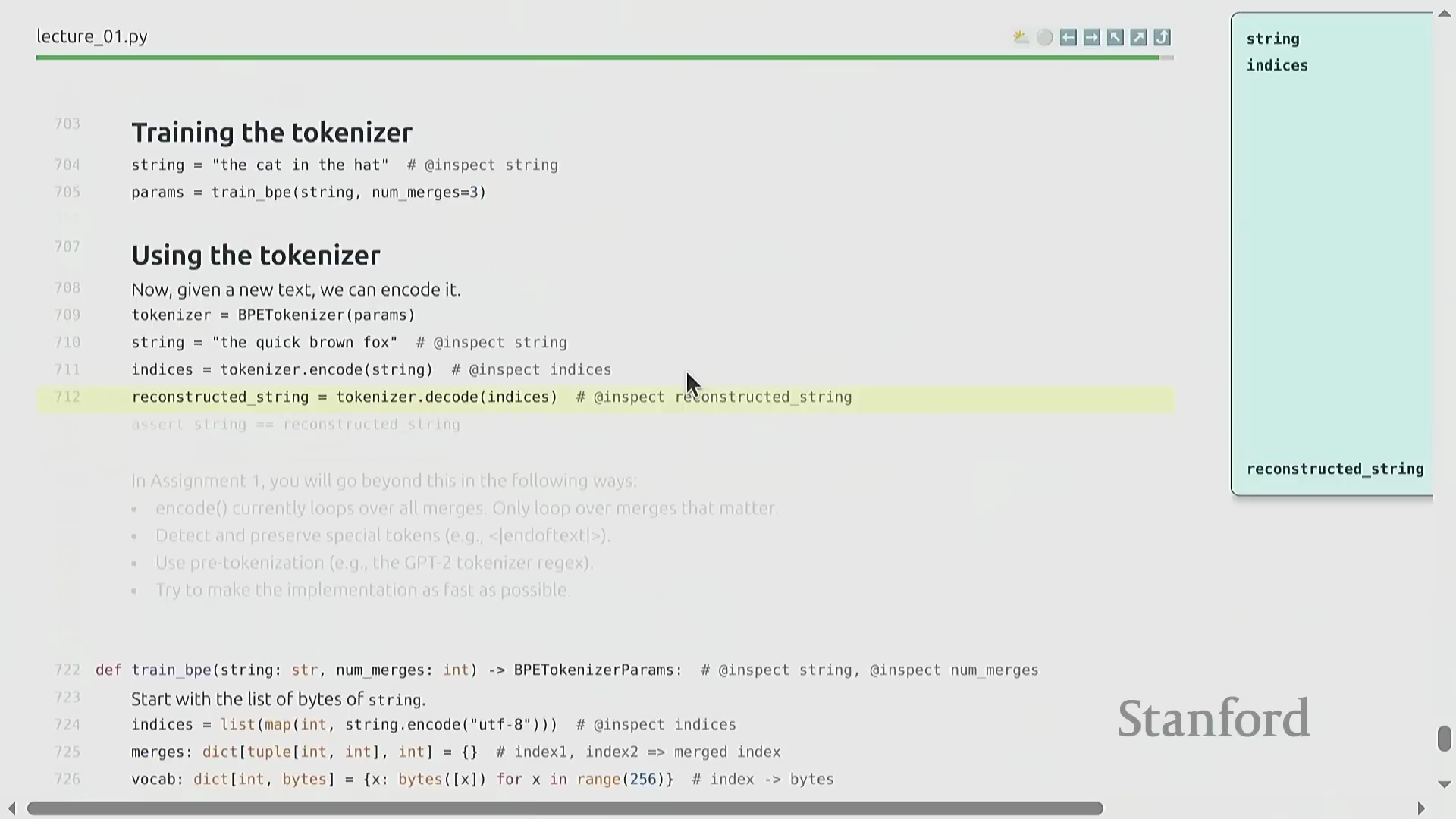
课程评分采用透明且细粒度的积分系统,既通过自动化单元测试(Automated Unit Tests)评估代码实现的正确性,也考察损失值(Loss)和计算效率(Compute Efficiency)等实际模型性能指标。每个作业组件均分配有特定权重,从而确立了清晰的技术基准。进入第一个核心模块,课程将介绍词元化(Tokenization)这一基础过程,其教学内容深受现代开源教育资源启发。词元化旨在将原始 Unicode 文本(Unicode Text)转换为整数序列(Integer Sequence),其中每个整数代表一个独立的词元(Token)。该映射关系必须是完全可逆的(Bijective Mapping),因此需要设计精确的编码(Encoding)与解码(Decoding)流程,以确保在格式转换过程中实现信息的无损传递。

交互式分词演示与空格处理
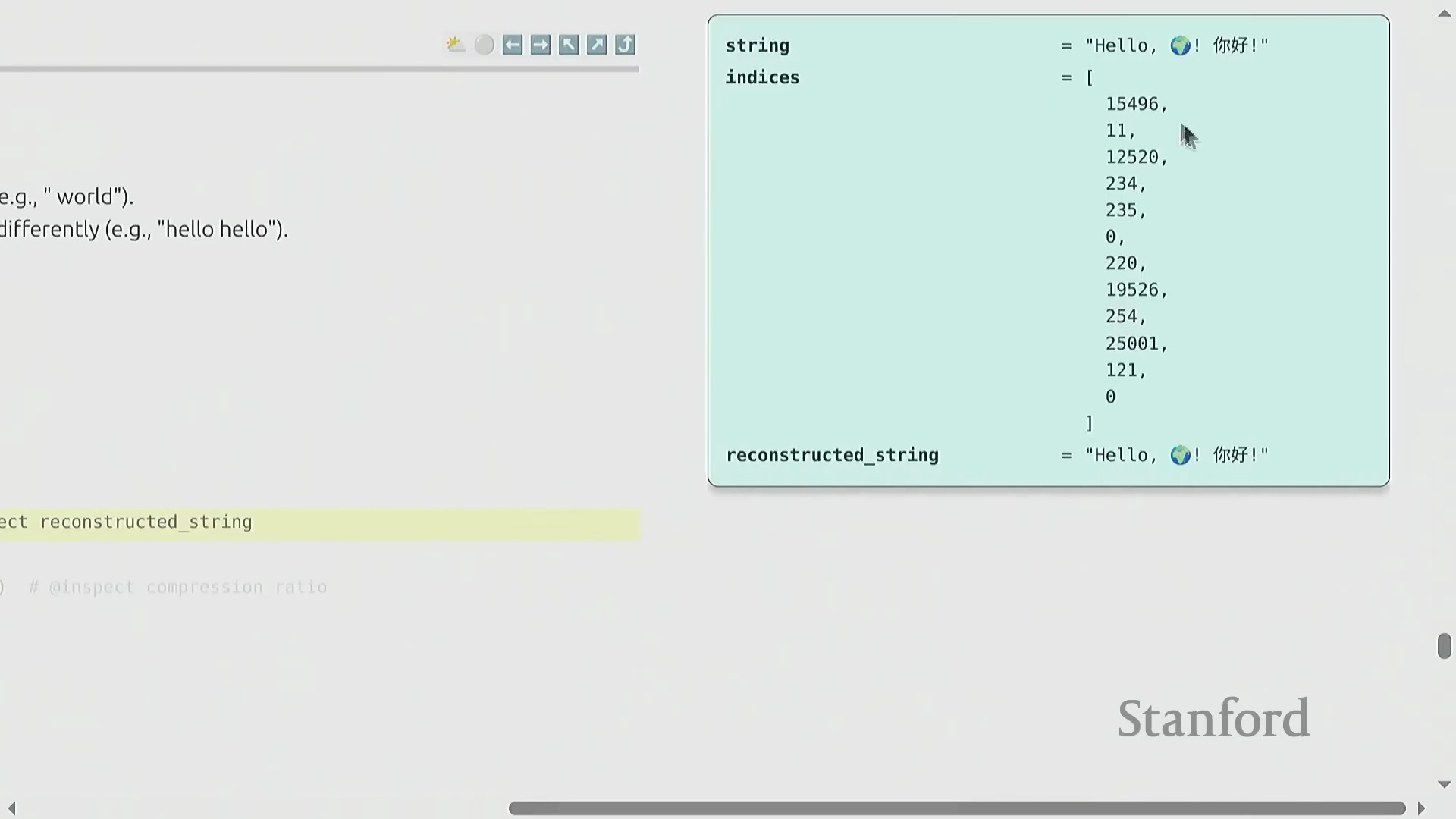
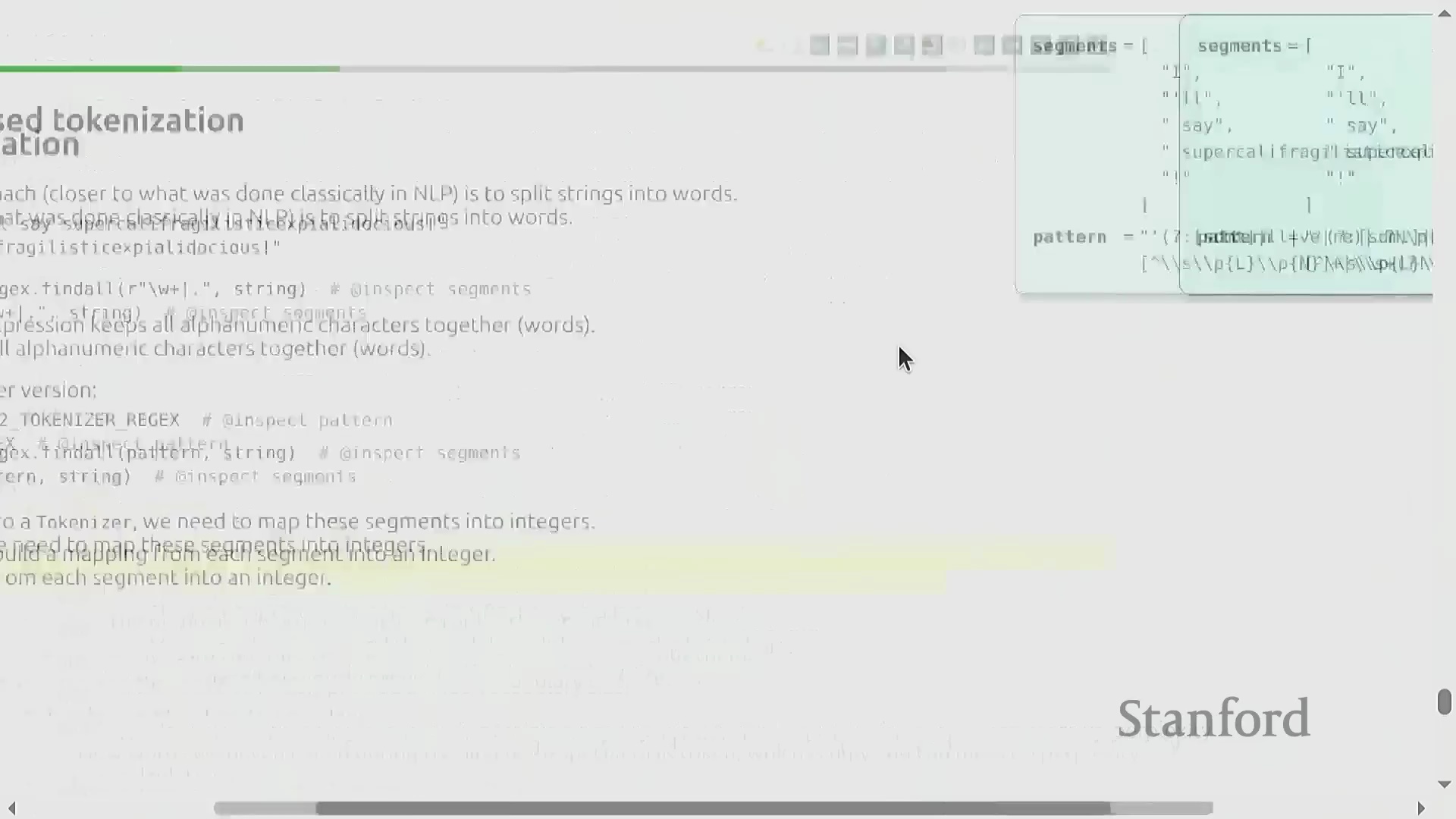
借助交互式词元化可视化工具(Interactive Tokenization Visualization Tools),我们可以直观地观察自然语言字符串如何被分解为整数序列。一个关键的架构细节在于对空格的处理:与传统自然语言处理(Natural Language Processing, NLP)流水线通常直接丢弃空格的惯例不同,现代词元化工具会显式保留空格,以确保实现完美的往返解码(Round-Trip Decoding)。按照行业惯例,空格通常会被合并至后续单词的开头(例如," hello" 会被视为一个与 "hello" 截然不同的独立词元)。尽管这种前缀空格(Prefix Space)的设计初看有悖直觉,但它已深度集成于标准的预分词(Pre-tokenization)算法中。此外,数字序列同样遵循从左至右的切分规则,其切分逻辑完全基于统计频率(Statistical Frequency),而非基于语义分组(Semantic Grouping)。


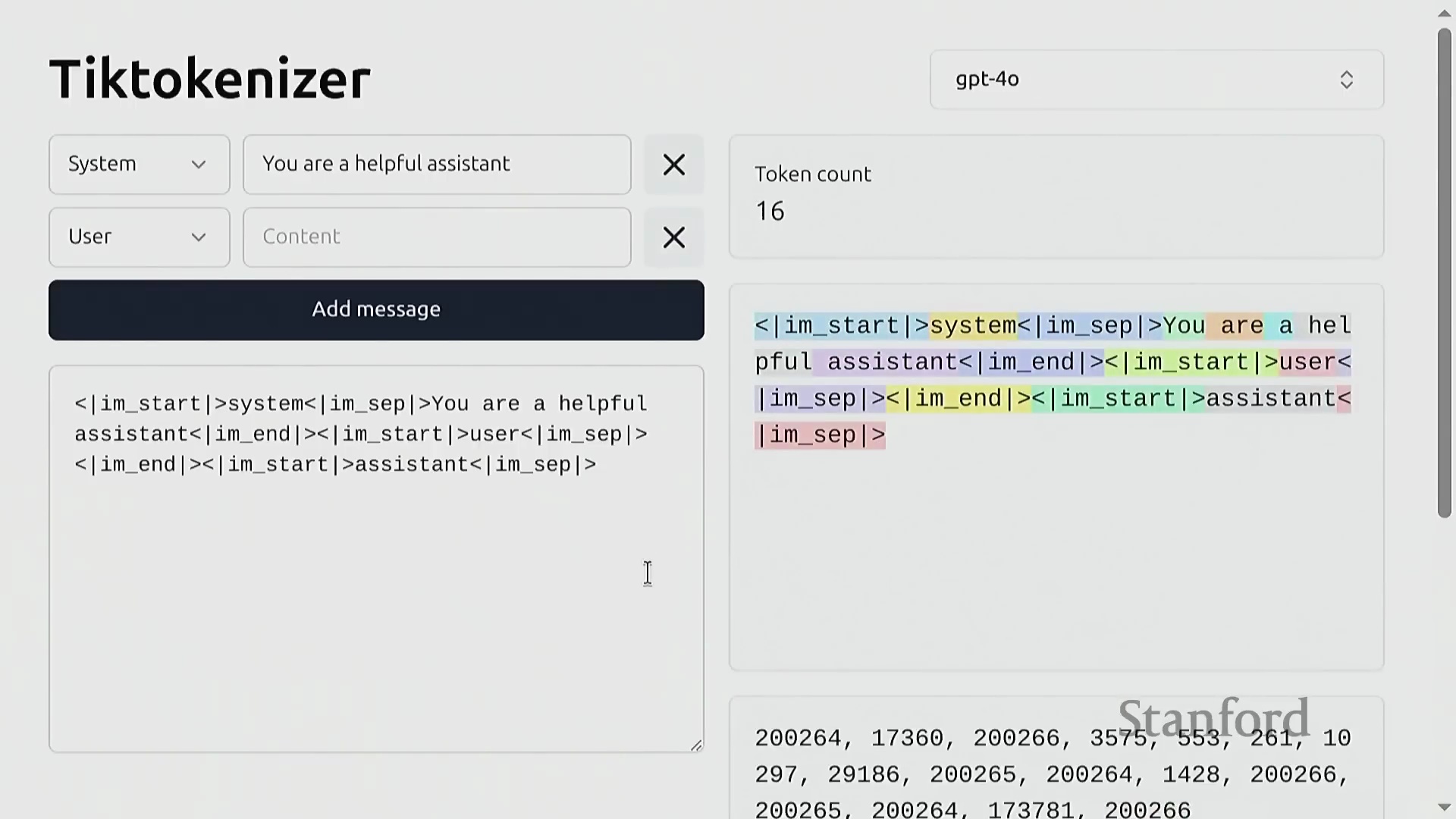
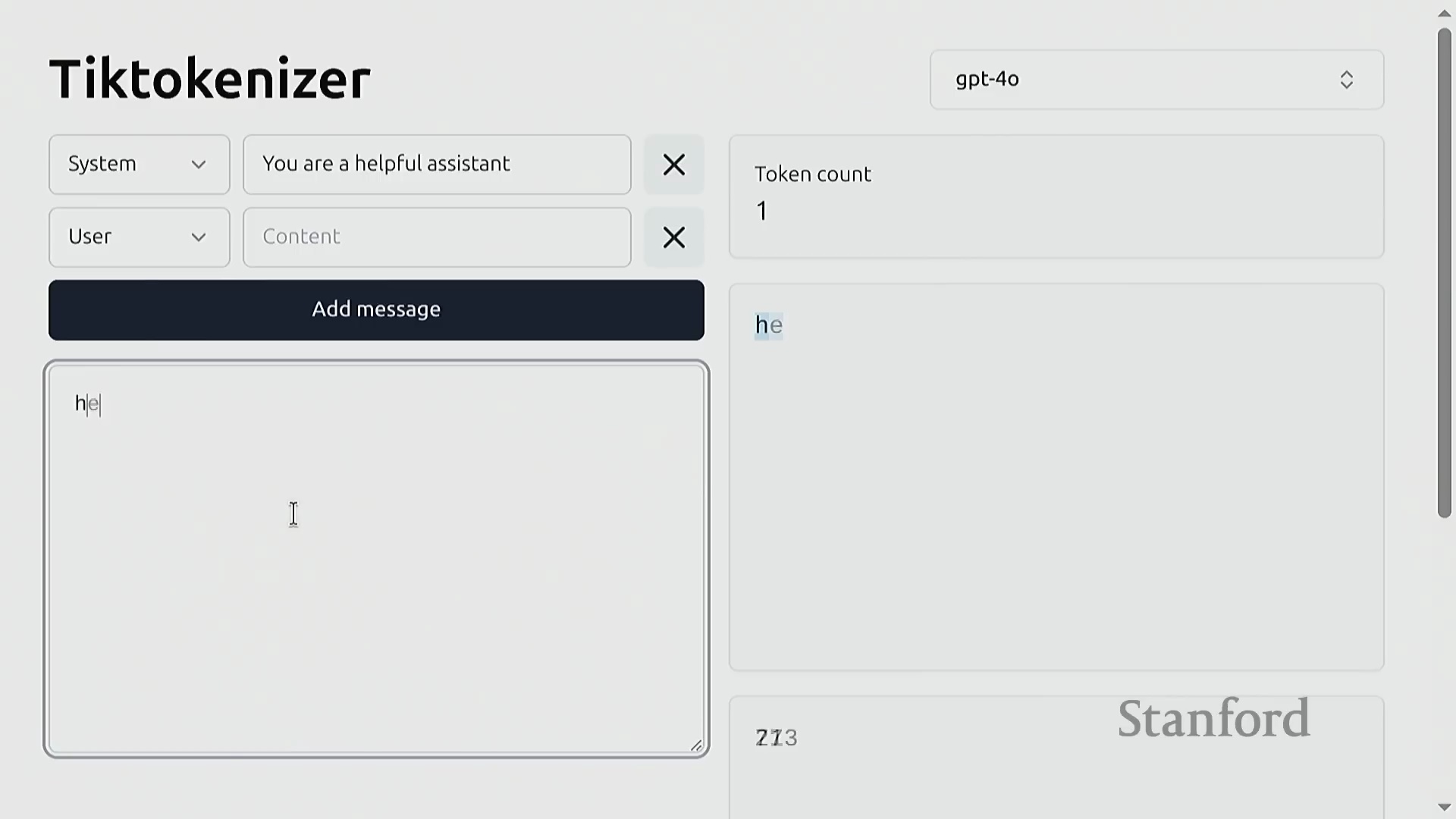
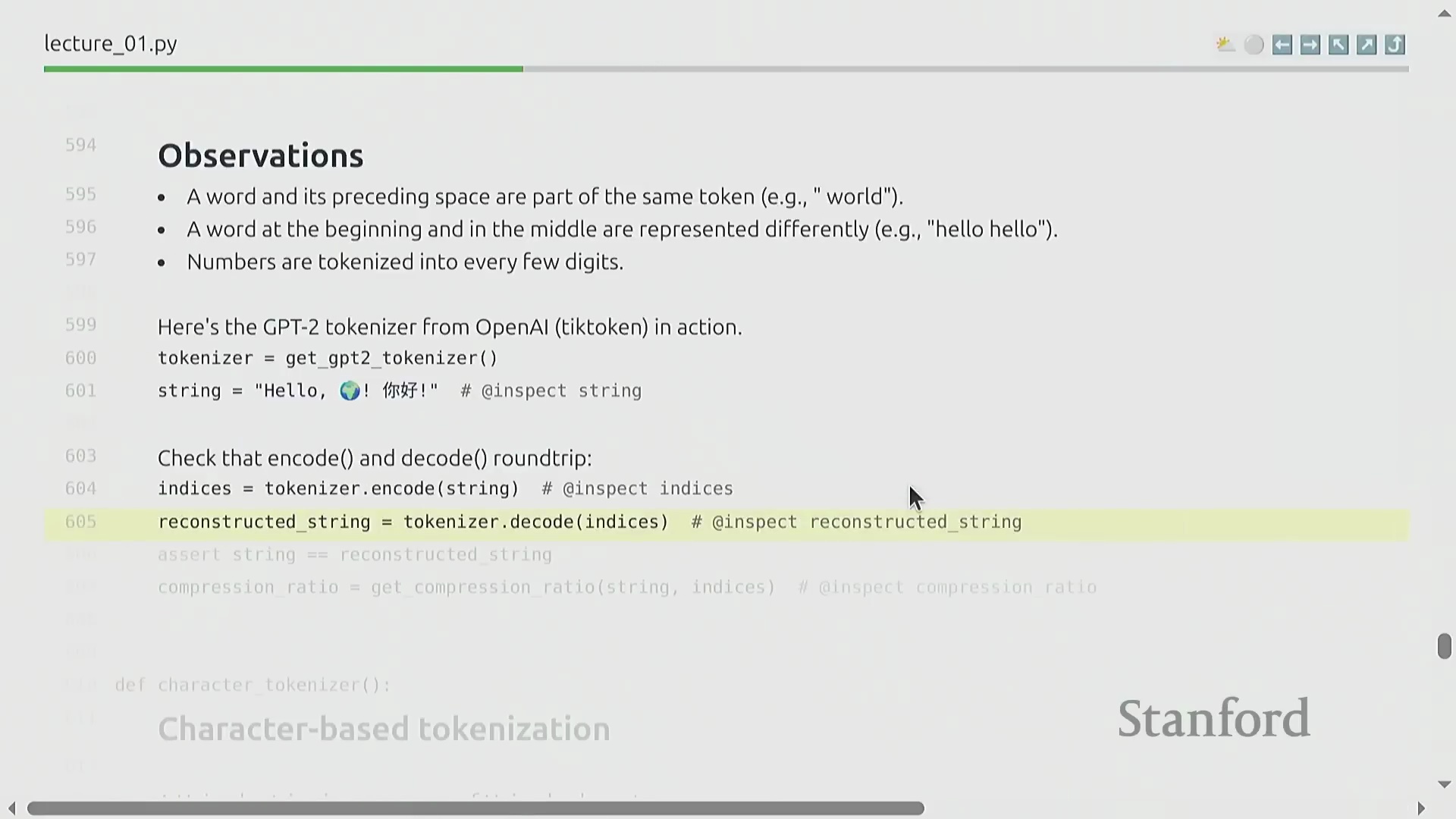
GPT-2 分词器与压缩指标
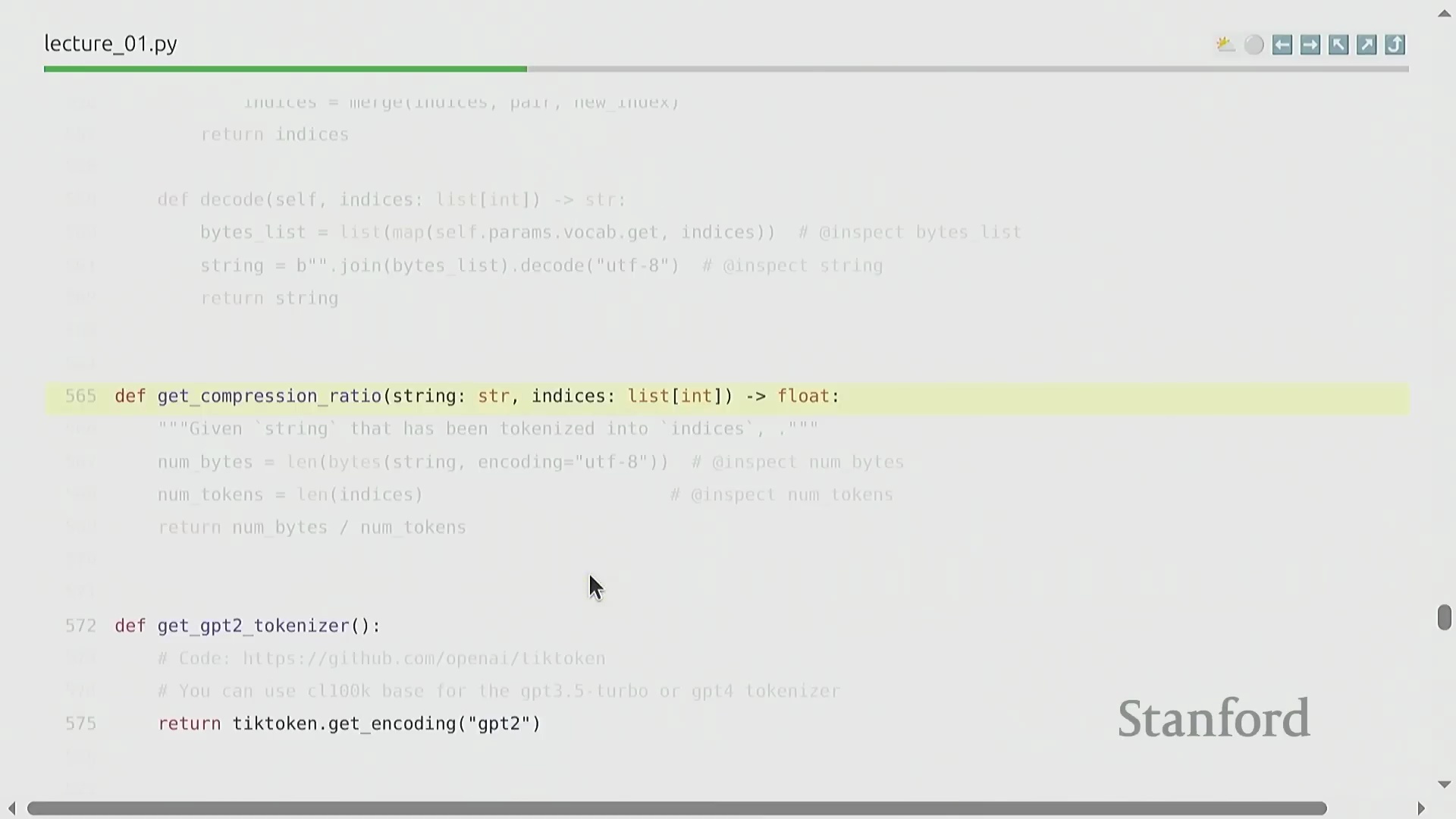
GPT-2 分词器(GPT-2 Tokenizer)是本课程的主要参考实现(Reference Implementation)。文本经由该工具处理后,将被精确映射为整数索引,并支持无损解码还原为原始字符串。评估词元化工具效率的一个核心指标是压缩率(Compression Ratio),其定义为平均每个词元所能表示的原始字节数。对于 GPT-2 模型而言,该比率约为 1.6 字节/词元(Bytes per Token),表明其能够高效地对文本数据进行压缩。这种在词表规模(Vocabulary Size)与序列长度(Sequence Length)之间取得的平衡,对于在 Transformer 架构中优化计算资源分配至关重要。



基于字符的词元化评估
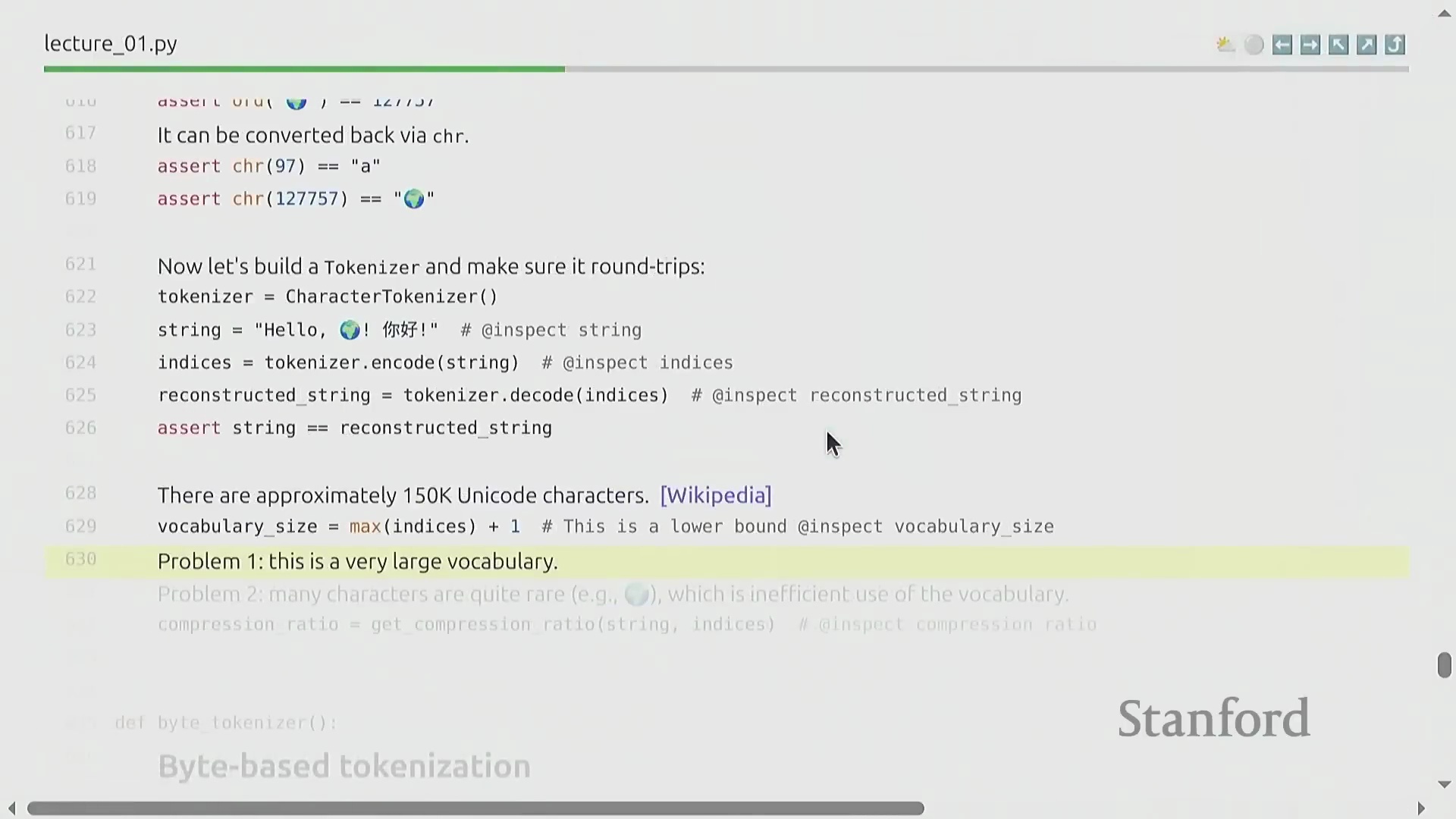
最朴素的词元化方案是将每个 Unicode 字符直接映射为其对应的数值码位(Numeric Code Points)(例如,'a' → 97)。尽管其数学映射原理简单,但该策略在大规模建模中效率极低。由于 Unicode 标准涵盖超过 14 万个独立码位,这将导致嵌入词表(Embedding Vocabulary)异常庞大。在此方案下,极其生僻的字符会占用与高频常用字符完全相同的模型维度资源(Model Dimensionality)。此外,该方案的压缩率仅徘徊在 1.5 字节/词元左右,无法有效缩短输入序列长度。这种均等化的资源分配策略严重浪费了计算预算(Compute Budget),已被业界证实不适用于现代语言模型架构。
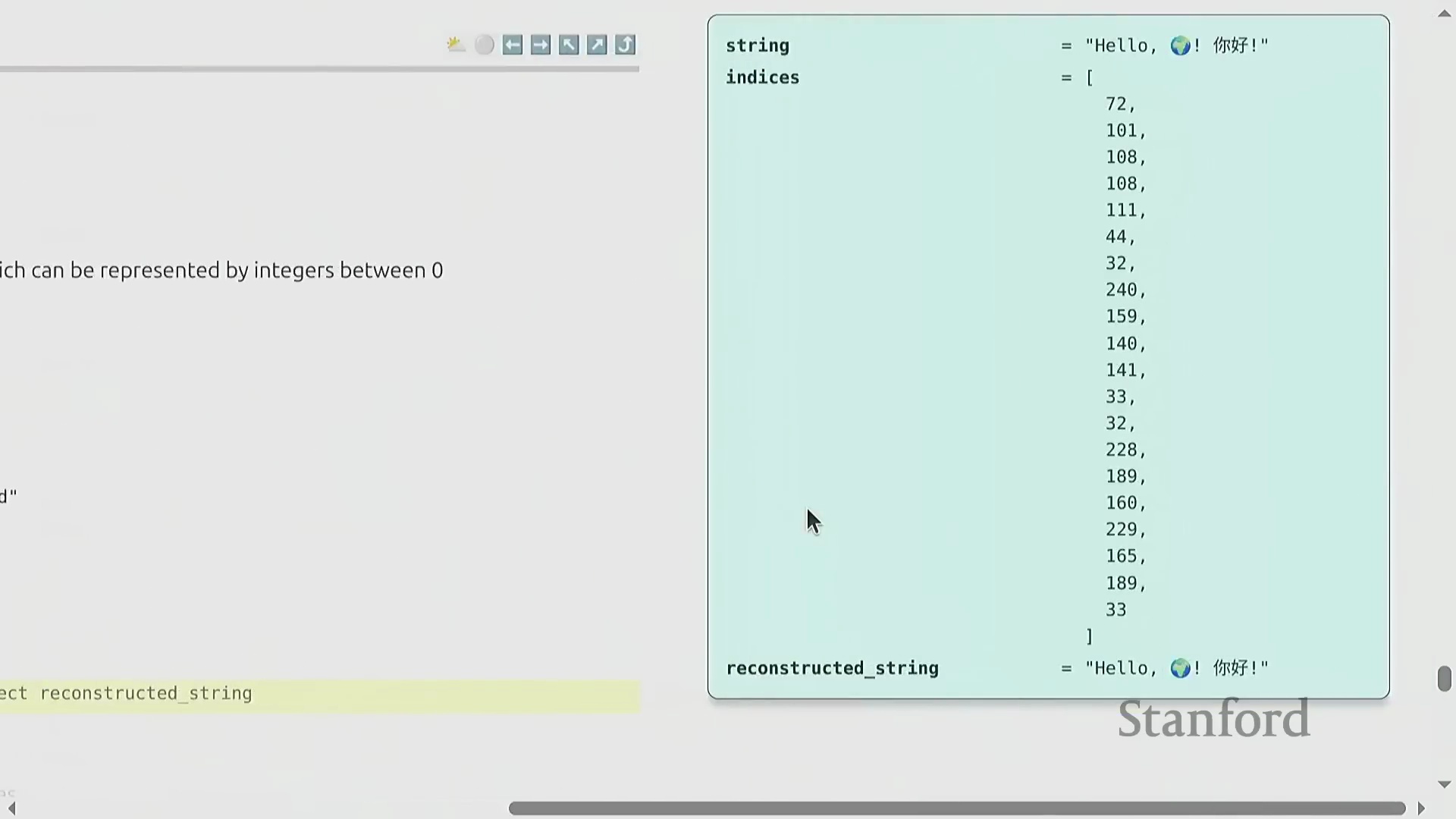
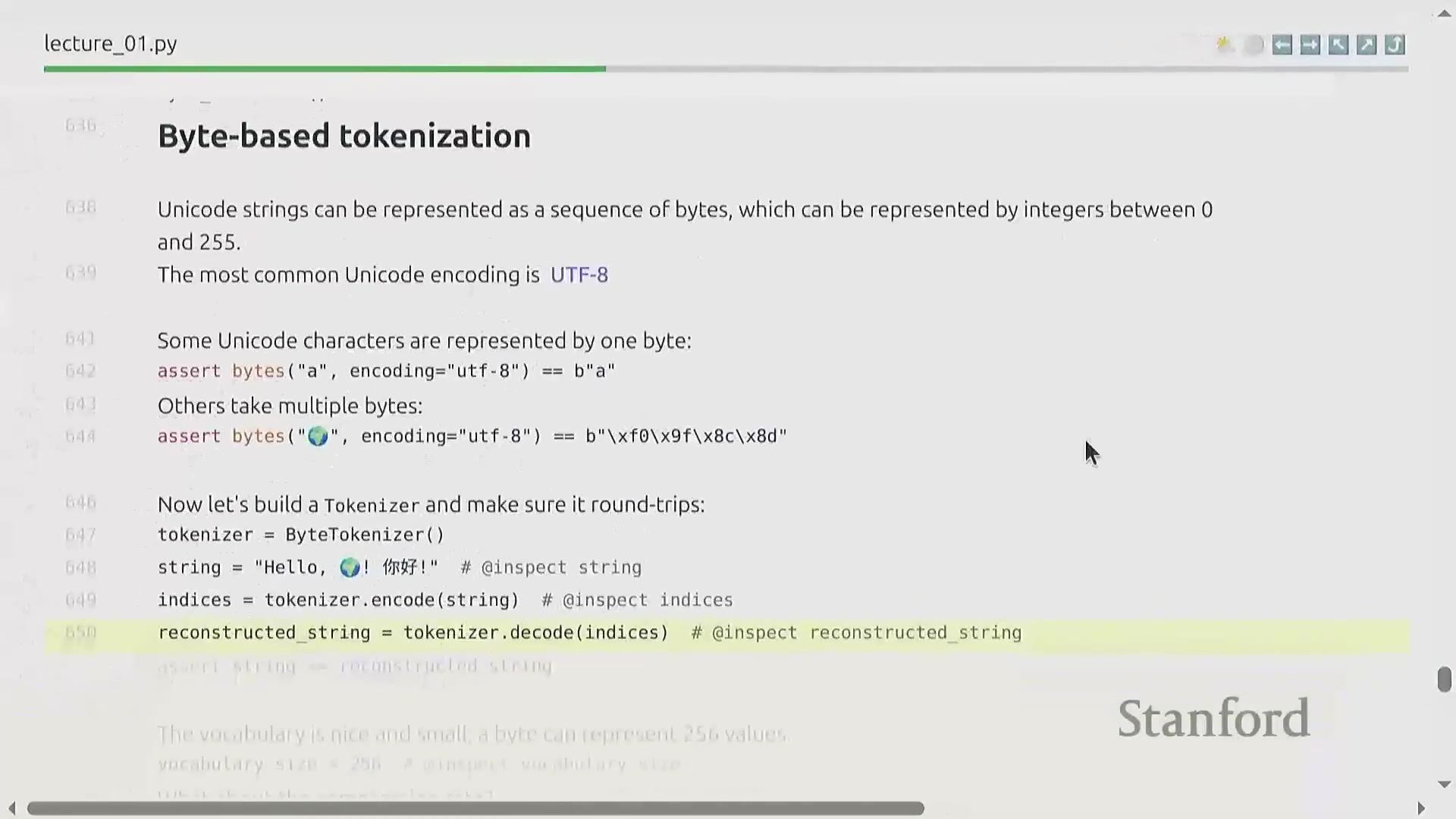
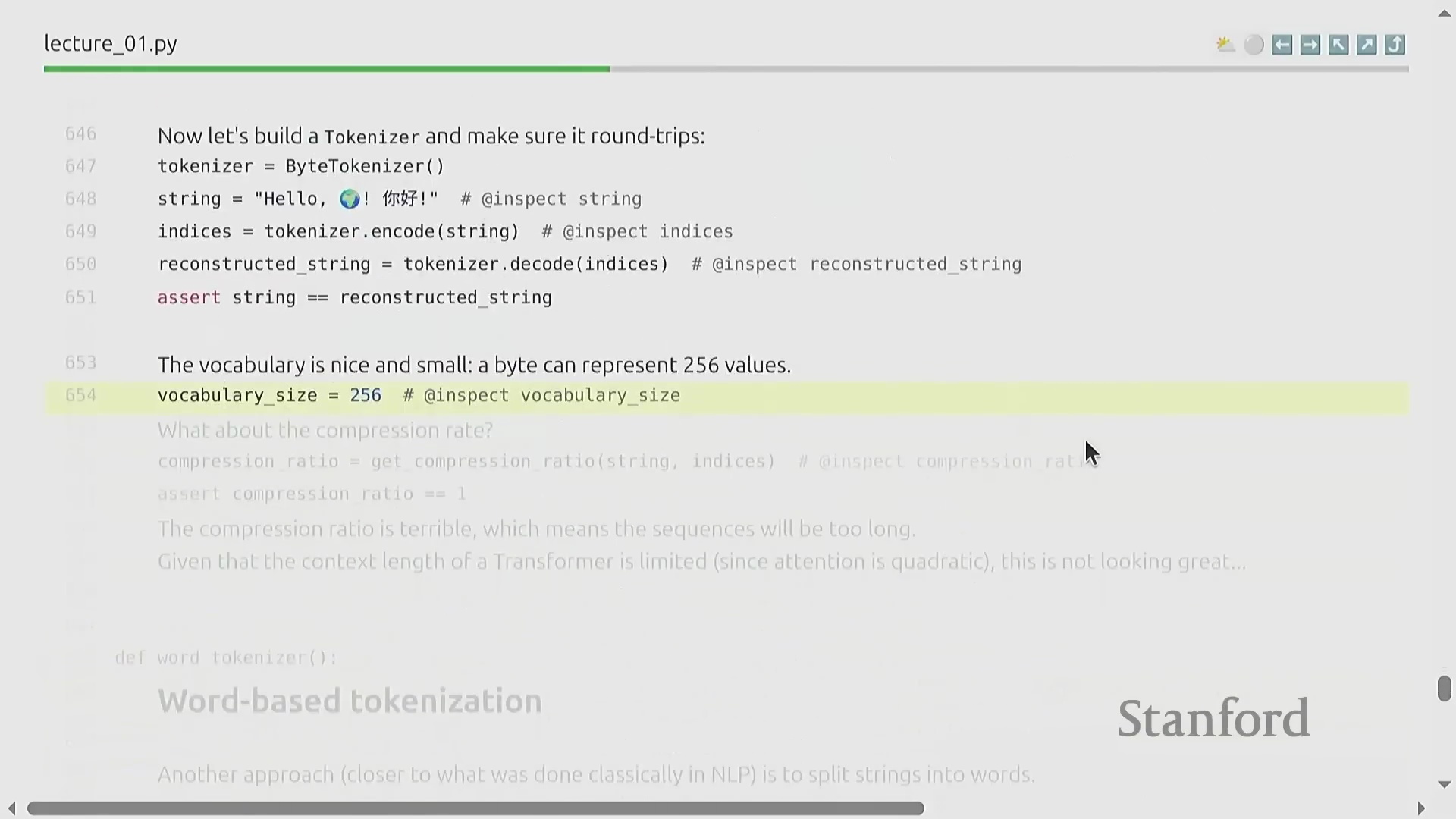
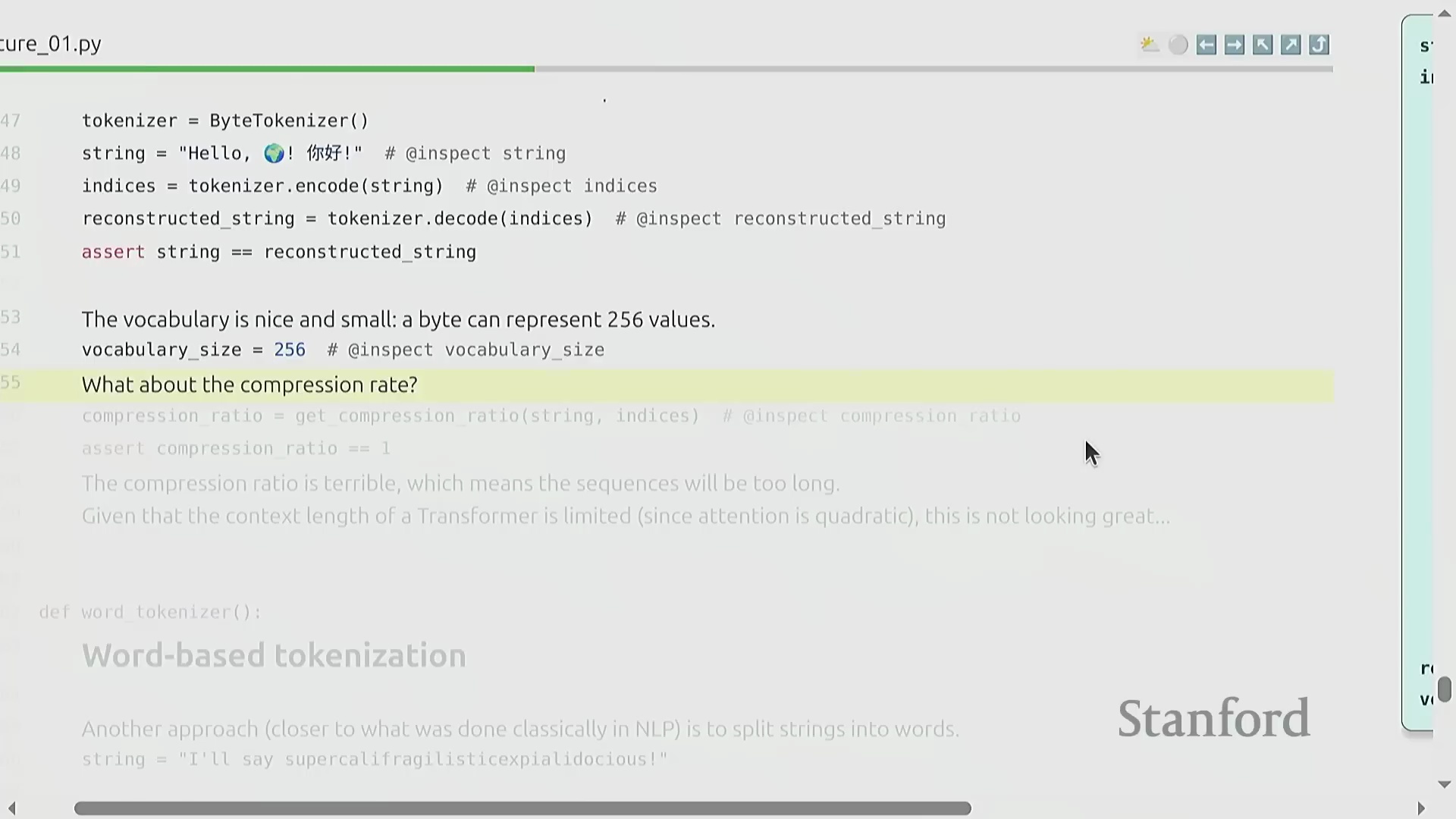
基于字节的词元化替代方案
另一种替代方案是直接将原始字符串转换为 UTF-8 字节序列(UTF-8 Byte Sequences),从而将词表规模严格限制在 256 个可能值内。该方案虽优雅地规避了词表爆炸(Vocabulary Explosion)问题,却引入了严重的计算瓶颈:压缩率骤降至 1.0 字节/词元。由于每个独立字节均被视作一个单独的词元,输入序列的长度将呈倍数膨胀。鉴于自注意力机制(Self-Attention Mechanism)的计算复杂度随序列长度呈平方级增长(Quadratic Growth),该方法将引发难以承受的显存开销(Memory Overhead),并大幅拖慢模型的训练与推理(Inference)速度。因此,尽管该策略在理论设计上颇具美感,但在实际工程应用中并不可行。
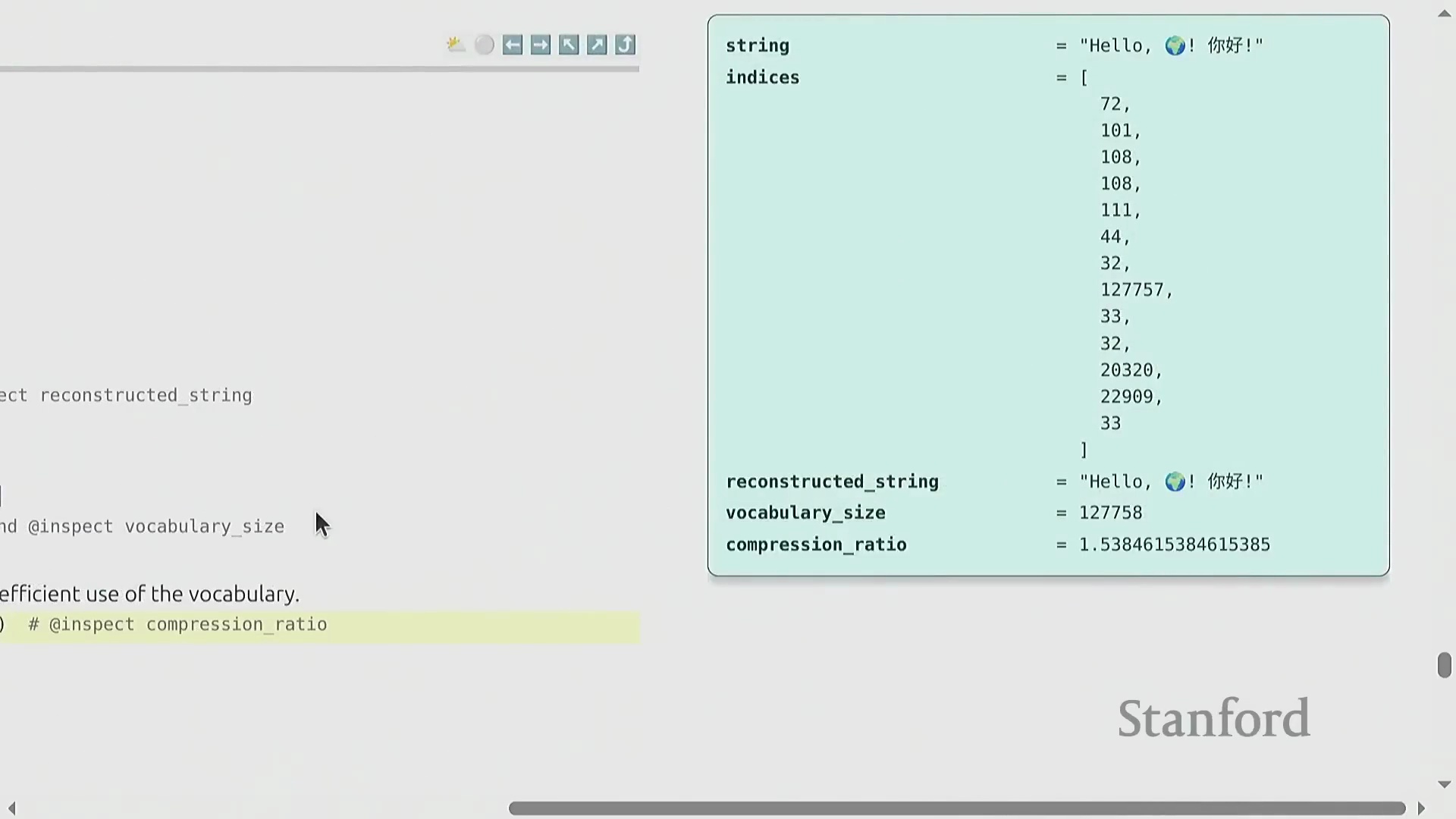


自适应与基于词的分词
为突破固定长度映射的局限,现代大语言模型广泛采用了诸如子词分词(Subword Tokenization)与基于词的分词(Word-based Tokenization)等自适应策略(Adaptive Strategies)。与逐字符或逐字节处理不同,原始文本首先会通过基于正则表达式(Regular Expressions)的预分词器被切分为具有语言学意义的片段(该切分逻辑与 GPT-2 的标准规则高度一致)。这些与完整单词或高频子词(Subwords)高度契合的片段,随后被映射为紧凑的整数标识符(Integer IDs)。这种自适应的词元分配机制确保了高频语言模式能够以更少的词元数量进行表示,同时保持对罕见字符的完整兼容性。该设计在最大化词表利用率(Vocabulary Utilization)的同时,显著提升了整体训练流水线(Training Pipeline)的计算效率。
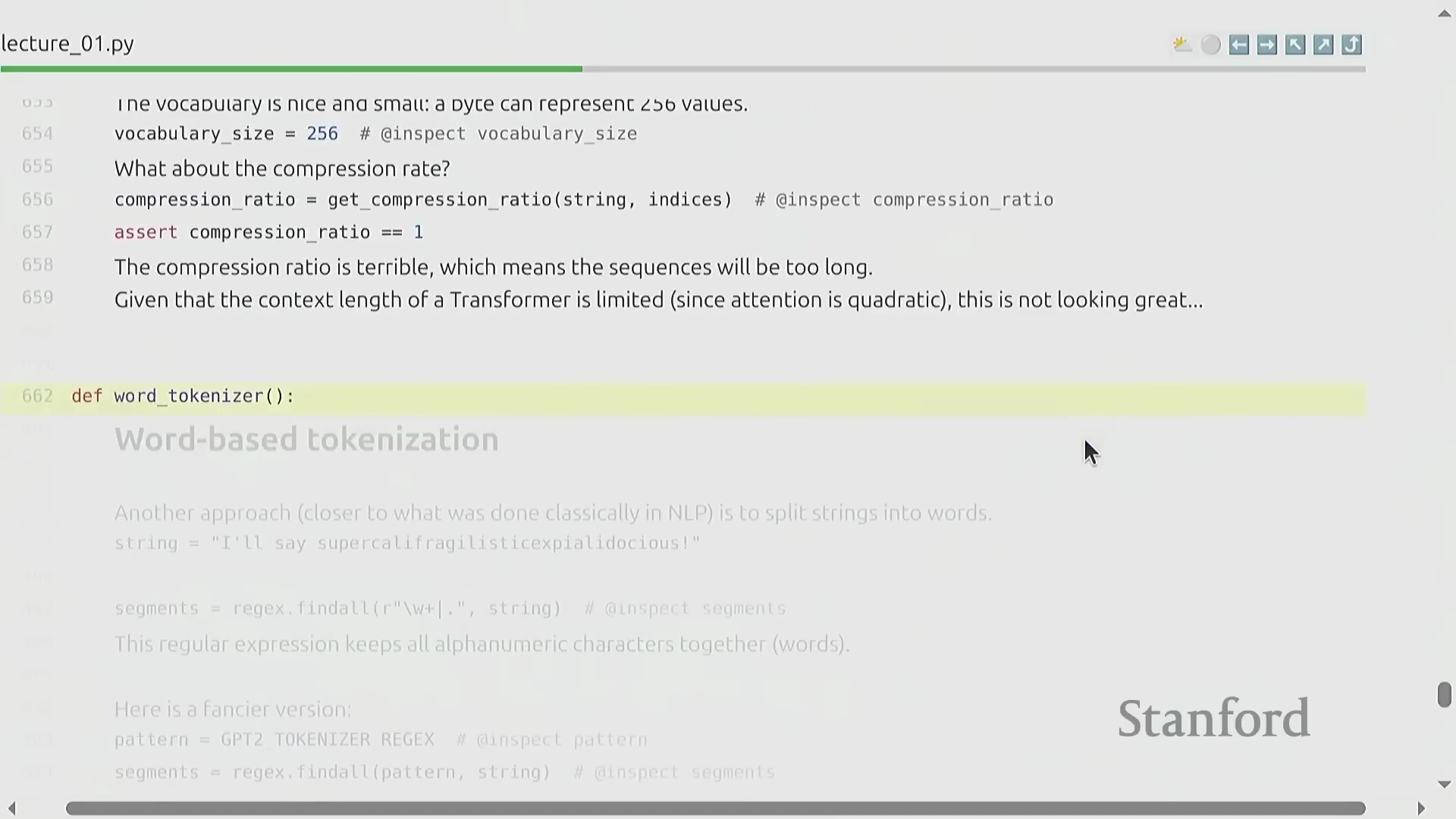
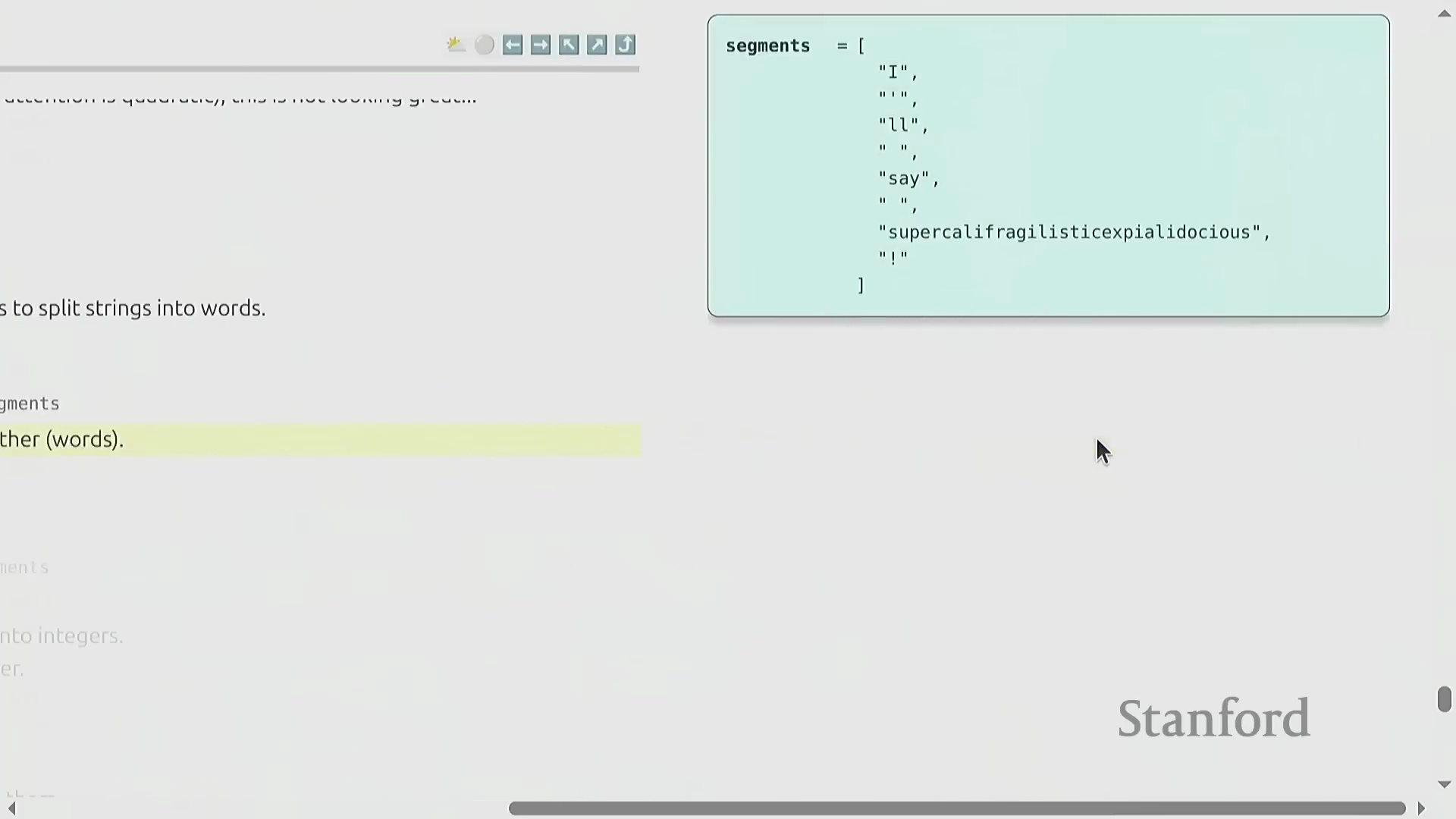


基于词的分词的局限性
尽管基于词的分词(Word-based Tokenization)直观地体现了自适应文本切分(Adaptive Text Splitting)的理念,但它为现代人工智能(Artificial Intelligence, AI)系统引入了严重的可扩展性(Scalability)问题。其主要缺陷在于词表规模(Vocabulary Size)在理论上是无上限的,因为新词或罕见词汇会持续出现在未见过数据(Unseen Data)中。这迫使模型严重依赖作为后备机制(Fallback Mechanism)的 <unk>(未知词元/Unknown Token),从而损害语言表征能力(Language Representation)、破坏往返解码(Round-Trip Decoding)的连贯性,并显著增加困惑度(Perplexity)计算的复杂度。因此,纯基于词的方法在构建稳健(Robust)的大规模语言模型(Large Language Models, LLMs)时并不具备工程可行性。



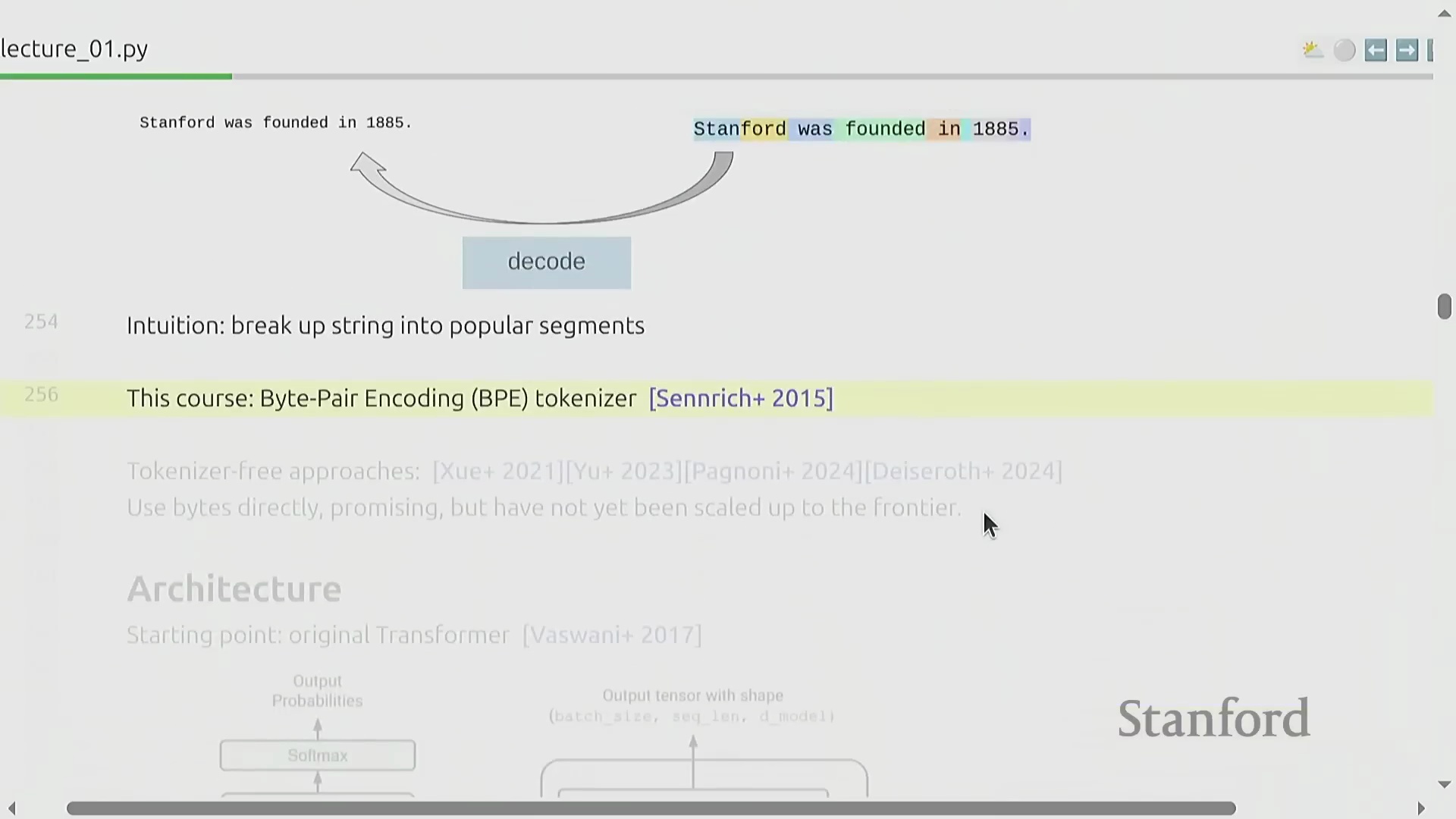
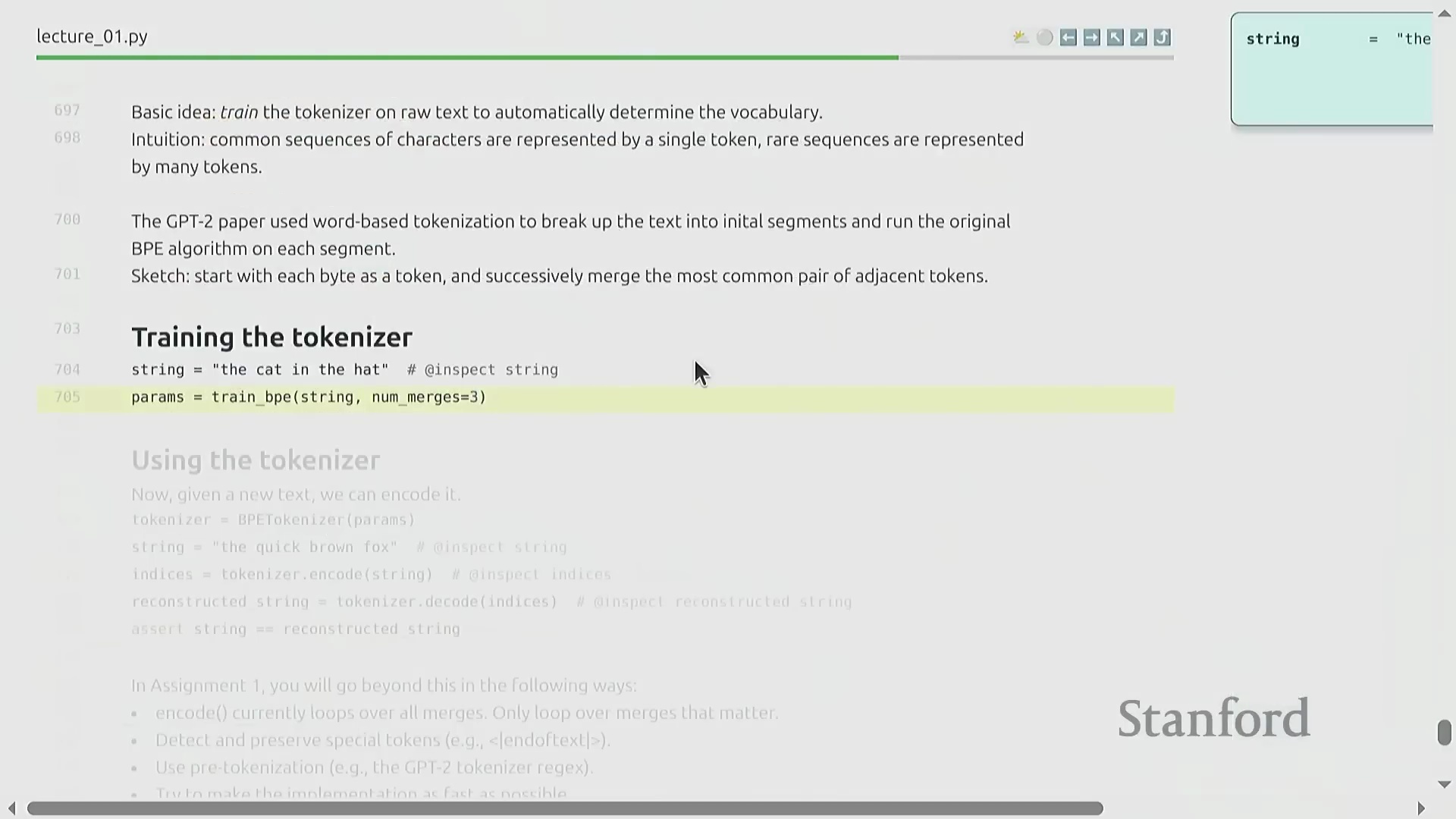
字节对编码(BPE)简介
为克服上述传统方法的局限性,本课程正式引入字节对编码(Byte Pair Encoding, BPE)。BPE 最初由 Philip Gage 于 1994 年作为一种数据压缩算法(Data Compression Algorithm)提出,随后被引入神经机器翻译(Neural Machine Translation, NMT)领域,并随着 GPT-2 的发布在大型语言模型中得到广泛应用与普及。BPE 不再依赖静态的预定义切分规则(Static Pre-defined Splitting Rules),而是直接基于原始语料库(Raw Corpus)的统计分布特征进行动态训练。它能够智能分配词表空间(Vocabulary Space):高频的多字符序列(Multi-character Sequences)被合并压缩为单个词元,而低频或罕见模式则保持拆分为多个基础词元。由此构建的高效数据驱动型词表(Data-driven Vocabulary),彻底消除了对未知词元后备机制的依赖。
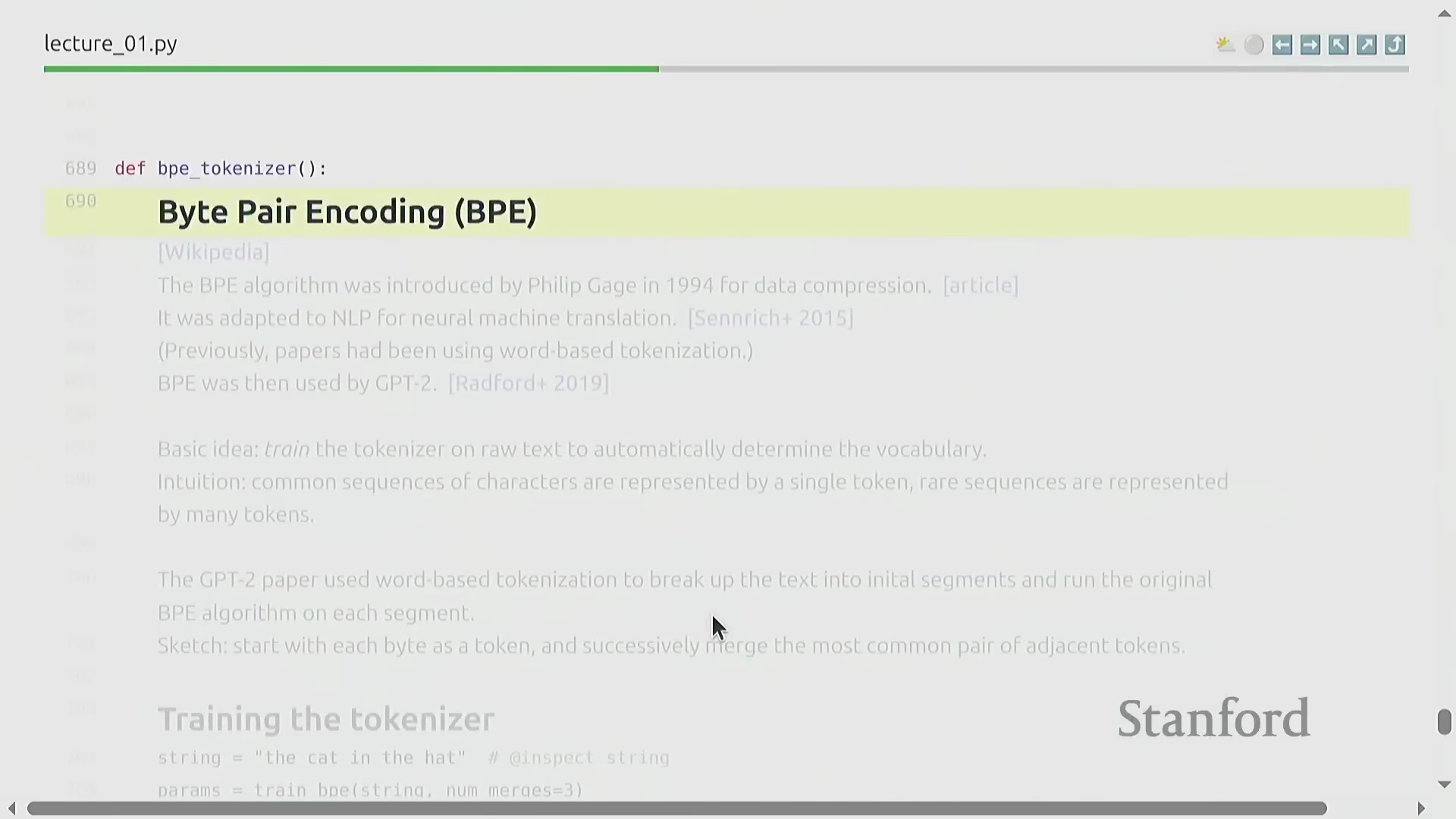


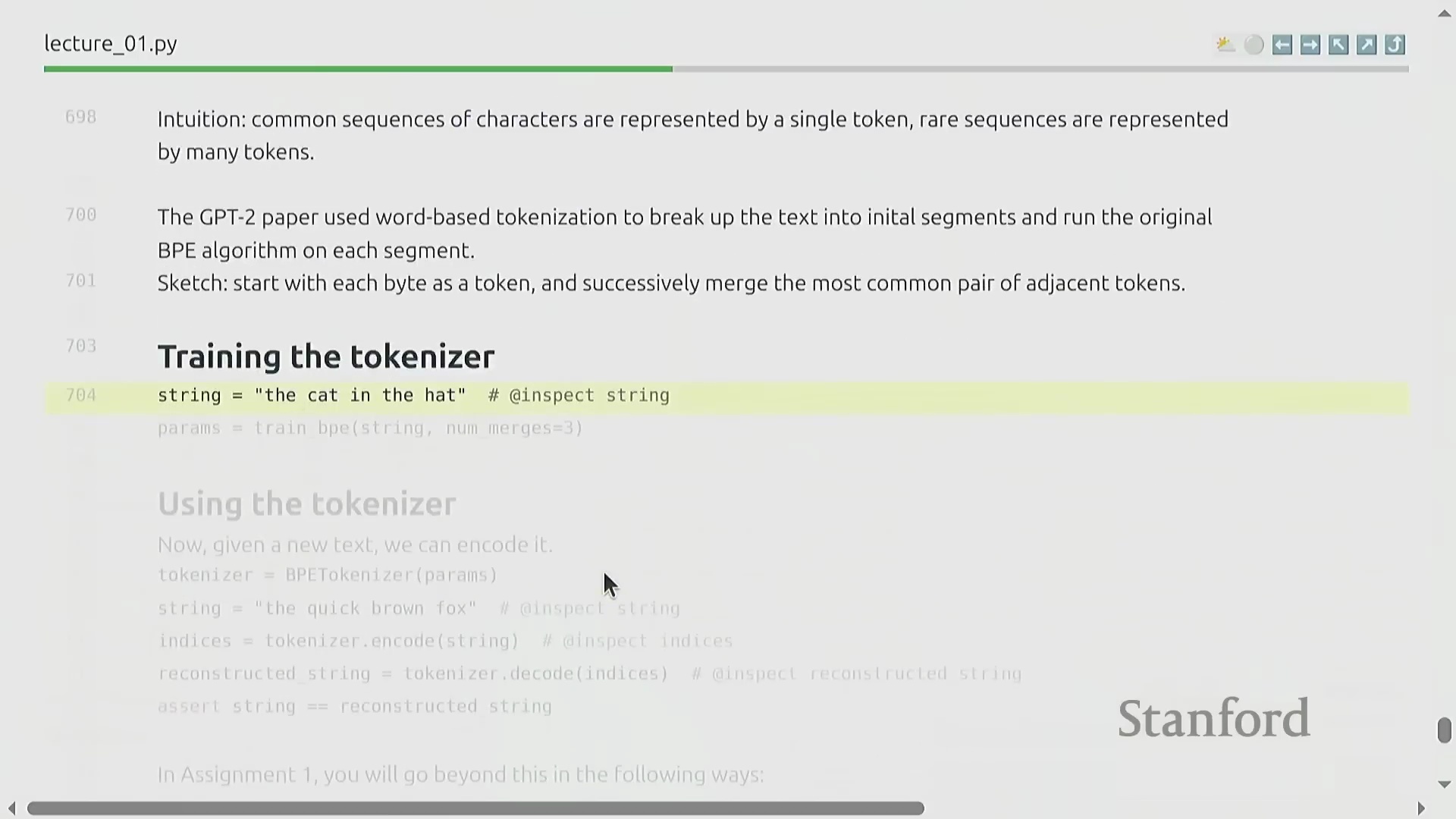
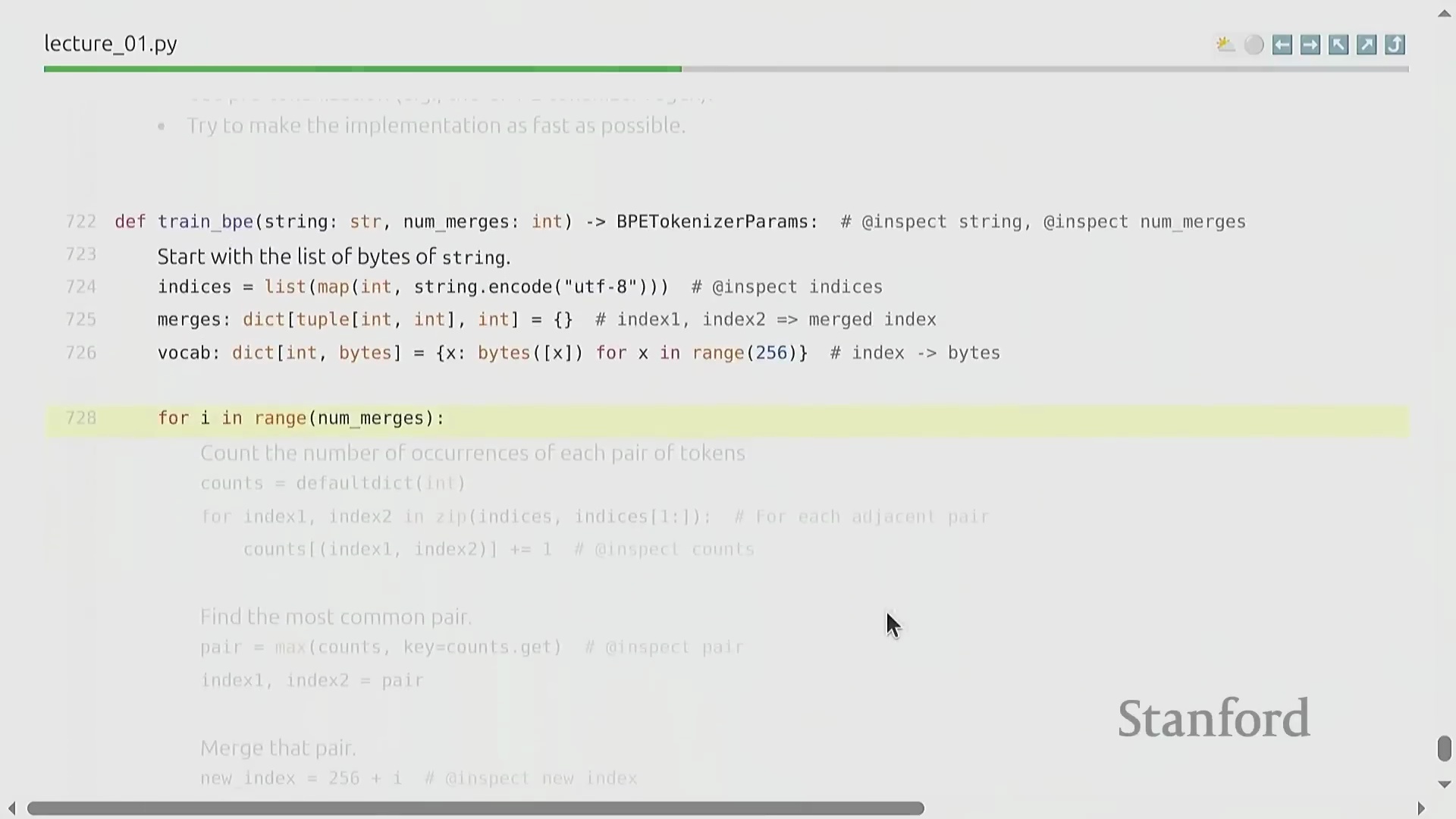
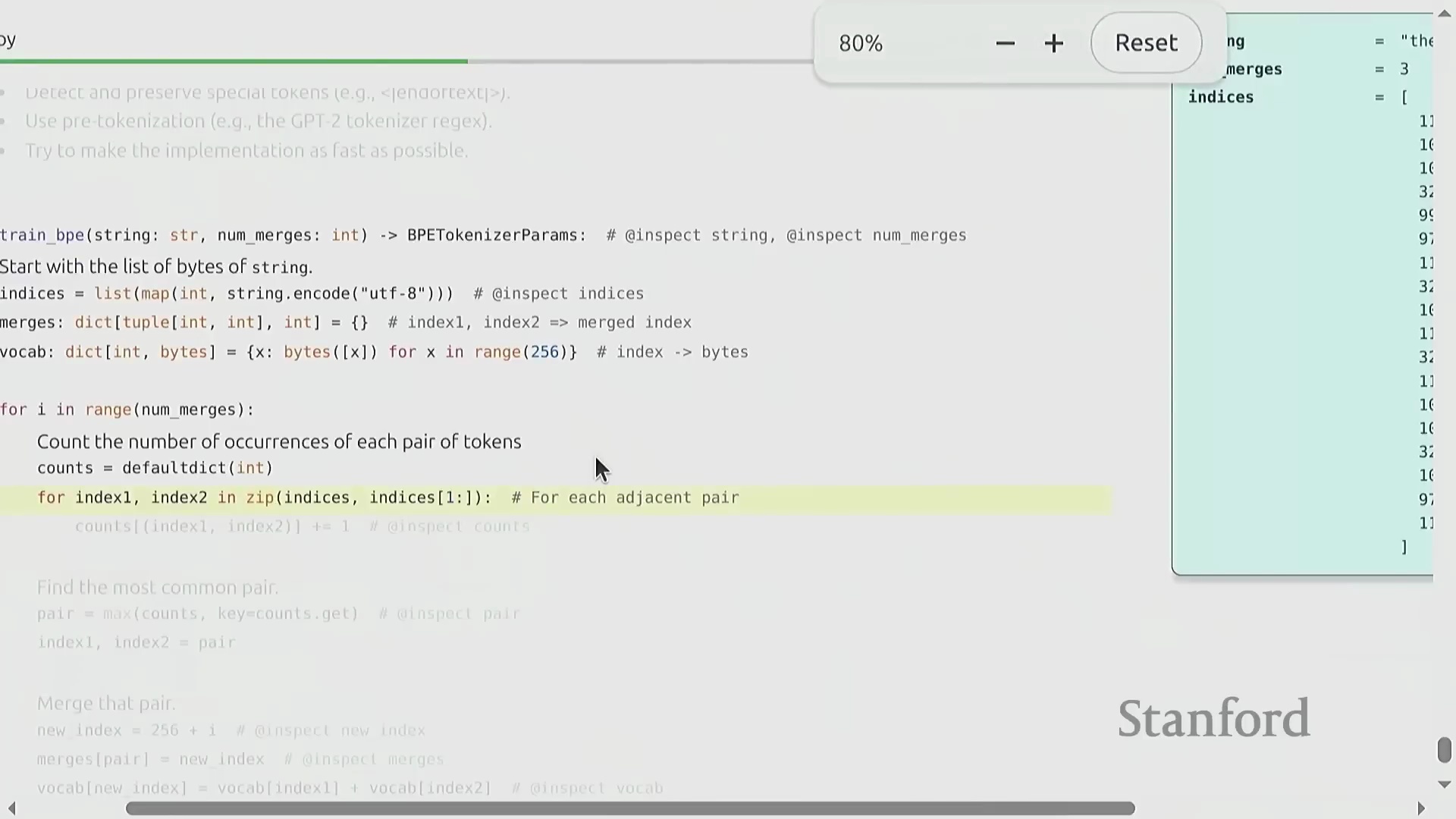
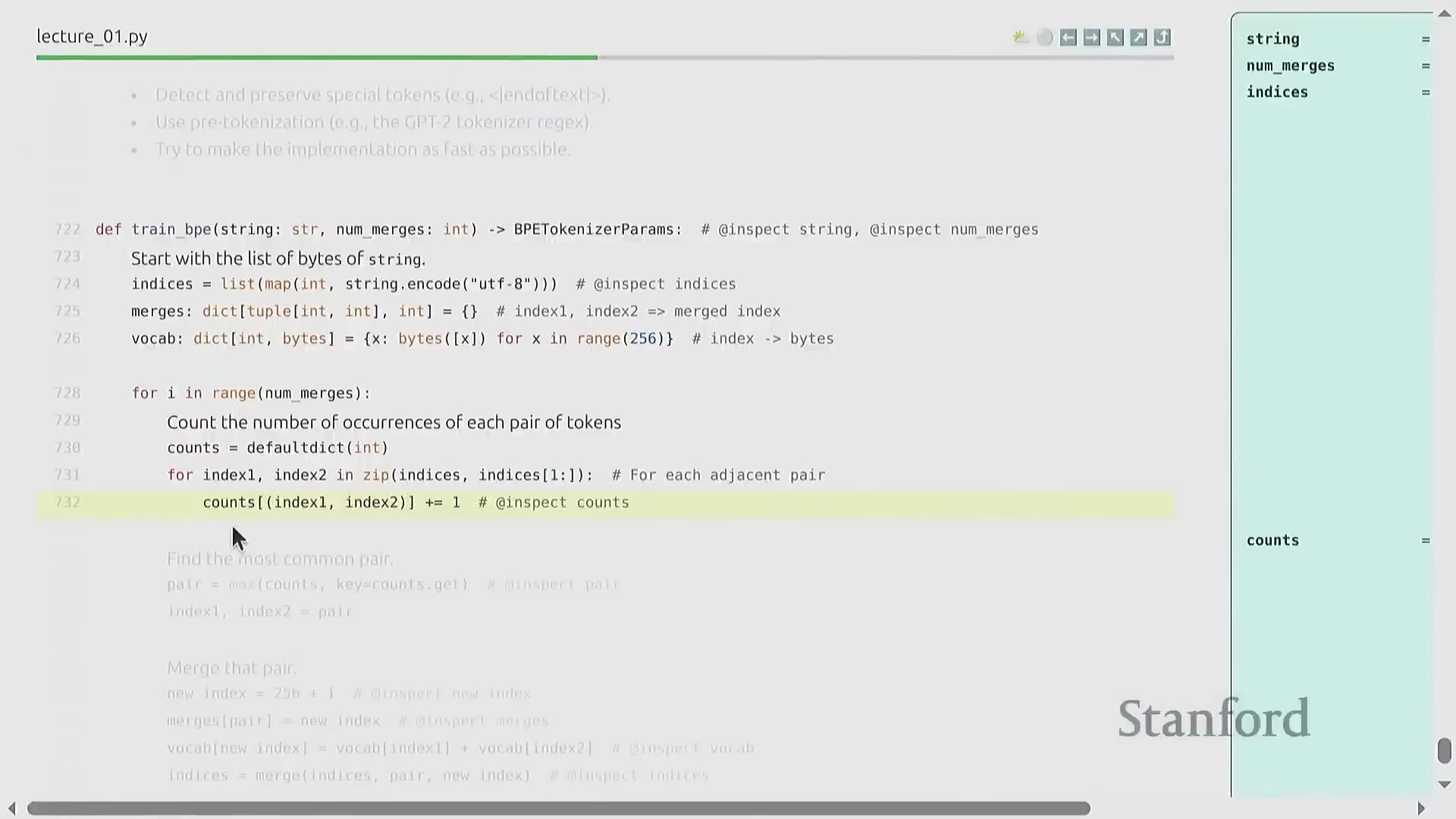
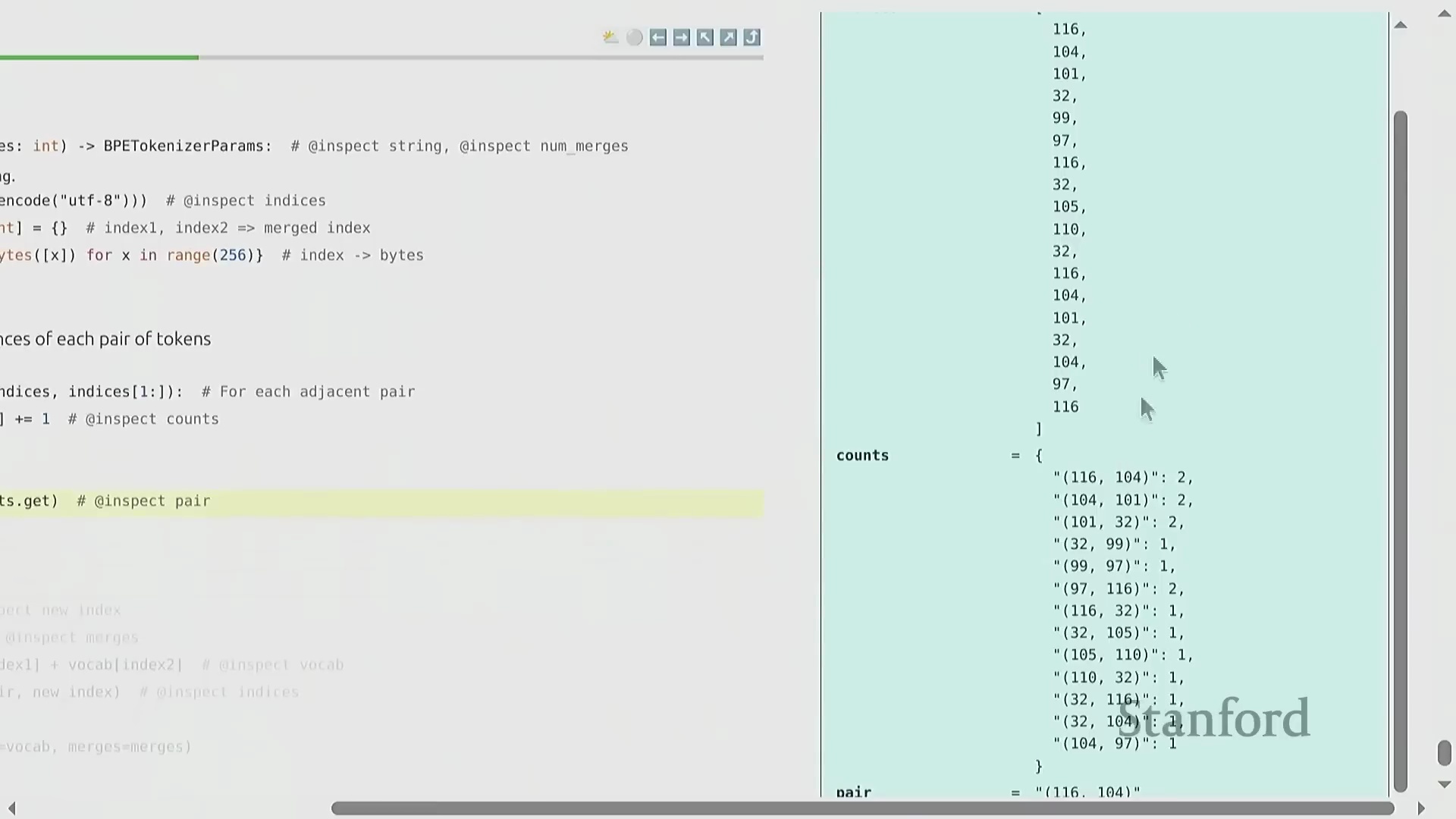
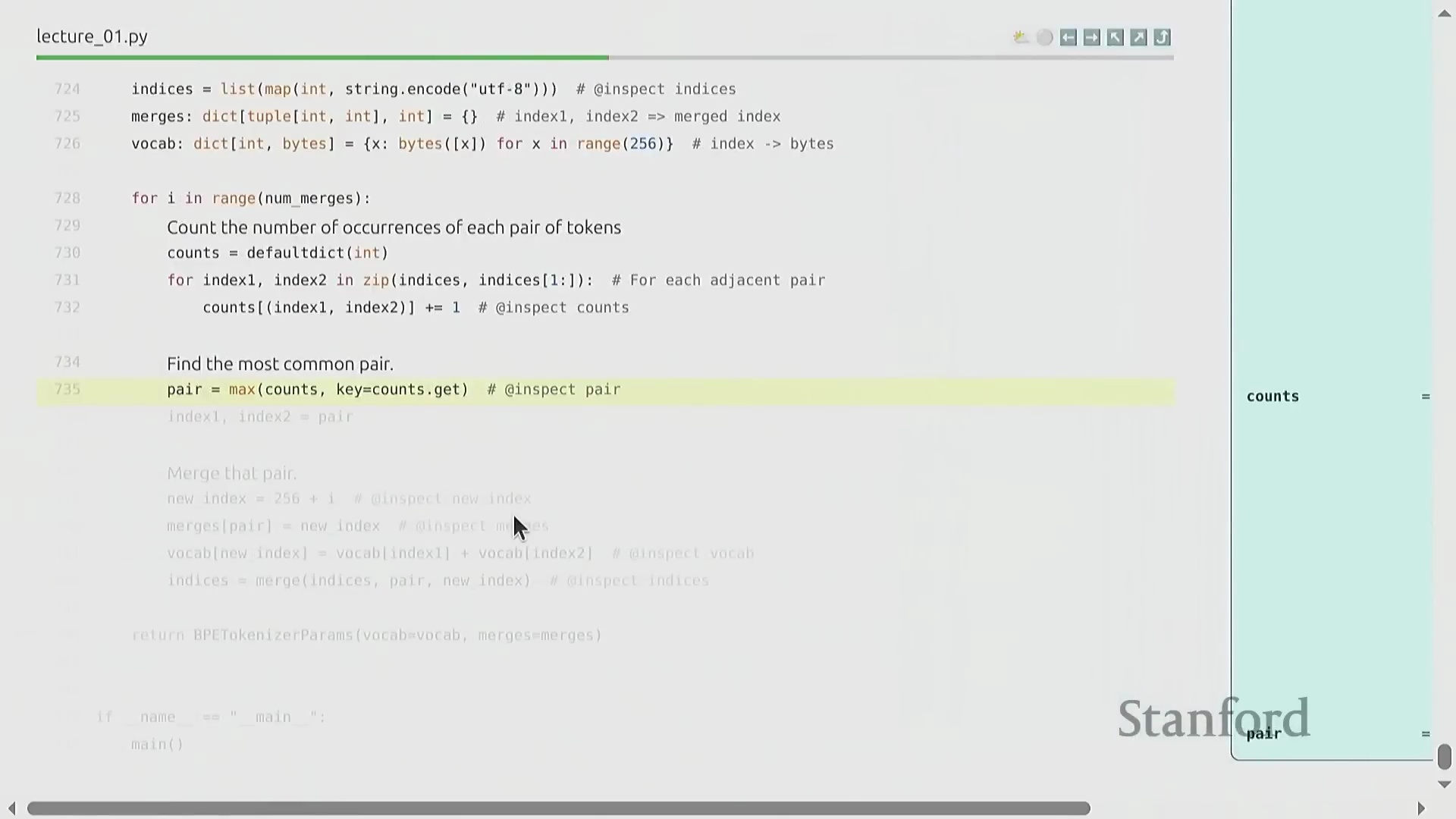
BPE 算法:逐步详解
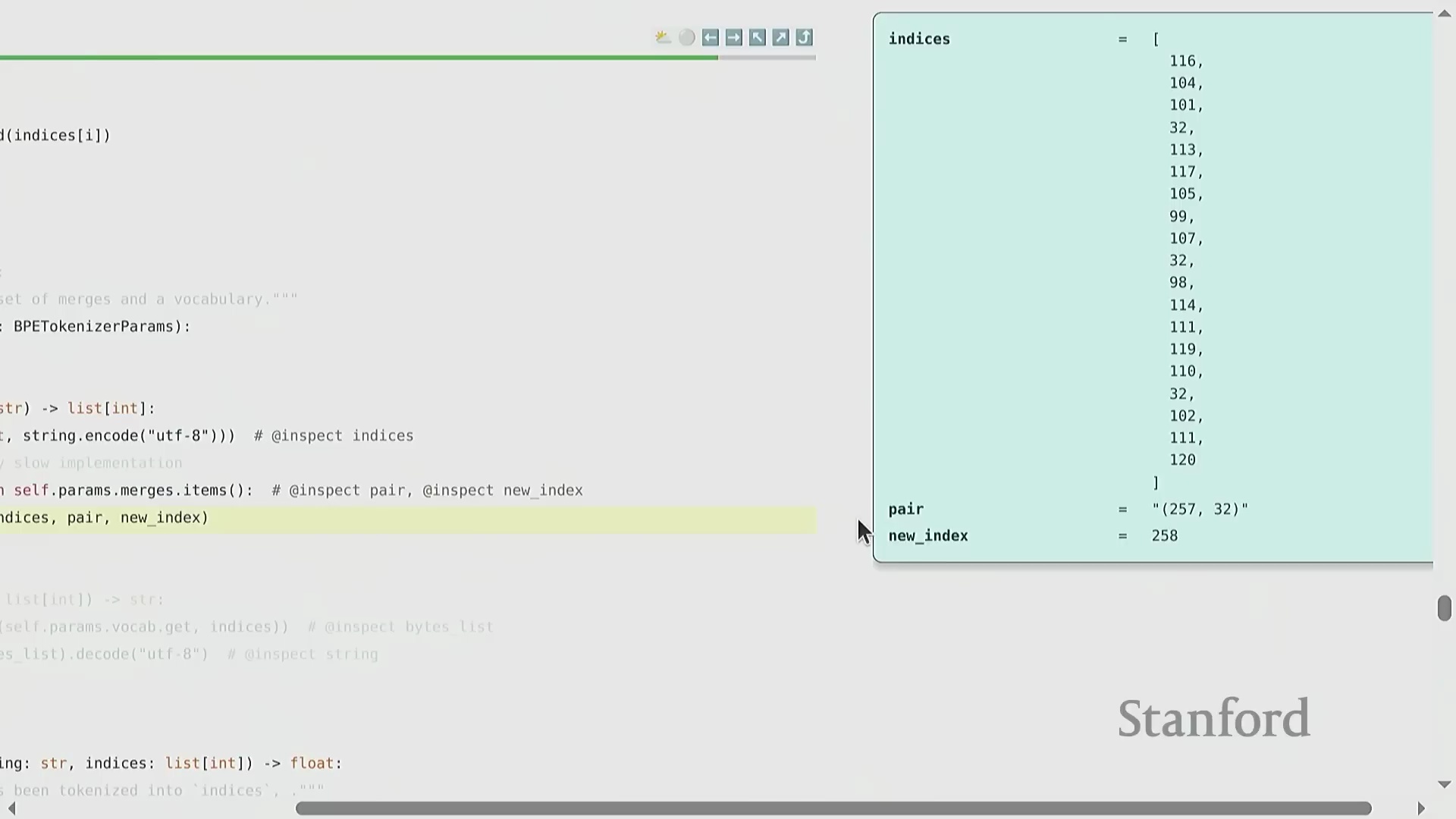
BPE 的训练过程呈现出高度优雅的迭代特性(Iterative Nature)。原始文本首先被转换为字节整数序列(Sequence of Byte Integers)。随后,算法遍历统计语料库中所有相邻词元对(Adjacent Token Pairs)的出现频率(Frequency),定位最高频的配对,并将其合并(Merge)为一个新的词元标识符(Token ID,通常从 256 开始递增分配)。这一合并操作(Merge Operation)系统性地缩短了整体序列长度(Sequence Length),从而有效提升了数据压缩率(Compression Ratio)。通过预设次数的循环迭代(Iterative Loop),算法最终构建出一张完整的合并映射表(Merge Map)。该表在动态压缩常见语言模式的同时,以细粒度(Fine-grained)保留罕见字符,从而确保词表利用率(Vocabulary Utilization)达到最优。
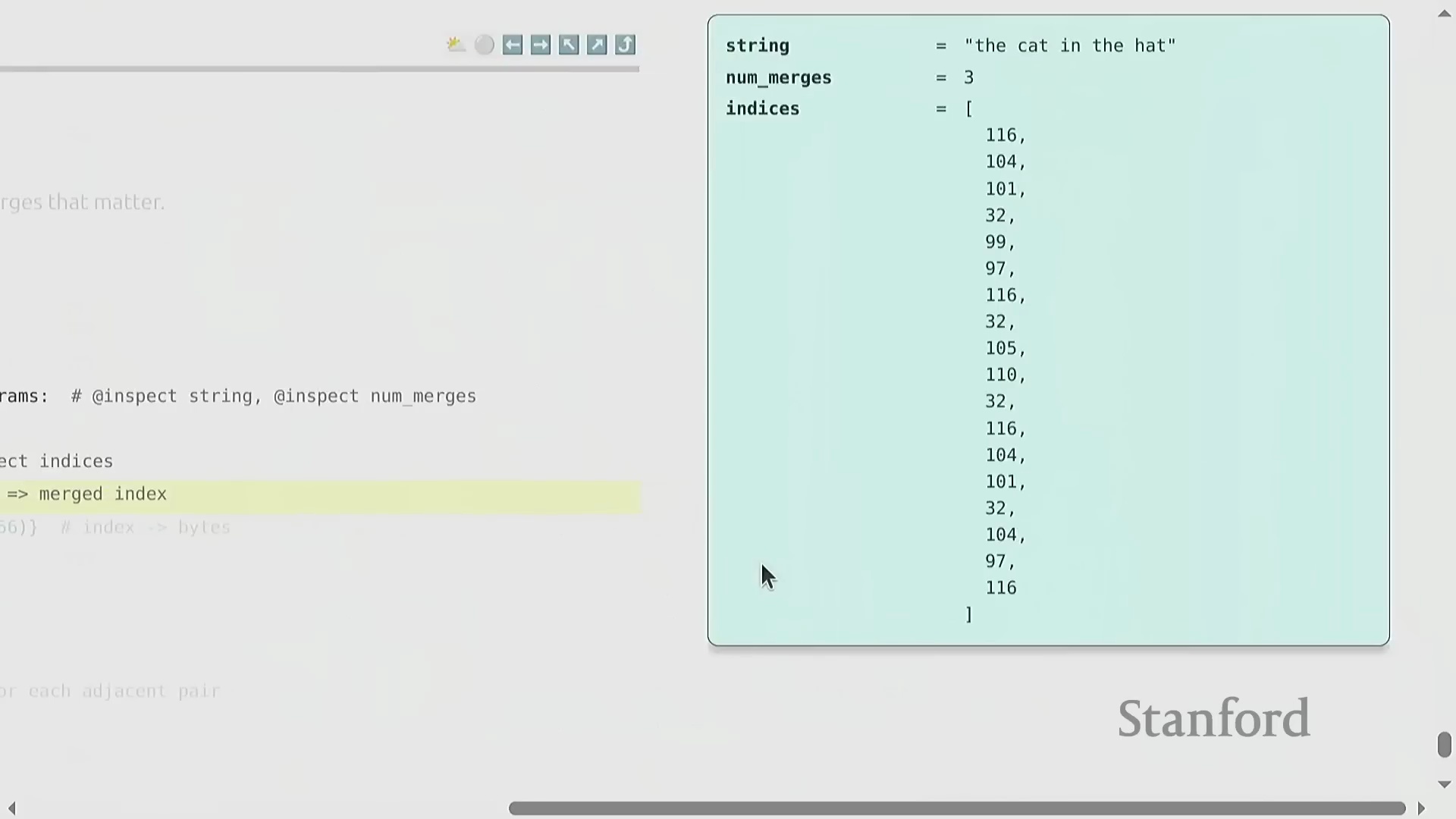
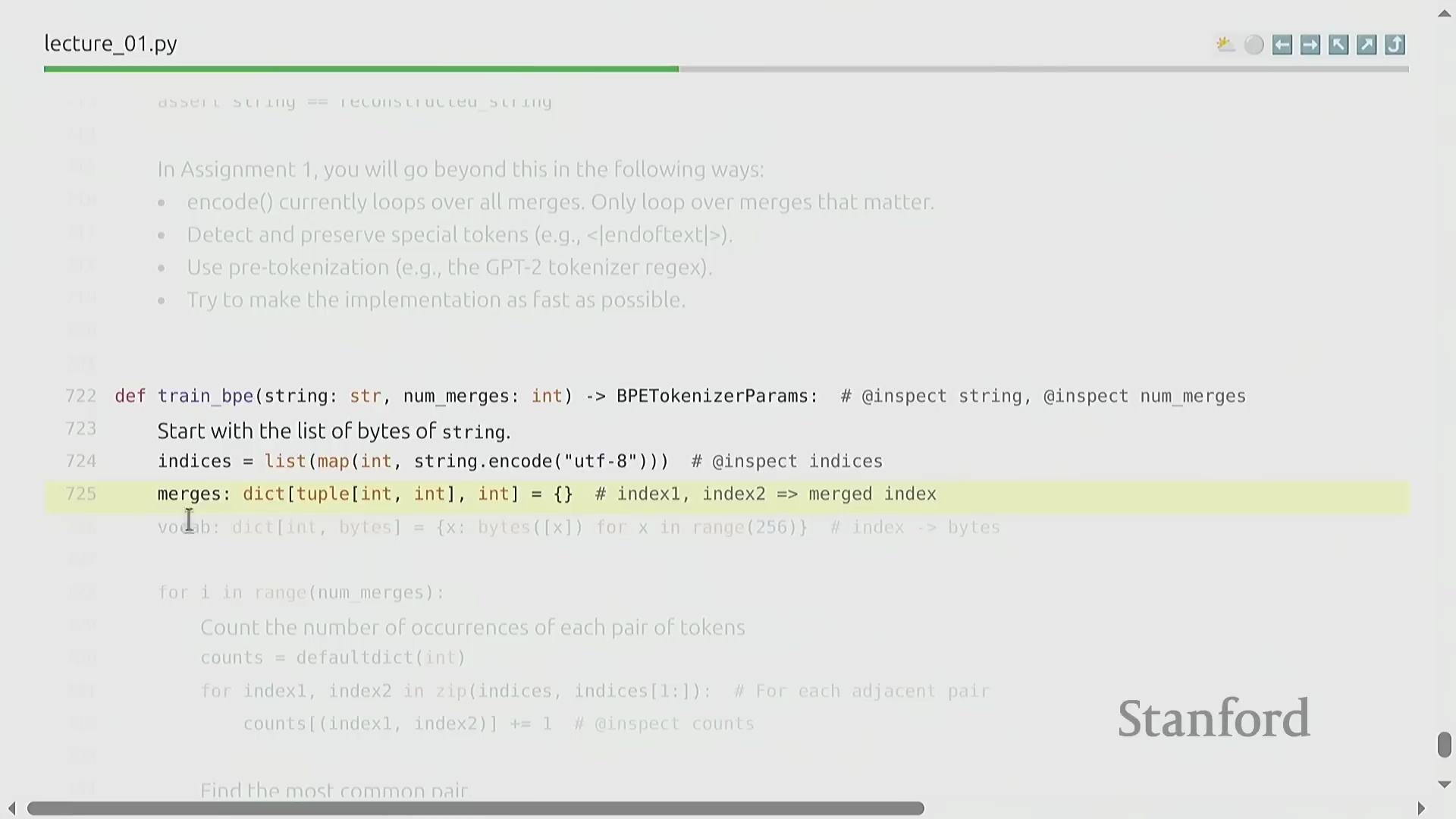
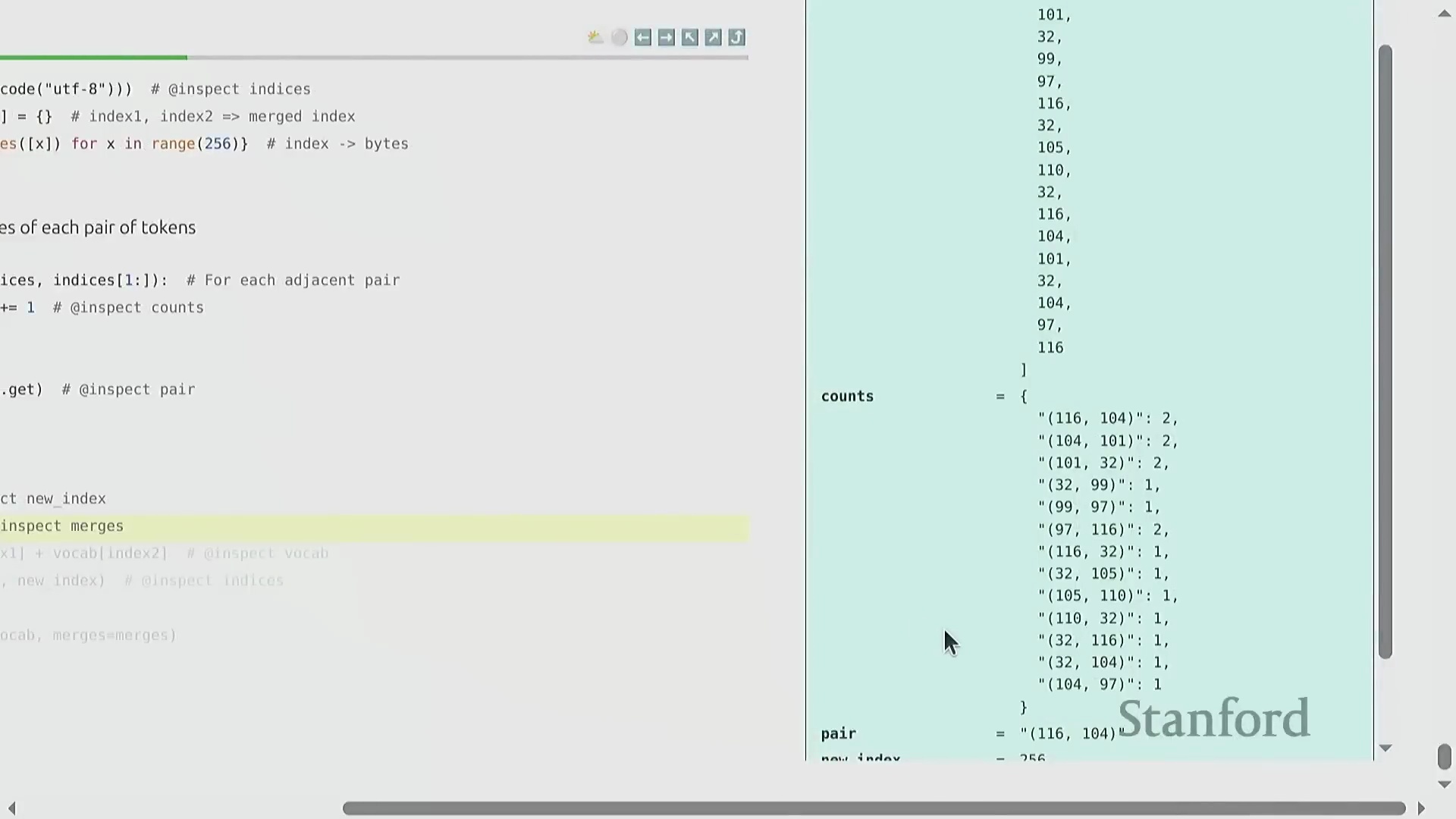
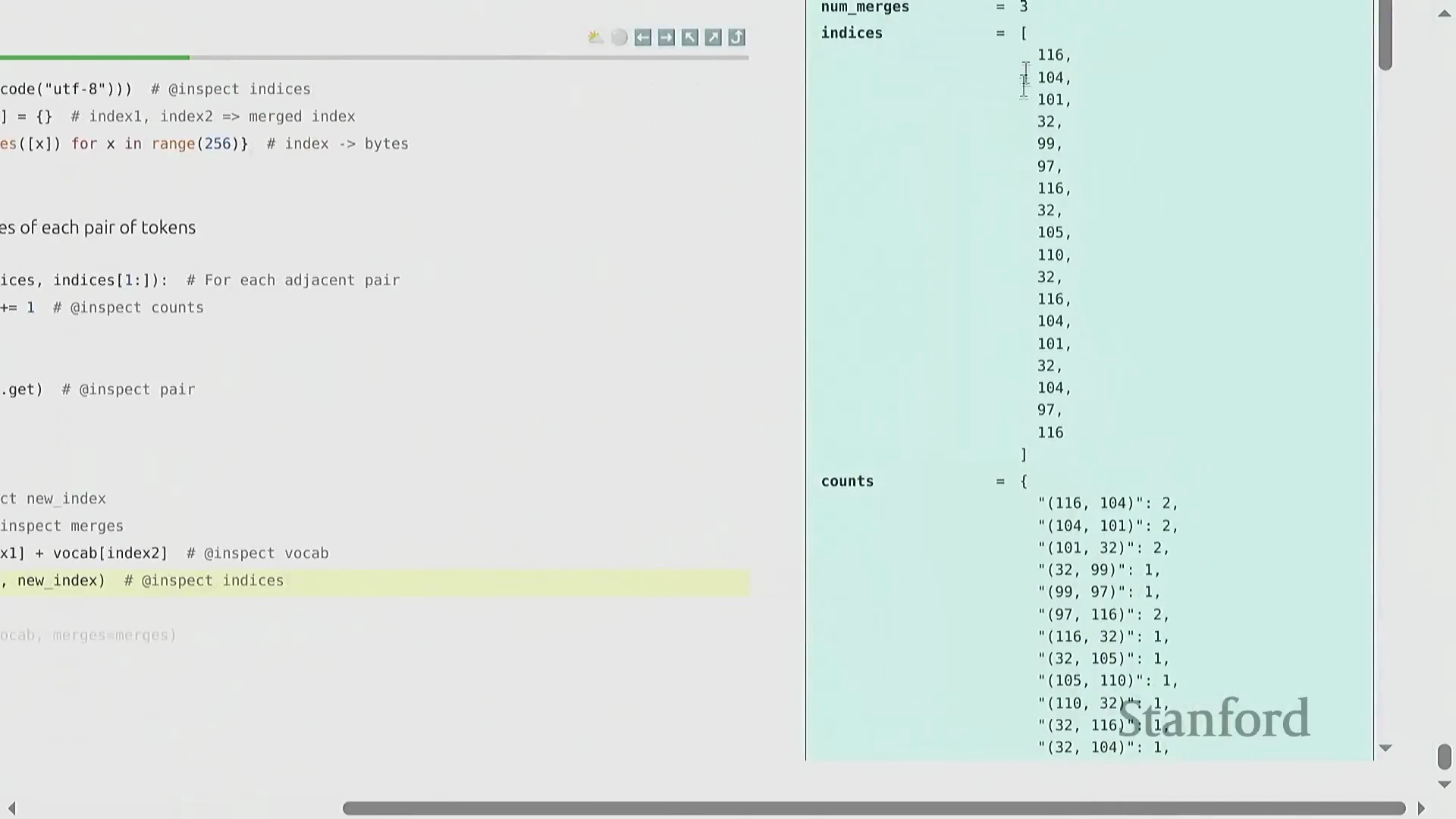
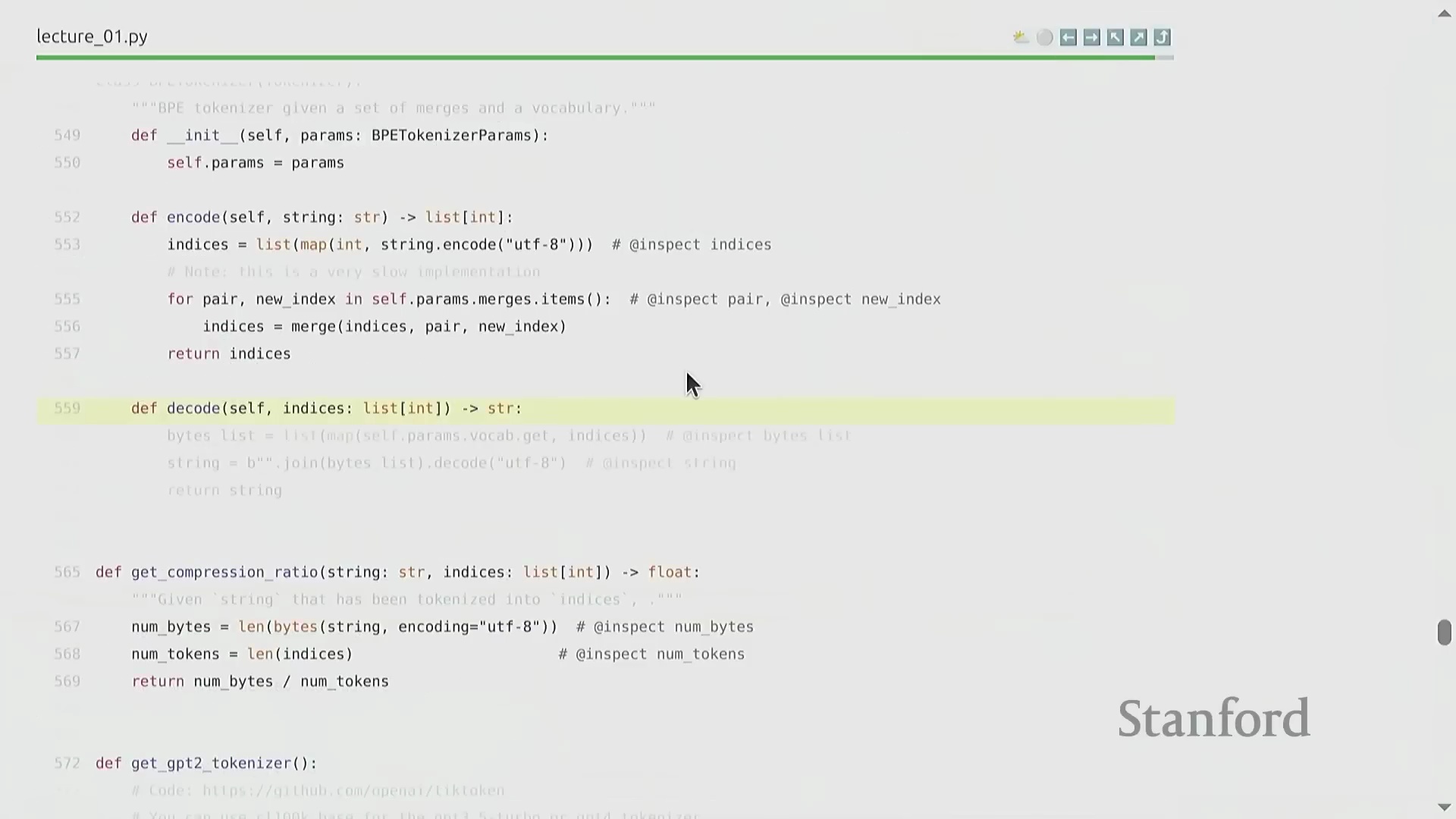
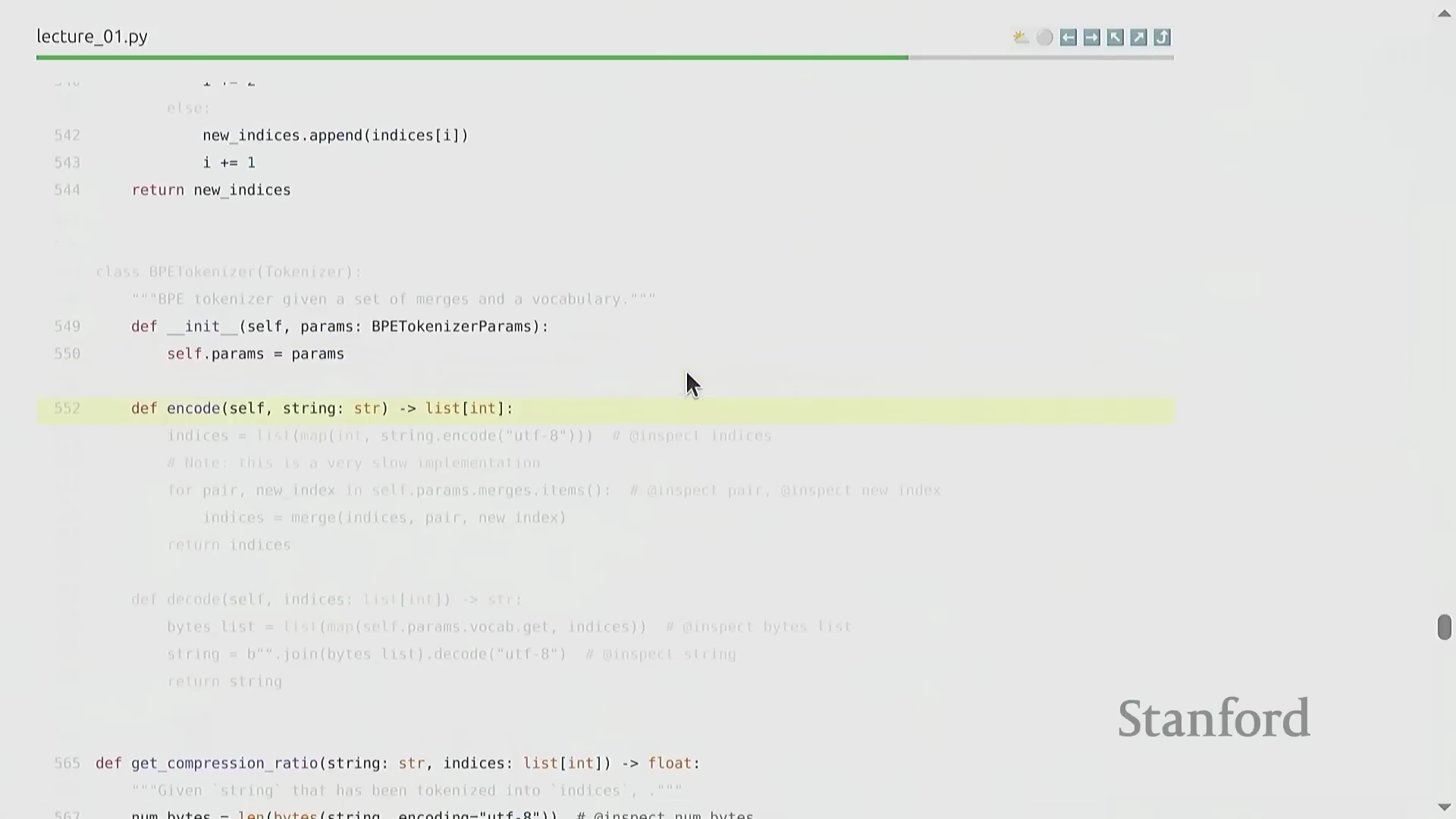
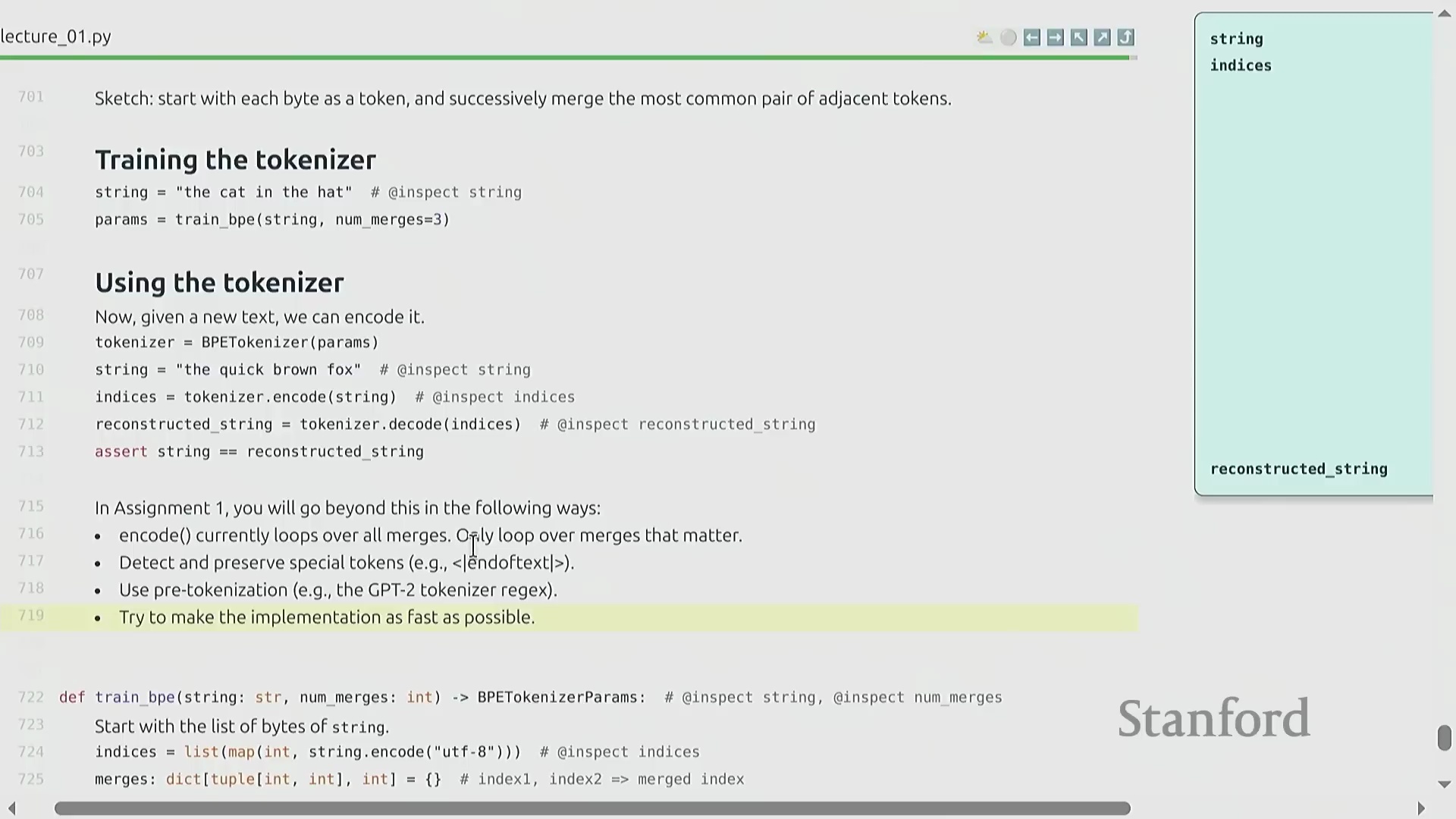
编码、解码与实现优化
在将训练完成的词元化工具(Trained Tokenizer)应用于新数据时,需先将输入字符串转换为字节序列,并严格遵循训练阶段生成的顺序执行合并操作。尽管该算法在概念层面极为直观,但朴素的实现方式(Naive Implementation)会产生巨大的计算开销(Computational Overhead),例如盲目遍历大量不相关的合并规则。在课程作业中,学员需从零开始工程化实现一个高度优化的 BPE 算法。这要求妥善处理预分词(Pre-tokenization)逻辑、严格管理特殊词元(Special Tokens),并巧妙运用并行计算(Parallel Computing)或提前退出策略(Early Exit Strategy),以确保词元化工具在大规模数据预处理流水线(Data Preprocessing Pipeline)中具备高效的可扩展性。

分词总结与下节课预告
词元化(Tokenization)始终是连接原始自然语言(Raw Natural Language)与神经网络架构(Neural Network Architectures)的基础桥梁。尽管基于字符(Character-based)、字节(Byte-based)和词的分词方法各自存在显著局限,但 BPE 提供了一种稳健且基于统计的启发式策略(Statistical Heuristic),能够依据语料库频率自适应地分配词表空间。尽管未来的模型架构可能会通过直接处理原始字节(Directly Processing Raw Bytes)来彻底绕过分词步骤(Bypass Tokenization),但 BPE 目前仍是业界的实际标准(De facto Standard)。下一讲将转向 PyTorch 框架基础(PyTorch Fundamentals),重点讲解细粒度的资源核算(Fine-grained Resource Accounting)、精确的浮点运算次数(Floating Point Operations, FLOPs)追踪,以及构建高效、可扩展模型训练(Scalable Model Training)所需的底层计算原语(Compute Primitives)。